| БрМЭЦМі: |
БОЮФРДздгкcnblogsЃЌЮФеТжївЊНщЩмСЫMask-R-CNNСїГЬЁЂГщЯѓМмЙЙвдМАНсЙЙЕШЯрЙиФкШнЁЃ |
|
вЛЁЂMask-RCNNСїГЬ
Mask R-CNNЪЧвЛИіЪЕР§ЗжИюЃЈInstance segmentationЃЉЫуЗЈЃЌЭЈЙ§діМгВЛЭЌЕФЗжжЇЃЌПЩвдЭъГЩФПБъЗжРрЁЂФПБъМьВтЁЂгявхЗжИюЁЂЪЕР§ЗжИюЁЂШЫЬхзЫЪЦЪЖБ№ЕШЖржжШЮЮёЃЌСщЛюЖјЧПДѓЁЃ

Mask R-CNNНјааФПБъМьВтгыЪЕР§ЗжИю

Mask R-CNNНјааШЫЬхзЫЬЌЪЖБ№
ЦфГщЯѓМмЙЙШчЯТЃК
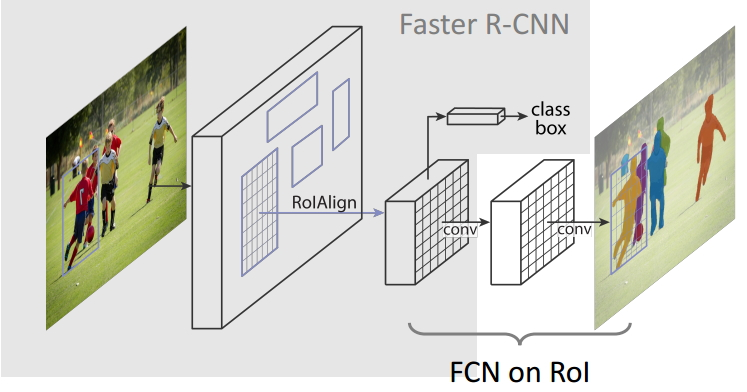
ЪзЯШЃЌЪфШывЛЗљФуЯыДІРэЕФЭМЦЌЃЌШЛКѓНјааЖдгІЕФдЄДІРэВйзїЃЌЛђепдЄДІРэКѓЕФЭМЦЌЃЛ
ШЛКѓЃЌНЋЦфЪфШыЕНвЛИідЄбЕСЗКУЕФЩёОЭјТчжаЃЈResNeXtЕШЃЉЛёЕУЖдгІЕФfeature mapЃЛ
НгзХЃЌЖдетИіfeature mapжаЕФУПвЛЕуЩшЖЈдЄЖЈИіЕФROIЃЌДгЖјЛёЕУЖрИіКђбЁROIЃЛ
НгзХЃЌНЋетаЉКђбЁЕФROIЫЭШыRPNЭјТчНјааЖўжЕЗжРрЃЈЧАОАЛђБГОАЃЉКЭBBЛиЙщЃЌЙ§ТЫЕєвЛВПЗжКђбЁЕФROIЃЈНижЙЕНФПЧАЃЌMaskКЭFasterЭъШЋЯрЭЌЃЌЦфЪЕR-FCNжЎРрЕФдкетжЎЧАвВУЛгаЪВУДВЛЭЌЃЉЃЛ
