| 编辑推荐: |
本文来自于网络,本文将从场景驱动的角度来探讨如何建立一个灵活快速又可落地生效的图像检测框架。
|
|
分享大纲:
1. 线上线下融合场景中的图像视觉技术
2. 复杂场景中的图像视觉技术
3. 复杂场景中的文本识别
4. 复杂场景中的三维重建
线上线下融合场景中的图像视觉技术
今天演讲的标题是线上线下融合场景中的图像识别技术。看到这个标题大家可能会有一些疑惑,图像视觉技术还分线上线下场景?本身图像视觉技术是通用的,不分场景。但是我们在本地生活领域做图像视觉技术的时候,会发现它和传统搜索引擎或推荐系统推进领域之下的图像视觉不完全相同。所以我今天不会讲常用的一些图像分类或图像相似度算法,我们讲一些类似于目标检测,或者视觉3D重建的新技术。

什么是所谓的线上线下融合?过去十年,我们看到O2O领域有大量的应用产生,例如打车,外卖以及洗车美容等。总体来讲,O2O是指将线上订单与线下实际服务提供能力连接在一起。但是走到了如今,特别是2017年,很多环境都发生了变化,成就了现在的线上线下融合的场景。
线上线下融合与传统的线上到线下的订单流程肯定是有一些不同之处。
第一个明显的不同点是O2O是单向的,是online到Offline。但是OMO是双向的,不光线上的订单会流到线下,线下的服务提供能力也会影响到线上的订单生成。
以饿了么为例解释一下。大家在饿了么APP下单,外卖会及时配送到大家手中,表面来看,这是一个典形的O2O,
订单从线上流到线下。但实际上也有反向的一个流程,假设线下的物流配送能力不足,那么会不会影响线上订单的产生过程呢?实际上会影响。比如在高峰期的时候,你会发现你平时常订餐的餐馆突然找不到了,但是在下午4点钟平峰期的时候又出现了。是因为在高峰期的时候,我们会做一些压力调控,一些供需平衡的策略。在运力比较紧张的时候,我们会缩小线上的配送圈。所以在中午的时候,你不能完成远距离下单,但在平峰期的时候却可以。所以说,这个影响是双向的,线下也会影响到线上的下单流程。
第二点就是传统的O2O讲究连接,但在饿了么这个领域我们讲的更多是融合。连接是旨把线上的流量和线下的服务能力连接在一起,它并不会对线下的服务能力有彻底的改造。但是在融合这个领域,我们通过算法技术,会对线下进行重新改造,特别是现在我们会通过人工智能和物联网的技术,未来对线下的人和物等进行改造,让它具备一些可以快速复制的一些特征。
第三点就是在O2O的领域下,线下实际上是被动的,因为订单是在线上产生的,线下实际上是被动的接受线上的订单。但是在饿了么领域,线下实际上是被改造。
最后一点就是在O2O领域,一项关键技术叫分单调度,去年也是在这个会议上我给大家介绍过饿了么的智能调度
。当然在外卖领域,智能调度的难度实际上比其他O2O应用领域要大,因为饿了么每天存在着两个很高的高峰期,单量比较集中。在高峰期的时候,我们的物流配送能力实际上是跟不上的,所以调度做起来难度比较高。但是在OMO领域,最核心的技术并不是分单调度,而是智能物联。智能物联怎么理解?具体来说就是我们要用人工智能和物联网的机制,对线上和线下进行融合打通。并且在这种联合打通的过程中,我们的图像视觉技术会起到非常关键的作用。
一些线上线下融合的典型应用场景,例如万物互联、虚实结合、人机协同、智能制造等。
复杂场景中的图像视觉技术

