| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌБОЮФжївЊНщЩмСЫШчКЮгУЩюЖШЧПЛЏбЇЯАРДеЙЪОTensorFlow
2.0ЕФЧПДѓЬиадЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
дкБОНЬГЬжаЃЌЮвНЋЭЈЙ§ЪЕЪЉAdvantage Actor-Critic(бндБ-ЦРТлМвЃЌA2C)ДњРэРДНтОіОЕфЕФCartPole-v0ЛЗОГЃЌЭЈЙ§ЩюЖШЧПЛЏбЇЯАЃЈDRLЃЉеЙЪОМДНЋЭЦГіЕФTensorFlow2.0ЬиадЁЃЫфШЛЮвУЧЕФФПБъЪЧеЙЪОTensorFlow2.0ЃЌЕЋЮвНЋОЁзюДѓХЌСІШУDRLЕФНВНтИќМгЦНвзНќШЫЃЌАќРЈЖдИУСьгђЕФМђвЊИХЪіЁЃ
ЪТЪЕЩЯЃЌгЩгк2.0АцБОЕФНЙЕуЪЧШУПЊЗЂШЫдБЕФЩњЛюБфЕУИќЧсЫЩЃЌЫљвдЮвШЯЮЊЯждкЪЧЪЙгУTensorFlowНјШыDRLЕФКУЪБЛњЃЌБОЮФгУЕНЕФР§згЕФдДДњТыВЛЕН150ааЃЁДњТыПЩвддкетРяЛђепетРяЛёШЁЁЃ
НЈСЂ
гЩгкTensorFlow2.0ШдДІгкЪдбщНзЖЮЃЌЮвНЈвщНЋЦфАВзАдкЖРСЂЕФащФтЛЗОГжаЁЃЮвИіШЫБШНЯЯВЛЖAnacondaЃЌЫљвдЮвНЋгУЫќРДбнЪОАВзАЙ§ГЬЃК
| conda
create -n tf2 python=3.6
> source activate tf2
> pip install tf-nightly-2.0-preview # tf-nightly-gpu-2.0-preview
for GPU version
|
ШУЮвУЧПьЫйбщжЄвЛЧаЪЧЗёАДФмЙЛе§ГЃЙЄзїЃК
|
import tensorflow as tf
>>> print(tf.__version__)
1.13.0-dev20190117
>>> print(tf.executing_eagerly())
True
|
ВЛвЊЕЃаФ1.13.xАцБОЃЌетжЛЪЧвтЮЖзХЫќЪЧдчЦкдЄРРЁЃетРявЊзЂвтЕФЪЧЮвУЧФЌШЯДІгкeagerФЃЪНЃЁ
| >>>
print(tf.reduce_sum([1, 2, 3, 4, 5]))
tf.Tensor(15, shape=(), dtype=int32)
|
ШчЙћФуЛЙВЛЪьЯЄeagerФЃЪНЃЌФЧУДЪЕжЪЩЯвтЮЖзХМЦЫуЪЧдкдЫааЪББЛжДааЕФЃЌЖјВЛЪЧЭЈЙ§дЄБрвыЕФЭМЃЈЧњЯпЭМЃЉРДжДааЁЃФуПЩвддкTensorFlowЮФЕЕжаевЕНвЛИіКмКУЕФИХЪіЁЃ
ЩюЖШЧПЛЏбЇЯА
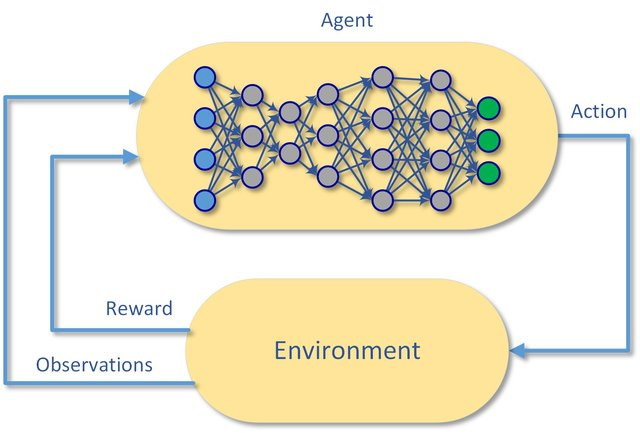
