| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФЪЧвЛЦЊЛњЦїбЇЯАScikit-learnЕФБЪМЧЃЌжївЊНщЩмScikit-learnЕФАВзАКЭЪЙгУЃЌЯЃЭћЛсЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
Scikit-learnАВзА
sklearnПтвРРЕгкnumpyЁЂscipyЁЂmatplotlibПтЃЌЪзЯШАВзАnumpyЃЌШЛКѓАВзАscipyЁЂmatplotlibПтЃЌзюКѓАВзАscikit-learnПтЁЃПЩвдЭЈЙ§anacondaНјааАВзАЛђепЭЈЙ§вРРЕЙиЯЕЃЌж№ИіНјааpip
installНјааАВзАЁЃ
Scikit-learnЕФЪ§ОнМЏНщЩм
scikit-learnЪ§ОнМЏШчЯТЭМЫљЪОЃЌАќРЈСЫаЁЪ§ОнМЏКЭДѓЪ§ОнМЏЃЌВЩгУКЏЪ§ЗНЗЈЕїгУЁЃ
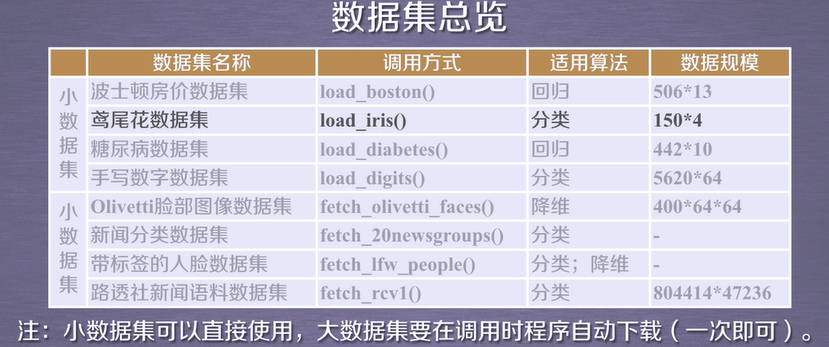
| #
МгдиbostonЗПМлаХЯЂЪОР§
from sklearn.datasets import load_boston
data, target = load_boston(return_X_y=True)
print(data.shape)
print(target.shape)
|
| #МгдиЪжаДЪ§зжПт
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
digits = load_digits()
plt.matshow(digits.images[3])
plt.show()
|
sklearnПтАќРЈ6ДѓВПЗжЃЌАќРЈЗжРрЁЂЛиЙщЁЂОлРрЁЂНЕЮЌЁЂФЃаЭбЁдёвдМАЪ§ОндЄДІРэЁЃОпЬхЕФКЏЪ§ШчЯТЭМЫљЪОЃК
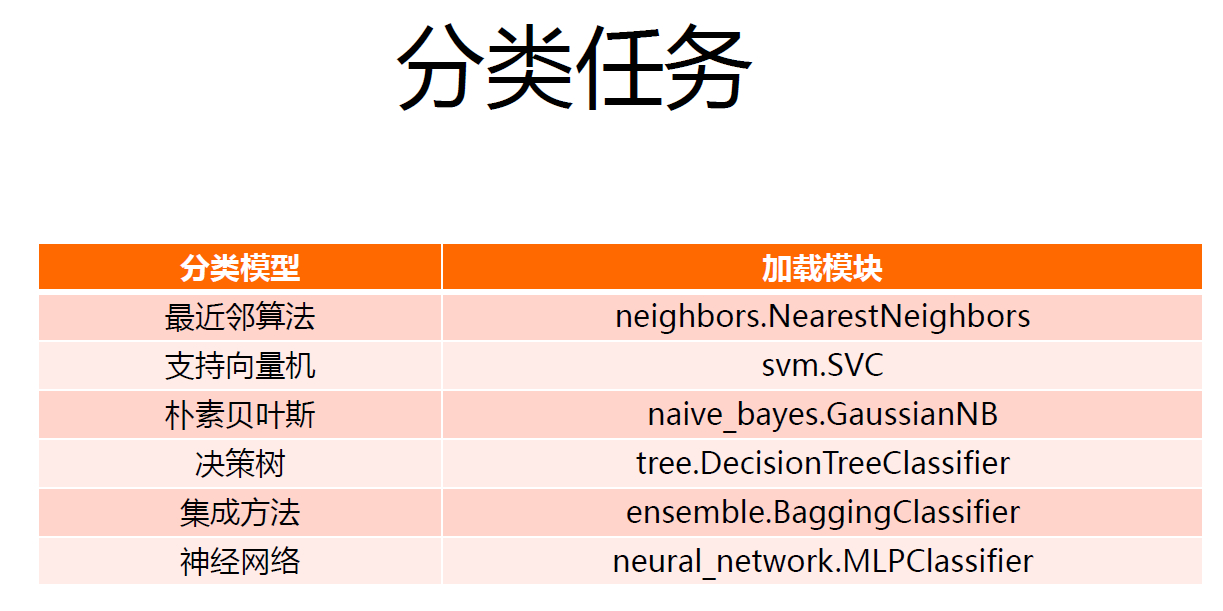
SklearnЮоМрЖНбЇЯАЪЙгУ
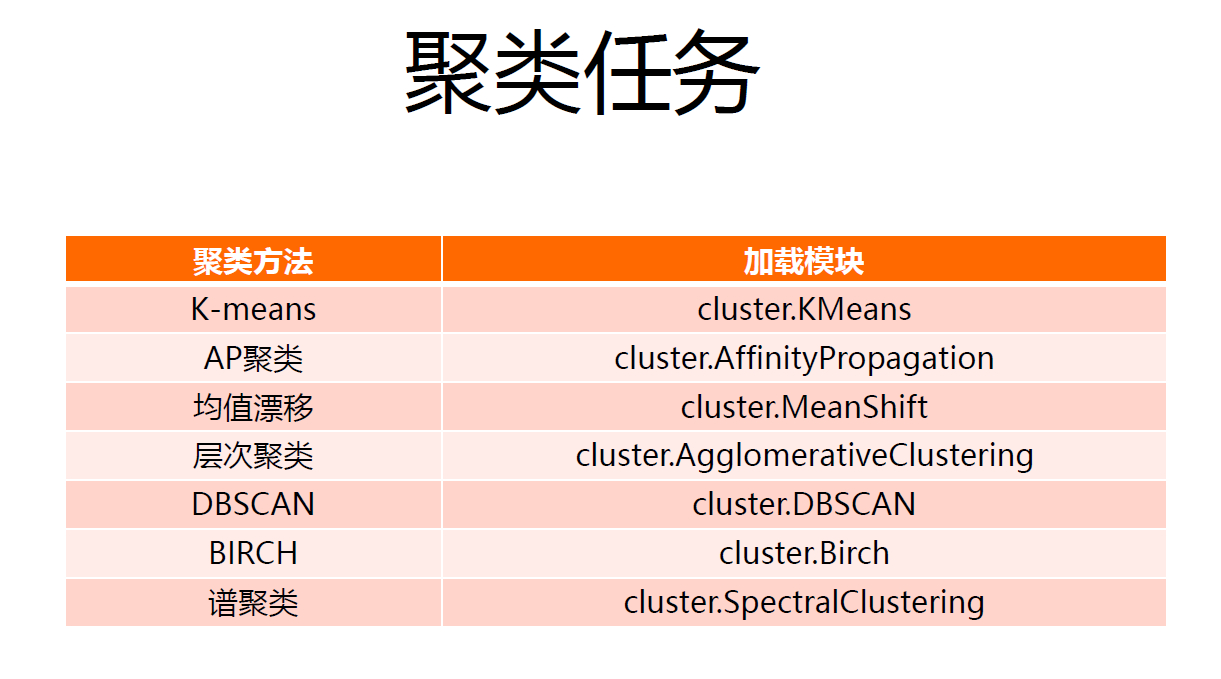
ЮоМрЖНбЇЯАВЩгУЮоБъЧЉЪ§ОнЃЌДІРэЪ§ОнЗжВМЛђепЪ§ОнЙиЯЕЃЌАќРЈОлРрКЭНЕЮЌЁЃ
ОлРрВЩгУОрРыНјааКтСПбљБОЕФЗжРрЧщПіЃЌПЩвдВЩгУХЗЪЯОрРыЁЂТќЙўЖйОрРыЁЂТэЪЯОрРыЃЈАќКЌСЫЪєадЕФБъзМВюЃЉЁЂгрЯвЯрЫЦЖШЃЈЯђСПЯрЫЦЖШЕФвЛИіЗНУцЃЉЁЃ
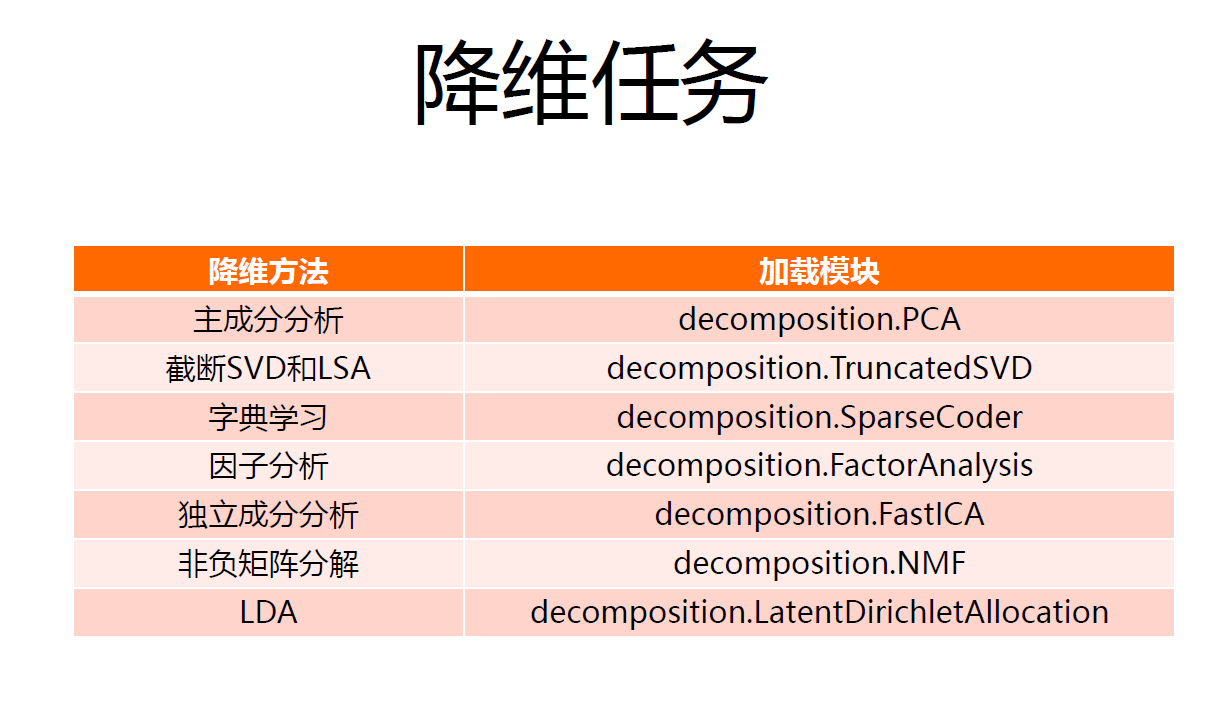
sklearnОлРрЫуЗЈАќКЌгкsklearn.clusterжаЃЌАќКЌСЫk-meansЁЂСкНќДЋВЅЫуЗЈЁЂDBSCANЕШЁЃ
sklearn.clusterПЩвдВЩгУЖржжЪ§ОнаЮЪНзїЮЊЪфШыЃЌБъзМаЮЪНЮЊ[бљБОИіЪ§
ЬиеїИіЪ§]ЃЌЛЙПЩвдВЩгУЦфЫћЗНЪННјааЁЃ
НЕЮЌЃЌдкБЃжЄЪ§ОнЫљОпгаЕФЬиеїЧщПіЯТЃЌНЋИпЮЌЪ§ОнзЊЛЏЮЊЕЭЮЌЪ§ОнЕФЙ§ГЬЃЌПЩгУгкЪ§ОнПЩЪгЛЏЛђепОЋМђЪ§ОнЕФзїгУЁЃ
