| БрМЭЦМі: |
БОЮФРДздгкit168ЃЌЮФеТНщЩмСЫTensorflow
ЪЕЯждРэЁЂбЕСЗФЃаЭЁЂжДааЭМЕШЯрЙижЊЪЖЁЃ |
|
1. Tensorflow ЪЕЯждРэ
ЪЕЯждРэ
TensorFlowгавЛИіживЊзщМўclientЃЌЙЫУћЫМвхЃЌОЭЪЧПЭЛЇЖЫЃЌЫќЭЈЙ§SessionЕФНгПкгыmasterМАЖрИіworkerЯрСЌЁЃЦфжаУПвЛИіworkerПЩвдгыЖрИігВМўЩшБИЃЈdeviceЃЉЯрСЌЃЌБШШчCPUЛђGPUЃЌВЂИКд№ЙмРэетаЉгВМўЁЃЖјmasterдђИКд№жИЕМЫљгаworkerАДСїГЬжДааМЦЫуЭМЁЃTensorFlowгаЕЅЛњФЃЪНКЭЗжВМЪНФЃЪНСНжжЪЕЯжЃЌЦфжаЕЅЛњжИclientЁЂmasterЁЂworkerШЋВПдквЛЬЈЛњЦїЩЯЕФЭЌвЛИіНјГЬжаЃЛЗжВМЪНЕФАцБОдЪаэclientЁЂmasterЁЂworkerдкВЛЭЌЛњЦїЕФВЛЭЌНјГЬжаЃЌЭЌЪБгЩМЏШКЕїЖШЯЕЭГЭГвЛЙмРэИїЯюШЮЮёЁЃ
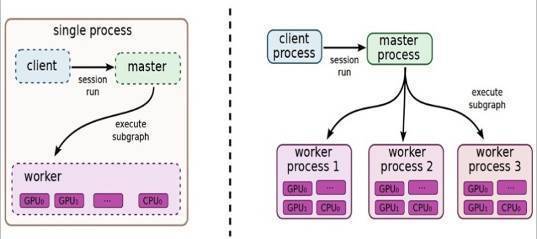
ЭМ1.1 TensorFlowЕЅЛњАцБОКЭЗжВМЪНАцБОЕФЪОР§ЭМ
TensorFlowМЦЫуЭМЕФдЫааЛњжЦ
Client
ClientЛљгкTensorFlowЕФБрГЬНгПкЃЌЙЙдьМЦЫуЭМЁЃДЫЪБЃЌTensorFlowВЂЮДжДааШЮКЮМЦЫуЁЃжБжСНЈСЂSessionЛсЛАЃЌВЂвдSessionЮЊЧХСКЃЌНЈСЂClientгыКѓЖЫдЫааЪБЕФЭЈЕРЃЌНЋProtobufИёЪНЕФGraphDefЗЂЫЭжСDistributed
MasterЁЃвВОЭЪЧЫЕЃЌЕБClientЖдOPНсЙћНјааЧѓжЕЪБЃЌНЋДЅЗЂDistributed MasterЕФМЦЫуЭМЕФжДааЙ§ГЬЁЃШчЯТЭМЫљЪОЃЌClientЙЙНЈСЫвЛИіМђЕЅМЦЫуЭМЁЃЫќЪзЯШНЋwгыxНјааОиеѓЯрГЫЃЌдйгыНиОрbАДЮЛЯрМгЃЌзюКѓИќаТжСsЁЃ
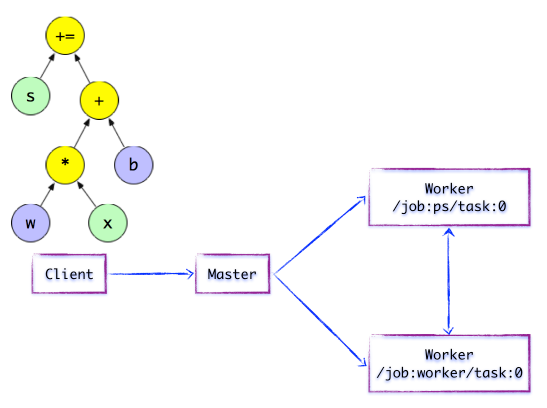
