| БрМЭЦМі: |
БОЮФРДздгкarleyzhangВЉПЭЃЌБОЮФжївЊНщЩмФПБъМьВтжаСНВНМьВтЫуЗЈЕФзмНсЖдБШЃЌЬсГіСЫвЛжжаТЕФСНВНМьВтФЃаЭЃЌ
Light-Head RCNN ЃЌЯЃЭћЛсЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
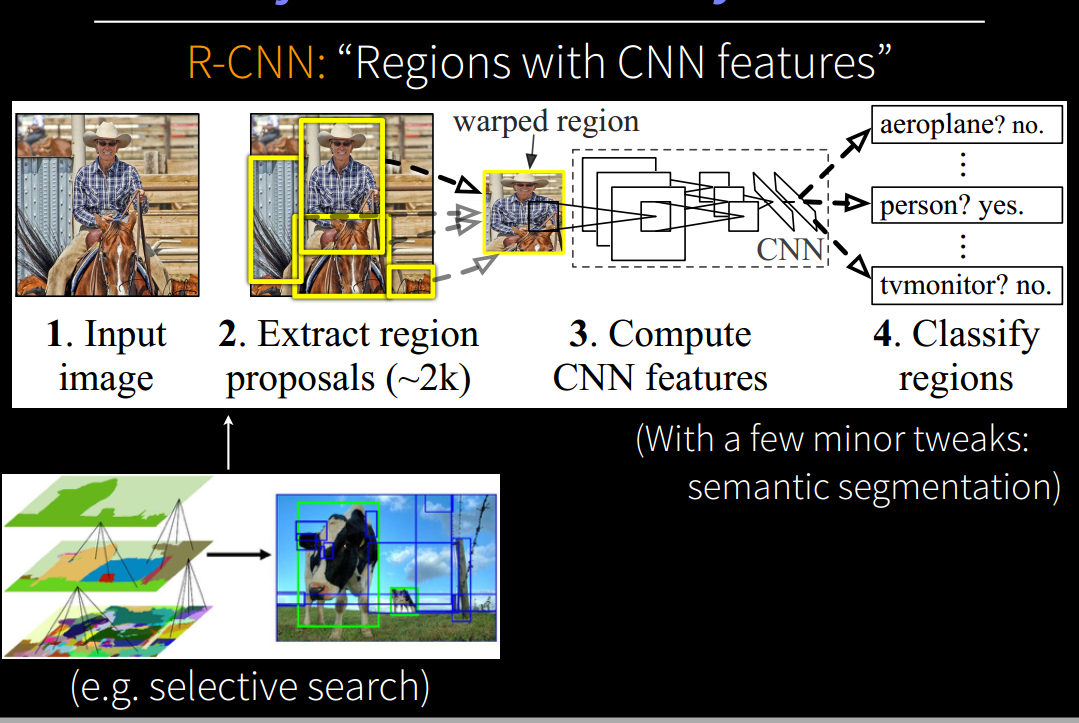
R-CNN
RbgЬсГіЕФR-CNNЕФЗНЗЈ
1.вЛеХЭМЯёЯШЭЈЙ§selective searchЕФЗНЗЈЃЌЩњГЩ1K~2KИіКђбЁЧјгђЃЌетИіВНжшЩњГЩЕФКђбЁЧјгђДѓаЁЪЧВЛвЛбљЕФЃЌвђДЫашвЊ
warped regionЃЌвВОЭЪЧНЋВЛЭЌДѓаЁЕФ region ЫѕЗХЕНЭЌбљЕФГпДчЃЌвђЮЊCNNКѓУцЕФШЋСЌНгВувЊЧѓЪфШыГпДчЙЬЖЈЁЃ
2.ЖдУПИі warped КѓЕФКђбЁЧјгђЃЌЪЙгУCNNЬсШЁЬиеї ЃЌЬсШЁЕФЬиеїашДцДЂЕНДХХЬЃЛ
3.ЖСШЁЬиеїЃЌЫЭШыУПвЛРрЕФ SVM ЗжРрЦїЃЌХаБ№ЪЧЗёЪєгкИУРрЃЛ
4.зюжеЛЙгавЛИіЮЛжУЛиЙщЦїгУгкОЋЯИаое§ЁЃ
ЛиЙщЗНЗЈЃК

ЛиЙщКЏЪ§ЃК
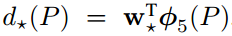
Ы№ЪЇКЏЪ§ЃК
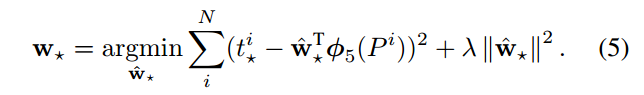
бЕСЗЗНЗЈЃК

гХЕуЃК
1.НсЙЙМђЕЅУїСЫЃЌШнвзРэНтЃЛ
2.CNNздЖЏЬсШЁЬиеїЃЌЪЁШЅЪжЙЄЩшМЦЬиеїЕФИДдгВйзїЃЌвдМАЖдОбщКЭдЫЦјЕФвРРЕадЃЛ
3.ЪЙгУ selective searchЗНЗЈРДЩњГЩКђбЁЧјгђЃЌЯджјМѕЩйКђбЁЧјгђЕФЪ§СПЃЌдіМгКђбЁЧјгђЕФжЪСПЃЈАќКЌФПБъЕФПЩФмадИќДѓЃЉЃЌвђЮЊетЯрЕБгквЛИіШѕМьВтЦїЃЌЯрБШгкsliding
windowЧюОйЫбЫїЕФЗНЪНПЯЖЈвЊКУКмЖрЃЛ
4.дЄВтОЋЖШЬсИпСЫ30%ЁЃ
ШБЕуЃК
1.ЬсШЁЬиеїЪБЃЌCNNашвЊдкУПвЛИіКђбЁЧјгђЩЯХмвЛБщЃЛКђбЁЧјгђжЎМфЕФНЛЕўЪЙЕУЬиеїБЛжиИДЬсШЁ,
дьГЩСЫбЯжиЕФ
2.ЫйЖШЦПОБ, НЕЕЭСЫМЦЫуаЇТЪ;
3.НЋКђбЁЧјгђжБНгЫѕЗХЕНЙЬЖЈДѓаЁ, ЦЦЛЕСЫЮяЬхЕФГЄПэБШ, ПЩФмЕМжТЮяЬхЕФОжВПЯИНкЫ№ЪЇ;
4.R-CNNЛЙВЛЪЧЖЫЕНЖЫЕФФЃаЭЃЌбЕСЗВНжшЗБЫіmulti-stageЃЈЯШдЄбЕСЗЁЂfine
tuningЁЂДцДЂCNNЬсШЁЕФЬиеїЃЛдйбЕСЗSVM ЃЛдйregressionЃЉЁЃДгfine tuning
ЕНбЕСЗSVMЪБЃЌВЛФмвЛВНЕНЮЛЃЌвЊЗжГЩСНВНЃЛ
