| БрМЭЦМі: |
БОЮФРДздгкibmЃЌЮФеТНщЩмШчКЮАВзАКЭЩшжУ
MLflow ЛЗОГЃЌдк R жабЕСЗКЭИњзйЛњЦїбЇЯАФЃаЭЃЌНЋдДДњТыКЭЪ§ОнЗтзАдк
MLproject жаЃЌВЂЪЙгУ mlflow run УќСюдЫааЯюФПЕШЁЃ |
|
дкБОЮФеТжаЃЌЮвЛсМђвЊЕиНщЩм MLflow МАЦфЙЄзїЗНЪНЁЃMLflow
ФПЧАЬсЙЉСЫ Python жаЕФ APIЃЌФњПЩвддкЛњЦїбЇЯАдДДњТыжаЕїгУетаЉ API РДМЧТМ MLflow
ИњзйЗўЮёЦївЊИњзйЕФВЮЪ§ЁЂжИБъКЭЙЄМўЁЃ
ШчЙћФњЪьЯЄЛњЦїбЇЯАВйзїВЂдк R жажДааСЫетаЉВйзїЃЌФЧУДПЩФмЯывЊЪЙгУ MLflow РДИњзйФЃаЭКЭУПДЮдЫааЁЃФњПЩвдЪЙгУвдЯТМИжжЗНЗЈЃК
ЕШД§ MLflow ЗЂВМ R жаЕФ API
ЗтзА MLflow RESTful API ВЂЭЈЙ§ curl УќСюНјааМЧТМ
ЪЙгУвЛаЉПЩЕїгУ Python НтЪЭЦїЕФ R АќРДЕїгУЯжгаЕФ Python API
зюКѓвЛжжЗНЗЈМђЕЅвзааЃЌВЂдЪаэФњгы MLflow НјааНЛЛЅЃЌЖјЮоашЕШД§ЬсЙЉ R ЕФ APIЁЃдкБОНЬГЬжаЃЌЮвНЋЫЕУїШчКЮЪЙгУ
reticulate R АќРДжДааДЫВйзїЁЃ
reticulate ЪЧвЛИіПЊдД R АќЃЌЫќдЪаэЭЈЙ§дк R ЛсЛАжаЧЖШы Python ЛсЛАРДДг R
жаЕїгУ PythonЁЃИУАќдк R гы Python жЎМфЬсЙЉЮоЗьЕФИпадФмЛЅВйзїадЁЃдк CRAN ДцДЂПтжаЬсЙЉСЫИУАќЁЃ
MLflow ЛЙЫцИНСЫ Projects зщМўЃЌИУзщМўЛсНЋЪ§ОнЁЂдДДњТыМАУќСюЁЂВЮЪ§КЭжДааЛЗОГЩшжУвЛЦ№ДђАќЮЊвЛИіЖРСЂЙцЗЖЁЃдкЖЈвх
MLproject КѓЃЌПЩвддкШЮКЮЕиЗНдЫааДЫЯюФПЁЃФПЧАЃЌMLproject ПЩвддЫаа Python
ДњТыЛђ shell УќСюЁЃЫќЛЙПЩвдЮЊгУЛЇЖЈвхЕФ conda.yaml ЮФМўжажИЖЈЕФЯюФПЩшжУ Python
ЛЗОГЁЃ
Ждгк R гУЛЇЃЌЭЈГЃЛсдк R дДДњТыжаЕМШывЛаЉАќЁЃБиаыАВзАетаЉАќВХФмдЫаа R ДњТыЁЃЮДРДПЩвдзіГіЕФвЛЯюгХЛЏЪЧЃЌдк
MLflow жаЬэМгРрЫЦгк conda.yaml ЕФЙІФмРДЩшжУ R АќвРРЕЯюЁЃБОНЬГЬНщЩмСЫШчКЮДДНЈАќКЌ
