| БрМЭЦМі: |
БОЮФРДздМђЪщЃЌБОЮФНЋНщЩмЩёОЭјТчЕФЯрЙижЊЪЖЁЃЖСКѓФуНЋЖдЩёОЭјТчгаИіДѓИХСЫНт,ЫќЪЧШчКЮЙЄзїЕФ?ШчКЮДДНЈЩёОЭјТч?
|
|
НВЕФКмКУЃЌЧГЯдвзЖЎЃЌШыУХЪзбЁЃЌ ЖјЧвдкgithubгаДњТыЃЌ
ЯыПДЪгЦЕЕФвВПЩвдШЅЫћЕФгХПсРяЕФЦЕЕРевЁЃ
Tensorflow ЙйЭј
ЩёОЭјТчЪЧвЛжжЪ§бЇФЃаЭЃЌЪЧДцдкгкМЦЫуЛњЕФЩёОЯЕЭГЃЌгЩДѓСПЕФЩёОдЊЯрСЌНгВЂНјааМЦЫуЃЌдкЭтНчаХЯЂЕФЛљДЁЩЯЃЌИФБфФкВПЕФНсЙЙЃЌГЃгУРДЖдЪфШыКЭЪфГіМфИДдгЕФЙиЯЕНјааНЈФЃЁЃ
ЩёОЭјТчгЩДѓСПЕФНкЕуКЭжЎМфЕФСЊЯЕЙЙГЩЃЌИКд№ДЋЕнаХЯЂКЭМгЙЄаХЯЂЃЌЩёОдЊвВПЩвдЭЈЙ§бЕСЗЖјБЛЧПЛЏЁЃ
етИіЭМОЭЪЧвЛИіЩёОЭјТчЯЕЭГЃЌЫќгЩКмЖрВуЙЙГЩЁЃЪфШыВуОЭЪЧИКд№НгЪеаХЯЂЃЌБШШчЫЕвЛжЛУЈЕФЭМЦЌЁЃЪфГіВуОЭЪЧМЦЫуЛњЖдетИіЪфШыаХЯЂЕФШЯжЊЃЌЫќЪЧВЛЪЧУЈЁЃвўВиВуОЭЪЧЖдЪфШыаХЯЂЕФМгЙЄДІРэЁЃ
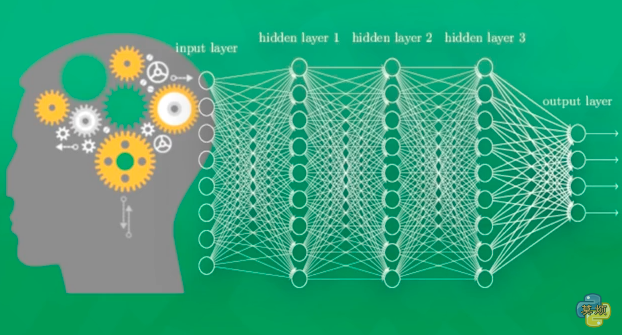
ЩёОЭјТчЪЧШчКЮБЛбЕСЗЕФЃЌЪзЯШЫќашвЊКмЖрЪ§ОнЁЃБШШчЫћвЊХаЖЯвЛеХЭМЦЌЪЧВЛЪЧУЈЁЃОЭвЊЪфШыЩЯЧЇЭђеХЕФДјгаБъЧЉЕФУЈУЈЙЗЙЗЕФЭМЦЌЃЌШЛКѓдйбЕСЗЩЯЧЇЭђДЮЁЃ
ЩёОЭјТчбЕСЗЕФНсЙћгаЖдЕФвВгаДэЕФЃЌШчЙћЪЧДэЮѓЕФНсЙћЃЌНЋБЛЕБзіЗЧГЃБІЙѓЕФОбщЃЌФЧУДЪЧШчКЮДгОбщжабЇЯАЕФФиЃПОЭЪЧЖдБШе§ШЗД№АИКЭДэЮѓД№АИжЎМфЕФЧјБ№ЃЌШЛКѓАбетИіЧјБ№ЗДЯђЕФДЋЕнЛиШЅЃЌЖдУПИіЯргІЕФЩёОдЊНјаавЛЕуЕуЕФИФБфЁЃФЧУДЯТвЛДЮдкбЕСЗЕФЪБКђОЭПЩвдгУвбОИФНјвЛЕуЕуЕФЩёОдЊШЅЕУЕНЩдЮЂзМШЗвЛЕуЕФНсЙћЁЃ
ЩёОЭјТчЪЧШчКЮбЕСЗЕФФиЃПУПИіЩёОдЊЖМгаЪєгкЫќЕФМЄЛюКЏЪ§ЃЌгУетаЉКЏЪ§ИјМЦЫуЛњвЛИіДЬМЄааЮЊЁЃ
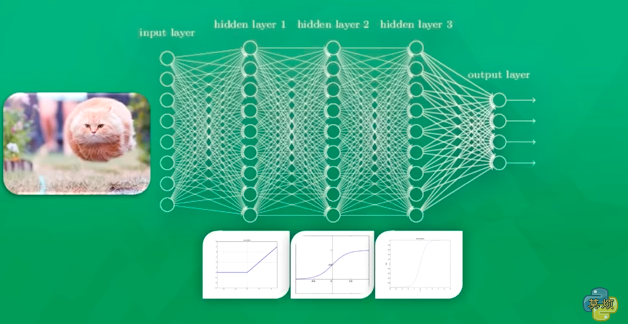
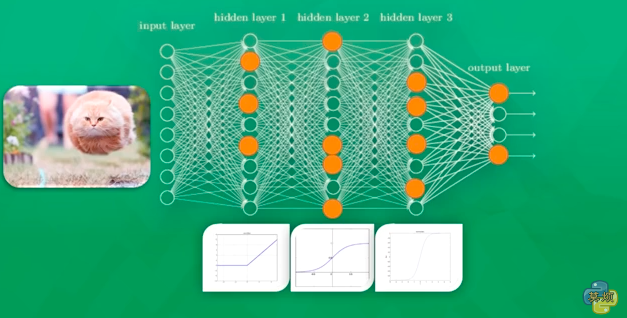
дкЕквЛДЮИјМЦЫуЛњПДУЈЕФЭМЦЌЕФЪБКђЃЌжЛгаВПЗжЕФЩёОдЊБЛМЄЛюЃЌБЛМЄЛюЕФЩёОдЊЫљДЋЕнЕФаХЯЂЪЧЖдЪфГіНсЙћзюгаМлжЕЕФаХЯЂЁЃШчЙћЪфГіЕФНсЙћБЛХаЖЈЮЊЪЧЙЗЃЌвВОЭЪЧЫЕЪЧДэЮѓЕФСЫЃЌФЧУДОЭЛсаоИФЩёОдЊЃЌвЛаЉШнвзБЛМЄЛюЕФЩёОдЊЛсБфЕУГйЖлЃЌСэЭтвЛаЉЩёОдЊЛсБфЕУУєИаЁЃетбљвЛДЮДЮЕФбЕСЗЯТШЅЃЌЫљгаЩёОдЊЕФВЮЪ§ЖМдкБЛИФБфЃЌЫќУЧБфЕУЖдеце§живЊЕФаХЯЂИќЮЊУєИаЁЃ