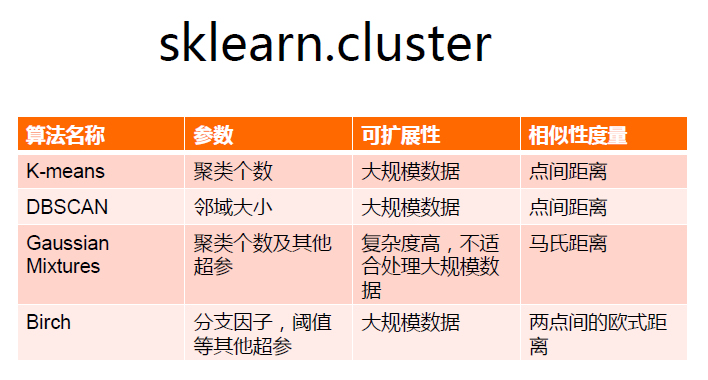
sklearnНЕЮЌЫуЗЈАќКЌгкsklearn.decompositionЃЌФПЧАга7жжНЕЮЌЫуЗЈЁЃ
ОлРржЎkmeansЗНЗЈЪЙгУ
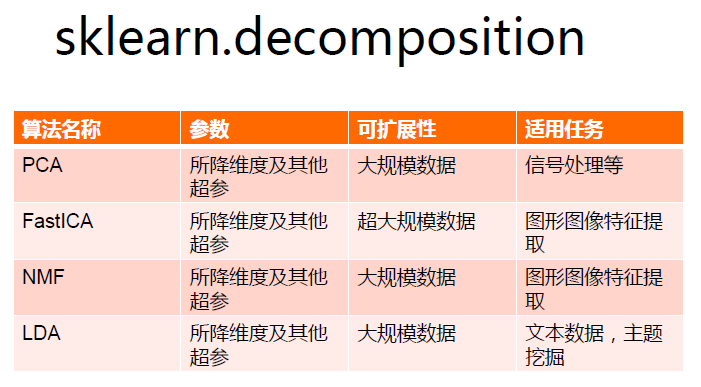
kmeansЫуЗЈНЋЪ§ОнЗжЮЊkИіДиЃЌДиФкЯрЫЦЖШНЯИпЃЌДиМфЯрЫЦЖШНЯЕЭЁЃЦфВйзїЙ§ГЬШчЯТЭМЫљЪОЁЃ

ЩцМАЕНЕФЙ§ГЬАќРЈЃКШчКЮЫцЛњбЁШЁkИіЕуЃЛШчКЮМЦЫуЦфгрЕугыбЁШЁЕуЕФОрРыЃЛШчКЮМЦЫуУПвЛРрЕФОљжЕЃЛШчКЮХаЖЯЭЃжЙЃЛШчКЮжЄУїгааЇадЁЃ
ВЩгУkmeansНјааОлРрВйзїЃЌЪ§ОнЮЊ31ИіЩэЗнОгУёМвЭЅЦНОљжЇГіЃЌАќКЌ8ИіЮЌЖШЪ§ОнЃЌЖдгк31ИіЪЁЗнНјааОлРрЁЃ
бЁШЁЪ§ОнЕуВЩгУСЫKmeansЕФГѕЪМЛЏЫуЗЈЗНЗЈЃЌгЩгкУЛгаЪ§ОнЃЌетРяВЩгУload_iris()Ъ§ОнНјааЗжРрЃЌДцдквЛЖЈЕФЗжРрЮѓВюЃЌДѓдМга0.09~0.11ЕФЗжРрЮѓВюЁЃ
| from
sklearn.cluster import KMeans
from sklearn.datasets import load_iris
if __name__ == '__main__':
# import iris data: x is the iris feature and
y is the class
x, y = load_iris(return_X_y=True)
# the number clusters is 3
km = KMeans(n_clusters=3,init='k-means++', max_iter=10000)
label = km.fit_predict(x)
# evaluate the accuracy
error_cnt = 0
sum_cnt = 0
for i in range(len(label)):
if (y[i] != label[i]):
error_cnt =error_cnt + 1
sum_cnt = sum_cnt + 1
print("Error rate:%.2f" % (error_cnt/sum_cnt))
|
kmeansПЩвдгУгкЭМЯёЗжИюЃЌМДРћгУЭМЯёЗжЛвЖШЁЂбеЩЋЁЂЮЦРэЁЂаЮзДЕШЬиеїНЋЭМЯёЗжЮЊШєИЩВЛжиЕўЧјгђЃЌЪЙетаЉЬиеїдкЭЌвЛЧјгђОпгаЯрЫЦадЖјВЛЭЌЧјгђГЪЯжкЄЯыВювьадЁЃЭМЯёЗжИюГЃгУММЪѕАќРЈСЫуажЕЗжИюЁЂБпдЕЗжИюЁЂжБЗНЭМЗЈКЭОлРрЗжЮіЁЂаЁВЈБфЛЛЕШЁЃkmeansЗжИюПЩвдЪЕЯжЭМЯёжаЯрЫЦЬиеїОлРрЃЌДгЖјЭъГЩЗжИюЧщПіЁЃЖдгкЭЌвЛРрВЩгУЯрЭЌбеЩЋБъМЧЃЌзюжеПЩвдаЮГЩЗжИюЭМЯёЁЃЪЕР§ШчЯТЃЌвЛИіНЯживЊЕФАќЮЊPILЃЌЪЕР§ДњТыШчЯТЃК