5.бЕСЗSVMЪБашвЊНЋжЎЧАCNNЬсШЁЕНЕФЬиеїШЋВПДцДЂдкДХХЬЩЯЃЌДХХЬЖСаДКФЪБЃЌЧвеМгУПеМфДѓЃЌЃЈPascal
200GЃЉЃЛ
6.ЪЙгУЖюЭтЕФselective search ЫуЗЈЩњГЩКђбЁЧјгђЕФЙ§ГЬвВКмКФЪБЃЛ
7.дЄВтЪБМфКмТ§ЃЌвЛеХЭМЦЌвЊ49sЁЃ
SPPNet
еыЖдR-CNNЕФСНИіШБЯнЃК
1.ЯШЩњГЩКђбЁЧјгђЃЌдйЖдЧјгђНјааОэЛ§ЃЌКђбЁЧјгђжЎМфЕФНЛЕўЪЙЕУЬиеїБЛжиИДЬсШЁ,
дьГЩСЫбЯжиЕФЫйЖШЦПОБ, НЕЕЭСЫМЦЫуаЇТЪ;
2.НЋКђбЁЧјгђжБНгЫѕЗХЕНЙЬЖЈДѓаЁ, ЦЦЛЕСЫЮяЬхЕФГЄПэБШ, ПЩФмЕМжТЮяЬхЕФОжВПЯИНкЫ№ЪЇ;
КЮПУїЬсГіЕФИФНјЗНЗЈШчЯТЃК
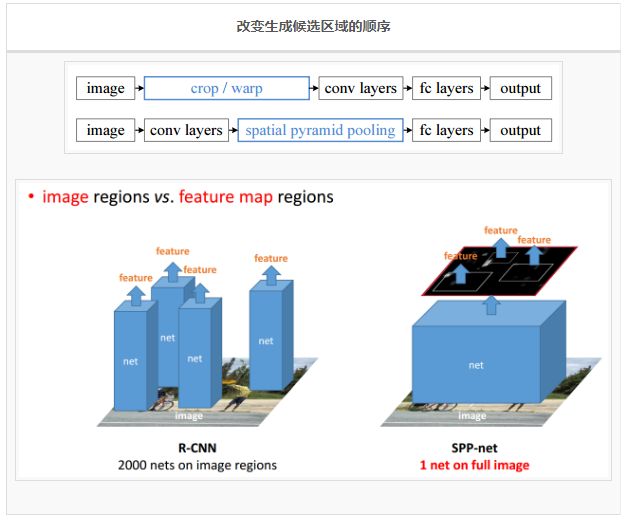
ИФБфЩњГЩКђбЁЧјгђЕФЫГађЁЃДгЯШЩњГЩКђбЁЧјгђдйЬсШЁЬиеїЃЌБфГЩЯШЬсШЁЬиеїдйЩњГЩКђбЁЧјгђЃЌЪЕЯжСЫЬиеїЬсШЁВПЗжЕФМЦЫуЙВЯэЃЌМЋДѓЕФМѕЩйМЦЫуСПЁЃЩњГЩКђбЁЧјгђЕФЗНЪНЛЙЪЧ
selective searchЫуЗЈЃЌдкдЭМЩЯЩњГЩКђбЁЧјгђКѓЃЌгГЩфЕНЬиеїЭМЩЯШЅЁЃ
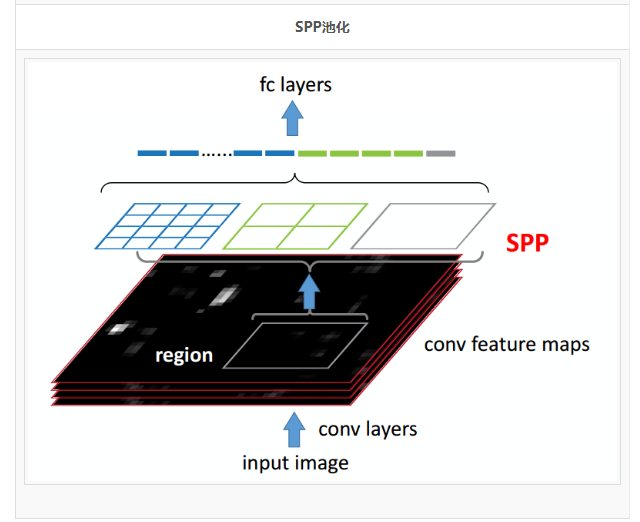
ЪЙгУSPPГиЛЏЃЈSpatial pyramid model, ПеМфН№зжЫўГиЛЏГиЛЏЃЉЃКДЋЭГЕФГиЛЏЗНЪНЪЧ
вбжЊЪфШыГпДчКЭ ЙЬЖЈГиЛЏКЫДѓаЁЃЌШЗЖЈЪфГіГпДчЃЌФЧУДетЪБКђЪфГіГпДчПЯЖЈЪЧЫцЪфШыГпДчБфЛЏЕФЃЌЫљвдетЪБКђОЭвЊЧѓЪфШыЭМЦЌЪЧЙЬЖЈГпДчЁЃЖјSPPГиЛЏЪЧ
вбжЊЪфШыГпДч КЭ ЙЬЖЈЪфГіГпДчЃЌРДШЗЖЈШЗЖЈГиЛЏКЫЕФДѓаЁЁЃSPP ВугУВЛЭЌДѓаЁЕФГиЛЏДАПкзїгУгкОэЛ§ЕУЕНЕФЬиеїЭМЃЌГиЛЏДАПкЕФДѓаЁКЭВНГЄИљОнЬиеїЭМЕФГпДчНјааЖЏЬЌМЦЫуЃЌзюжеПЩвдзщКЯГЩвЛИіЬиЖЈЮЌЖШЕФЬиеїЪфГіЁЃетРяЕФЪфШыПЩвдЪЧвЛИіfeature
mapЃЈЗжРрЮЪЬтЃЉЃЌвВПЩвдЪЧвЛИіwindowЃЈМьВтЮЪЬтЃЉЁЃ
бЕСЗЙ§ГЬЃК

гХЕуЃК
SPP-net ЖдгквЛЗљЭМЯёЕФЫљгаКђбЁЧјгђ, жЛашвЊНјаавЛДЮОэЛ§Й§ГЬ, БмУтСЫжиИДМЦЫу, ЯджјЬсИпСЫМЦЫуаЇТЪЁЃИУЗНЗЈдкЫйЖШЩЯБШ
R-CNN ЬсИп 24 ~102 БЖ .
SPPГиЛЏВуЪЙЕУМьВтЭјТчПЩвдДІРэШЮвтГпДчЕФЭМЯё, вђДЫПЩвдВЩгУЖрГпЖШЭМЯёРДбЕСЗЭјТч, ДгЖјЪЙЕУЭјТчЖдФПБъЕФГпЖШгаКмКУЕФТГАєад.