**Tensorflow **ЪЧЙШИшПЊЗЂЕФЩюЖШбЇЯАЯЕЭГЃЌгУЫќПЩвдКмПьЫйЕиШыУХЩёОЭјТчЁЃ
ЫќПЩвдзіЗжРрЃЌвВПЩвдзіФтКЯЮЪЬтЃЌОЭЪЧвЊАбетИіФЃЪНИјФЃФтГіРДЁЃ

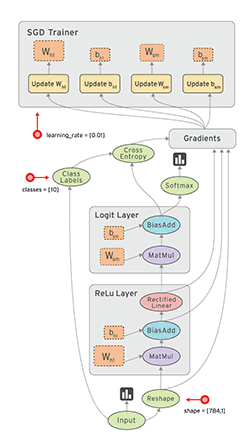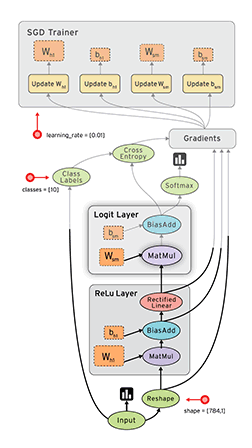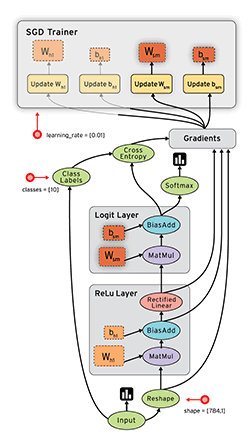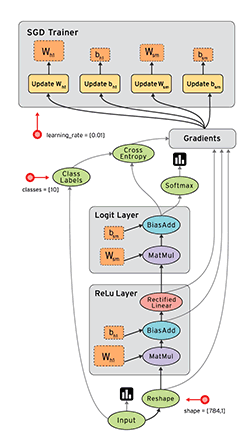
етЪЧвЛИіЛљБОЕФЩёОЭјТчЕФНсЙЙЃЌгаЪфШыВуЃЌвўВиВуЃЌКЭЪфГіВуЁЃ
УПвЛВуЕуПЊЖМгаЫќЯргІЕФФкШнЃЌКЏЪ§КЭЙІФмЁЃ
ФЧЮвУЧвЊзіЕФОЭЪЧвЊНЈСЂвЛИіетбљЕФНсЙЙЃЌШЛКѓАбЪ§ОнЮЙНјШЅЁЃ
АбЪ§ОнЗХНјШЅКѓЫќОЭПЩвдздМКдЫааЃЌTensorFlow ЗвыЙ§РДОЭЪЧЯђСПдкРяУцЗЩЁЃ
етИіЖЏЭМЕФНтЪЭОЭЪЧЃЌдкЪфШыВуЪфШыЪ§ОнЃЌШЛКѓЪ§ОнЗЩЕНвўВиВуЗЩЕНЪфГіВуЃЌгУЬнЖШЯТНЕДІРэЃЌЬнЖШЯТНЕЛсЖдМИИіВЮЪ§НјааИќаТКЭЭъЩЦЃЌИќаТКѓЕФВЮЪ§дйДЮХмЕНвўВиВуШЅбЇЯАЃЌетбљвЛжБбЛЗжБЕННсЙћЪеСВЁЃ
tensors_flowing.gif
НёЬьвЛПкЦјАбећИіЯЕСаЖМбЇЭъСЫЃЌЯШРДвЛЖЮЭъећЕФДњТыЃЌШЛКѓНтЪЭживЊЕФжЊЪЖЕуЃЁ
1. ДюНЈЩёОЭјТчЛљБОСїГЬ
ЖЈвхЬэМгЩёОВуЕФКЏЪ§
1.бЕСЗЕФЪ§Он
2.ЖЈвхНкЕузМБИНгЪеЪ§Он
3.ЖЈвхЩёОВуЃКвўВиВуКЭдЄВтВу
4.ЖЈвх loss БэДяЪН
5.бЁдё optimizer ЪЙ loss ДяЕНзюаЁ
ШЛКѓЖдЫљгаБфСПНјааГѕЪМЛЏЃЌЭЈЙ§ sess.run optimizerЃЌЕќДњ
1000 ДЮНјаабЇЯАЃК
import tensorflow
as tf
import numpy as np
# ЬэМгВу
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of
this layer
Weights = tf.Variable(tf.random_normal([in_size,
out_size]))
biases = tf.Variable(tf.zeros([1, out_size])
+ 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
# 1.бЕСЗЕФЪ§Он
# Make up some real data
x_data = np.linspace(-1,1,300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# 2.ЖЈвхНкЕузМБИНгЪеЪ§Он
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
