| 编辑推荐: |
本文来自于DL4J网站,本文将详细介绍基于Deeplearning4j神经网络学习的可视化、监测及调试方法,希望对您的学习有所帮助。
|
|
基于Deeplearning4j定型界面的网络定型可视化
注:以下说明适用于0.7.0及以上的DL4J版本。
DL4J提供的用户界面可以在浏览器中实现当前网络状态以及定型进展的(实时)可视化。该用户界面通常用于调试神经网络,亦即通过选择合适的超参数(例如学习速率)来提高网络性能。
第1步:将Deeplearning4j用户界面依赖项添加至您的项目。
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-ui_2.10</artifactId>
<version>${dl4j.version}</version>
</dependency> |
请注意后缀_2.10:这是Scala的版本(因为后端使用Play框架和一个Sacal库)。如果您没有使用其他的Scala库,那么_2.10或者_2.11都可以。
第2步:在您的项目中启用用户界面
这一步相对比较简单:
//初始化用户界面后端
UIServer uiServer = UIServer.getInstance();
//设置网络信息(随时间变化的梯度、分值等)的存储位置。这里将其存储于内存。
StatsStorage statsStorage = new InMemoryStatsStorage();
//或者: new FileStatsStorage(File),用于后续的保存和载入
//将StatsStorage实例连接至用户界面,让StatsStorage的内容能够被可视化
uiServer.attach(statsStorage);
//然后添加StatsListener来在网络定型时收集这些信息
net.setListeners(new StatsListener(statsStorage));
|
访问用户界面的方式是打开浏览器并访问http://localhost:9000/train。 您可以用org.deeplearning4j.ui.port系统属性来设置端口:比如,若要使用9001端口,请在JVM启动参数中添加:-Dorg.deeplearning4j.ui.port=9001
随后当您对网络调用fit方法时,相关信息就会被收集起来,传送给用户界面。
示例:用户界面示例见此处
全套的用户界面示例参见此处。
Deeplearning4j用户界面:总览页面
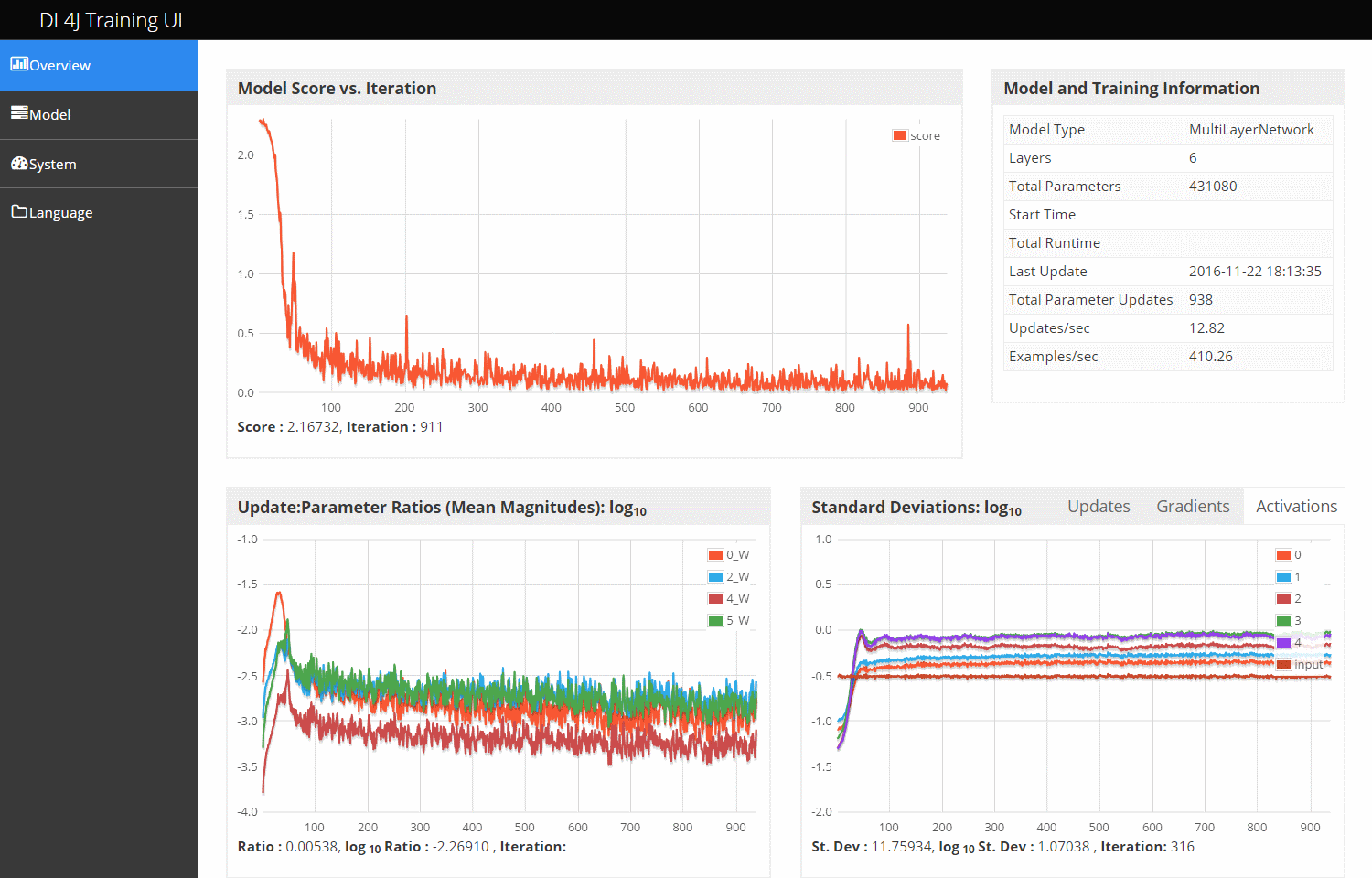
总览页面(用户界面的3个页面之一)包含以下信息:
左上方:分值与迭代次数的关系图-这是当前微批次的损失函数的值
右上方:模型和定型信息
左下方:所有网络权重的更新值与参数之比(各层)同迭代次数的关系
右下方:激活函数、梯度和更新值的标准差(随时间变化情况)
