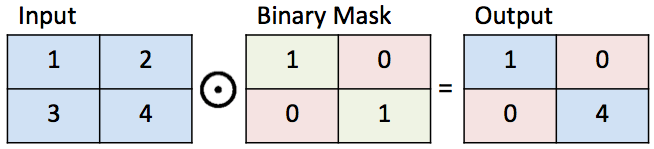
| БрМЭЦМі: |
БОЮФРДздcsdnЃЌБОЮФгУЕФР§згЪЧСГВПЭМЯёЃЌЕЋ DCGANsвВПЩвдБЛбЕСЗзіЦфЫћРраЭЕФЭМЯёаоИД.
|
|
ЩшМЦЪІКЭЩугАЪІгУФкШнздЖЏЬюВЙРДВЙГфЭМЯёжаВЛЯывЊЕФЛђШБЪЇЕФВПЗжЁЃгыжЎЯрЫЦЕФММЪѕЛЙгаЭМЯёЭъЩЦКЭаоИДЁЃЪЕЯжФкШнздЖЏЬюВЙЃЌЭМЯёЭъЩЦКЭаоИДЕФЗНЗЈгаКмЖрЁЃБОЮФНщЩмЕФЪЧ
Raymond Yeh КЭ Chen Chen ЕШШЫЕФТлЮФЁИSemantic Image Inpainting
with Perceptual and Contextual LossesЁЙжаЕФЗНЗЈЃЌДЫТлЮФгк 2016Фъ
7дТ 26Ше дк arXiv ЩЯЗЂБэЁЃетЦЊТлЮФбнЪОСЫШчКЮЭЈЙ§вЛИі DCGAN гУЩюЖШбЇЯАНјааЭМЯёаоИДЁЃБОЮФУцЯђвЛАуЕФММЪѕЖСепЃЌгаВПЗжЩюЖШФкШнеыЖдгаЛњЦїбЇЯАЛљДЁЕФШЫЁЃ
Мг [ML-Heavy] етИіБъМЧЕФВПЗжШчЙћФуВЛЯыжЊЕРЬЋЖрЯИНкОЭПЩвдЬјЙ§ЁЃБОЮФАИР§гУЕФЪЧаоВЙШЫСГЭМЦЌШБЪЇЯёЫиЁЃ
ФПТМ
НщЩм
ЕквЛВНЃКАбЭМЯёНтЮіГЩИХТЪЗжВМжаЕФбљБОЕу
ЕкЖўВНЃКПьЫйЩњГЩЮБдьЭМЯё
ЕкШ§ВНЃКевЕНаоИДЭМЯёЕФзюМбЮБдьЭМЦЌ
НсТл
ЭъГЩЭМЯёаоИДашвЊШ§ВНЁЃ
1. ЮвУЧЪзЯШвЊАбЭМЯёНтЮіГЩИХТЪЗжВМжаЕФбљБОЕу
2. етжжНтЮіШУЮвУЧбЇЯАШчКЮВњЩњЮБЭМЯё
3. НгзХЮвУЧОЭФмевЕНВЙШЋаоИДЫљашЕФзюМбЮБЭМЯё

Р§Шч PSжаздЖЏФЈШЅЭМЯёжаВЛЯывЊЕФВПЗжЃЈЭМЯёРДдДЃКCCЃЉ
ЕквЛВНЃКАбЭМЯёНтЮіГЩИХТЪЗжВМжаЕФбљБОЕу
ШчКЮЬюВЙШБЪЇЕФаХЯЂФиЃП
дкЩЯУцЕФР§згжаЃЌЯыЯѓФувЊЙЙНЈвЛИіЬюВЙШБЪЇЫщЦЌЕФЯЕЭГЁЃФуИУдѕУДзіФиЃПФуШЯЮЊШЫФдЪЧШчКЮзіЕНЕФФиЃПФугУЕНЕФЪЧКЮжжаХЯЂЃПдкБОЮФжаЮвУЧжївЊЙизЂСНжжРраЭЕФаХЯЂЃК
1. ЛЗОГаХЯЂЃКФуПЩвдЭЈЙ§жмЮЇЯёЫиЕуЕФаХЯЂЭЦЖЯГіШБЪЇЕФЯёЫиЕуЪЧЪВУДЁЃ
2. жЊОѕаХЯЂЃКФуЛсЬюВЙвЛаЉФуШЯЮЊЪЧЁИе§ГЃЁЙЕФФкШнЃЌБШШчФудкЯжЪЕЩњЛюжаЛђЦфЫћЭМЯёжаПЩФмПДЕНЕФЖЋЮїЁЃ
етСНРраХЯЂЖМКмживЊЁЃУЛгаЛЗОГаХЯЂЃЌФуШчКЮжЊЕРИУЬюВЙЪВУДЖЋЮїФиЃПЖјУЛгажЊОѕаХЯЂЕФЛАЃЌФЧКЯЪЪЕФЬюГфФкШнОЭЬЋЖрСЫЁЃФЧаЉЛњЦїШЯЮЊЪЧЁИе§ГЃЁЙЕФЖЋЮївВаэЖдШЫРрРДЫЕВЂВЛе§ГЃЁЃ
гавЛИіФмЭЌЪБзЅзЁетСНЕуЬиадЕФзМШЗгжжБЙлЕФЫуЗЈЪЧКмАєЕФЃЌетИіЫуЗЈФмЙЛж№ВНеЙЪОШчКЮаоИДвЛИіЭМЯёЁЃЖдЬиЖЈЧщаЮДДдьетбљвЛИіЫуЗЈвВаэЪЧПЩФмЕФЃЌЕЋУЛгаШЫжЊЕРШчКЮаДГівЛИіЭЈгУЕФЫуЗЈЁЃНёЬьзюКУЕФЗНЗЈгУЕФЪЧЭГМЦбЇЃЌВЂЭЈЙ§ЛњЦїбЇЯАШЅбЇЯАвЛИіНгНќЕФММЪѕЁЃ
ЕЋЭГМЦбЇдѕУДФмгУдкетРяФиЃПетаЉЪЧЭМЯёАЁЃЁ
ЮЊСЫНтОі етИіЮЪЬтЃЌШУЮвУЧДгвЛжжИХТЪЗжВМШыЪжЃЌетжжЗжВМвбОЮЊШЫЪьжЊВЂЧвПЩвдМђНрЕигУЗтБеЕФаЮЪНБэЪОЃКе§ЬЌЗжВМЁЃетРяЪЧе§ЬЌЗжВМЕФИХТЪУмЖШКЏЪ§ЃЈprobability
density function ЃЌPDFЃЉ ЕФЁЃPDFКЏЪ§ПЩвдетбљНтЪЭЃКбизХЪфШыПеМфЕФЫЎЦНЗНЯђЃЌзнзјБъжсЯдЪОЕФЪЧФГИіЪфШыГіЯжЕФИХТЪЁЃЃЈШчЙћФуИааЫШЄЃЌЛГіетжжЧњЯпЕФДњТыдк
https://github.com/bamos/dcgan-completion.tensorflow/blob/master/simple-distributions.pyЃЉ
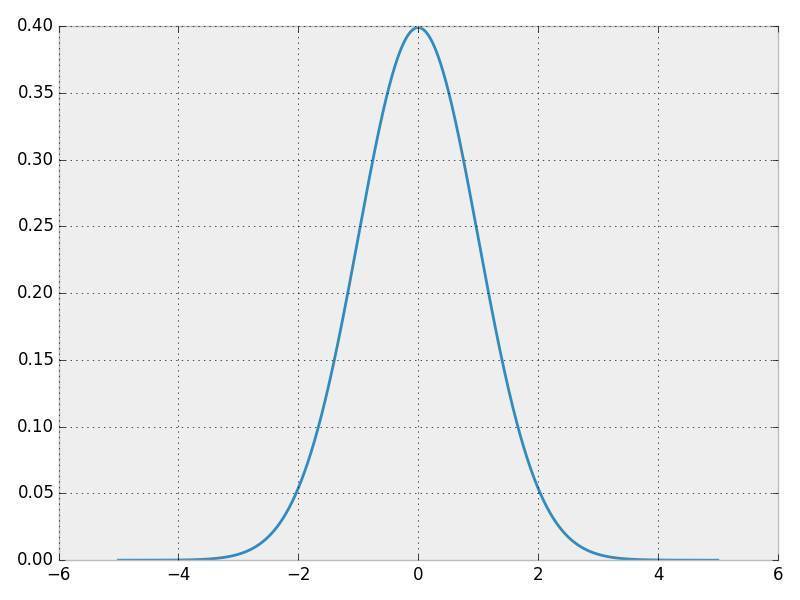
вЛИіе§ЬЌЗжВМЕФИХТЪУмЖШКЏЪ§ЃЈPDFЃЉ
ШУЮвУЧДгетИіЗжВНжаШЁбљвдЛёШЁвЛаЉЪ§ОнЁЃвЊШЗБЃФуРэНтСЫPDF КЭетаЉбљБОЕФСЊЯЕЁЃ
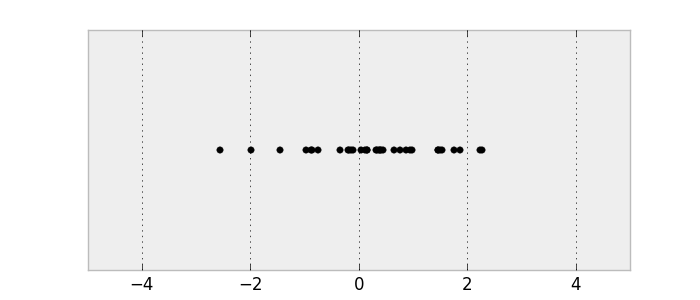
вЛИіе§ЬЌЗжВМжаШЁГіЕФбљБО
етЪЧвЛИівЛЮЌИХТЪЗжВМЃЌвђЮЊЪфШыжЛгавЛИіЮЌЖШЁЃЮвУЧПЩвдЖдЖўЮЌЗжВМзіЭЌбљЕФЪТЧщЁЃ
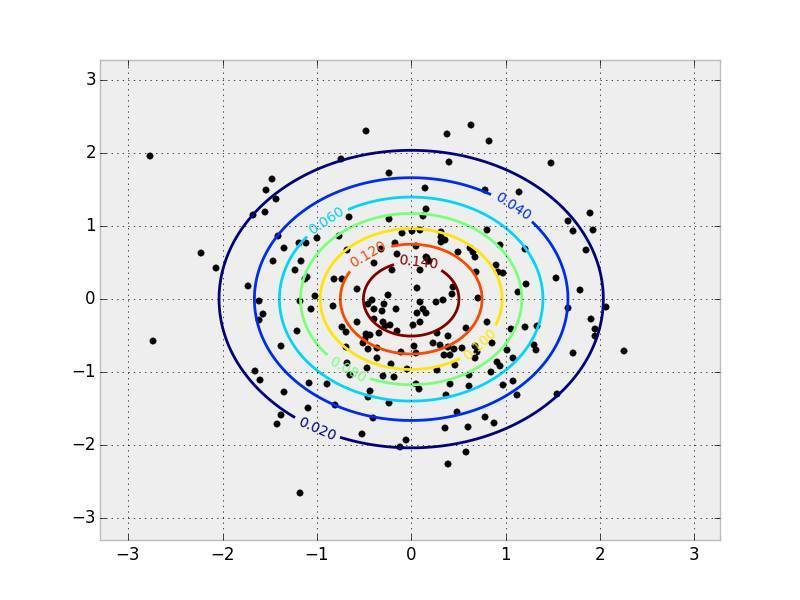
вЛИіЖўЮЌе§ЬЌЗжВМЕФ PDF КЭбљБОЁЃPDF гУЕШжЕЯпБэЪОЃЌбљБОИВИЧдкЫќЩЯЗНЁЃ