ШБЕуЃК
SPP-net ЕФбЕСЗЙ§ГЬИќИДдгСЫЃЌЃЈЯШдЄбЕСЗЁЂДцДЂSPPЬиеїЁЂЪЙгУSPPЬиеїfine tuningШЋСЌНгВуЁЂДцДЂCNNЬсШЁЕФЬиеїЃЛдйбЕСЗSVM
ЃЛдйregressionЃЉЁЃ
CNN ЬсШЁЕФЬиеїДцДЂашвЊЕФПеМфКЭЪБМфПЊЯњдіДѓ;
дкЮЂЕїНзЖЮ, SPP-net жЛФмИќаТПеМфН№зжЫўГиЛЏВуКѓЕФШЋСЌНгВу, ЖјВЛФмИќаТОэЛ§Ву(КУЯёЪЧЬнЖШВЛСЌај),
етЯожЦСЫМьВтадФмЕФЬсЩ§ЁЃ
Fast R-CNN

ЮЊЪВУД SPPnetКЭ R-CNNбЕСЗКмТ§ЃП
жївЊдвђгаСНЕу
1.ЪЙгУSVMзіЗжРрЦїЪБЃЌашвЊНЋЬиеїЪТЯШДцДЂЕНДХХЬЩЯЃЌДХХЬНЛЛЅКФЪБЃЛ
2.бЕСЗВНжшЗБЫіЃЌВЛФмСЊКЯбЕСЗЁЃ
еыЖд R-CNN КЭ SPPNet ЕФетСНИіЮЪЬт, rbg ЬсГі ФмЙЛЖЫЕНЖЫСЊКЯбЕСЗЕФ Fast R-CNN
ЫуЗЈ ЃЌШчЯТЃК
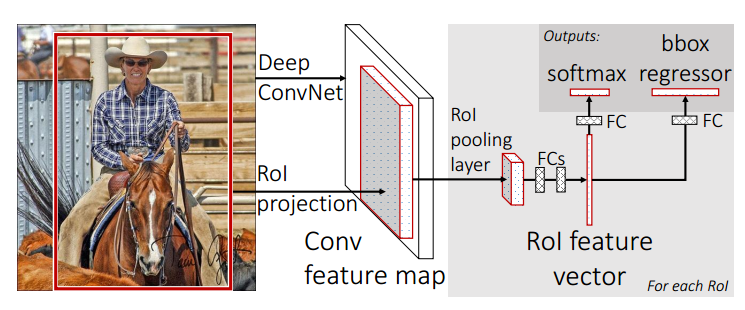
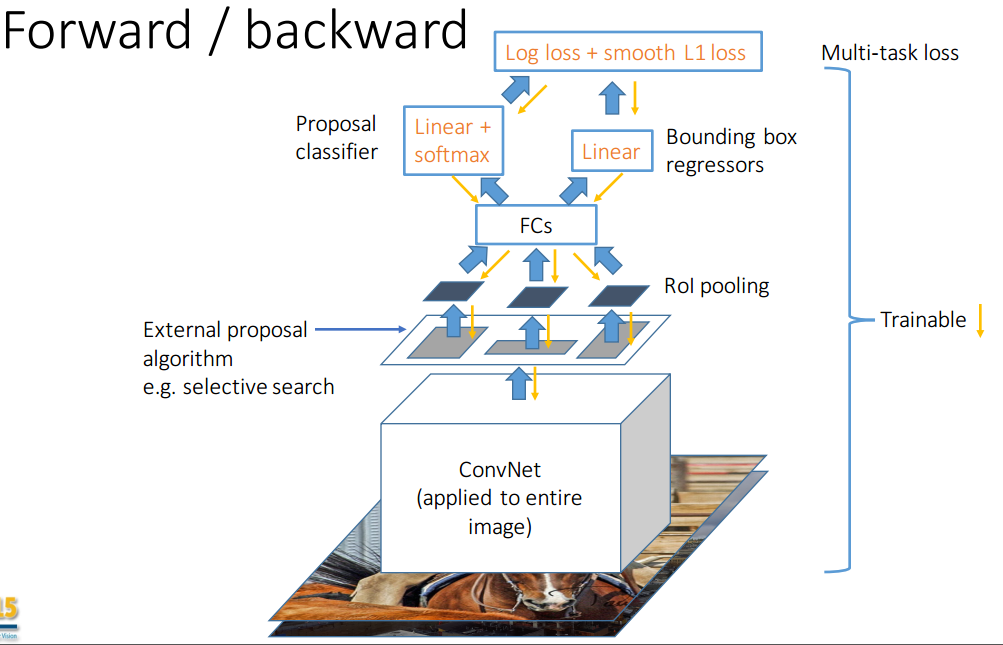
ЪзЯШдкЭМЯёжаЬсШЁИааЫШЄЧјгђ (Regions of Interest, RoI)ЃЌЛЙЪЧЪЙгУselective
searchЫуЗЈЃЌЩњГЩЕФКђбЁЧјгђетРяГЦЮЊROIЃЌНЋROIгГЩфЕНfeature mapЩЯ;
ШЛКѓВЩгУгы SPP-net ЯрЫЦЕФДІРэЗНЪН,ЖдУПЗљЭМЯёжЛНјаавЛДЮОэЛ§,
дкзюКѓвЛИіОэЛ§ВуЪфГіЕФЬиеїЭМЩЯЖдУПИі RoI НјаагГЩф, ЕУЕНЯргІЕФRoI ЕФЬиеїЭМ, ВЂЫЭШы RoI
ГиЛЏВу (ЯрЕБгкЕЅВуЕФSPP Ву, ЭЈЙ§ИУВуАбИїГпДчЕФЬиеїЭМЭГвЛЕНЯрЭЌЕФДѓаЁ);
зюКѓОЙ§ШЋСЌНгВуЕУЕНСНИіЪфГіЯђСП, вЛИіНјаа Softmax ЗжРр, СэвЛИіНјааБпПђЛиЙщ.
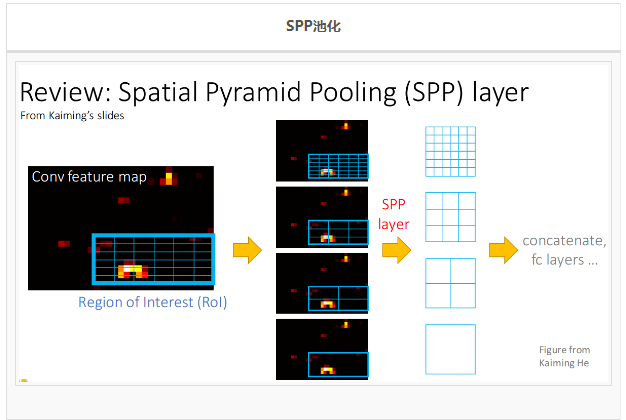
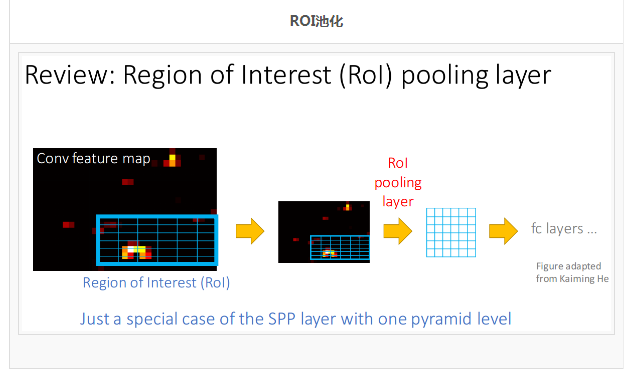
ИФНјЕФЗНЗЈЃК
ДЎааНсЙЙИФГЩВЂааНсЙЙ ЃКдРДЕФ R-CNN ЪЧЯШЖдКђбЁПђЧјгђНјааЗжРрЃЌХаЖЯгаУЛгаЮяЬхЃЌШчЙћгадђЖд