# 3.ЖЈвхЩёОВуЃКвўВиВуКЭдЄВтВу
# add hidden layer ЪфШыжЕЪЧ xsЃЌдквўВиВуга 10 ИіЩёОдЊ
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer ЪфШыжЕЪЧвўВиВу l1ЃЌдкдЄВтВуЪфГі 1 ИіНсЙћ
prediction = add_layer(l1, 10, 1, activation_function=None)
# 4.ЖЈвх loss БэДяЪН
# the error between prediciton and real data
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys
- prediction),
reduction_indices=[1]))
# 5.бЁдё optimizer ЪЙ loss ДяЕНзюаЁ
# етвЛааЖЈвхСЫгУЪВУДЗНЪНШЅМѕЩй lossЃЌбЇЯАТЪЪЧ 0.1
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# important step ЖдЫљгаБфСПНјааГѕЪМЛЏ
init = tf.initialize_all_variables()
sess = tf.Session()
# ЩЯУцЖЈвхЕФЖМУЛгадЫЫуЃЌжБЕН sess.run ВХЛсПЊЪМдЫЫу
sess.run(init)
# ЕќДњ 1000 ДЮбЇЯАЃЌsess.run optimizer
for i in range(1000):
# training train_step КЭ loss ЖМЪЧгЩ placeholder
ЖЈвхЕФдЫЫуЃЌЫљвдетРявЊгУ feed ДЋШыВЮЪ§
sess.run(train_step, feed_dict={xs: x_data,
ys: y_data})
if i % 50 == 0:
# to see the step improvement
print(sess.run(loss, feed_dict={xs: x_data,
ys: y_data}))
|
2. жївЊВНжшЕФНтЪЭЃК
жЎЧАаДЙ§вЛЦЊЮФеТ TensorFlow ШыУХ НВСЫ tensorflow
ЕФАВзАЃЌетРяЪЙгУЪБжБНгЕМШыЃК
import tensorflow
as tf
import numpy as np |
ЕМШыЛђепЫцЛњЖЈвхбЕСЗЕФЪ§Он x КЭ yЃК
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3 |
ЯШЖЈвхГіВЮЪ§ WeightsЃЌbiasesЃЌФтКЯЙЋЪН yЃЌЮѓВюЙЋЪН
lossЃК
Weights = tf.Variable(tf.random_uniform([1],
-1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases
loss = tf.reduce_mean(tf.square(y-y_data))
|
бЁдё Gradient Descent етИізюЛљБОЕФ OptimizerЃК
| optimizer = tf.train.GradientDescentOptimizer(0.5) |
ЩёОЭјТчЕФ key ideaЃЌОЭЪЧШУ loss ДяЕНзюаЁЃК
