| БрМЭЦМі: |
БОЮФРДздcsdnЃЌЮФеТжївЊЗжЮіСЫROI PoolЕФВЛзуЃЌНЋЪЕР§ЗжИюЗжНтЮЊЗжРрКЭmaskЩњГЩСНИіЗжжЇМАВЂааНјааЗжРрКЭmaskЩњГЩШЮЮёЁЃ
|
|
вЛЁЂMask R-CNNЪЧЪВУДЃЌПЩвдзіФФаЉШЮЮёЃП
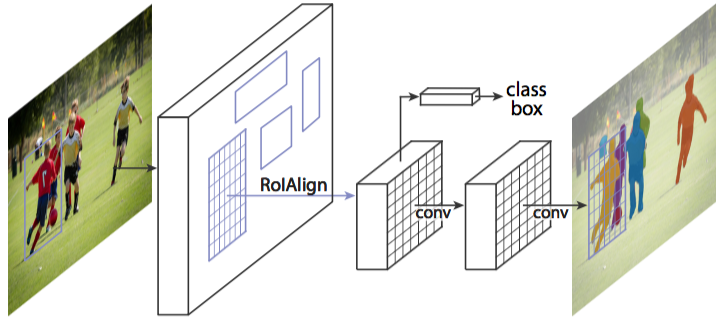
ЭМ1 Mask R-CNNећЬхМмЙЙ
Mask R-CNNЪЧвЛИіЪЕР§ЗжИюЃЈInstance segmentationЃЉЫуЗЈЃЌПЩвдгУРДзіЁАФПБъМьВтЁБЁЂЁАФПБъЪЕР§ЗжИюЁБЁЂЁАФПБъЙиМќЕуМьВтЁБЁЃ
1. ЪЕР§ЗжИюЃЈInstance segmentationЃЉКЭгявхЗжИюЃЈSemantic segmentationЃЉЕФЧјБ№гыСЊЯЕ
СЊЯЕЃКгявхЗжИюКЭЪЕР§ЗжИюЖМЪЧФПБъЗжИюжаЕФСНИіаЁЕФСьгђЃЌЖМЪЧгУРДЖдЪфШыЕФЭМЦЌзіЗжИюДІРэЃЛ
ЧјБ№ЃК

ЭМ2 ЪЕР§ЗжИюгыгявхЗжИюЧјБ№
1.ЭЈГЃвтвхЩЯЕФФПБъЗжИюжИЕФЪЧгявхЗжИюЃЌгявхЗжИювбОгаКмГЄЕФЗЂеЙРњЪЗЃЌвбОШЁЕУСЫКмКУЕиНјеЙЃЌФПЧАгаКмЖрЕФбЇепдкзіетЗНУцЕФбаОПЃЛШЛЖјЪЕР§ЗжИюЪЧвЛИіДгФПБъЗжИюСьгђЖРСЂГіРДЕФвЛИіаЁСьгђЃЌЪЧзюНќМИФъВХЗЂеЙЦ№РДЕФЃЌгыЧАепЯрБШЃЌКѓепИќМгИДдгЃЌЕБЧАбаОПЕФбЇепвВБШНЯЩйЃЌЪЧвЛИігабаОППеМфЕФШШУХСьгђЃЌШчЭМ1ЫљЪОЃЌетЪЧвЛИіе§дкЬНЫїжаЕФСьгђЃЛ
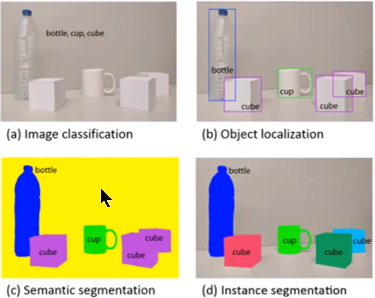
ЭМ3 ЪЕР§ЗжИюгыгявхЗжИюЧјБ№
2.ЙлВьЭМ3жаЕФcКЭdЭМЃЌcЭМЪЧЖдaЭМНјаагявхЗжИюЕФНсЙћЃЌdЭМЪЧЖдaЭМНјааЪЕР§ЗжИюЕФНсЙћЁЃСНепзюДѓЕФЧјБ№ОЭЪЧЭМжаЕФ"cubeЖдЯѓ"ЃЌдкгявхЗжИюжаИјСЫЫќУЧЯрЭЌЕФбеЩЋЃЌЖјдкЪЕР§ЗжИюжаШДИјСЫВЛЭЌЕФбеЩЋЁЃМДЪЕР§ЗжИюашвЊдкгявхЗжИюЕФЛљДЁЩЯЖдЭЌРрЮяЬхНјааИќОЋЯИЕФЗжИюЁЃ
зЂЃККмЖрВЉПЭжаЖМУЛгаЭъШЋРэНтЧхГўетИіЮЪЬтЃЌКмЖрШЫНЋетИіЫуЗЈПДзігявхЗжИюЃЌЦфЪЕЫќЪЧвЛИіЪЕР§ЗжИюЫуЗЈЁЃ
2. Mask R-CNNПЩвдЭъГЩЕФШЮЮё

ЭМ4 Mask R-CNNНјааФПБъМьВтгыЪЕР§ЗжИю

ЭМ5 Mask R-CNNНјааШЫЬхзЫЬЌЪЖБ№
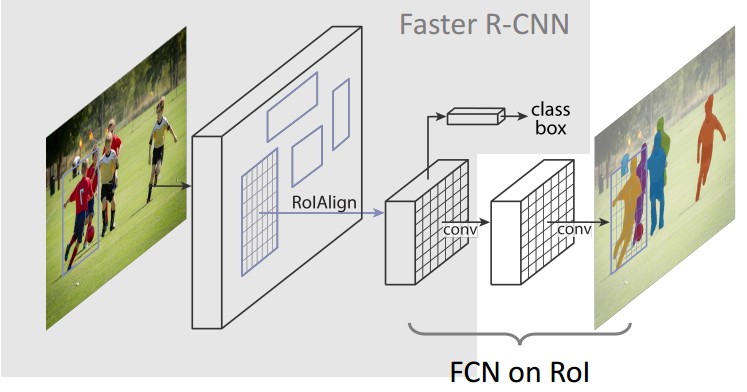
змжЎЃЌMask R-CNNЪЧвЛИіЗЧГЃСщЛюЕФПђМмЃЌПЩвддіМгВЛЭЌЕФЗжжЇЭъГЩВЛЭЌЕФШЮЮёЃЌПЩвдЭъГЩФПБъЗжРрЁЂФПБъМьВтЁЂгявхЗжИюЁЂЪЕР§ЗжИюЁЂШЫЬхзЫЪЦЪЖБ№ЕШЖржжШЮЮёЃЌецВЛРЂЪЧвЛИіКУЫуЗЈЃЁ
3.Mask R-CNNдЄЦкДяЕНЕФФПБъ
ИпЫй
ИпзМШЗТЪЃЈИпЕФЗжРрзМШЗТЪЁЂИпЕФМьВтзМШЗТЪЁЂИпЕФЪЕР§ЗжИюзМШЗТЪЕШЃЉ
МђЕЅжБЙл
взгкЪЙгУ
4. ШчКЮЪЕЯжетаЉФПБъ