вЛАуЖјбдЃЌЧПЛЏбЇЯАЪЧНтОіСЌајОіВпЮЪЬтЕФИпМЖПђМмЁЃRLЭЈЙ§ЛљгкФГаЉagentНјааЕМКНЙлВьЛЗОГЃЌВЂЧвЛёЕУНБРјЁЃДѓЖрЪ§RLЫуЗЈЭЈЙ§зюДѓЛЏДњРэдквЛТжгЮЯЗЦкМфЪеМЏЕФНБРјзмКЭРДЙЄзїЁЃ
ЛљгкRLЕФЫуЗЈЕФЪфГіЭЈГЃЪЧpolicyЃЈВпТдЃЉ-НЋзДЬЌгГЩфЕНКЏЪ§гааЇЕФВпТджаЃЌгааЇЕФВпТдПЩвдЯёгВБрТыЕФЮоВйзїЖЏзївЛбљМђЕЅЁЃдкФГаЉзДЬЌЯТЃЌЫцЛњВпТдБэЪОЮЊааЖЏЕФЬѕМўИХТЪЗжВМЁЃ
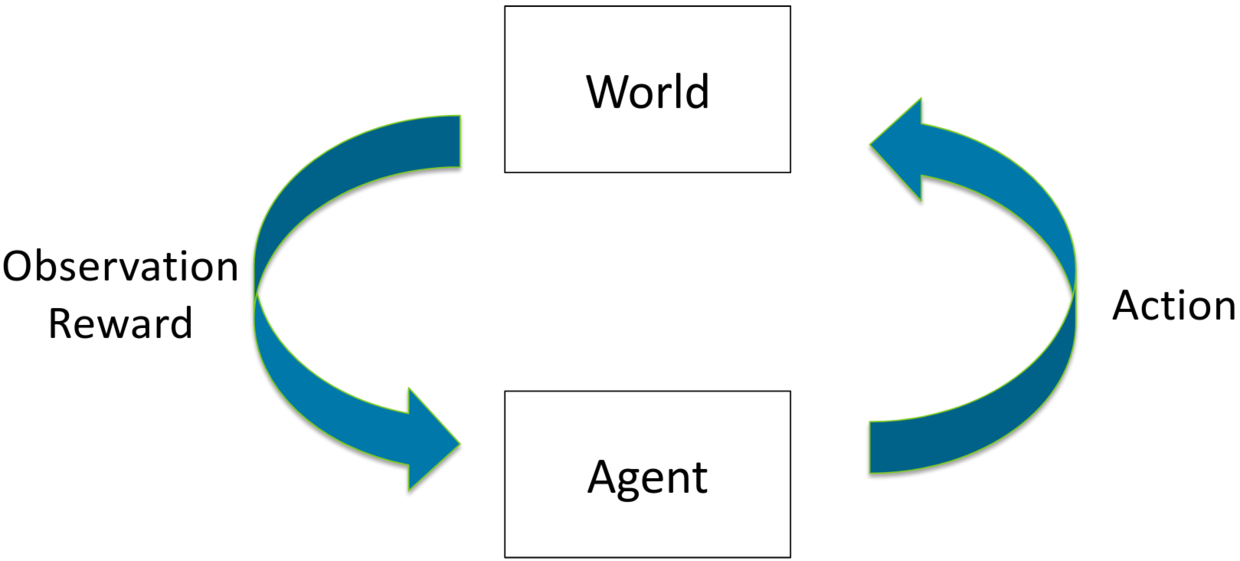
бндБЃЌЦРТлМвЗНЗЈЃЈActor-Critic MethodsЃЉ
RLЫуЗЈЭЈГЃЛљгкЫќУЧгХЛЏЕФФПБъКЏЪ§НјааЗжзщЁЃValue-basedжюШчDQNжЎРрЕФЗНЗЈЭЈЙ§МѕЩйдЄЦкЕФзДЬЌ-ЖЏзїжЕЕФЮѓВюРДЙЄзїЁЃ
ВпТдЬнЖШЃЈPolicy GradientsЃЉЗНЗЈЭЈЙ§ЕїећЦфВЮЪ§жБНггХЛЏВпТдБОЩэЃЌЭЈГЃЭЈЙ§ЬнЖШЯТНЕЭъГЩЕФЁЃЭъШЋМЦЫуЬнЖШЭЈГЃЪЧФбвдДІРэЕФЃЌвђДЫЭЈГЃвЊЭЈЙ§УЩЬиПЈТоЗНЗЈЙРЫуЫќУЧЁЃ
зюСїааЕФЗНЗЈЪЧСНепЕФЛьКЯЃКactor-criticЗНЗЈЃЌЦфжаДњРэВпТдЭЈЙ§ВпТдЬнЖШНјаагХЛЏЃЌЖјЛљгкжЕЕФЗНЗЈгУзїдЄЦкжЕЙРМЦЕФв§ЕМЁЃ
ЩюЖШбндБ-ХњЦРЗНЗЈ
ЫфШЛКмЖрЛљДЁЕФRLРэТлЪЧдкБэИёАИР§жаПЊЗЂЕФЃЌЕЋЯжДњRLМИКѕЭъШЋЪЧгУКЏЪ§БЦНќЦїЭъГЩЕФЃЌР§ШчШЫЙЄЩёОЭјТчЁЃОпЬхЖјбдЃЌШчЙћВпТдКЭжЕКЏЪ§гУЩюЖШЩёОЭјТчНќЫЦЃЌдђRLЫуЗЈБЛШЯЮЊЪЧЁАЩюЖШЁБЁЃ
вьВНгХЪЦбндБ-ЦРТлМвЃЈactor-criticalЃЉ
ЖрФъРДЃЌЮЊСЫЬсИпбЇЯАЙ§ГЬЕФбљБОаЇТЪКЭЮШЖЈадЃЌММЪѕЗЂУїепвбОНјааСЫвЛаЉИФНјЁЃ
ЪзЯШЃЌЬнЖШМгШЈЛиБЈЃКелЯжЕФЮДРДНБРјЃЌетдквЛЖЈГЬЖШЩЯЛКНтСЫаХгУЗжХфЮЪЬтЃЌВЂвдЮоЯоЕФЪБМфВНГЄНтОіСЫРэТлЮЪЬтЁЃ
ЦфДЮЃЌЪЙгУгХЪЦКЏЪ§ДњЬцдЪМЛиБЈЁЃгХЪЦдкЪевцгыФГаЉЛљЯпжЎМфЕФВювьжЎМфаЮГЩЃЌВЂЧвПЩвдБЛЪгЮЊКтСПИјЖЈжЕгыФГаЉЦНОљжЕЯрБШгаЖрКУЕФжИБъЁЃ