НгзХЃЌЖдетаЉЪЃЯТЕФROIНјааROIAlignВйзїЃЈМДЯШНЋдЭМКЭfeature mapЕФpixelЖдгІЦ№РДЃЌШЛКѓНЋfeature
mapКЭЙЬЖЈЕФfeatureЖдгІЦ№РДЃЉЃЈROIAlignЮЊБОЮФДДаТЕу1ЃЌБШROIPoolingгаГЄзуНјВНЃЉЃЛ
зюКѓЃЌЖдетаЉROIНјааЗжРрЃЈNРрБ№ЗжРрЃЉЁЂBBЛиЙщКЭMASKЩњГЩЃЈдкУПвЛИіROIРяУцНјааFCNВйзїЃЉЃЈв§ШыFCNЩњГЩMaskЮЊБОЮФДДаТЕу2ЃЌЪЙЕУБОЮФНсЙЙПЩвдНјааЗжИюаЭШЮЮёЃЉЁЃ
ЁОзЂЁПгаЙиMASKВПЗжЃЌЛЙгавЛДІШнвзКіЪгЕФДДаТЕу3ЃКЫ№ЪЇКЏЪ§ЕФМЦЫуЃЌзїепЗХЦњСЫИќЙуЗКЕФsoftmaxЃЌзЊЖјЪЙгУСЫsigmoidЃЌБмУтСЫЭЌРрОКељЃЌИќЖрЕФОРњЗХдкгХЛЏmaskЯёЫиЩЯЃЌетвЛЕуЮвУЧЯТвЛаЁНкЛсЬсЕНЁЃ
ЛиЕНЖЅВП
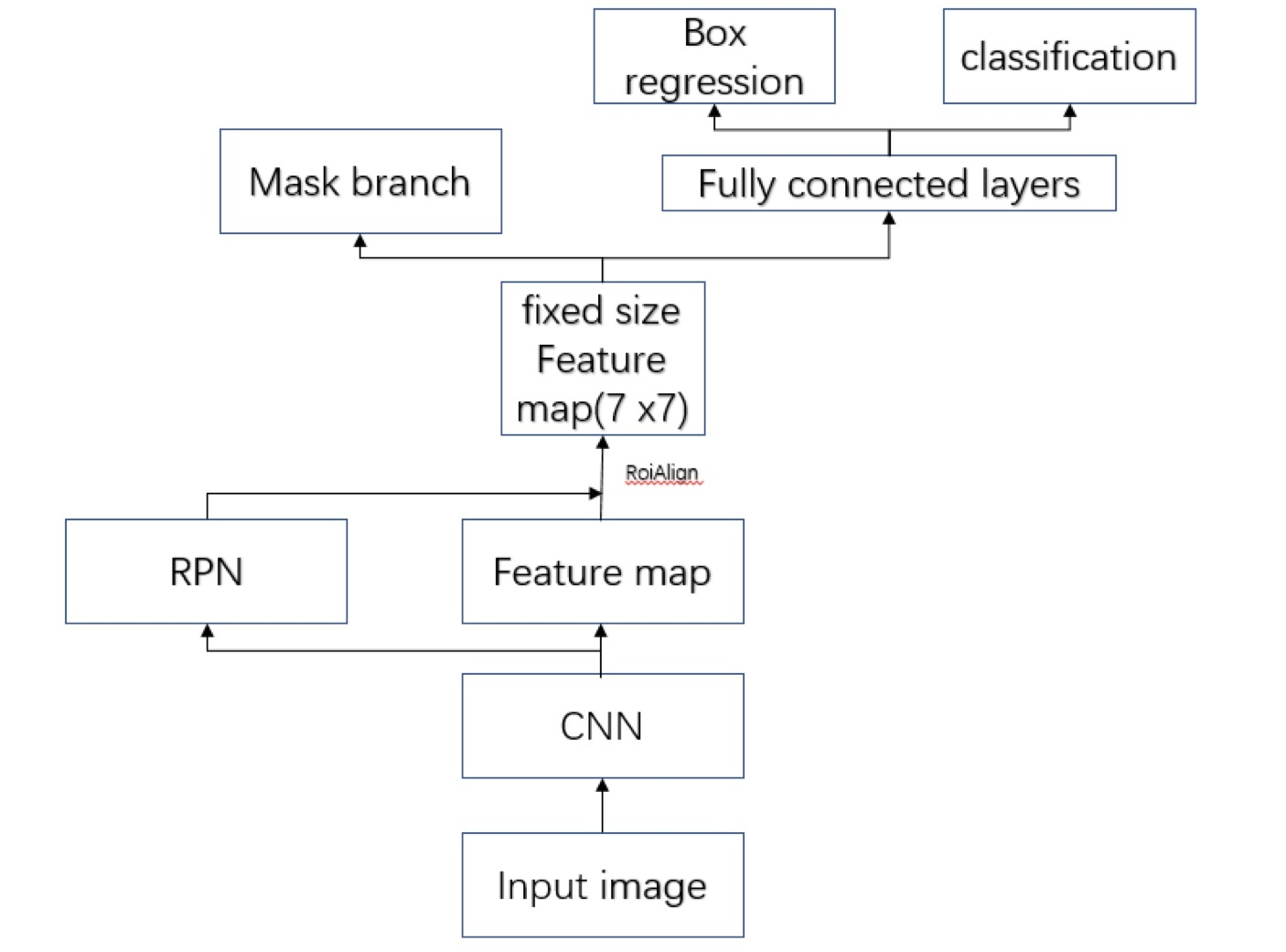
ЖўЁЂMask-RCNNНсЙЙ
ROIPoolingЕФЮЪЬт
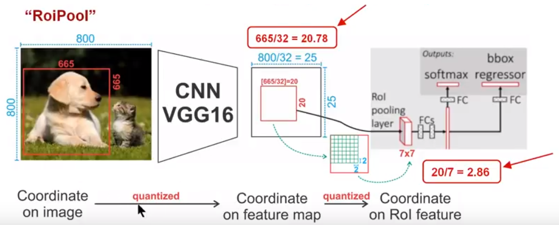
RoiPoolЙ§ГЬ
МйЖЈЮвУЧЪфШыЕФЪЧвЛеХ800x800ЕФЭМЯёЃЌдкЭМЯёжагаСНИіФПБъЃЈУЈКЭЙЗЃЉЃЌЙЗЕФBBДѓаЁЮЊ665x665ЃЌОЙ§VGG16ЭјТчКѓЃЌЛёЕУЕФfeature
map ЛсБШдЭМЫѕаЁвЛЖЈЕФБШР§ЃЌетКЭPoolingВуЕФИіЪ§КЭДѓаЁгаЙиЃК
