| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТжївЊНщЩмСЫMask
RCNNећЬхЪЕЯжПђМмЁЂFPNКЭRPNЕФЖдгІЙиЯЕвдМАЗжРрКЭbboxЛиЙщЕШЯрЙиФкШнЁЃ |
|
ВЮПМзЪСЯ
вЊГфЗжРэНтmaskRCNNНЈвщЯШЭЈЖСRCNЕФЯЕСаТлЮФСЫНтжїЬтТіТч, ШЛКѓВЮПМДњТыЪЕЯжСЫНтЯИНкЁЃ
RCNN
FAST-RCNN
FASTER-RCNN
FPN
MASK-RCNN
БОЮФФкШнЛљгкmatterportЕФЪЕЯжАцБОЃЌетРягавЛЗнЙйЗНВЉПЭНщЩмСЫвЛаЉЪЕЯжЯИНкЃЌЭЦМідФЖСЁЃ
ећЬхМмЙЙ
ЯТЭМЮЊmask-rcnnЕФећЬхЪЕЯжПђМм
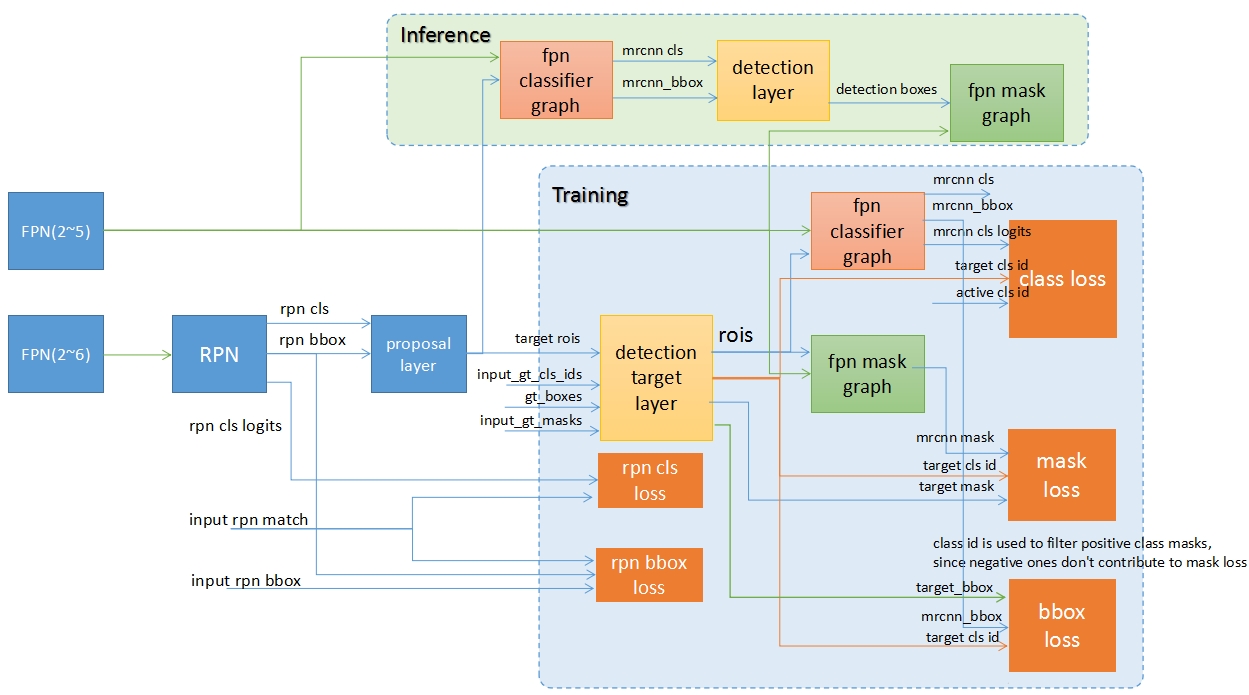
бЕСЗКЭЭЦЕМЙ§ГЬЕФЧјБ№
ДгЭМжаПЩвдПДГіРДЃЌMASK-RCNNЕФбЕСЗКЭЭЦЕМЙ§ГЬТдгаВЛЭЌЁЃ
1ЃЉ бЕСЗЕФЪБКђЃЌЗжРрЦїЪЙгУЕФregion proposalЪЧИљОнground truthКЭrpnЕФНсЙћМЦЫуГіРДЕФЃЌЖјЭЦЕМЕФЪБКђЃЌжБНгЪЙгУRPNЕФНсЙћЁЃ
2ЃЉ бЕСЗЕФЪБКђЗжРрЦїКЭmaskЩњГЩЦїЪЧВЂааЕФЃЌЭЦЕМЕФЪБКђЪЧДЎааЕФЃЌЯШНјааЗжРрКЭbboxЕФЛиЙщЃЌШЛКѓЪЙгУЦфНсЙћНјааmaskЕФЩњГЩЁЃ
3ЃЉзЂвтЫфШЛСїГЬВЛЭЌЃЌЕЋЪЧВЛвЛбљЕФВПЗж(detection target layerКЭdetection
