| 编辑推荐: |
本文来自于csdn,本文章主要对真实数据(csv表格数据)的查看以及如何正确的分开训练测试集进行实战操作,希望对您的学习有帮助。
|
|
三、开始实战(处理CSV表格数据)
5、查看训练集的特征图像信息以及特征之间的相关性
上一节粗略地查看了数据的统计信息,接下来需要从训练样本中得到更多的信息,从而对数据进行一些处理。
查看训练集的特征图像信息
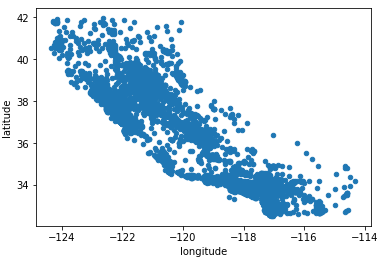
为了防止误操作在查看的时候修改了训练集,所以先复制一份进行操作。对longitude和latitude(经纬度)以散点(scatter)的形式输出,看数据的地区分布。
| train_housing
= strat_train_set.copy()
train_housing.plot(kind="scatter",
x="longitude", y="latitude")
|
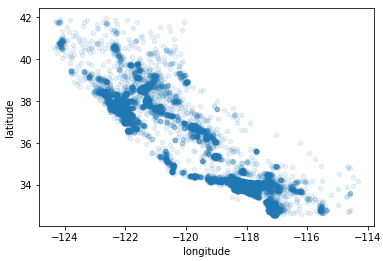
若加上参数alpha=0.1可以看到数据高密度的区域,若alpha设为1,则和上面一样,alpha越靠近0则只加深越高密度的地方。
| train_housing.plot(kind="scatter",
x="longitude", y="latitude",
alpha=0.1) |
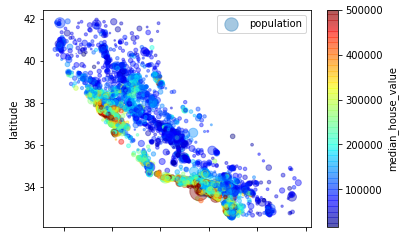
为了查看目标median_house_value的在各个地区的分布情况,所以可以增加参数c(用于对某参数显示颜色),参数s(表示某参数圆的半径),cmap表示一个colormap,jet为一个蓝到红的颜色,colorbar为右侧颜色条
| train_housing.plot(kind="scatter",
x="longitude", y="latitude",
alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=True,)
plt.legend()
|
查看特征之间的相关性
查看median_house_value与其他变量的线性相关性,并排序输出,数据越靠近1则越相关,靠近-1则越负相关,接近0为不相关。
| corr_matrix
= train_housing.corr()
corr_matrix["median_house_value"].sort_values
(ascending=False)
|

可以看到除了与自己最相关以外,和median_income线性相关性很强。
然而上面只是计算了线性相关性,而特征之间可能是非线性的关系,因此需要画出图来看一下变量之间是否相关。(代码中只取其中的几个来看)
| from
pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value",
"median_income", "total_rooms"]
scatter_matrix(housing[attributes], figsize=(12,
8))
|
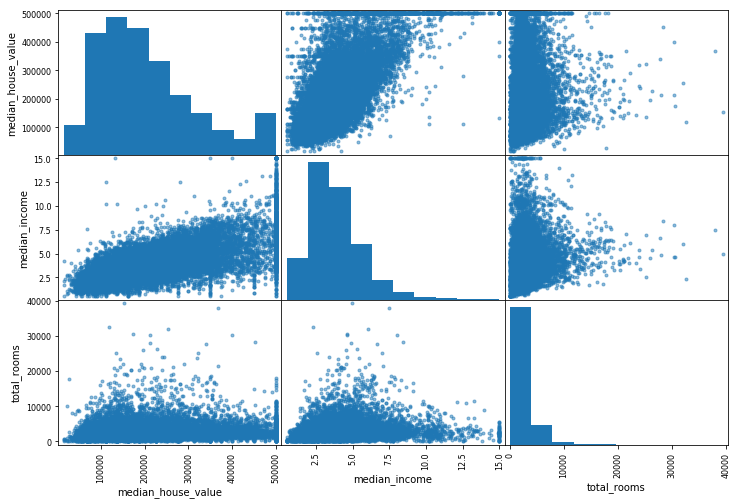
从第一行第二幅图,可以看到median_house_value和median_income的正线性相关性还是比较强的,但是还是看到一些问题,比如大于500000后的点可能在收集资料或预处理时设立的边界,使得变为一条直线一样;而且还有右下角一些奇异的点。为了让算法不学习到这些有问题的点,你可以去除这些相关区域的点。
特征之间的组合
两个特征对目标的相关性都不强,但是组合起来可能有较大的提升。最后还可以尝试一下特征的组合(不是特别重要)
| train_housing["rooms_per_household"]
= housing
["total_rooms"]/housing["households"]
train_housing["bedrooms_per_room"]
= housing
["total_bedrooms"]/housing["total_rooms"]
train_housing["population_per_household"]=housing
["population"]/housing["households"]
corr_matrix = train_housing.corr()
corr_matrix["median_house_value"].sort_values
(ascending=False)
|
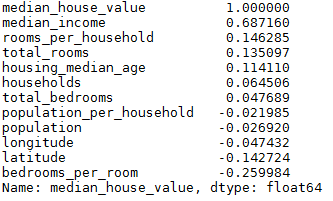
经过特征组合,可以看到新特征bedrooms_per_room对median_house_value的影响比较大(-0.2599),呈一定的负相关,即每个房子的卧室越少,价格反而越贵。
6、准备数据(数据预处理)
首先分开特征(feature)和目标标签(label),以median_house_value作为标签,其他作为特征。
| train_housing
= strat_train_set.drop("median_house_value",
axis=1)
train_housing_labels = strat_train_set["median_house_value"].copy() |