注意下方两幅图中显示的值为实际值的常用对数(底为10)。因此,如果图表中更新值与参数之比的值为-3,则对应的实际比例为10-3
= 0.001。
更新值与参数之比在此处指更新值与参数的平均值之比。
这些数值在实践中的使用方式参见后面的段落。
Deeplearning4j用户界面:模型页面
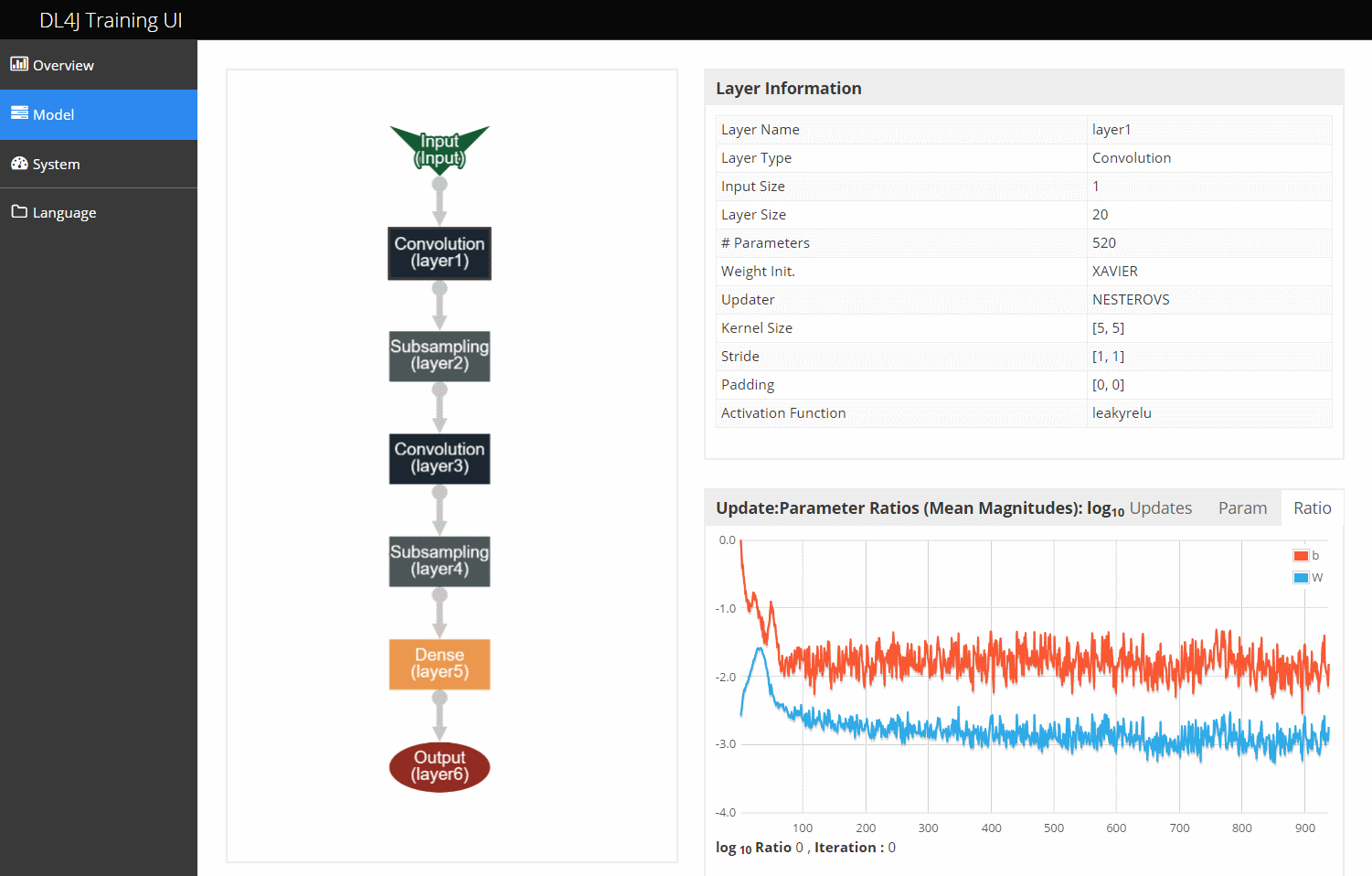
模型页面包含一幅神经网络的层次图,起到选择机制的作用。点击其中的任意一层,即会显示该层的信息。
选择了某一层之后,页面右侧可显示以下图表:
1.该层的信息表
2.该层的更新值与参数之比,如总览页面中所示。点击选项卡即可分别显示这一比例的两个项(更新值和参数各自的平均值)的情况。
3.该层中的激活函数(平均值及平均值+/-2个标准差范围)随时间变化的情况
4.各类参数及更新值的柱状图
学习速率与时间的关系(仅在使用学习速率计划时才会有变化)
注意:参数标记方式如下:权重(W),偏差(b)。在循环神经网络中,W指将该层与下一层连接的权重,而RW指循环权重(即时间步之间的权重)。
Deeplearning4J用户界面与Spark定型
DL4J用户界面可以配合Spark使用。但是,截止到0.7.0版,由于依赖项的冲突,在同个JVM中同时运行用户界面和Spark可能会比较困难。
有两种替代方法:
收集并保存相关统计数据,随后再进行(线下)可视化
在另一个服务器中运行用户界面,然后用远程用户界面功能将数据从Spark主节点上传至用户界面实例
收集数据以供线下使用
SparkDl4jMultiLayer
sparkNet = new SparkDl4jMultiLayer(sc, conf, tm);
StatsStorage ss = new FileStatsStorage(new File("myNetworkTrainingStats.dl4j"));
sparkNet.setListeners(ss, Collections.singletonList(new
StatsListener(null)));
|
之后可以用如下代码加载并显示已保存的信息:
StatsStorage
statsStorage = new FileStatsStorage(statsFile);
//如果文件已存在:从其中加载数据
UIServer uiServer = UIServer.getInstance();
uiServer.attach(statsStorage); |
使用远程用户界面功能
首先在JVM中运行用户界面:
UIServer uiServer
= UIServer.getInstance();
uiServer.enableRemoteListener(); //必要操作:默认情况下不启用远程支持
|
这一步需要deeplearning4j-ui_2.10或deeplearning4j-ui_2.11依赖项。其次,在Spark定型实例中:
SparkDl4jMultiLayer
sparkNet = new SparkDl4jMultiLayer(sc, conf, tm);
StatsStorageRouter remoteUIRouter = new RemoteUIStatsStorageRouter("http://UI_MACHINE_IP:9000");
sparkNet.setListeners(remoteUIRouter, Collections.singletonList(new
StatsListener(null))); |
为避免与Spark发生依赖项冲突,应当使用deeplearning4j-ui-model依赖项来获取StatsListener,而不是完整的deeplearning4j-ui_2.10用户界面依赖项。
注意:您应当将UI_MACHINE_IP替换为运行用户界面实例的计算机的IP地址。
用UI调试网络
Andrej Karpathy的这个网页对神经网络定型的可视化作了很透彻的介绍,值得一读,不妨先将其中的内容消化一下。
神经网络的调试可能更像是一门技艺,而非科学。但以下的一些思路可能会有所帮助:
总览页面-模型分值与迭代次数的关系图
随着迭代次数的增加,(整体)分值应当逐渐下降。
1.如果分值持续上升,那么有可能是学习速率设置过高。尝试降低学习速率,直至分值变得更稳定。
2.分值持续上升也有可能是其他网络问题造成的,例如数据标准化不当
3.如果分值保持不变,或者下降速度十分缓慢(需要经过几百次迭代),那么(a)学习速率有可能太低,或者(b)优化可能遇到了困难。在后一种情况下,如果您使用的是SGD更新器,可以试着将其换成
Nesterov(动量)、RMSProp或Adagrad更新器。
4.注意:未经随机化的数据(即每个微批次只有一个分类类别)可能会导致分值与迭代次数关系图出现很大波动或异常形态
5.这幅图中出现一些噪声是正常的(即曲线会小范围上下波动)。但是,如果不同迭代之间的分值差异很大,就可能存在问题
6.造成这种现象的原因可能包括上述各类问题(学习速率、标准化、数据随机化)。
7.每个微批次中的样例数量太少也有可能造成图中出现较大噪声,同时有可能会导致优化困难
总览页面和模型页面-更新值与参数比例图的使用
1.总览页面和模型页面上都会显示更新值与参数的平均值之比
此处的“平均值” = 当前时间步下参数或更新值的绝对值的平均数
2.该比例最重要的用途是帮助设定学习速率。一般的规则是:该比例应当在1:1000
= 0.001左右,在(log10)图中为-3(即10-3 = 0.001)
注意这只是大概的原则,不一定适用于所有的神经网络,不过通常可以以此为起点开始尝试。
如果实际比例与此相差很多(比如 > -2,即10-2=0.01,或者 < -4,即10-4=0.0001),那么参数可能太不稳定或者变化太慢,网络无法学会识别有用的特征