| train = optimizer.minimize(loss) |
ЧАУцЪЧЖЈвхЃЌдкдЫааФЃаЭЧАЯШвЊГѕЪМЛЏЫљгаБфСПЃК
| init = tf.initialize_all_variables() |
НгЯТРДАбНсЙЙМЄЛюЃЌsesseionЯёвЛИіжИеыжИЯђвЊДІРэЕФЕиЗНЃК
init ОЭБЛМЄЛюСЫЃЌВЛвЊЭќМЧМЄЛюЃК
бЕСЗ201ВНЃК
вЊбЕСЗ trainЃЌвВОЭЪЧ optimizerЃК
УП 20 ВНДђгЁвЛЯТНсЙћЃЌsess.run жИЯђ WeightsЃЌbiases
ВЂБЛЪфГіЃК
if step % 20
== 0:
print(step, sess.run(Weights), sess.run(biases)) |
ЫљвдЙиМќЕФОЭЪЧ yЃЌlossЃЌoptimizer ЪЧШчКЮЖЈвхЕФЁЃ
3. TensorFlow ЛљБОИХФюМАДњТыЃК
дк TensorFlow ШыУХ вВЬсЕНСЫМИИіЛљБОИХФюЃЌетРяЪЧМИИіГЃМћЕФгУЗЈЁЃ
Session
ОиеѓГЫЗЈЃКtf.matmul
| product = tf.matmul(matrix1,
matrix2) # matrix multiply np.dot(m1, m2) |
ЖЈвх SessionЃЌЫќЪЧИіЖдЯѓЃЌзЂвтДѓаДЃК
result вЊШЅ sess.run ФЧРяШЁНсЙћЃК
| result = sess.run(product) |
Variable
гУ tf.Variable ЖЈвхБфСПЃЌгыpythonВЛЭЌЕФЪЧЃЌБиаыЯШЖЈвхЫќЪЧвЛИіБфСПЃЌЫќВХЪЧвЛИіБфСПЃЌГѕЪМжЕЮЊ0ЃЌЛЙПЩвдИјЫќвЛИіУћзж
counterЃК
| state = tf.Variable(0,
name='counter') |
НЋ new_value МгдиЕН state ЩЯЃЌcounterОЭБЛИќаТЃК
| update = tf.assign(state,
new_value) |
ШчЙћгаБфСПОЭвЛЖЈвЊзіГѕЪМЛЏЃК
| init = tf.initialize_all_variables()
# must have if define variable |
placeholderЃК
вЊИјНкЕуЪфШыЪ§ОнЪБгУ placeholderЃЌдк TensorFlow жагУplaceholder
РДУшЪіЕШД§ЪфШыЕФНкЕуЃЌжЛашвЊжИЖЈРраЭМДПЩЃЌШЛКѓдкжДааНкЕуЕФЪБКђгУвЛИізжЕфРДЁАЮЙЁБетаЉНкЕуЁЃЯрЕБгкЯШАбБфСП
hold зЁЃЌШЛКѓУПДЮДгЭтВПДЋШыdataЃЌзЂвт placeholder КЭ feed_dict ЪЧАѓЖЈгУЕФЁЃ
етРяМђЕЅЬсвЛЯТ feed ЛњжЦЃЌ Иј feed ЬсЙЉЪ§ОнЃЌзїЮЊ run()
ЕїгУЕФВЮЪ§ЃЌ feed жЛдкЕїгУЫќЕФЗНЗЈФкгааЇ, ЗНЗЈНсЪј, feed ОЭЛсЯћЪЇЁЃ
| import tensorflow
as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
ouput = tf.mul(input1, input2)
