| 编辑推荐: |
本文来自于oschina,文章介绍了卷积神经网络原理,基于dl4j定型一个卷积神经网络来进行手写数字识别等相关内容。 |
|
一、前言
最近一直在研究深度学习,联想起之前所学,感叹数学是一门朴素而神奇的科学。F=G*m1*m2/r2万有引力描述了宇宙星河运转的规律,E=mc2描述了恒星发光的奥秘,V=H*d哈勃定律描述了宇宙膨胀的奥秘,自然界的大部分现象和规律都可以用数学函数来描述,也就是可以求得一个函数。
神经网络可以逼近任何连续的函数,那么神经网络就有无限的泛化能力。对于大部分分类问题而言,本质就是求得一个函数y=f(x),例如:对于图像识别而言就是求得一个以像素张量为自变量的函数y=F(像素张量),其中y=猫、狗、花、汽车等等;对于文本情感分析而言,就是为了求得一个以词向量或者段落向量为自变量的函数y=F(词向量),其中y=正面、负面等等……
二、导读
本篇博客包括以下内容:
1、卷积神经网络的原理
2、基于dl4j定型一个卷积神经网络来进行手写数字识别
三、卷积神经网络原理
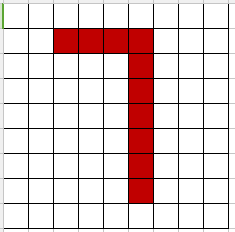
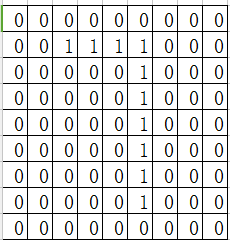
下面左边有个9*9的网格,红色填充的部分构成了数字7,把红色部分填上1,空白部分填上0,就构成了一个二维矩阵,传统做法可以用求向量距离,如果数字全部都标准的写在网格中相同的位置,那么肯定是准确的,但是,实际上数字7在书写的过程中,可能偏左一点、偏右一点,变形扭曲一点,这时候就难以识别。另外,一幅图片的像素点的数量是巨大的,例如一幅50*50的图片将有2500个像素点,每个像素点有R、G、B三个维度的颜色,那么输入参数的个数有7500个,这个运算量是巨大的。
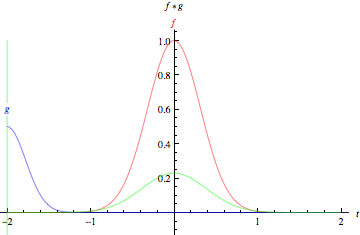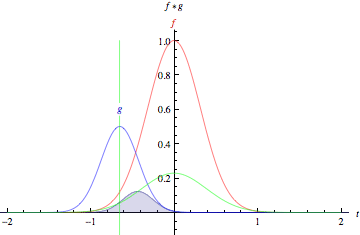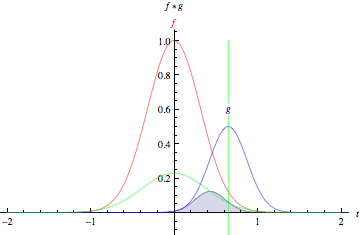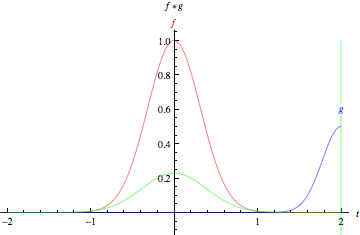
那么就需要有一个抽象特征、降低数据维度的方法,这就说到了卷积运算,用一个小于图片的卷积核扫过整幅图片求点积。卷积的过程看下图。图片来源于https://my.oschina.net/u/876354/blog/1620906
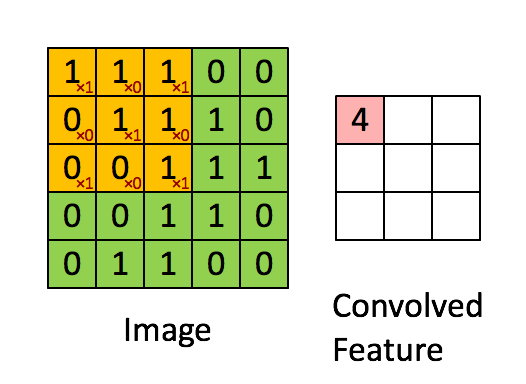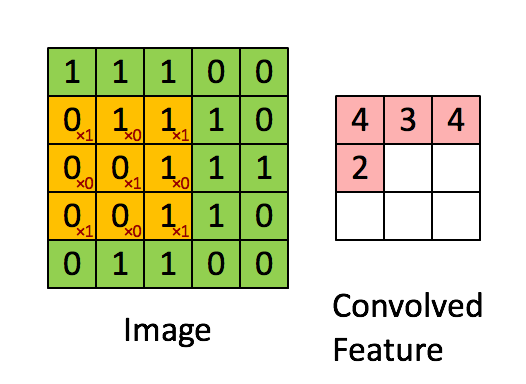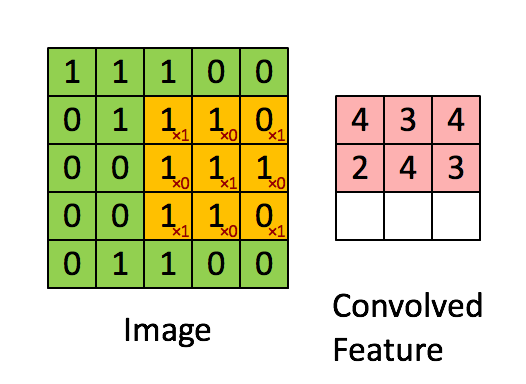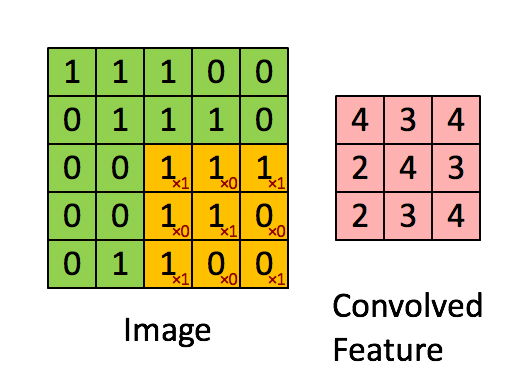
卷积运算的过程在于寻找图片中的显著特征,并达到降维的目的,整个过程相当于一个函数扫过另一个函数,扫过时两个函数的积分重叠部分并没改变图片的特征形状,并可以降低维度,另外还可以分区块来提取特征,并且拼接特征。
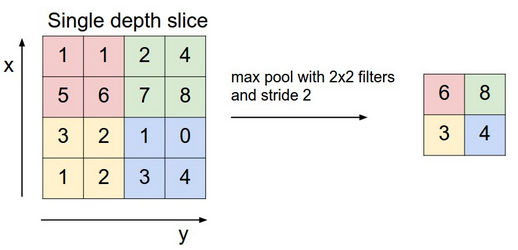
为了进一步降低维度,引入了池化,池化的方式有很多,如最大值,平均值。下图展示了一个步长为2的2*2最大池化过程,用一个2*2的方块扫描过,求Max,总共扫描4次,4次扫描的最大值分别是6、8、3、4。
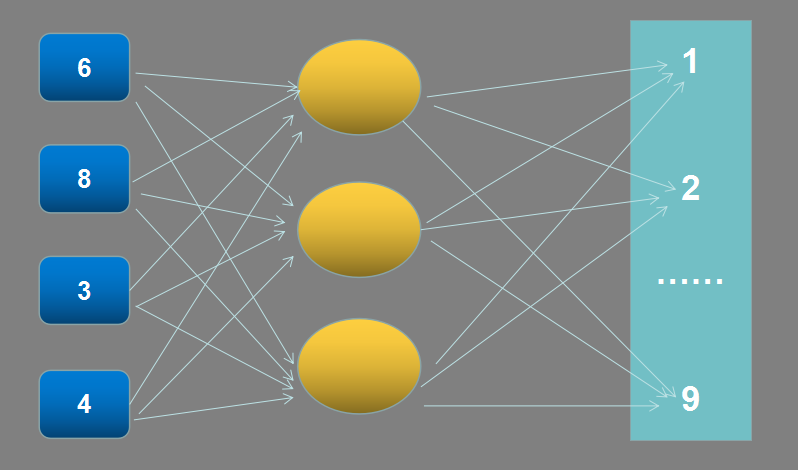
最后,经过多层卷积和池化之后,会得到一个矩阵,该矩阵作为一个全连接网络的输入,在逼近一个函数,就识别出数字了,以上图得到的6、8、3、4为例,全连接网络求一个函数。
四、deeplearning4j手写体识别
1、先下载mnist数据集,地址如下:
http://github.com/myleott/mnist_png/raw
/master/mnist_png.tar.gz
2、解压(我解压在E盘)
3、训练网络,评估(一些比较难的部分都做了注释)