ИпЫйКЭИпзМШЗТЪЃКЮЊСЫЪЕЯжетИіФПЕФЃЌзїепбЁгУСЫОЕфЕФФПБъМьВтЫуЗЈFaster-rcnnКЭОЕфЕФгявхЗжИюЫуЗЈFCNЁЃFaster-rcnnПЩвдМШПьгжзМЕФЭъГЩФПБъМьВтЕФЙІФмЃЛFCNПЩвдОЋзМЕФЭъГЩгявхЗжИюЕФЙІФмЃЌетСНИіЫуЗЈЖМЪЧЖдгІСьгђжаЕФОЕфжЎзїЁЃMask
R-CNNБШFaster-rcnnИДдгЃЌЕЋЪЧзюжеШдШЛПЩвдДяЕН5fpsЕФЫйЖШЃЌетКЭдЪМЕФFaster-rcnnЕФЫйЖШЯрЕБЁЃгЩгкЗЂЯжСЫROI
PoolingжаЫљДцдкЕФЯёЫиЦЋВюЮЪЬтЃЌЬсГіСЫЖдгІЕФROIAlignВпТдЃЌМгЩЯFCNОЋзМЕФЯёЫиMASKЃЌЪЙЕУЦфПЩвдЛёЕУИпзМШЗТЪЁЃ
МђЕЅжБЙлЃКећИіMask R-CNNЫуЗЈЕФЫМТЗКмМђЕЅЃЌОЭЪЧдкдЪМFaster-rcnnЫуЗЈЕФЛљДЁЩЯУцдіМгСЫFCNРДВњЩњЖдгІЕФMASKЗжжЇЁЃМДFaster-rcnn
+ FCNЃЌИќЯИжТЕФЪЧ RPN + ROIAlign + Fast-rcnn + FCNЁЃ
взгкЪЙгУЃКећИіMask R-CNNЫуЗЈЗЧГЃЕФСщЛюЃЌПЩвдгУРДЭъГЩЖржжШЮЮёЃЌАќРЈФПБъЗжРрЁЂФПБъМьВтЁЂгявхЗжИюЁЂЪЕР§ЗжИюЁЂШЫЬхзЫЬЌЪЖБ№ЕШЖрИіШЮЮёЃЌетНЋЦфвзгкЪЙгУЕФЬиЕуеЙЯжЕФСмРьОЁжТЁЃЮвКмЩйМћЕНгаФФИіЫуЗЈгаетУДКУЕФРЉеЙадКЭвзгУадЃЌжЕЕУЮвУЧбЇЯАКЭНшМјЁЃГ§ДЫжЎЭтЃЌЮвУЧПЩвдИќЛЛВЛЭЌЕФbackbone
architectureКЭHead ArchitectureРДЛёЕУВЛЭЌадФмЕФНсЙћЁЃ
ЖўЁЂMask R-CNNПђМмНтЮі
ЭМ6Mask R-CNNЫуЗЈПђМм
1.Mask R-CNNЫуЗЈВНжш
ЪзЯШЃЌЪфШывЛЗљФуЯыДІРэЕФЭМЦЌЃЌШЛКѓНјааЖдгІЕФдЄДІРэВйзїЃЌЛђепдЄДІРэКѓЕФЭМЦЌЃЛ
ШЛКѓЃЌНЋЦфЪфШыЕНвЛИідЄбЕСЗКУЕФЩёОЭјТчжаЃЈResNeXtЕШЃЉЛёЕУЖдгІЕФfeature mapЃЛ
НгзХЃЌЖдетИіfeature mapжаЕФУПвЛЕуЩшЖЈдЄЖЈИіЕФROIЃЌДгЖјЛёЕУЖрИіКђбЁROIЃЛ
НгзХЃЌНЋетаЉКђбЁЕФROIЫЭШыRPNЭјТчНјааЖўжЕЗжРрЃЈЧАОАЛђБГОАЃЉКЭBBЛиЙщЃЌЙ§ТЫЕєвЛВПЗжКђбЁЕФROIЃЛ
НгзХЃЌЖдетаЉЪЃЯТЕФROIНјааROIAlignВйзїЃЈМДЯШНЋдЭМКЭfeature mapЕФpixelЖдгІЦ№РДЃЌШЛКѓНЋfeature
mapКЭЙЬЖЈЕФfeatureЖдгІЦ№РДЃЉЃЛ
зюКѓЃЌЖдетаЉROIНјааЗжРрЃЈNРрБ№ЗжРрЃЉЁЂBBЛиЙщКЭMASKЩњГЩЃЈдкУПвЛИіROIРяУцНјааFCNВйзїЃЉЁЃ
2.Mask R-CNNМмЙЙЗжНт
дкетРяЃЌЮвНЋMask R-CNNЗжНтЮЊШчЯТЕФ3ИіФЃПщЃЌFaster-rcnnЁЂROIAlignКЭFCNЁЃШЛКѓЗжБ№Ждет3ИіФЃПщНјааНВНтЃЌетвВЪЧИУЫуЗЈЕФКЫаФЁЃ
3. Faster-rcnnЃЈИУЫуЗЈЧыВЮПМИУСДНгЃЌЮвНјааСЫЯъЯИЕФЗжЮіЃЉ