| import
PIL.Image as image
def loadData(filePath):
f = open(filePath,'rb')
data = []
img = image.open(f)
m,n = img.size
for i in range(m):
for j in range(n):
x,y,z = img.getpixel((i,j))
data.append([x/256.0,y/256.0,z/256.0])
f.close()
return np.mat(data),m,n
|
ОлРржЎDBSCANЗНЗЈЪЙгУ
DBSCANЛљгкУмЖШНјааОлРрЃЌВЛашвЊжИЖЈОлРрИіЪ§ЁЃDBSCANЫуЗЈНЋЪ§ОнЕуЗжЮЊШ§РрЃККЫаФЕуЁЂБпНчЕуКЭдывєЕуЃЌетвРОнвЛЕуЕФСкгђepsФкЦфЫћЕуИіЪ§ЕФЧщПіЪЧЗёДѓгкminptsРДОіЖЈЁЃ
ЫуЗЈСїГЬШчЯТЫљЪОЃЌЕквЛВНАќРЈСЫМЦЫуУПвЛИіЕуСкгђepsОрРыФкЕФЕуЃЌГЌЙ§minptsИіЪ§ЃЌдђМЧИУЕуЮЊКЫаФЕуЃЛШЛКѓВщПДЪЃгрЕуЪЧЗёдкСкгђФкЃЌШчЙћдкдђЮЊСкгђЕуЃЛЗёдђЮЊдыЩљЕуЁЃЕкЖўВНЮЊЩОГ§дыЩљЕуЃЛЕкШ§ВНЮЊСЌНгОрРыдкepsФкЕФКЫаФЕуЃЌЙЙГЩвЛИіДиЃЛЕкЫФВНЃЌжИЖЈБпНчЕуЙщРргкФФвЛИіДиЁЃ

| #
ЭГМЦУПвЛРрБ№дЊЫиИіЪ§ЕФДњТы
for i in range(0,nc):
numberOfClass.append(len(label[label[:] == i]))
print(numberOfClass)
|
| #
ЭГМЦЗжРрИіЪ§ЕФДњТы
n_clusters = len(set(labels))-(1 if -1 in labels
else 0)
|
| #
DBSCANКЫаФДњТы
db = DBSCAN(eps=1,min_samples=20).fit(x)
labels = db.labels_
|
DBSCANЛљгкУмЖШЗжВМНјааОлРрЃЌЖдгкirisЪ§ОнФбвдЪЕЯжгааЇОлРрЁЃ
ДгpythonдДТыПДЃЌDBSCANгыKNNДцдквЛЖЈЕФСЊЯЕЁЃДгЪЕМЪВйзїЖјбдЃЌDBSCANгыkmeansОљДцдкОрРыМЦЫуВНжшЃЌетвВЪЧОлРрЫуЗЈЕФвЛИіБиаыВНжшЃЛЖдгкОрРыЧщПіЃЌkmeansВЩШЁзюЖЬОрРыЙщРрддђЃЌетЗћКЯЭГМЦЧщПіЃЛЖјDBSCANдђВЩШЁвЛЖЈЕФthresholdЃЌЖдгкВПЗждыЩљЪ§ОнПЩвдНјааЙ§ТЫЁЃ
НЕЮЌжЎPCA
PCAЃЌжїГЩЗжЗжЮіЃЌНЯЮЊГЃгУЕФвЛжжНЕЮЌЗНЗЈЃЌПЩвдгУгкИпЮЌЪ§ОнЕФЬНЫїКЭПЩЪгЛЏЃЌЛЙПЩвдгУзїЪ§ОнбЙЫѕКЭдЄДІРэЁЃ
ОиеѓЕФжїГЩЗжОЭЪЧЦфаЗНВюОиеѓЖдгІЕФЬиеїЯђСПЃЌАДееЖдгІЕФЬиеїжЕДѓаЁНјааХХађЃЌзюДѓЕФЮЊЕквЛжїГЩЗжЃЌЦфДЮЮЊЕкЖўжїГЩЗжЁЃбљБОЕФPCAЫуЗЈШчЯТЫљЪОЃК