layer)ЪЧЙЬЖЈЕФСїГЬЃЌУЛгаВЮЪ§КЭЁЎПЩбЇЯАЁЏЕФВПЗжЁЃЦфЫћжївЊЕФашвЊбЕСЗбЇЯАЕФЭјТчЪЧвЛбљЕФЁЃ
ЖрШЮЮёбЕСЗ
BackboneвЛАужБНгЪЙгУбЕСЗКУЕФФЃаЭЃЌБШШчResNetЃЌVGGNetЕШЁЃRPNЭјТчЁЂРрБ№ХаЖЈКЭBBoxЛиЙщЭјТчЃЌMaskЩњГЩЭјТчЃЌИїздЖМгаЖдгІЕФlossЃЌМИИіФЃПщПЩвдЭЌЪБбЇЯАЃЌЖјЧвОнЫЕЭЌЪБбЕСЗаЇЙћИќКУЁЃ
FPNКЭRPNЕФЖдгІЙиЯЕ
ОпЬхРДЫЕЃЌFPNЕФИїВуfeatureЖМгІгУЕНЭЌвЛИіRPN, ЕЋЪЧЖдгІВЛЭЌЕФanchor boxЕФДѓаЁЁЃетРяКЭanchor
boxДѓаЁЕФЖдгІЙиЯЕЪЧвўКЌЕФЁЃБШШчЖдгк512*512ЕФЪфШыЭМЦЌЃЌШчЙћfeatureЪЧ128*128ЕФЃЌФЧУДЖдгІЕФanchor
boxЪЧ8*8ЁЃВЛЙ§етИіЖдгІЙиЯЕЪЧПЩХфжУЕФ(RPN_ANCHOR_SCALES, BACKBONE_STRIDES)ЃЌвВПЩвдгаВЛвЛбљЕФЖдгІЙиЯЕЃЌШчЙћаоИФЕФашвЊзЂвтreception
fieldЃЌвдМАдкЙЙдьground truth bboxЕФЪБКђвЊЖдгІКУЁЃ
FPNдкЗжРр/BBOXЛиЙщ/maskЩњГЩЪЧШчКЮЪЙгУ
ИљОнRPNЩњГЩЕФBBOXЕФДѓаЁЃЌЖдгІЕНВЛЭЌЕФfeatureВуЁЃmatterportЕФДњТыетРяЪЧаДЫРЕФЁЃЖдгк224*224ЕФROIЃЌЖдгІЕНFPNЕФP4.