4. FCN
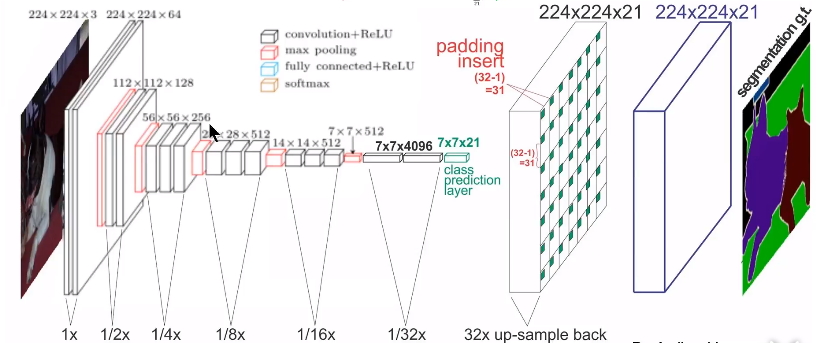
ЭМ7 FCNЭјТчМмЙЙ
FCNЫуЗЈЪЧвЛИіОЕфЕФгявхЗжИюЫуЗЈЃЌПЩвдЖдЭМЦЌжаЕФФПБъНјаазМШЗЕФЗжИюЁЃЦфзмЬхМмЙЙШчЩЯЭМЫљЪОЃЌЫќЪЧвЛИіЖЫЕНЖЫЕФЭјТчЃЌжївЊЕФФЃПьАќРЈОэЛ§КЭШЅОэЛ§ЃЌМДЯШЖдЭМЯёНјааОэЛ§КЭГиЛЏЃЌЪЙЦфfeature
mapЕФДѓаЁВЛЖЯМѕаЁЃЛШЛКѓНјааЗДОэЛ§ВйзїЃЌМДНјааВхжЕВйзїЃЌВЛЖЯЕФдіДѓЦфfeature mapЃЌзюКѓЖдУПвЛИіЯёЫижЕНјааЗжРрЁЃДгЖјЪЕЯжЖдЪфШыЭМЯёЕФзМШЗЗжИюЁЃОпЬхЕФЯИНкЧыВЮПМИУСДНгЁЃ
5. ROIPoolingКЭROIAlignЕФЗжЮігыБШНЯ
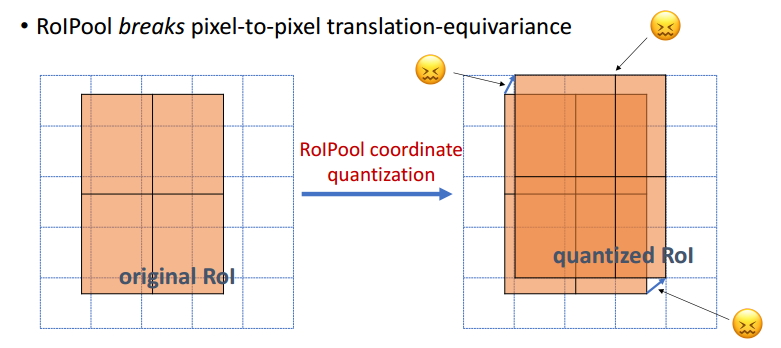
ЭМ8ROIPoolingКЭROIAlignЕФБШНЯ
ШчЭМ8ЫљЪОЃЌROI PoolingКЭROIAlignзюДѓЕФЧјБ№ЪЧЃКЧАепЪЙгУСЫСНДЮСПЛЏВйзїЃЌЖјКѓепВЂУЛгаВЩгУСПЛЏВйзїЃЌЪЙгУСЫЯпадВхжЕЫуЗЈЃЌОпЬхЕФНтЪЭШчЯТЫљЪОЁЃ
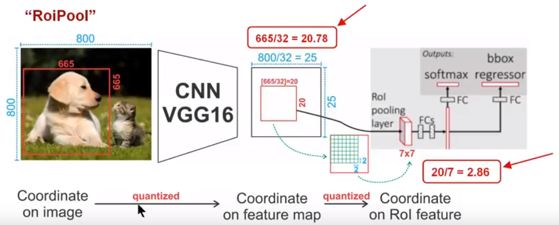
ЭМ9 ROI PoolingММЪѕ
ШчЭМ9ЫљЪОЃЌЮЊСЫЕУЕНЙЬЖЈДѓаЁЃЈ7X7ЃЉЕФfeature mapЃЌЮвУЧашвЊзіСНДЮСПЛЏВйзїЃК1ЃЉЭМЯёзјБъ
ЁЊ feature mapзјБъЃЌ2ЃЉfeature mapзјБъ ЁЊ ROI featureзјБъЁЃЮвУЧРДЫЕвЛЯТОпЬхЕФЯИНкЃЌШчЭМЮвУЧЪфШыЕФЪЧвЛеХ800x800ЕФЭМЯёЃЌдкЭМЯёжагаСНИіФПБъЃЈУЈКЭЙЗЃЉЃЌЙЗЕФBBДѓаЁЮЊ665x665ЃЌОЙ§VGG16ЭјТчКѓЃЌЮвУЧПЩвдЛёЕУЖдгІЕФfeature
mapЃЌШчЙћЮвУЧЖдОэЛ§ВуНјааPaddingВйзїЃЌЮвУЧЕФЭМЦЌОЙ§ОэЛ§ВуКѓБЃГждРДЕФДѓаЁЃЌЕЋЪЧгЩгкГиЛЏВуЕФДцдкЃЌЮвУЧзюжеЛёЕУfeature
map ЛсБШдЭМЫѕаЁвЛЖЈЕФБШР§ЃЌетКЭPoolingВуЕФИіЪ§КЭДѓаЁгаЙиЁЃдкИУVGG16жаЃЌЮвУЧЪЙгУСЫ5ИіГиЛЏВйзїЃЌУПИіГиЛЏВйзїЖМЪЧ2PoolingЃЌвђДЫЮвУЧзюжеЛёЕУfeature
mapЕФДѓаЁЮЊ800/32 x 800/32 = 25x25ЃЈЪЧећЪ§ЃЉЃЌЕЋЪЧНЋЙЗЕФBBЖдгІЕНfeature
mapЩЯУцЃЌЮвУЧЕУЕНЕФНсЙћЪЧ665/32 x 665/32 = 20.78 x 20.78ЃЌНсЙћЪЧИЁЕуЪ§ЃЌКЌгааЁЪ§ЃЌЕЋЪЧЮвУЧЕФЯёЫижЕПЩУЛгааЁЪ§ЃЌФЧУДзїепОЭЖдЦфНјааСЫСПЛЏВйзїЃЈМДШЁећВйзїЃЉЃЌМДЦфНсЙћБфЮЊ20
x 20ЃЌдкетРяв§ШыСЫЕквЛДЮЕФСПЛЏЮѓВюЃЛШЛЖјЮвУЧЕФfeature mapжагаВЛЭЌДѓаЁЕФROIЃЌЕЋЪЧЮвУЧКѓУцЕФЭјТчШДвЊЧѓЮвУЧгаЙЬЖЈЕФЪфШыЃЌвђДЫЃЌЮвУЧашвЊНЋВЛЭЌДѓаЁЕФROIзЊЛЏЮЊЙЬЖЈЕФROI