дкsklearnПтжаЃЌПЩвдЪЙгУsklearn.decomposition.PCAНјааНЕЮЌЃЌЙиМќВЮЪ§гажїГЩЗжИіЪ§n_componentsКЭsvd_solverЁЃВЩгУPCAПЩвдЖдгкirisЪ§ОнМЏНјааНЕЮЌВйзїЁЃ
| #
дЪ§ОнЮЊЫФЮЌЕФЃЌЪЙгУPCAЖдЪ§ОнНјааНЕЮЌЃЌ
# ЪЕЯждкЖўЮЌЦНУцЕФПЩЪгЛЏ
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# МгдиЪ§ОнМЏЕМШыКЏЪ§
data = load_iris()
# вдзжЕфаЮЪНМгдиЪ§ОнМЏ
y = data.target
# yБэЪОЪ§ОнМЏжаЕФБъЧЉ
X = data.data
# xБэЪОЪ§ОнМЏжаЕФЪєадЪ§Он
pca = PCA(n_components=2)
# МгдиpcaЫуЗЈЃЌжїГЩЗжЪ§ФПЮЊ2
reduced_X = pca.fit_transform(X)
# ЖддЪМЪ§ОнНјааНЕЮЌЃЌБЃДцдкreduced_Xжа
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
# АДРрБ№НЋНЕЮЌКѓЕФЪ§ОнНјааБЃДц
for i in range(len(reduced_X)):
# range(5) #ДњБэДг0ЕН5(ВЛАќКЌ5)
if y[i] == 0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i] == 1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
# АДее№АЮВЛЈЕФРрБ№НЋНЕЮЌКѓЕФЪ§ОнЕуБЃДцдкВЛЭЌЕФСаБэжа
plt.scatter(red_x, red_y, c='r', marker='x')
# ЛxЙигкyЕФЩЂЕуЭМЃЌcЃКcolorЃЌrЃКredЁЃ
# makerЃКБъМЧЕуЕФаЮзДЁЃxЃКxаЮЃЛDЃКзъЪЏаЮЃЛ.ЃКЕуаЮ
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()
|
НЕЮЌжЎNMF
NMFЃЌЗЧИКОиеѓЗжНтЃЌЪЧдкОиеѓЫљгадЊЫиЮЊЗЧИКЪ§етвЛЬѕМўдМЪјЧщПіЯТЕФОиеѓЗжНтЗНЗЈЁЃЦфЫМЯыЮЊЃЌЖдгквЛИіЗЧИКОиеѓЃЌПЩвдевЕНСэЭтЕФОиеѓWКЭHЃЌетСНепвВЪЧЗЧИКОиеѓЃЌЪЙЕУWГЫвдHНгНќОиеѓVЁЃЦфжаWОиеѓГЦЮЊЛљДЁЭМЯёОиеѓЃЌЖјHОиеѓЮЊЯЕЪ§ОиеѓЁЃWОиеѓРрЫЦгкVОиеѓжаГщШЁЕФЬиеїЁЃ
NMFЕФЫуЗЈашвЊНјвЛВННјааЬНОПЃЌПЩвдЪЙгУNMFЗНЗЈНјааЃЌЙиМќВЮЪ§гаn_componentsЃЌinitБэЪОWКЭHОиеѓЕФГѕЪМЛЏЗНЗЈЁЃ