дкИУVGG16жаЃЌЮвУЧЪЙгУСЫ5ИіГиЛЏВйзїЃЌУПИіГиЛЏВйзїЖМЪЧ2PoolingЃЌвђДЫЮвУЧзюжеЛёЕУfeature
mapЕФДѓаЁЮЊ800/32 x 800/32 = 25x25ЃЈЪЧећЪ§ЃЉЃЌЕЋЪЧНЋЙЗЕФBBЖдгІЕНfeature
mapЩЯУцЃЌЮвУЧЕУЕНЕФНсЙћЪЧ665/32 x 665/32 = 20.78 x 20.78ЃЌНсЙћЪЧИЁЕуЪ§ЃЌКЌгааЁЪ§ЃЌШЁећБфЮЊ20
x 20ЃЌдкетРяв§ШыСЫЕквЛДЮЕФСПЛЏЮѓВюЃЛ
ШЛКѓЮвУЧашвЊНЋ20 x 20ЕФROIгГЩфГЩ7 x 7ЕФROI featureЃЌЦфНсЙћЪЧ 20 /7
x 20/7 = 2.86 x 2.86ЃЌЭЌбљЪЧИЁЕуЪ§ЃЌКЌгааЁЪ§ЕуЃЌЭЌбљЕФШЁећЃЌдкетРяв§ШыСЫЕкЖўДЮСПЛЏЮѓВюЁЃ
етРяв§ШыЕФЮѓВюЛсЕМжТЭМЯёжаЕФЯёЫиКЭЬиеїжаЕФЯёЫиЕФЦЋВюЃЌМДНЋfeatureПеМфЕФROIЖдгІЕНдЭМЩЯУцЛсГіЯжКмДѓЕФЦЋВюЁЃдвђШчЯТЃКБШШчгУЮвУЧЕкЖўДЮв§ШыЕФЮѓВюРДЗжЮіЃЌБОРДЪЧ2,86ЃЌЮвУЧНЋЦфСПЛЏЮЊ2ЃЌетЦкМфв§ШыСЫ0.86ЕФfeatureПеМфЮѓВюЃЌЮвУЧЕФfeatureПеМфКЭЭМЯёПеМфЪЧгаБШР§ЙиЯЕЕФЃЌдкетРяЪЧ1:32ЃЌФЧУДЖдгІЕНдЭМЩЯУцЕФВюОрОЭЪЧ0.86
x 32 = 27.52ЃЈетНіНіПМТЧСЫЕкЖўДЮЕФСПЛЏЮѓВюЃЉЁЃ