今天的主题是线上线下融合领域中的图像视觉技术。线上线下融合打通,最典型的应用是在本地生活服务场景。在本地生活服务场景中,我们所用的图像视觉技术主要有三种:目标检测、文本识别、三维重建。

首先给大家简单的介绍一下目标检测的一些应用场景。饿了么有很多线上线下的场景。例如,饿了么的骑手每天都需要在饿了么骑手APP上传一张自己的自拍照,饿了么会根据自拍照对骑手做现场的着装规范检测。但是饿了么在全国有300万的注册配送员,人工检测是不现实的,所以饿了么利用图像检测技术去自动判断。首先,会对骑手的人脸进行识别,确认骑手是否是系统里注册的饿了么骑手。其次需要对骑手身上的物品进行检测,例如衣服、帽、餐箱等。所以我们需要进行目标检测,即物体检测。我们要通过深度学习技术,检测这些箱子,帽子等物品是否符合饿了么的送餐规范。
第二个应用场景是关于场景中的一些目标识别,例如行人识别、办公桌椅检测、电梯按钮检测与识别等。可能大家要问为什么饿了么要做这些事情。因为饿了么已经开始研究无人配送。大家可以想象一下一个机器人在办公楼里穿梭的场景,如果他想要将手中的餐食正确的送到订餐人手中,他就必须能够识别周围的人,周围的办公桌椅,甚至在乘坐电梯的时候能够识别按钮。
第三个是合规检测,这就比较好理解。因为饿了么作为一个本地生活服务平台,有大量的商家图片、菜品图片,所以我们希望我们平台上的每张图片都符合规范。例如它上面不能有二维码,不能有水印,不能有logo等商标的一些附加物的出现。所以我们就要用图像技术去判断,做一些二维码检测,水印检测等。
最后是场景文本识别,在饿了么的场景中,比较多的是菜单的识别、招牌的识别、指示牌的识别、海报的识别等。这其中比较难的是菜单的识别,因为不同餐馆的菜单都是五花八门的,很难找到类似的。我们需要通过扫描菜单的图片,将菜品的名字和价格准确的抽取出来。
以上提到的这些场景实际上都会用到目标检测的技术,目标检测在这些场景中都起到至关重要的作用。
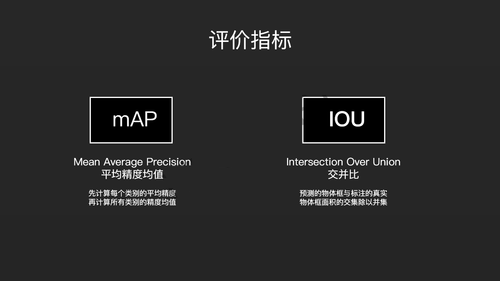
接下来我简单的介绍一下目标检测中常用的一些评价指标。
目标检测其实在做两件事情,第一件是物体框的回归,我们需要找出物体框。第二件是我们需要对框内的物体进行辨别,也就是分类。对于这个分类,我们常用的评价指标是mAP,即先计算每个类别的平均精度,再计算所有类别的精度均值。对于回归的物体框的准确性我们使用IOU,即预测的物体框与标注的真实物体面积的交集除以并集。当然,在物体检测领域还有其他一些重要指标,这两个只是最常用的,并不是万能的。
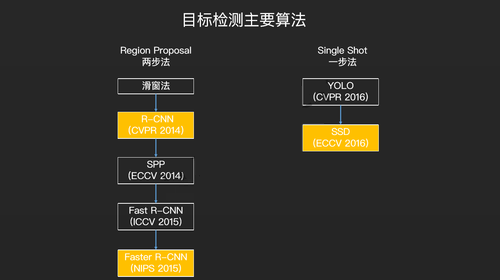
这个是目标检测算法发展的一个过程。
2010 年之前,目标检测算法主要基于非深度学习。第一个把深度学习应用到目标检测中的是R-CNN,相关论文发表于2014年。R-CNN是由一位外国人提出来的,然后一位中国人对它进行了优化继而推出SPP。但SPP运行的速度比较慢,以至于前一位R-CNN的提出者不服气,便又继续推出比SPP更快的Fast
R-CNN。最后两位提出者携手提出Faster R-CNN,一种更有效,更通用的方法。但总体而言,整个框架始终没有跳出R-CNN
的两步法思路。
所以目标检测第一类算法称之为两步法,什么叫两步法?第一步就是找出物体框,第二步就是对物体框进行分类。此外,还有另外一类方法称之为一步法,简单说就是从YOLO到SSD。