ЭМЯёКЭЭГМЦбЇжЎМфЕФЙиМќСЊЯЕдкгкЃЌЮвУЧПЩвдАбЭМЯёНтЮіГЩвЛИіИпЮЌИХТЪЗжВМжаЕФбљБОЕуЁЃЯыЯѓвЛЯТФуе§ФУзХЯрЛњХФееЁЃетеХееЦЌЩЯгаЪ§СПгаЯоЕФЯёЫиЕуЁЃФуПЩвдШЯЮЊФуИеХФЯТЕФетеХееЦЌЩЯЕФЯёЫиЕуЕФИХТЪзщГЩСЫвЛИіИХТЪЗжВМЁЃЕБФугУЯрЛњХФетеХееЦЌЪБЃЌФуОЭЪЧдкДгетИіИДдгЕФИХТЪЗжВМжаШЁбљЁЃетжжЗжВМОЭЪЧЮвУЧгУРДХаЖЯЪВУДбљЕФФкШне§ГЃЛђВЛе§ГЃЕФвРОнЁЃдкБОЮФжаЃЌЮвУЧвЊгУЕФЪЧгУ
RGB беЩЋФЃЪНБэЪОЕФВЪЩЋЭМЦЌЁЃЮвУЧЕФЭМЯёПэЖШЮЊ64ЯёЫиЃЌИпЖШвВЮЊ64ЯёЫиЃЌвђДЫЮвУЧЕФИХТЪЗжВМга 64?64?3Ёж12k
ИіЮЌЖШЁЃЭМЦЌВЛЯёе§ЬЌЗжВМЃЌЮвУЧВЛжЊЕРеце§ЕФИХТЪЗжВМЃЌЮвУЧжЛФмЪеМЏбљБОЕуЁЃ
ФЧУДИУдѕбљаоИДЭМЦЌФиЃП
ШУЮвУЧЪзЯШПМТЧЯТжЎЧАЕФЖрдЊЖЏЬЌЗжВМЁЃЖдгк x=1 ЃЌзюгаПЩФмЕФ y жЕЪЧЖрЩйЃПЮвУЧПЩвдЭЈЙ§ x=1
ЙЬЖЈЪБдкЫљгаПЩФмЕФ y жЕЩЯзюДѓЛЏ PDF ЕФжЕРДевЕНетИі y ЁЃ
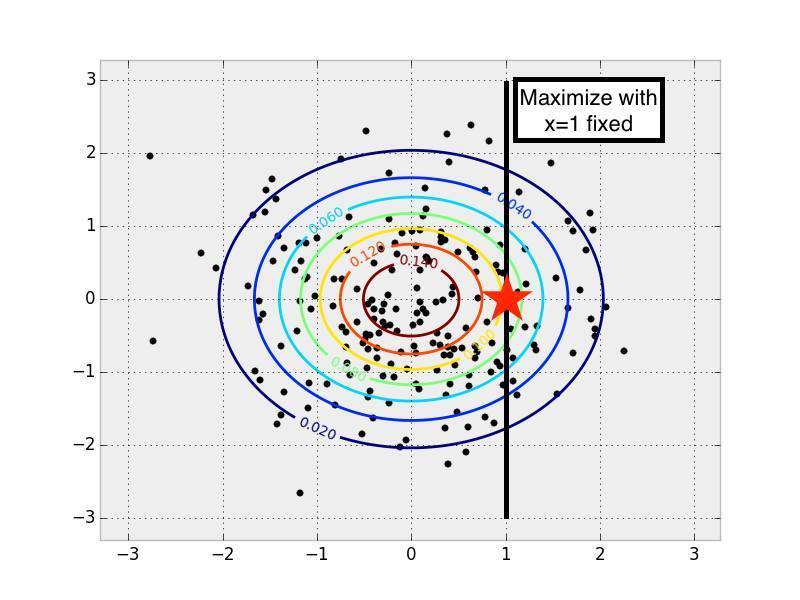
дквЛИіЖрдЊе§ЬЌЗжВМжаЕБ x ЮЊФГаЉЙЬЖЈжЕЪБевЕНЖдгІзюгаПЩФмЕФ y жЕ
ЕБЮвУЧжЊЕРвЛаЉжЕВЂЯыаоИДЫљгаШБЪЇжЕЪБЃЌетИіИХФюКмздШЛЕиОЭбгЩьЕНСЫЭМЯёИХТЪЗжВМжаЁЃЮвУЧдкбАевЫљгаПЩФмЕФШБЪЇжЕЪБЃЌОЭАбЫќЕБзїСЫвЛИізюДѓЛЏЮЪЬтРДЬжТлЁЃаоИДЕУЕНЕФОЭЪЧПЩФмадзюДѓЕФЭМЯёЁЃШчЙћжБНгЙлВье§ЬЌЗжВМжаФЧаЉбљБОЕуЃЌжЛДгбљБОЕужаевЕН
PDF ЫЦКѕЪЧКЯРэЕФЁЃЬєбЁФузюЯВЛЖЕФЭГМЦФЃаЭВЂЧвгУЫќРДФтКЯЪ§ОнОЭПЩвдСЫЁЃ
ЫфШЛКмШнвзФмДгбљБОЗжВМжаИДдГі PDFЃЌЕЋЖдгкЭМЯёетжжИќИДдгЕФЗжВМетЦфЪЕКмРЇФбЃЌЖјЧвЭЈГЃЖМКмМЌЪжЁЃетжжИДдгадВПЗжРДздгкИДдгЕФЬѕМўЯрЙиадЃКвЛИіЯёЫиЕуЕФжЕЪЧгЩЭМЯёжаЦфЫћЕуЕФжЕОіЖЈЕФЁЃЖјЧвдкЭЈгУ
PDF ЩЯНјаазюДѓЛЏЪЧвЛИіМЋЦфРЇФбЖјЧвМИКѕЪЧФбНтаЭЗЧЭЙгХЛЏЮЪЬтЁЃ
ЕкЖўВНЃКПьЫйЩњГЩЮБдьЭМЯё
бЇЯАШчКЮДгвЛИіЮДжЊИХТЪЗжВМжаВњЩњаТбљБОЕу
ЮвУЧВЛбЇЯАШчКЮМЦЫу PDFЃЌСэвЛжжГфЗжбаОПЙ§ЕФЭГМЦбЇИХФюЪЧбЇЯАШчКЮгУвЛИіЩњГЩФЃаЭЃЈgenerative
modelЃЉВњЩњаТЕФЃЈЫцЛњЃЉбљБОЕуЁЃЩњГЩФЃаЭвЛАуКмФббЕСЗЛђФбНтЃЌЕЋзюНќЩюЖШбЇЯАСьгђдкетЗНУцШЁЕУСЫКмДѓНјеЙЁЃYann
LeCun дкетЦЊ Quora ВЉЮФжаЖдШчКЮбЕСЗЩњГЩФЃаЭИјГіСЫКмКУЕФНщЩмЃЌАбЫќУшЪіГЩЛњЦїбЇЯАНќЪЎФъРДзюгавтЫМЕФРэФюЃК
Yann LeCun дкетЦЊQuora ВЉЮФжаНщЩмСЫЖдПЙадбЕСЗЁЃ(ВЉЮФЕижЗЃК_https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning/answer/Yann-LeCun?srid=nZuy_
(https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning/answer/Yann-LeCun?srid=nZuy)ЃЉ

EyeScream ВЉЮФжаЕФЖдПЙбЕСЗЕФНжЭЗАдЭѕгЮЯЗРрБШЃЈStreet
Fighter analogy for adversarial networksЃЉЁЃЃЈВЉЮФЕижЗЃКЃЉетаЉЭјТчЛЅЯрељЖЗВЂЧввЛЦ№ЗЂеЙНјВНЃЌОЭЯёСНИіЭцЖдеНгЮЯЗЕФШЫРрЁЃ
[ML-Heavy] ЩњГЩЖдПЙЭјТчЃЈGenerative Adversarial Net ЃЌGANЃЉЕФМмЙЙ
етИіРэФюЦ№ГѕЪЧдк Ian Goodfellow ЕШШЫЕФПЊДДадТлЮФЁИGenerative Adversarial
NetsЃЈGANsЃЉЁЙ жаЬсГіЕФЃЌТлЮФгк2014ФъЕФЩёОаХЯЂДІРэЯЕЭГЛсвщЃЈNeural Information
Processing SystemsЃЌNIPSЃЉЩЯЗЂБэЁЃЮвУЧЖЈвхвЛИібљБОКЭвЛИіДѓМвЖМЪьжЊЕФЗжВМЃЌАбЫќБэЪОЮЊ
pzЁЃетЦЊВЉЮФЪЃЯТЕФВПЗжЃЌЮвУЧЖМЛсгУpzРДБэЪОвЛИіЃ1ЕН1ЃЈАќРЈЃ1КЭ1ЃЉжЎМфЕФОљдШЗжВМЁЃЮвУЧгУ z~
pz РДБэЪОДгетИіЗжВМжаШЁбљГівЛИіЪ§зжЁЃШчЙћ pz ЪЧЮхЮЌЕФЃЌЮвУЧПЩвдЭЈЙ§ numpy гУвЛаа Python
ДњТыБэЪОЃК
z = np.random.uniform(-1, 1, 5)array([ 0.77356483,
0.95258473, -0.18345086, 0.69224724, -0.34718733])