ЕкШ§ЃЌдкФПБъКЏЪ§жаЪЙгУЖюЭтЕФьизюДѓЛЏЯювдШЗБЃДњРэГфЗжЬНЫїИїжжВпТдЁЃБОжЪЩЯЃЌьивдОљдШЗжВМзюДѓЛЏРДВтСПИХТЪЗжВМЕФЫцЛњадЁЃ
зюКѓЃЌВЂааЪЙгУЖрИіЙЄШЫМгЫйбљЦЗВЩМЏЃЌЭЌЪБдкбЕСЗЦкМфАяжњЫќУЧШЅЯрЙиЁЃ
НЋЫљгаетаЉБфЛЏгыЩюЖШЩёОЭјТчЯрНсКЯЃЌЮвУЧЕУГіСЫСНжжзюСїааЕФЯжДњЫуЗЈ:вьВНгХЪЦбндБЦРТлМвЃЈactor-criticalЃЉЫуЗЈЃЌМђГЦA3CЛђепA2CЁЃСНепжЎМфЕФЧјБ№дкгкММЪѕадЖјЗЧРэТладЃКЙЫУћЫМвхЃЌЫќЙщНсЮЊВЂааЙЄШЫШчКЮЙРМЦЦфЬнЖШВЂНЋЦфДЋВЅЕНФЃаЭжаЁЃ
гаСЫетИіЃЌЮвНЋНсЪјЮвУЧЕФDRLЗНЗЈжЎТУЃЌвђЮЊВЉПЭЮФеТЕФжиЕуИќЖрЪЧЙигкTensorFlow2.0ЕФЙІФмЁЃШчЙћФуШдШЛВЛСЫНтИУжїЬтЃЌЧыВЛвЊЕЃаФЃЌДњТыЪОР§гІИУИќЧхГўЁЃШчЙћФуЯыСЫНтИќЖрЃЌФЧУДвЛИіКУЕФзЪдДОЭПЩвдПЊЪМдкDeep
RLжаНјааSpinning UpСЫЁЃ
ЪЙгУTensorFlow 2.0ЕФгХЪЦбндБ-ЦРТлМв
ШУЮвУЧПДПДЪЕЯжЯжДњDRLЫуЗЈЕФЛљДЁЪЧЪВУДЃКбндБЦРТлМвДњРэЃЈactor-critic agentЃЉЁЃШчЧАвЛНкЫљЪіЃЌЮЊМђЕЅЦ№МћЃЌЮвУЧВЛЛсЪЕЯжВЂааЙЄзїГЬађЃЌОЁЙмДѓЖрЪ§ДњТыЖМЛсжЇГжЫќЃЌИааЫШЄЕФЖСепПЩвдНЋЦфгУзїЖЭСЖЛњЛсЁЃ
зїЮЊВтЪдЦНЬЈЃЌЮвУЧНЋЪЙгУCartPole-v0ЛЗОГЁЃЫфШЛЫќгаЕуМђЕЅЃЌЕЋЫќШдШЛЪЧвЛИіКмКУЕФбЁдёПЊЪМЁЃдкЪЕЯжRLЫуЗЈЪБЃЌЮвзмЪЧвРРЕЫќзїЮЊвЛжжНЁШЋадМьВщЁЃ
ЭЈЙ§Keras Model APIЪЕЯжЕФВпТдКЭМлжЕ
ЪзЯШЃЌШУЮвУЧдкЕЅИіФЃаЭРрЯТДДНЈВпТдКЭМлжЕЙРМЦNNЃК
| import
numpy as np
import tensorflow as tf
import tensorflow.keras.layers as kl
class ProbabilityDistribution(tf.keras.Model):
def call(self, logits):
# sample a random categorical action from given
logits
return tf.squeeze(tf.random.categorical(logits,
1), axis=-1)
class Model(tf.keras.Model):
def __init__(self, num_actions):
