| БрМЭЦМі: |
БОЮФРДздгкВЉПЭЃЌБОЮФжївЊНщЩмСЫOnline
LearningЕФЛљБОдРэКЭСНжжГЃгУЕФOnline LearningЫуЗЈЁЃ
|
|
Online LearningЪЧЙЄвЕНчБШНЯГЃгУЕФЛњЦїбЇЯАЫуЗЈЃЌдкКмЖрГЁОАЯТЖМФмгаКмКУЕФаЇЙћЁЃБОЮФжївЊНщЩмOnline
LearningЕФЛљБОдРэКЭСНжжГЃгУЕФOnline LearningЫуЗЈЃКFTRLЃЈFollow The
Regularized LeaderЃЉ[1]КЭBPRЃЈBayesian Probit RegressionЃЉ[2]ЃЌвдМАOnline
LearningдкУРЭХвЦЖЏЖЫЭЦМіжиХХађЕФгІгУЁЃ
ЪВУДЪЧOnline Learning
зМШЗЕиЫЕЃЌOnline LearningВЂВЛЪЧвЛжжФЃаЭЃЌЖјЪЧвЛжжФЃаЭЕФбЕСЗЗНЗЈЃЌOnline
LearningФмЙЛИљОнЯпЩЯЗДРЁЪ§ОнЃЌЪЕЪБПьЫйЕиНјааФЃаЭЕїећЃЌЪЙЕУФЃаЭМАЪБЗДгГЯпЩЯЕФБфЛЏЃЌЬсИпЯпЩЯдЄВтЕФзМШЗТЪЁЃOnline
LearningЕФСїГЬАќРЈЃКНЋФЃаЭЕФдЄВтНсЙћеЙЯжИјгУЛЇЃЌШЛКѓЪеМЏгУЛЇЕФЗДРЁЪ§ОнЃЌдйгУРДбЕСЗФЃаЭЃЌаЮГЩБеЛЗЕФЯЕЭГЁЃШчЯТЭМЫљЪОЃК
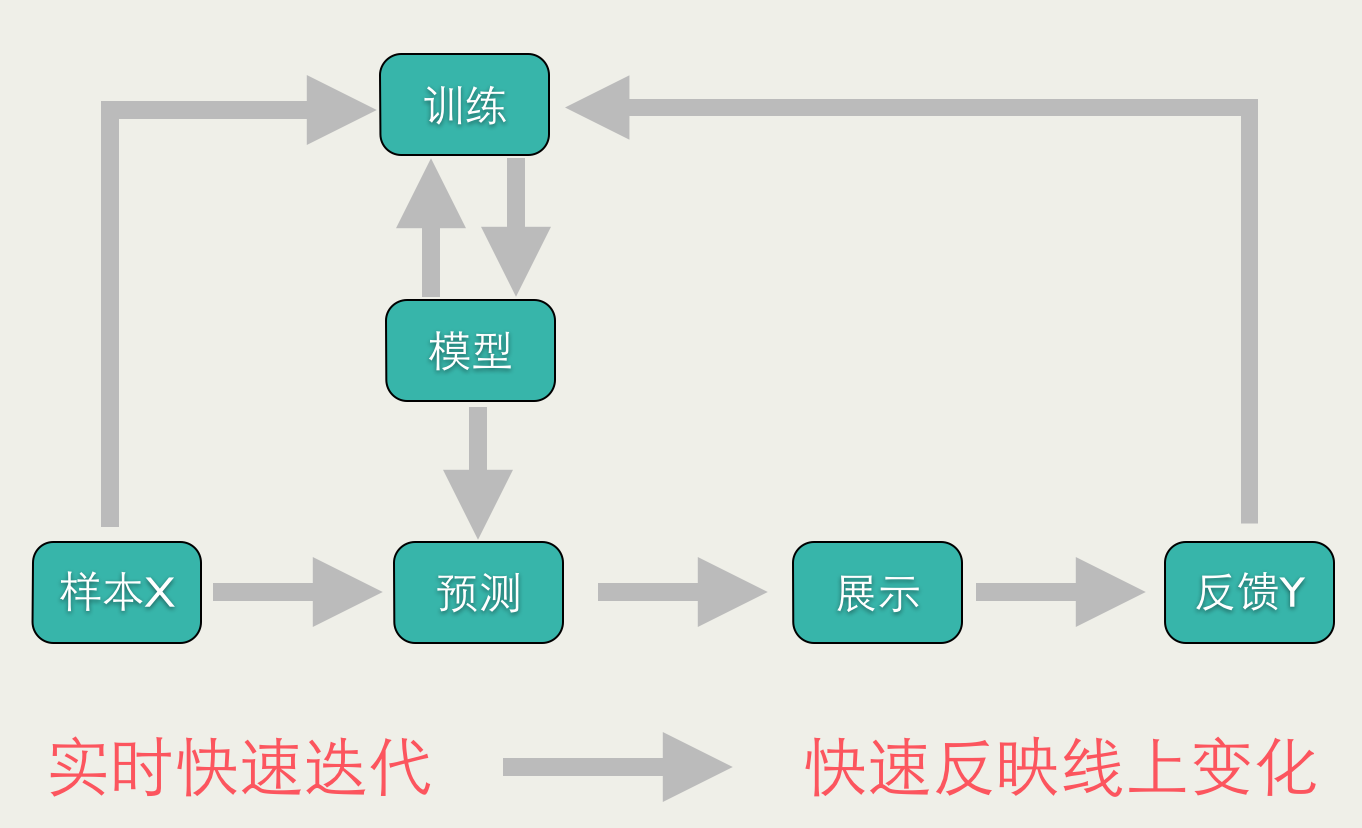
Online LearningгаЕуЯёздЖЏПижЦЯЕЭГЃЌЕЋгжВЛОЁЯрЭЌЃЌЖўепЕФЧјБ№ЪЧЃКOnline LearningЕФгХЛЏФПБъЪЧећЬхЕФЫ№ЪЇКЏЪ§зюаЁЛЏЃЌЖјздЖЏПижЦЯЕЭГвЊЧѓзюжеНсЙћгыЦкЭћжЕЕФЦЋВюзюаЁЁЃ
ДЋЭГЕФбЕСЗЗНЗЈЃЌФЃаЭЩЯЯпКѓЃЌИќаТЕФжмЦкЛсБШНЯГЄЃЈвЛАуЪЧвЛЬьЃЌаЇТЪИпЕФЪБКђЮЊвЛаЁЪБЃЉЃЌетжжФЃаЭЩЯЯпКѓЃЌвЛАуЪЧОВЬЌЕФЃЈвЛЖЮЪБМфФкВЛЛсИФБфЃЉЃЌВЛЛсгыЯпЩЯЕФзДПігаШЮКЮЛЅЖЏЃЌМйЩшдЄВтДэСЫЃЌжЛФмдкЯТвЛДЮИќаТЕФЪБКђЭъГЩИќе§ЁЃOnline
LearningбЕСЗЗНЗЈВЛЭЌЃЌЛсИљОнЯпЩЯдЄВтЕФНсЙћЖЏЬЌЕїећФЃаЭЁЃШчЙћФЃаЭдЄВтДэЮѓЃЌЛсМАЪБзіГіаое§ЁЃвђДЫЃЌOnline