featureЃЌдкетРяЪЙгУЕФЪЧ7x7ЕФROI featureЃЌФЧУДЮвУЧашвЊНЋ20 x 20ЕФROIгГЩфГЩ7
x 7ЕФROI featureЃЌЦфНсЙћЪЧ 20 /7 x 20/7 = 2.86 x 2.86ЃЌЭЌбљЪЧИЁЕуЪ§ЃЌКЌгааЁЪ§ЕуЃЌЮвУЧВЩШЁЭЌбљЕФВйзїЖдЦфНјааШЁећАЩЃЌдкетРяв§ШыСЫЕкЖўДЮСПЛЏЮѓВюЁЃЦфЪЕЃЌетРяв§ШыЕФЮѓВюЛсЕМжТЭМЯёжаЕФЯёЫиКЭЬиеїжаЕФЯёЫиЕФЦЋВюЃЌМДНЋfeatureПеМфЕФROIЖдгІЕНдЭМЩЯУцЛсГіЯжКмДѓЕФЦЋВюЁЃдвђШчЯТЃКБШШчгУЮвУЧЕкЖўДЮв§ШыЕФЮѓВюРДЗжЮіЃЌБОРДЪЧ2,86ЃЌЮвУЧНЋЦфСПЛЏЮЊ2ЃЌетЦкМфв§ШыСЫ0.86ЕФЮѓВюЃЌПДЦ№РДЪЧвЛИіКмаЁЕФЮѓВюбНЃЌЕЋЪЧФувЊМЧЕУетЪЧдкfeatureПеМфЃЌЮвУЧЕФfeatureПеМфКЭЭМЯёПеМфЪЧгаБШР§ЙиЯЕЕФЃЌдкетРяЪЧ1:32ЃЌФЧУДЖдгІЕНдЭМЩЯУцЕФВюОрОЭЪЧ0.86
x 32 = 27.52ЁЃетИіВюОрВЛаЁАЩЃЌетЛЙЪЧНіНіПМТЧСЫЕкЖўДЮЕФСПЛЏЮѓВюЁЃетЛсДѓДѓгАЯьећИіМьВтЫуЗЈЕФадФмЃЌвђДЫЪЧвЛИібЯжиЕФЮЪЬтЁЃКУЕФЃЌгІИУНтЪЭЧхГўСЫАЩЃЌКУРлЃЁ
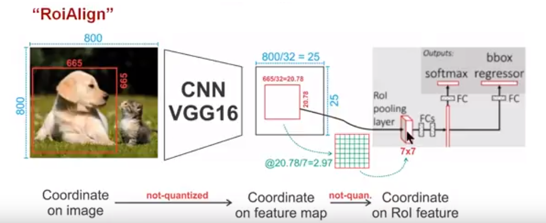
ЭМ10 ROIAlignММЪѕ
ШчЭМ10ЫљЪОЃЌЮЊСЫЕУЕНЮЊСЫЕУЕНЙЬЖЈДѓаЁЃЈ7X7ЃЉЕФfeature mapЃЌROIAlignММЪѕВЂУЛгаЪЙгУСПЛЏВйзїЃЌМДЮвУЧВЛЯыв§ШыСПЛЏЮѓВюЃЌБШШч665
/ 32 = 20.78ЃЌЮвУЧОЭгУ20.78ЃЌВЛгУЪВУД20РДЬцДњЫќЃЌБШШч20.78 / 7 = 2.97ЃЌЮвУЧОЭгУ2.97ЃЌЖјВЛгУ2РДДњЬцЫќЁЃетОЭЪЧROIAlignЕФГѕждЁЃФЧУДЮвУЧШчКЮДІРэетаЉИЁЕуЪ§ФиЃЌЮвУЧЕФНтОіЫМТЗЪЧЪЙгУЁАЫЋЯпадВхжЕЁБЫуЗЈЁЃЫЋЯпадВхжЕЪЧвЛжжБШНЯКУЕФЭМЯёЫѕЗХЫуЗЈЃЌЫќГфЗжЕФРћгУСЫдЭМжаащФтЕуЃЈБШШч20.56етИіИЁЕуЪ§ЃЌЯёЫиЮЛжУЖМЪЧећЪ§жЕЃЌУЛгаИЁЕужЕЃЉЫФжмЕФЫФИіецЪЕДцдкЕФЯёЫижЕРДЙВЭЌОіЖЈФПБъЭМжаЕФвЛИіЯёЫижЕЃЌМДПЩвдНЋ20.56етИіащФтЕФЮЛжУЕуЖдгІЕФЯёЫижЕЙРМЦГіРДЁЃРїКІЙўЁЃШчЭМ11ЫљЪОЃЌРЖЩЋЕФащЯпПђБэЪООэЛ§КѓЛёЕУЕФfeature
mapЃЌКкЩЋЪЕЯпПђБэЪОROI featureЃЌзюКѓашвЊЪфГіЕФДѓаЁЪЧ2x2ЃЌФЧУДЮвУЧОЭРћгУЫЋЯпадВхжЕРДЙРМЦетаЉРЖЕуЃЈащФтзјБъЕуЃЌгжГЦЫЋЯпадВхжЕЕФЭјИёЕуЃЉДІЫљЖдгІЕФЯёЫижЕЃЌзюКѓЕУЕНЯргІЕФЪфГіЁЃетаЉРЖЕуЪЧ2x2CellжаЕФЫцЛњВЩбљЕФЦеЭЈЕуЃЌзїепжИГіЃЌетаЉВЩбљЕуЕФИіЪ§КЭЮЛжУВЛЛсЖдадФмВњЩњКмДѓЕФгАЯьЃЌФувВПЩвдгУЦфЫќЕФЗНЗЈЛёЕУЁЃШЛКѓдкУПвЛИіщйКьЩЋЕФЧјгђРяУцНјааmax