饿了么实现过的目标检测算法比较多,我这边只是列举了一些重要和常见的。
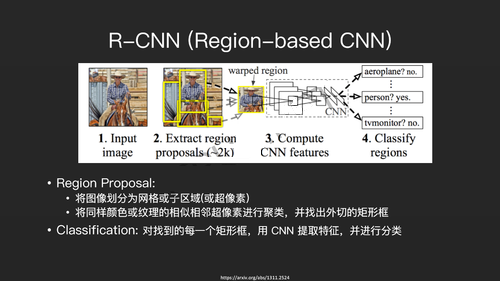
R-CNN是最简单的,也是最好理解的,它的思路非常简单。第一步先将图像划分为网格或子区域(或超像素),将同样颜色或纹理的相似相邻超像素进行聚类,并找出外切的矩形框。第二步就是对这些矩形框运行一个CNN分类算法,进行分类。R-CNN的提出是一种创新性的革命性的,但以今天的观点来看,它的速度比较慢。因此后续又提出了很多改进版的R-CNN。

第一个改进版就是SPP,也称之为金字塔池化。这个算法最核心的改进就是对所有的候选框共享一次卷积网络前向计算。它的第二个共性就是它可以通过一种金字塔的结构,获取不同尺度空间下的ROI区域。
这样的改进能够让它更快,并且能够发现不同尺度之下的地方,既可以发现大的物体也可以发现小的物体。但它的缺点仍然还是比较慢,无法达到实时。所以后续又提出了Fast
R-CNN,它简化了SPP的同时还采取多种加速策略。
但SPP和Fast R-CNN只是对R-CNN进行了改进,并没有实现颠覆性的创新。真正实现了颠覆性的创新其实是最后的Faster
R-CNN。Faster R-CNN创造性的提出了RPN (Region Proposal Networks)
代替 Selective Search,实现端到端的训练。也就是说原先整个目标检测分为两步,第一步是通过一些规则的方式找到一些矩形框。第二步是通过神经网络来做分类。但是Faster
R-CNN把第一步的人工规则也转成了一个神经网络,称之为Region Proposal Networks,它的第一步是一个神经网络,第二步做分类也是一个神经网络,实现了一种端到端的训练。这样的算法有很高的精度和性能。
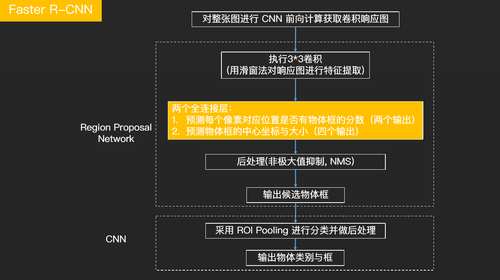
这张框架图是Faster R-CNN的一个主要执行过程,首先它对整张图进行CNN前向计算获取卷积响应图。这个和一般的图像分类操作没什么区别,一个主要区别就是中间的这个矩形框。它首先用滑窗法对响应图进行特征提取,然后会预测每个像素对应位置是否有物体的分数(两个输出),它会输出是和否。此外它还会去预测物体框的中心坐标与大小(四个输出),中心坐标的X轴、Y轴两个值。物体框大小主要是通过长和宽来表示,所以一共是四个数字。
所以它的两个全连接层总共会输出六个数字,然后进行后处理,典型的就是用NMS来做物体框的选择,然后把物体框给输出来。最后对输出后的物理框做分类,分类方法还是使用传统的CNN。所以它的创新过程主要体现在中间的矩形框,这也是创新最成功的地方。

接下来再给大家简单的介绍一下一步法。一步法中代表性的算法主要是YOLO和SSD。YOLO的英文全称是You
Only Look Once,它只需要把图片扫描一次,就能把物体检测出来。它最大的优点是速度比较快,但缺点是精准度比较差。这是YOLO的整个框架,它的核心点是中间的这个大的矩形框。它会把响应图划分为S
*S个格子,然后会预测物体框的中心坐标与大小,以及是否有物体的置信度,还会预测这个格子在每个物体类别的概率。所以,我们可以看到YOLO框架的整个核心思想和Faster
R-CNN 里面的 Region Proposal Networks是有很多相似之处的。
