| БрМЭЦМі: |
БОЮФРДздгкibmЃЌЮФеТНщЩмСЫОэЛ§ЭјТчЕФЙЄзїдРэвдМАШчКЮЪЙгУ
Python ЪЕЯжвЛИіЖдЪжаДЪ§зжНјааЗжРрЕФМђЕЅЭјТчЁЃ |
|
дкШеГЃЩњЛюжаЕФФГвЛПЬЃЌФњПЩФмМћЙ§ФПБъЪЖБ№ЫуЗЈЕФФГжжЪЕМЪгІгУЃЌР§ШчФњЪжЛњЩуЯёЭЗЩЯЕФШЫСГМьВтЁЃВЛЙ§ЃЌЫќЕФЙЄзїдРэЪЧЪВУДЃПетаЉМЦЫуЛњЪгОѕНтОіЗНАИЕФКЫаФЪЧОэЛ§ЩёОЭјТч
(CNN)ЁЃМђЕЅРДНВЃЌетаЉЭјТчЪЧЬиБ№ЩЦгкИљОнВЛЬЋИДдгЕФЬиеїЙЙНЈИДдгЬиеїЕФЩёОЭјТчЁЃвЛИіОЕфЕФР§згОЭЪЧШЫСГМьВтЦїЃЌдчЦкИїВуИКд№БцБ№ГіДЙжБКЭЫЎЦНЯпЃЌКѓУцЕФНзЖЮИКд№евЕНБЧзгКЭзьАЭЁЃ
БОЮФНЋНтЪЭетаЉОэЛ§ЭјТчЕФЙЄзїдРэЁЃЛЙНЋеЙЪОШчКЮЪЙгУ Python ЪЕЯжвЛИіЖдЪжаДЪ§зжНјааЗжРрЕФМђЕЅЭјТчЁЃШУЮвУЧНјШые§ЬтЃЁ
ГѕЪЖЩёОЭјТч
БОЮФВЛЛсЯъЯИНщЩмЩёОЭјТчЕФвЛАуЙЄзїдРэЃЌЕЋФњашвЊгавЛЖЈЕФБГОАжЊЪЖВХФмДІРэОэЛ§ЭјТчЁЃЩёОЭјТчгавЛжжЗжВуМмЙЙЁЃУПВугЩвЛаЉНкЕузщГЩЃЌУПИіНкЕуЖдвЛИіЪфШыгааЇжДааФГжжЪ§бЇдЫЫуЃЌЭЈЙ§МЦЫуЛёЕУвЛИіЪфГіЁЃЬсЙЉИјШЮКЮИјЖЈНкЕуЕФЪфШыЖМЪЧЧАвЛВуЕФЪфГіЃЈвдМАЭЈГЃЕШгк
1 Лђ 0 ЕФЦЋжУЯюЃЉЕФМгШЈзмКЭЁЃЫуЗЈЛсдкбЕСЗЦкМфЛсбЇЯАетаЉШЈжиЁЃЮЊСЫбЇЯАетаЉВЮЪ§ЃЌПЩвдНЋдЫаавЛДЮбЕСЗЕФЪфГігыецЪЕжЕНјааБШНЯЃЌВЂЭЈЙ§дкЭјТчжаЗДЯђДЋВЅДэЮѓРДИќаТШЈжиЁЃ
ОэЛ§
ОэЛ§ЪЧвЛжжЪ§бЇдЫЫуЃЌЫќВЩгУФГжжЗНЪННЋвЛИіКЏЪ§ЁАгІгУЁБЕНСэвЛИіКЏЪ§ЁЃНсЙћПЩвдРэНтЮЊСНИіКЏЪ§ЕФЁАЛьКЯЬхЁБЁЃОэЛ§гЩвЛИіаЧКХ
(*) БэЪОЃЌетПЩФмгыаэЖрБрГЬгябджаЭЈГЃгУгкГЫЗЈЕФ * дЫЫуЗћЛьЯ§ЁЃ
ВЛЙ§ЃЌетЖдМьВтЭМЯёжаЕФФПБъгаКЮАяжњЃПЪТЪЕжЄУїЃЌОэЛ§ЗЧГЃЩУГЄМьВтЭМЯёжаЕФМђЕЅНсЙЙЃЌШЛКѓНсКЯетаЉМђЕЅЬиеїРДЙЙдьИќИДдгЕФЬиеїЁЃдкОэЛ§ЭјТчжаЃЌЛсдквЛЯЕСаЕФВуЩЯЗЂЩњДЫЙ§ГЬЃЌУПВуЖдЧАвЛВуЕФЪфГіжДаавЛДЮОэЛ§ЁЃ
