| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊИХЪівЛЯТR-CNNЪЧШчКЮВЩгУОэЛ§ЩёОЭјТчНјааФПБъМьВтЕФЙЄзїЃЌЯЃЭћЛсЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
Mask R-CNNЪЧICCV 2017ЕФbest paperЃЌеУЯдСЫЛњЦїбЇЯАМЦЫуЛњЪгОѕСьгђдк2017ФъЕФзюаТГЩЙћЁЃдкЛњЦїбЇЯА2017ФъЕФзюаТЗЂеЙжаЃЌЕЅШЮЮёЕФЭјТчНсЙЙвбОж№НЅВЛдйв§ШЫжѕФПЃЌШЁЖјДњжЎЕФЪЧМЏГЩЃЌИДдгЃЌвЛЪЏЖрФёЕФЖрШЮЮёЭјТчФЃаЭЁЃMask
R-CNNОЭЪЧЕфаЭЕФДњБэЁЃ
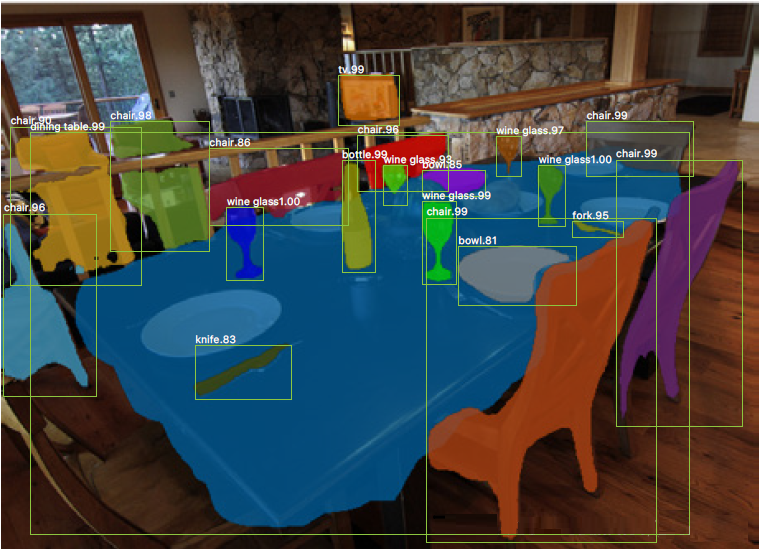

ДѓМвПЩвдПДЕНЃЌдкЪЕР§ЗжИюMask R-CNNПђМмжаЃЌЛЙЪЧжївЊЭъГЩСЫШ§МўЪТЧщЃК
1) ФПБъМьВтЃЌжБНгдкНсЙћЭМЩЯЛцжЦСЫФПБъПђ(bounding box)ЁЃ
2) ФПБъЗжРрЃЌЖдгкУПвЛИіФПБъЃЌашвЊевЕНЖдгІЕФРрБ№(class)ЃЌЧјЗжЕНЕзЪЧШЫЃЌЪЧГЕЃЌЛЙЪЧЦфЫћРрБ№ЁЃ
3) ЯёЫиМЖФПБъЗжИюЃЌдкУПИіФПБъжаЃЌашвЊдкЯёЫиВуУцЧјЗжЃЌЪВУДЪЧЧАОАЃЌЪВУДЪЧБГОАЁЃ
ПЩЪЧЃЌдкНтЮіMask R-CNNжЎЧАЃЌБЪепВЛЕУВЛИцЫпДѓМввЛИіЪТЪЕЃЌMask
R-CNNЪЧМЬГагкFaster R-CNN (2016)ЕФЃЌMask R-CNNжЛЪЧдкFaster
R-CNNЩЯУцМгСЫвЛИіMask Prediction Branch (Mask дЄВтЗжжЇ)ЃЌВЂЧвИФСМСЫROI
PoolingЃЌЬсГіСЫROI AlignЁЃДгЭГМЦЪ§ОнРДПДЃЌ"Faster R-CNN"дкMask
R-CNNТлЮФЕФЧАШ§еТжаГіЯжСЫЖўЪЎгрДЮЃЌвђДЫЃЌШчЙћВЛСЫНтRoss GirshickКЭКЮПУїжЎЧАЕФЙЄзїЃЌЪЧКмФбХЊЖЎMask
R-CNNЕФЁЃ
дкИјДѓМвНтЮіFaster R-CNNжЎЧАЃЌБЪепгжвЊИцЫпДѓМвЃЌFaster R-CNNЪЧМЬГагкFast
R-CNN (2015)ЃЌFast R-CNNМЬГагкR-CNN (2014)ЁЃвђДЫЃЌЫїадЦЦИЊГСжлЃЌдкБОЦЊВЉЮФжаЃЌБЪепОЭАДееR-CNN,
Fast R-CNNЃЌFaster R-CNNдйЕНMask R-CNNЕФЗЂеЙЫГађШЋВПНтЮіЁЃ
ЪзЯШЪБМфЛиЕНСЫ2014ФъЃЌдк2014ФъЃЌе§ЪЧЩюЖШбЇЯАШчЛ№ШчнБЕФЗЂеЙЕФЕкШ§ФъЁЃдкCVPR
2014ФъжаRoss GirshickЬсГіЕФR-CNNжаЃЌЪЙгУЕНСЫОэЛ§ЩёОЭјТчРДНјааФПБъМьВтЁЃЯТУцБЪепОЭРДИХЪівЛЯТR-CNNЪЧШчКЮВЩгУОэЛ§ЩёОЭјТчНјааФПБъМьВтЕФЙЄзїЁЃ
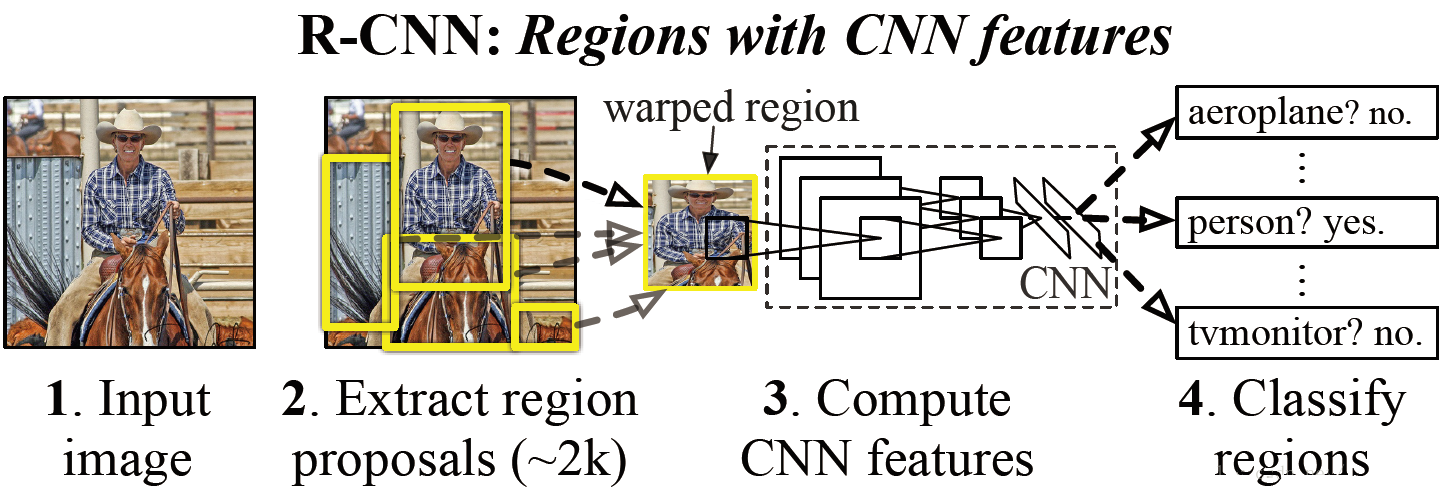
ЪзЯШФЃаЭЪфШыЮЊвЛеХЭМЦЌЃЌШЛКѓдкЭМЦЌЩЯЬсГіСЫдМ2000ИіД§МьВтЧјгђЃЌШЛКѓет2000ИіД§МьВтЧјгђвЛИівЛИіЕи(ДЎСЊЗНЪН)ЭЈЙ§ОэЛ§ЩёОЭјТчЬсШЁЬиеїЃЌШЛКѓетаЉБЛЬсШЁЕФЬиеїЭЈЙ§вЛИіжЇГжЯђСПЛњ(SVM)НјааЗжРрЃЌЕУЕНЮяЬхЕФРрБ№ЃЌВЂЭЈЙ§вЛИіbounding