R дДДњТыЕФ MLprojectЃЌвдМАШчКЮЪЙгУ mlflow run УќСюдЫааДЫЯюФПЁЃ
бЇЯАФПБъ
дкБОНЬГЬжаЃЌФњНЋАВзАКЭЩшжУ MLflow ЛЗОГЃЌдк R жабЕСЗКЭИњзйЛњЦїбЇЯАФЃаЭЃЌНЋдДДњТыКЭЪ§ОнЗтзАдк
MLproject жаЃЌВЂЪЙгУ mlflow run УќСюдЫааДЫЯюФПЁЃ
ЧАЬсЬѕМў
дкПЊЪМБОНЬГЬжЎЧАЃЌгІИУЯШдкдЫаа R ЕФЦНЬЈЩЯАВзА PythonЁЃЮвЪзбЁАВзА
minicondaЁЃгЩгкНЋдк R жаЭъГЩЛњЦїбЇЯАбЕСЗЃЌвђДЫвВгІИУдкЦНЬЈЩЯАВзАСЫ RЁЃ
ВНжш
Ек 1 ВНЃКАВзА MLflow
ЮЊ MLflow ДДНЈ virtualenvЃЌВЂАДШчЯТЗНЪНАВзА mlflow АќЃЈЪЙгУ condaЃЉЃК
conda create
-q -n mlflow python=3.6
source activate mlflow
pip install -U pip
pip install mlflo |
Ек 2 ВНЃКАВзА reticulate R Аќ
ЭЈЙ§ R АВзА reticulate АќЁЃ
| install.packages("reticulate") |
reticulate дЪаэ R ЮоЗьЕїгУ Python КЏЪ§ЁЃЭЈЙ§
import гяОфзАШы Python АќЁЃЭЈЙ§ $ дЫЫуЗћЕїгУКЏЪ§ЁЃ
> library(reticulate)
> path <- import("os.path")
> path$isdir("/tmp")
[1] TRUE |
е§ШчФњЫљМћЃЌЪЙгУДЫАќДг R жаЕїгУ os.path ФЃПщжаЕФ Python КЏЪ§ЪЎЗжМђЕЅЁЃЭЈЙ§ЕМШы
mlflow АќЃЌШЛКѓЕїгУ mlflow$log_param КЭ mlflow$log_metric
вдМЧТМ R НХБОЕФВЮЪ§КЭжИБъЃЌПЩвдЖд mlflow АќжДааЯрЭЌЕФВйзїЁЃ
Ек 3 ВНЃКЪЙгУ SparkR бЕСЗ GLM ФЃаЭ
вдЯТ R НХБОЪЙгУ SparkR ЙЙНЈЯпадЛиЙщФЃаЭЁЃЖдгкДЫЪОР§ЃЌБиаывбАВзА
SparkR АќЁЃ
# load the reticulate
package and import mlflow Python module
library(reticulate)
mlflow <- import("mlflow")
# load SparkR package and start spark session
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"),
"R", "lib")))
sparkR.session(master="local[*]")