ФЧУДЃЌФњЛсдкМЦЫуЛњЪгОѕжаЪЙгУФФжжОэЛ§ФиЃПвЊРэНтетвЛЕуЃЌЪзЯШБиаыСЫНтЭМЯёЕНЕзЪЧЪВУДЁЃЭМЯёЪЧвЛжжЖўНзЛђШ§НззжНкЪ§зщЃЌЖўНзЪ§зщАќКЌПэЖШКЭИпЖШСНИіЮЌЖШЃЌШ§НзЪ§зщга
3 ИіЮЌЖШЃЌАќРЈПэЖШЁЂИпЖШКЭЖрИіЭЈЕРЁЃЫљвдЛвНзЭМЪЧЖўНзЕФЃЌЖј RGB ЭМЪЧШ§НзЕФЃЈАќКЌ 3 ИіЭЈЕРЃЉЁЃзжНкЕФжЕБЛМђЕЅНтЪЭЮЊећЪ§жЕЃЌУшЪіСЫБиаыдкЯргІЯёЫиЩЯЪЙгУЕФЬиЖЈЭЈЕРЪ§СПЁЃЫљвдЛљБОЩЯНВЃЌдкДІРэМЦЫуЛњЪгОѕЪБЃЌПЩвдНЋвЛИіЭМЯёЯыЯѓЮЊвЛИі
2D Ъ§зжЪ§зщЃЈЖдгк RGB Лђ RGBA ЭМЯёЃЌПЩвдНЋЫќУЧЯыЯѓЮЊ 3 ИіЛђ 4 Иі 2D Ъ§зжЪ§зщЕФЯрЛЅжиЕўЃЉЁЃ
вђДЫЃЌЮвЕФОэЛ§ЛёШЁДЫЪ§зщЃЈЮвднЪБМйЩшИУЭМЪЧЛвНзЕФЃЉЃЌВЂНЋЫќгыЕкЖўИіЪ§зщЃЈвЛИіЙ§ТЫЦїЃЉНјааОэЛ§дЫЫуЁЃОэЛ§Й§ГЬШчЯТЁЃЪзЯШЃЌНЋЙ§ТЫЦїЕўМгдкЭМЯёЪ§зщЕФзѓЩЯВПЁЃНгЯТРДЃЌЖдЙ§ТЫЦїМАЦфФПЧАЫљдкЕФЭМЯёзгВПЗжжДааЖдгІдЊЫиГЫЛ§ЁЃвВОЭЪЧЫЕЃЌНЋЙ§ТЫЦїЕФзѓЩЯВПдЊЫигыЭМЯёЕФзѓЩЯВПдЊЫиЯрГЫЃЌвРДЫРрЭЦЁЃШЛКѓЃЌНЋетаЉНсЙћЯрМгРДЩњГЩвЛИіжЕЁЃНгзХЃЌНЋЙ§ТЫЦїдкЭМЯёЩЯвЦЖЏвЛЖЮОрРыЃЈГЦЮЊВНЗљЃЉЃЌВЂжиИДИУЙ§ГЬЁЃДЫЙ§ГЬЕФЪфГіЪЧвЛИіОпгагыЭМЯёЪ§зщВЛЭЌЮЌЪ§ЕФаТЪ§зщЃЈНсЙћЭЈГЃОпгаИќаЁЕФПэЖШКЭИпЖШЃЌЕЋАќКЌИќЖрЕФЭЈЕРЃЉЁЃЮЊСЫбнЪООэЛ§дЫЫуЕФЙЄзїдРэЃЌШУЮвУЧРДПДвЛИіЪОР§ЁЃетЪЧвЛИі
3 x 3 Й§ТЫЦїЃК
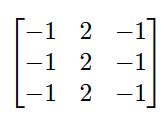
ЮвНЋАбетИіЙ§ТЫЦїгІгУЕНЯТЭМЁЃ
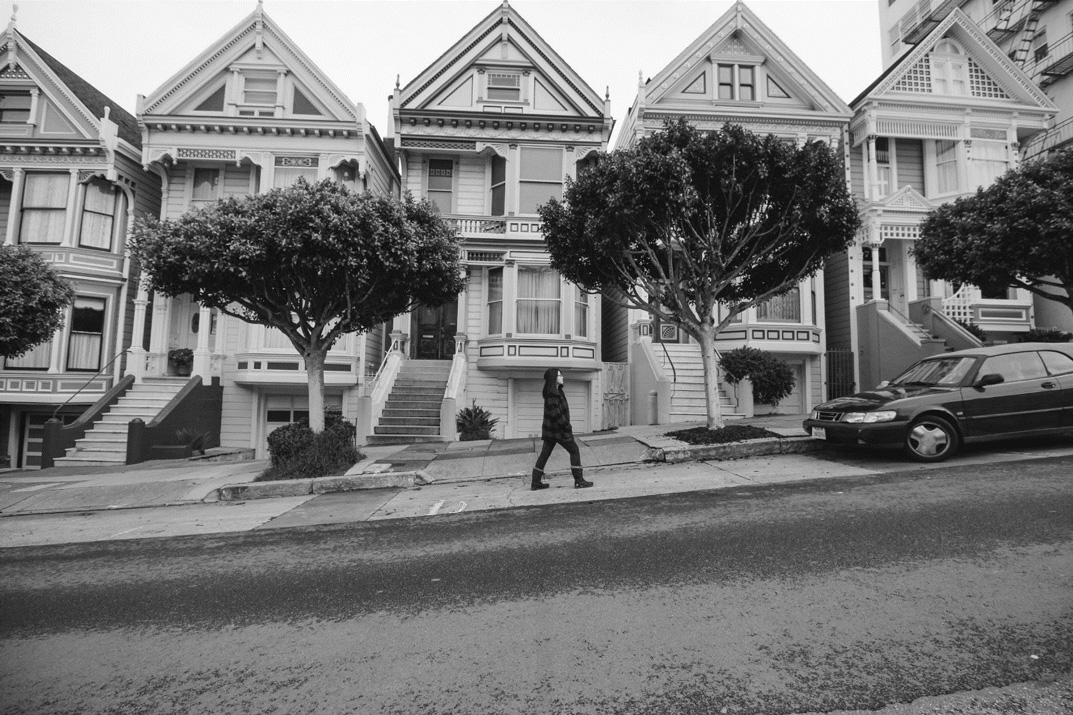
ЯђДЫЭМгІгУСЫвЛТжЙ§ТЫЦїКѓЃЌЮвЛёЕУСЫвдЯТНсЙћЁЃ

