| 编辑推荐: |
本文来自于segmentfault.com, 文中主要讲解了布式环境下机器学习编程,对于输入数据较多的情况我们要从Extract,Transform,Load三方面考虑进行优化处理。
|
|
迁移学习
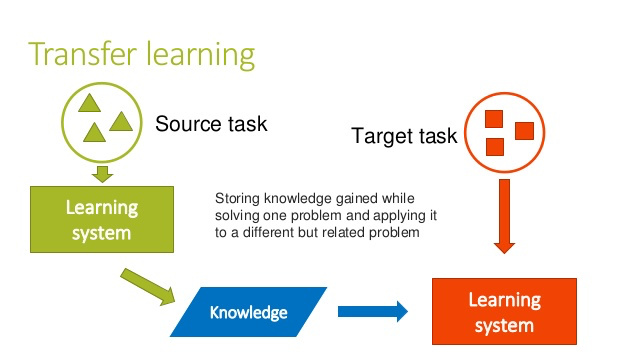
迁移学习就是用别人已经训练好的模型,如:Inception Model,Resnet Model等,把它当做Pre-trained
Model,帮助我们提取特征。常用方法是去除Pre-trained Model的最后一层,按照自己的需求重新更改,然后用训练集训练。
因为Pre-trained Model可能已经使用过大量数据集,经过了长时间的训练,所以我们通过迁移学习可以使用较少的数据集训练就可以获得相对不错的结果。
由于项目中使用到Estimator,所以我们再简单介绍下Estimator。
TF Estimator
这里引用下官网 Estimator的介绍。
您可以在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改模型。此外,您可以在
CPU、GPU 或 TPU 上运行基于 Estimator 的模型,而无需重新编码模型。
Estimator 简化了在模型开发者之间共享实现的过程。
您可以使用高级直观代码开发先进的模型。简言之,采用 Estimator 创建模型通常比采用低阶 TensorFlow
API 更简单。
Estimator 本身在 tf.layers 之上构建而成,可以简化自定义过程。
Estimator 会为您构建图。
Estimator 提供安全的分布式训练循环,可以控制如何以及何时:构建图,初始化变量,开始排队,处理异常,创建检查点并从故障中恢复,保存TensorBoard的摘要。
使用 Estimator 编写应用时,您必须将数据输入管道从模型中分离出来。这种分离简化了不同数据集的实验流程。
案例
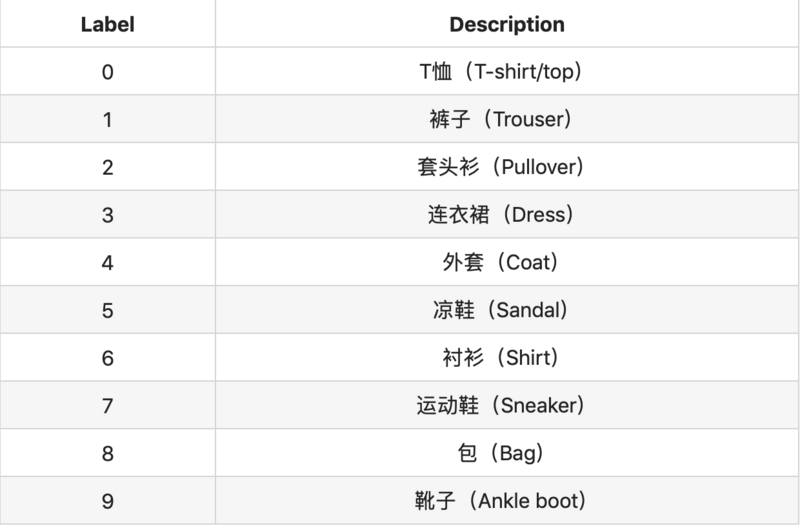
我们可以使用“tf.keras.estimator.model_to_estimator”将keras转换Estimator。这里使用的数据集是Fashion-MNIST。
Fashion-MNIST数据标签:
数据导入:
import os
import time
import tensorflow as tf
import numpy as np
import tensorflow.contrib as tcon
(train_image,train_lables),(test_image,test_labels)=tf.keras.datasets.fashion_mnist.load_data()
TRAINING_SIZE=len(train_image)
TEST_SIZE=len(test_image)
# 将像素值由0-255 转为0-1 之间
train_image=np.asarray(train_image,dtype=np.float32)/255
# 4维张量[batch_size,height,width,channels]
train_image=train_image.reshape(shape=(TRAINING_SIZE,28,28,1))
test_image=np.asarray(test_image,dtype=np.float32)/255
test_image=test_image.reshape(shape=(TEST_SIZE,28,28,1)) |
使用tf.keras.utils.to_categorical将标签转为独热编码表示:
# lables 转为 one_hot表示
# 类别数量
LABEL_DIMENSIONS=10