LearningФмЙЛИќМгМАЪБЕиЗДгГЯпЩЯБфЛЏЁЃ
Online LearningЕФгХЛЏФПБъ
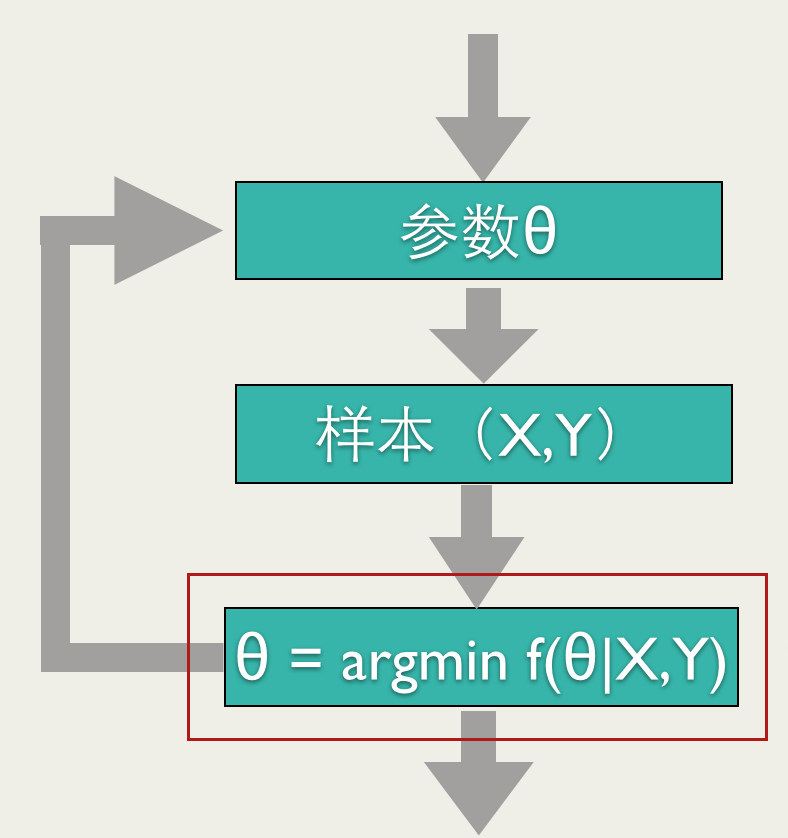
ШчЩЯЭМЫљЪОЃЌOnline LearningбЕСЗЙ§ГЬвВашвЊгХЛЏвЛИіФПБъКЏЪ§ЃЈКьПђБъзЂЕФЃЉЃЌЕЋЪЧКЭЦфЫћЕФбЕСЗЗНЗЈВЛЭЌЃЌOnline
LearningвЊЧѓПьЫйЧѓГіФПБъКЏЪ§ЕФзюгХНтЃЌзюКУЪЧФмгаНтЮіНтЁЃ
дѕбљЪЕЯжOnline Learning
ЧАУцЫЕЕНOnline LearningвЊЧѓПьЫйЧѓГіФПБъКЏЪ§ЕФзюгХНтЁЃвЊТњзуетИівЊЧѓЃЌвЛАуЕФзіЗЈгаСНжжЃКBayesian
Online LearningКЭFollow The Regularized LeaderЁЃЯТУцОЭЯъЯИНщЩметСНжжзіЗЈЕФЫМТЗЁЃ
БДвЖЫЙЗНЗЈФмЙЛБШНЯздШЛЕиЕМГіOnline LearningЕФбЕСЗЗНЗЈЃКИјЖЈВЮЪ§ЯШбщЃЌИљОнЗДРЁМЦЫуКѓбщЃЌНЋЦфзїЮЊЯТвЛДЮдЄВтЕФЯШбщЃЌШЛКѓдйИљОнЗДРЁМЦЫуКѓбщЃЌШчДЫНјааЯТШЅЃЌОЭЪЧвЛИіOnline
LearningЕФЙ§ГЬЃЌШчЯТЭМЫљЪОЁЃ
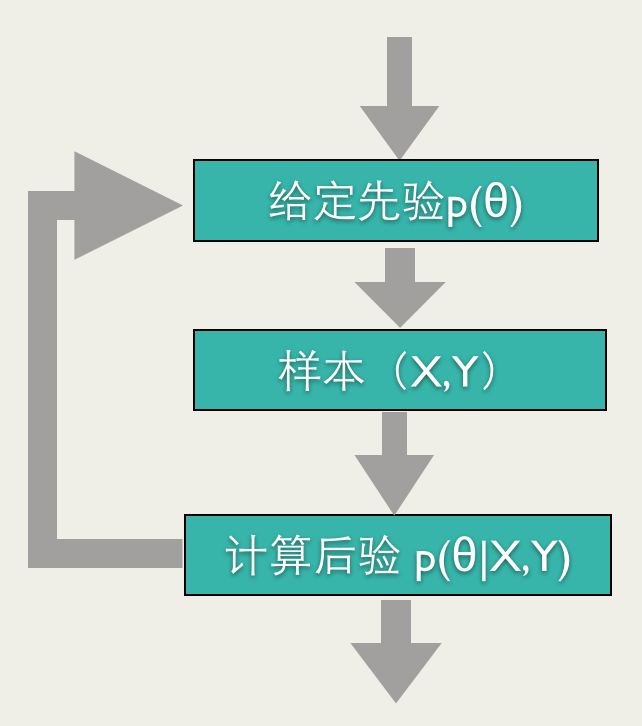
ОйИіР§згЃЌ ЮвУЧзівЛИіХзгВБвЪЕбщЃЌЙРЫугВБве§УцЕФИХТЪІЬІЬЁЃЮвУЧМйЩшІЬІЬЕФЯШбщТњзу
ЖдгкЙлВтжЕYЃН1YЃН1ЃЌДњБэЪЧе§УцЃЌЮвУЧПЩвдЫуЕФКѓбщЃК
ЖдгкЙлВтжЕYЃН0YЃН0ЃЌДњБэЪЧЗДУцЃЌЮвУЧПЩвдЫуЕФКѓбщЃК
АДееЩЯУцЕФBayesian Online LearningСїГЬЃЌЮвУЧПЩвдЕУЕНЙРЫуІЬІЬЕФOnline
LearningЫуЗЈЃК
| ГѕЪМЛЏ
ІСІС,ІТІТ
for i = 0 ... n
ШчЙћ YiYiЪЧе§Уц
ІС=ІС+1ІС=ІС+1
ШчЙћ YiYiЪЧЗДУц
ІТ=ІТ+1 |
зюже: ІЬЁЋBeta(ІС,ІТ)ІЬЁЋBeta?(ІС,ІТ)ЃЌПЩвдШЁІЬІЬЕФЦкЭћЃЌІЬ=ІСІС+ІТІЬ=ІСІС+ІТ