ROIAlign
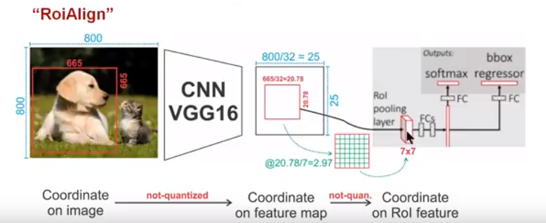
ROIAlignЙ§ГЬ
ЮЊСЫЕУЕНЮЊСЫЕУЕНЙЬЖЈДѓаЁЃЈ7X7ЃЉЕФfeature mapЃЌROIAlignММЪѕВЂУЛгаЪЙгУСПЛЏВйзїЃЌШЁЖјДњжЎЕФЪЙгУСЫЫЋЯпадВхжЕЃЌЫќГфЗжЕФРћгУСЫдЭМжаащФтЕуЃЈБШШч20.56етИіИЁЕуЪ§ЃЌЯёЫиЮЛжУЖМЪЧећЪ§жЕЃЌУЛгаИЁЕужЕЃЉЫФжмЕФЫФИіецЪЕДцдкЕФЯёЫижЕРДЙВЭЌОіЖЈФПБъЭМжаЕФвЛИіЯёЫижЕЃЌМДПЩвдНЋ20.56етИіащФтЕФЮЛжУЕуЖдгІЕФЯёЫижЕЙРМЦГіРДЁЃ
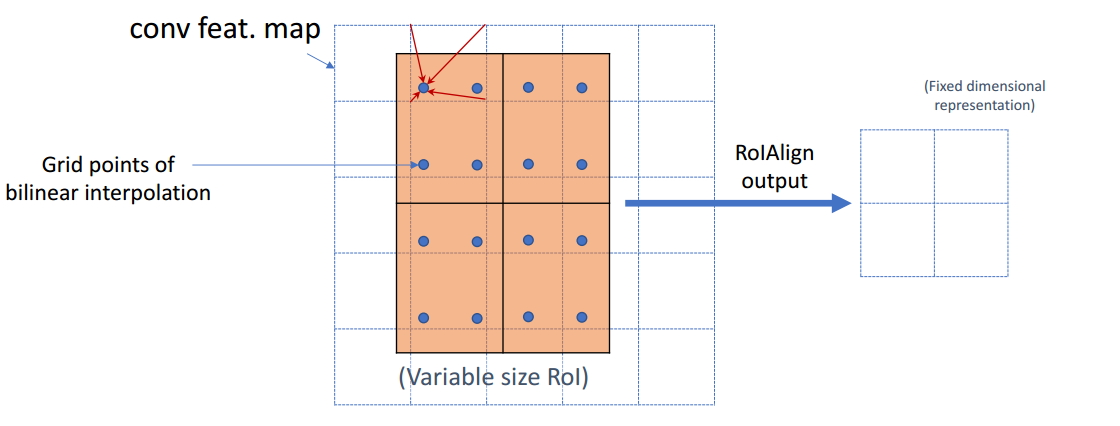
РЖЩЋЕФащЯпПђБэЪООэЛ§КѓЛёЕУЕФfeature mapЃЌКкЩЋЪЕЯпПђБэЪОROI featureЃЌзюКѓашвЊЪфГіЕФДѓаЁЪЧ2x2ЃЌФЧУДЮвУЧОЭРћгУЫЋЯпадВхжЕРДЙРМЦетаЉРЖЕуЃЈащФтзјБъЕуЃЌгжГЦЫЋЯпадВхжЕЕФЭјИёЕуЃЉДІЫљЖдгІЕФЯёЫижЕЃЌзюКѓЕУЕНЯргІЕФЪфГіЁЃ
ШЛКѓдкУПвЛИіщйКьЩЋЕФЧјгђРяУцНјааmax poolingЛђепaverage poolingВйзїЃЌЛёЕУзюже2x2ЕФЪфГіНсЙћЁЃЮвУЧЕФећИіЙ§ГЬжаУЛгагУЕНСПЛЏВйзїЃЌУЛгав§ШыЮѓВюЃЌМДдЭМжаЕФЯёЫиКЭfeature