box regressionЕїећФПБъАќЮЇПђЕФДѓаЁЁЃЯТУцЃЌБЪепМђвЊИХЪівЛЯТR-CNNЪЧдѕУДЪЕЯжвдЩЯВНжшЕФЁЃ
ЪзЯШдкЕквЛВНЬсШЁ2000ИіД§МьВтЧјгђЕФЪБКђЃЌЪЧЭЈЙ§вЛИі2012ФъЬсГіЕФЗНЗЈЃЌНазіselective
searchЁЃМђЕЅРДЫЕОЭЪЧЭЈЙ§вЛаЉДЋЭГЭМЯёДІРэЗНЗЈНЋЭМЯёЗжГЩШєИЩПщЃЌШЛКѓЭЈЙ§вЛИіSVMНЋЪєгкЭЌвЛФПБъЕФШєИЩПщФУГіРДЁЃselective
searchЕФКЫаФЪЧвЛИіSVMЃЌМмЙЙШчЯТЫљЪОЃК
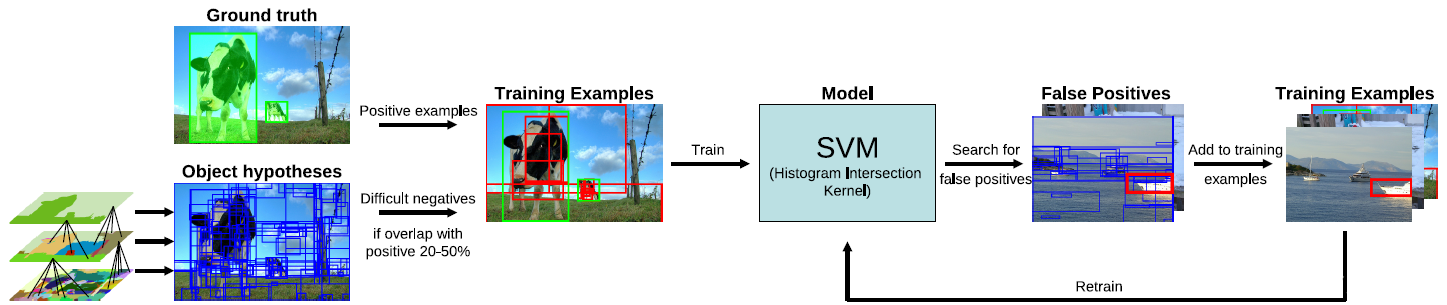
ШЛКѓдкЕкЖўВННјааЬиеїЬсШЁЕФЪБКђЃЌRossжБНгНшжњСЫЕБЪБЩюЖШбЇЯАЕФзюаТГЩЙћAlexNet (2012)ЁЃФЧУДЃЌИУЭјТчЪЧШчКЮбЕСЗЕФФиЃПЪЧжБНгдкImageNetЩЯУцбЕСЗЕФЃЌвВОЭЪЧЫЕЃЌЪЙгУЭМЯёЗжРрЪ§ОнМЏбЕСЗСЫвЛИіНіНігУгкЬсШЁЬиеїЕФЭјТчЁЃ
дкЕкШ§ВННјааЖдФПБъЕФЪБКђЃЌЪЙгУСЫвЛИіжЇГжЯђСПЛњ(SVM)ЃЌдкбЕСЗетИіжЇГжЯђСПЛњЕФЪБКђЃЌНсКЯФПБъЕФБъЧЉ(РрБ№)гыАќЮЇПђЕФДѓаЁНјаабЕСЗЃЌвђДЫЃЌИУжЇГжЯђСПЛњвВЪЧБЛЕЅЖРбЕСЗЕФЁЃ
дк2014ФъR-CNNКсПеГіЪРЕФЪБКђЃЌЕпИВСЫвдЭљЕФФПБъМьВтЗНАИЃЌОЋЖШДѓДѓЬсЩ§ЁЃЖдгкR-CNNЕФЙБЯзЃЌПЩвджївЊЗжЮЊСНИіЗНУцЃК
1) ЪЙгУСЫОэЛ§ЩёОЭјТчНјааЬиеїЬсШЁЁЃ
2) ЪЙгУbounding box regressionНјааФПБъАќЮЇПђЕФаое§ЁЃ
ЕЋЪЧЃЌЮвУЧРДПДвЛЯТЃЌR-CNNгаЪВУДЮЪЬтЃК
1) КФЪБЕФselective searchЃЌЖдвЛжЁЭМЯёЃЌашвЊЛЈЗб2sЁЃ
2) КФЪБЕФДЎааЪНCNNЧАЯђДЋВЅЃЌЖдгкУПвЛИіRoIЃЌЖМашвЊОЙ§вЛИіAlexNetЬсЬиеїЃЌЮЊЫљгаЕФRoIЬсЬиеїДѓдМЛЈЗб47sЁЃ
3) Ш§ИіФЃПщЪЧЗжБ№бЕСЗЕФЃЌВЂЧвдкбЕСЗЕФЪБКђЃЌЖдгкДцДЂПеМфЕФЯћКФКмДѓЁЃ
ФЧУДЃЌУцЖдетжжЧщЪЦЃЌRossдк2015ФъЬсГіЕФFast R-CNNНјааСЫИФНјЃЌЯТУцЮвУЧРДИХЪівЛЯТFast
R-CNNЕФНтОіЗНАИЃК
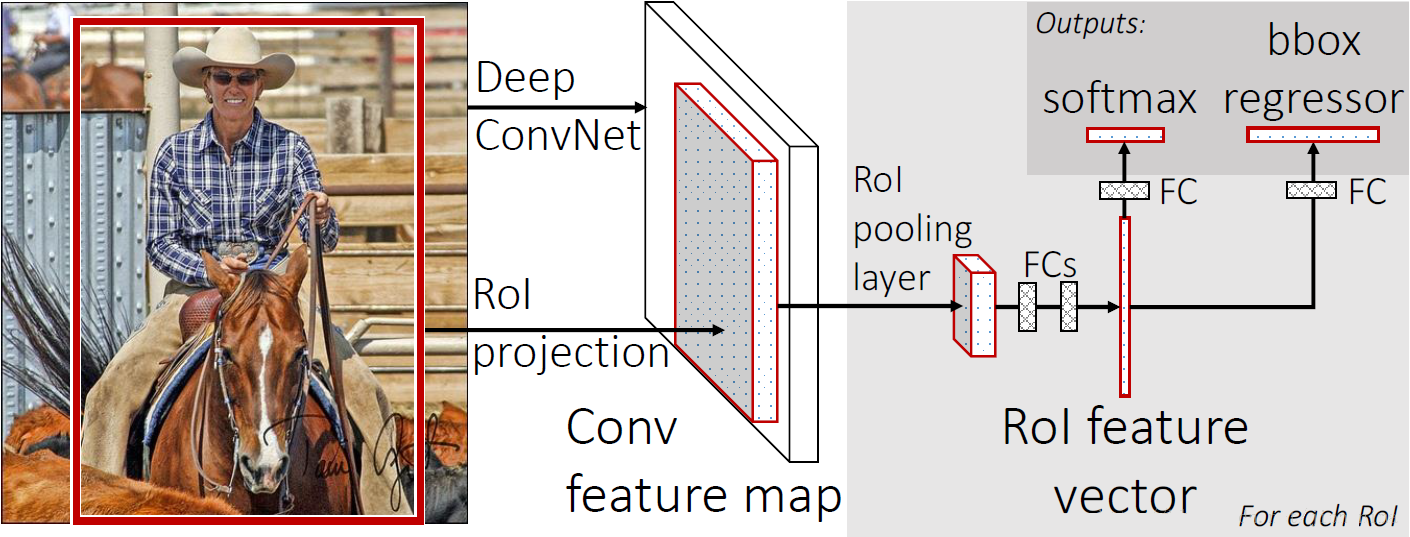
ЪзЯШЛЙЪЧВЩгУselective searchЬсШЁ2000ИіКђбЁПђЃЌШЛКѓЃЌЪЙгУвЛИіЩёОЭјТчЖдШЋЭМНјааЬиеїЬсШЁЁЃНгзХЃЌЪЙгУвЛИіRoI
Pooling LayerдкШЋЭМЬиеїЩЯеЊШЁУПвЛИіRoIЖдгІЕФЬиеїЃЌдйЭЈЙ§ШЋСЌНгВу(FC Layer)НјааЗжРргыАќЮЇПђЕФаое§ЁЃFast
R-CNNЕФЙБЯзПЩвджївЊЗжЮЊСНИіЗНУцЃК
1) ШЁДњR-CNNЕФДЎааЬиеїЬсШЁЗНЪНЃЌжБНгВЩгУвЛИіЩёОЭјТчЖдШЋЭМЬсШЁЬиеї(етвВЪЧЮЊЪВУДашвЊRoI
PoolingЕФдвђ)ЁЃ