super().__init__('mlp_policy')
# no tf.get_variable(), just simple Keras API
self.hidden1 = kl.Dense(128, activation='relu')
self.hidden2 = kl.Dense(128, activation='relu')
self.value = kl.Dense(1, name='value')
# logits are unnormalized log probabilities
self.logits = kl.Dense(num_actions, name='policy_logits')
self.dist = ProbabilityDistribution()
def call(self, inputs):
# inputs is a numpy array, convert to Tensor
x = tf.convert_to_tensor(inputs, dtype=tf.float32)
# separate hidden layers from the same input
tensor
hidden_logs = self.hidden1(x)
hidden_vals = self.hidden2(x)
return self.logits(hidden_logs), self.value(hidden_vals)
def action_value(self, obs):
# executes call() under the hood
logits, value = self.predict(obs)
action = self.dist.predict(logits)
# a simpler option, will become clear later
why we don't use it
# action = tf.random.categorical(logits, 1)
return np.squeeze(action, axis=-1), np.squeeze(value,
axis=-1)
|
бщжЄЮвУЧбщжЄФЃаЭЪЧЗёАДдЄЦкЙЄзїЃК
| import
gym
env = gym.make('CartPole-v0')
model = Model(num_actions=env.action_space.n)
obs = env.reset()
# no feed_dict or tf.Session() needed at all
action, value = model.action_value(obs[None,
:])
print(action, value) # [1] [-0.00145713]
|
етРявЊзЂвтЕФЪТЯюЃК
1.ФЃаЭВуКЭжДааТЗОЖЪЧЗжПЊЖЈвхЕФЃЛ
2.УЛгаЁАЪфШыЁБЭМВуЃЌФЃаЭНЋНгЪмдЪМnumpyЪ§зщЃЛ
3.ПЩвдЭЈЙ§КЏЪ§APIдквЛИіФЃаЭжаЖЈвхСНИіМЦЫуТЗОЖЃЛ