ЯждкЮвУЧОЭгаСЫвЛИіПЩвдЧсЫЩДгжаШЁбљЕФМђЕЅЗжВМСЫЃЌЮвУЧПЩвдЖЈвхвЛИіКЏЪ§G(z)ЃЌетИіКЏЪ§ПЩвдДгдЪМИХТЪЗжВМжаЩњГЩбљБОЕуЁЃ
def G(z):
...
return imageSamplez = np.random.uniform(-1, 1,
5)imageSample = G(z)
ЫљвдЮвУЧдѕУДРДЖЈвхG(z)вдШУЫќвЛИіЪфШыЯђСПЃЌВЂЗЕЛивЛИіЭМЯёЃПЮвУЧНЋЪЙгУвЛИіЩюЖШЩёОЭјТчЁЃгааэЖрКмАєЕФНщЩмЩюЩёОЭјТчЕФЛљДЁжЊЪЖЃЌЫљвдЮвВЛдкетРяЫЕСЫЁЃЮвЕФЭЦМіЪЧЫЙЬЙИЃЕФ
CS231n
ПЮГЬЃЌIan Goodfellow ЕШШЫЕФ ЩюЖШбЇЯАЯрЙиЪщМЎЃЌЭМЯёФкКЫПЩЪгЛЏНтЪЭ
КЭОэЛ§ЫуЗЈжИФЯЃЈ convolution
arithmetic guide ЃЉ
гаКмЖрЭЈЙ§ЩюЖШбЇЯАЙЙНЈG(z)ЕФЗНЗЈЁЃзюдчФЧЦЊЩњГЩЖдПЙЭјТчТлЮФЬсГіСЫетИіРэФюЃЌвЛИібЕСЗСїГЬЃЌКЭГѕВНЕФЪЕбщадНсЙћЁЃКѓајКмЖрбаОПЖМНЈСЂдкетИіРэФюЩЯЃЌЯждкгаСЫКмДѓНјеЙЁЃзюНќвЛЦЊТлЮФ
ЁИгУЩюЖШОэЛ§ЩњГЩЖдПЙЭјТчНјааЗЧМрЖНБэеїбЇЯАЃЈUnsupervised Representation
Learning with Deep Convolutional Generative Adversarial
NetworksЃЉЁЙжаОЭЬсГіСЫвЛИіаТЗНЗЈЃЌИУТлЮФгЩ Radford, Luke Metz, КЭ Soumith
Chintala дк2016ФъЕФбЇЯАБэЪОЙњМЪЛсвщЃЈInternational Conference
on Learning RepresentationsЃЉЩЯЗЂБэЁЃЫќЬсГіСЫгУЮЂВНЗљЃЈfractionally-stridedЃЉОэЛ§НјааЭМЯёЩЯВЩбљЃЈupsampleЃЉЕФОэЛ§
ЩњГЩЖдПЙЭјТчЃЈ DCGANЃЉЁЃ
ЪВУДЪЧЮЂВНЗљОэЛ§ЃЌЫќУЧгжЪЧШчКЮНјааЭМЯёЩЯВЩбљЕФФиЃПVincent Dumoulin
КЭ Francesco Visin ЕФТлЮФЁИЩюЖШбЇЯАЕФОэЛ§ЫуЗЈжИФЯЃЈA guide to convolution
arithmetic for deep learningЃЉЁЙКЭ conv_arithmetic
ЪЧвЛИіаДЕФКмКУЕФЖдЩюЖШбЇЯАОэЛ§ЫуЗЈЕФНщЩмЁЃетИіПЩЪгЛЏзіЕФЗЧГЃАєЃЌКмжБЙлЕФеЙЯжСЫЮЂВНЗљОэЛ§ЪЧШчКЮЙЄзїЕФЁЃЪзЯШЃЌШЗБЃФуФмРэНтвЛИіе§ГЃЕФОэЛ§ЪЧШчКЮдкЪфШыПеМфЃЈРЖЩЋЃЉЛЌЙ§вЛИіФкКЫВЂВњЩњЪфГіПеМфЃЈТЬЩЋЃЉЕФЁЃетРяЃЌЪфГіБШЪфШыаЁЁЃЃЈШчЙћВЛРэНтЃЌЧыВЮдФ
the CS231n CNN section еТНкЛђОэЛ§ЫуЗЈжИФЯЁЃ
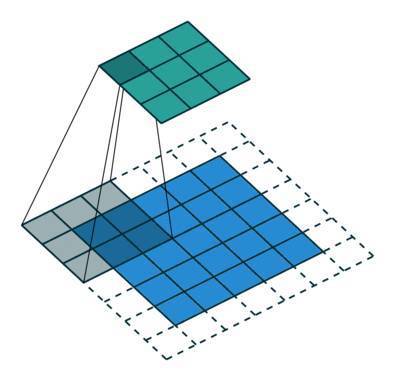
вЛИіДгЪфШыЃЈРЖЩЋЃЉЕНЪфГіЃЈТЬЩЋЃЉЕФОэЛ§ЪОвтЭМЁЃЭМЯёРДдДЃК vdumoulin/conv_arithmetic
НгЯТРДЃЌМйЩшФугавЛИі 3x3 ЕФЪфШыЁЃЮвУЧЕФФПБъЪЧЩЯВЩбљЃЌвђДЫЪфГіИќДѓаЉЁЃ ФуПЩвдАбЮЊВНЗљОэЛ§НтЪЭГЩРЉеЙЯёЫиЕуЃЌетбљЯёЫиЕужЎМфОЭЬюГфСЫКмЖр0ЁЃШЛКѓдкетИіРЉДѓКѓЕФПеМфЩЯОэЛ§ЃЌОЭЛсЕМжТИќДѓЕФЪфГіЁЃетРяЃЌЪфГіЪЧ
5x5ЁЃ
ДгЪфШыЃЈРЖЃЉЕНЪфГіЃЈТЬЃЉЕФЮЂВНЗљОэЛ§ЪОвтЭМЁЃЭМЯёРДдДЃКvdumoulin/conv_arithmetic
етРяаДвЛИіБпзЂЃЌЩЯВЩбљЕФОэЛ§ВугаКмЖрУћзжЃКШЋОэЛ§ЃЈfull convolutionЃЉЃЌЭјТчФкЩЯВЩбљЃЈ
in-network upsamplingЃЉЃЌЮЂВНЗљОэЛ§ЃЈfractionally-strided
convolutionЃЉЃЌЗДЯђОэЛ§ЃЈbackwards convolutionЃЉЃЌШЅОэЛ§ЃЈdeconvolutionЃЉЃЌЩЯОэЛ§ЃЈupconvolutionЃЉЃЌвдМАзЊжУОэЛ§ЃЈtransposed
convolutionЃЉЁЃгУЁИШЅОэЛ§ЁЙетИіЪѕгяЪЧЗЧГЃВЛЭЦМіЕФЃЌвђЮЊетЪЧвЛИіЙ§диЕФЪѕгяЃКдкЪ§бЇдЫЫуЛђМЦЫуЛњЪгОѕжаЕФЦфЫћгІгУгазХЭъШЋВЛЭЌЕФКЌвхЁЃ
ЯждкЮвУЧгаСЫЮЂВНЗљОэЛ§зїЮЊЛ§ФОЃЌЮвУЧжегкПЩвдБэЪО G(z) СЫЃЌЫќгУвЛИіЯђСП z~ p_z зїЮЊЪфШыЃЌВЂЪфГівЛИі
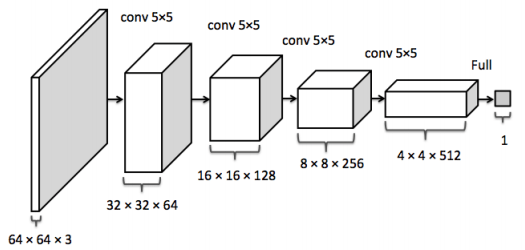
64x64x3 ЕФRGBЭМЯёЁЃ
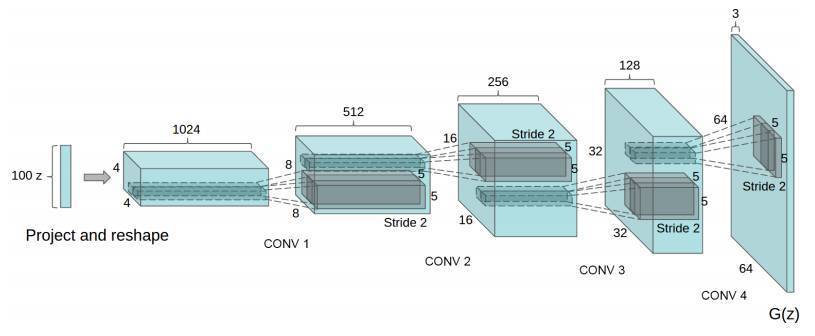
вЛжжгУ DCGAN ЙЙНЈЩњГЩЦї G(z) ЕФЗНЗЈЁЃЭМЯёРДдДЃКDCGAN paper