ЭМ1.2 МђЕЅЕФTensorFlowМЦЫуЭМ
Distributed Master
дкЗжВМЪНЕФдЫааЪБЛЗОГжаЃЌDistributed MasterИљОнSession.runЕФFetchingВЮЪ§ЃЌДгМЦЫуЭМжаЗДЯђБщРњЃЌевЕНЫљвРРЕЕФзюаЁзгЭМЁЃШЛКѓDistributed
MasterИКд№НЋИУзгЭМдйДЮЗжСбЮЊЖрИіЁИзгЭМЦЌЖЮЁЙЃЌвдБудкВЛЭЌЕФНјГЬКЭЩшБИЩЯдЫааетаЉЁИзгЭМЦЌЖЮЁЙЁЃзюКѓЃЌDistributed
MasterНЋетаЉЭМЦЌЖЮХЩЗЂИјWork ServiceЁЃЫцКѓWork ServiceЦєЖЏЁИБОЕизгЭМЁЙЕФжДааЙ§ГЬЁЃDistributed
MasterНЋЛсЛКДцЁИзгЭМЦЌЖЮЁЙЃЌвдБуКѓајжДааЙ§ГЬжиИДЪЙгУетаЉЁИзгЭМЦЌЖЮЁЙЃЌБмУтжиИДМЦЫуЁЃ
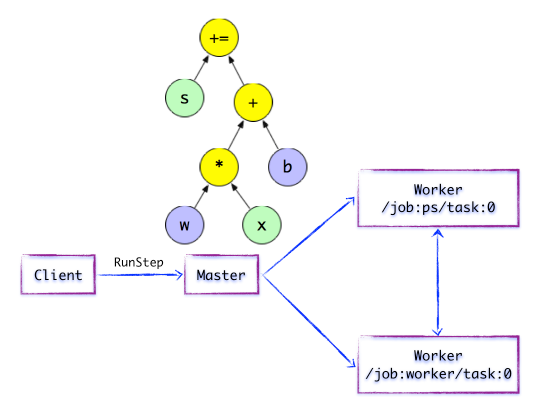
ЭМ1.3 МђЕЅЕФTensorFlowМЦЫуЭМ---ПЊЪМжДаа
жДааЭММЦЫу
ШчЩЯЭМЫљЪОЃЌDistributed MasterПЊЪМжДааМЦЫузгЭМЁЃдкжДаажЎЧАЃЌDistributed
MasterЛсЪЕЪЉвЛЯЕСагХЛЏММЪѕЃЌР§ШчЁИЙЋЙВБэДяЪНЯћГ§ЁЙЃЌЁИГЃСПелЕўЁЙЕШЁЃЫцКѓЃЌDistributed
MasterИКд№ШЮЮёМЏЕФаЭЌЃЌжДаагХЛЏКѓЕФМЦЫузгЭМЁЃ
ЭМ1.4 МђЕЅЕФTensorFlowМЦЫуЭМ---згЭМЦЌЖЮ
згЭМЦЌЖЮ
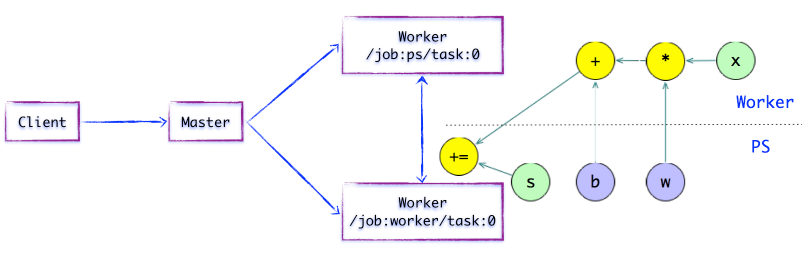
ШчЩЯЭМЫљЪОЃЌДцдквЛжжКЯРэЕФЁИзгЭМЦЌЖЮЁЙЛЎЗжЫуЗЈЁЃDistributed MasterНЋФЃаЭВЮЪ§ЯрЙиЕФOPНјааЗжзщЃЌВЂЗХжУдкPSШЮЮёЩЯЁЃЦфЫћOPдђЛЎЗжЮЊСэЭтвЛзщЃЌЗХжУдкWorkerШЮЮёЩЯжДааЁЃ
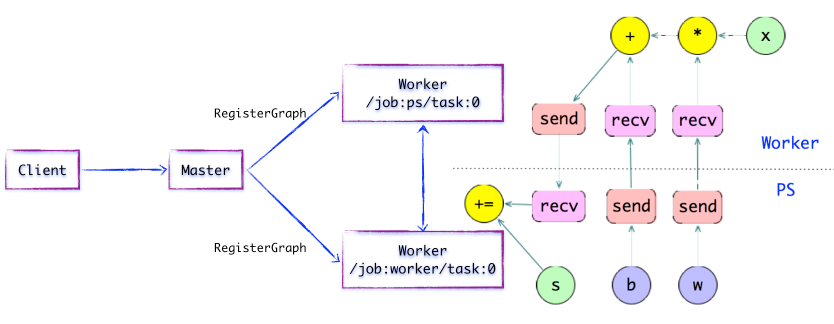
ЭМ1.5 МђЕЅЕФTensorFlowМЦЫуЭМ---ВхШыSEND/RECVНкЕу