ЯЃЭћФњПЩвдПДЕНЃЌЙ§ТЫЦїЫЦКѕНЋИїИіжЕДЙжБХХСаЁЃетвтЮЖзХЫќБцБ№ГіСЫЭМЯёжаЕФДЙжБЬиеїЃЌетвЛЕуПЩвддкНсЙћжаПДЕНЁЃетЪЧвЛИідкдЫаа
CNN ЪБбЇЕНЕФЙ§ТЫЦїжЕЁЃ
гІИУзЂвтЕФЪЧЃЌВНЗљКЭЙ§ТЫЦїДѓаЁЪЧГЌВЮЪ§ЃЌетвтЮЖзХФЃаЭВЛЛсбЇЯАЫќУЧЁЃЫљвдФњБиаыгІгУПЦбЇЫМЮЌРДШЗЖЈетаЉЪ§СПжаЕФФФаЉжЕзюЪЪКЯФњЕФгІгУГЬађЁЃ
ЖдгкОэЛ§ЃЌФњашвЊРэНтЕФзюКѓвЛИіИХФюЪЧЬюГфЁЃШчЙћФњЕФЭМЯёЮоЗЈдкећЪ§ДЮФкгыЙ§ТЫЦїФтКЯЃЈНЋВНЗљПМТЧдкФкЃЉЃЌФЧУДФњБиаыЬюГфЭМЯёЁЃПЩЭЈЙ§СНжжЗНЪНЪЕЯжДЫВйзїЃКVALID
ЬюГфКЭ SAME ЬюГфЁЃЛљБОЩЯНВЃЌVALID ЬюГфЖЊЦњСЫЭМЯёБпдЕЕФЫљгаЪЃгржЕЁЃвВОЭЪЧЫЕЃЌШчЙћЙ§ТЫЦїЮЊ
2 x 2ЃЌВНЗљЮЊ 2ЃЌЭМЯёЕФПэЖШЮЊ 3ЃЌФЧУД VALID ЬюГфЛсКіТдРДздЭМЯёЕФЕкШ§СажЕЁЃSAME
ЬюГфЯђЭМЯёБпдЕЬэМгжЕЃЈЭЈГЃЮЊ 0ЃЉРДдіМгЫќЕФЮЌЪ§ЃЌжБЕНЙ§ТЫЦїФмЙЛФтКЯећЪ§ДЮЁЃетжжЬюГфЭЈГЃвдЖдГЦЗНЪННјааЕФЃЈвВОЭЪЧЫЕЃЌЛсГЂЪддкЭМЯёЕФУПвЛБпЬэМгЯрЭЌЪ§СПЕФСа/ааЃЉЁЃ
ЭЌбљжЕЕУзЂвтЕФЪЧЃЌЭМЯёОэЛ§ЕФгУЭОВЂВЛНіЯогкМЦЫуЛњЪгОѕЁЃаэЖрЭМЯёЙ§ТЫММЪѕЖМПЩвдЪЙгУОэЛ§РДЪЕЯжЃЌБШШчФЃК§ЛЏКЭШёЛЏЁЃ
ЯТУцЕФЛљБО Python ДњТыеЙЪОСЫОэЛ§дЫЫуЕФЙЄзїдРэЃЈФњПЩвдШУДЫДњТыБфЕУИќМђНрЃЌБШШчЭЈЙ§ЪЙгУ numpyЃЉЃК
def basic_conv(image,
out, in_width, in_height, out_width, out_height,
filter,
filter_dim, stride):
result_element = 0
for res_y in range(out_height):
for res_x in range(out_width):
for filter_y in range(filter_dim):
for filter_x in range(filter_dim):
image_y = res_y + filter_y
image_x = res_x + filter_x
result_element += (filter[filter_y][filter_x]