ДЫДІгаИівЩЮЪЃЌЖдгкВЛЭЌЕФЪфШыЭМЦЌДѓаЁЃЌЪЧВЛЪЧгІИУгаВЛЭЌЕФЖдгІЙиЯЕЁЃ
FPNЕФИїВуfeatureЦфЪЕУЛгаКЯЦ№РДвЛЦ№гУЃЌRPNгУВЛЭЌВуЕФfeatureЖдгІВЛЭЌЕФanchor
boxЕФДѓаЁЃЌРрБ№ХаЖЈКЭbboxЛиЙщЃЌвдМАmaskЩњГЩЖМЪЧбЁЖЈФГвЛВуfeatureзїЮЊЭјТчЕФЪфШыЁЃ
FPN
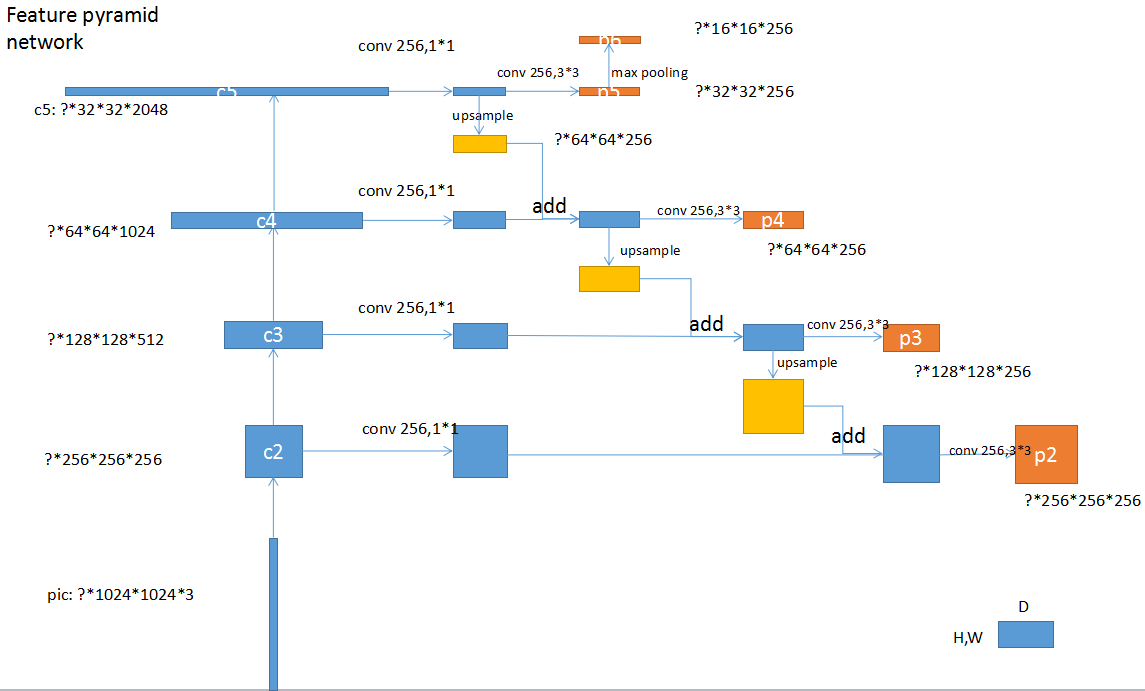
FPNЩЯВуupsampleжЎКѓКЭЯТВужБНгЯрМгЃЌchannelЪ§ВЛБфЁЃетРяКЭUnetВЛвЛбљЃЌUnetгУСЌНг(concatenation)ЕФЗНЪНКЯВЂЩЯЯТВуfeature,ЕУЕНЕФchannelЪ§ЛсБфЖрЁЃ
RPN
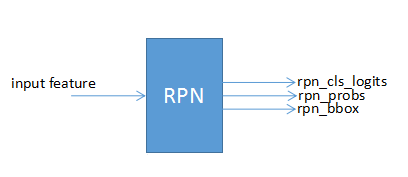
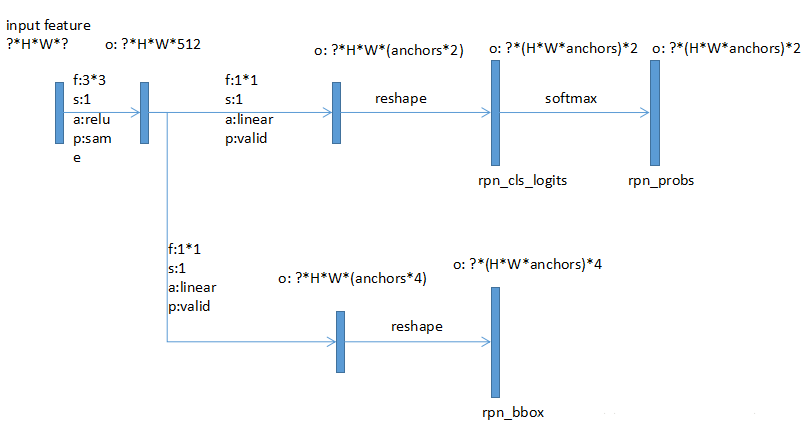
ТлЮФжаRPNЪЧдкfeaturelayerЩЯЪЙгУ3*3ЕФЧјгђзїЮЊЪфШыЃЌдкЪЕЯжЕФЪБКђОЭЪЧМђЕЅЕФ3*3ОэЛ§ЃЌУПИіЮЛжУЖМЩњГЩНсЙћЁЃ
RPNгыProposal LayerЕФЖдгІЙиЯЕ
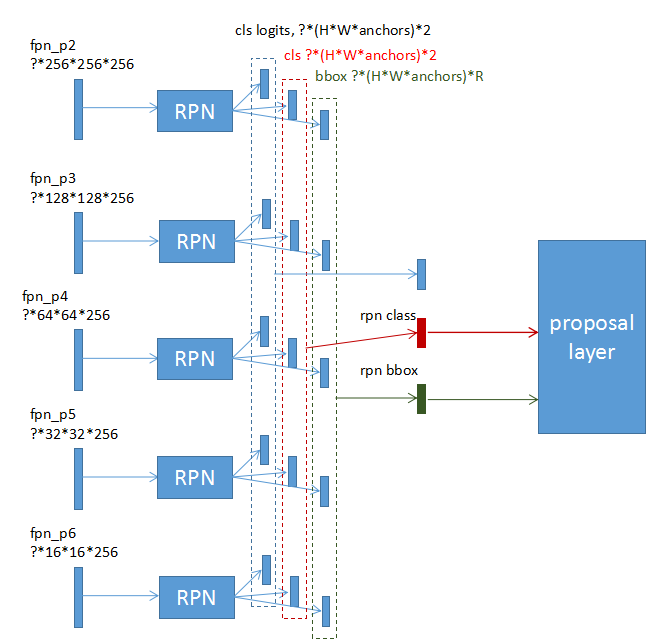
FPNЕФВЛЭЌfeatureВуЖМЪфШыЕНrpnЭјТчЃЌЩњГЩвЛзщRPNНсЙћЃЌШЛКѓНЋетаЉНсЙћКЯВЂЦ№РДЃЌЪфШыЕНProposalLayerЁЃашвЊзЂвтЖдгІЙиЯЕЃЌвђЮЊФГИіRPNЕФНсЙћЖдгІФФИіBox