МйЩшХзСЫNNДЮгВБвЃЌе§УцГіЯжHHДЮЃЌЗДУцГіЯжTTДЮЃЌАДееЩЯУцЕФЫуЗЈЃЌПЩвдЫуЕУЃК
КЭзюДѓЛЏЫЦШЛКЏЪ§ЃК
| log[p(ІЬЈOІС,ІТ)?p(Y=1ЈOІЬ)H?p(Y=0ЈOІЬ)T] |
ЕУЕНЕФНтЪЧвЛбљЕФЁЃ
ЩЯУцЕФР§згЪЧеыЖдРыЩЂЗжВМЕФЃЌЮвУЧПЩвддйПДвЛИіСЌајЗжВМЕФР§згЁЃ
гавЛжжВтСПвЧЦїЃЌВтСПЕФЗНВюІв2Ів2ЪЧвбжЊЕФЃЌ ВтСПНсЙћЮЊЃКY1,Y2,Y3,...,YnY1,Y2,Y3,...,Yn,
ЧѓецЪЕжЕІЬІЬЕФЗжВМЁЃ
вЧЦїЕФЗНВюЪЧІв2Ів2, ЫљвдЙлВтжЕYТњзуИпЫЙЗжВМЃК
ЙлВтЕН Y1,Y2,Y3,...,YnY1,Y2,Y3,...,Yn, ЙРМЦВЮЪ§ ІЬІЬ ЁЃ
МйЩшВЮЪ§ ІЬІЬ ТњзуИпЫЙЗжВМЃК
ЙлВтЕНYiYi, ПЩвдМЦЫуЕФКѓбщЃК
| p(ІЬЈOYi)=N(ІЬЈOYiv2+mІв2Ів2+v2,Ів2v2Ів2+v2) |
ПЩвдЕУЕНвдЯТЕФOnline LearningЫуЗЈЃК
| ГѕЪМЛЏ
mm,v2v2
for i = 0 ... n
ЙлВтжЕЮЊYiYi
ИќаТ
m=Yiv2+mІв2Ів2+v2
m=Yiv2+mІв2Ів2+v2
v2=Ів2v2Ів2+v2
|
ЩЯУцЕФСНИіНсЙћЖМЪЧКѓбщИњЯШбщЪЧЭЌвЛЗжВМЕФЃЈвЛАуШЁЙВщюЯШбщЃЌОЭЛсгаетбљЕФаЇЙћЃЉЃЌетИіКѓбщКмздШЛЕФзїЮЊКѓУцВЮЪ§ЙРМЦЕФЯШбщЁЃМйЩшКѓбщЗжВМКЭЯШбщВЛвЛбљЃЌЮвУЧИУдѕУДАьФиЃП
ОйИіР§згЃКМйЩшЩЯУцЕФВтСПвЧЦїжЛФмЙлВтЕНYYЃЌЪЧДѓгк0ЃЌЛЙЪЧаЁгк0ЃЌМДYiЁЪ{?1ЃЌ1}YiЁЪ{?1ЃЌ1},Yi=?1Yi=?1ЃЌДњБэЙлВтжЕаЁгк0ЃЌYi=1Yi=1ДњБэЙлВтжЕДѓгк0ЁЃ
ДЫЪБЃЌЮвУЧШдШЛПЩвдМЦЫуКѓбщЗжВМЃК
|
p(ІЬЈOYiЃН1)=I(ІЬ>0)p(ІЬ)Ёв+Ёо0p(ІЬ)du
p(ІЬЈOYiЃН1)=I(ІЬ>0)p(ІЬ)Ёв0+Ёоp(ІЬ)du
p(ІЬЈOYiЃН?1)=I(ІЬ<0)p(ІЬ)Ёв0?Ёоp(ІЬ)du
|
ЕЋЪЧКѓбщЗжВМЯдШЛВЛЪЧИпЫЙЗжВМЃЈЪЧНиЖЯИпЫЙЗжВМЃЉЃЌетжжЧщПіЯТЃЌЮвУЧПЩвдгУКЭЩЯУцЗжВМKLОрРызюНќЕФИпЫЙЗжВМДњЬцЁЃ