*
image[image_y][image_x])
out[res_y][res_x] = result_element
result_element = 0
res_x += (stride - 1)
res_y += (stride - 1)
return out |
ЧызЂвтЃЌШчЙћЯЃЭћНЋНсЙћаДЕНЭМЯёЮФМўжаЃЈЯёЮвЩЯУцФЧбљЖдЫќНјааПЩЪгЛЏЃЉЃЌдђБиаыЯожЦЪфГіжЕЃЌЪЙЫќУЧВЛГЌЙ§
255ЁЃ
ГиЛЏВуКЭШЋСЌНгВу
ЪЕМЪЕФОэЛ§ЭјТчКмЩйНіЭЈЙ§ОэЛ§ВуРДЙЙНЈЁЃЫќУЧЭЈГЃЛЙгаЦфЫћРраЭЕФВуЁЃзюМђЕЅЕФЪЧШЋСЌНгВуЁЃетЪЧвЛжжЦеЭЈЕФОэЛ§ЭјТчВуЃЌЦфжаЧАвЛВуЕФЫљгаЪфГіБЛСЌНгЕНЯТвЛВуЩЯЕФЫљгаНкЕуЁЃЭЈГЃЃЌетаЉВуЮЛгкЭјТчФЉЖЫЁЃ
ФњЛсдкОэЛ§ЭјТчжаПДЕНЕФСэвЛжжживЊЕФВуЪЧГиЛЏВуЁЃГиЛЏВуОпгаЖржжаЮЪНЃЌЕЋзюГЃгУЕФЪЧзюДѓГиЛЏЃЌЦфжаЪфШыОиеѓБЛВ№ЗжЮЊЯрЭЌДѓаЁЕФЗжЖЮЃЌЪЙгУУПИіЗжЖЮжаЕФзюДѓжЕРДЬюГфЪфГіОиеѓЕФЯргІдЊЫиЁЃ
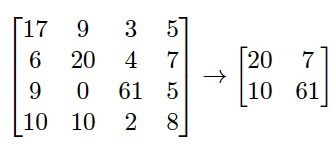
дкЩЯУцЕФДњТыЧхЕЅжаЃЌЪфШыБЛВ№ЗжЮЊ 2 x 2 ИіЯѓЯоЃЌВЂгІгУСЫзюДѓГиЛЏЁЃвђДЫЃЌЮвПЩвдНЋетИіЬиЖЈЕФВйзїУшЪіЮЊгЕгавЛИі
2 ЮЌЙ§ТЫЦїЧвВНЗљЮЊ 2ЁЃДЫЙ§ГЬЕФзїгУЪЧБцБ№ГіОпгаФГИіЬиеїЕФЙуЗКЧјгђЁЃЯыЯѓетИіЭјТче§дкбАевШЫСГЁЃдкетжжЧщПіЯТЃЌФњПЩвдНЋетДЮГиЛЏЕФНсЙћНтЪЭЮЊЃЌгвЯТВПКмПЩФмгавЛеХШЫСГЃЌзѓЩЯВППЩФмгавЛеХШЫСГЃЌгвЩЯВПЛђзѓЯТВППЩФмУЛгаШЫСГЁЃ
def max_pool(input,
out, in_width, in_height, out_width, out_height,
kernel_dim,
stride):
max = 0
for res_y in range(out_height):
for res_x in range(out_width):
for kernel_y in range(kernel_dim):
for kernel_x in range(kernel_dim):
in_y = (res_y * stride) + kernel_y