poolingЛђепaverage poolingВйзїЃЌЛёЕУзюже2x2ЕФЪфГіНсЙћЁЃЮвУЧЕФећИіЙ§ГЬжаУЛгагУЕНСПЛЏВйзїЃЌУЛгав§ШыЮѓВюЃЌМДдЭМжаЕФЯёЫиКЭfeature
mapжаЕФЯёЫиЪЧЭъШЋЖдЦыЕФЃЌУЛгаЦЋВюЃЌетВЛНіЛсЬсИпМьВтЕФОЋЖШЃЌЭЌЪБвВЛсгаРћгкЪЕР§ЗжИюЁЃетУДЯИаФЃЌзіПЦбаОЭгІИУЙизЂЯИНкЃЌЯИНкОіЖЈГЩАмЁЃ
we propose an RoIAlign layer that
removes the harsh quantization of RoIPool, properly
aligning the extracted features with the input. Our
proposed change is simple: we avoid any quantization
of the RoI boundaries or bins (i.e., we use x=16 instead
of [x=16]). We use bilinear interpolation [22] to
compute the exact values of the input features at
four regularly sampled locations in each RoI bin,
and aggregate the result (using max or average), see
Figure 3 for details. We note that the results are
not sensitive to the exact sampling locations, or
how many points are sampled, as long as no quantization
is performedЁЃ
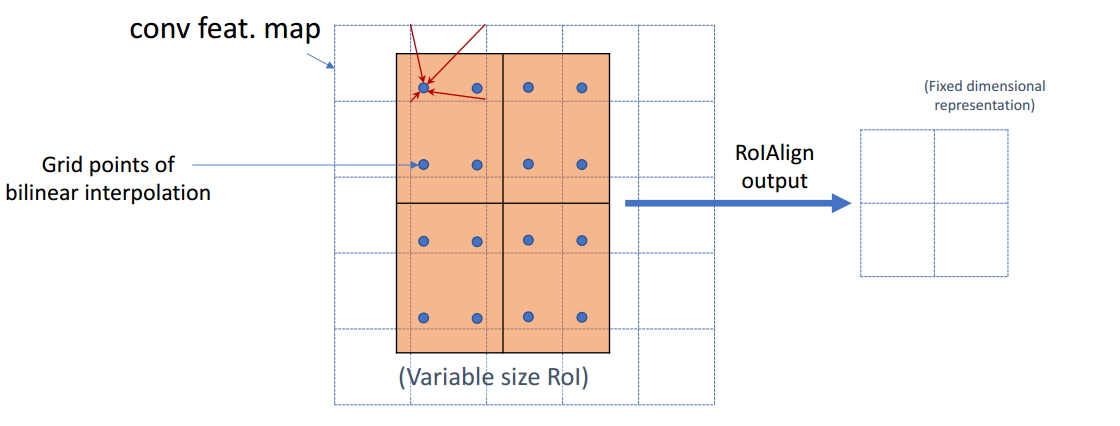
ЭМ11 ЫЋЯпадВхжЕ
6. LOSSМЦЫугыЗжЮі
гЩгкдіМгСЫmaskЗжжЇЃЌУПИіROIЕФLossКЏЪ§ШчЯТЫљЪОЃК
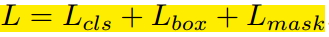
ЦфжаLclsКЭLboxКЭFaster r-cnnжаЖЈвхЕФЯрЭЌЁЃЖдгкУПвЛИіROIЃЌmaskЗжжЇгаKm*mЮЌЖШЕФЪфГіЃЌЦфЖдKИіДѓаЁЮЊm*mЕФmaskНјааБрТыЃЌУПвЛИіmaskгаKИіРрБ№ЁЃЮвУЧЪЙгУСЫper-pixel
sigmoidЃЌВЂЧвНЋLmaskЖЈвхЮЊthe average binary cross-entropy
lossЁЃЖдгІвЛИіЪєгкGTжаЕФЕкkРрЕФROIЃЌLmaskНіНідкЕкkИіmaskЩЯУцгаЖЈвхЃЈЦфЫќЕФk-1ИіmaskЪфГіЖдећИіLossУЛгаЙБЯзЃЉЁЃЮвУЧЖЈвхЕФLmaskдЪаэЭјТчЮЊУПвЛРрЩњГЩвЛИіmaskЃЌЖјВЛгУКЭЦфЫќРрНјааОКељЃЛЮвУЧвРРЕгкЗжРрЗжжЇЫљдЄВтЕФРрБ№БъЧЉРДбЁдёЪфГіЕФmaskЁЃетбљНЋЗжРрКЭmaskЩњГЩЗжНтПЊРДЁЃетгыРћгУFCNНјаагявхЗжИюЕФгаЫљВЛЭЌЃЌЫќЭЈГЃЪЙгУвЛИіper-pixel
sigmoidКЭвЛИіmultinomial cross-entropy lossЃЌдкетжжЧщПіЯТmaskжЎМфДцдкОКељЙиЯЕЃЛЖјгЩгкЮвУЧЪЙгУСЫвЛИіper-pixel
sigmoid КЭвЛИіbinary lossЃЌВЛЭЌЕФmaskжЎМфВЛДцдкОКељЙиЯЕЁЃОбщБэУїЃЌетПЩвдЬсИпЪЕР§ЗжИюЕФаЇЙћЁЃ