ЪЕзїЕФЖдЯѓЮЊolivettiШЫСГЪ§ОнМЏЃЌАќКЌ400еХШЫСГЪ§ОнЃЌУПеХЭМЯёЮЊ64*64ДѓаЁЃЌвВОЭЪЧЫЕдЪМЕФЪ§ОнОпга4096ИіЮЌЖШЁЃПЩвдВЩгУNMFНјааНЕЮЌЃЌОЙ§ЕїећзюжеЕФЬиеїИіЪ§ПЩвдЮЊ6ИіЃЌвВОЭЪЧЫЕНЕЮЌКѓЕФЪ§ОнМЏЮЊ400еХ*6ИіЬиеїЁЃ(Д§ШЗЖЈ)
NMFКЭPCAПЩвджБНгЬцДњЪЙгУЃЌЖўепВЮЪ§НгНќЁЃ
SklearnМрЖНбЇЯАЪЙгУ
МрЖНбЇЯАЕФФПБъЪЧРћгУвЛзщДјгаБъЧЉЕФЪ§ОнЃЌЙЙГЩвЛИіДгЪфШыЕНЪфГіЕФгГЩфЃЌШЛКѓНЋетжжгГЩфЙиЯЕгІгУЕНЮДжЊЪ§ОнЃЌДяЕНЗжРрЛђЛиЙщЕФФПЕФЁЃ
sklearnПтжаЗжРрЫуЗЈЮДБЛЭГвЛЗтзАЃЌвђДЫЦфimportЗНЪНИїгаВЛЭЌЃЌЦфЗжРрЫуЗЈАќРЈСЫKNNЃЌЦгЫиБДвЖЫЙЃЌSVMЃЌОіВпЪїЃЌЩёОЭјТчФЃаЭЕШЕШЃЌМШгаЯпадЗжРрЦїЃЌвВгаЗЧЯпадЗжРрЦїЁЃ
ЛиЙщЗжЮідђЪЧгУгкЗжЮіЖрИіБфСПЕФЯрЙиадЃЌгЩгкИјГідкздБфСПБфЛЏЪБЃЌвђБфСПЕФБфЛЏЧщПіЁЃвЛАуЖјбдЃЌЭЈЙ§ЛиЙщЗжЮіПЩвдЕУЕНгЩздБфСПИјГівђБфСПЕФЬѕМўЦкЭћЁЃ
sklearnПтЕФЛиЙщКЏЪ§ЗтзАдкlinear_modelКЭprepocessingжаЃЌЦфжаЯпадЛиЙщКЏЪ§АќРЈЯпадЛиЙщЁЂСыЛиЙщЁЂLASSOЛиЙщЃЌЗЧЯпадЛиЙщШчЖрЯюЪНЛиЙщЕШЁЃ
ЗжРржЎKNN
KNNЕФЛљБОЫМЯыЪЧЭЈЙ§МЦЫуД§ЗжРрЪ§ОнгыбЕСЗМЏЪ§ОнЕФОрРыЃЌШЁЧАKИіЕуЃЌНЋД§ЗжРрЪ§ОнЛЎЗжЕНГіЯжДЮЪ§зюЖрЕФФЧИіРрБ№ЁЃ
sklearnжаВЩгУsklearn.neighbors.KNeighborsClassifierДДНЈKНќСкЗжРрЦїЃЌЙиМќВЮЪ§АќРЈn_neighborsКЭweightsЁЃЮЊСЫФмЙЛЖдгкДѓЪ§ОнНјааДІРэЃЌПЩвдВЩгУКЯЪЪЕФМЦЫуСйНќЕуЕФЗНЗЈЁЃЪЕМЪЪЙгУЙ§ГЬжаЃЌЧуЯђгкЪЙгУНЯаЁЕФKЃЌВЂЧвЪЙгУНЛВцбщжЄЕУЕНзюгХЕФKжЕЁЃ
| #
KNNМђвзДњТы
from sklearn.neighbors import KNeighborsClassifier
x = [[0],[1],[2],[3]]
y = [0,0,1,1]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(x,y)
print(neigh.predict([[1.1]]))
|
ЗжРржЎОіВпЪї
ЙЙНЈЙ§ГЬЮЊЬиеїЕФаХЯЂдівцЃЌЗжРрЪБжЛашвЊИљОнОіВпЪїЕФНкЕуНјааХаЖЯЃЌДгЖјЕУЕНЫљЪєРрБ№ЁЃ
sklearnПЩвдЪЙгУsklearn.tree.DecisionTreeClassifierНјааЗжРрЃЌВЮЪ§гаcriterionЃЌПЩвдбЁдёginiЛђепentropyЃЛmax_featuresПЩвдбЁдёОіВпЪїНкЕуНјааЗжРрЪБЃЌДгЖрЩйИіЬиеїжабЁШЁзюгХЬиеїЁЃ