ЙлВтЕНYi=1Yi=1
| KL(p(ІЬЈOYi=1)||N(ІЬЈOm~,v~2)) |
ПЩвдЧѓЕУЃК
| m~=m+v?Ід(mv)
m~=m+v?Ід(mv)
v~2=v2(1?Іи(mv) |
ЙлВтЕНY=1Y=1
| KL(p(ІЬЈOYi=?1)||N(ІЬЈOІЬ~,v~2)) |
ПЩвдЧѓЕУЃК
| m~=m?v?Ід(?mv)
m~=m?v?Ід(?mv)
v~2=v2(1?Іи(?mv)) |
СНепзлКЯЦ№РДЃЌПЩвдЧѓЕУЃК
| m~=m+Yiv?Ід(Yimv)
m~=m+Yiv?Ід(Yimv)
v~2=v2(1?Іи(Yimv)) |
ЦфжаЃК
| Ід(t)=?(t)ІЕ(t)
Ід(t)=?(t)ІЕ(t)
?(t)=12Іаexp(?12t2)
?(t)=12Іаexp(?12t2)
ІЕ(t)=Ёвt?Ёо?(t)dt
ІЕ(t)=Ёв?Ёоt?(t)dt
Іи(t)=Ід(t)?(t?Ід(t))
|
гаСЫКѓбщЮвУЧПЩвдЕУЕНOnline Bayesian LearningСїГЬЃК
| ГѕЪМЛЏ
mm,v2v2
for i = 0 ... n
ЙлВтжЕЮЊYiYi
ИќаТ
m=m+Yi?v?Ід(Yi?mv)
m=m+Yi?v?Ід(Yi?mv)
v2=v2(1?Іи(Yi?mv))
|
Bayesian Online LearningзюГЃМћЕФгІгУОЭЪЧBPRЃЈBayesian Probit
RegressionЃЉЁЃ
BPR
дкПДOnline BPRЧАЃЌЮвУЧЯШСЫНтвдЯТLinear Gaussian System(ОпЬхПЩвдВЮПМ[3]ЕФ4.4Нк)ЁЃ
xxЪЧТњзуЖрЮЌИпЫЙЗжВМЃК
yyЪЧxxЭЈЙ§ЯпадБфЛЛМгШыЫцЛњШХЖЏІВyІВyЕУЕНЕФБфСПЃК
вбжЊxxЃЌЮвУЧПЩвдЕУЕНyyЕФЗжВМЃК
| p(y)=N(yЈOAІЬX+b,ІВy+AІВxAT) |
ЩЯУцетИіНсТлЕФОпЬхЕФЭЦЕМЙ§ГЬПЩвдВЮПМ[3]ЕФ4.4НкЃЌетРяЮвУЧжБНгФУРДгУЁЃ
ЮвУЧПЩвдМйЩшЬиеїШЈжи ww ТњзуЖРСЂИпЫЙЗжВМЃЌМД
| p(w)=N(wЈOІЬ,ІВ)
p(w)=N(wЈOІЬ,ІВ)
ЃК
ІЬ=[ІЬ1,ІЬ2,...,ІЬD]T
ІЬ=[ІЬ1,ІЬ2,...,ІЬD]T
ІВ=???????Ів210?00Ів22?0ЁЁ?Ё00?Ів2D???????