ШчЩЯЭМЫљЪОЃЌШчЙћМЦЫуЭМЕФБпБЛШЮЮёНкЕуЗжИюЃЌDistributed MasterНЋИКд№НЋИУБпНјааЗжСбЃЌдкСНИіЗжВМЪНШЮЮёжЎМфВхШыSENDКЭRECVНкЕуЃЌЪЕЯжЪ§ОнЕФДЋЕнЁЃ
ЫцКѓЃЌDistributed MasterНЋЁИзгЭМЦЌЖЮЁЙХЩЗЂИјЯргІЕФШЮЮёжажДааЃЌдкWorker ServiceГЩЮЊЁИБОЕизгЭМЁЙЃЌЫќИКд№жДааИУзгЭМЕФЩЯЕФOPЁЃ
Worker Service
ЖдгкУПИіШЮЮёЃЌЖМНЋДцдкЯргІЕФWorker ServiceЃЌЫќжївЊИКд№ШчЯТ3ИіЗНУцЕФжАд№ЃК
ДІРэРДздMasterЕФЧыЧѓЃЛ
ЕїЖШOPЕФKernelЪЕЯжЃЌжДааБОЕизгЭМЃЛ
аЭЌШЮЮёжЎМфЕФЪ§ОнЭЈаХЁЃ
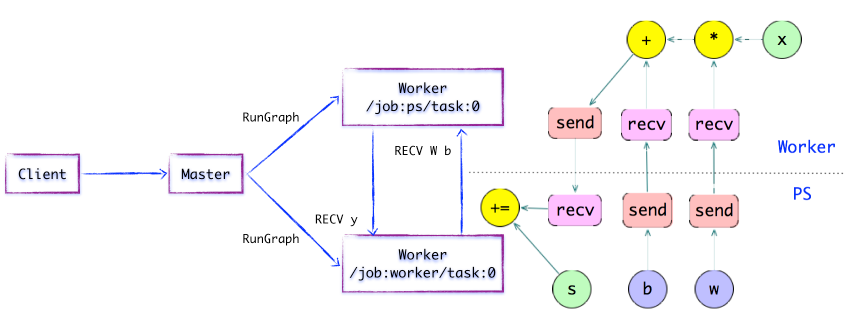
ЭМ1.6 МђЕЅЕФTensorFlowМЦЫуЭМ---жДааБОЕизгЭМ
жДааБОЕизгЭМ
Worker ServiceХЩЗЂOPЕНБОЕиЩшБИЃЌжДааKernelЕФЬиЖЈЁЃЫќНЋОЁзюДѓПЩФмЕиРћгУЖрCPU/GPUЕФДІРэФмСІЃЌВЂЗЂЕижДааKernelЪЕЯжЁЃ
СэЭтЃЌTensorFlowИљОнЩшБИРраЭЃЌЖдгкЩшБИМфЕФSEND/RECVНкЕуНјааЬиЛЏЪЕЯжЃК
ЪЙгУcudaMemcpyAsyncЕФAPIЪЕЯжБОЕиCPUгыGPUЩшБИЕФЪ§ОнДЋЪфЃЛ
ЖдгкБОЕиЕФGPUжЎМфдђЪЙгУЖЫЕНЖЫЕФDMAЃЌБмУтСЫПчhost CPUАКЙѓЕФПНБДЙ§ГЬЁЃ
ЖдгкШЮЮёжЎМфЕФЪ§ОнДЋЕнЃЌTensorFlowжЇГжЖравщЃЌжївЊАќРЈЃК
gRPC over TCP
RDMA over Converged Ethernet
ЪОР§ДњТы
import tensorflow
as tf
# ЖЈвхГЃСП
hello = tf.constant('Hello World!')
sess = tf.Session()
"""
target: (Optional.) The execution engine to
connect to.