DCGAN ТлЮФЛЙеЙЯжСЫЦфЫћЕФММЧЩЃЌЛЙгаЖд DCGAN бЕСЗЕФЕїНкЗНЗЈЃЌБШШчгУХњЙщвЛЛЏЃЈbatch
normalizationЃЉЛђ leaky ReLUЁЃ
гУ G(z) ВњЩњЮБЭМЯё
ШУЮвУЧднЭЃЃЌИаМЄвЛЯТетИі G(z) ЗНГЬгаЖрЧПДѓАЩЁЃФЧЦЊ DCGAN ТлЮФНтЪЭСЫШчКЮдквЛИіЮдЪвЭМЯёЪ§ОнМЏжабЕСЗ
DCGANЁЃНгзХЖд G(zЃЉШЁбљЃЌОЭПЩвдВњЩњГіЮБЭМЦЌЁЊЩњГЩЦїШЯЮЊЕФЮдЪвбљУВЁЃетаЉЭМЦЌЖМВЛдкдЪМЪ§ОнМЏжаЃЁ

гУ DCGAN ЩњГЩЮдЪвЭМЯёЁЃЭМЦЌРДдДЃКDCGAN paper
ЖјЧвФувВПЩвддк z ЪфШыПеМфжаНјааЯђСПЫуЗЈЁЃНгЯТРДЪЧдквЛИіБЛбЕСЗЕУПЩвдЩњГЩСГВПЭМЯёЕФЭјТчЩЯЁЃ
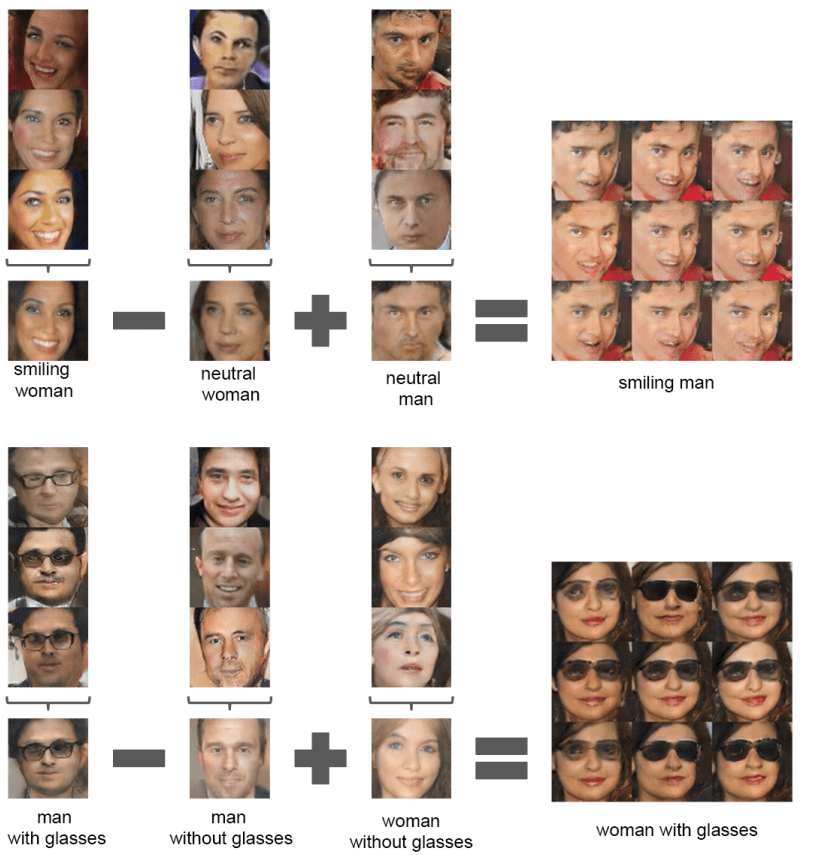
гУ DCGAN ЕФСГВПЫуЗЈЁЃЭМЦЌРДдДЃКDCGAN paper
[ML-Heavy]бЕСЗDCGANs
ЯждкЮвУЧвбОЖЈвхСЫ G(z)ЃЌВЂЧвМћЪЖЕНСЫетИіЗНГЬгаЖрЧПДѓЃЌЮвУЧИУШчКЮбЕСЗЫќФиЃПЮвУЧашвЊевЕНКмЖрЧБдкБфСПЁЃетОЭЪЧашвЊгУЕНЖдПЙЭјТчРэФюЕФЕиЗНСЫЁЃ
ЪзЯШШУЮвУЧЖЈвхвЛаЉБъЪЖЗћЁЃАбЮвУЧЪ§ОнЕФЃЈЮДжЊЃЉИХТЪЗжВМЖЈвхГЩ pdataЁЃЮвУЧвВПЩвдАб G(z)
ЃЈz~pzЃЉНтЪЭГЩДгвЛИіИХТЪЗжВМжаЬсШЁбљБОЕуЃЌШУЮвУЧАбЫќНазіЩњГЩИХТЪЗжВМЃЌpgЁЃ

МјБ№ЦїЭјТч D(x) ЪфШыФГИіЭМЯё xЃЌВЂЗЕЛиЭМЯё x Дг pdata жаШЁбљЕФИХТЪЁЃЕБЭМЯёЪЧРДздгкpdata
ЪБЃЌМјБ№ЦїгІИУФмЗЕЛивЛИіНгНќ1ЕФжЕЃЌЖјШчЙћЭМЯёЪБЮБдьЕФЃЌБШШчДг pg ШЁбљЕФЭМЯёЃЌМјБ№ЦїгІИУФмЗЕЛивЛИіНгНќ
0 ЕФжЕЁЃдк DCGAN жаЃЌD(x) ЪЧвЛИіДЋЭГОэЛ§ЭјТчЁЃ
МјБ№ЦїОэЛ§ЭјТчЁЃЭМЯёРДдДЃКinpainting paper
бЕСЗМјБ№Цї D(x) ЕФФПБъЪЧЃК
1. ЖдгкецЪЕЪ§ОнЗжВМ x~ pdataжаЕФУПИіЭМЯёзюДѓЛЏ D(x)ЁЃ
2. ЖдгкРДздЗЧецЪЕЪ§ОнЗжВМ x? pdata ЕФУПИіЭМЯёАб D(x) зюаЁЛЏЁЃ
бЕСЗЩњГЩЦї G(z) ЕФФПБъЪЧЩњГЩФЧаЉПЩвдЦлЦ D ЕФбљБОЁЃЩњГЩЦїЪфГіЕФЪЧвЛИіЭМЯёЃЌЖјЧвПЩвдгУзїМјБ№ЦїЕФЪфШыЁЃвђДЫЩњГЩЦїЯывЊзюДѓЛЏ
D(G(z))ЃЌЛђепЭЌбљЕФзюаЁЛЏ ЃЈ1-D(G(z)ЃЉЃЌвђЮЊ D ЪЧЙРжЕЗЖЮЇдк 0 КЭ 1 жЎМфЕФИХТЪЗжВМЁЃ
е§ШчФЧЦЊТлЮФжаеЙЪОЕФЃЌЖдПЙЭјТчЕФбЕСЗЪЧЭЈЙ§вдЯТЕФМЋДѓМЋаЁгЮЯЗЭъГЩЕФЁЃЕквЛИіЬѕМўЕФЦкЭћБщРњСЫецЪЕЪ§ОнЗжВМКЭЕФбљБОЃЌЕкЖўИіЬѕМўЕФЦкЭћБщРњ
G(z)~pg жаЕФбљБОЁЃ
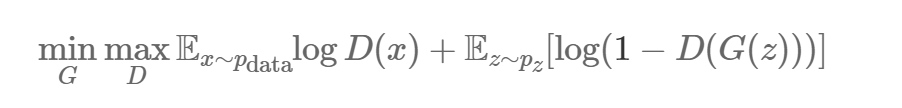
ЮвУЧЖдD КЭ G ЕФбЕСЗНЋЭЈЙ§ШЁЕУЦкЭћжЕЬнЖШВЂПМТЧЫќУЧЕФВЮЪ§НјааЁЃЮвУЧжЊЕРШчКЮПьЫйМЦЫуетИіБэДяЪНЕФУПИіВПЗжЁЃЦкЭћжЕЪЧдкГпДчmЕФЮЂаЭХњДЮжаМЦЫуЕФЃЌФкВПзюДѓжЕПЩвдгУЬнЖШВНЙРЫуГіРДЁЃk=1
БЛжЄУїгаРћгкбЕСЗЁЃ
Аб ІШd зїЮЊМјБ№ЦїЕФВЮЪ§ЃЌІШg зїЮЊЩњГЩЦїЕФВЮЪ§ЁЃІШd КЭ ІШg ЕФЬнЖШПЩвдЭЈЙ§ЗДЯђДЋВЅМЦЫуГіРДЃЌвђЮЊ
D КЭ G ЪЧгУШнвзРэНтЕФЩёОдЊЭјТчГЩЗжЖЈвхЕФЁЃетЪЧ GAN жаЕФбЕСЗЫуЗЈЁЃРэЯыЧщПіЯТвЛЕЉетвЛВНЭъГЩКѓЃЌpg=pdataЃЌвђДЫ
G(z) ОЭФмДг pdataжаВњЩњГіаТЕФбљБОЕуЁЃ

GAN paperРяЕФGANбЕСЗЫуЗЈ
вбгаЕФGANКЭ DCGANЪЕЯжЗНЗЈ
GitHub ЩЯгаКмЖрКУЕФ GAN КЭ DCGAN ЪЕЯжЗНЗЈЃК
goodfeli/adversarial :
GAN ТлЮФзїепЗХГіЕФ Theano GAN ЪЕЯжЗНЗЈЁЃtqchen/mxnet-gan :
ЗЧе§ЪНMXNet GANЪЕЯжЁЃ
Newmu/dcgan_code : DCGAN ТлЮФзїепЗХГіЕФTheano
DCGAN ЪЕЯжЗНЗЈЁЃ
soumith/dcgan.torch:
DCGAN ТлЮФзїепжЎвЛЃЈSoumith ChintalaЃЉЗХГіЕФTorch DCGAN ЪЕЯжЗНЗЈЁЃ
carpedm20/DCGAN-tensorflow : ЗЧе§ЪН
TensorFlow DCGANU ЪЕЯжЁЃ
openai/improved-gan: OpenAIЕквЛЦЊТлЮФБГКѓЕФДњТыЁЃДѓЗљаое§СЫcarpedm20/DCGAN-tensorflowЁЃ
mattya/chainer-DCGAN :ЗЧе§ЪН