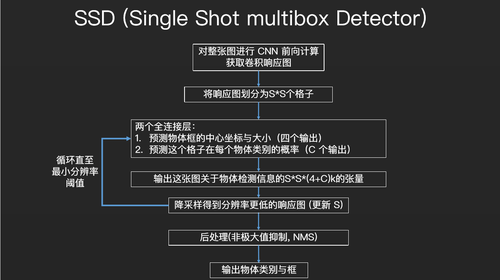
目前用的比较多的另一种目标检测算法是SSD,它是大家做物理检测用的最多的算法。它是对YOLO的一种改进,一项重要的改进就是把YOLO的两个全连接层变得了一种循环的模式。它首先会从一张比较大的图片中寻找物体框,判断物体的类别,然后把整个图片缩小,继续寻找物体框和类别,再缩小,以此循环不断缩小图片的分辨率。最终将这些物体的类别与框输出来。这样的优点是,它能够获取不同尺度下图片中物体的信息,不管是大物体还是小物体,不管物体的尺寸、长宽比怎样,它都能推测出来。
复杂场景中的文本识别

文本识别在饿了么有很多的应用场景,第一个就是证件识别,饿了么平台有大量的身份证,健康证、营业执照、卫生许可证等。首先我们要做识别,其次要做一些类似于防伪的检测,例如证件照是否被ps等,这些都是我们OCR常用的场景。
第二个应用就是门头照的识别,我们要求商户上传自己的门头照,查看商户大概的用餐环境,但是很多商户可能将别人的门头照上传到自己的,这个时候我们就需要用文本识别的手段去把门头照里面的信息提取出来,与商户的信息进行比对,确保商户上传的门头照是真实的。
第三个应用是票据识别,第一种是小票,例如饿了么的物流小票、商户提供的水单等。其次饿了么业务会涉及到新零售,新零售背后有很长的供应链。在供应链中,饿了么的工作人员经常会用纸质的报表对商品进行整理。线下的这些文本如果要逐一录入到系统之中,需要很大的工作量,所以就需要用文本识别的方式进行检测和识别。
最后一个应用场景是刚才提到过的菜单识别。第一个是字体的匹配,因为菜单的字体是千奇百怪的,即便我们能识别200种字体,但有的菜单字体我们也是没有见过的。另外还有菜名识别和价格识别,都是OCR中需要做的。

下面介绍一下传统的OCR技术。OCR这个词早在八九十年代就被提出,它是光学字符识别的缩写(Optical
Character Recognition)。光学字符识别,顾名思义它主要针对印刷体,比如报纸、书本等。传统的OCR技术主要分为两步。第一步是传统的图像处理技术,比如几何校正,对比度调整,连通域分析,投影分析等。第二步是统计机器学习,最常见的是SVM和AdaBoost两种模型,这两种模型会把最终的字符给识别出来。
一般来讲,如果印刷体在光照非常好的情况下,传统的OCR取得的效果相对比较好。但今天我们的主题是线上线下场景中的图像识别,实际上在这种场景之中,我们发现传统的OCR的效果就比较差。因为在线上线下融合场景中,大多数的文字都是用手机拍摄,手机拍摄就会涉及角度、光线各方面的影响,它实际上是不规范的。另外,实际生活上应用的文本不会像印刷体那样横平竖直,它的排列方式、颜色、字体大小等都是千奇百怪的。识别这样的不规范的照片,传统的OCR就会遇到一些问题。
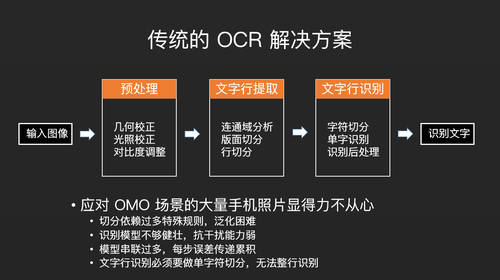
传统的OCR解决方案主要分为三步,第一步是预处理,第二步是文字行提取,第三步是文字行识别。特别要注意的是文字行识别的时候,传统的OCR实际上没法识别正常的文字,它只能一个字符一个字符的识别。所以识别到文字行之后,它首先要对文字行进行切割,还要把文字行切割为字符,然后对单个字符进行识别。

但在生活场景中,我们往往面对的是这样的一些图片,如何在这样的图片中来做文本识别?