Bounding Box НјааОЋао ЛиЙщ ЁЃетЪЧвЛИіДЎСЊЪНЕФШЮЮёЃЌФЧУДЪЦБиУЛгаВЂСЊЕФПьЃЌЫљвд rbg
ОЭНЋдгаНсЙЙИФГЩВЂааЃЌдкЗжРрЕФЭЌЪБЃЌЖд Bbox НјааЛиЙщЃЛ
ROIГиЛЏЃКдкетИіФЃаЭРяЃЌROIОЭЪЧИааЫШЄЧјгђ(Regions of Interest, RoI)
ЃЌвВОЭЪЧжЎЧАФЃаЭжаЕФКђбЁЧјгђЁЃSPPГиЛЏЕФИФНјЃЌЯрЕБгкжЛгУСЫвЛжжГпДчЕФ SPPГиЛЏЃЛ
ВЛгУSVMЗжРрЃЌИФгУSoftMaxЗжРрЃЌПЩвдЪЁШЅЬиеїДцДЂЃЛ
ЪЙгУmulti-task loss ЖрШЮЮёЫ№ЪЇКЏЪ§ЃЈЗжРр+ЛиЙщЃЉЃЌЖЫЕНЖЫЃЈend-to-endЃЉбЕСЗЁЃ
бЕСЗЗНЪНЃК
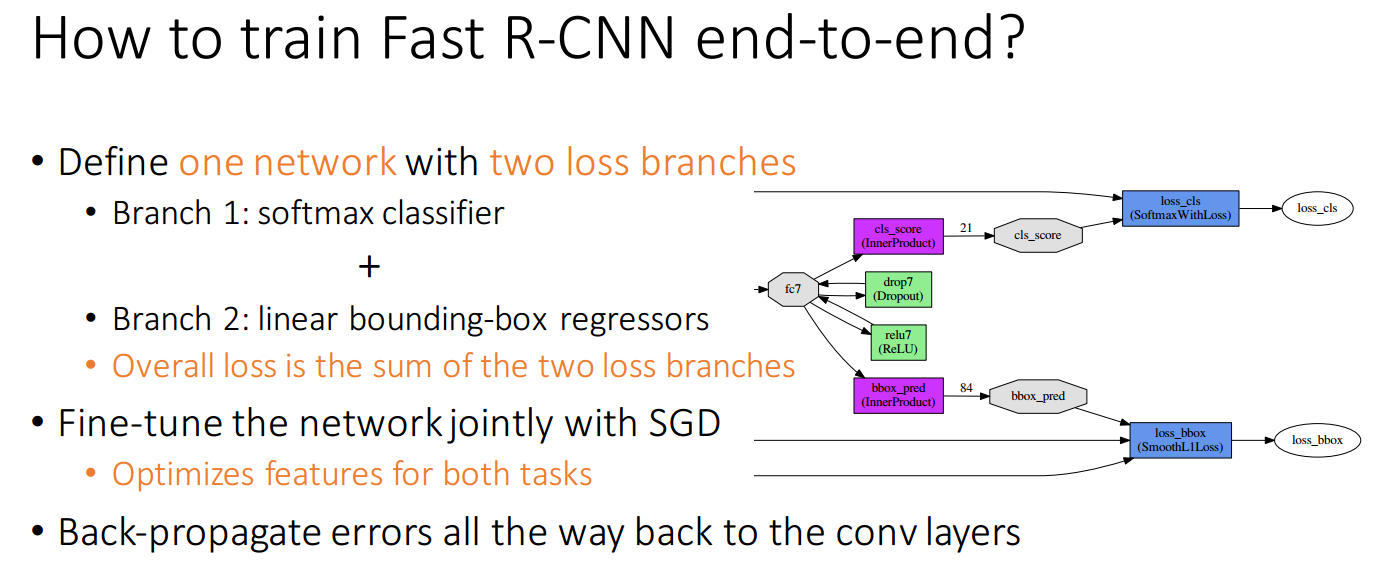
multi-task Ы№ЪЇКЏЪ§ЃК
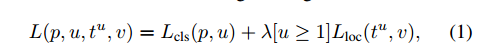
аТЕФЬєеНМАНтОіЗНЗЈЃК
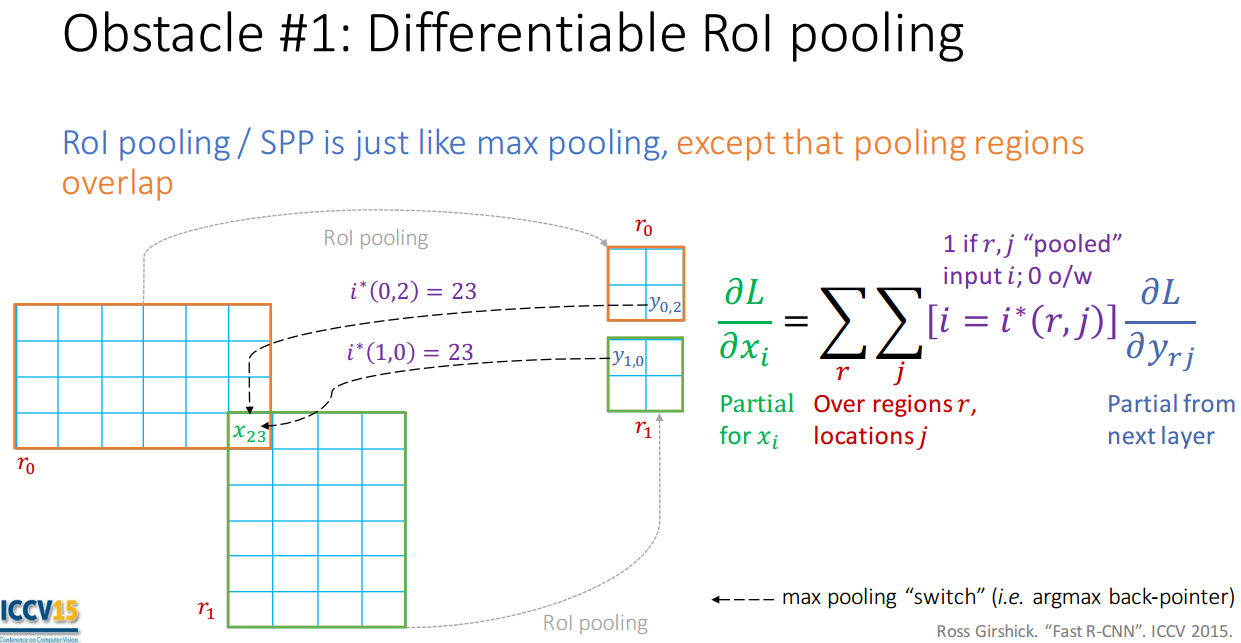

ROIГиЛЏЃК
вЛОфЛАИХРЈзїгУЃКНЋВЛЭЌГпДчЪфШыЕФfeature mapЛђеп ROIЃЌНЕВЩбљГЩЙЬЖЈГпДчЕФЪфГі feature
mapЃЌдйЫЭШыШЋСЌНгВуЁЃ
зіЗЈЃК
НЋimageжаЕФROI гГЩфЕНfeature map жаЖдгІЮЛжУЕФЧјгђЃЌетаЉЧјгђДѓаЁЪЧВЛЭГвЛЕФЃЈвбжЊЪфШыЃЉЃЛ
НЋгГЩфКѓЕФЧјгђЛЎЗжЮЊЯрЭЌДѓаЁЕФsectionsЃЈsectionsЪ§СПгыЪфГіЕФЮЌЖШЯрЭЌЃЌЙЬЖЈЪфГіГпДчЃЉЃЛетИіЙ§ГЬжаЃЌУПИіROIЗжКУЕФsectionжаЕФЯёЫиЪ§СПЪЧВЛвЛбљЕФЃЈГиЛЏКЫЕФДѓаЁКЭВНГЄИљОнЪфШыКЭЪфГіГпДчНјааЖЏЬЌМЦЫуЃЉЃЌзюжеПЩвдзщКЯГЩвЛИіЬиЖЈЮЌЖШЕФЬиеїЪфГіЃЛ
ЖдУПИіsectionsНјааmax poolingВйзїЃЛ
ВЮПМЃКRegion of interest pooling explained
гХЕуЃК
1.ОЋЖШгаЬсИп
2.ЭЈЙ§ЪЙгУ multi-task loss ЃЌПЩвдЪЕЯж end-to-endбЕСЗЃЌsingle-stageЃЌГ§СЫдЄбЕСЗжЎЭтЃЌЦфЫћЕФЖМЪЧПЩвдвЛЦјКЧГЩЕФЁЃ
3.ЗжРрКЭЛиЙщШЮЮёПЩвдЙВЯэОэЛ§Ьиеї,ЯрЛЅДйНј.