Chainer DCGAN ЪЕЯжЁЃ
jacobgil/keras-dcgan:
ЗЧе§ЪНЃЈвВВЛЭъећЃЉKeras DCGAN ЪЕЯжЁЃ
НгзХЃЌЮвУЧНЋдк carpedm20/DCGAN-tensorflow НјааЙЙНЈЁЃ
[ML-Heavy]TensorFlowЩЯЕФ DCGANs
етВПЗжЕФЪЕЯжЗНЗЈдкЮвЕФGitHubзЪдДПтжаЃЈbamos/dcgan-completion.tensorflow
ЃЉЮвдкетРязХжиЧПЕїетВПЗжЕФДњТыРДздTaehoon Kim ЕФзЪдДПтЃЈ carpedm20/DCGAN-tensorflow
ЃЉЁЃдкетРягУЮвЕФзЪдДПтЃЌетбљдкЯТИіЛЗНкЮвУЧОЭФмЧсЫЩдЫгУЭМЦЌаоИДЕФВПЗжСЫЁЃ
етИіЙ§ГЬДѓВПЗжЖМдквЛИіНазі DCGAN ЕФ Python РрЃЈclassЃЉжаЃЈmodel.py
ЃЉЁЃЯёетбљАбЫљгаЖЋЮїЖМЗХдквЛИіРржаЗЧГЃгагУЃЌвђЮЊбЕСЗКѓжаМфзДЬЌПЩвдБЛБЃДцЦ№РДЃЌвдБуКѓУцЪЙгУЁЃ
ЪзЯШШУЮвУЧЖЈвхЩњГЩЦїКЭМјБ№ЦїЁЃlinear, conv2d_transpose,
conv2d, КЭ lrelu КЏЪ§ЖМЪЧдк ops.py
жаЖЈвхЕФЁЃ
| def generator(self,
z, y=None):
ЁЁЁЁself.z_, self.h0_w, self.h0_b = linear(z,
self.gf_dim*8*4*4,
ЁЁЁЁ'g_h0_lin', with_w=True)
ЁЁЁЁself.h0 = tf.reshape(self.z_, [-1, 4, 4,
self.gf_dim * 8])
ЁЁЁЁh0 = tf.nn.relu(self.g_bn0(self.h0))
ЁЁЁЁself.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,
ЁЁЁЁ[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1',
with_w=True)
ЁЁЁЁh1 = tf.nn.relu(self.g_bn1(self.h1))
ЁЁЁЁh2, self.h2_w, self.h2_b = conv2d_transpose(h1,
ЁЁЁЁ[self.batch_size, 16, 16, self.gf_dim*2],
name='g_h2', with_w=True)
ЁЁЁЁh2 = tf.nn.relu(self.g_bn2(h2))
ЁЁЁЁh3, self.h3_w, self.h3_b = conv2d_transpose(h2,
ЁЁЁЁ[self.batch_size, 32, 32, self.gf_dim*1],
name='g_h3', with_w=True)
ЁЁЁЁh3 = tf.nn.relu(self.g_bn3(h3))
ЁЁЁЁh4, self.h4_w, self.h4_b = conv2d_transpose(h3,
ЁЁЁЁ[self.batch_size, 64, 64, 3], name='g_h4',
with_w=True)
ЁЁЁЁreturn tf.nn.tanh(h4) def discriminator(self,
image, reuse=False, y=None):
ЁЁЁЁif reuse:
ЁЁЁЁtf.get_variable_scope().reuse_variables()
ЁЁЁЁh0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
ЁЁЁЁh1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2,
name='d_h1_conv')))
ЁЁЁЁh2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4,
name='d_h2_conv')))
ЁЁЁЁh3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8,
name='d_h3_conv')))
ЁЁЁЁh4 = linear(tf.reshape(h3, [-1, 8192]), 1,
'd_h3_lin')
ЁЁЁЁreturn tf.nn.sigmoid(h4), h4 |
ЕБЮвУЧГѕЪМЛЏетИіРрЪБЃЌЮвУЧОЭгУетаЉКЏЪ§ДДдьСЫФЃаЭЁЃЮвУЧашвЊСНжжАцБОЕФМјБ№ЦїЃЌЫћУЧЙВЯэЃЈЛђдйЪЙгУЃЉЭЌбљЕФВЮЪ§ЁЃвЛИігУгкРДздЪ§ОнЗжВМЕФаЁХњЭМЯёЃЌСэвЛИігУгкРДздЩњГЩЦїЕФаЁХњЭМЯёЁЃ
| ЁЁself.G = self.generator(self.z)self.D,
self.D_logits = self.discriminator(self.images)self.D_,
self.D_logits_ = self.discriminator(self.G, reuse=True) |
НгзХЃЌЮвУЧНЋЖЈвхЫ№ЪЇКЏЪ§ЁЃдкетРяВЛгУЧѓКЭЃЈsumsЃЉЃЌЮвУЧгУDЕФдЄВтКЭЮвЯыШУЫќИќКУЕиЙЄзїЖјЖдЫќЕФЦкЭћжЎМфЕФНЛВцьиЃЈ
cross entropy (https://en.wikipedia.org/wiki/Cross_entropy)ЃЉЁЃМјБ№ЦїЯыШУРДздецЪЕЪ§ОнЕФдЄВтЖМЮЊ1ЃЌЖјРДздЩњГЩЦїЕФМйдьЪ§ОнЖМЮЊ0ЁЃЩњГЩЦїЯыШУМјБ№ЦїЕФЫљгадЄВтЖМЮЊ1.