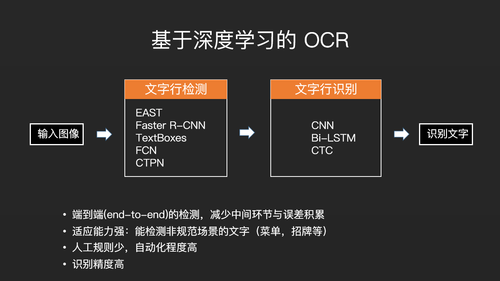
现在比较常用的是基于深度学习的OCR。它一般分为两步,第一步是文字行检测,是指从一张图片中把对应的文字行找出来。因为文字行包含在图片之中,它可能是斜的,也可能是竖着的。第二步是文字行识别,现在基于深度学习的文字行识别一般是一种端到端的方式,也就是说我们并不需要把文字行切割为单字符然后进行分类,而是我们输入一个文字行图片,直接就会出来一个文字序列,中间不需要做文字符切割,这就是现在的深度学习技术的一个最大的改进。基于深度学习的文字行识别,它有一些好处。第一个,它是端到端的检测,能减少中间环节与误差积累。第二,它的适应能力比较强,它不光能识别报纸、杂志文本,还能识别招牌、菜单等文本。第三,它的人工规则比较少,自动化程度比较高。第四,它的识别精度高。
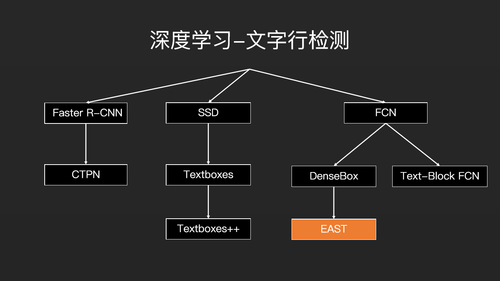
深度学习我们分为两部分,第一部分是文字行的检测,第二部分是文字行的识别。文字行检测的主流技术主要是三条线在走。第一条线是基于Faster
R-CNN做文字行检测。第二条线是基于SSD,第三条线是基于全卷积网络FCN做图片的语义分割,然后基于语义分割再做文字行检测。目前基本上所有的基于深度学习的文字行检测算法,都是沿着这三条线在做优化。
基于Faster R-CNN的文本识别方法,比较有名的是CTPN,基于 SSD上的是Textboxes和Textboxe++。另外,基于FCN还有Text-Block
FCN。我这里主要想强调的是EAST,因为目前为止,综合比较之下,EAST是最好的,因为它能发现任意形状的四边形,无论是斜的还是歪的都可以检测。
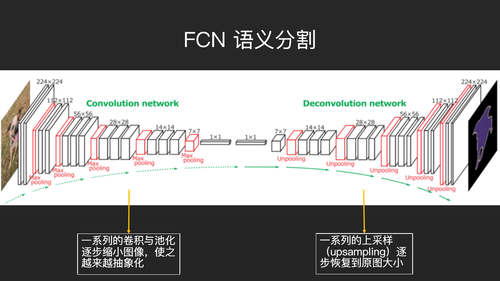
在介绍EAST算法之前先简单的介绍一下全卷积网络(FCN)。FCN主要是做语义分割,什么是语义分割?我们刚才说的目标检测是指找出一个矩形框,物体框在里面,而语义分割是对图片进行分割,分割成几块,在每一块上面打一个标识符。FCN的一个核心特点就是会先做卷积,再做反卷积。卷积会把这个图像不断的缩小,通过卷积和池化,图像的特征会逐渐的聚拢,图像会越来越抽象化,大小和分辨率会越来越低。当低到一定程度之后,它会做一个反卷积操作,这个反卷积操作采用称之为upsampling,把图像又逐步放大。由于
FCN 的形状长得像 U 型,所以 FCN 的一个变种又称为U-Net。

接下来简单介绍一下EAST算法。EAST算法是基于FCN,全称是Efficient and Accurate
Scene Text Detector,它最大的卖点是可以检测任意形状的四边形。下面有两张图片示例,左边是一张广告,通过EAST之后,不管字体是斜的还是歪的都能被检测出来,右边也是如此。它的检测结果是一种任意形状的四边形,连接四个顶点,构成一个四边的框,把文本框在里面,所以EAST算法的通用能力非常强。
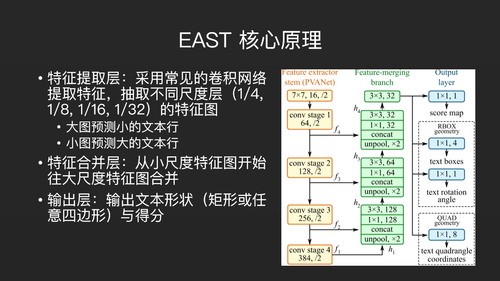