数据清洗
在第一节我们得知total_bedrooms存在一些缺失值,对于缺失值的处理有三种方案:
1、去掉含有缺失值的个体(dropna)
2、去掉含有缺失值的整个特征(drop)
3、给缺失值补上一些值(0、平均数、中位数等)(fillna)
| #train_housing.dropna(subset=["total_bedrooms"])
# option 1
#train_housing.drop("total_bedrooms",
axis=1) # option 2
median = train_housing["total_bedrooms"].median()
train_housing["total_bedrooms"].fillna(median)
# option 3
|
为了得到更多可利用的数据,在这里我们选择方案3。
当然非常方便的Scikit-Learn也存在对缺失值处理的类Imputer。我们打算对所有地方的缺失值都补全,以防运行模型时发生错误。使用Imputer函数需要先定义一个补缺失值的策略(如median),由于median策略只能对实数值有效,所以需要将文本属性先去除,然后再补缺失值。最后使用fit方法对变量执行相应操作。
| from
sklearn.preprocessing import Imputer
imputer = Imputer(strategy="median")
housing_num = train_housing.drop("ocean_proximity",
axis=1)
imputer.fit(housing_num)
|
对数据缺失值补全以后,一般需要转化为Numpy的矩阵格式,方便模型的输入,所以可以调用Imputer的transform()方法,当然fit和transform也可以合起来使用,即fit_transform(),这个函数会比分开调用要快一些。
| X
= imputer.transform(housing_num)
#X = imputer.fit_transform(housing_num)
#也可以将numpy格式的转换为pd格式
#housing_tr = pd.DataFrame(X, columns=housing_num.columns)
|
处理类别文本特征
由于文本属性不能作median等操作,所以需要将文本特征编码为实数特征,对应Scikit-Learn中的类为LabelEncoder,通过调用LabelEncoder类,再使用fit_transform()方法自动将文本特征编码
| from
sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
housing_cat = train_housing["ocean_proximity"]
housing_cat_encoded = encoder.fit_transform(housing_cat)
print(housing_cat_encoded)
print(encoder.classes_)
|
输出的数字编码与编码对应的类型为:

由于0到1的距离比0到3的距离要近,所以这种数字编码暗含了0和1的相似性比0到3的相似性要强,然而事实上并非如此,每个元素的相似性应趋于相等。如果该数字编码作为label,则只是一个标签,没有什么影响。但是如果用于特征,则这种数字编码不适用,应该采用one
hot编码(形式可以看下面的图),对应Scikit-Learn中的类为OneHotEncoder
| from
sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
|
默认的输出结果为稀疏矩阵Scipy(sparse matrix),而不是Numpy,由于矩阵大部分为0,浪费空间,所以使用稀疏矩阵存放,如果想看矩阵的具体样子,则用toarray()方法变为dense
matrix(Numpy)。
| housing_cat_1hot.toarray() |

上述文本编码先经过数字编码再转为one hot编码用了两步,当然也可以一步到位,直接从文本编码到one
hot,对应Scikit-Learn中的类为LabelBinarizer
| from
sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
#encoder = LabelBinarizer(sparse_output=True)
housing_cat_1hot = encoder.fit_transform(housing_cat)
|
要注意的是,不设参数sparse_output=True的话,默认输出的是Numpy矩阵。
自定义Transformer
由于Scikit-Learn中的函数中提供的Transformer方法并不一定适用于真实情形,所以有时候需要自定义一个Transformer,与Scikit-Learn能够做到“无缝结合”,比如pineline(以后会说到)。定义类时需要加入基础类:BaseEstimator(必须),以及TransformerMixin(用于自动生成fit_transformer()方法)。下面是一个例子:用于增加组合特征的Trainsformer