4.Fast R-CNN ВЩгУ Softmax ЗжРргыБпПђЛиЙщвЛЦ№НјаабЕСЗ,
ЪЁШЅСЫЬиеїДцДЂ, ЬсИпСЫПеМфКЭЪБМфРћгУТЪЁЃ гы R-CNN ЯрБШ, дкбЕСЗ VGG ЭјТчЪБ,Fast
R-CNN ЕФбЕСЗНзЖЮПь 9 БЖ, ВтЪдНзЖЮПь 213БЖ; гы SPP-net ЯрБШ, Fast R-CNN
ЕФбЕСЗНзЖЮПь 3БЖ, ВтЪдНзЖЮПь 10 БЖЁЃ
ШБЕуЃК
Fast R-CNN ШдШЛДцдкЫйЖШЩЯЕФЦПОБ, ОЭЪЧКђбЁЧјгђЩњГЩВНжшКФЗбСЫећИіМьВтЙ§ГЬЕФДѓСПЪБМф.
Faster R-CNN
ЮЊСЫНтОіКђбЁЧјгђЩњГЩВНжшЯћКФДѓСПМЦЫузЪдД, ЕМжТМьВтЫйЖШЙ§Т§ЕФЮЪЬт,
ШЮЩйЧфЃЌКЮПУїЃЌrbgСЊКЯЬсГіЧјгђЩњГЩЭјТч (Region proposal network, RPN),
ВЂЧвАбRPN КЭ Fast R-CNN ШкКЯЕНвЛИіЭГвЛЕФЭјТч (ГЦЮЊ Faster R-CNN),
ЖўепЙВЯэОэЛ§Ьиеї. ШчЯТЃК
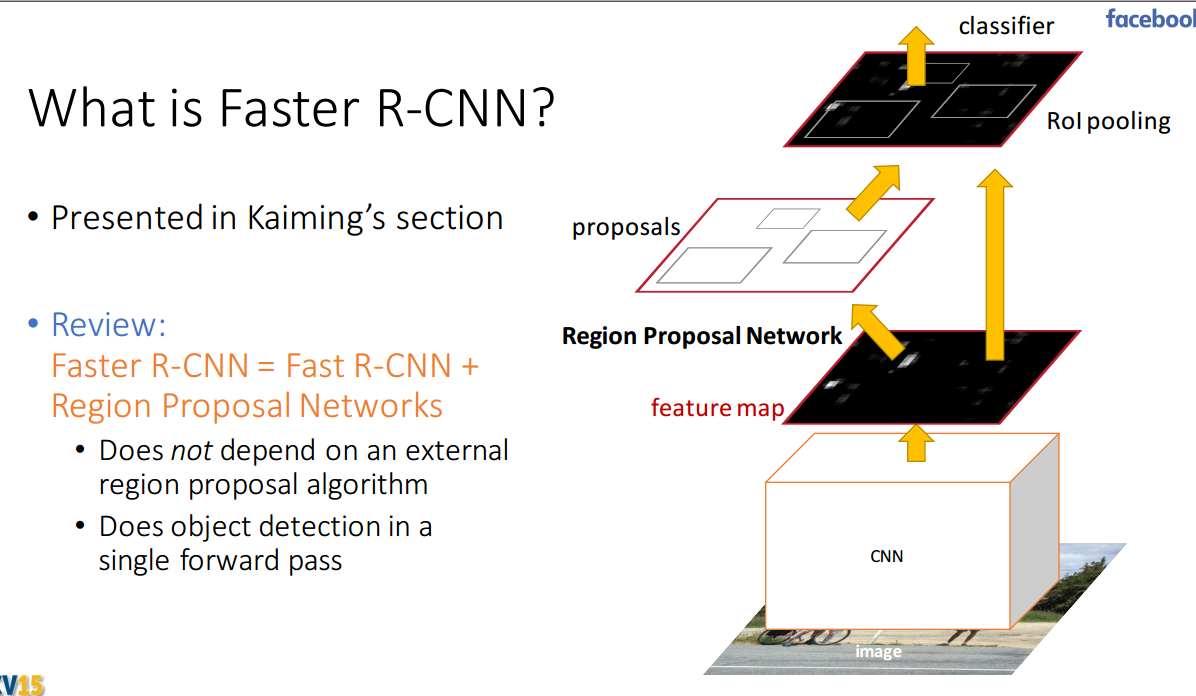
RPN НЋвЛећЗљЭМЯёзїЮЊЪфШы, ЪфГівЛЯЕСаЕФОиаЮКђбЁЧјгђ. ЫќЪЧвЛИіШЋОэЛ§ЭјТчФЃаЭ, ЭЈЙ§дкгы Fast
R-CNN ЙВЯэОэЛ§ВуЕФзюКѓвЛВуЪфГіЕФЬиеїЭМЩЯЛЌЖЏвЛИіаЁаЭЭјТчЃЈsliding windowЃЉ, етИіЭјТчгыЬиеїЭМЩЯЕФаЁДАПкШЋСЌНг,
УПИіЛЌЖЏДАПкгГЩфЕНвЛИіЕЭЮЌЕФЬиеїЯђСП, дйЪфШыИјСНИіВЂСаЕФШЋСЌНгВу, МДЗжРрВу (cls layer)
КЭБпПђЛиЙщВу(reg layer), гЩгкЭјТчЪЧвдЛЌЖЏДАЕФаЮЪНРДНјааВйзї, ЫљвдШЋСЌНгВуЕФВЮЪ§дкЫљгаПеМфЮЛжУЪЧЙВЯэЕФ.