in_x = (res_x * stride) + kernel_x
if input[in_y][in_x] > max:
max = input[in_y][in_x]
out[res_y][res_x] = max
max = 0
return out |
ЪОР§БГОА
ЯждкЃЌШУЮвУЧЭЈЙ§ДДНЈвЛИіЪЖБ№ЭМЯёжаЕФЪжаДЪ§зжЕФЭјТчЃЌНтОівЛИіМђЕЅЕФМЦЫуЛњЪгОѕЮЪЬтЁЃетЪЧзюГЃгУгкеЙЪОЩёОЭјТчЧПДѓЙІФмЕФЛљзМЪОР§жЎвЛЁЃИУЪОР§ЪЧгУ
Python БраДЕФЃЌВЂЪЙгУСЫ TensorFlow ПтЃЌЫљвдФњВЛашвЊЙ§ЖрЕиЙизЂОпЬхЕФЪЕЯжЯИНкЃЌПЩвдИќЖрЕиЙизЂећЬхМмЙЙЁЃTensorFlow
гаСэвЛИігХЪЦЁЃЫќФкжУСЫ MNIST Ъ§ОнМЏЃЌЕЋгІИУзЂвтЕФЪЧЃЌЦфЫћЛњЦїбЇЯАПђМмЃЈБШШч SciKit-LearnЃЉвВзіЕНСЫетвЛЕуЁЃ
ЖдгкбЕСЗКЭВтЪдЃЌЮвЪЙгУетИі MNIST Ъ§ОнМЏЁЃЮвЪЙгУСЫвЛИіЛљгк LeNet-5 ЕФЯрЖдМђЕЅЕФОэЛ§ЭјТчМмЙЙЁЃетИіМмЙЙдк
MNIST Ъ§ОнМЏЩЯЪЕЯжСЫ 0.9% ЕФДэЮѓТЪЃЌЕЋЪЧЮвВЛЛсЪЕЯжетвЛзМШЗТЪЫЎЦНЃЌвђЮЊЮвНЋЗХЦњ LeCun
КЭЦфЫћШЫжДааЕФаэЖрВйзїРДЬсИпЭјТчадФмЃЌЖјЧвЮвЛЙЛсМђЛЏМмЙЙЕФФГаЉЗНУцЁЃ
ЭъећДњТыПЩвддкЮвЕФ GitHub ДцДЂПтжаевЕНЁЃетИіДцДЂПтЛЙАќКЌбнЪОжЎЧАЕФБпдЕМьВтЭМЯёЙ§ТЫЦїЕФДњТыЁЃ
МмЙЙ
ЮвНЋЪЙгУЕФМмЙЙШчЯТЫљЪОЃК
вЛИіОэЛ§ВуЃЌНЋ 32x32x1 MNIST ЭМЯёЫѕМѕЮЊвЛИі 28x28x6 ЪфГі
вЛИізюДѓГиЛЏВуЃЌАќКЌИїИіЬиеїЕФПэЖШКЭИпЖШ
вЛИіОэЛ§ВуЃЌНЋЮЌЪ§МѕЩйЮЊ 10x10x16
вЛИізюДѓГиЛЏВуЃЌдйвЛДЮНЋПэЖШКЭИпЖШМѕАы
вЛИіШЋСЌНгВуЃЌНЋЬиеїЪ§СПДг 400 МѕЩйЕН 120
ЕкЖўИіШЋСЌНгВу
зюКѓЕФШЋСЌНгВуЃЌЪфГівЛИіДѓаЁЮЊ 10 ЕФЪИСП
УПИіжаМфВуЖМЪЙгУСЫвЛИі ReLU ЗЧЯпадЬиеїЃЌУПИіОэЛ§ВуЖМЪЙгУвЛИіВНЗљЮЊ 1 ЧвВЩгУСЫ VALID
ЬюГфЕФ 5x5 Й§ТЫЦїЁЃгыДЫЭЌЪБЃЌзюДѓГиЛЏЙ§ТЫЦїЕФЮЌЪ§ЮЊ 2ЁЃ