train_lables_onehot=tf.keras.utils.to_categorical(
y=train_lables,num_classes=LABEL_DIMENSIONS
)
test_labels_onehot=tf.keras.utils.to_categorical(
y=test_labels,num_classes=LABEL_DIMENSIONS
)
train_lables_onehot=train_lables_onehot.astype(np.float32)
test_labels_onehot=test_labels_onehot.astype(np.float32) |
创建Keras模型:
“”“
3层卷积层,2层池化层,最后展平添加全连接层使用softmax分类
”“”
inputs=tf.keras.Input(shape=(28,28,1))
conv_1=tf.keras.layers.Conv2D(
filters=32,
kernel_size=3,
# relu激活函数在输入值为负值时,激活值为0,此时可以使用LeakyReLU
activation=tf.nn.relu
)(inputs)
pool_1=tf.keras.layers.MaxPooling2D(
pool_size=2,
strides=2
)(conv_1)
conv_2=tf.keras.layers.Conv2D(
filters=64,
kernel_size=3,
activation=tf.nn.relu
)(pool_1)
pool_2=tf.keras.layers.MaxPooling2D(
pool_size=2,
strides=2
)(conv_2)
conv_3=tf.keras.layers.Conv2D(
filters=64,
kernel_size=3,
activation=tf.nn.relu
)(pool_2)
conv_flat=tf.keras.layers.Flatten()(conv_3)
dense_64=tf.keras.layers.Dense(
units=64,
activation=tf.nn.relu
)(conv_flat)
predictions=tf.keras.layers.Dense(
units=LABEL_DIMENSIONS,
activation=tf.nn.softmax
)(dense_64) |
模型配置:
model=tf.keras.Model(
inputs=inputs,
outputs=predictions
)
model.compile(
loss='categorical_crossentropy',
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
metrics=['accuracy']
) |
创建Estimator
指定GPU数量,然后将keras转为Estimator,代码如下:
NUM_GPUS=2
strategy=tcon.distribute.MirroredStrategy(num_gpus=NUM_GPUS)
config=tf.estimator.RunConfig(train_distribute=strategy)
estimator=tf.keras.estimator.model_to_estimator(
keras_model=model,config=config
) |
前面说到过使用 Estimator 编写应用时,您必须将数据输入管道从模型中分离出来,所以,我们先创建input
function。使用prefetch将data预置缓冲区可以加快数据读取。因为下面的迁移训练使用的数据集较大,所以在这里有必要介绍下优化数据输入管道的相关内容。
优化数据输入管道