4.ФЃаЭПЩвдАќКЌвЛаЉИЈжњЗНЗЈЃЌР§ШчЖЏзїВЩбљЃЛ
5.дкeagerЕФФЃЪНЯТЃЌвЛЧаЖМПЩвдДгдЪМЕФnumpyЪ§зщжадЫааЃЛ
ЫцЛњДњРэ
ЯждкЮвУЧПЩвдМЬајбЇЯАвЛаЉгаШЄЕФЖЋЮїA2CAgentРрЁЃЪзЯШЃЌШУЮвУЧЬэМгвЛИіЙсДЉећМЏЕФtestЗНЗЈВЂЗЕЛиНБРјзмКЭЁЃ
| class
A2CAgent:
def __init__(self, model):
self.model = model
def test(self, env, render=True):
obs, done, ep_reward = env.reset(), False, 0
while not done:
action, _ = self.model.action_value(obs[None,
:])
obs, reward, done, _ = env.step(action)
ep_reward += reward
if render:
env.render()
return ep_reward
|
ШУЮвУЧПДПДЮвУЧЕФФЃаЭдкЫцЛњГѕЪМЛЏШЈжиЯТЕУЗжЖрЩйЃК
| agent
= A2CAgent(model)
rewards_sum = agent.test(env)
print("%d out of 200" % rewards_sum)
# 18 out of 200
|
РызюМбзЊЬЈЛЙгаКмдЖЃЌНгЯТРДЪЧбЕСЗВПЗжЃЁ
Ы№ЪЇ/ФПБъКЏЪ§
е§ШчЮвдкDRLИХЪіВПЗжЫљУшЪіЕФФЧбљЃЌДњРэЭЈЙ§ЛљгкФГаЉЫ№ЪЇЃЈФПБъЃЉКЏЪ§ЕФЬнЖШЯТНЕРДИФНјЦфВпТдЁЃдкбндБЦРТлМвжаЃЌЮвУЧбЕСЗСЫШ§ИіФПБъЃКгУгХЪЦМгШЈЬнЖШМгЩЯьизюДѓЛЏРДИФНјВпТдЃЌВЂзюаЁЛЏМлжЕЙРМЦЮѓВюЁЃ
| import
tensorflow.keras.losses as kls
import tensorflow.keras.optimizers as ko
class A2CAgent:
def __init__(self, model):
# hyperparameters for loss terms
self.params = {'value': 0.5, 'entropy': 0.0001}
self.model = model
self.model.compile(
optimizer=ko.RMSprop(lr=0.0007),
# define separate losses for policy logits and
value estimate
loss=[self._logits_loss, self._value_loss]
)
def test(self, env, render=True):
# unchanged from previous section
...