# convert iris data.frame to SparkDataFrame
df <- as.DataFrame(iris)
# parameter for GLM
family <- c("gaussian")
# log the parameter
mlflow$log_param("family", family)
# fit the GLM model
model <- spark.glm(df, Species ~ ., family
= family)
# exam the model
summary(model)
# path to save the model
model_path <- "/tmp/mlflow-GLM"
# save the model
write.ml(model, model_path)
# log the artifact
mlflow$log_artifacts(model_path)
# stop spark session
sparkR.session.stop() |
ФњПЩвдНЋНХБОИДжЦЕН R Лђ Rstudio ВЂвдНЛЛЅЗНЪНдЫааИУНХБОЃЌЛђепНЋЦфБЃДцЕНЮФМўжаВЂЪЙгУ Rscript
УќСюдЫааИУНХБОЁЃШЗБЃ PATH ЛЗОГБфСПАќКЌ mlflow Python virtualenv ЕФТЗОЖЁЃ
Ек 4 ВНЃКЦєЖЏ MLflow UI
ЭЈЙ§Дг shell жадЫаа mlflow ui УќСюРДЦєЖЏ MLflow UIЁЃШЛКѓЃЌДђПЊфЏРРЦїВЂЪЙгУ
URL http://127.0.0.1:5000 зЊжСвГУцСДНгЁЃЯжвбЯдЪОФњжЎЧАЕФ GLM ФЃаЭбЕСЗЃЌФњПЩвдЖдЦфНјааИњзйЁЃЯТЭМЯдЪОСЫЦфНиЦСЁЃ
Ек 5 ВНЃКбЕСЗОіВпЪїФЃаЭ
НЋвЊбЇЯАЕФ wine-quality.csv Ъ§ОнЯТдиЕНФњЕФЦНЬЈЁЃ
дк R ЛЗОГжаАВзА rpart АќЃК
| install.packages("rpart") |
АДееДЫЪОР§ rpart-example.R РДЮЊЪїФЃаЭзіКУзМБИЃК
# Source prep.R
file to install the dependencies
source("prep.R")
# Import mlflow python package for tracking
library(reticulate)
mlflow <- import("mlflow")
# Load rpart to build a tree model
library(rpart)
# Read in data
wine <- read.csv("wine-quality.csv")
# Build the model
fit <- rpart(quality ~ ., wine)
# Save the model that can be loaded later
saveRDS(fit, "fit.rpart")