mapжаЕФЯёЫиЪЧЭъШЋЖдЦыЕФЃЌУЛгаЦЋВюЃЌетВЛНіЛсЬсИпМьВтЕФОЋЖШЃЌЭЌЪБвВЛсгаРћгкЪЕР§ЗжИюЁЃ
ROIДІРэМмЙЙ
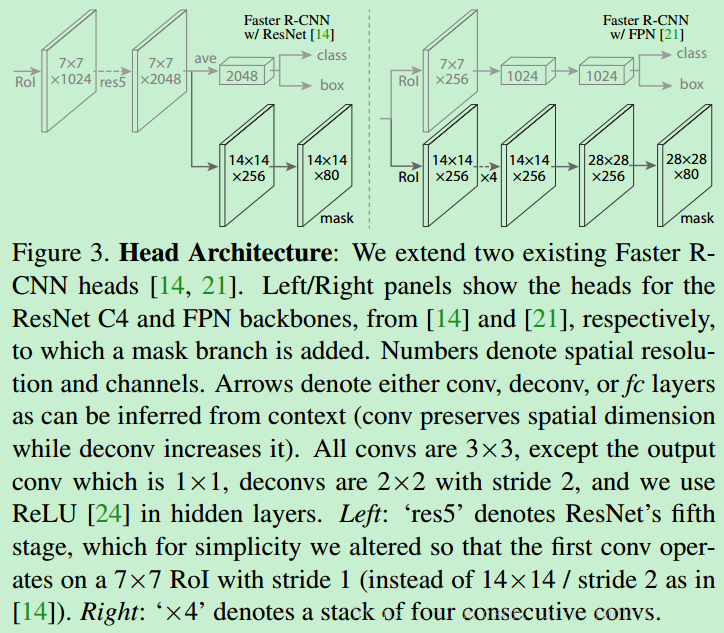
"""
ЮЊСЫжЄУїЮвУЧЗНЗЈЕФЭЈгУадЃЌЮвУЧЙЙдьСЫЖржжВЛЭЌНсЙЙЕФMask R-CNNЁЃЯъЯИЕФЫЕЃЌЮвУЧЪЙгУВЛЭЌЕФЃК
ЃЈiЃЉгУгкећИіЭМЯёЩЯЕФЬиеїЬсШЁЕФОэЛ§жїИЩМмЙЙЃЛ
ЃЈiiЃЉгУгкБпПђЪЖБ№ЃЈЗжРрКЭЛиЙщЃЉКЭбкФЃдЄВтЕФЩЯВуЭјТчЃЌЗжБ№гІгУгкУПИіRoIЁЃ
ЮвУЧЪЙгУЪѕгяЁАЭјТчЩюВуЬиеїЁБРДУќУћЯТВуМмЙЙЁЃЮвУЧЦРЙРСЫЩюЖШЮЊ50Лђ101ВуЕФResNet [14]КЭResNeXt
[34] ЭјТчЁЃЪЙгУResNet [14]ЕФFaster R-CNNДгЕкЫФМЖЕФзюжеОэЛ§ВуЬсШЁЬиеїЃЌЮвУЧГЦжЎЮЊC4ЁЃР§ШчЃЌЪЙгУResNet-50ЕФжїИЩМмЙЙгЩResNet-50-C4БэЪОЁЃетЪЧ[14,7,16,30]жаГЃгУЕФбЁдёЁЃ
ЮвУЧвВЬНЫїСЫгЩLi[21]ЕШШЫзюНќЬсГіЕФСэвЛжжИќгааЇжїИЩМмЙЙЃЌГЦЮЊЬиеїН№зжЫўЭјТчЃЈFPNЃЉЁЃFPNЪЙгУОпгаКсЯђСЌНгЃЈlateral
connections ЃЉЕФздЖЅЯђЯТМмЙЙЃЌДгЕЅвЛЙцФЃЕФЪфШыЙЙНЈЭјТчЙІФмН№зжЫўЁЃЪЙгУFPNЕФFaster