ЦфБОжЪЪЧвЛжжбАеввЛжжЖдЬиеїПеМфЕФЛЎЗжЃЌДгЖјЙЙНЈвЛИіЖдгкбЕСЗЪ§ОнФтКЯКУЃЌВЂЧвИДдгЖШаЁЕФОіВпЪїЁЃ
| from
sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
# ФЌШЯЪЙгУginiЗжРрЃЌетРяВЩгУentropyЗжРр
clf = DecisionTreeClassifier(criterion='entropy')
iris = load_iris()
print(cross_validate(clf,iris.data,iris.target,cv=10))
|
ЗжРржЎЦгЫиБДвЖЫЙ
ЦгЫиБДвЖЫЙЃЌnaive bayesЃЌЮЊЕфаЭЕФЩњГЩбЇЯАЗНЗЈЃЌЭЈЙ§бЕСЗЪ§ОнЕУЕНСЊКЯЗжВМЃЌШЛКѓЧѓШЁКѓбщИХТЪЁЃЖдгкаЁЙцФЃЁЂЖрЗжРрШЮЮёЁЃ
дкsklearnПтжагавдЯТШ§РрБДвЖЫЙЗжРрЦїЃЌnaive_bayes.GaussianNBЃЌЗжБ№еыЖдИпЫЙЦгЫиБДвЖЫЙЁЂеыЖдЖрЯюЪНФЃаЭЕФЦгЫиБДвЖЫЙКЭеыЖдЖрдЊВЎХЌРћФЃаЭЕФЦгЫиБДвЖЫЙЃЌЦфЧјБ№дкгкМйЩшФГвЛЬиеїЕФЙлВтжЕЪєгкФГвЛЬиЖЈЗжВМЁЃ
| #
ЦгЫиБДвЖЫЙЪОР§ДњТы
import numpy as np
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
Y = np.array([1,1,1,2,2,2])
clf = GaussianNB(priors=None)
clf.fit(X,Y)
print(clf.predict([[-0.8,-1]]))
|
ЗжРржЎSVM
SVMЗжРрЗНЗЈдкsklearn.svm.SVCжаЃЌДњТыШчЯТЫљЪОЃЌашвЊЩшжУkernelВЮЪ§ЃЌР§ШчrbfЃЌlinear,poly,sigmoidЕШЁЃЭЌЪБеыЖдБОЗжРрЃЌПЩвдВњЩњбЕСЗМЏКЭВтЪдМЏЁЃ
| from
sklearn.datasets import load_iris
from sklearn.model_selection import cross_validate
from sklearn import svm
clf = svm.SVC(kernel='rbf')
x,y = load_iris(return_X_y=True)
print(cross_validate(clf,x,y,cv=10))
|
ЗжРржЎMLP
MLPЃЌМДЖрВуШЋСЌНгЩёОЭјТчЁЃЖдгкDBRHDЪ§ОнМЏЃЌЦфДѓаЁЮЊ32*32ЕФЮФБООиеѓЃЌЖјMLPВЩгУЯђСПЪфШыЃЌвђДЫашвЊеЙПЊЮФБООиеѓЃЌЪфГіВЩгУone-hot
vectorsЁЃHidden layerЕФВуЪ§КЭЩёОдЊИіЪ§ОљЛсгАЯьЪЖБ№зМШЗТЪЁЃ
| clf