public class
MnistClassifier {
private static final Logger log = LoggerFactory.getLogger(MnistClassifier.class);
private static final String basePath = "E:";
public static void main(String[] args) throws
Exception {
int height = 28;
int width = 28;
int channels = 1;
// 这里有没有复杂的识别,没有分成红绿蓝三个通道
int outputNum = 10;
// 有十个数字,所以输出为10
int batchSize = 54;
//每次迭代取54张小批量来训练,可以查阅神经网络
的mini
batch相关优化,也就是小批量求平均梯度
int nEpochs = 1;
//整个样本集只训练一次
int iterations = 1;
int seed = 1234;
Random randNumGen = new Random(seed);
File trainData = new File(basePath + "/mnist_png/training");
FileSplit trainSplit = new FileSplit(trainData,
NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ParentPathLabelGenerator labelMaker = new
ParentPathLabelGenerator();
//以父级目录名作为分类的标签名
ImageRecordReader trainRR = new ImageRecordReader
(height,
width, channels, labelMaker);
//构造图片读取类
trainRR.initialize(trainSplit);
DataSetIterator trainIter = new
RecordReaderDataSetIterator
(trainRR,
batchSize, 1, outputNum);
// 把像素值区间 0-255 压缩到0-1 区间
DataNormalization scaler = new
ImagePreProcessingScaler(0,
1);
scaler.fit(trainIter);
trainIter.setPreProcessor(scaler);
// 向量化测试集
File testData = new File(basePath +
"/mnist_png/testing");
FileSplit testSplit = new FileSplit(testData,
NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader testRR = new
ImageRecordReader(height,
width, channels, labelMaker);
testRR.initialize(testSplit);
DataSetIterator testIter = new
RecordReaderDataSetIterator(testRR,
batchSize, 1, outputNum);
testIter.setPreProcessor(scaler);
// same normalization
for better results
log.info("Network configuration and training...");
Map<Integer, Double> lrSchedule = new
HashMap<>();
//设定动态改变学习速率的策略,key表示小批量迭代到几次
lrSchedule.put(0, 0.06);