def _value_loss(self, returns, value):
# value loss is typically MSE between value
estimates and returns
return self.params['value']*kls.mean_squared_error(returns,
value)
def _logits_loss(self, acts_and_advs, logits):
# a trick to input actions and advantages through
same API
actions, advantages = tf.split(acts_and_advs,
2, axis=-1)
# polymorphic CE loss function that supports
sparse and weighted options
# from_logits argument ensures transformation
into normalized probabilities
cross_entropy = kls.CategoricalCrossentropy(from_logits=True)
# policy loss is defined by policy gradients,
weighted by advantages
# note: we only calculate the loss on the actions
we've actually taken
# thus under the hood a sparse version of CE
loss will be executed
actions = tf.cast(actions, tf.int32)
policy_loss = cross_entropy(actions, logits,
sample_weight=advantages)
# entropy loss can be calculated via CE over
itself
entropy_loss = cross_entropy(logits, logits)
# here signs are flipped because optimizer minimizes
return policy_loss - self.params['entropy']*entropy_loss
|
ЮвУЧЭъГЩСЫФПБъКЏЪ§ЃЁЧызЂвтДњТыЕФНєДеГЬЖШЃКзЂЪЭааМИКѕБШДњТыБОЩэЖрЁЃ
ДњРэбЕСЗбЛЗ
зюКѓЃЌЛЙгабЕСЗЛиТЗБОЩэЃЌЫќЯрЖдНЯГЄЃЌЕЋЯрЕБМђЕЅЃКЪеМЏбљБОЃЌМЦЫуЛиБЈКЭгХЪЦЃЌВЂдкЦфЩЯбЕСЗФЃаЭЁЃ
| class
A2CAgent:
def __init__(self, model):
# hyperparameters for loss terms
self.params = {'value': 0.5, 'entropy': 0.0001,
'gamma': 0.99}
# unchanged from previous section
...
def train(self, env, batch_sz=32, updates=1000):
# storage helpers for a single batch of data
actions = np.empty((batch_sz,), dtype=np.int32)
rewards, dones, values = np.empty((3, batch_sz))
observations = np.empty((batch_sz,) + env.observation_space.shape)
# training loop: collect samples, send to optimizer,
repeat updates times
ep_rews = [0.0]
next_obs = env.reset()
for update in range(updates):
for step in range(batch_sz):
observations[step] = next_obs.copy()
actions[step], values[step] = self.model.action_value(next_obs[None,
:])
next_obs, rewards[step], dones[step], _ = env.step(actions[step])
ep_rews[-1] += rewards[step]
if dones[step]:
ep_rews.append(0.0)
next_obs = env.reset()
_, next_value = self.model.action_value(next_obs[None,
:])
returns, advs = self._returns_advantages(rewards,
dones, values, next_value)
# a trick to input actions and advantages through
same API
acts_and_advs = np.concatenate([actions[:, None],
advs[:, None]], axis=-1)
# performs a full training step on the collected
batch
# note: no need to mess around with gradients,
Keras API handles it
losses = self.model.train_on_batch(observations,
[acts_and_advs, returns])
return ep_rews
def _returns_advantages(self, rewards, dones,
values, next_value):
# next_value is the bootstrap value estimate
of a future state (the critic)
returns = np.append(np.zeros_like(rewards),
next_value, axis=-1)
# returns are calculated as discounted sum of
future rewards
for t in reversed(range(rewards.shape[0])):
returns[t] = rewards[t] + self.params['gamma']
* returns[t+1] * (1-dones[t])
returns = returns[:-1]
# advantages are returns - baseline, value estimates
in our case
advantages = returns - values
return returns, advantages
def test(self, env, render=True):
# unchanged from previous section
...
def _value_loss(self, returns, value):
# unchanged from previous section
...
def _logits_loss(self, acts_and_advs, logits):
# unchanged from previous section
...
|
бЕСЗКЭНсЙћ
ЮвУЧЯждквбОзМБИКУдкCartPole-v0ЩЯбЕСЗЮвУЧЕФЕЅЙЄA2CДњРэСЫЃЁбЕСЗЙ§ГЬВЛгІГЌЙ§МИЗжжгЃЌбЕСЗЭъГЩКѓЃЌФугІИУПДЕНДњРэГЩЙІДяЕН200ЗжжаЕФФПБъЁЃ
| rewards_history
= agent.train(env)
print("Finished training, testing...")