TensorFlow数据输入管道是以下三个过程:
Extract:数据读取,如本地,服务端
Transform:使用CPU处理数据,如图片翻转,裁剪,数据shuffle等
Load:将数据转给GPU进行计算
数据读取:
通常,当CPU为计算准备数据时,GPU/TPU处于闲置状态;当GPU/TPU运行时,CPU处于闲置,显然设备没有被合理利用。 
tf.data.Dataset.prefetch可以将上述行为并行实现,当GPU/TPU执行第N次训练,此时让CPU准备N+1次训练使两个操作重叠,从而利用设备空闲时间。
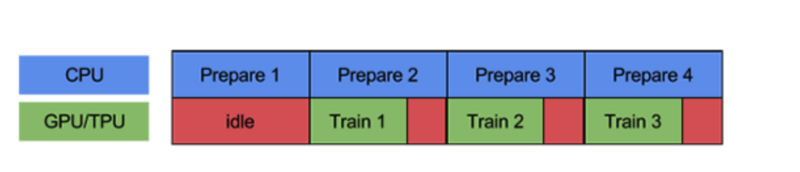
通过使用tf.contrib.data.parallel_interleave可以并行从多个文件读取数据,并行文件数有cycle_length指定。
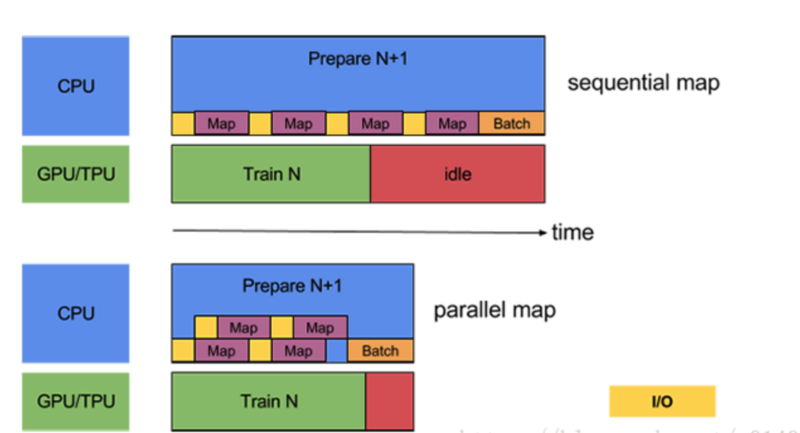
数据转换:
使用tf.data.Dataset.map对数据集中的数据进行处理,由于数据独立,所以可以并行处理。此函数读取的文件是含有确定性顺序,如果顺序对训练没有影响,也可以取消确定性顺序加快训练。
def input_fn(images,labels,epochs,batch_size):
ds=tf.data.Dataset.from_tensor_slices((images,labels))
# repeat值为None或者-1时将无限制迭代
ds=ds.shuffle(500).repeat(epochs).batch(batch_size).prefetch(batch_size)
return ds |
模型训练
# 用于计算迭代时间
class TimeHistory(tf.train.SessionRunHook):
def begin(self):
self.times = []
def before_run(self, run_context):
self.iter_time_start = time.time()
def after_run(self, run_context, run_values):
self.times.append(time.time() - self.iter_time_start)
time_hist = TimeHistory()
BATCH_SIZE = 512
EPOCHS = 5
# lambda为了填写参数
estimator.train(lambda:input_fn(train_images,
train_labels,
epochs=EPOCHS,
batch_size=BATCH_SIZE),
hooks=[time_hist])
# 训练时间
total_time = sum(time_hist.times)
print(f"total time with {NUM_GPUS} GPU(s):
{total_time} seconds")
# 训练数据量
avg_time_per_batch = np.mean(time_hist.times)
print(f"{BATCH_SIZE*NUM_GPUS/avg_time_per_batch}
images/second with
{NUM_GPUS} GPU(s)") |
结果如图:
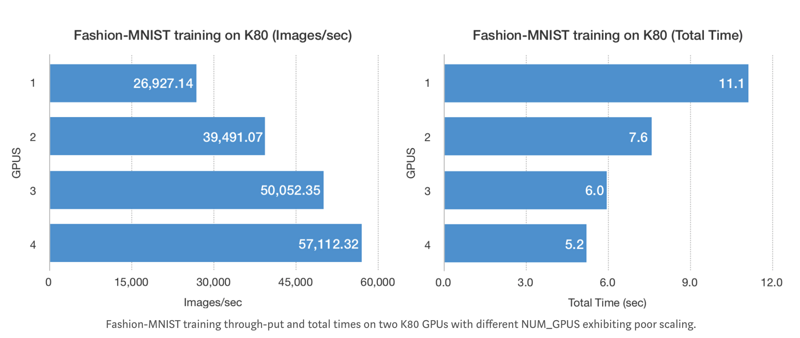
得益于Estimator数据输入和模型的分离,评估方法很简单。
estimator.evaluate(lambda:input_fn(test_images,
test_labels,
epochs=1,
batch_size=BATCH_SIZE)) |
迁移学习训练新模型
我们使用Retinal OCT images数据集进行迁移训练,数据标签为:NORMAL, CNV,