2) Г§СЫselective searchЃЌЦфЫћВПЗжЖМПЩвдКЯдквЛЦ№бЕСЗЁЃ
ПЩЪЧЃЌFast R-CNNвВгаШБЕуЃЌЬхЯждкКФЪБЕФselective searchЛЙЪЧвРОЩДцдкЁЃФЧУДЃЌШчКЮИФСМетИіШБЯнФиЃПЗЂБэгк2016ФъЕФFaster
R-CNNНјааСЫШчЯТДДаТЃК
ШЁДњselective searchЃЌжБНгЭЈЙ§вЛИіRegion Proposal
Network (RPN)ЩњГЩД§МьВтЧјгђЃЌетУДзіЃЌдкЩњГЩRoIЧјгђЕФЪБКђЃЌЪБМфвВОЭДг2sЫѕМѕЕНСЫ10msЁЃЮвУЧРДПДвЛЯТFaster
R-CNNЪЧдѕУДзіЕФЁЃ
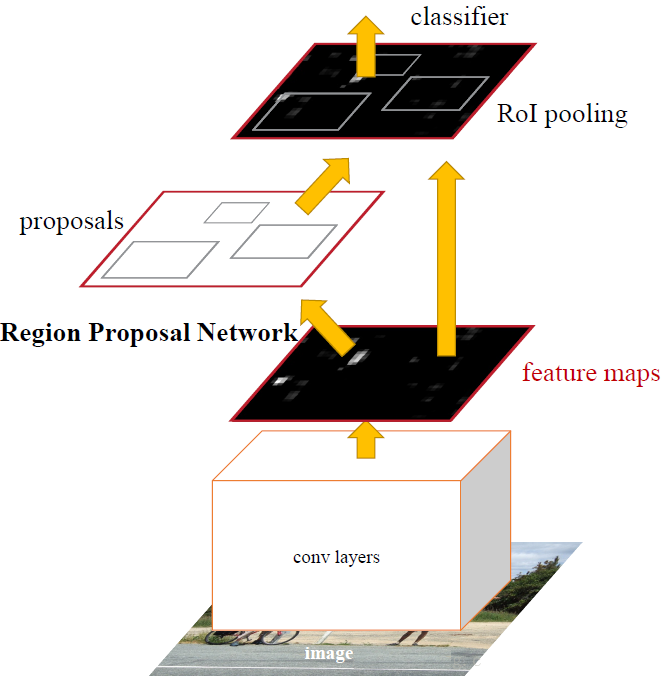
ЪзЯШЪЙгУЙВЯэЕФОэЛ§ВуЮЊШЋЭМЬсШЁЬиеїЃЌШЛКѓНЋЕУЕНЕФfeature mapsЫЭШыRPNЃЌRPNЩњГЩД§МьВтПђ(жИЖЈRoIЕФЮЛжУ)ВЂЖдRoIЕФАќЮЇПђНјааЕквЛДЮаое§ЁЃжЎКѓОЭЪЧFast
R-CNNЕФМмЙЙСЫЃЌRoI Pooling LayerИљОнRPNЕФЪфГідкfeature mapЩЯУцбЁШЁУПИіRoIЖдгІЕФЬиеїЃЌВЂНЋЮЌЖШжУЮЊЖЈжЕЁЃзюКѓЃЌЪЙгУШЋСЌНгВу(FC
Layer)ЖдПђНјааЗжРрЃЌВЂЧвНјааФПБъАќЮЇПђЕФЕкЖўДЮаое§ЁЃгШЦфзЂвтЕФЪЧЃЌFaster R-CNNеце§ЪЕЯжСЫЖЫЕНЖЫЕФбЕСЗ(end-to-end
training)ЁЃ
вЊРэНтMask R-CNNЃЌжЛгаЯШРэНтFaster R-CNNЁЃвђДЫЃЌБЪепИљОнFaster
R-CNNЕФМмЙЙ(Faster R-CNNЕФZF modelЕФtrain.prototxt)ЃЌЛСЫвЛИіНсЙЙЭМЃЌШчЯТЫљЪОЃК
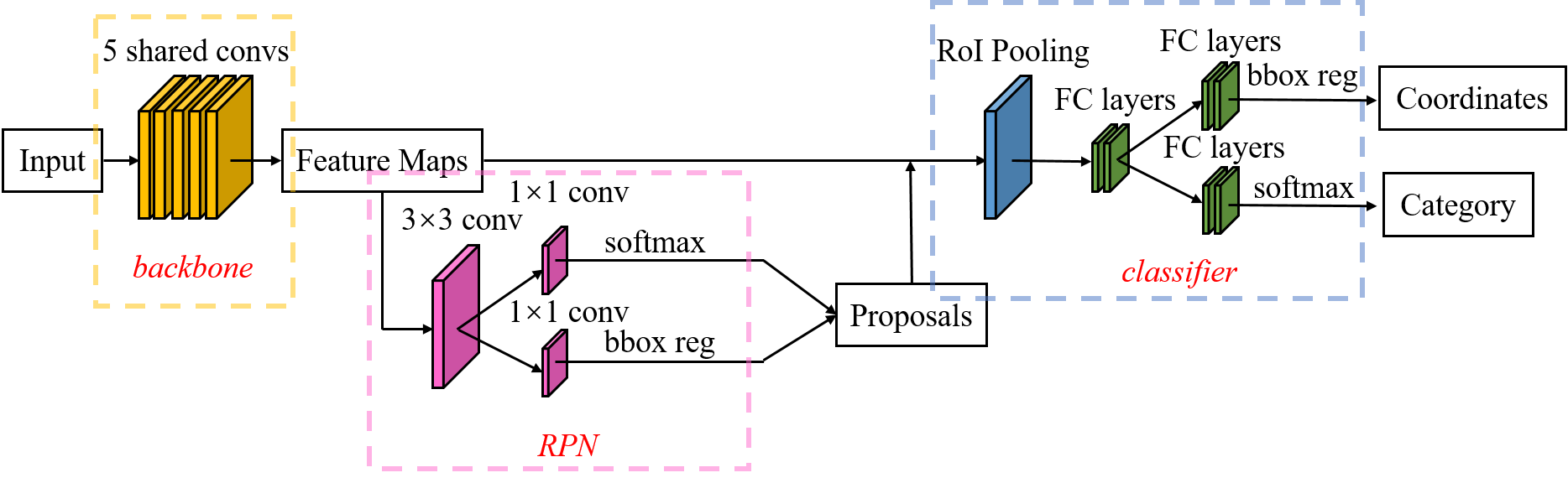
ШчЩЯЭМЫљЪОЃЌFaster R-CNNЕФНсЙЙжївЊЗжЮЊШ§ДѓВПЗжЃЌЕквЛВПЗжЪЧЙВЯэЕФОэЛ§Ву-backboneЃЌЕкЖўВПЗжЪЧКђбЁЧјгђЩњГЩЭјТч-RPNЃЌЕкШ§ВПЗжЪЧЖдКђбЁЧјгђНјааЗжРрЕФЭјТч-classifierЁЃЦфжаЃЌRPNгыclassifierВПЗжОљЖдФПБъПђгааое§ЁЃclassifierВПЗжЪЧддБОБОМЬГаЕФFast
R-CNNНсЙЙЁЃЮвУЧЯТУцРДМђЕЅПДПДFaster R-CNNЕФИїИіФЃПщЁЃ
ЪзЯШРДПДПДRPNЕФЙЄзїдРэЃК
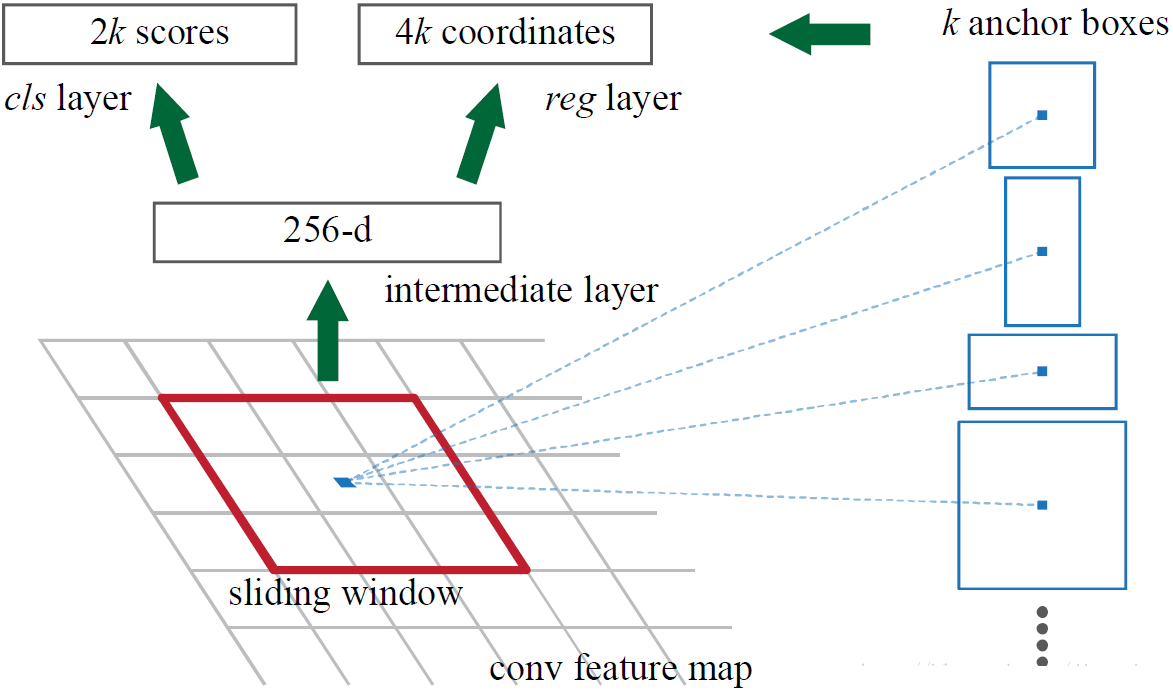
МђЕЅЕиЫЕЃЌRPNвРППвЛИідкЙВЯэЬиеїЭМЩЯЛЌЖЏЕФДАПкЃЌЮЊУПИіЮЛжУЩњГЩ9жждЄЯШЩшжУКУГЄПэБШгыУцЛ§ЕФФПБъПђ(ЮФжаНазіanchor)ЁЃет9жжГѕЪМanchorАќКЌШ§жжУцЛ§(128ЁС128ЃЌ256ЁС256ЃЌ512ЁС512)ЃЌУПжжУцЛ§гжАќКЌШ§жжГЄПэБШ(1:1ЃЌ1:2ЃЌ2:1)ЁЃЪОвтЭМШчЯТЫљЪОЃК
гЩгкЙВЯэЬиеїЭМЕФДѓаЁдМЮЊ40ЁС60ЃЌRPNЩњГЩЕФГѕЪМanchorЕФзмЪ§дМЮЊ20000Иі(40ЁС60ЁС9)ЁЃЖдгкЩњГЩЕФanchorЃЌRPNвЊзіЕФЪТЧщгаСНИіЃЌЕквЛИіЪЧХаЖЯanchorЕНЕзЪЧЧАОАЛЙЪЧБГОАЃЌвтЫМОЭЪЧХаЖЯетИіanchorЕНЕзгаУЛгаИВИЧФПБъЃЌЕкЖўИіЪЧЮЊЪєгкЧАОАЕФanchorНјааЕквЛДЮзјБъаое§ЁЃЖдгкЧАвЛИіЮЪЬтЃЌFaster