= MLPClassifier(hidden_layer_sizes=(100,),
activation='logistic', solver='adam',
learning_rate_init = 0.0001, max_iter=2000)
print(clf)
clf.fit(train_dataSet,train_hwLabels)
#read testing dataSet
dataSet,hwLabels = readDataSet('testDigits')
res = clf.predict(dataSet) #ЖдВтЪдМЏНјаадЄВт
|
Ъ§ОнЕФДІРэЗНЗЈ
sklearnЬсЙЉСЫЪ§ОндЄДІРэФЃПщImputerЃЌздЖЏЩњГЩбЕСЗМЏКЭВтЪдМЏЕФФЃПщtrain_test_splitЃЌдЄВтНсЙћЦРЙРФЃПщclassification_reportЁЃзЂвтЃЌtrain_test_splitвбОБЛЩОГ§ЁЃ
| from
sklearn.preprocessing import Imputer
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
|
ПЩвдВЩгУpandasФЃПщЖСШЁЪ§ОнЮФМўЃЌПЩвдДІРэЗжИєЗћЃЌШБЪЇжЕЧвШЅГ§БэЭЗааЁЃДІРэШБЪЇжЕДњТыШчЯТЫљЪОЁЃетРягЩгкДцдкЖрИіЗжЩЂЮФМўЃЌвђДЫЪЙгУСЫnp.concatenateНјааЮФМўЪ§ОнКЯВЂЁЃ
|
df = pd.read_table(file, delimiter=',', na_values='?',
header=None)
imp = Imputer(missing_values='NaN', strategy='mean',
axis=0)
imp.fit(df)
df = imp.transform(df)
feature = np.concatenate((feature, df))
|
train_test_splitКЏЪ§ПЩвдНЋЪ§ОнЫГађДђТвЃЌЖјclassification_reportПЩвдЩњГЩЪ§ОнЗжРрЕФНсЙћзМШЗЖШЁЃ
| print(classification_report(y_label,
y_clf_result))
|
ЖдгкЪ§ОнЃЌашвЊНјааЬиеїбЁдёЃЌПЩвдНшжњИЈжњШэМўНјааЪ§ОнПЩЪгЛЏЁЃ
ЖдгкCSVЮФМўЃЌПЩвдЭЈЙ§pandasФЃПщЕФread_csvКЏЪ§НјааДІРэЃЌЪ§ОнПЩвдНјааХХађВйзїЃЌетЖдгкЪБМфађСаЪ§ОнгШЦфгагУЁЃ

ЖдгкЪБМфађСаКЏЪ§ЃЌПЩвджИЖЈЬиЖЈЕФЧАађЪБМфНјааЬиеїЗжЮіЃЌЖјКѓЕФЪБМфзїЮЊНсЙћlabelЃЌШчЯТЗжЮіЫљЪОЁЃГѕЪМЪ§Онга200ЬьЕФНсЙћЃЌЪЙгУЧАађ150ЬьзїЮЊtraining
setЁЃвђДЫзюжеЕФбљБОАќРЈСЫ50ЬѕЃЌУПвЛЬѕбљБОЕФЪ§ОнАќРЈСЫЧА150ЬьЕФИїЬиеїЃЌИУЬиеїЪЧЖўЮЌЪ§зщаЮЪНЃЌвђДЫашвЊНјааreshapeВйзїЁЃ