R-CNNИљОнЦфГпЖШЬсШЁВЛЭЌМЖБ№ЕФН№зжЫўЕФRoIЬиеїЃЌВЛЙ§ЦфЫћВПЗжКЭЦНГЃЕФResNetРрЫЦЁЃЪЙгУResNet-FPNжїИЩМмЙЙЕФMask
R-CNNНјааЬиеїЬсШЁЃЌПЩвддкОЋЖШКЭЫйЖШЗНУцЛёЕУМЋДѓЕФЬсЩ§ЁЃгаЙиFPNЕФИќЖрЯИНкЃЌЖСепПЩвдВЮПМ[21]ЁЃ
ЖдгкЩЯВуЭјТчЃЌЮвУЧЛљБОзёбСЫвдЧАТлЮФжаЬсГіЕФМмЙЙЃЌЮвУЧЬэМгСЫвЛИіШЋОэЛ§ЕФбкФЃдЄВтЗжжЇЁЃОпЬхРДЫЕЃЌЮвУЧРЉеЙСЫResNet
[14]КЭFPN[21]жаЬсГіЕФFaster R-CNNЕФЩЯВуЭјТчЁЃЯъЧщМћЯТЭМЃЈЭМ3ЃЉЫљЪОЃКЃЈЩЯВуМмЙЙЃКЮвУЧРЉеЙСЫСНжжЯжгаЕФFaster
R-CNNЩЯВуМмЙЙ[14,21]ЃЌВЂЗжБ№ЬэМгСЫвЛИібкФЃЗжжЇЁЃзѓ/гвУцАхЗжБ№ЯдЪОСЫResNet C4КЭFPNжїИЩЕФЩЯВуМмЙЙЁЃЭМжаЪ§зжБэЪОЭЈЕРЪ§КЭЗжБцТЪЃЌМ§ЭЗБэЪООэЛ§ЁЂЗДОэЛ§КЭШЋСЌНгВуЃЈПЩвдЭЈЙ§ЩЯЯТЮФЭЦЖЯЃЌОэЛ§МѕаЁЮЌЖШЃЌЗДОэЛ§діМгЮЌЖШЁЃЃЉЫљгаЕФОэЛ§ЖМЪЧ3ЁС3ЕФЃЌГ§СЫЪфГіВуЪЧ1ЁС1ЁЃЗДОэЛ§ЪЧ2ЁС2ЃЌЦфВННјЮЊ2ЃЌЮвУЧдквўВиВужаЪЙгУReLU[24]ЁЃдкзѓЭМжаЃЌЁАres5ЁББэЪОResNetЕФЕкЮхМЖЃЌМђЕЅЦ№МћЃЌЮвУЧаоИФСЫЕквЛИіОэЛ§ВйзїЃЌЪЙгУ7ЁС7ЃЌВНГЄЮЊ1ЕФRoIДњЬц14ЁС14ЃЌВНГЄЮЊ2ЕФRoI[14]ЁЃгвЭМжаЕФЁАЁС4