АяжњЦїЗНЗЈ
ИУДњТыгаЖрИіАяжњЦїЗНЗЈЃЌГщЯѓЛЏСЫМмЙЙжаЗДИДГіЯжЕФвЛаЉЯИНкЃЌБШШчДДНЈЙ§ТЫЦїЃЈУПИіЙ§ТЫЦїЮЊ
5x5ЃЌЕЋгаВЛЭЌЕФЩюЖШЃЉКЭОэЛ§ВуЁЃЧызЂвтЃЌЮвдкШЈжиГѕЪМЛЏжаЪЙгУСЫвЛжжБЛНиЖЯЕФИпЫЙЗжВМЃЌвђЮЊзюГѕЕФШЈжиЮоЙиНєвЊЃЌжЛвЊЫќУЧВЛЭъШЋЯрЭЌМДПЩЁЃетбљзіЪЧЮЊСЫЦЦЛЕЖдГЦадЁЃвдЯТДњТыИјГіСЫвЛИіАяжњЦїЗНЗЈЕФЪОР§ЁЃ
def make_conv_layer(self,
input, in_channels, out_channels):
layer_weights = self.init_conv_weights(in_channels,
out_channels)
layer_bias = self.make_bias_term(out_channels)
layer_activations = tf.nn.conv2d(input, layer_weights,
strides =
self.conv_strides, padding = self.conv_padding)
+ layer_bias
return self.relu(layer_activations) |
ЙЙдьЭјТч
ГщЯѓЛЏСЫДДНЈВуЕФОпЬхЯИНкКѓЃЌЭјТчЕФЙЙдьЯрЖдБШНЯМђЕЅЁЃ
# Layer 2: Max
Pooling.28x28x6 --> 14x14x6
p2 = self.make_pool_layer(c1)
# Layer 3. convolutional, ReLU nonlinearity, 14x14x6
--> 10x10x16
c3 = self.make_conv_layer(p2, 6, 16)
# Layer 4.Max Pooling.10x10x16 --> 5x5x16
p4 = self.make_pool_layer(c3)
# Flattening the features to be fed into a fully
connected layer
fc5 = self.flatten_input(p4)
# Layer 5.Fully connected.400 --> 120
fc5 = self.make_fc_layer(fc5, 400, 120)
# Layer 6.Fully connected.120 --> 84 fc6 =
self.make_fc_layer(fc5, 120, 84) # Layer 7.Fully
connected.84 --> 10.Output layer, so no ReLU.