| ЁЁself.d_loss_real
= tf.reduce_mean(
ЁЁЁЁtf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,
ЁЁЁЁtf.ones_like(self.D)))self.d_loss_fake =
tf.reduce_mean(
ЁЁЁЁtf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
ЁЁЁЁtf.zeros_like(self.D_)))self.d_loss = self.d_loss_real
+ self.d_loss_fakeself.g_loss = tf.reduce_mean(
ЁЁЁЁtf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
ЁЁЁЁtf.ones_like(self.D_))) |
ЗжБ№ДгУПИіФЃаЭжаЪеМЏБфСПЃЌШУЫќУЧПЩвдБЛЗжПЊбЕСЗЁЃ
| ЁЁt_vars = tf.trainable_variables()self.d_vars
= [var for var in t_vars if 'd_' in var.name]self.g_vars
= [var for var in t_vars if 'g_' in var.name] |
ЯждкЮвУЧзМБИКУгХЛЏВЮЪ§СЫЃЌЮвУЧвЊгУЕФЪЧ ADAM (https://arxiv.org/abs/1412.6980)ЃЌетЪЧвЛжжЪЪгІЕФЗЧЭЙгХЛЏЗНЗЈЃЌЭЈГЃгУгкЯжДњЩюЖШбЇЯАжаЁЃADAM
ОГЃЛсгы SGD ОКељЃЌЖјЧвЭЈГЃВЛашвЊЪжЖЏЕїНкбЇЯАЫйТЪЃЌЖЏСПЃЌМАЦфЫћГЌВЮЪ§ЃЈhyper-parameterЃЉЁЃ
| ЁЁd_optim = tf.train.AdamOptimizer(config.learning_rate,
beta1=config.beta1) \
ЁЁЁЁ.minimize(self.d_loss, var_list=self.d_vars)g_optim
= tf.train.AdamOptimizer(config.learning_rate,
beta1=config.beta1) \
ЁЁЁЁ.minimize(self.g_loss, var_list=self.g_vars) |
ЮвУЧзМБИКУБщРњЪ§ОнСЫЁЃдкУПвЛИіЪБЦкЃЌЮвУЧдквЛИіаЁХњЭМЦЌжаШЁбљЃЌдЫаагХЛЏЦїЩ§МЖЭјТчЁЃгаШЄЕФЪЧЃЌШчЙћ
G жЛИќаТСЫвЛДЮЃЌМјБ№ЦїЕФЫ№КФОЭВЛЛсЮЊСуЁЃЖјЧвЃЌЮвШЯЮЊзюКѓЖд d_loss_fake КЭ d_loss_real
КЏЪ§ЕФЖюЭтЕїгУв§ЗЂСЫвЛЕуВЛБивЊЕФМЦЫуЃЌЖјЧвЪЧЖргрЕФЃЌвђЮЊетаЉжЕвбОзїЮЊ d_optim КЭ g_optim
ЕФвЛВПЗжМЦЫуЙ§СЫЁЃзїЮЊ TensorFlow жаЕФвЛЯюСЗЯАЃЌФуПЩвдЪдзХгУетИіВПЗжШЅгХЛЏЃЌВЂИјдЪМ repo
ЗЂЫЭвЛИі PR ЁЃ
| for epoch in
xrange(config.epoch):
ЁЁЁЁ...
ЁЁЁЁfor idx in xrange(0, batch_idxs):
ЁЁЁЁbatch_images = ...
ЁЁЁЁbatch_z = np.random.uniform(-1, 1, [config.batch_size,
self.z_dim]) \
ЁЁЁЁ.astype(np.float32)
ЁЁЁЁ# Update D network
ЁЁЁЁЃЃИќаТвЛИі D ЭјТч
ЁЁЁЁ_, summary_str = self.sess.run([d_optim,
self.d_sum],
ЁЁЁЁfeed_dict={ self.images: batch_images, self.z:
batch_z })
ЁЁЁЁ# Update G network
ЁЁЁЁЃЃИќаТвЛИі G ЭјТч
ЁЁЁЁ_, summary_str = self.sess.run([g_optim,
self.g_sum],
ЁЁЁЁfeed_dict={ self.z: batch_z })
ЁЁЁЁ# Run g_optim twice to make sure that d_loss
does not go to zero*
ЁЁЁЁ# (different from paper)
ЁЁЁЁЃЃдЫааСНДЮ*g_optim вдШЗБЃ d_loss ВЛЛсБфГЩ0
ЁЁЁЁЃЃЃЈгыТлЮФРяВЛвЛбљЃЉ
ЁЁЁЁ_, summary_str = self.sess.run([g_optim,
self.g_sum],
ЁЁЁЁfeed_dict={ self.z: batch_z })
ЁЁЁЁerrD_fake = self.d_loss_fake.eval({self.z:
batch_z})
ЁЁЁЁerrD_real = self.d_loss_real.eval({self.images:
batch_images})
ЁЁЁЁerrG = self.g_loss.eval({self.z: batch_z}) |
етОЭЭъГЩСЫЃЁЕБШЛЭъећДњТыгаИќЖрзЂЪЭЃЌФуПЩвддк model.py (https://github.com/bamos/dcgan-completion.tensorflow/blob/master/model.py)
ЩЯВщПДЁЃ
дкФуздМКЕФЭМЯёЩЯдЫаа DCGAN
етВПЗжЕФЪЕЯжЗНЗЈдкЮвЕФGitHubзЪдДПтжаЃЈbamos/dcgan-completion.tensorflow
ЃЉЮвдкетРязХжиЧПЕїетВПЗжЕФДњТыРДздTaehoon Kim ЕФзЪдДПтЃЈ carpedm20/DCGAN-tensorflow
ЃЉЁЃЮвУЧдкетРягУЮвЕФзЪдДПтЃЌетбљдкЯТИіЛЗНкЮвУЧОЭФмЧсЫЩдЫгУЭМЦЌаоИДЕФВПЗжСЫЁЃетРягавЛЕуОЏИцЃЌШчЙћФуУЛгазАдиСЫ
CUDA ЕФ GPUЃЌгУетИіВПЗжЕФДњТыбЕСЗЩёОЭјТчПЩФмЛсЗЧГЃТ§ЁЃ
ШчЙћЯТУцЕФВПЗжФугУВЛЦ№РДЧыЗЂаХЯЂИјЮвЃЁ
ЪзЯШШУЮвУЧАбЮвЕФ bamos/dcgan-completion.tensorflow
КЭ OpenFace
зЪдДПтИДжЦЙ§РДЁЃЮвУЧвЊгУ OpenFace ЕФ Python-only ВПЗждЄДІРэЭМЯёЁЃВЛвЊЕЃаФЃЌФуВЛашвЊАВзА
OpenFace ЕФ Torch ИНЪєЁЃЮЊетИіДДдьвЛИіаТЕФЙЄзїФПТМЃЌВЂИДжЦзЪдДПтЃК
| git clone https://github.com/cmusatyalab/openface.git
git clone https://github.com/bamos/dcgan-completion.tensorflow.git |
ЯТвЛВНЃЌАВзА OpenFace ЕФ Python ПтЃЌетбљЮвУЧОЭПЩвддЄДІРэЭМЯёСЫЁЃOpenFace
ЯждкгУЕФЪЧ Python 2,ЕЋШчЙћФуИааЫШЄЕФЛАЃЌФуАбЫќзіГЩ Python 3 ПЩМцШнЕФЛАЮввВКмПЊаФЃЌБ№ЭќСЫЗЂЫЭвЛИіетРяЬсЕНЕФ