这是EAST模型的核心原理。从区域来看,它的整个网络结构被分为左边的黄色,中间的绿色和右边的蓝色。黄色部分是卷积操作,不断把图像缩小,通过卷积操作不断提取特征。它通过卷积操作把图像分为四层,分别把图像划分为原来的1/4、1/8、1/16和1/32,然后再基于每一层,进行特征合并。
中间绿色部分是从下往上执行,它会把这一层和上一层CNN抽取的特征首尾相连构成一个新向量。最后获取最上方的最大特征向量,基于这个特征向量再次寻找物体框。找出来的物体框分为两种,第一种称之为RBOX,它是一个矩形,边角是直角,但它可以旋转。第二种称之为QUAD,是一个任意的四边形。
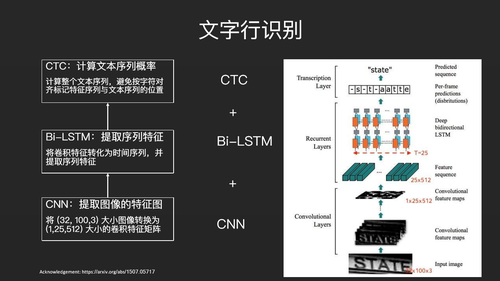
接下来我们来介绍文字行识别。目前最流行的文字行识别是CNN+Bi-LSTM+CTC的方式。所以这张PPT应该从下往上看,首先输入一张图片,通过CNN提取图像特征图,然后把图像的特征视为一种时间序列,再通过Bi-LSTM提取序列特征。两波特征提取之后,最后再通过CTC计算最终文本序列的概率。
这个算法设计的特别巧妙,巧妙之处在于它运用了不同方面的技术来解决问题:CNN是用来做图像分类的,Bi-LSTM一般做文本的挖掘与自然语言处理。而CTC一般是用来做语音识别。所以它相当于把图像识别、文本识别、语音识别三项技术结合在一起做文字行的识别。
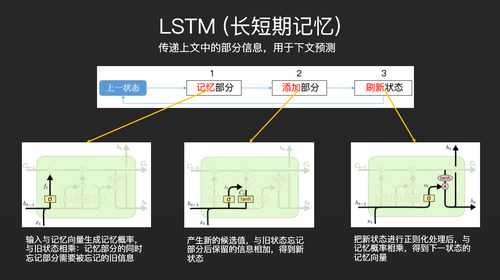
CNN 的原理不再细说。LSTM的整个原理其实非常简单,这几个框图就能解释。首先它是循环的,每个循环会做三个操作,第一步,它会把上一状态记忆一部分,同时忘记一部分,称之为记忆部分,也就是左下角这个图,它通过一个记忆向量生成记忆概率,然后把旧状态的部分信息记忆下来,同时旧状态的部分信息也会被忘掉。第二步,它会产生新的候选值,然后把旧状态记下来的信息和新的候选值加起来,得到一个新的状态,也就是添加部分。第三步,刷新状态,即刷新过去的记忆向量。
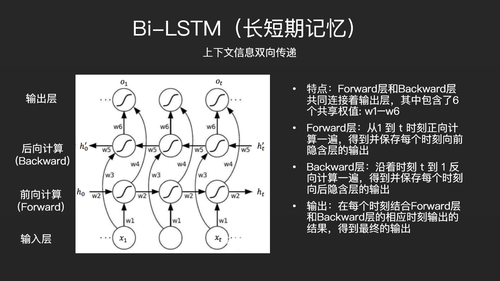
在实际场景中,我们用的最多的是Bi-LSTM,也就是双向的LSTM。双向的LSTM不光上文的信息能够传递到下文,下文的信息也可以反向传递到上文。所以它的结构分成了两层,一层是Forward,一层是Backward,Forward层会从1时刻往t时刻计算,Backward层会从t时刻往1时刻计算。每一次输出就等于把Forward层输出和Backward层输出合并起来,这就是双向LSTM的核心思想。

最后到了CTC的环节。CTC中文全称是连接主义时序分类器。它的整个原理比较简单,传统的语音识别中,上面是一段声纹,下面是识别出来的文本。但声音序列和文本序列肯定是不对齐的,比如声音是十秒钟,文本只出了五个字,在打标签的时候就会涉及到声波的波峰对应哪个字符的问题,找对应关系是非常麻烦的。而CTC可以不用去找这些对应关系,它是序列的识别,做声音识别的时候,它不会把声音切割成单个音符再做识别,而是把整个声音作为一个主体,再输出对应。它在里面加了一些填充字符,一个小写的E,这个E就是一个空字符。填充完之后,再对序列进行识别,然后做分类。