print("%d out of 200" % agent.test(env))
# 200 out of 200
|

дкдДДњТыжаЃЌЮвАќКЌСЫвЛаЉЖюЭтЕФАяжњГЬађЃЌПЩвдДђгЁГідЫааЕФНБРјКЭЫ№ЪЇЃЌвдМАrewards_historyЕФЛљБОЛцЭМвЧЁЃ
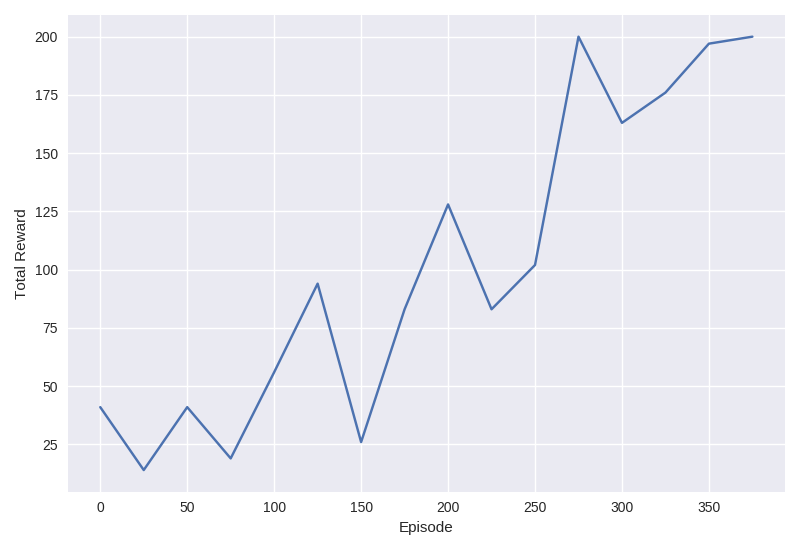
ОВЬЌМЦЫуЭМ
гаСЫЫљгаетжжПЪЭћФЃЪНЕФГЩЙІЕФЯВдУЃЌФуПЩФмЯыжЊЕРОВЬЌЭМаЮжДааЪЧЗёПЩвдЁЃЕБШЛЃЁДЫЭтЃЌЮвУЧЛЙашвЊЖрвЛааДњТыРДЦєгУЫќЃЁ
| with
tf.Graph().as_default():
print(tf.executing_eagerly()) # False
model = Model(num_actions=env.action_space.n)
agent = A2CAgent(model)
rewards_history = agent.train(env)
print("Finished training, testing...")
print("%d out of 200" % agent.test(env))
# 200 out of 200
|
гавЛЕуашвЊзЂвтЃЌдкОВЬЌЭМаЮжДааЦкМфЃЌЮвУЧВЛФмжЛгаTensorsЃЌетОЭЪЧЮЊЪВУДЮвУЧдкФЃаЭЖЈвхЦкМфашвЊЪЙгУCategoricalDistributionЕФММЧЩЁЃЪТЪЕЩЯЃЌЕБЮвдкбАеввЛжждкОВЬЌФЃЪНЯТжДааЕФЗНЗЈЪБЃЌЮвЗЂЯжСЫвЛИіЙигкЭЈЙ§Keras
APIЙЙНЈЕФФЃаЭЕФвЛИігаШЄЕФЕЭМЖЯИНкЁЃ
ЛЙгавЛМўЪТЁ
ЛЙМЧЕУЮвЫЕЙ§TensorFlowФЌШЯЪЧдЫаадкeagerФЃЪНЯТАЩЃЌЩѕжСгУДњТыЦЌЖЮжЄУїЫќТ№ЃПКУАЩЃЌЮвДэСЫЁЃ
ШчЙћФуЪЙгУKeras APIРДЙЙНЈКЭЙмРэФЃаЭЃЌФЧУДЫќНЋГЂЪдНЋЫќУЧБрвыЮЊОВЬЌЭМаЮЁЃЫљвдФузюжеЕУЕНЕФЪЧОВЬЌМЦЫуЭМЕФадФмЃЌОпгаПЪЭћжДааЕФСщЛюадЁЃ
ФуПЩвдЭЈЙ§model.run_eagerlyБъжОМьВщФЃаЭЕФзДЬЌЃЌФувВПЩвдЭЈЙ§ЩшжУДЫБъжОРДЧПжЦжДааeagerФЃЪНБфГЩTrueЃЌОЁЙмДѓЖрЪ§ЧщПіЯТФуПЩФмВЛашвЊетбљзіЁЃЕЋШчЙћKerasМьВтЕНУЛгаАьЗЈШЦЙ§eagerФЃЪНЃЌЫќНЋздЖЏЭЫГіЁЃ
ЮЊСЫЫЕУїЫќШЗЪЕЪЧзїЮЊОВЬЌЭМдЫааЃЌетРяЪЧвЛИіМђЕЅЕФЛљзМВтЪдЃК
| #
create a 100000 samples batch
env = gym.make('CartPole-v0')
obs = np.repeat(env.reset()[None, :], 100000,
axis=0)
|