|
ЃК
YYЪЧвЛЮЌБфСПЃЌЪЧwwгыЬиеїЯђСПxxЕФФкЛ§ЃЌМгШыЗНВюЮЊІТ2ІТ2ЕФШХЖЏЃК
ИљОнЩЯУцЕФЪНзгПЩвдЕУГіЃК
| p(yЈOw)=N(yЈOxTІЬ,xTІВx+ІТ2) |
гЩгкЮвУЧжЛФмЙлВтЕНYYЃЌЪЧДѓгк0ЃЌЛЙЪЧаЁгк0ЃЌМДYiЁЪ{?1ЃЌ1}YiЁЪ{?1ЃЌ1},Yi=?1Yi=?1ЃЌДњБэЙлВтжЕаЁгк0ЃЌYi=1Yi=1ДњБэЙлВтжЕДѓгк0ЁЃ
ЖдгкЙлВтжЕЃЌЮвУЧПЩвдЯШгУKLОрРыНќЫЦyyЕФЗжВМЃЌЮвУЧПЩвдЫуГіКѓбщЃК
гаСЫyyЕФНќЫЦЗжВМЃЌЮвУЧПЩвдМЦЫуГіКѓбщЃК
ПЩвдЧѓЕУЃК
Online Bayesian Probit Regression бЕСЗСїГЬШчЯТЃК
FTRL
Г§СЫOnline Bayesian LearningЃЌЛЙгавЛжжзіЗЈОЭЪЧFTRLЃЈFollow The
Regularized LeaderЃЉЁЃ
FTRLЕФЭјЩЯзЪСЯКмЖрЃЌЕЋЪЧДѓВПЗжНщЩмдѕУДбљВњЩњЯЁЪшЛЏНтЃЌЖјЭљЭљКіТдСЫFTRLЕФЛљБОдРэЁЃЙЫУћЫМвхЃЌFTRLКЭЯЁЪшЛЏВЂУЛгаЙиЯЕЃЌЫќжЛЪЧвЛжжзіOnline
LearningЕФЫМЯыЁЃ
ЯШЫЕЫЕFTLЃЈFollow The LeaderЃЉЫуЗЈЃЌFTLЫМЯыОЭЪЧУПДЮевЕНШУжЎЧАЫљгаЫ№ЪЇКЏЪ§жЎКЭзюаЁЕФВЮЪ§ЁЃСїГЬШчЯТЃК
FTRLЫуЗЈОЭЪЧдкFTLЕФгХЛЏФПБъЕФЛљДЁЩЯЃЌМгШыСЫе§ЙцЛЏЃЌЗРжЙЙ§ФтКЯЃК
| w=argminwЁЦi=1tfi(w)+R(w) |
ЦфжаЃЌR(w)R(w)ЪЧе§ЙцЛЏЯюЁЃ
FTRLЫуЗЈЕФЫ№ЪЇКЏЪ§ЃЌвЛАувВВЛЪЧФмЙЛКмПьЧѓНтЕФЃЌетжжЧщПіЯТЃЌвЛАуашвЊеввЛИіДњРэЕФЫ№ЪЇКЏЪ§ЁЃ