with tf.Session() as sess:
print(sess.run(ouput, feed_dict={input1: [7.],
input2: [2.]})) |
4. ЩёОЭјТчЛљБОИХФю
МЄРјКЏЪ§ЃК
Р§ШчвЛИіЩёОдЊЖдУЈЕФблОІУєИаЃЌФЧЕБЫќПДЕНУЈЕФблОІЕФЪБКђЃЌОЭБЛМЄРјСЫЃЌЯргІЕФВЮЪ§ОЭЛсБЛЕїгХЃЌЫќЕФЙБЯзОЭЛсдНДѓЁЃ
ЯТУцЪЧМИжжГЃМћЕФМЄЛюКЏЪ§ЃК
xжсБэЪОДЋЕнЙ§РДЕФжЕЃЌyжсБэЪОЫќДЋЕнГіШЅЕФжЕЃК
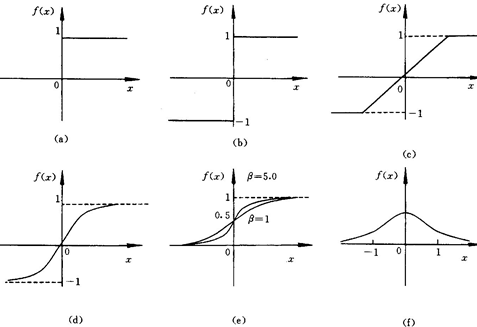
МЄРјКЏЪ§дкдЄВтВуЃЌХаЖЯФФаЉжЕвЊБЛЫЭЕНдЄВтНсЙћФЧРяЃК
TensorFlow ГЃгУЕФ activation function
ЬэМгЩёОВуЃК
ЪфШыВЮЪ§га inputs, in_size, out_size,
КЭ activation_function
| import tensorflow
as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size,
out_size]))
biases = tf.Variable(tf.zeros([1, out_size])
+ 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs |
ЗжРрЮЪЬтЕФ loss КЏЪ§ cross_entropy ЃК
# the error between
prediction and real data
# loss КЏЪ§гУ cross entropy
cross_entropy = tf.reduce_mean (-tf.reduce_sum(ys
* tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.GradientDescentOptimizer(0.5) .minimize(cross_entropy) |
overfittingЃК
ЯТУцЕкШ§ИіЭМОЭЪЧ overfittingЃЌОЭЪЧЙ§ЖШзМШЗЕиФтКЯСЫРњЪЗЪ§ОнЃЌЖјЖдаТЪ§ОндЄВтЪБОЭЛсгаКмДѓЮѓВюЃК
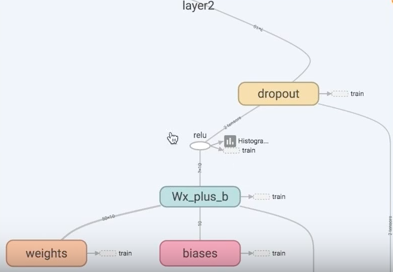
Tensorflow гавЛИіКмКУЕФЙЄОп, Назіdropout, жЛашвЊИјгшЫќвЛИіВЛБЛ drop ЕєЕФАйЗжБШЃЌОЭФмКмКУЕиНЕЕЭ
overfittingЁЃ
dropout ЪЧжИдкЩюЖШбЇЯАЭјТчЕФбЕСЗЙ§ГЬжаЃЌАДеевЛЖЈЕФИХТЪНЋвЛВПЗжЩёОЭјТчЕЅдЊднЪБДгЭјТчжаЖЊЦњЃЌЯрЕБгкДгдЪМЕФЭјТчжаевЕНвЛИіИќЪнЕФЭјТчЃЌетЦЊВЉПЭжаНВЕФЗЧГЃЯъЯИ
ДњТыЪЕЯжОЭЪЧдк add layer КЏЪ§РяМгЩЯ dropout, keep_prob ОЭЪЧБЃГжЖрЩйВЛБЛ
dropЃЌдкЕќДњЪБдк sess.run жаБЛ feed:
def add_layer(inputs,
in_size, out_size, layer_name, activation_function=None,