вЛИіmaskЖдвЛИіФПБъЕФЪфШыПеМфВМОжНјааБрТыЃЌгыРрБ№БъЧЉКЭBBЦЋжУВЛЭЌЃЌЫќУЧЭЈГЃашвЊЭЈЙ§FCВуЖјЕМжТЦфвдЖЬЯђСПЕФаЮЪНЪфГіЁЃЮвУЧПЩвдЭЈЙ§гЩОэЛ§ЬсЙЉЕФЯёЫиКЭЯёЫиЕФЖдгІЙиЯЕРДЛёЕУmaskЕФПеМфНсЙЙаХЯЂЁЃОпЬхЕФРДЫЕЃЌЮвУЧЪЙгУFCNДгУПвЛИіROIжадЄВтГівЛИіm*mДѓаЁЕФmaskЃЌетЪЙЕУmaskЗжжЇжаЕФУПИіВуФмЙЛУїШЗЕФБЃГжmЁСmПеМфВМОжЃЌЖјВЛНЋЦфелЕўГЩШБЩйПеМфЮЌЖШЕФЯђСПБэЪОЁЃКЭвдЧАгУfcВузіmaskдЄВтЕФЗНЗЈВЛЭЌЕФЪЧЃЌЮвУЧЕФЪЕбщБэУїЮвУЧЕФmaskБэЪОашвЊИќЩйЕФВЮЪ§ЃЌЖјЧвИќМгзМШЗЁЃетаЉЯёЫиЕНЯёЫиЕФааЮЊашвЊЮвУЧЕФROIЬиеїЃЌЖјЮвУЧЕФROIЬиеїЭЈГЃЪЧБШНЯаЁЕФfeature
mapЃЌЦфвбОНјааСЫЖдЦфВйзїЃЌЮЊСЫвЛжТЕФНЯКУЕФБЃГжУїШЗЕФЕЅЯёЫиПеМфЖдгІЙиЯЕЃЌЮвУЧЬсГіСЫROIAlignВйзїЁЃ
Ш§ЁЂMask R-CNNЯИНкЗжЮі
1.Head Architecture
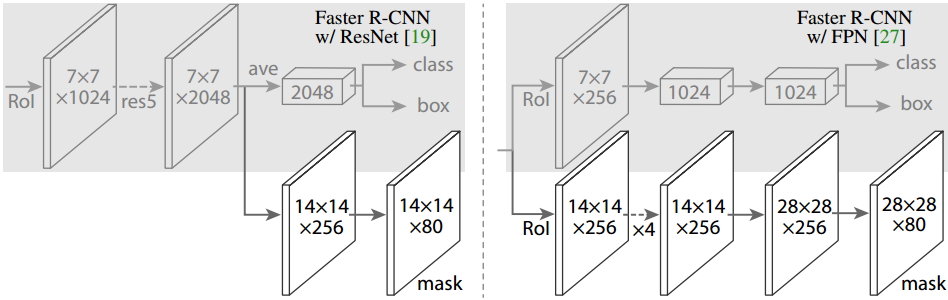
ЭМ12 Head Architecture
ШчЩЯЭМЫљЪОЃЌЮЊСЫВњЩњЖдгІЕФMaskЃЌЮФжаЬсГіСЫСНжжМмЙЙЃЌМДзѓБпЕФFaster
R-CNN/ResNetКЭгвБпЕФFaster R-CNN/FPNЁЃЖдгкзѓБпЕФМмЙЙЃЌЮвУЧЕФbackboneЪЙгУЕФЪЧдЄбЕСЗКУЕФResNetЃЌЪЙгУСЫResNetЕЙЪ§Ек4ВуЕФЭјТчЁЃЪфШыЕФROIЪзЯШЛёЕУ7x7x1024ЕФROI
featureЃЌШЛКѓНЋЦфЩ§ЮЌЕН2048ИіЭЈЕРЃЈетРяаоИФСЫдЪМЕФResNetЭјТчМмЙЙЃЉЃЌШЛКѓгаСНИіЗжжЇЃЌЩЯУцЕФЗжжЇИКд№ЗжРрКЭЛиЙщЃЌЯТУцЕФЗжжЇИКд№ЩњГЩЖдгІЕФmaskЁЃгЩгкЧАУцНјааСЫЖрДЮОэЛ§КЭГиЛЏЃЌМѕаЁСЫЖдгІЕФЗжБцТЪЃЌmaskЗжжЇПЊЪМРћгУЗДОэЛ§НјааЗжБцТЪЕФЬсЩ§ЃЌЭЌЪБМѕЩйЭЈЕРЕФИіЪ§ЃЌБфЮЊ14x14x256ЃЌзюКѓЪфГіСЫ14x14x80ЕФmaskФЃАхЁЃЖјгвБпЪЙгУЕНЕФbackboneЪЧFPNЭјТчЃЌетЪЧвЛИіаТЕФЭјТчЃЌЭЈЙ§ЪфШыЕЅвЛГпЖШЕФЭМЦЌЃЌзюКѓПЩвдЖдгІЕФЬиеїН№зжЫўЃЌШчЙћЯывЊСЫНтЫќЕФЯИНкЃЌЧыВЮПМИУСДНгЁЃЕУЕНжЄЪЕЕФЪЧЃЌИУЭјТчПЩвддквЛЖЈГЬЖШЩЯУцЬсИпМьВтЕФОЋЖШЃЌЕБЧАКмЖрЕФЗНЗЈЖМгУЕНСЫЫќЁЃгЩгкFPNЭјТчвбОАќКЌСЫres5ЃЌПЩвдИќМгИпаЇЕФЪЙгУЬиеїЃЌвђДЫетРяЪЙгУСЫНЯЩйЕФfiltersЁЃИУМмЙЙвВЗжЮЊСНИіЗжжЇЃЌзїгУгкЧАепЯрЭЌЃЌЕЋЪЧЗжРрЗжжЇКЭmaskЗжжЇКЭЧАепЯрБШгаКмДѓЕФЧјБ№ЁЃПЩФмЪЧвђЮЊFPNЭјТчПЩвддкВЛЭЌГпЖШЕФЬиеїЩЯУцЛёЕУаэЖргагУаХЯЂЃЌвђДЫЗжРрЪБЪЙгУСЫИќЩйЕФТЫВЈЦїЁЃЖјmaskЗжжЇжаНјааСЫЖрДЮОэЛ§ВйзїЃЌЪзЯШНЋROIБфЛЏЮЊ14x14x256ЕФfeatureЃЌШЛКѓНјааСЫ5ДЮЯрЭЌЕФВйзїЃЈВЛЧхГўетРяЕФдРэЃЌЦкД§зХФуЕФНтЪЭЃЉЃЌШЛКѓНјааЗДОэЛ§ВйзїЃЌзюКѓЪфГі28x28x80ЕФmaskЁЃМДЪфГіСЫИќДѓЕФmaskЃЌгыЧАепЯрБШПЩвдЛёЕУИќЯИжТЕФmaskЁЃ