# Save the model to mlflow tracking server
mlflow$log_artifact("fit.rpart")
# Plot
jpeg("rplot.jpg")
par(xpd=TRUE)
plot(fit)
text(fit, use.n=TRUE)
dev.off()
# Save the plot to mlflow tracking server
mlflow$log_artifact("rplot.jpg") |
R ДњТыАќРЈШ§ИіВПЗжЃКФЃаЭбЕСЗЁЂЭЈЙ§ MLflow ЪЕЯжЕФЙЄМўМЧТМвдМА R АќвРРЕЯюАВзАЁЃ
Ек 6 ВНЃКЮЊ MLproject зМБИАќвРРЕЯю
дкЧАУцЕФЪОР§жаЃЌашвЊ reticulate КЭ rpart R АќВХФмдЫааДњТыЁЃвЊНЋетаЉДњТыЗтзАЕНвЛИіЖРСЂЯюФПжаЃЌШчЙћЦНЬЈУЛгаАВзАетаЉАќЃЌФЧУДгІдЫааФГжжНХБОРДздЖЏАВзАетаЉАќЁЃ
НЋЪЙгУвдЯТДњТыЁЂЭЈЙ§ prep.R РДАВзАЯюФПЫљашЕФЫљгаЬиЖЈ R АќЃК
# Accept parameters,
args[6] is the R package repo url
args <- commandArgs()
# All installed packages
pkgs <- installed.packages()
# List of required packages for this project
reqs <- c("reticulate", "rpart")
# Try to install the dependencies if not installed
sapply(reqs, function(x){
if (!x %in% rownames(pkgs)) {
install.packages(x, repos=c(args[6]))
}
}) |
Ек 7 ВНЃКВтЪдДњТы
дкНЋетаЉДњТыЗтзАЕН MLproject жЎЧАЃЌЧыГЂЪдЭЈЙ§жБНгЕїгУ
Rscript УќСюРДВтЪдетаЉДњТыЃЌШчЯТЫљЪОЃК
| Rscript rpart-example.R
https://cran.r-project.org/ |
дк MLflow UI жаЃЌФњгІИУПДЕНетДЮдЫаавбБЛИњзйЃЌШчЯТЭМЫљЪОЃК
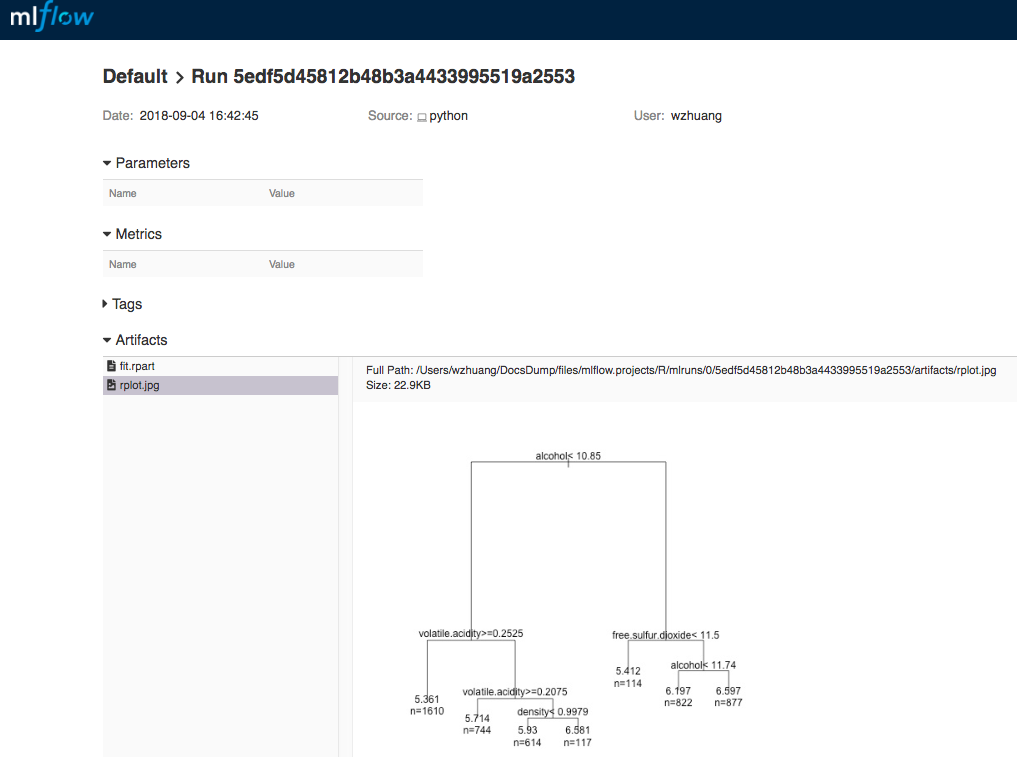
Ек 8 ВНЃКДДНЈ MLproject
ЯждкЃЌЮвУЧРДБраДЙцЗЖЃЌВЂНЋДЫЯюФПЗтзАЕН MLflow ПЩЪЖБ№ВЂдЫааЕФ
MLproject жаЁЃФњжЛашвЊдкЭЌвЛИіФПТМжаДДНЈ MLproject ЮФМўЁЃ
name: r_example