PRЁЃШчЙћФугУЕФВЛЪЧащФтЛЗОГЃЌФугІИУдкдЫаа setup.py ЪБгУ sudo ШЅШЋОжАВзА OpenFaceЁЃ
cd openface
pip2 install -r requirements.txt
ЁЁpython2 setup.py installcd .. |
НгзХЯТдивЛИіСГВПЭМЯёЪ§ОнМЏЁЃФугаУЛгаБъЧЉЖМЮоЫљЮНЃЌЮвУЧЛсШгЕєЫќУЧЕФЁЃетРяСаГіВПЗжПЩбЁдёЕФЃК:
MS-Celeb-1M , CelebA ЃЌCASIA-WebFace , FaceScrub, LFW
(), вдМА MegaFace ЁЃАбЪ§ОнМЏЗХШы dcgan-completion.tensorflow/data/your-dataset/raw
жаЃЌБэУїетИіЪ§ОнМЏЪЧЮДОМгЙЄЕФЭМЦЌЁЃЯждкЮвУЧОЭгУ OpenFace ЕФХХСаЙЄОпАбЭМЯёгыДІРэГЩ 64x64
ЕФЁЃ
| ЁЁЁЁ./openface/util/align-dlib.py
data/dcgan-completion.tensorflow/data/your-dataset/raw
align innerEyesAndBottomLip data/dcgan-completion.tensorflow/data/your-dataset/aligned
--size 64 |
зюКѓЮвУЧОЭАбХХСаКУЕФЭМЯёФПТМЦНЦЬЃЌетбљЫќОЭжЛЛсАќКЌЭМЯёЖјУЛгазгФПТМСЫЁЃ
cd dcgan-completion.tensorflow/data/your-dataset/aligned
bfind . -name ' .png' -exec mv {} . \;
ЁЁfind . -type d -empty -deletecd ../../.. |
ЮвУЧзМБИКУбЕСЗ DCGAN СЫЁЃдкАВзАСЫ TensorFlow вдКѓЃЌПЊЪМбЕСЗЁЃ
| ЁЁ./train-dcgan.py
--dataset ./data/your -dataset/aligned --epoch
20 |
ФуПЩвддк samples ФПТМжаВщПДРДздЩњГЩЦїЕФЫцЛњШЁбљЭМЯёПДЦ№РДЪЧЪВУДбљзгЁЃЮвдк CASIA-WebFace
КЭ FaceScrub Ъ§ОнМЏЩЯбЕСЗЃЌвђЮЊЮвЪжЭЗОЭгаЫќУЧЁЃдк14ИіЕќДњжмЦкКѓЃЌЮвЕФЭМЯёПДЦ№РДЪЧетбљЕФЃК

бЕСЗ14ИіЕќДњжмЦкКѓЃЌЮвЕФDCGAN жаЕФбљБОЃЌЪ§ОнМЏНсКЯСЫ CASIA-WebFace КЭ
FaceScrubЁЃ
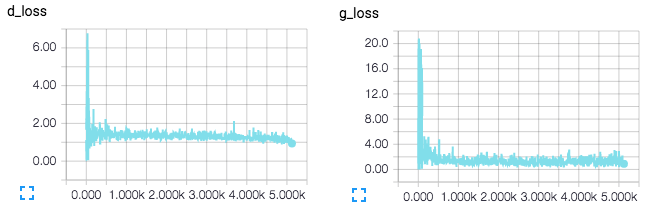
TensorBoard Ы№КФЕФПЩЪгЛЏЃЌНЋдкбЕСЗжаЪЕЪБИќаТЁЃ

DCGAN ЭјТчЕФ TensorBoard ПЩЪгЛЏЁЃ
ЕкШ§ВНЃКевЕНаоИДЭМЯёЕФзюМбЮБдьЭМЦЌ
гУ DCGANs аоИДЭМЯё
ЯждкЮвУЧОЭгаСЫвЛИібЕСЗКУЕФМјБ№Цї D(x) КЭЩњГЩЦї G(z)ЃЌФЧШчКЮгУЫќУЧРДаоИДЭМЯёФиЃПетИіЛЗНкЮввЊНщЩмЕФЪЧ
Raymond Yeh КЭ Chen Chen ЕШШЫЕФТлЮФ ЁИжЊОѕКЭЛЗОГШБЪЇЯТЖдЭМЯёЕФгявхаоИДЃЈSemantic
Image Inpainting with Perceptual and Contextual LossesЃЉЁЙжаЬсГіЕФММЪѕЃЌетЦЊТлЮФИеИегк2016Фъ7дТ26Шедк
arXiv ЩЯЗЂБэЁЃ
ЖдгкгааЉЭМЯёЕФаоИДЃЌдкЯёЫиЕуЩЯНјаа D(y) зюДѓЛЏШЗЪЕЪЧвЛжжКЯРэЕЋШДВЛЙмгУЕФЗНЗЈЁЃетЛсВњЩњвЛаЉМШВЛЪЧРДздЪ§ОнЗжВМ
pdataвВВЛЪЧРДздЩњГЩЕФЗжВМ pg жаЕФНсЙћЁЃЮвУЧЯывЊЕФЪЧ y дкЩњГЩЗжВМЩЯЕФКЯРэгГЩфЁЃ
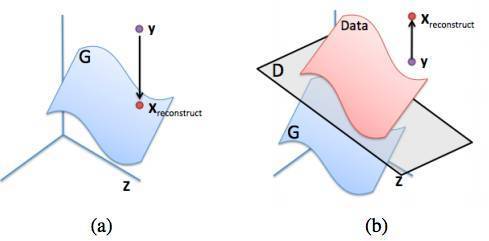
(a): y дкЩњГЩЗжВМЃЈРЖЩЋЃЉЩЯЕФРэЯыжиНЈ
(b): ЪдЭМжЛЭЈЙ§зюДѓЛЏ D(y) жиНЈ y ЕФЪЇАмР§згЁЃЭМЯёРДдДЃКinpainting paper
[ML-Heavy] pgЩЯгГЩфЕФЫ№ЪЇКЏЪ§
вЛИіЖўНјжЦБъМЧЕФЪОвтЫЕУїЭМ
НгЯТРДЃЌМйЩшЮвУЧевЕНСЫвЛеХРДздЩњГЩЦї G(z? ) ЃЈЖдФГаЉ z? ЕФЃЉЕФЭМЯёЃЌЫќИјГіСЫвЛжжЖдШБЪЇВПЗжЕФКЯРэжиЙЙЁЃФЧУДВЙШЋКѓЕФЯёЫиЕу
(1?M)ЁбG(z? )(1?M)ЁбG(z? ) ОЭПЩвдБЛМгЕНдЪМЯёЫиЕужаЃЌЩњГЩГіжиЙЙКѓЕФЭМЯёЃК
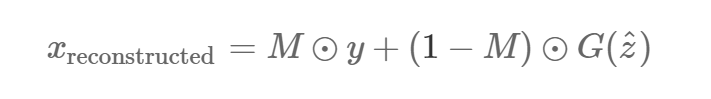
ЯждкЮвУЧЫљашвЊбАевЕФОЭЪЧвЛаЉФмЙЛКмКУаоИДЭМЯёЕФz? ЁЃЮЊСЫевЕНz? ЃЌШУЮвУЧжиаТЩѓЪгЯТБОЮФвЛПЊЪМЃЈдк
DCGAN ФЧВПЗжаДЕНЕФЃЉЮвУЧЯывЊИДдЛЗОГКЭИажЊаХЯЂЕФФПБъЁЃЮвУЧНЋЭЈЙ§ЖдвЛИіШЮвтЕФ z~ p_z ЖЈвхЫ№КФКЏЪ§зіЕНетЕуЁЃетаЉЫ№КФКЏЪ§ЕФжЕИќаЁОЭвтЮЖзХ
z ЖдгкаоИДЭМЯёИќКЯЪЪЁЃ
ЛЗОГШБЪЇЃКЮЊСЫБЃГжгыЪфШыЭМЯёЭЌбљЕФЛЗОГаХЯЂЃЌвЊШЗБЃвбжЊЪфШыЭМЯё y
жаЕФвбжЊЯёЫиЮЛжУгы G(z) жаЕФЯёЫиЮЛжУЯрНќЁЃШчЙћ G(z) УЛгаВњЩњГівЛИігывбжЊЯёЫиЕуЯрЫЦЕФЭМЯёЃЌЮвУЧОЭвЊГЭЗЃЫќЁЃе§ЪНЕФЗНЗЈЪЧДг
G(z) жа element-wise МѕШЅ y жаЕФЯёЫиЕуЃЌШЛКѓЙлВьЫќУЧгаЖрДѓВюБ№ЃК
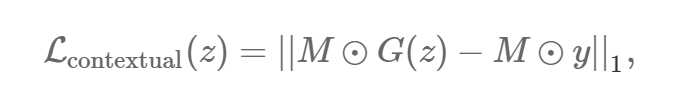
||x||1=ЁЦi|xi|||x||1=ЁЦi|xi| ЪЧФГаЉЯђСП x ЕФ ?t БъзМЁЃ ?2
БъзМЪЧСэвЛИіКЯРэЕФбЁдёЃЌЕЋФЧЦЊЭМЯёаоИДТлЮФЫЕ ?1 БъзМдкЪЕМЪгІгУжааЇЙћИќКУЁЃдкетИіРэЯыЕФЧщПіЯТЃЌЫљгавбжЊЮЛжУЕФЯёЫиЕудк
y КЭ G(z) жЎМфЖМЪЧвЛбљЕФЁЃЫљвдЖдвбжЊЯёЫиЕу
G(z)i?yi= 0ЃЌвђЖјLcontextual(z)=0ЁЃ
жЊОѕШБЪЇЃКЮЊСЫИДдГівЛеХПДЦ№РДКмецЪЕЕФЭМЯёЃЌЮвУЧвЊШУМјБ№ЦїШЗаХетеХЭМЯёПДЦ№РДЪЧецЕФЁЃЮвУЧвЊгУЕФЪЧгыбЕСЗ
DCGAN ЪБЭЌбљЕФБъзМЃК
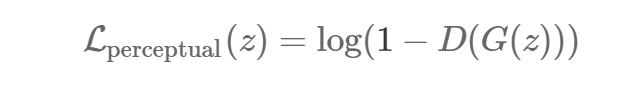
зюжеЮвУЧОЭЛсзМБИКУгУЛЗОГШБЪЇКЭжБОѕШБЪЇЕФНсКЯРДбАев z? СЫЃК