DME DRUSEN,包含分辨率为512*296,84495张照片。
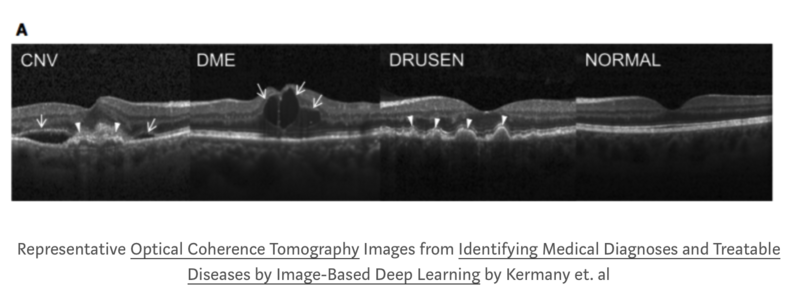
数据读取,设置input_fn:
labels = ['CNV',
'DME', 'DRUSEN', 'NORMAL']
train_folder = os.path.join('OCT2017', 'train',
'**', '*.jpeg')
test_folder = os.path.join('OCT2017', 'test',
'**', '*.jpeg') |
def input_fn(file_pattern,
labels,
image_size=(224,224),
shuffle=False,
batch_size=64,
num_epochs=None,
buffer_size=4096,
prefetch_buffer_size=None):
# 创建查找表,将string 转为 int 64ID
table = tcon.lookup.index_table_from_tensor(mapping=tf.constant(labels))
num_classes = len(labels)
def _map_func(filename):
# sep = '/'
label = tf.string_split([filename], delimiter=os.sep).values[-2]
image = tf.image.decode_jpeg(tf.read_file(filename),
channels=3)
image = tf.image.convert_image_dtype(image,
dtype=tf.float32)
image = tf.image.resize_images(image, size=image_size)
# tf.one_hot:根据输入的depth返回one_hot张量
# indices = [0, 1, 2]
# depth = 3
# tf.one_hot(indices, depth) return:
# [[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]]
return (image, tf.one_hot(table.lookup(label),
num_classes))
dataset = tf.data.Dataset.list_files(file_pattern,
shuffle=shuffle)
if num_epochs is not None and shuffle:
dataset = dataset.apply(
tcon.data.shuffle_and_repeat(buffer_size, num_epochs))
elif shuffle:
dataset = dataset.shuffle(buffer_size)
elif num_epochs is not None:
dataset = dataset.repeat(num_epochs)
dataset = dataset.apply(
tcon.data.map_and_batch(map_func=_map_func,
batch_size=batch_size,
num_parallel_calls=os.cpu_count()))
dataset = dataset.prefetch(buffer_size=prefetch_buffer_size)
return dataset |
使用VGG16网络
通过keras使用预训练的VGG16网络,我们重训练最后5层:
# include_top:不包含最后3个全连接层
keras_vgg16 = tf.keras.applications.VGG16(input_shape=(224,224,3),