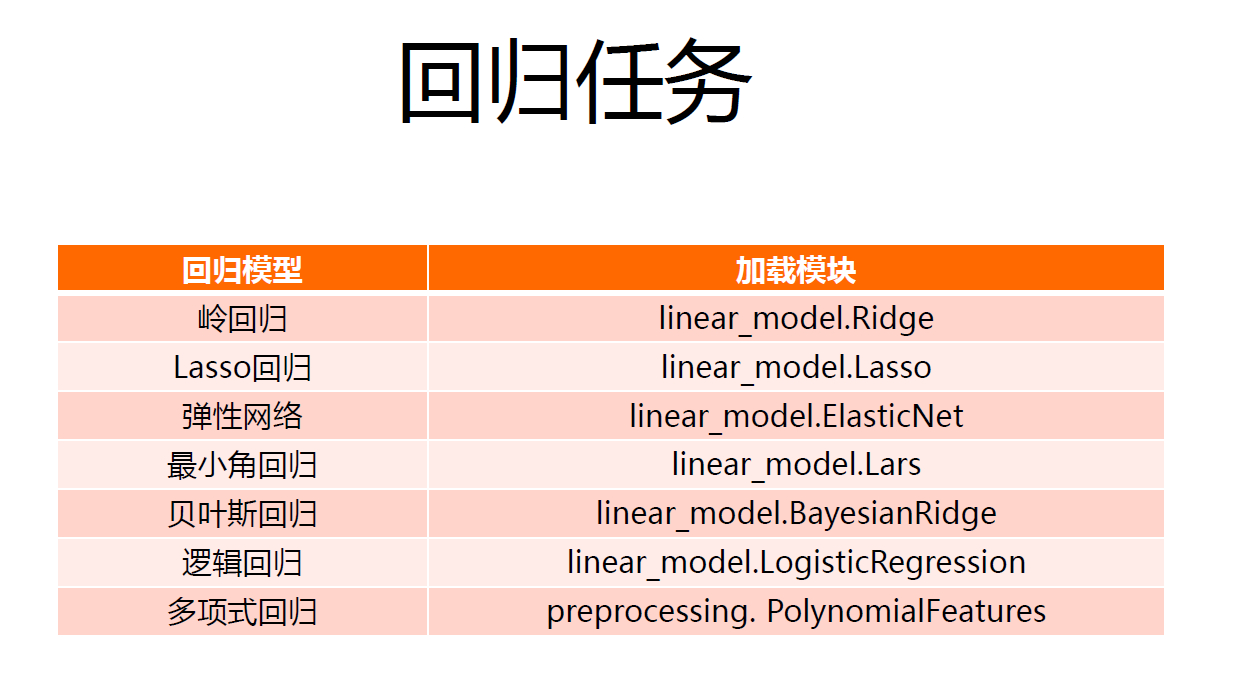
ЛиЙщжЎЯпадЛиЙщКЭЖрЯюЪНЛиЙщ
ЯпадЛиЙщРћгУзюаЁЖўГЫЗЈЃЌЖдгкЛиЙщЗНГЬНјааЧѓНтЃЌзюжеПЩвдЕУЕНGDЕШЖржжгХЛЏЕќДњЗНЗЈЁЃ
ЛиЙщЗжЮіЕФЙиМќДњТыШчЯТЫљЪОЃЌЪЙгУЕФКЏЪ§ЮЊsklearn.linear_model.LinearRegression()ЃЌfit()гУгкФтКЯЪфШыЪфГіЪ§ОнЁЃ
ЖрЯюЪНЛиЙщБОжЪвВЪЧЯпадЛиЙщЃЌвђЮЊВЮЪ§ЖдгкЪфГіЪЧЯпадЕФЁЃЖдгкЖрЯюЪНЛиЙщЃЌsklearnЬсЙЉСЫдЄДІРэЗНЗЈЃЌЙЙдьЖрЯюЪНЬиеїЁЃ
| from
sklearn.prepocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 2)
X_poly = poly_reg.fit_transform(datasets_X)
lin_reg_2 = linear_model.LinearRegression()
lin_reg_2.fit(X_poly, datasets_Y)
|
ЛиЙщжЎСыЛиЙщ
ЖдгкЛиЙщЗжЮіЖјбдЃЌзюаЁЖўГЫЗЈЕФНтЮіНтДцдкВЛЮШЖЈЧщПіЁЃвВОЭЪЧДцдквЛИізЊжУЯюЃЌгЩгкXЕФФГаЉСаЯпадЯрЙиЖШНЯДѓЃЌШнвзГіЯж$X^TX$НгНќ0ЁЃЖдгкНгНќгкСуЕФЧщПіОпгаВЛЮШЖЈадЁЃвђДЫПЩвдЭЈЙ§в§Шые§дђЯюНјааНтОіЃЌетГЦЮЊСыЛиЙщЃЌШчЯТЭМЫљЪОЃК

дкsklearnПтжаЃЌПЩвдЕїгУsklearn.linear_model.RidgeЃЌВЮЪ§гаalphaЃЌЖдгІе§дђЛЏвђзгЃЌfit_interceptБэЪОЪЧЗёМЦЫуНиОрЃЌsolverжИЖЈЧѓНтЦїЁЃЪЕР§жажИЖЈЕФalpha=1.0ЁЃ
ЧПЛЏбЇЯАМАМђЕЅгЮЯЗбЕСЗ
ЧПЛЏбЇЯАЪЧГЬађagentЭЈЙ§гыЛЗОГВЛЖЯНјааНЛЛЅбЇЯАЃЌЕУЕНДгЛЗОГЕНЖЏзїЕФгГЩфЃЌДгЖјЪЙЕУРлМЦЛуБЈзюДѓЛЏЁЃ
ТэЖћПЩЗђОіВпЙ§ГЬЃЌMDPЃЌЪЧвЛжжНЯЮЊГЃгУЕФЧПЛЏбЇЯАЙ§ГЬЃЌИУбЇЯАЗНЗЈашвЊЛёЕУЛЗОГЕФзДЬЌвдМАПЩФмВЩШЁЖЏзїЕФзДЬЌЁЃ
ЯжЪЕжаЃЌЖдгкЛЗОГЕФзЊвЦИХТЪКЭНБРјКЏЪ§КмФбЕУЕНЃЌвђДЫПЩвдВЩгУВЛвРРЕгкЛЗОГНјааНЈФЃЕФбЇЯАЫуЗЈЃЌГЦЮЊУтФЃаЭбЇЯАЃЌУЩЬиПЈТхЧПЛЏбЇЯАОЭЪЧЦфжавЛРрЃЌВЩгУЖрДЮВЩбљЛёЕУЦНОљЕФРлМЦНБЩЭЁЃИќЧПЕФбЇЯАЗНЗЈЮЊQ-learningЫуЗЈЁЃ
DQN: РћгУЩюЖШЭјТчЃЌПЩвдЪЕЯжЩюЖШЧПЛЏбЇЯАЃЌЕУЕННЯКУЕФбЇЯАаЇЙћЁЃИУЗНЗЈжБНгбЇЯАЛЗОГКЭЖЏзїзДЬЌКЏЪ§ЕФгГЩфЙиЯЕЃЌЕУЕНЮЪЬтЕФНтЁЃ
|