entry_points:
main:
parameters:
r-repo: {type: string, default: "https://cran.r-project.org/"}
command: "Rscript rpart-example.R {r-repo}"
|
ДЫЮФМўЪЙгУ main ШыПкЕуЖЈвх r_example ЯюФПЁЃИУШыПкЕужИЖЈвЊЭЈЙ§ mlflow run
жДааЕФУќСюКЭВЮЪ§ЁЃЖдгкДЫЯюФПЃЌRscript ЪЧгУгкЕїгУ R дДДњТыЕФ shell УќСюЁЃr-repo
ВЮЪ§ЛсЬсЙЉ URL зжЗћДЎЃЌФњПЩвдЭЈЙ§ЫќРДАВзАДгЪєАќЁЃвбЩшжУвЛИіШБЪЁжЕЁЃНЋДЫВЮЪ§ДЋЕнжСгУгкдЫаа R
дДДњТыЕФУќСюЁЃ
ЯждкЃЌФњвбгЕгабЕСЗДЫЪїФЃаЭЫљашЕФЫљгаЮФМўЃЌПЩвдЭЈЙ§ДДНЈФПТМВЂНЋЪ§ОнКЭ
R дДДњТыИДжЦЕНИУФПТМРДДДНЈ MLprojectЁЃ
.
ЉИЉЄЉЄ R
ЉРЉЄЉЄ MLproject
ЉРЉЄЉЄ prep.R
ЉРЉЄЉЄ rpart-example.R
ЉИЉЄЉЄ wine-quality.csv |
Ек 9 ВНЃКМьШыВЂВтЪд MLproject
ПЩвдНЋЯШЧАЕФ MLproject МьШыВЂЭЦЫЭЕН GitHub ДцДЂПтЁЃЪЙгУвдЯТУќСюРДВтЪдИУЯюФПЁЃПЩвддкАВзАСЫ
R ЕФШЮКЮЦНЬЈЩЯдЫааИУЯюФПЁЃ
| mlflow run https://github.com/adrian555/DocsDump#files/mlflow-projects/R |
вВПЩвдДг MLflow ИњзйНчУцжаВщПДИУЯюФПЃЌШчЯТЭМЫљЪОЃК
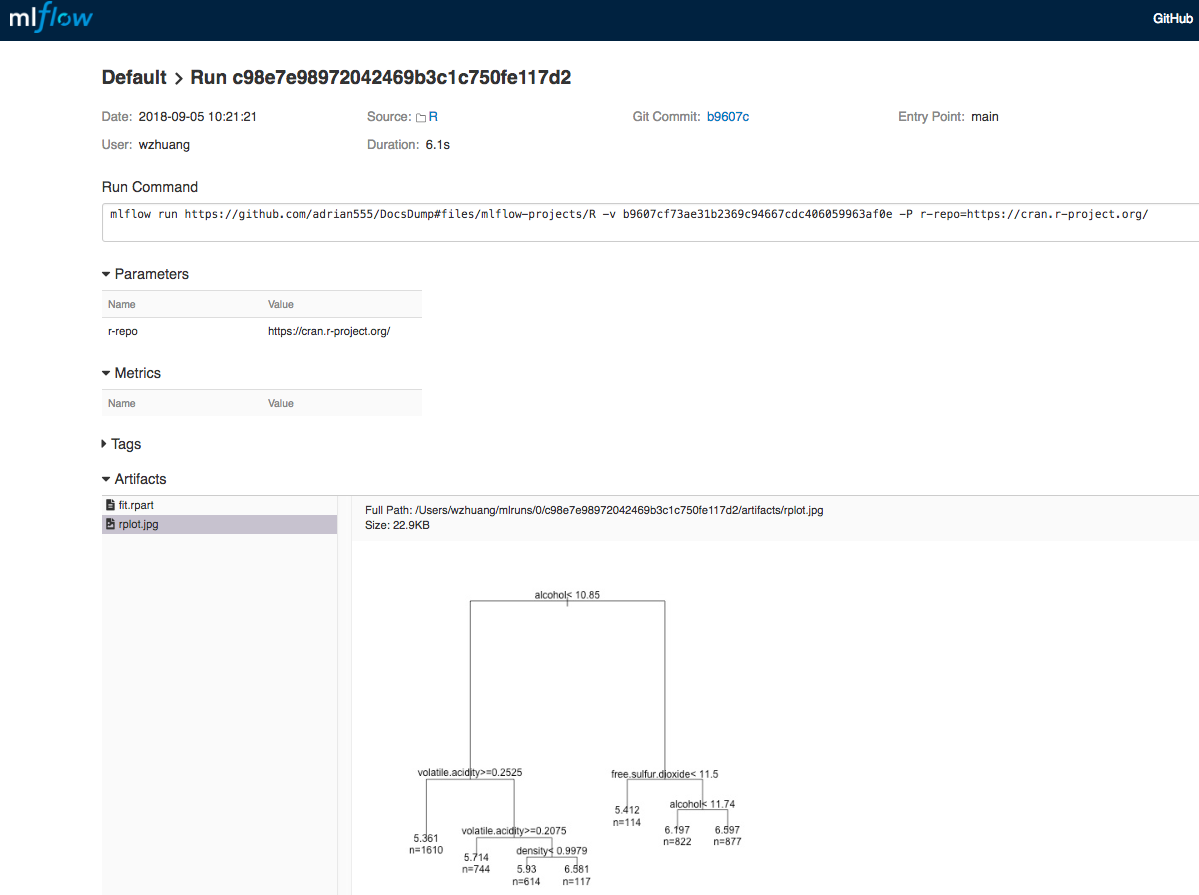
ДЫЪгЭМгыЧАвЛДЮдЫааЃЈЮо Mlproject ЙцЗЖЃЉжЎМфЕФВювьЪЧ Run CommandЃЈНЋВЖЛёгУгкдЫааЯюФПЕФШЗЧаУќСюЃЉКЭ
ParametersЃЈНЋздЖЏМЧТМДЋЕнЕНШыПкЕуЕФШЮКЮВЮЪ§ЃЉЁЃ
НсЪјгя
дкБОНЬГЬжаЃЌФњвбдк R жаГЩЙІЕиДДНЈСЫ MLprojectЃЌВЂЪЙгУ MLflow ИњзйКЭдЫааСЫИУЯюФПЁЃДЫЗНЗЈШУ
R гУЛЇФмЙЛЪЙгУ MLflow Tracking зщМўЃЌДгЖјПЩвдПьЫйИњзй R ФЃаЭЁЃЫќЛЙбнЪОСЫ MLflow
ЕФ Projects зщМўЕФгУЭОЃЌМДЖЈвхЯюФПВЂЪЙЯюФПБугкжиаТдЫааЁЃR гУЛЇПЩвдПьЫйЩшжУЦфЯюФПЃЌВЂЧвПЩвдЪЙгУ
MLflow ЧсЫЩИњзйКЭдЫааЯюФПЁЃ |