这是一个CTC大概的处理流程。 首先CTC接收的是双向的LSTM输出,即一个向量,它要对向量进行分类,传统的分类没有空白字符,CTC首先会把空白字符加到字符集里,完成步长特征到字符的分类。然后开始计算每个字符序列的出现概率,并输出最大概率对应的字符序列。所以它并不会去计算每个字符的概率,而是计算整个序列的概率。最后把空白符号和预测出的重复符号消除掉,做一些后处理,然后输出。
复杂场景中的三维重建
三维重建其实是3D视觉的子领域,是一门非常古老的学科,远在深度学习开始之前,就已经存在了大量的三维重建方面的研究。但在近几年随着无人驾驶的兴起,视觉导航得到了长足的发展。包括近期VR和AR发展,在这个领域我们又看到了大量的基于三维重建的应用。
接下来主要给大家介绍的是三维重建领域的一些核心技术。
饿了么一直在无人配送领域进行着研究,三维重建是该领域的一项非常核心的技术,基于今天的演讲主题,我们主要从图像视觉的角度去分析三维重建,而不涉及到激光雷达的点云信息。
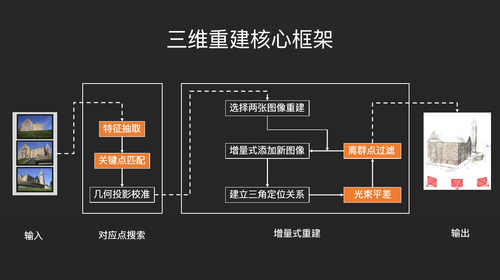
如何从大量的图片中完成一个三维重建的过程?下面我们介绍一个最常用也是最核心的应用,假设你对一个物体拍摄了大量的照片,你如何从这些照片中提取出这个物体的3D模型?这张框架图就给大家展示了一个大概过程。第一步,图像特征抽取,这里提取的特征跟CNN提取的特征不一样,这里提取的主要是一些具有空间尺度不变性的角点特征,所以角点特征抽取的算法一般不用CNN。第二步,特征点匹配,这涉及到大量的匹配方法。第三步,投影校准,因为这些图片都是由摄像机拍出来的,所以需要对相机参数进行一些校准。最后进入三维重建过程。
进入三维重建,首先我们需要选择两张角度比较合适的图片作为一个起始,然后进入下面的循环环节。循环环节分为四步,第一步,增量式的往里面添加新的图像,即添加新的信息。第二部,添加新的三角定位关系。因为每往里面添加一张新的图像,这张图像里的新的特征就会和旧的图像之间建立一种三角定位关系。第三步是一项非常重要的操作,称之为光束平差。早期的光束平差是对摄像机参数的预估。光束平差是一个非常古老的算法,已经有将近100年的历史。它会对相机的参数进行一些最优化,然后我们进行离群点过滤,把那些匹配出错的地方去掉。去掉之后,再往里面添加一张新的图像,这样不断的循环,整个3D模型就能增量式的被勾勒出来。
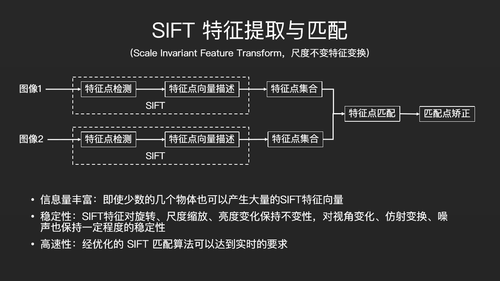
最后,我们介绍一下三维重建里的特征提取以及相机参数的优化。特征提取最常用的是SIFT特征,它具有尺度不变性,你可以对它进行旋转、缩放,甚至对光线进行明亮度调整,它的特征都不会发生变化。SIFT特征有很多优点,例如给它一张图像,它能产生大量的匹配特征。它也有一些缺点,例如它的速度如果不进行优化,就无法满足实时的需求。
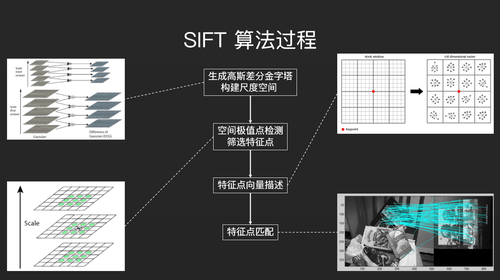
这是对SIFT做特征提取和匹配的一个简单介绍。