ДњРэЫ№ЪЇКЏЪ§ашвЊТњзуМИИівЊЧѓЃК
1.ДњРэЫ№ЪЇКЏЪ§БШНЯШнвзЧѓНтЃЌзюКУЪЧгаНтЮіНт
2.гХЛЏДњРэЫ№ЪЇКЏЪ§ЧѓЕФНтЃЌКЭгХЛЏдКЏЪ§ЕУЕНЕФНтВюОрВЛФмЬЋДѓ
ЮЊСЫКтСПЬѕМў2жаЕФСНИіНтЕФВюОрЃЌетРяашвЊв§ШыregretЕФИХФюЁЃ
МйЩшУПвЛВНгУЕФДњРэКЏЪ§ЪЧht(w)ht(w)
УПДЮШЁ
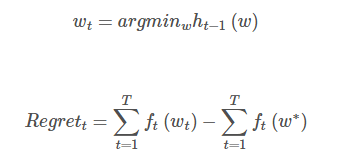
Цфжаw?=argminwЁЦti=1fi(w)w?=argminwЁЦi=1tfi(w)ЃЌЪЧдКЏЪ§ЕФзюгХНтЁЃОЭЪЧЮвУЧУПДЮДњРэКЏЪ§ЧѓГіНтЃЌРыеце§Ы№ЪЇКЏЪ§ЧѓГіНтЕФЫ№ЪЇВюОрЁЃЕБШЛетИіЫ№ЪЇБиаыТњзувЛЖЈЕФЬѕМўЃЌOnline
LearningВХПЩвдгааЇЃЌОЭЪЧЃК
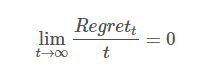
ЫцзХбЕСЗбљБОЕФдіЖрЃЌетСНИігХЛЏФПБъгХЛЏГіЕФВЮЪ§ЕФЪЕМЪЫ№ЪЇжЕВюОрдНРДдНаЁЁЃ
ДњРэКЏЪ§ ht(w)ht(w) гІИУИУдѕУДбЁФиЃП
ШчЙћft(w)ft(w) ЪЧЭЙКЏЪ§ЃЌЮвУЧПЩвдгУЯТУцЕФДњРэЫ№ЪЇКЏЪ§ЃК
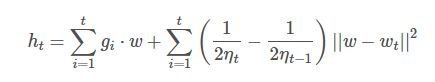
Цфжаgigi ЪЧfi(wi)fi(wi)ДЮЬнЖШЃЈШчЙћ fi(wi)fi(wi)ЪЧПЩЕМЕФЃЌДЮЬнЖШОЭЪЧЬнЖШЃЉЁЃІЧtІЧtТњзуЃК
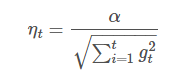
ЮЊСЫВњЩњЯЁЪшЕФаЇЙћЃЌЮвУЧвВПЩвдМгШыl1е§ЙцЛЏЃК
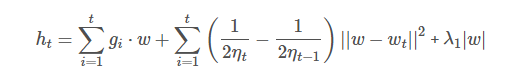