R-CNNЕФзіЗЈЪЧЪЙгУSoftmaxLossжБНгбЕСЗЃЌдкбЕСЗЕФЪБКђХХГ§ЕєСЫГЌдНЭМЯёБпНчЕФanchorЃЛЖдгкКѓвЛИіЮЪЬтЃЌВЩгУSmoothL1LossНјаабЕСЗЁЃФЧУДЃЌRPNдѕУДЪЕЯжФиЃПетИіЮЪЬтЭЈЙ§RPNЕФБОжЪКмКУЧѓНтЃЌRPNЕФБОжЪЪЧвЛИіЪїзДНсЙЙЃЌЪїИЩЪЧвЛИі3ЁС3ЕФОэЛ§ВуЃЌЪїжІЪЧСНИі1ЁС1ЕФОэЛ§ВуЃЌЕквЛИі1ЁС1ЕФОэЛ§ВуНтОіСЫЧАКѓОАЕФЪфГіЃЌЕкЖўИі1ЁС1ЕФОэЛ§ВуНтОіСЫБпПђаое§ЕФЪфГіЁЃРДПДПДдкДњТыжаЪЧдѕУДзіЕФЃК

ДгШчЩЯДњТыжаПЩвдПДЕНЃЌЖдгкRPNЪфГіЕФЬиеїЭМжаЕФУПвЛИіЕуЃЌвЛИі1ЁС1ЕФОэЛ§ВуЪфГіСЫ18ИіжЕЃЌвђЮЊЪЧУПвЛИіЕуЖдгІ9ИіanchorЃЌУПИіanchorгавЛИіЧАОАЗжЪ§КЭвЛИіБГОАЗжЪ§ЃЌЫљвд9ЁС2=18ЁЃСэвЛИі1ЁС1ЕФОэЛ§ВуЪфГіСЫ36ИіжЕЃЌвђЮЊЪЧУПвЛИіЕуЖдгІ9ИіanchorЃЌУПИіanchorЖдгІСЫ4Иіаое§зјБъЕФжЕЃЌЫљвд9ЁС4=36ЁЃФЧУДЃЌвЊЕУЕНетаЉжЕЃЌRPNЭјТчашвЊбЕСЗЁЃдкбЕСЗЕФЪБКђЃЌОЭашвЊЖдгІЕФБъЧЉЁЃФЧУДЃЌШчКЮХаЖЈвЛИіanchorЪЧЧАОАЛЙЪЧБГОАФиЃПЮФжазіГіСЫШчЯТЖЈвхЃКШчЙћвЛИіanchorгыground
truthЕФIoUдк0.7вдЩЯЃЌФЧетИіanchorОЭЫуЧАОА(positive)ЁЃРрЫЦЕиЃЌШчЙћетИіanchorгыground
truthЕФIoUдк0.3вдЯТЃЌФЧУДетИіanchorОЭЫуБГОА(negative)ЁЃдкзїепНјааRPNЭјТчбЕСЗЕФЪБКђЃЌжЛЪЙгУСЫЩЯЪіСНРрanchorЃЌгыground
truthЕФIoUНщгк0.3КЭ0.7ЕФanchorУЛгаЪЙгУЁЃдкбЕСЗanchorЪєгкЧАОАгыБГОАЕФЪБКђЃЌЪЧдквЛеХЭМжаЃЌЫцЛњГщШЁСЫ128ИіЧАОАanchorгы128ИіБГОАanchorЁЃ
дкЩЯвЛЖЮжаУшЪіСЫЧАОАгыБГОАЗжРрЕФбЕСЗЗНЗЈЃЌБОЖЮУшЪіanchorБпПђаое§ЕФбЕСЗЗНЗЈЁЃБпПђаое§жївЊгЩ4ИіжЕЭъГЩЃЌtx,ty,th,twЁЃетЫФИіжЕЕФвтЫМЪЧаое§КѓЕФПђдкanchorЕФxКЭyЗНЯђЩЯзіГіЦНвЦ(гЩtxКЭtyОіЖЈ)ЃЌВЂЧвГЄПэИїздЗХДѓвЛЖЈЕФБЖЪ§(гЩthКЭtyОіЖЈ)ЁЃФЧУДЃЌШчКЮбЕСЗЭјТчВЮЪ§ЕУЕНетЫФИіжЕФиЃПFast
R-CNNИјГіСЫД№АИЃЌВЩгУSmoothL1lossНјаабЕСЗЃЌОпЬхПЩвдУшЪіЮЊЃК
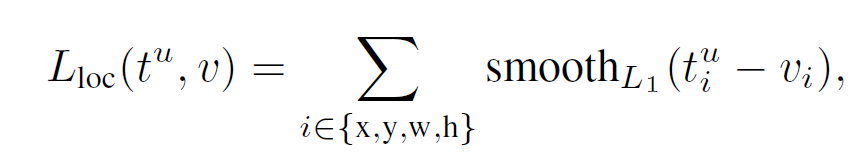
ЕНетРягаИіЮЪЬтЃЌОЭЪЧВЛЪЧЖдгкЫљгаЕФanchorЃЌЖМашвЊНјааanchorАќЮЇПђаое§ЕФВЮЪ§бЕСЗЃЌжЛЪЧЖдpositiveЕФanchorsгаетвЛВНЁЃвђДЫЃЌдкбЕСЗRPNЕФЪБКђЃЌжЛгаЖд128ИіЫцЛњГщШЁЕФpositive