| from
sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, household_ix
= 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator,
TransformerMixin):
def __init__(self, add_bedrooms_per_room = True):
# no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:,
household_ix]
population_per_household = X[:, population_ix]
/ X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:,
rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
|
在该代码中,init中设置参数,可以调整是否加入该元素,用于尝试确定加入该元素是否对模型效果提升,方便修改,节省时间。
特征缩放
由于机器学习算法在不同尺度范围的特征之间表现的不好,比如total number of rooms范围是6-39320,而median_incomes范围是0-15。因此需要对特征的范围进行缩放,对应Scikit-Learn中的类为:
1、MinMaxScaler:将特征缩放到0-1之间,但异常值对这个影响比较大,比如异常值为100,缩放0-15为0-0.15;
2、feature_range:可以自定义缩放的范围,不一定是0-1;
3、StandardScaler:标准化(减均值,除方差),对异常值的影响较小,但可能会不符合某种范围
需要注意:每次缩放只能针对训练集或只是测试集,而不能是整个数据集,这是由于测试集(或新数据)不属于训练范围。
Transformation Pipelines
可以看到,上述有非常多的转换操作,并按一定的顺序执行,但是再次处理其他数据(如测试数据)时需要重新调用执行众多步骤,代码看起来过于繁琐。所以Scikit-Learn提供了Pineline类来帮助这种一系列的转换,把这些转换封装为一个转换。下面是一个简单的例子。
| from
sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
|
Pipeline是由(name(名字),Estimator(类))对组成,但最后一个必须为transformer,这是因为要形成fit_transform()方法
上面的pineline只是用于处理实数特征的,对于处理类别特征的还有另一个Pineline,这就可以使用FearureUnion类来结合多个pineline,多个Pineline可以并行处理,最后将结果拼接在一起输出。
由于Scikit-Learn没有处理Pandas数据的DataFrame,因此需要自己自定义一个如下:
| from
sklearn.base import BaseEstimator, TransformerMixin
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
|
然后就可以通过FeatureUnion类结合两个Pineline
| from
sklearn.pipeline import FeatureUnion
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('label_binarizer', LabelBinarizer()),
])
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
housing_prepared = full_pipeline.fit_transform(train_housing)
! |
需要注意:在scikit-learn == 0.18.0及以前版本LabelBinarizer()用在Pineline没有问题;而在0.19.0版本则会报错,因此需要自己定义一个新的LabelBinarizer_new(),代码如下;0.20.0版本以后可以使用新的类CategoricalEncoder()
| from
sklearn.base import BaseEstimator, TransformerMixin
class LabelBinarizer_new(TransformerMixin, BaseEstimator):
def fit(self, X, y = 0):
self.encoder = None
return self
def transform(self, X, y = 0):
if(self.encoder is None):
print("Initializing encoder")
self.encoder = LabelBinarizer();
result = self.encoder.fit_transform(X)
else:
result = self.encoder.transform(X)
return result
|
|