жЛвЊft(w)ft(w) ЪЧЭЙКЏЪ§ЃЌЩЯУцЕФДњРэКЏЪ§вЛЖЈТњзуЃК
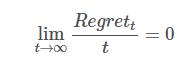
ЩЯУцЕФЪНзгЮвУЧПЩвдЕУГіwwЕФНтЮіНтЃК
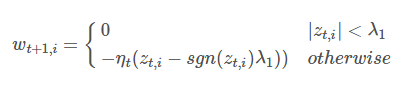
Цфжа
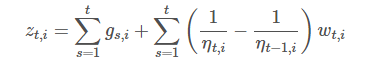
ПЩвдЕУЕНFTRLЕФИќаТСїГЬШчЯТЃК

Online LearningЪЕМљ
ЧАУцНВСЫOnline LearningЕФЛљБОдРэЃЌетРявдвЦЖЏЖЫЭЦМіжиХХађЮЊР§ЃЌНщЩмвЛЯТOnline
LearningдкЪЕМЪжаЕФгІгУЁЃ
ЭЦМіжиХХађНщЩм
ФПЧАЕФЭЦМіЯЕЭГЃЌжївЊВЩгУСЫСНВуМмЙЙЃЌЪзЯШЪЧДЅЗЂВуЃЌЛсИљОнЩЯЯТЮФЬѕМўКЭгУЛЇЕФРњЪЗааЮЊЃЌДЅЗЂгУЛЇПЩФмИааЫШЄЕФitemЃЌШЛКѓгЩХХађФЃаЭЖдДЅЗЂЕФitemХХЫуЗЈбЁдёађЃЌШчЯТЭМЫљЪОЃК
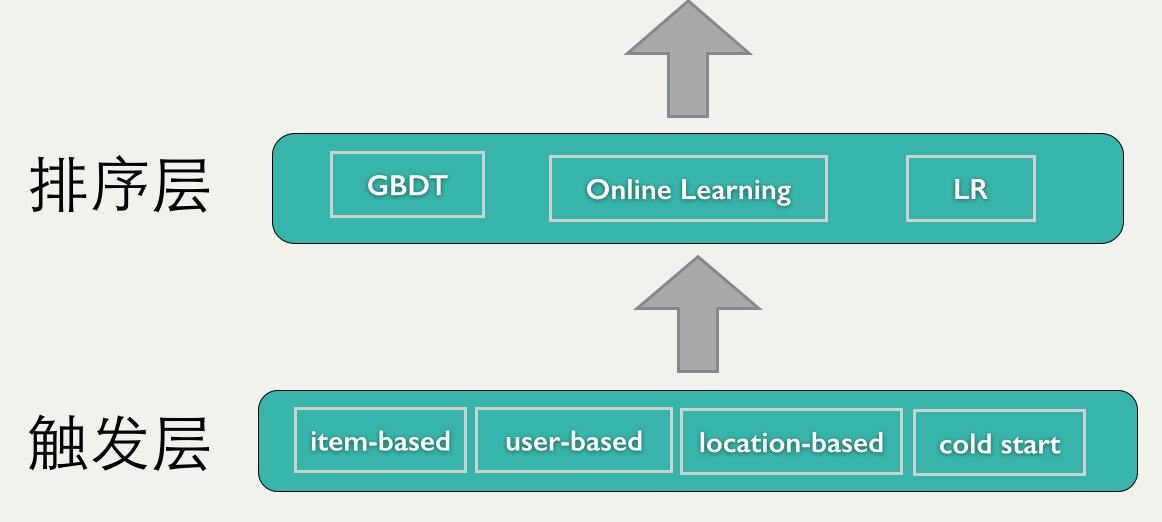
ЭЦМіжиХХађМШФмШкКЯВЛЭЌДЅЗЂВпТдЃЌгжФмНЯДѓЗљЖШЬсИпЭЦМіаЇЙћЃЈЮвУЧетРяжївЊЪЧЯТЕЅТЪЃЉЁЃдквЦЖЏЖЫЃЌЦСФЛИќМгаЁЃЌгУЛЇУПДЮПДЕНЕФitemЪ§ФПИќМгЩйЃЌХХађЕФзїгУИќМгЭЛГіЁЃ
УРЭХжиХХађOnline LearningМмЙЙ
УРЭХOnline LearningМмЙЙШчЯТЭМЫљЪОЃК
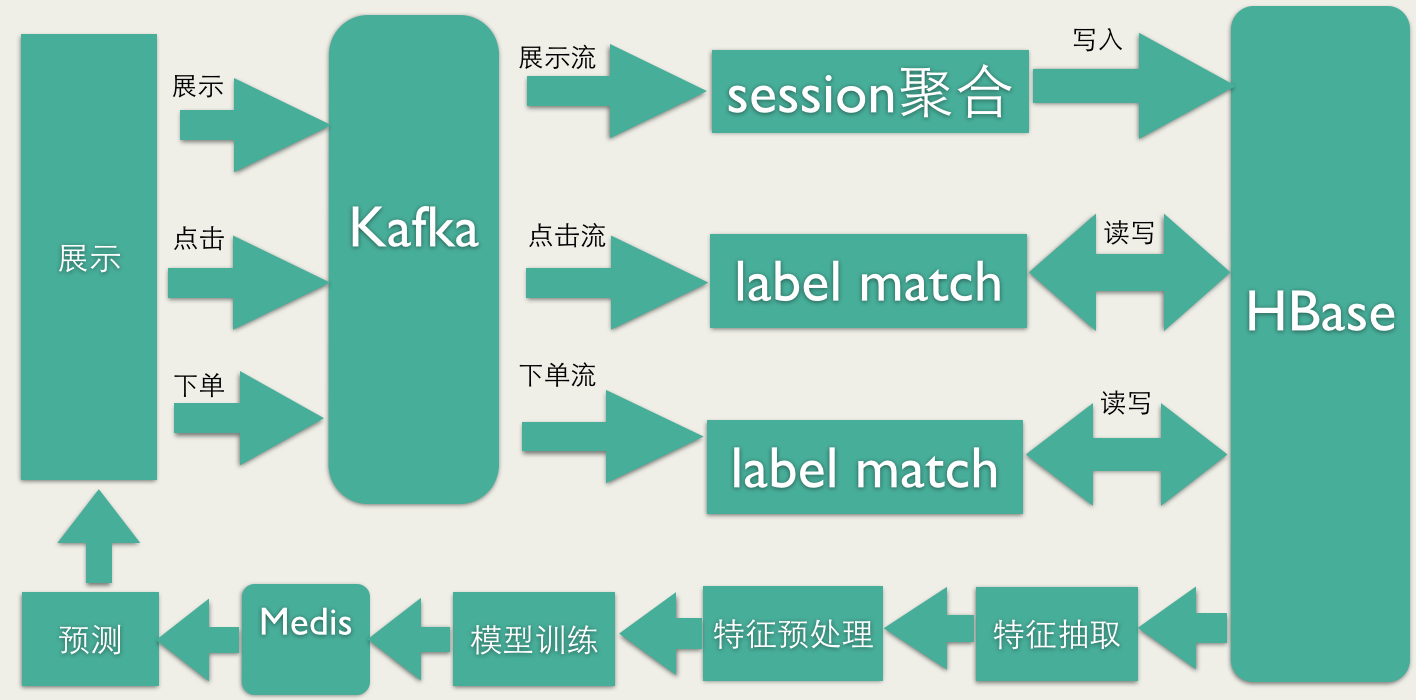
ЯпЩЯЕФеЙЪОШежОЃЌЕуЛїШежОКЭЯТЕЅШежОЛсаДШыВЛЭЌЕФKafkaСїЁЃЖСШЁKafkaСїЃЌвдHBaseЮЊжаМфЛКДцЃЌЭъГЩlabel