RPNЕФНсЙЙдкЪЕЯжЪБЪЕМЪЩЯЪЧвЛИіШЋОэЛ§ЭјТчЁЃ
RPNЪЧвЛИіШѕМьВтЦїЃЌRPNЕФЪфГіЪЧвЛаЉПЩФмАќКЌФПБъЕФКђбЁПђЃЈ region proposals
ЛђепГЦЮЊ region of interest ,ROIЃЉ,етаЉROI НЋЛсЪфШыFast R-CNNжаЃЌгУгкзюКѓЕФМьВтЁЃ
бЕСЗЗНЪНЃК

AnchorЕФзїгУ
АДееСНВНМьВтЕФЙпР§ЃЌгІИУвЊЯШгаГѕВНЕФROI ЃЌШЛКѓВХЪЧзюжеЕФЗжРрКЭЛиЙщЃЌЖдгкдАцЕФFast R-CNNРДЫЕЃЌЫќЕФROIЪЧгЩselective
searchЫуЗЈЬсЙЉЕФЃЛЖјFaster R-CNNжаЕФ Fast R-CNNЕФ ROI дђЪЧгЩRPNЭјТчВњЩњЕФЁЃ
ФЧУДRPNМШШЛЪЧвЛИіШѕМьВтЦїЃЌФЧУДRPNЕФROIЛђеп region proposalsДгФФРДЃП Д№АИЪЧДг
anchor жаРДЁЃ
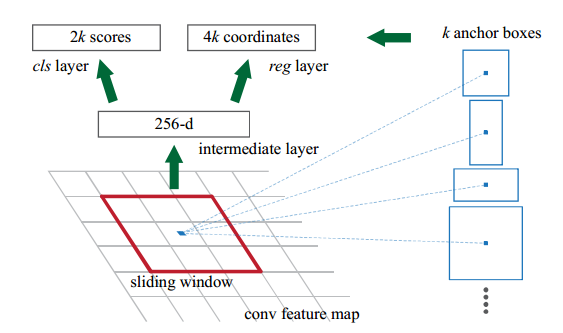
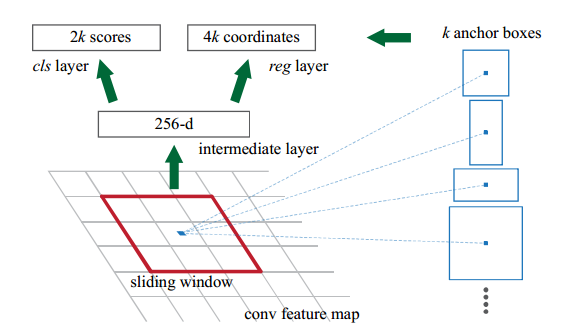
НсКЯЩЯУцЕФЭМЃЌRPNдкCNNЬсШЁЬиеїжЎКѓвдsliding windowЕФЗНЪНдкзюКѓвЛИіfeature
mapЩЯЬсШЁЬиеїЃЌУПИіЛЌЖЏДАПкжааФЖМЙиСЊзХ kИі boxЃЌетаЉboxОЭГЦЮЊanchorЃЌЛђепНаanchor
boxЁЃетаЉЙиСЊЕФbox ПЩвдЭЈЙ§ФцЯђгГЩфЖдгІЕНдЭМЩЯЃЌЖдгІЕНдЭМЩЯЕФЧјгђОЭЪЧregion proposalsЃЌВЛЙ§етаЉregion
proposalsЖМЪЧЮЛгкЭЌвЛИіжааФЕуЁЃОЭЪЧЫЕsliding windowЪБЕФwindowЃЈДѓаЁЙЬЖЈЃЉЪЧгЩетаЉдЭМЩЯЕФВЛЭЌДѓаЁКЭБШР§ЕФ
region proposals ЩњГЩЕФЃЈРрЫЦгкROIГиЛЏЕФЙІФмЃЉЁЃ
ЪЕМЪЩЯsliding windowЪБУПИі window Ц№ЕНСЫвЛВПЗжregion proposals
ЕФзїгУЃЌЕЋЪЧгЩгкетРяЕФsliding windowЕФГпДчЪЧЙЬЖЈЕФЃЌЫљвдВЛФмЦ№ЕНЖрГпЖШЃЌЖрГпДчЃЈmultiple
scales and sizes ЃЉдЄВтЕФзїгУЃЌвђДЫЬсГіЙиСЊkИіВЛЭЌДѓаЁКЭГЄПэБШЕФanchor boxЃЌетбљЖўепНсКЯМДПЩЦ№ЕНЖрГпЖШЃЌЖрГпДчдЄВтЕФзїгУЁЃВЮПМЯТЭМЃК
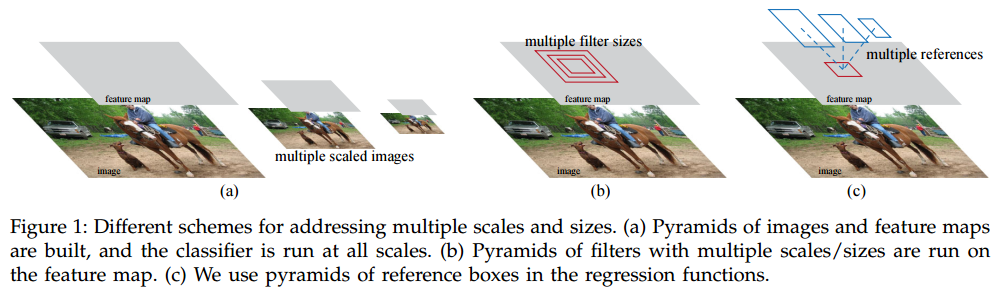
ЪЙгУanchorЕФКУДІЪЧЃЌRPNзюКѓsliding window ЪБПЩвдЪЙгУ ОэЛ§ЕФЗНЪНЪЕЯжЃЈвђЮЊ
windowЕФДѓаЁЪЧЙЬЖЈЕФЃЉЃЌЪЙЭјТчБфЕУКмМђЕЅЁЃ
ЖјКѓУцЕФ 256ЮЌЯђСПЕФЪфШы гЩгкгУОэЛ§ВуЪЕЯжЫљвдвВгЩ ЃЈ1,1,256ЃЉЃЌБфГЩСЫЃЈW,H,256ЃЉ.
ЕЋЪЧЮвУЧжЊЕРКѓУцЕФЪфШыЪЧЙЬЖЈГпДчЕФ window ЃЌФЧУДдкЗжРрКЭЛиЙщЪБЪЧШчКЮРДЗДгГВЛЭЌГпДчКЭБШР§ЕФ
region proposalsФиЃПД№АИЪЧЭЈЙ§ БъЧЉКЭЫ№ЪЇКЏЪ§ЁЃ
вдЯТв§гУзд [ВЮПМзЪСЯ 1]ЃЌдкФЧЮЛДѓажЕмЕФВЉПЭжаЃЌвЛПЊЪМЫћЕФРэНтЪЧЖдЕФЃЌЕЋЪЧКѓУцЕФВЙГфЫћгжИјИФДэСЫЃЌЕЋЪЧВЛЪЧЪВУДДѓДэЃЌФкШнЪЧЖдЕФЃЌжЛЪЧвђЙћЙиЯЕИуЗДСЫЃЌетРяжЛАбФкШнЬљГіРДЃК
ДгnxnЬсГіЕФ256dЬиеїЪЧБЛетkжжЧјгђЙВЯэЕФЃЌдкclc layerКЭreg layerМЦЫуЫ№ЪЇЕФЪБКђЃЌгУетЙВЯэЕФ256dЬиеї
МгЩЯ anchorЭЦЫуГіkжжЧјгђЕФзјБъКЭЧАОАЁЂБГОАЕФБъЧЉЃЌБуПЩвдЖдетkжжЧјгђЭЌЪБМЦЫуlossЁЃ
clc layerКЭreg layerЭЌЪБдЄВтkИіЧјгђЕФЧАОАЁЂБГОАИХТЪЃЈ1ИіЧјгђ2ИіscoresЃЌЫљвдЪЧ2kИіscoresЃЉЃЌвдМАbounding
boxЃЈ1ИіЧјгђ4ИіcoordinatesЃЌЫљвдЪЧ4kИіcoordinatesЃЉЃЌОпЬхЕФЫЕЃК