anchorsгаетвЛВНбЕСЗЁЃвђДЫЃЌбЕСЗRPNЕФЫ№ЪЇКЏЪ§ПЩвдаДГЩЃК
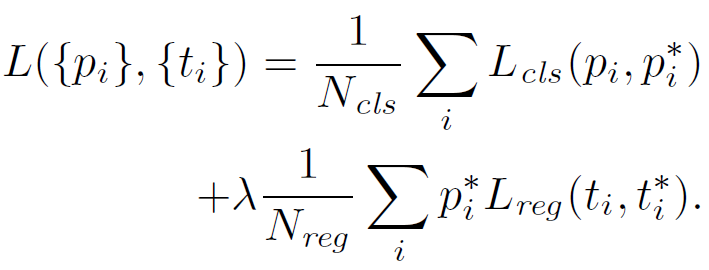
дкетРяLregОЭЪЧЩЯУцЕФLlocЃЌІЫБЛЩшжУЮЊ10ЃЌNclsЮЊ256ЃЌNregЮЊ2400ЁЃетбљЩшжУЕФЛАЃЌRPNЕФСНВПЗжlossжЕФмБЃГжЦНКтЁЃ
ЕНетРяRPNОЭНтЮіЭъБЯСЫЃЌЯТУцЮвУЧРДПДПДКѓУцЕФclassifierЃЌЕЋЪЧдкНщЩмclassifierжЎЧАЃЌЮвУЧЯШРДПДПДRoI
PoolingЕНЕззіСЫЪВУДЃП
ЪзЯШЕквЛИіЮЪЬтЪЧЮЊЪВУДашвЊRoI PoolingЃПД№АИЪЧдкFast
R-CNNжаЃЌЬиеїБЛЙВЯэОэЛ§ВувЛДЮадЬсШЁЁЃвђДЫЃЌЖдгкУПИіRoIЖјбдЃЌашвЊДгЙВЯэОэЛ§ВуЩЯеЊШЁЖдгІЕФЬиеїЃЌВЂЧвЫЭШыШЋСЌНгВуНјааЗжРрЁЃвђДЫЃЌRoI
PoolingжївЊзіСЫСНМўЪТЃЌЕквЛМўЪЧЮЊУПИіRoIбЁШЁЖдгІЕФЬиеїЃЌЕкЖўМўЪТЪЧЮЊСЫТњзуШЋСЌНгВуЕФЪфШыашЧѓЃЌНЋУПИіRoIЖдгІЕФЬиеїЕФЮЌЖШзЊЛЏГЩФГИіЖЈжЕЁЃRoI
PoolingЪОвтЭМШчЯТЫљЪОЃК
ШчЩЯЭМЫљЪОЃЌЖдгкУПвЛИіRoIЃЌRoI Pooling LayerНЋЦфЖдгІЕФЬиеїДгЙВЯэОэЛ§ВуЩЯФУГіРДЃЌВЂзЊЛЏГЩвЛбљЕФДѓаЁ(6ЁС6)ЁЃ
дкRoI Pooling LayerжЎКѓЃЌОЭЪЧFast R-CNNЕФЗжРрЦїКЭRoIБпПђаое§бЕСЗЁЃЗжРрЦїжївЊЪЧЗжетИіЬсШЁЕФRoIОпЬхЪЧЪВУДРрБ№(ШЫЃЌГЕЃЌТэЕШЕШ)ЃЌвЛЙВC+1Рр(АќКЌвЛРрБГОА)ЁЃRoIБпПђаое§КЭRPNжаЕФanchorБпПђаое§дРэвЛбљЃЌЭЌбљвВЪЧSmoothL1
LossЃЌжЕЕУзЂвтЕФЪЧЃЌRoIБпПђаое§вВЪЧЖдгкЗЧБГОАЕФRoIНјаааое§ЃЌЖдгкРрБ№БъЧЉЮЊБГОАЕФRoIЃЌдђВЛНјааRoIБпПђаое§ЕФВЮЪ§бЕСЗЁЃЖдгкЗжРрЦїКЭRoIБпПђаое§ЕФбЕСЗЃЌПЩвдЙЋЪНУшЪіШчЯТЃК
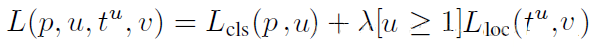
ЩЯЪНжаu>=1БэЪОRoIБпПђаое§ЪЧЖдгкЗЧБГОАЕФRoIЖјбдЕФЃЌЪЕбщжаЃЌЩЯЪНЕФІЫШЁ1ЁЃ
дкбЕСЗЗжРрЦїКЭRoIБпПђаое§ЪБЃЌВНжшШчЯТЫљЪОЃК
1) ЪзЯШЭЈЙ§RPNЩњГЩдМ20000Иіanchor(40ЁС60ЁС9)ЁЃ
2) Жд20000ИіanchorНјааЕквЛДЮБпПђаое§ЃЌЕУЕНаоЖЉБпПђКѓЕФproposalЁЃ
3) ЖдГЌЙ§ЭМЯёБпНчЕФproposalЕФБпНјааclipЃЌЪЙЕУИУproposalВЛГЌЙ§ЭМЯёЗЖЮЇЁЃ
4) КіТдЕєГЄЛђепПэЬЋаЁЕФproposalЁЃ
5) НЋЫљгаproposalАДееЧАОАЗжЪ§ДгИпЕНЕЭХХађЃЌбЁШЁЧА12000ИіproposalЁЃ
6) ЪЙгУуажЕЮЊ0.7ЕФNMSЫуЗЈХХГ§ЕєжиЕўЕФproposalЁЃ
7) еыЖдЩЯвЛВНЪЃЯТЕФproposal,бЁШЁЧА2000ИіproposalНјааЗжРрКЭЕкЖўДЮБпПђаое§ЁЃ