):
# add one more layer and return the output of
this layer
Weights = tf.Variable(tf.random_normal([in_size,
out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) +
0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# here to dropout
# дк Wx_plus_b ЩЯdropЕєвЛЖЈБШР§
# keep_prob БЃГжЖрЩйВЛБЛdropЃЌдкЕќДњЪБдк sess.run жа feed
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.histogram_summary(layer_name + '/outputs',
outputs)
return outputs |
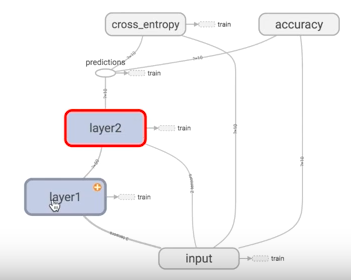
5. ПЩЪгЛЏ Tensorboard
Tensorflow здДј tensorboard ЃЌПЩвдздЖЏЯдЪОЮвУЧЫљНЈдьЕФЩёОЭјТчСїГЬЭМЃК
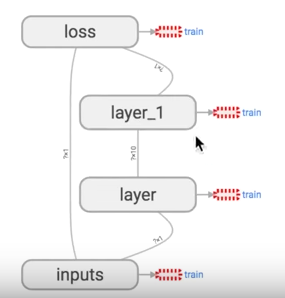
ОЭЪЧгУ with tf.name_scope ЖЈвхИїИіПђМмЃЌзЂвтПДДњТызЂЪЭжаЕФЧјБ№ЃК
| import tensorflow
as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of
this layer
# ЧјБ№ЃКДѓПђМмЃЌЖЈвхВу layerЃЌРяУцга аЁВПМў
with tf.name_scope('layer'):
# ЧјБ№ЃКаЁВПМў
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size,
out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size])
+ 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights),
biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
# ЧјБ№ЃКДѓПђМмЃЌРяУцга inputs xЃЌy
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediciton and real data
# ЧјБ№ЃКЖЈвхПђМм loss
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys
- prediction),
reduction_indices=[1]))
# ЧјБ№ЃКЖЈвхПђМм train
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
# ЧјБ№ЃКsess.graph АбЫљгаПђМмМгдиЕНвЛИіЮФМўжаЗХЕНЮФМўМа"logs/"Ря
# НгзХДђПЊterminalЃЌНјШыФуДцЗХЕФЮФМўМаЕижЗЩЯвЛВуЃЌдЫааУќСю tensorboard
--logdir='logs/'