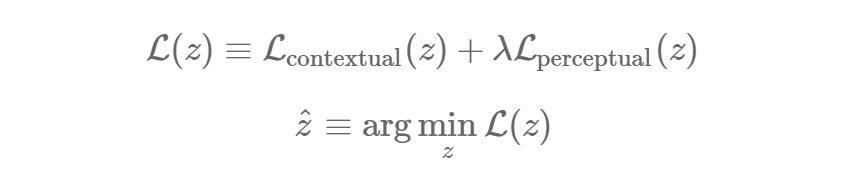
ІЫ ЪЧвЛИіПижЦЪфШыЛЗНкШБЪЇШчКЮгыжБОѕШБЪЇЯрСЊЯЕЕФГЌВЮЪ§ЁЃЃЈЮвгУСЫФЌШЯЕФ ІЫ=0.1ЃЌЖјЧвЛЙУЛгаЬЋЖрИФБфЫќЁЃЃЉНгзХОЭИњЧАУцвЛбљЃЌжиЙЙКѓЕФЭМЯёгУ
y ЃЈG(z? )ЃЉЬюВЙСЫШБЪЇжЕЃК
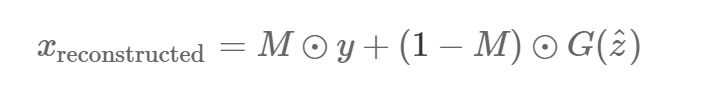
ФЧЦЊЭМЯёаоИДТлЮФвВгУСЫВДЫЩЛьКЯЪЙжиЙЙКѓЕФЭМЯёБфЕУЦНЛЌЁЃ
гУ DCGAN аоИДЭМЯёЕФ Tensorflow ВПЪ№
етвЛЛЗНкеЙЪОСЫЮвЬэМгЕН bamos/dcgan-completion.tensorflow
ЃЌаое§СЫKim ЭМЯёаоИДЕФ carpedm20/DCGAN-tensorflow ЁЃ
ЮвУЧПЩвджиаТАбКмЖрвбДцдкЕФБфСПгУгкаоИДЁЃЮЈвЛМгШыЕФаТБфСПОЭЪЧвЛИіаоИДБъМЧЃК
| self.mask = tf.placeholder(tf.float32,
[None] + self.image_shape, name='mask') |
ЮвУЧвЊЭЈЙ§ЬнЖШЯТНЕЗЈЃЈgradient descentЃЉЕќДњЕиНтОіargminzL(z)ЃЌЬнЖШЮЊ?zL(z)ЁЃ
TensorFlow ЕФздЖЏЗжЛЏПЩвдздЖЏЮЊЮвУЧМЦЫуГіетИіЃЌвЛЕЉЮвУЧЖЈвхСЫЫ№КФКЏЪ§ЃЁЫљвдетећИігУ DCGANs
аоИДЕФРэФюПЩвдЭЈЙ§дквбгаЕФ DCGAN ЩЯМгШыЫФаа TensorFlow ДњТыРДЪЕЯжЁЃЃЈЕБШЛЮвУЧЛЙашвЊвЛаЉЗЧTensorFlow
ДњТыЁЃЃЉ
self.contextual_loss
= tf.reduce_sum(
tf.contrib.layers.flatten(
ЁЁtf.abs(tf.mul(self.mask, self.G) - tf.mul(self.mask,
self.images))), 1)self.perceptual_loss = self.g_lossself.complete_loss
= self.contextual_loss + self.lam*self.perceptual_lossself.grad_complete_loss
= tf.gradients(self.complete_loss, self.z) |
НгзХЃЌШУЮвУЧЖЈвхвЛИіБъМЧЁЃЮввбОдкЭМЯёжааФЮЛжУМгСЫвЛИіЃЌЕЋФуПЩвдздгЩЬэМгЦфЫћЕФЃЌБШШчвЛИіЫцЛњБъМЧЃЌВЂАбЬсГівЛИі
pull ЧыЧѓЁЃ
| if config.maskType
== 'center':
ЁЁЁЁscale = 0.25
ЁЁЁЁasser (scale <= 0.5)
ЁЁЁЁmask = np.ones(self.image_shape)
ЁЁЁЁsz = self.image_size
ЁЁЁЁl = int(self.image_size*scale)
ЁЁЁЁu = int(self.image_size*(1.0-scale))
ЁЁЁЁmask[l:u, l:u, :] = 0.0 |
ЮвУЧвЊгУ minibatche КЭЖЏСПАб z гГЩфЕН [-1,1]ЗЖЮЇФкРДНјааЬнЖШЯТНЕЁЃ
| for idx in xrange(0,
batch_idxs):
ЁЁЁЁbatch_images = ...
ЁЁЁЁbatch_mask = np.resize(mask, [self.batch_size]
+ self.image_shape)
ЁЁЁЁzhats = np.random.uniform(-1, 1, size=(self.batch_size,
self.z_dim))
ЁЁЁЁv = 0
ЁЁЁЁfor i in xrange(config.nIter):
ЁЁЁЁfd = {
ЁЁЁЁself.z: zhats,
ЁЁЁЁself.mask: batch_mask,
ЁЁЁЁself.images: batch_images,
ЁЁЁЁ}
ЁЁЁЁrun = [self.complete_loss, self.grad_complete_loss,
self.G]
ЁЁЁЁloss, g, G_imgs = self.sess.run(run, feed_dict=fd)
ЁЁЁЁv_prev = np.copy(v)
ЁЁЁЁv = config.momentum v - config.lrg[0]
ЁЁЁЁzhats += -config.momentum v_prev + (1+config.momentum)*v
ЁЁЁЁnp.clip(zhats, -1, 1) |
аоИДФуЕФЭМЯё
бЁдёвЛаЉвЊаоИДЕФЭМЯёЃЌШЛКѓАбЫќУЧЗХЕНdcgan-completion.tensorflow/your-test-data/raw
жаЁЃдк asdcgan-completion.tensorflow/your-test-data/aligned
жЎЧААбЫќУЧХХСаКУЁЃЮвЫцЛњДг LFW жабЁШЁСЫвЛаЉЭМЯёРДзіЁЃ
ФуПЩвдгУвдЯТДњТыдЫаааоИДжИСюЃК
| ЁЁ./complete.py
./data/your-test-data/aligned/***** --outDir outputImages |
етЛсдЫааЦ№РДВЂжмЦкадЕФЪфГіаоИДЙ§ЕФЭМЯёИј ЁЊoutDirЁЃФуПЩвдгУ
ImageMagick ДгжаЩњГЩвЛИі gif ЭМЯёЃК
cd outputImages
ЁЁconvert -delay 10 -loop 0 before.png completed/
.png completion.gif |
зюжеЕФЭМЯёаоИДЁЃетаЉЭМЯёЕФжааФЖМЪЧздЖЏЩњГЩЕФЁЃЯрЙидДДњТыдк https://github.com/bamos/dcgan-completion.tensorflow
ЁЃетаЉВЂУЛгаБЛМрЙмЃЁЮвЪЧДгLFW Ъ§ОнМЏжаЫцЛњбЁШЁСЫвЛИіЭМЯёзгМЏЁЃ
НсТл
БОЮФНВЪіСЫаоИДЭМЯёЕФЗНЗЈЃК
1. АбЭМЯёНтЮіГЩвЛИіИХТЪЗжВМжаЕФбљБОЕу
2. ЩњГЩЮБЭМЯё
3. евЕНаоИДЫљашЕФзюМбЮБЭМЯё
БОЮФгУЕФР§згЪЧСГВПЭМЯёЃЌЕЋ DCGANsвВПЩвдБЛбЕСЗзіЦфЫћРраЭЕФЭМЯёаоИДЁЃвЛАуРДЫЕбЕСЗ GAN
гаРЇФбЃЌЯждкЛЙВЛжЊЕРШчКЮдкЬиЖЈЖдЯѓРрЩЯбЕСЗЫќУЧЃЌвВВЛжЊЕРШчКЮдкДѓЭМЦЌЩЯбЕСЗЁЃЕЋетЪЧвЛИіКмгаЧАОАЕФФЃЪНЃЌЗЧГЃЦкД§
GAN баОПШеКѓЕФаТНјеЙЁЃ

ImageNet ЩЯЕФ DCGAN бљБОЃЈзѓЃЉКЭИФНјКѓЕФ GAN бљБОЃЈгвЃЌБОЮФжаЮЊЩцМАЕНЃЉЃЌБэУїЮвУЧЛЙУЛгаРэНтШчКЮЖдУПжжРраЭЭМЯёдЫгУ
GAN ЁЃЭМЯёРДдДЃКimproved GAN paper
|