matchЃЈЯТЕЅКЭЕуЛїЖдгГЕНЯргІЕФеЙЪОШежОЃЉЃЌдкзіlabel matchЕФЙ§ГЩжаЃЌЛсЖдАбЭЌвЛИіsessionЕФШежОЗХдквЛЦ№ЃЌЗНБуКѓУцзіskip
aboveЃК
бЕСЗЪ§ОнЩњГЩ
вЦЖЏЖЫЭЦМіЕФЪ§ОнИњPCЖЫВЛЭЌЃЌвЦЖЏЖЫвЛДЮЛсМгдиКмЖрitemЃЌЕЋЪЧЮоЗЈБЃжЄетаЉitemЛсБЛгУЛЇПДЕНЁЃЮЊСЫБЃжЄЪ§ОнЕФзМШЗадЃЌЮвУЧВЩгУСЫskip
aboveЕФАьЗЈЃЌШчЯТЭМЫљЪОЃК
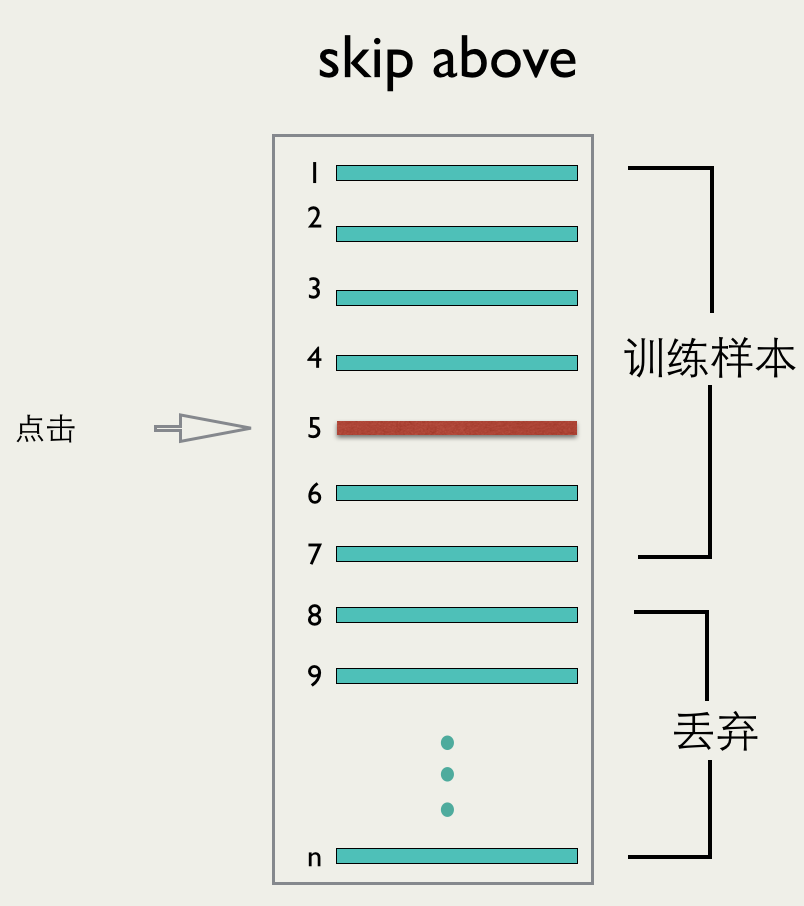
МйЩшгУЛЇЕуЛїСЫЕкiИіЮЛжУЃЌЮвУЧБЃСєДгЕк1ЬѕЕНЕкi+2ЬѕЪ§ОнзїЮЊбЕСЗЪ§ОнЃЌЦфЫћЕФЖЊЦњЁЃетбљФмЙЛзюДѓГЬЖШЕФБЃжЄбЕСЗбљБОжаЕФЪ§ОнЪЧБЛгУЛЇПДЕНЕФЁЃ
Ьиеї
гУЕФЬиеїШчЯТЭМЫљЪОЃК

ЫуЗЈбЁдё
ЮвУЧГЂЪдСЫFTRLКЭBPRаЇЙћЃЌЯпЯТЪЕбщаЇЙћШчЯТБэЃК

BPRЕФаЇЙћТдКУЃЌЕЋЪЧЮвУЧЯпЩЯбЁгУСЫFTRLФЃаЭЃЌжївЊдвђЪЧFTRLФмЙЛВњЩњЯЁЪшЛЏЕФаЇЙћЃЌбЕСЗГіЕФФЃаЭЛсБШНЯаЁЁЃ
ФЃаЭбЕСЗ
бЕСЗЫуЗЈВЛЖЯЕиДгHBaseжаЖСШЁЪ§ОнЃЌЭъГЩФЃаЭЕибЕСЗЃЌбЕСЗФЃаЭЗХдкMedisЃЈУРЭХФкВПЕиRedisЃЉжаЃЌЯпЩЯЛсгУMedisжаЕФФЃаЭдЄВтЯТЕЅТЪЃЌИљОндЄВтЕФЯТЕЅТЪЃЌЭъГЩХХађЁЃ
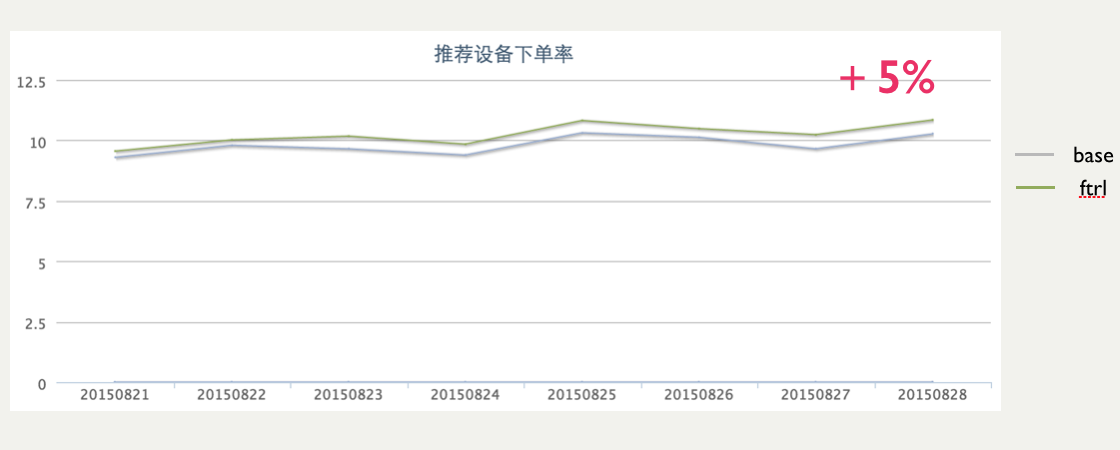
ЯпЩЯаЇЙћ
ЩЯЯпКѓЃЌзюжеЕФаЇЙћШчЯТЭМЫљЪОЃЌКЭbaseЫуЗЈЯрБШЃЌЯТЕЅТЪЬсИпСЫ5%ЁЃ
|