ЁББэЪОЖбЕўЕФ4ИіСЌајЕФОэЛ§ЁЃЃЉResNet-C4жїИЩЕФЩЯВуЭјТчАќРЈResNetЕФЕк5НзЖЮЃЈМД9ВуЕФЁЏres5ЁЏ[14]ЃЉЃЌетЪЧМЦЫуУмМЏаЭЕФЁЃЕЋЖдгкFPNЃЌЦфжїИЩвбОАќКЌСЫres5ЃЌвђДЫПЩвдЪЙЩЯВуЭјТчАќКЌИќЩйЕФОэЛ§КЫЖјБфЕФИќМгИпаЇЁЃ
"""
жиЕудкгкЃКзїепАбИїжжЭјТчзїЮЊbackboneНјааЖдБШЃЌЗЂЯжЪЙгУResNet-FPNзїЮЊЬиеїЬсШЁЕФbackboneОпгаИќИпЕФОЋЖШКЭИќПьЕФдЫааЫйЖШЃЌЫљвдЪЕМЪЙЄзїЪБДѓЖМВЩгУгвЭМЕФЭъШЋВЂааЕФmask/ЗжРрЛиЙщ
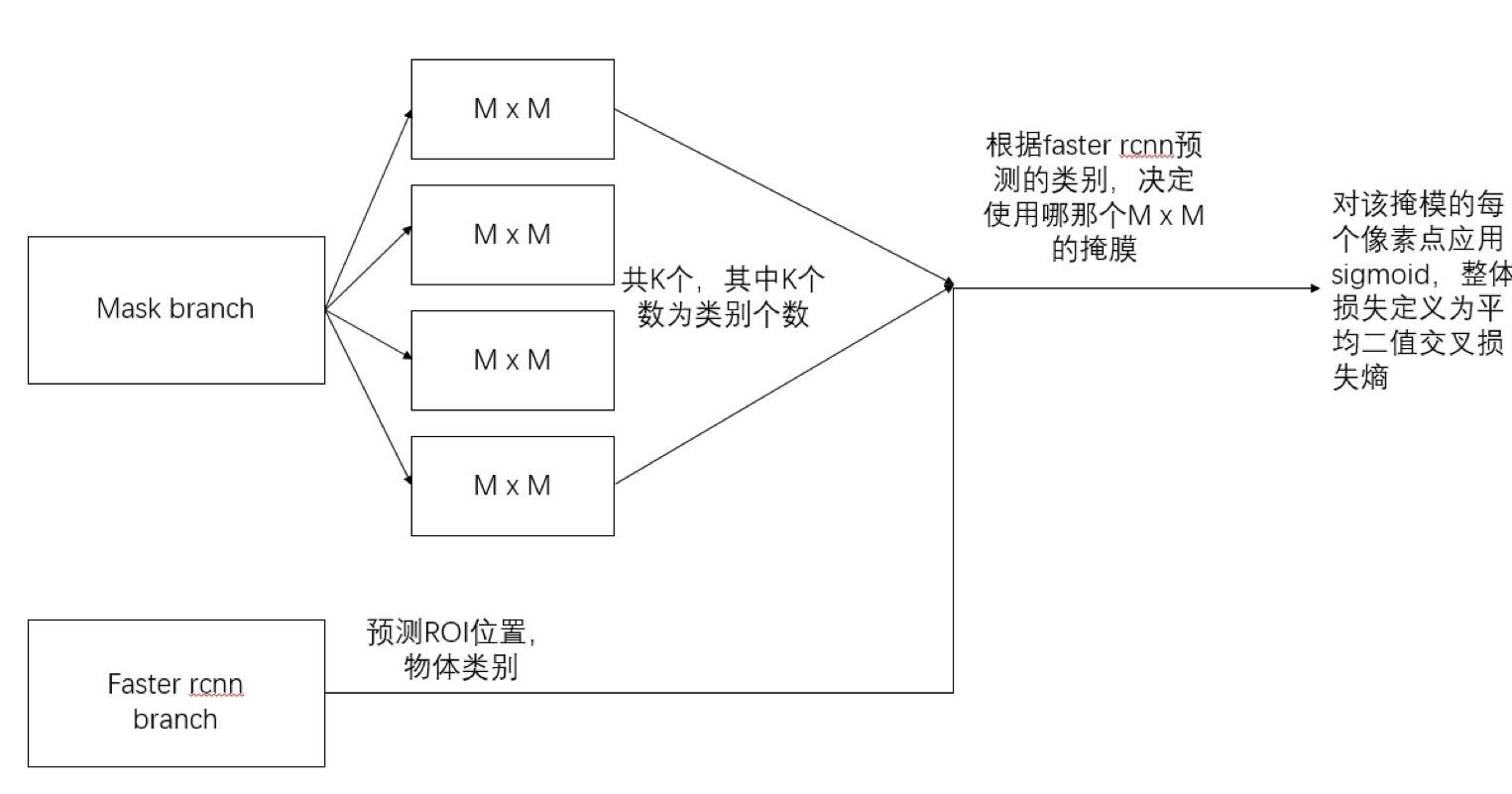
maskЗжжЇеыЖдУПИіRoIВњЩњвЛИіK*m*mЕФЪфГіЃЌМДKИіЗжБцТЪЮЊm*mЕФЖўжЕЕФбкФЄЃЌKЮЊЗжРрЮяЬхЕФжжРрЪ§ФПЁЃвРОндЄВтРрБ№ЗжжЇдЄВтЕФЪфГіЃЌЮвУЧНіНЋЕкiИіРрБ№ЕФЪфГіЕЧМЧЃЌгУгкМЦЫу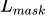
Mask R-CNNВЩгУСЫКЭFaster R-CNNЯрЭЌЕФСНВНзпВпТдЃЌМДЯШЪЙгУRPNЬсШЁКђбЁЧјгђЃЌЙигкRPNЕФЯъЯИНщЩмЃЌПЩвдВЮПМFaster