ScaleЃЌФФИіBox ratioЃЌвдМАЖдгІдЪМЭМЦЌФФИіPositionЃЌЖМЪЧЙЬЖЈЕФЃЌКѓајМЦЫуLossЕФЪБКђашвЊКЭGround
TruthЖдгІЦ№РДЁЃдкProposalLayerжЎКѓетИіЖдгІЙиЯЕОЭВЛашвЊСЫЃЌвђЮЊBboxБОЩэМЧТМСЫЮЛжУЁЃ
ЗжРрКЭbboxЛиЙщ
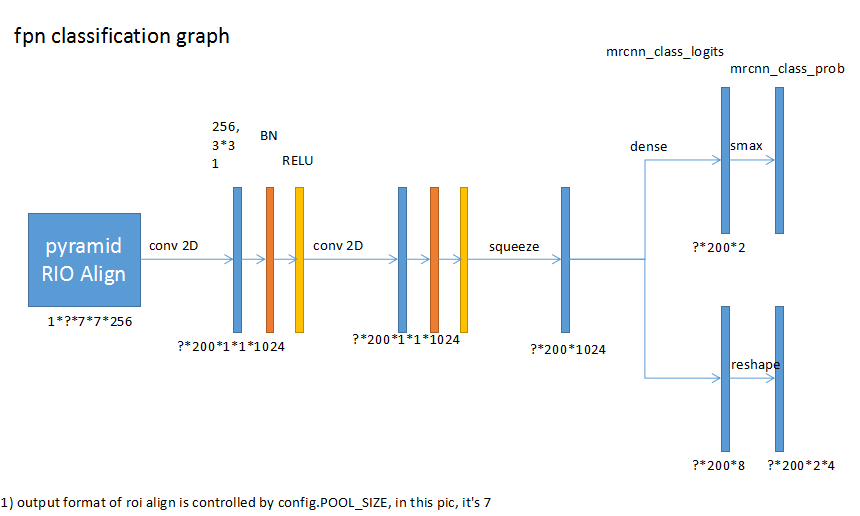
ЪфГіЗжРрНсЙћЃЈЩЯВПЃЉКЭbboxЛиЙщЃЈЯТВПЃЉЁЃУПИіРрБ№гавЛИіНсЙћЃЈВЛАќРЈБГОАЃЉЃЌЩЯЭМжаРрБ№ЮЊ2ЁЃ
MaskЩњГЩЭјТч
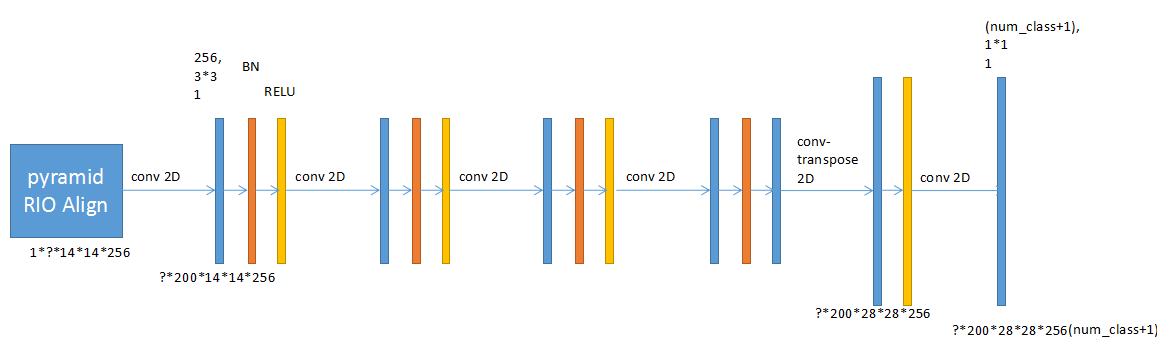
ФЌШЯЧщПіЯТЩњГЩ28*28ДѓаЁЕФMaskЃЌУПИіРрБ№вЛИіMaskЁЃЭЦРэЪБЪЙгУКѓДІРэНЋmask resizeЕНbboxЕФДѓаЁЃЌВЂЬюГф0БфГЩдЭМЦЌДѓаЁ(utils.unmold_mask)ЁЃ
GradientДЋЕн
PyramidROIAlignВузшжЙGradientЯђROI proposalsДЋЕнЃЌЕЋЪЧЛсЯђFPNДЋЕнЁЃвВОЭЪЧЫЕЭЗВПЕФЗДЯђДЋЕнВПЗжЖдRPNЭјТчВЛВњЩњгАЯьЁЃДњТыВЮПМmodels.PyramidROIAlign
ЦфЫћФЃПщ