# ЛсЗЕЛивЛИіЕижЗЃЌШЛКѓгУфЏРРЦїДђПЊетИіЕижЗЃЌдк graph БъЧЉРИЯТДђПЊ
writer = tf.train.SummaryWriter("logs/",
sess.graph)
# important step
sess.run(tf.initialize_all_variables()) |
дЫааЭъЩЯУцДњТыКѓЃЌДђПЊ terminalЃЌНјШыФуДцЗХЕФЮФМўМаЕижЗЩЯвЛВуЃЌдЫааУќСю tensorboard
--logdir='logs/' КѓЛсЗЕЛивЛИіЕижЗЃЌШЛКѓгУфЏРРЦїДђПЊетИіЕижЗЃЌЕуЛї graph БъЧЉРИЯТОЭПЩвдПДЕНСїГЬЭМСЫЃК

6. БЃДцКЭМгди
бЕСЗКУСЫвЛИіЩёОЭјТчКѓЃЌПЩвдБЃДцЦ№РДЯТДЮЪЙгУЪБдйДЮМгдиЃК
import tensorflow
as tf
import numpy as np
## Save to file
# remember to define the same dtype and shape
when restore
W = tf.Variable([[1,2,3],[3,4,5]], dtype=tf.float32,
name='weights')
b = tf.Variable([[1,2,3]], dtype=tf.float32,
name='biases')
init= tf.initialize_all_variables()
saver = tf.train.Saver()
# гУ saver НЋЫљгаЕФ variable БЃДцЕНЖЈвхЕФТЗОЖ
with tf.Session() as sess:
sess.run(init)
save_path = saver.save(sess, "my_net/save_net.ckpt")
print("Save to path: ", save_path)
################################################
# restore variables
# redefine the same shape and same type for
your variables
W = tf.Variable(np.arange(6).reshape((2, 3)),
dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)),
dtype=tf.float32, name="biases")
# not need init step
saver = tf.train.Saver()
# гУ saver ДгТЗОЖжаНЋ save_net.ckpt БЃДцЕФ W КЭ b restore
НјРД
with tf.Session() as sess:
saver.restore(sess, "my_net/save_net.ckpt")
print("weights:", sess.run(W))
print("biases:", sess.run(b)) |
tensorflow ЯждкжЛФмБЃДц variablesЃЌЛЙВЛФмБЃДцећИіЩёОЭјТчЕФПђМмЃЌЫљвддйЪЙгУЕФЪБКђЃЌашвЊжиаТЖЈвхПђМмЃЌШЛКѓАб
variables ЗХНјШЅбЇЯАЁЃ
|