clc layerЪфГідЄВтЧјгђЕФ2ИіВЮЪ§ЃЌМДдЄВтЮЊЧАОАЕФИХТЪpaКЭpbЃЌЫ№ЪЇгУsoftmax lossЃЈcross
entropy lossЃЉЃЈБОРДЛЙвдЮЊЪЧsigmoidЃЌетбљЕФЛАжЛдЄВтpaОЭПЩвдСЫЃПЃЉЁЃашвЊЕФМрЖНаХЯЂЪЧY=0,1ЃЌБэЪОетИіЧјгђЪЧЗёground
truth
reg layerЪфГідЄВтЧјгђЕФ4ИіВЮЪ§ЃКx,y,w,hЃЌгУsmooth L1 lossЁЃашвЊЕФМрЖНаХЯЂЪЧ
anchorЕФЧјгђзјБъ{xa,ya,wa,ha} КЭ ground truthЕФЧјгђзјБъ{x,y,w,h}
ЯдШЛЃЌЩЯУцЕФМрЖНаХЯЂЃКYЃЌ{xa,ya,wa,ha}ЃЈkИіЃЉЃЌ{x*,y*,w*,h*}ЃЈ1ИіЃЉЃЌОЭЪЧЭЈЙ§anchorЛњжЦВњЩњЕФЁЃетМИИіВЮЪ§ЕФжИЖЈЃЈБШШчkИіanchorЧјгђЕФYЪЧдѕУДЕУЕНЕФЃЉЪЧИљОнЮФеТжаЕФбљБОВњЩњЙцдђЃЌКмЖрВЉПЭжавВЖМЬсЕНСЫЁЃ
ВЮПМзЪСЯЃК
faster-rcnnжаЃЌЖдRPNЕФРэНт
faster rcnnжаrpnЕФanchorЃЌsliding windowsЃЌproposalsЃП
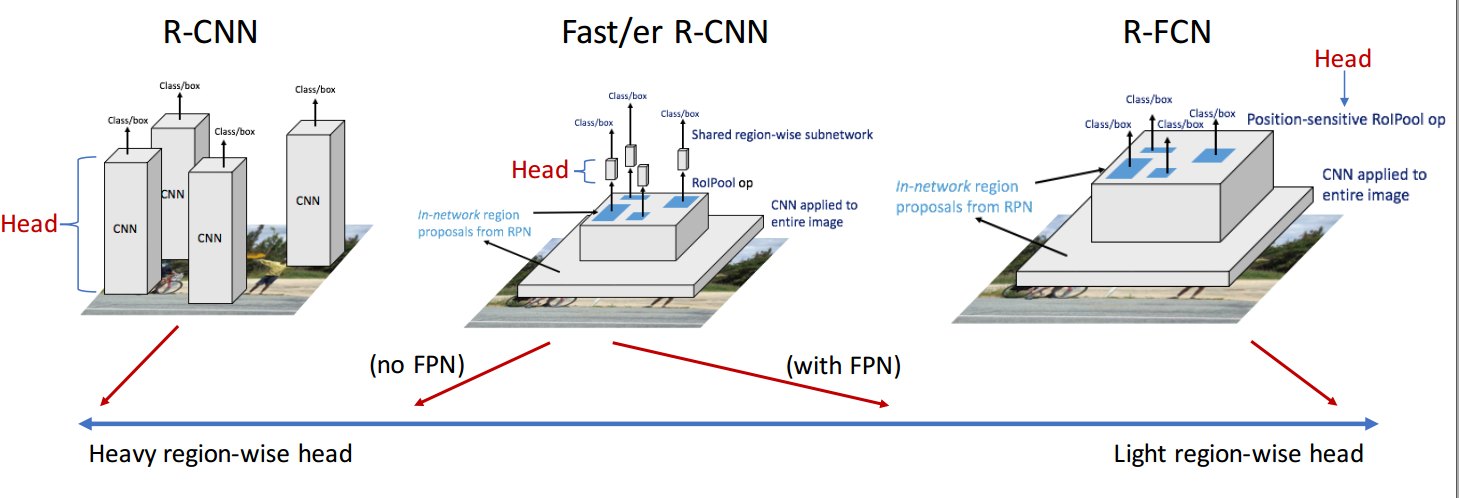
R-FCN
ШчЙћВЛПМТЧЩњГЩROIЕФВПЗжЃЈБШШчRPNЃЌRegion Proposal NetworkЃЉЃЌСНВНМьВтФЃаЭПЩвдЗжЮЊСНВПЗжзгЭјТчЃЈsubnetworks
ЃЉЃК
ЕквЛВПЗжЪЧЙВЯэМЦЫуЕФШЋОэЛ§ЛљДЁзгЭјТч baseЃЌЛђГЦbodyЃЌtrunk ЃЌетвЛВПЗжЪЧгыROIЖРСЂЕФЃЌжївЊгУгкЬсШЁЬиеї
ЕкЖўВПЗжЪЧВЛЙВЯэМЦЫуЕФзгЭјТч headЃЌЩњГЩЕФУПвЛИіROIЖМвЊОЙ§headВПЗжЃЌжївЊгУгкЗжРр
Faster R-CNN ЪЕЯжСЫКмЖрМЦЫуЕФЙВЯэЃКROIжЎМфЕФЬиеїЬсШЁЙВЯэМЦЫуЃЌROI ЬсШЁгыbaseВПЗжЙВЯэМЦЫуЃЌЕЋЪЧROIЭЈЙ§headВПЗжЪЧВЛЙВЯэМЦЫуЁЃ
R-FCNОЭЪЧЛљгкFCNНЋ headВПЗжвВЪЕЯжСЫМЦЫуЙВЯэЁЃЕЋЪЧгЩгкжБНгНЋ Faster R-CNN
ЕФheadВПЗжвВОЭЪЧШЋСЌНгВуИФЮЊШЋОэЛ§ВуЃЌШЛКѓдйЪЙгУ
R-FCNЪЧвЛжжаТЕФЛљгкЧјгђЕФШЋОэЛ§ЭјТчМьВтЗНЗЈ. ЮЊСЫИјЭјТчв§ШыЦНвЦБфЛЏ, ЙЙНЈЖдЮЛжУУєИаЕФГиЛЏЗНЪН
(Position sensitive pooling), БрТыИааЫШЄЧјгђЕФЯрЖдПеМфЮЛжУаХЯЂ. ИУЭјТчНтОіСЫ
Faster R-CNN гЩгкжиИДМЦЫуШЋСЌНгВуЖјЕМжТЕФКФЪБЮЪЬт, ЪЕЯжСЫШУећИіЭјТчжаЫљгаЕФМЦЫуЖМПЩвдЙВЯэ
ЁЃ
Position sensitive poolingЃК
ROI Pooling жаЕФУПвЛИіЭјИёЖМРДздЧАУц position-sensitive score
mapsжаВЛЭЌзщЭЈЕРЕФ feature mapЁЃетИіИњЗжзщОэЛ§ЕФвтЫМгаЕуЯёЃЌетИіПЩвдНазіЗжзщROIГиЛЏЁЃЪЧвЛжжбЁдёадROIГиЛЏЃЌжївЊЪЧЮЊСЫдіЧПЖдЮЛжУЕФУєИаГЬЖШЁЃ
Light-head RCNN
ВЛЙмЪЧ Faster R-CNNЛЙЪЧ R-FCN дк ROI(Region of Interest)
ЩњГЩЧАКѓЖМЪЧМЦЫуСПКмДѓЕФЃЌБШШч Faster R-CNN ЕФheadВПЗжАќКЌСНИіШЋСЌНгВугУгкROI
ЗжРрЃЌЖјШЋСЌНгВуМЋДѓЕиЯћКФМЦЫуЃЛR-FCNЫфШЛБШ Faster R-CNNПьаэЖрЃЌЕЋЪЧгЩгкЩњГЩЕФ score
mapsЬЋЖрЃЌЯывЊДяЕНЪЕЪБЃЈ30FPS, Frame Per SecondЃЉЛЙЪЧгаЕуРЇФбЕФЁЃвВОЭЪЧЫЕетаЉФЃаЭжЎЫљвдЫйЖШТ§ЕФдвђдкгкМЦЫуСПЙ§гкЗБжиЕФ
headВПЗж (heavy-head design )ЃЌМДБуЪЧНЋ baseВПЗжЯїМѕбЙЫѕЃЌМЦЫуЯћКФвВВЛФмКмДѓГЬЖШЕФЯїМѕЁЃ