Detection target layerЃЌProposal layerЃЌ вдМАЭЦЕМЙ§ГЬжаЕФDetetion
layerЖМЪЧЦеЭЈЕФЗЧбЇЯАЕФЙ§ГЬ.
Proposal layerбЁдё6000ИіИХТЪзюДѓЕФanchor boxesЃЌзівЛаЉКѓДІРэЃЌЪЙгУNMSШЅжиЁЃЕУЕНЕФНсЙћзїЮЊКѓајЕФЪфШыЁЃгЩгкFPNЕФИпОЋЖШВуБШНЯДѓЃЌБШШч128*128ЃЌЛсЩњГЩ128*128*NUM_bbox_ratioИіНсЙћЃЌвд0.5,1,2Ш§Иіbox
ratioРДМЦЫуЪЧ128*128*3=49152ИіЃЌЖјЧвПЩФмДцдкДѓСПЕФжиЕўЃЌШчЙћВЛМгДІРэЪфШыЕНКѓајЭјТчЃЌЛсеМгУДѓСПЕФФкДцЁЃ
Detection target layerАбProposal layerЕФЪфГіНјвЛВНДІРэЃЌЩњГЩКЯЪЪЕФКђбЁROIsЪфШыЕНКѓајЭјТчЃЌВЂЮЊМЦЫуlossзізМБИЁЃ
Detection layerжївЊЪЧИљОнФПБъЗжРрКЭBboxЛиЙщЕФНсЙћЃЌбЁдёКЯЪЪЕФROIЃЈШЅГ§БГОАЃЌШЅГ§ЕЭИХТЪЕФboxЃЌNMSШЅжиЃЉЪфШыЕНmaskЩњГЩЭјТчЁЃ
ROIAlign ТлЮФжаетВПЗжЪЧЪЙгУВхжЕЕФЗНЪНЃЌНЋBBoxЖдгІЕФfeatureБфЛЛГЩ7*7ДѓаЁЁЃmatterportЕФЪЕЯжжБНгЪЙгУСЫtfЕФresizeЁЃ
|