fc7 = self.make_fc_layer(fc6, 84, 10, True)
return fc7 |
бЕСЗ
ЪзЯШЃЌЮвНЋ MNIST Ъ§ОнМЏВ№ЗжЮЊвЛИібЕСЗМЏЁЂвЛИіНЛВцбщжЄМЏКЭвЛИіВтЪдМЏЁЃ
x_train, y_train,
x_valid, y_valid, x_test, y_test = split()
x_train = pad(x_train)
x_valid = pad(x_valid)
x_test = pad(x_test)
x_train_tensor = tf.placeholder(tf.float32, (None,
32, 32, 1))
y_train_tensor = tf.placeholder(tf.int32, (None))
y_train_one_hot = tf.one_hot(y_train_tensor, 10)
! |
бЕСЗБъЧЉБЛИФСМЮЊвЛИіЖРШШЪИСПЁЃдкЖРШШЪИСПжаЃЌУПИідЊЫиБэЪОвЛИіРрЃЌШчЙћЪОР§ЪєгкИУРрЃЌдђИУдЊЫиЕШгк 1ЃЌЗёдђЕШгк
0ЁЃЫљвдЖдгквЛИіУшЛцЪ§зж 1 ЕФЭМЯёЃЌЖРШШБэЪОЮЊЃК
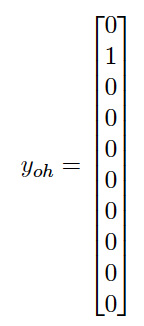
ЮвЩшжУСЫвЛаЉВйзїРДЖЈвхЮвНЋШчКЮбЕСЗФЃаЭЃЌР§ШчЖЈвхЮвЯЃЭћдкбЕСЗЦкМфзюаЁЛЏФФИіЪ§СПЁЃ
net = lenet.LeNet5()
logits = net.run_network(x_train_tensor)
learn_rate = 0.001
cross_ent = tf.nn.softmax_cross_entropy_with_logits(logits
= logits, labels =
y_train_one_hot)
loss = tf.reduce_mean(cross_ent) # We want to
minimise the mean cross entropy
optimisation = tf.train.AdamOptimizer(learning_rate
= learn_rate)
train_op = optimisation.minimize(loss)
correct = tf.equal(tf.argmax(logits, 1), tf.argmax(y_train_one_hot,
1))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) |
ЮвЪЙгУНЛВцьиРДЖШСПЫ№КФЃЌВЂЪЙгУ AdamOptimiser РДжДаагХЛЏЁЃ
бЕСЗМЏБЛВ№ЗжЮЊДѓаЁЮЊ 128 ЕФХњДЮЃЌЮвЖдбЕСЗдЫаавЛЖЈЕФТжЪ§ЃЈдкБОР§жаЮЊ
10ЃЉЁЃУПТждЫааКѓЃЌЖМВЮееНЛВцбщжЄМЏРДМьВщНсЙћШЈжиМЏЁЃ
with tf.Session()
as sess:
sess.run(tf.global_variables_initializer())
example_count = len(x_train)
for i in range(num_epochs):
x_train, y_train = shuffle(x_train, y_train)
for j in range(0, example_count, batch_size):
batch_end = j + batch_size
batch_x, batch_y = x_train[j : batch_end], y_train[j
: batch_end]
sess.run(train_op, feed_dict = {x_train_tensor:
batch_x,
y_train_tensor: batch_y})
accuracy_valid = eval(x_valid, y_valid)
print("Accuracy: {}".format(accuracy_valid))
print()
save.save(sess, "SavedModel/Saved") |
ШЛКѓБЃДцНсЙћФЃаЭЃЌЙЉвдКѓдкВтЪдМЏЩЯЪЙгУЁЃ
адФм
еыЖдВтЪдМЏЖјдЫааЪБЃЌИУФЃаЭЛёЕУСЫ 98.5% ЕФзМШЗТЪЃЈ1.5% ЕФДэЮѓТЪЃЉЁЃгЩгкЪ§ОнзМБИЕШЗНУцЕФВювьЃЌДЫадФмЩдЮЂЕЭгк
LeCun ЕФЪЕЯжЁЃЕЋЪЧЃЌЖдгкЯёЮветбљЕФЯрЖдМђЕЅЕФЪЕЯжЖјбдЃЌетвбЪЧЗЧГЃИпЕФадФмЁЃ
НсЪјгя
дкБОЮФжаЃЌФњбЇЯАСЫОэЛ§ЩёОЭјТчЕФЛљДЁжЊЪЖЃЌАќРЈОэЛ§Й§ГЬБОЩэЁЂзюДѓГиЛЏКЭШЋСЌНгВуЁЃШЛКѓЃЌФњСЫНтСЫвЛжжЯрЖдМђЕЅЕФ
CNN МмЙЙЪЕЯжЁЃЯЃЭћетЛсдкФњЙЄзїжаЪЙгУ CNN ЪБАяжњФњРэНтЫќУЧЃЌЛђепАяжњФњЬЄЩЯетИіСюШЫЩёЭљЕФЛњЦїбЇЯАЗжжЇЕФбЇЯАжЎТУЁЃ
|