змЕФРДЫЕЃЌFaster R-CNNЕФlossЗжСНДѓПщЃЌЕквЛДѓПщЪЧбЕСЗRPNЕФloss(АќКЌвЛИіSoftmaxLossКЭSmoothL1Loss)ЃЌЕкЖўДѓПщЪЧбЕСЗFast
R-CNNжаЗжРрЦїЕФloss(АќКЌвЛИіSoftmaxLossКЭSmoothL1Loss)ЃЌFaster
R-CNNЕФзмЕФlossКЏЪ§УшЪіШчЯТЃК
ШЛКѓЃЌЖдгкFaster R-CNNЕФбЕСЗЗНЪНгаШ§жжЃЌПЩвдБЛУшЪіШчЯТЃК
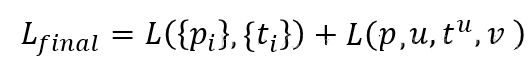
1) RPNКЭFast R-CNNНЛЬцбЕСЗЃЌетжжЗНЪНвВЪЧзїепВЩгУЕФЗНЪНЁЃ
2) НќЫЦСЊКЯRPNКЭFast R-CNNЕФбЕСЗЃЌдкбЕСЗЪБКіТдЕєСЫRoIБпПђаое§ЕФЮѓВюЃЌвВОЭЪЧЫЕжЛЖдanchorзіСЫБпПђаоЖЉЃЌетвВЪЧЮЊЪВУДНа"НќЫЦСЊКЯ"ЕФдвђЁЃ
3) СЊКЯRPNКЭFast R-CNNЕФбЕСЗЁЃ
ЖдгкзїепВЩгУЕФНЛЬцбЕСЗЕФЗНЪНЃЌВНжшШчЯТЃК
1) ЪЙгУдкImageNetЩЯдЄбЕСЗЕФФЃаЭГѕЪМЛЏЙВЯэОэЛ§ВуВЂбЕСЗRPNЁЃ
2) ЪЙгУЩЯвЛВНЕУЕНЕФRPNВЮЪ§ЩњГЩRoI proposalЁЃдйЪЙгУImageNetЩЯдЄбЕСЗЕФФЃаЭГѕЪМЛЏЙВЯэОэЛ§ВуЃЌбЕСЗFast
R-CNNВПЗж(ЗжРрЦїКЭRoIБпПђаоЖЉ)ЁЃ
3) НЋбЕСЗКѓЕФЙВЯэОэЛ§ВуВЮЪ§ЙЬЖЈЃЌЭЌЪБНЋFast R-CNNЕФВЮЪ§ЙЬЖЈЃЌбЕСЗRPNЁЃ(ДгетвЛВНПЊЪМЃЌЙВЯэОэЛ§ВуЕФВЮЪ§еце§БЛСНДѓПщЭјТчЙВЯэ)
4) ЭЌбљНЋЙВЯэОэЛ§ВуВЮЪ§ЙЬЖЈЃЌВЂНЋRPNЕФВЮЪ§ЙЬЖЈЃЌбЕСЗFast R-CNNВПЗжЁЃ
Faster R-CNNЕФВтЪдСїГЬКЭбЕСЗСїГЬЭІЯрЫЦЃЌУшЪіШчЯТЃК1) ЪзЯШЭЈЙ§RPNЩњГЩдМ20000Иіanchor(40ЁС60ЁС9)ЭЈЙ§RPNЁЃ
2) Жд20000ИіanchorНјааЕквЛДЮБпПђаое§ЃЌЕУЕНаоЖЉБпПђКѓЕФproposalЁЃ
3) ЖдГЌЙ§ЭМЯёБпНчЕФproposalЕФБпНјааclipЃЌЪЙЕУИУproposalВЛГЌЙ§ЭМЯёЗЖЮЇЁЃ
4) КіТдЕєГЄЛђепПэЬЋаЁЕФproposalЁЃ
5) НЋЫљгаproposalАДееЧАОАЗжЪ§ДгИпЕНЕЭХХађЃЌбЁШЁЧА6000ИіproposalЁЃ
6) ЪЙгУуажЕЮЊ0.7ЕФNMSЫуЗЈХХГ§ЕєжиЕўЕФproposalЁЃ
7) еыЖдЩЯвЛВНЪЃЯТЕФproposal,бЁШЁЧА300ИіproposalНјааЗжРрКЭЕкЖўДЮБпПђаое§ЁЃ
ЕНетРяЃЌFaster R-CNNОЭНщЩмЭъБЯСЫЁЃНгЯТРДЕНСЫMask R-CNNЃЌЮвУЧРДПДПДRoI
PoolingГіСЫЪВУДЮЪЬтЃК
ЮЪЬт1ЃКДгЪфШыЭМЩЯЕФRoIЕНЬиеїЭМЩЯЕФRoI featureЃЌRoI PoolingЪЧжБНгЭЈЙ§ЫФЩсЮхШыШЁећЕУЕНЕФНсЙћЁЃ
етвЛЕуПЩвддкДњТыжагЁжЄЃК

ПЩвдПДЕНжБНггУroundШЁЕФжЕЃЌетбљЛсДјРДЪВУДЛЕДІФиЃПОЭЪЧRoI PoolingЙ§КѓЕФЕУЕНЕФЪфГіПЩФмКЭдЭМЯёЩЯЕФRoIЖдВЛЩЯЃЌШчЯТЭМЫљЪОЃК