第一步,生成高斯差分金字塔,构建尺度空间。第二步,在金字塔里面寻找空间极值点,什么是空间极值点?即如果一个像素的值比它附近的像素的值都大或者小,那么这个像素点就称之为空间的极值点。我们需要把空间极值点找出来,去掉不要的空间极值点。第二步,进行特征点向量描述。这个向量描述用的是128位的向量描述,即把像素周围16×16
的像素取出来,再把它按照4×4的规模分成小格子(见右上角图),每个格子里会求它的梯度,梯度会在八个方向上取值形成一个梯度直方图。梯度直方图全部拼起来会形成一个128位的向量。第三步,基于128位的向量做特征点匹配(也就是下面这个过程)。但是匹配过程很容易出错,因为A图片中的某一点和B图片中的某一点很可能长得很像,所以这里会涉及到大量的优化操作。
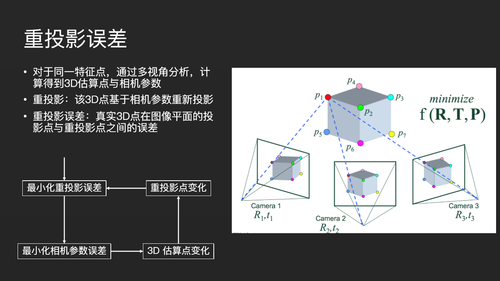
对于优化,有一个非常重要的概念叫做重投影误差。什么是重投影误差?即对于空间中的一点,经过多视角的分析,得到它在空间中的一个坐标系XYZ,以及一套相机参数。这和人眼来看世界是非常相似的,我们左眼看到一张图像,右眼看到一张图像,基于这两张图像构建出空间中的XYZ。但构建出的空间点是有误差的,因为涉及到相机旋转角度、拍摄位移等问题,我们估算出来的相机参数是不准的。而我们基于估算出的相机参数重新拍照,由于参数估算不准,两张图像会出现误差,这个误差就叫做重投影误差。
我们的目标就是要最小化重投影误差,最小化相机参数的误差。假设我们已经把相机参数最小化了,实际上我们基于相机参数所估算的三维空间点也会发生变化,所以重投影误差也会发生变化,它是一个循环动态的优化过程,整个优化过程有个非常专业的术语叫做光束平差。
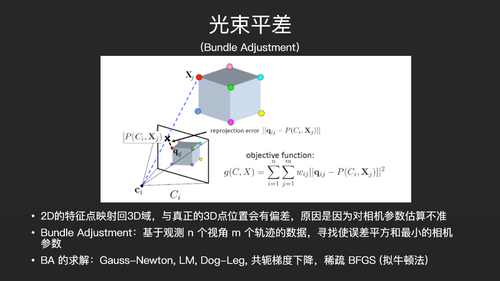
光束平差,Bundle Adjustment。它其实就是一个做大型线性规划的算法。我们从每一张照片中记录每一个视角和每一个轨迹,都会得到一个误差值。最终我们要最小化误差的平方和。求解误差平方和最小的方法,传统的机器学习是用梯度下降法,这里也跟这个方法类似。当然用梯度误差法,它的速度是无法满足实时要求的。最新的方法是稀疏BFGS。稀疏BFGS是一种拟牛顿法,要做二阶泰勒展开。拟牛顿法是一种近似的牛顿法,稀疏BFGS是大规模稀疏矩阵中的一种快速的优化算法。

最后涉及到对匹配的错误点进行过滤。比较传统的算法称之为RANSAC。RANSAC过滤算法有个最大的优点,即假设你的数据集中超过50%的点都是噪点,那么一般情况下普通的算法是完成不了分类和聚类的,但RANSAC算法就可以。它的算法思想,就是抽样部分点构建最优模型,统计适应于该模型的点数,反复抽样若干次,选择点数最高的模型。
整个从特征点提取,到光束平差,到RANSAC的过程听起来非常复杂,但这有一个非常简单的应用例子。假设你用手机拍了两张不同的照片,两张照片的视角,旋转方向都是不一致的。但如果你通过SIFT特征以及Bundle
Adjustment,包括刚才的RANSAC,这一套流程下来最后完成两张图片的拼接,得到图中的第二张图片。其实它不是真的而是歪的,把它经过适当的旋转之后,就能和第一张图片拼装起来。

|