include_top=False)
output = keras_vgg16.output
output = tf.keras.layers.Flatten()(output)
prediction = tf.keras.layers.Dense(len(labels),
activation=tf.nn.softmax)(output)
model = tf.keras.Model(inputs=keras_vgg16.input,
outputs=prediction)
# 后5层不训练
for layer in keras_vgg16.layers[:-4]:
layer.trainable = False |
重新训练模型:
# 通过迁移学习得到模型
model.compile(loss='categorical_crossentropy',
# 使用默认学习率
optimizer=tf.train.AdamOptimizer(),
metrics=['accuracy'])
NUM_GPUS = 2
strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)
config = tf.estimator.RunConfig(train_distribute=strategy)
# 转至estimator
estimator = tf.keras.estimator.model_to_estimator(model,
config=config)
BATCH_SIZE = 64
EPOCHS = 1
estimator.train(input_fn=lambda:input_fn(train_folder,
labels,
shuffle=True,
batch_size=BATCH_SIZE,
buffer_size=2048,
num_epochs=EPOCHS,
prefetch_buffer_size=4),
hooks=[time_hist])
# 模型评估:
estimator.evaluate(input_fn=lambda:input_fn(test_folder,
labels,
shuffle=False,
batch_size=BATCH_SIZE,
buffer_size=1024,
num_epochs=1))
VGG16网络 |
VGG16网络 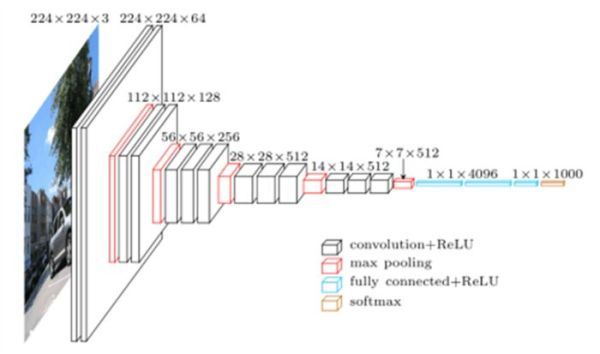
如图所示,VGG16有13个卷积层和3个全连接层。VGG16输入为[224,224,3],卷积核大小为(3,3),池化大小为(2,2)步长为2。各层的详细参数可以查看VGG
ILSVRC 16 layers因为图片较大,这里只给出部分截图,详情请点击链接查看。
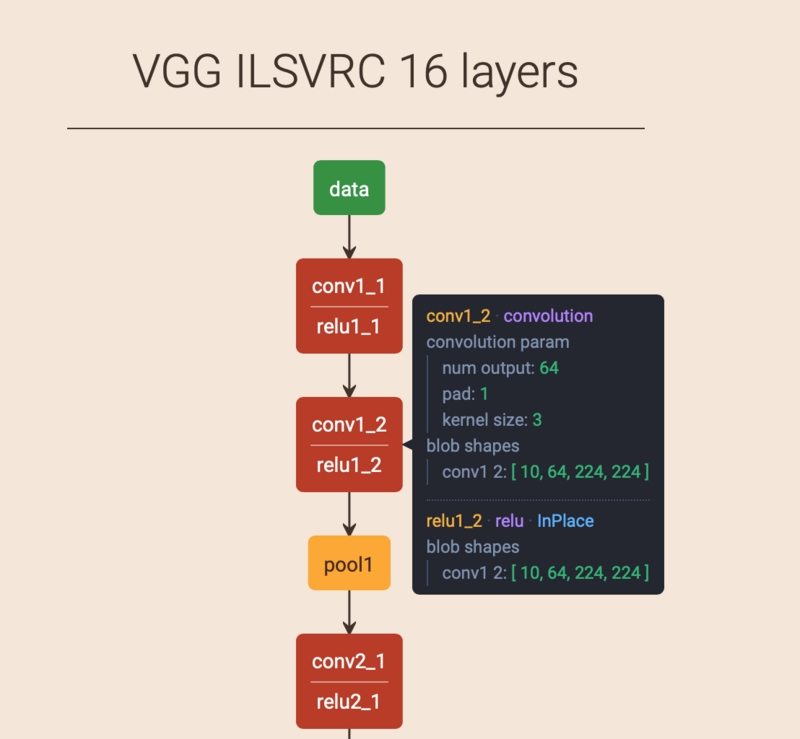
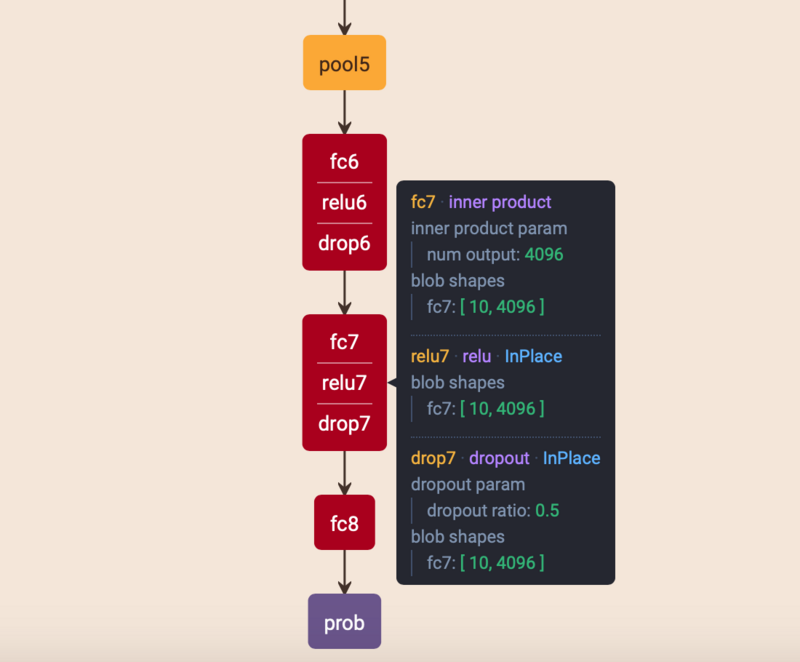
VGG16模型结构规整,简单,通过几个小卷积核(3,3)卷积层组合比大卷积核如(7,7)更好,因为多个(3,3)卷积比一个大的卷积拥有更多的非线性,更少的参数。此外,验证了不断加深的网络结构可以提升性能(卷积+卷积+卷积+池化,代替卷积+池化,这样减少W的同时有可以拟合更复杂的数据),不过VGG16参数量很多,占用内存较大。
总结
通过迁移学习我们可以使用较少的数据训练出来一个相对不错的模型,Estimator简化了机器学习编程特别是在分布式环境下。对于输入数据较多的情况我们要从Extract,Transform,Load三方面考虑进行优化处理。当然,除了VGG16我们还有很多选择,如:Inception
Model,Resnet Model。 |