гвЭМжаРЖЩЋВПЗжБэЪОАќКЌСЫНЮГЕжїЬхЕФЕФаХЯЂЕФЗНИёЃЌRoI Pooling LayerЕФЫФЩсЮхШыШЁећВйзїЕМжТЦфНјааСЫЦЋвЦЁЃ
ЮЪЬт2ЃКдйНЋУПИіRoIЖдгІЕФЬиеїзЊЛЏЮЊЙЬЖЈДѓаЁЕФЮЌЖШЪБЃЌгжВЩгУСЫШЁећВйзїЁЃдкетРяБЪепОйР§НВНтвЛЯТRoI
PoolingЕФВйзїЃК
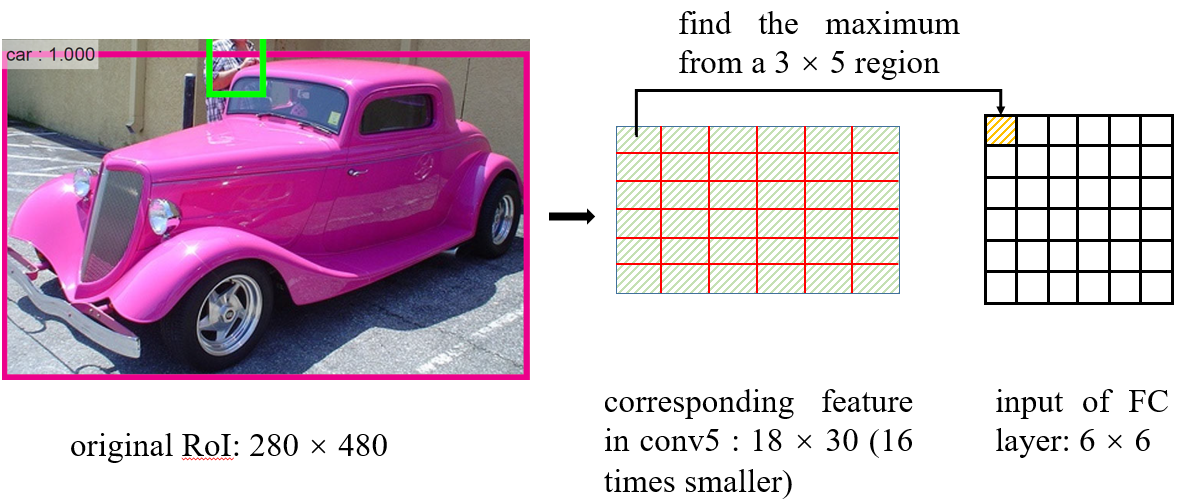
дкДгRoIЕУЕНЖдгІЕФЬиеїЭМЪБЃЌНјааСЫЮЪЬт1УшЪіЕФШЁећЃЌдкЕУЕНЬиеїЭМКѓЃЌШчКЮЕУЕНвЛИі6ЁС6ЕФШЋСЌНгВуЕФЪфШыФиЃПRoI
PoolingетбљзіЃКНЋRoIЖдгІЕФЬиеїЭМЗжГЩ6ЁС6ПщЃЌШЛКѓжБНгДгУППщжаевЕНзюДѓжЕЁЃдкЩЯЭМжаЕФР§згжаЃЌБШШчдЭМЩЯЕФЕФRoIДѓаЁЪЧ280ЁС480ЃЌЕУЕНЖдгІЕФЬиеїЭМЪЧ18ЁС30ЁЃНЋЬиеїЭМЗжГЩ6ПщЃЌУППщДѓаЁЪЧ3ЁС5ЃЌШЛКѓдкУПвЛПщжаЗжБ№бЁдёзюДѓжЕЗХШы6ЁС6ЕФЖдгІЧјгђжаЁЃдкНЋЬиеїЭМЗжПщЕФЪБКђЃЌгжгУЕНСЫШЁећЃЌетЕуЭЌбљПЩвддкДњТыжаЕУЕНзєжЄЃК

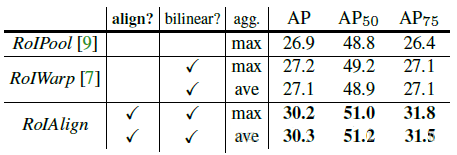
етжжШЁећВйзї(дкMask R-CNNжаБЛГЦЮЊquantization)ЖдRoIЗжРргАЯьВЛДѓЃЌПЩЪЧЖдж№ЯёЫиЕФдЄВтФПБъЪЧгаКІЕФЃЌвђЮЊЖдУПИіRoIШЁЕУЕФЬиеїВЂУЛгагыRoIЖдЦыЁЃвђДЫЃЌMask
R-CNNЖдRoI PoolingзіСЫИФНјВЂЬсГіСЫRoI AlignЁЃ
RoI AlignЕФжївЊДДаТЕуЪЧЃЌеыЖдЮЪЬт1ЃЌВЛдйНјааШЁећВйзїЁЃеыЖдЮЪЬт2ЃЌЪЙгУЫЋЯпадВхжЕРДИќОЋШЗЕиевЕНУПИіПщЖдгІЕФЬиеїЁЃзмЕФРДЫЕЃЌRoI
AlignЕФзїгУжївЊОЭЪЧЬоГ§СЫRoI PoolingЕФШЁећВйзїЃЌВЂЧвЪЙЕУЮЊУПИіRoIШЁЕУЕФЬиеїФмЙЛИќКУЕиЖдЦыдЭМЩЯЕФRoIЧјгђЁЃ
ЯТЭМВћЪіСЫMask R-CNNЕФMask branchЃК
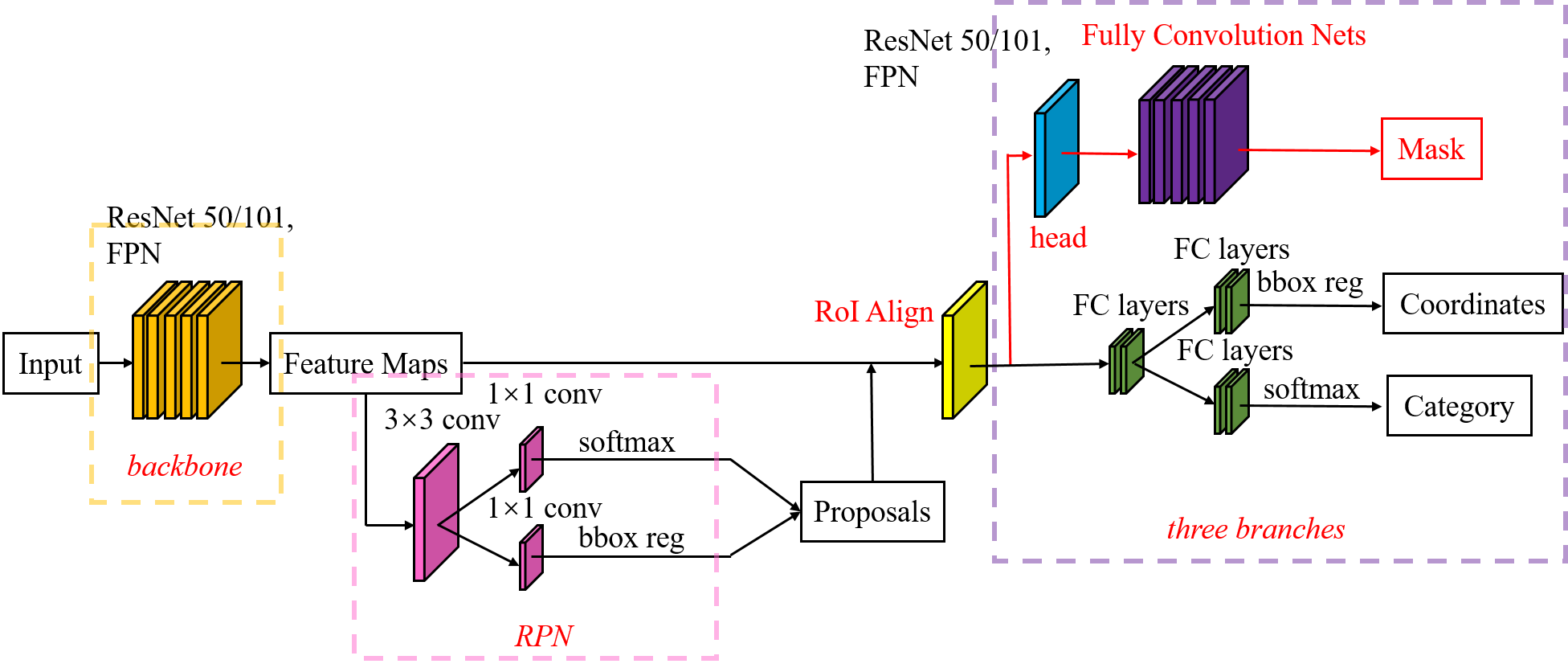
дкMask R-CNNжаЕФRoI AlignжЎКѓгавЛИі"head"ВПЗжЃЌжївЊзїгУЪЧНЋRoI
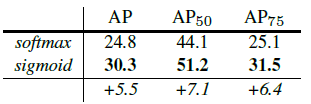
AlignЕФЪфГіЮЌЖШРЉДѓЃЌетбљдкдЄВтMaskЪБЛсИќМгОЋШЗЁЃдкMask BranchЕФбЕСЗЛЗНкЃЌзїепУЛгаВЩгУFCNЪНЕФSoftmaxLossЃЌЗДЖјЪЧЪфГіСЫKИіMaskдЄВтЭМ(ЮЊУПвЛИіРрЖМЪфГівЛеХ)ЃЌВЂВЩгУaverage
binary cross-entropy lossбЕСЗЃЌЕБШЛдкбЕСЗMask branchЕФЪБКђЃЌЪфГіЕФKИіЬиеїЭМжаЃЌвВжЛЪЧЖдгІground
truthРрБ№ЕФФЧвЛИіЬиеїЭМЖдMask lossгаЙБЯзЁЃ
Mask R-CNNЕФбЕСЗЫ№ЪЇКЏЪ§ПЩвдУшЪіЮЊЃК
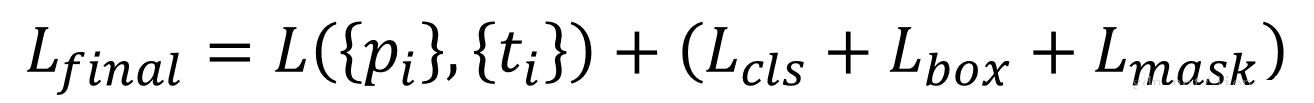
дкЩЯЪНжаЃЌLboxКЭLmaskЖМЪЧЖдpositive RoIВХЛсЦ№зїгУЕФЁЃ