ЭМ13 BBЪфГіЕФmaskНсЙћ
ШчЩЯЭМЫљЪОЃЌЭМЯёжаКьЩЋЕФBBБэЪОМьВтЕНЕФФПБъЃЌЮвУЧПЩвдгУШтблПЩвдЙлВьЕНМьВтНсЙћВЂВЛЪЧКмКУЃЌМДећИіBBЩдЮЂЦЋгвЃЌзѓБпЕФвЛВПЗжЯёЫиВЂУЛгаАќРЈдкBBжЎФкЃЌЕЋЪЧгвБпЯдЪОЕФзюжеНсЙћШДКмЭъУРЁЃ
2.Equivariance in Mask R-CNN
Equivariance жИЫцзХЪфШыЕФБфЛЏЪфГівВЛсЗЂЩњБфЛЏЁЃ
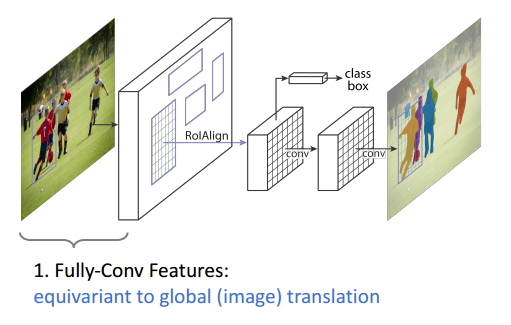
ЭМ14 Equivariance 1
МДШЋОэЛ§ЬиеїЃЈFaster R-CNNЭјТчЃЉКЭЭМЯёЕФБфЛЛОпгаЭЌБфаЮЃЌМДЫцзХЭМЯёЕФБфЛЛЃЌШЋОэЛ§ЕФЬиеївВЛсЗЂЩњЖдгІЕФБфЛЏЃЛ
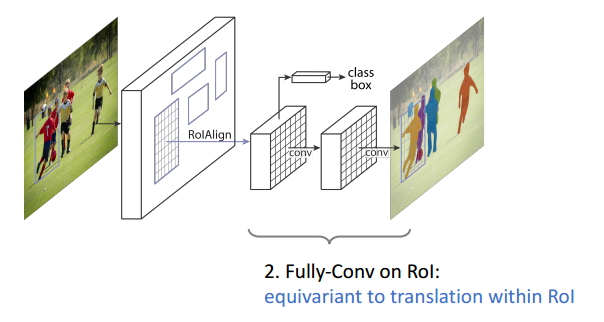
ЭМ15 Equivariance2
дкROIЩЯУцЕФШЋОэЛ§ВйзїЃЈFCNЭјТчЃЉКЭдкROIжаЕФБфЛЛОпгаЭЌБфадЃЛ
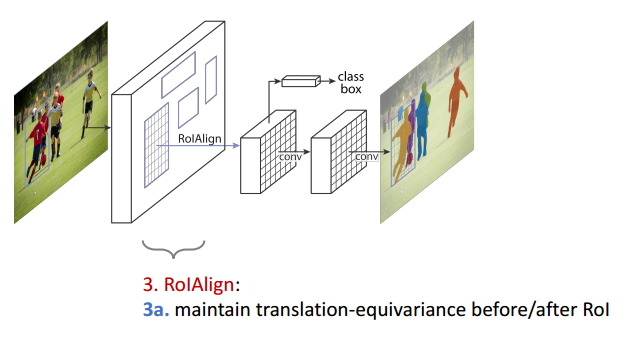
ЭМ16 Equivariance3
ROIAlignВйзїБЃГжСЫROIБфЛЛЧАКѓЕФЭЌБфадЃЛ

ЭМ17 ROIжаЕФШЋОэЛ§
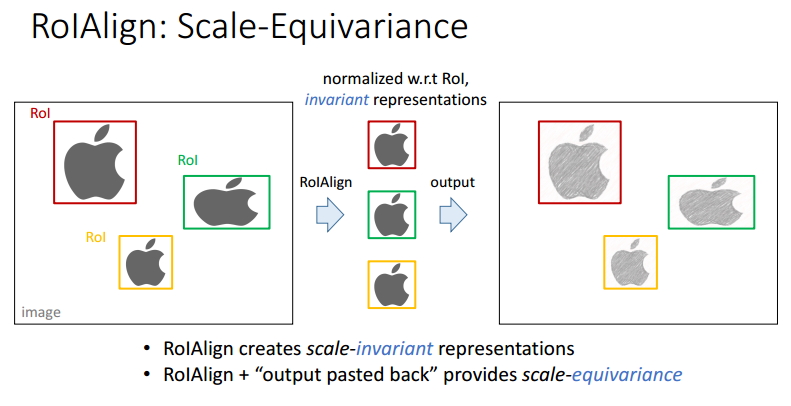
ЭМ18 ROIAlignЕФГпЖШЭЌБфад

ЭМ19 Mask R-CNNжаЕФЭЌБфадзмНс
3. ЫуЗЈЪЕЯжЯИНк

ЭМ20 ЫуЗЈЪЕЯжЯИНк
ЙлВьЩЯЭМЃЌЮвУЧПЩвдЕУЕНвдЯТЕФаХЯЂЃК
Mask R-CNNжаЕФГЌВЮЪ§ЖМЪЧгУСЫFaster r-cnnжаЕФжЕЃЌЛњжЧЃЌЪЁЪБЪЁСІЃЌаЇЙћЛЙКУЃЌБ№ШЫвбОЬцФуЕїНкЙ§РВЃЌЙўЙўЙўЃЛ
ЪЙгУЕНЕФдЄбЕСЗЭјТчАќРЈResNet50ЁЂResNet101ЁЂFPNЃЌЖМЪЧвЛаЉадФмКмКУЕиЭјТчЃЌгШЦфЪЧFPNЃЌКѓУцЛсгаЗжЮіЃЛ
ЖдгкЙ§ДѓЕФЭМЦЌЃЌЫќЛсНЋЦфВУМєГЩ800x800ДѓаЁЃЌЭМЯёЬЋДѓЕФЛАЛсДѓДѓЕФдіМгМЦЫуСПЕФЃЛ
РћгУ8ИіGPUЭЌЪБбЕСЗЃЌПЊЪМЕФбЇЯАТЪЪЧ0.01ЃЌОЙ§18kДЮНЋЦфЫЅМѕЮЊ0.001ЃЌResNet50-FPNЭјТчбЕСЗСЫ32аЁЪБЃЌResNet101-FPNбЕСЗСЫ44аЁЪБЃЛ
дкNvidia Tesla M40 GPUЩЯУцЕФВтЪдЪБМфЪЧ195ms/еХЃЛ
ЪЙгУСЫMS COCOЪ§ОнМЏЃЌНЋ120kЕФЪ§ОнМЏЛЎЗжЮЊ80kЕФбЕСЗМЏЁЂ35kЕФбщжЄМЏКЭ5kЕФВтЪдМЏЃЛ
ЫФЁЂадФмБШНЯ
1. ЖЈСПНсЙћЗжЮі
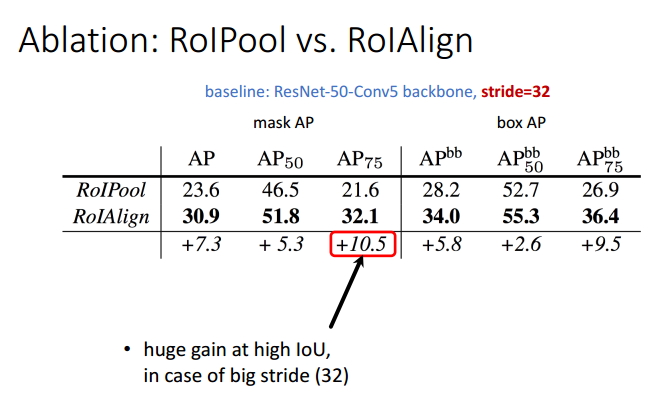
Бэ1 ROI PoolКЭROIAlignадФмБШНЯ