БОЮФЬсГіСЫвЛжжаТЕФСНВНМьВтФЃаЭЃЌ Light-Head RCNN ЃЌЮЊСЫНтОіЯждкЕФСНВНМьВтЦеБщДцдкЕФ
heavy-headЕФЮЪЬтЁЃдкБОЮФФЃаЭЕФЩшМЦжаЪЙгУСЫthin feature map КЭ cheap
R-CNN subnet (pooling and single fully-connected layer)ЃЌЪЧЖдR-FCNЕФИФНјЁЃ
ИФНјЃК
в§Нјinception V3жаПЩЗжРыОэЛ§ЕФЫМЯыЃЌзїепВЩгУlarge separable convolutionЩњГЩchannelЪ§ИќЩйЕФfeature
map(Дг3969МѕЩйЕН490)ЁЃ
гУFCВуДњЬцСЫR-FCNжаЕФglobal average poolЃЌБмУтПеМфаХЯЂЕФЖЊЪЇЁЃ
ВЮПМзЪСЯЃК
https://zhuanlan.zhihu.com/p/33158548
Mask R-CNN
дкfatser rcnnЕФЛљДЁЩЯЖдROIЬэМгвЛИіЗжИюЕФЗжжЇЃЌдЄВтROIЕБжадЊЫиЫљЪєЗжРрЃЌЪЙгУFCNНјаадЄВтЃЛ
ОпЬхВНжшЃКЪЙгУfatser rcnnжаЕФrpnЭјТчВњЩњregion proposalЃЈROIЃЉЃЌНЋROIЗжСНИіЗжжЇЃКЃЈ1ЃЉfatser
rcnnВйзїЃЌМДОЙ§ROI pooling ЪфШыfcНјааЗжРрКЭЛиЙщЃЛЃЈ2ЃЉmaskВйзїЃЌМДЭЈЙ§ROIAlignаЃе§ОЙ§ROI
PoolingжЎКѓЕФЯрЭЌДѓаЁЕФROIЃЌШЛКѓдкгУfcnНјаадЄВтЃЈЗжИюЃЉЁЃ
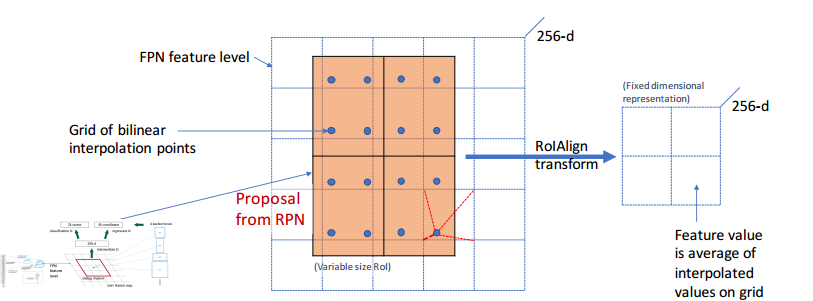
ROIAlignВњЩњЕФдвђЃКRoI PoolingОЭЪЧНЋдЭМROIЧјгђгГЩфЕНfeature mapЩЯЃЌзюКѓpoolingЕНЙЬЖЈДѓаЁЕФЙІФмЁЃЕБАбдЭМЩЯЕФROI
гГЩфЕН feature mapЩЯЪБЃЌДцдкЙщвЛЛЏЛђепСПЛЏЃЈМДШЁећЃЉЕФЙ§ГЬЁЃдкЙщвЛЛЏЕФЙ§ГЬЕБжаЃЌгЩгкДцдкЖрДЮСПЛЏЙ§ГЬЃЈОэЛ§ВНГЄЃЌГиЛЏЃЉЃЌЛсДцдкROIгыЬсШЁЕНЕФЬиеїВЛЖдзМЕФЯжЯѓГіЯж
вВОЭЪЧfeature mapЩЯЕФROIдйгГЩфЛсдЭМЪБЛсИњдРДЕФROIЖдВЛзМЃЌгЩгкЗжРрЮЪЬтЖдЦНвЦЮЪЬтБШНЯТГАєЃЌЫљвдгАЯьБШНЯаЁЁЃЕЋЪЧетдкдЄВтЯёЫиМЖОЋЖШЕФбкФЃЪБЛсВњЩњвЛИіЗЧГЃЕФДѓЕФИКУцгАЯьЁЃзїепОЭЬсГіСЫетИіИХФюROIAlignЃЌЪЙгУROIAlignВуЖдЬсШЁЕФЬиеїКЭЪфШыжЎМфНјаааЃзМЁЃ
ROI AlignЕФЫМТЗКмМђЕЅЃКШЁЯћСПЛЏВйзїЃЌЪЙгУЫЋЯпадВхжЕЕФЗНЗЈЛёЕУзјБъЮЊИЁЕуЪ§ЕФЯёЫиЕуЩЯЕФЭМЯёЪ§жЕ,ДгЖјНЋећИіЬиеїОлМЏЙ§ГЬзЊЛЏЮЊвЛИіСЌајЕФВйзїЃЌЁЃжЕЕУзЂвтЕФЪЧЃЌдкОпЬхЕФЫуЗЈВйзїЩЯЃЌROI
AlignВЂВЛЪЧМђЕЅЕиВЙГфГіКђбЁЧјгђБпНчЩЯЕФзјБъЕуЃЌШЛКѓНЋетаЉзјБъЕуНјааГиЛЏЃЌЖјЪЧжиаТЩшМЦСЫвЛЬзБШНЯгХбХЕФСїГЬЃЌШч
ЭМ ЫљЪОЃК
БщРњУПвЛИіКђбЁЧјгђЃЌБЃГжИЁЕуЪ§БпНчВЛзіСПЛЏЁЃ
НЋКђбЁЧјгђЗжИюГЩk x kИіЕЅдЊЃЌУПИіЕЅдЊЕФБпНчвВВЛзіСПЛЏЁЃ
дкУПИіЕЅдЊжаМЦЫуЙЬЖЈЫФИізјБъЮЛжУЃЌгУЫЋЯпадФкВхЕФЗНЗЈМЦЫуГіетЫФИіЮЛжУЕФжЕЃЌШЛКѓНјаазюДѓГиЛЏВйзїЁЃ
етРяЖдЩЯЪіВНжшЕФЕкШ§ЕузївЛаЉЫЕУїЃКетИіЙЬЖЈЮЛжУЪЧжИдкУПвЛИіОиаЮЕЅдЊЃЈbinЃЉжаАДееЙЬЖЈЙцдђШЗЖЈЕФЮЛжУЁЃБШШчЃЌШчЙћВЩбљЕуЪ§ЪЧ1ЃЌФЧУДОЭЪЧетИіЕЅдЊЕФжааФЕуЁЃШчЙћВЩбљЕуЪ§ЪЧ4ЃЌФЧУДОЭЪЧАбетИіЕЅдЊЦНОљЗжИюГЩЫФИіаЁЗНПщвдКѓЫќУЧЗжБ№ЕФжааФЕуЁЃЯдШЛетаЉВЩбљЕуЕФзјБъЭЈГЃЪЧИЁЕуЪ§ЃЌЫљвдашвЊЪЙгУВхжЕЕФЗНЗЈЕУЕНЫќЕФЯёЫижЕЁЃ
|