lrSchedule.put(200, 0.05);
lrSchedule.put(600, 0.028);
lrSchedule.put(800, 0.0060);
lrSchedule.put(1000, 0.001);
MultiLayerConfiguration conf = new
NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.regularization(true).l2(0.0005)
.learningRate(.01)
.learningRateDecayPolicy(LearningRatePolicy.Schedule)
.learningRateSchedule(lrSchedule)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm
.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS)
.list()
.layer(0, new ConvolutionLayer.Builder(5, 5)
.nIn(channels)
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer
.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
.layer(2, new ConvolutionLayer.Builder(5, 5)
.stride(1, 1)
.nOut(50)
.activation(Activation.IDENTITY)
.build())
.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer
.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
.layer(4, new DenseLayer.Builder().activation
(Activation.RELU)
.nOut(500).build())
.layer(5, new OutputLayer.Builder(LossFunctions
.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutionalFlat(28,
28, 1))
.backprop(true).pretrain(false).build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();
net.setListeners(new ScoreIterationListener(10));
log.debug("Total num of params: {}",
net.numParams());
// 评估测试集
for (int i = 0; i < nEpochs; i++) {
net.fit(trainIter);
Evaluation eval = net.evaluate(testIter);
log.info(eval.stats());
trainIter.reset();
testIter.reset();
}
ModelSerializer.writeModel(net, new File(basePath
+ "/minist-model.zip"), true);//保存训练好的网络
}
} |
运行main方法,得到如下评估结果:
# of classes: 10
Accuracy: 0.9897
Precision: 0.9897
Recall: 0.9897
F1 Score: 0.9896
整个效果还比较好,保存好训练的网络,便可以用于手写体数据的识别了,下一篇博客将介绍怎么加载定型的网络,配合springMVC来开发一个手写体识别的应用。 |