гЩЧАУцЕФЗжЮіЃЌЮвУЧОЭПЩвдЖЈадЕФЕУЕНвЛИіНсТлЃЌROIAlignЛсЪЙЕУФПБъМьВтЕФаЇЙћгаКмДѓЕФадФмЬсЩ§ЁЃИљОнЩЯБэЃЌЮвУЧНјааЖЈСПЕФЗжЮіЃЌНсЙћБэУїЃЌROIAlignЪЙЕУmaskЕФAPжЕЬсЩ§СЫ10.5ИіАйЗжЕуЃЌЪЙЕУboxЕФAPжЕЬсЩ§СЫ9.5ИіАйЗжЕуЁЃ
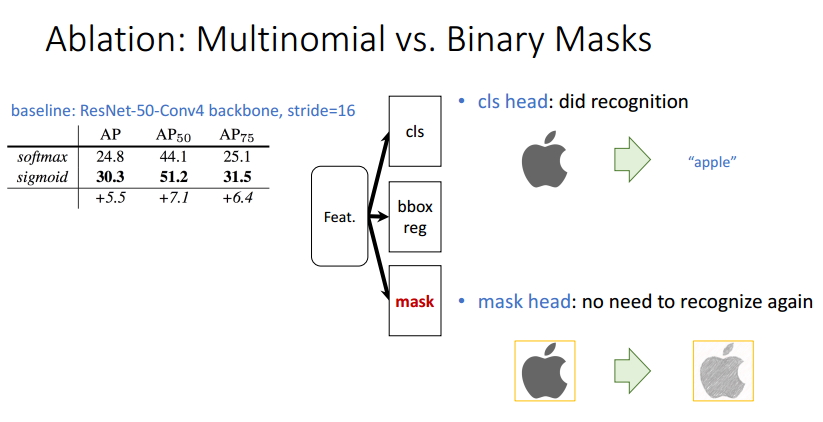
Бэ2 MultinomialКЭBinary lossБШНЯ
ИљОнЩЯБэЕФЗжЮіЃЌЮвУЧжЊЕРMask R-CNNРћгУСНИіЗжжЇНЋЗжРрКЭmaskЩњГЩНтёюГіРДЃЌШЛКѓРћгУBinary
LossДњЬцMultinomial LossЃЌЪЙЕУВЛЭЌРрБ№ЕФmaskжЎМфЯћГ§СЫОКељЁЃвРРЕгкЗжРрЗжжЇЫљдЄВтЕФРрБ№БъЧЉРДбЁдёЪфГіЖдгІЕФmaskЁЃЪЙЕУmaskЗжжЇВЛашвЊНјаажиаТЕФЗжРрЙЄзїЃЌЪЙЕУадФмЕУЕНСЫЬсЩ§ЁЃ

Бэ3 MLPгыFCN maskадФмБШНЯ
ШчЩЯБэЫљЪОЃЌMLPМДРћгУFCРДЩњГЩЖдгІЕФmaskЃЌЖјFCNРћгУConvРДЩњГЩЖдгІЕФmaskЃЌНіНіДгВЮЪ§СПЩЯРДНВЃЌКѓепБШЧАепЩйСЫКмЖрЃЌетбљВЛНіЛсНкдМДѓСПЕФФкДцПеМфЃЌЭЌЪБЛсМгЫйећИібЕСЗЙ§ГЬЃЈвђДЫашвЊНјааЭЦРэЁЂИќаТЕФВЮЪ§ИќЩйРВЃЉЁЃГ§ДЫжЎЭтЃЌгЩгкMLPЛёЕУЕФЬиеїБШНЯГщЯѓЃЌЪЙЕУзюжеЕФmaskжаЖЊЪЇСЫвЛВПЗжгагУаХЯЂЃЌЮвУЧПЩвджБЙлЕФДггвБпПДЕНВюБ№ЁЃДгЖЈадНЧЖШРДНВЃЌFCNЪЙЕУmask
APжЕЬсЩ§СЫ2.1ИіАйЗжЕуЁЃ
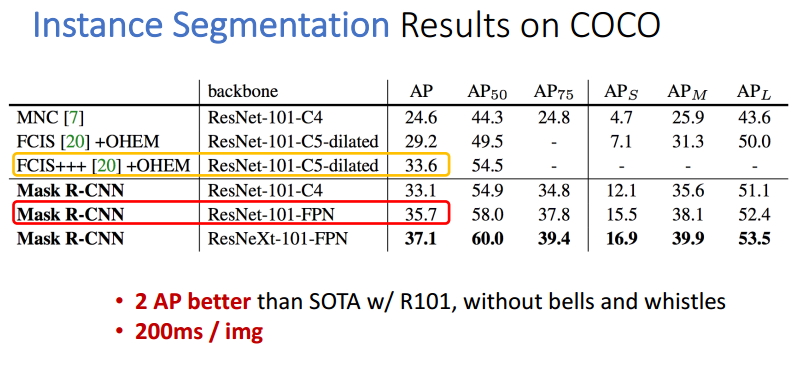
Бэ4 ЪЕР§ЗжИюЕФНсЙћ
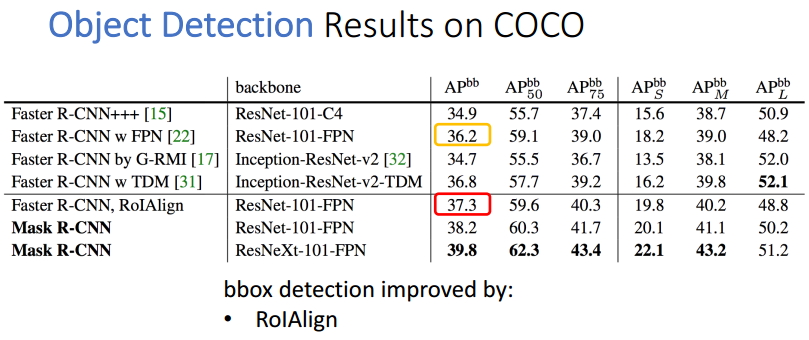
Бэ5 ФПБъМьВтЕФНсЙћ
ЙлВьФПБъМьВтЕФБэИёЃЌЮвУЧПЩвдЗЂЯжЪЙгУСЫROIAlignВйзїЕФFaster R-CNNЫуЗЈадФмЕУЕНСЫ0.9ИіАйЗжЕуЃЌMask
R-CNNБШзюКУЕФFaster R-CNNИпГіСЫ2.6ИіАйЗжЕуЁЃ
2. ЖЈадНсЙћЗжЮі

ЭМ21 ЪЕР§ЗжИюНсЙћ1

ЭМ22 ЪЕР§ЗжИюНсЙћ2
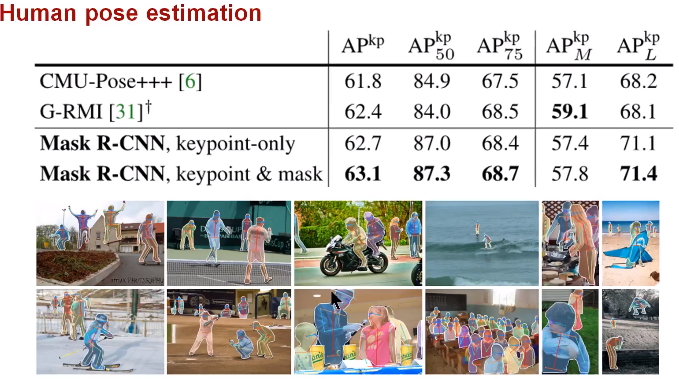
ЭМ23 ШЫЬхзЫЪЦЪЖБ№НсЙћ

ЭМ24 ЪЇАмМьВтАИР§1
ЭМ25 ЪЇАмМьВтАИР§2
ЮхЁЂзмНс
Mask R-CNNТлЮФЕФжївЊЙБЯзАќРЈвдЯТМИЕуЃК
ЗжЮіСЫROI PoolЕФВЛзуЃЌЬсЩ§СЫROIAlignЃЌЬсЩ§СЫМьВтКЭЪЕР§ЗжИюЕФаЇЙћЃЛ
НЋЪЕР§ЗжИюЗжНтЮЊЗжРрКЭmaskЩњГЩСНИіЗжжЇЃЌвРРЕгкЗжРрЗжжЇЫљдЄВтЕФРрБ№БъЧЉРДбЁдёЪфГіЖдгІЕФmaskЁЃЭЌЪБРћгУBinary
LossДњЬцMultinomial LossЃЌЯћГ§СЫВЛЭЌРрБ№ЕФmaskжЎМфЕФОКељЃЌЩњГЩСЫзМШЗЕФЖўжЕmaskЃЛ
ВЂааНјааЗжРрКЭmaskЩњГЩШЮЮёЃЌЖдФЃаЭНјааСЫМгЫйЁЃ
|