Defaults to using an in-process engine. See
@{$distributed$Distributed TensorFlow}
"""
sess.run(hello)
# Terminal out put info:
$ b'Hello World!' |
вдЩЯМђЖЬЕФДњТыЦфЪЕОЭвбОдЫгУЕНСЫTensorflowЗжВМЪННсЙЙЃЌжЛВЛЙ§ИУЗжВМЪНЕФclientЁЂmasterЁЂworkerЖМЪЧдкБОЕиЕФЭЌвЛЬЈЛњЦїЖјвбЁЃЖјЖрЬЈЛњЦїЪЕЯжЗжВМЪНжЛашвЊжИЖЈЯргІЕФclientЁЂmasterЁЂworkerЗжВМдкВЛЭЌЕФЛњЦїЩЯОЭПЩвдЪЕЯжСЫЃЌЯТУцНЋЯъЯИНщЩмШчКЮдкЖрЬЈЛњЦїЩЯЪЕЯжTensorflowЗжВМЪНЁЃ
2. Tensorflow ЗжВМЪНжЎ In-graph replication (ЭМФкПНБД)
gRPC
ЩЯУцЬсЕНСЫTensorflowЕФЕЅЛњФЃЪНЪЧНЋclientЁЂmasterЁЂworkerЖМЗХдкЭЌвЛЬЈЛњЦїЩЯЃЌЖјЗжВМЪНФЃЪНОЭЪЧНЋШ§епЗжВМЕНЖрЬЈЛњЦїЩЯЁЃетЪБОЭашвЊПМТЧЖрЬЈЛњЦїжЎЧАЕФЭЈаХЮЪЬтСЫЃЌдкTensorflowЕФЗжВМЪНжаГЃЪЙгУЕФЭЈаХавщЪЧgRPCавщЃЌgRPCЪЧGoogleПЊЗЂЕФвЛИіПЊдДЕФRPC(Remote
procedure call)авщЁЃИУавщдЪаэдЫаагквЛЬЈМЦЫуЛњЕФГЬађЕїгУСэвЛЬЈМЦЫуЛњЕФзгГЬађЃЌЖјГЬађдБЮоашЖюЭтЕиЮЊетИіНЛЛЅзїгУБрГЬЁЃ
In-graph replication
TensorflowбЕСЗФЃаЭЭЈГЃашвЊвЛаЉбЕСЗВЮЪ§ЃЌбЕСЗВЮЪ§ЕФЗжЗЂгаСНжжЗНЪНЃКIn-graph replicationЁЂBetween-graph
replicationЁЃЦфжаIn-graph replicationЗНЪНЕФЪ§ОнЗжЗЂЪЧдквЛИіНкЕуЩЯЃЌетбљЕФКУДІЪЧХфжУМђЕЅЃЌ
ЦфЫћЖрЛњЖрGPUЕФМЦЫуНкЕуЃЌжЛвЊЦ№ИіjoinВйзїЃЌ БЉТЖвЛИіЭјТчНгПкЃЌЕШдкФЧРяНгЪмШЮЮёОЭКУСЫЁЃ ЕЋЪЧетбљЕФЛЕДІЪЧбЕСЗЪ§ОнЕФЗжЗЂдквЛИіНкЕуЩЯЃЌвЊАббЕСЗЪ§ОнЗжЗЂЕНВЛЭЌЕФЛњЦїЩЯЃЌ
бЯжигАЯьВЂЗЂбЕСЗЫйЖШЁЃдкДѓЪ§ОнбЕСЗЕФЧщПіЯТЃЌ ВЛЭЦМіЪЙгУетжжФЃЪНЁЃ
ЪОР§ДњТы1 здЖЏНкЕуЗжХфВпТд----МђЕЅЕФЬАРЗВпТдДњМлФЃаЭЙРМЦ
worker_01
import tensorflow
as tf
# ЩшжУworker ЕижЗгыЖЫПк
worker_01 = "172.17.0.2:2222"
worker_02 = "172.17.0.3:2222"
worker_hosts = [worker_01, worker_02]
# Creates a `ClusterSpec`
cluster_spec = tf.train.ClusterSpec({"worker":
worker_hosts})
# Creates a new server with ClusterSpecЁЂjob_nameЁЂ
task_index
server = tf.train.Server(cluster_spec,
job_name="worker",
task_index=1)
server.join()
# Terminal Output
I tensorflow/core/distributed_runtime/rpc/grpc_channel.
cc:200]
Initialize GrpcChannelCache for job worker ->
{0 -> localhost:2222, 1 -> 172.17.0.3:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.
cc:221]
Started server with target: grpc://localhost:2222 |
worker_02
import tensorflow
as tf
# ЩшжУworker ЕижЗгыЖЫПк
worker_01 = "172.17.0.2:2222"
worker_02 = "172.17.0.3:2222"
worker_hosts = [worker_01, worker_02]
# Creates a `ClusterSpec`
cluster_spec = tf.train.ClusterSpec({"worker":
worker_hosts})
# Creates a new server with ClusterSpecЁЂjob_nameЁЂ
task_index
server = tf.train.Server(cluster_spec,
job_name="worker",
task_index=0)
server.join()
# Terminal Output
I tensorflow/core/distributed_runtime/rpc/grpc_channel.