R-CNNвЛЮФЁЃВЛЭЌгкFaster R-CNNжаЪЙгУЗжРрКЭЛиЙщЕФЖрШЮЮёЛиЙщЃЌMask R-CNNдкЦфЛљДЁЩЯВЂааЬэМгСЫвЛИігУгкгявхЗжИюЕФMaskЫ№ЪЇКЏЪ§ЃЌЫљвдMask
R-CNNЕФЫ№ЪЇКЏЪ§ПЩвдБэЪОЮЊЯТЪНЁЃ
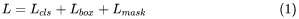
ЩЯЪНжаЃЌ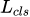 БэЪОbounding boxЕФЗжРрЫ№ЪЇжЕЃЌ
БэЪОbounding boxЕФЗжРрЫ№ЪЇжЕЃЌ 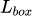 БэЪОbounding boxЕФЛиЙщЫ№ЪЇжЕЃЌ
БэЪОmaskВПЗжЕФЫ№ЪЇжЕЁЃ
БэЪОbounding boxЕФЛиЙщЫ№ЪЇжЕЃЌ
БэЪОmaskВПЗжЕФЫ№ЪЇжЕЁЃ
ЖдгкдЄВтЕФЖўжЕбкФЄЪфГіЃЌЮвУЧЖдУПИіЯёЫиЕугІгУsigmoidКЏЪ§ЃЌећЬхЫ№ЪЇЖЈвхЮЊЦНОљЖўжЕНЛВцЫ№ЪЇьиЁЃв§ШыдЄВтKИіЪфГіЕФЛњжЦЃЌдЪаэУПИіРрЖМЩњГЩЖРСЂЕФбкФЄЃЌБмУтРрМфОКељЁЃетбљзіНтёюСЫбкФЄКЭжжРрдЄВтЁЃВЛЯёFCNЕФзіЗЈЃЌдкУПИіЯёЫиЕуЩЯгІгУsoftmaxКЏЪ§ЃЌећЬхВЩгУЕФЖрШЮЮёНЛВцьиЃЌетбљЛсЕМжТРрМфОКељЃЌзюжеЕМжТЗжИюаЇЙћВюЁЃ
бЕСЗВЮЪ§

|