EagerЛљзМ
| %%time
model = Model(env.action_space.n)
model.run_eagerly = True
print("Eager Execution: ", tf.executing_eagerly())
print("Eager Keras Model:", model.run_eagerly)
_ = model(obs)
######## Results #######
Eager Execution: True
Eager Keras Model: True
CPU times: user 639 ms, sys: 736 ms, total:
1.38 s
|
ОВЬЌЛљзМ
| %%time
with tf.Graph().as_default():
model = Model(env.action_space.n)
print("Eager Execution: ", tf.executing_eagerly())
print("Eager Keras Model:", model.run_eagerly)
_ = model.predict(obs)
######## Results #######
Eager Execution: False
Eager Keras Model: False
CPU times: user 793 ms, sys: 79.7 ms, total:
873 ms
|
ФЌШЯЛљзМ
| %%time
model = Model(env.action_space.n)
print("Eager Execution: ", tf.executing_eagerly())
print("Eager Keras Model:", model.run_eagerly)
_ = model.predict(obs)
######## Results #######
Eager Execution: True
Eager Keras Model: False
CPU times: user 994 ms, sys: 23.1 ms, total:
1.02 s
|
е§ШчФуЫљПДЕНЕФЃЌeagerФЃЪНЪЧОВЬЌФЃЪНЕФБГКѓЃЌФЌШЯЧщПіЯТЃЌЮвУЧЕФФЃаЭШЗЪЕЪЧОВЬЌжДааЕФЁЃ
НсТл
ЯЃЭћБОЮФФмЙЛАяжњФуРэНтDRLКЭTensorFlow2.0ЁЃЧызЂвтЃЌTensorFlow2.0ШдШЛжЛЪЧдЄРРАцБОЃЌЩѕжСВЛЪЧКђбЁАцБОЃЌвЛЧаЖМПЩФмЗЂЩњБфЛЏЁЃШчЙћTensorFlowгаЪВУДЖЋЮїФуЬиБ№ВЛЯВЛЖЃЌШУЫќЕФПЊЗЂепжЊЕРЃЁ
ШЫУЧПЩФмЛсгавЛИіЛгжЎВЛШЅЕФЮЪЬтЃКTensorFlowБШPyTorchКУТ№ЃПвВаэЃЌвВаэВЛЪЧЁЃЫќУЧСНИіЖМЪЧЮАДѓЕФПтЃЌЫљвдКмФбЫЕетбљЫКУЃЌЫВЛКУЁЃШчЙћФуЪьЯЄPyTorchЃЌФуПЩФмвбОзЂвтЕНTensorFlow
2.0ВЛНіИЯЩЯСЫЫќЃЌЖјЧвЛЙБмУтСЫвЛаЉPyTorch APIЕФШБЯнЁЃ |