дкMask R-CNNжаЃЌЯрНЯгкFaster R-CNNЛЙгааЉТдЮЂЕФЕїећЃЌБШШчpositive
RoIБЛЖЈвхГЩСЫгыGround truthЕФIoUДѓгк0.5ЕФ(Faster R-CNNжаЪЧ0.7)ЁЃЬЋЙ§гкЯИНкЕФЖЋЮїБОЦЊВЉЮФВЛдйзИЪіЃЌЯъЧщВЮМћMask
R-CNNжаЕФImplementation DetailsЁЃ
ЕНетРядйНЋMask R-CNNКЭFCISзіИіБШНЯЃЌЪзЯШСНепЕФЯрЭЌЕуЪЧОљМЬГаСЫFaster
R-CNNЕФRPNВПЗжЁЃВЛЭЌЕуЪЧЖдгкFCISЃЌдЄВтmaskКЭЗжРрЪЧЙВЯэЕФВЮЪ§ЁЃЖјMask R-CNNдђЪЧИїЭцИїЕФЃЌСНИіШЮЮёИїздгаИїздЕФПЩбЕСЗВЮЪ§ЁЃЖдгкетвЛЕуЃЌMask
R-CNNТлЮФРяЛЙзЈУХзїСЫБШНЯЃЌЯдЪОЖдгкдЄВтmaskКЭЗжРрШчЙћЪЙгУЙВЯэЕФЬиеїЭМЖдгкФГаЉжиЕўФПБъПЩФмЛсГіЯжЮЪЬтЁЃ

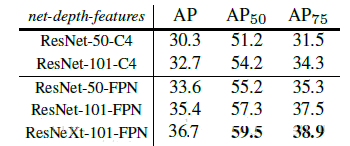
Mask R-CNNЕФЪЕбщШЁЕУСЫКмКУЕФаЇЙћЃЌДяЕНЩѕжСГЌЙ§СЫstate-of-the-artЕФЫЎЦНЁЃВЛЙ§бЕСЗДњМлвВЪЧЯрЕБДѓЕФЃЌашвЊ8ПщGPUСЊКЯбЕСЗЁЃ
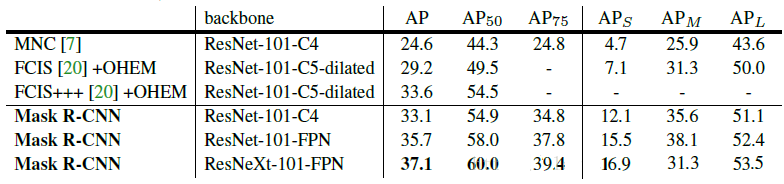
Mask R-CNNЕФЪЕбщЗЧГЃЯъЯИЃЌЛЙзіСЫКмЖрЖдБШЪЕбщЃЌБШШчЫЕИФЛЛЭјТчЩюЖШЃЌдкбЕСЗmask
branchЪБЕФЮѓВюжжРрЃЌНЋRoI AlignЭЌRoI PoolingКЭRoI WarpingНјааБШНЯЃЌИФБфдЄВтmaskЕФЗНЪН(FCNКЭШЋСЌНгВу)ЕШЃЌЯъЧщЧыВЮМћMask
R-CNNЕФЪЕбщВПЗжЁЃ

ЕНетРяMask R-CNNНщЩмОЭНгНќЮВЩљСЫЃЌБЪепЛЙЯыЫЕвЛаЉздМКЕФЫМПМгыИаЯыЃК
1) ПЩМЬГаЙЄзїЕФГфЗжЬхЯжЁЃДѓМвПДЕНMask R-CNNЕФНсЙЙЯрЕБИДдгЃЌЪЕМЪЩЯЪЧМЬГаСЫДѓСПжЎЧАЕФЙЄзїЁЃЪзЯШbounding
box regressionдк2014ФъЕФR-CNNжаОЭГіЯжЙ§ЁЃMask R-CNNЕФжївЊДДаТЕуRoI
AlignИФСМгкRoI PoolingЃЌЖјRoI PoolingЪЧдк2015ФъЕФFast R-CNNжаЬсГіЕФЁЃЖдгкRPNЕФгІгУЃЌИќЪЧжБНгМЬГаСЫ2016ФъЕФFaster
R-CNNЁЃжЕЕУвЛЬсЕФЪЧЃЌЩЯЪіЕФУПвЛЦЊЮФеТЃЌЖМЪЧЕпИВФПБъМьВтСьгђМЦЫуМмЙЙЕФНмГізїЦЗЁЃ
2)МЏГЩЕФЙЄзїЁЃЛЙЪЧФЧОфРЯЛАЃЌЕНСЫ2017-2018ФъЃЌЫцзХЩюЖШбЇЯАЕФИпЫйЗЂеЙЃЌЕЅШЮЮёФЃаЭвбОж№НЅБЛХзЦњЁЃШЁЖјДњжЎЕФЪЧИќМЏГЩЃЌИќзлКЯЃЌИќЧПДѓЕФЖрШЮЮёФЃаЭЁЃMask
R-CNNОЭЪЧЦфжаЕФДњБэЁЃ
3)в§СьГБСїЁЃдйДЮЯђКЮПУїКЭRoss GirshickжТОДЃЌЫћУЧЕФЪЕСІв§СьСЫФПБъМьВтСьгђЕФЗЂеЙЃЌвђДЫЮоТлЫћУЧдкФФЃЌЮоТлЪЧдкЮЂШэЛЙЪЧFaceBookЃЌЫћУЧЕФideaКЭзїЦЗЖМБЛЗЧГЃЖрЕФШЫгІгУЛђепМЬГаЁЃ
|