改变这一比例的方式是调整学习速率(有时也可以调整参数初始化)。对某些网络而言,有可能需要为不同的层设置不同的学习速率。
3.注意比例是否出现异常的大幅上升:这可能表明发生了梯度膨胀
模型页面:层中激活函数(与时间的关系)图
该图可用于检测激活函数消失或膨胀(可能由权重初始化不当、正则化过度、数据标准化不足或学习速率过高导致)。
1.理想状态下,随着时间推移,图像应当趋于稳定(通常需要数百次迭代)
2.较理想的激活函数标准差为0.5至2.0左右。如果标准差大幅超出这一范围,表明有可能出现了上述几种问题之一。
模型页面:层中参数的柱状图
层中参数的柱状图仅显示最近一次迭代的情况。
1.经过一定时间之后,权重的柱状图应大致呈现出高斯(正态)分布
2.偏差的柱状图一般从0开始,最终通常会大致呈高斯(正态)分布
LSTM循环网络的层是特殊情况:在默认状态下,一个门(遗忘门)的偏差设置为1.0,以帮助网络学习跨越较长时间段的依赖关系。因此,偏差图中最初会有许多偏差位于0.0附近,而另一组偏差则会在1.0附近
3.注意是否有参数偏离正常范围并趋向于正/负无穷:其原因可能是学习速率过高或者正则化不足(可以试着为网络添加一些L2正则化步骤)。
4.注意是否有偏差变得非常大。如果类别的分布极度不平衡,分类输出层有时会出现这种情况
模型页面:层中更新值的柱状图
层中更新值的柱状图仅显示最近一次迭代的情况。
注意图中显示的是更新值,也就是应用了学习速率、动量、正则化等之后的梯度
与参数图相类似,更新值的柱状图也应当大致呈现出高斯(正态)分布
注意是否出现特别大的更新值:有可能表明网络中有膨胀的梯度
梯度膨胀是一种问题,有可能会导致网络参数变得“混乱”
该情况下有可能是权重初始化、学习速率或输入/标签数据标准化的问题所致
对循环神经网络而言,添加一些梯度标准化或梯度裁剪的步骤可能会有帮助
模型页面:参数学习速率图
该图显示的就是所选层的参数的学习速率随时间变化的情况
如果您没有使用学习速率计划(learning rate schedule),图像将是水平直线。如果使用了学习速率计划,就可以用这张图来跟踪当前的学习速率(对于每个参数而言)及其随时间变化的情况。
TSNE与Word2vec
我们依靠TSNE来降低词特征向量的维度,将词向量投影至二维或三维的空间。以下是在Word2Vec网络中使用TSNE的代码:
log.info("Plot
TSNE....");
BarnesHutTsne tsne = new BarnesHutTsne.Builder()
.setMaxIter(1000)
.stopLyingIteration(250)
.learningRate(500)
.useAdaGrad(false)
.theta(0.5)
.setMomentum(0.5)
.normalize(true)
.usePca(false)
.build();
vec.lookupTable().plotVocab(tsne); |
|