cc:200]
Initialize GrpcChannelCache for job worker ->
{0 -> 172.17.0.2:2222, 1 -> localhost:2222}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.
cc:221]
Started server with target: grpc://localhost:2222 |
client
import tensorflow
as tf
import numpy as np
# placeholder
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Creates weight
w = tf.Variable(0.0, name="weight")
# Creates biases
b = tf.Variable(0.0, name="reminder")
# init Variable
init_var = tf.global_variables_initializer()
# loss function
loss = tf.square(Y - tf.multiply(X, w) - b)
# Optimizer
op = tf.train.GradientDescentOptimizer(0.01).minimize(cost_op)
# input parameter
train_X = np.linspace(-1, 1, 101)
train_Y = 2 * train_X + np.random.randn(*train_X.shape)
* 0.33 + 10
with tf.Session("grpc://172.17.0.2:2222")
as sess:
sess.run(init_op)
for i in range(10):
for (x, y) in zip(train_X, train_Y):
sess.run(train_op, feed_dict={X: x, Y: y})
print(sess.run(w))
print(sess.run(b)) |
ДгЩЯУцЕФЪОР§ДњТыжаЮвУЧПЩвдПДГіЃКетРяЪЙгУСЫШ§ЬЈЛњЦїдкбЕСЗЃЌвЛИіclintЃЌСНИіworkerЁЃетРяПЩФмЛсгавЛаЉЮЪЬтЃК
ЮЪЬт1. masterдкФФРяЃП
ЮЪЬт2. УПвЛИіНкЕуЕФШЮЮёдѕУДЗжХфЃП
ЖдгкЮЪЬт1ЃЌдкIn-graph replicationЗНЪНжаmasterЦфЪЕОЭЪЧwith tf.Session("grpc://172.17.0.2:2222")
as sess: етОфЛАжажИЖЈЕФtargetЃЌвВОЭЪЧЫЕ172.17.0.2:2222етЬЈЛњЦїОЭЪЧmasterЃЌдкдЫааЕФЪБКђЛсдкетЬЈЛњЦїЩЯДђгЁШчЯТШежОЃК
I tensorflow/core/distributed_runtime/master_session.cc:1012]
Start master session 254ffd62801d1bee with config:
ЖдгкЮЪЬт2ЃЌ
АбМЦЫувбОДгЕЅЛњЖрGPUЃЌвбОРЉеЙЕНСЫЖрЛњЖрGPUСЫЃЌ ВЛЙ§Ъ§ОнЗжЗЂЛЙЪЧдквЛИіНкЕуЁЃ етаЉМЦЫуНкЕуБЉТЖГіРДЕФЭјТчНгПкЃЌЪЙгУЦ№РДОЭИњБОЛњЕФвЛИіGPUЕФЪЙгУвЛбљЃЌ
жЛвЊдкВйзїЕФЪБКђжИЖЈtf.device("/job:worker/task:n")ЃЌ
ОЭПЩвдЯђжИЖЈGPUвЛбљЃЌАбВйзїжИЖЈЕНвЛИіМЦЫуНкЕуЩЯМЦЫуЃЌЪЙгУЦ№РДКЭЖрGPUЕФРрЫЦЁЃ
ЪОР§ДњТы2 гУЛЇЯожЦЕФНкЕуЗжХфВпТд
3. Tensorflow ЗжВМЪНжЎ Between-graph replication (ЭММфПНБД)
between-graphФЃЪНЯТЃЌбЕСЗЕФВЮЪ§БЃДцдкВЮЪ§ЗўЮёЦїЃЌ Ъ§ОнВЛгУЗжЗЂЃЌ Ъ§ОнЗжЦЌЕФБЃДцдкИїИіМЦЫуНкЕуЃЌ
ИїИіМЦЫуНкЕуздМКЫуздМКЕФЃЌ ЫуЭъСЫжЎКѓЃЌ АбвЊИќаТЕФВЮЪ§ИцЫпВЮЪ§ЗўЮёЦїЃЌВЮЪ§ЗўЮёЦїИќаТВЮЪ§ЁЃетжжФЃЪНЕФгХЕуЪЧВЛгУбЕСЗЪ§ОнЕФЗжЗЂСЫЃЌ
гШЦфЪЧдкЪ§ОнСПдкTBМЖЕФЪБКђЃЌ НкЪЁСЫДѓСПЕФЪБМфЃЌЫљвдДѓЪ§ОнЩюЖШбЇЯАЛЙЪЧЭЦМіЪЙгУbetween-graphФЃЪНЁЃ |









