| 编辑推荐: |
本文来自于简书,本文章主要通过举例来论证机器学习算法,通过矩阵进行强化学习介绍。
|
|
所谓强化学习就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强
-《百科》
简单来说就是给你一只小白鼠在迷宫里面,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到最正确的道路。
下面直接上例子:
假设我们有5间房,如下图所示,这5间房有些房间是想通的,我们分别用0-4进行了标注,其中5代表了是是出口。
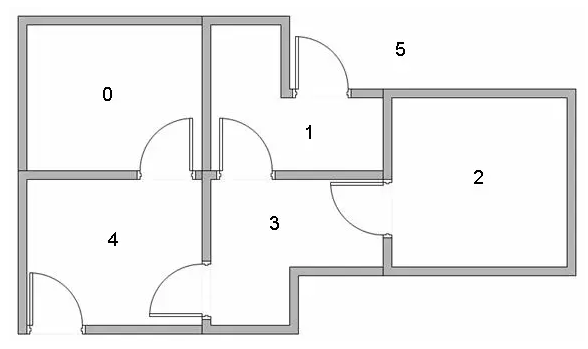
我们使用一副图来表示,就是下面这个样子
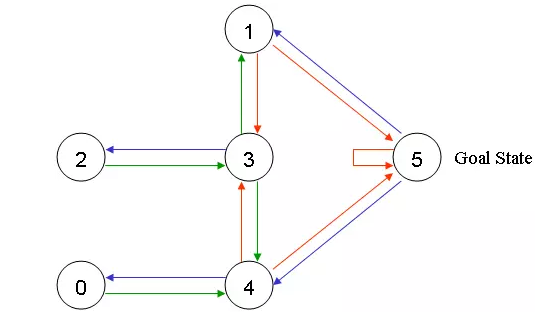
在这个例子里,我们的目标是能够走出房间,就是到达5的位置,为了能更好的达到这个目标,我们为每一个门设置一个奖励。比如如果能立即到达5,那么我们给予100的奖励,其它没法到5的我们不给予奖励,权重是0了,如下图所示
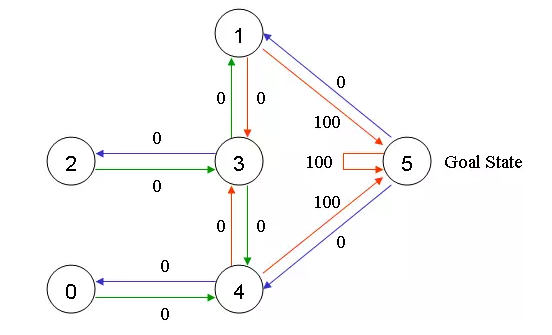
因为也可以到它自己,所以也是给100的奖励,其它方向到5的也都是100的奖励。
在Q-learning中,目标是权重值累加的最大化,所以一旦达到5,它将会一直保持在这儿。
想象下我们有一个虚拟的机器人,它对环境一无所知,但它需要通过自我学习知道怎么样到外面,就是到达5的位置。
好啦,现在可以引出Q-learning的概念了,“状态”以及“动作”,我们可以将每个房间看成一个state,从一个房间到另外一个房间的动作叫做action,state是一个节点,而action是用一个剪头表示。
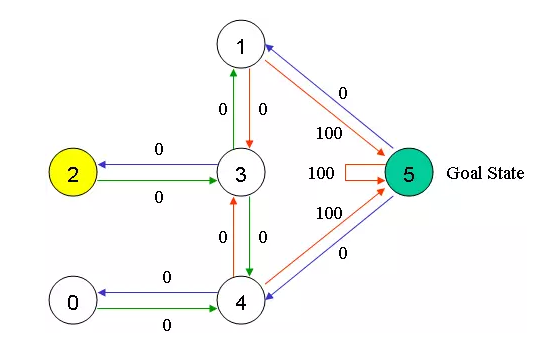
现在假设我们在状态2,从状态2可以到状态3,而无法到状态0、1、4,因为2没法直接到0、1、4;从状态3,可以到1、4或者2;而4可以到0、3、5;其它依次类推。
所以我们能够把这些用一个矩阵来表示:
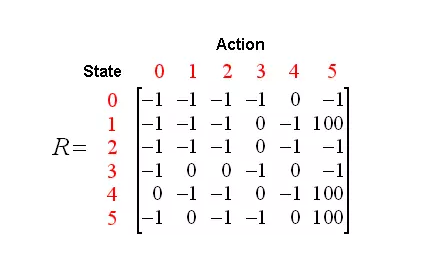
这个矩阵就是传说中的Q矩阵了,这个矩阵的列表表示的是当前状态,而行标表示的则是下一个状态,比如第三行的行标是2,如果取第四列,比如说2,4就表示了从2->4的收益是0,而-1就表示了没法从一个状态到另外一个状态。
Q矩阵初始化的时候全为0,因为它的状态我们已经全部知道了,所以我们知道总的状态是6。如果我们并不知道有多少个状态,那么请从1个状态开始,一旦发现新的状态,那么为这个矩阵添加上新的行和列。
于是我们就得出了如下的公式:
Q(state, action) = R(state, action) + Gamma * Max[Q(next
state, all actions)]
根据这个公式,Q矩阵值 = R的当前值 + ?Gamma(系数)* Q最大的action(看不懂不要紧,后面有例子)
我们的虚拟机器人将通过环境来学习,机器人会从一个状态跳转到另一个状态,直到我们到达最终状态。我们把从开始状态开始一直达到最终状态的这个过程称之为一个场景,机器人会从一个随机的开始场景出发,直到到达最终状态完成一个场景,然后立即重新初始化到一个开始状态,从而进入下一个场景。
因此,我们可以将算法归纳如下
Q-learning算法如下:
1 设置gamma相关系数,以及奖励矩阵R
2 将Q矩阵初始化为全0
3 For each episode:
设置随机的初使状态
Do While 当没有到达目标时?
选择一个最大可能性的action(action的选择用一个算法来做,后面再讲)
根据这个action到达下一个状态
根据计算公式:Q(state, action) = R(state,
action) + Gamma * Max[Q(next state, all actions)]计算这个状态Q的值
设置当前状态为所到达的状态
End Do
End For
其中Gamma的值在0,1之间(0 <= Gamma <1)。如果Gramma接近0,对立即的奖励更有效。如果接近1,整个系统会更考虑将来的奖励。
以上就是整个算法了,并不是很难的,下面来看个一段人肉算法操作,让你彻底明白这个算法。
人肉算法步骤
首先将Q初始化一个全为0的矩阵,Q是我们目标矩阵,我们希望能够把这个矩阵填满然

后初始化我们的R矩阵,假设这个值我们都是知道的,如下图所示
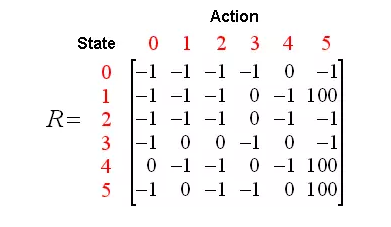
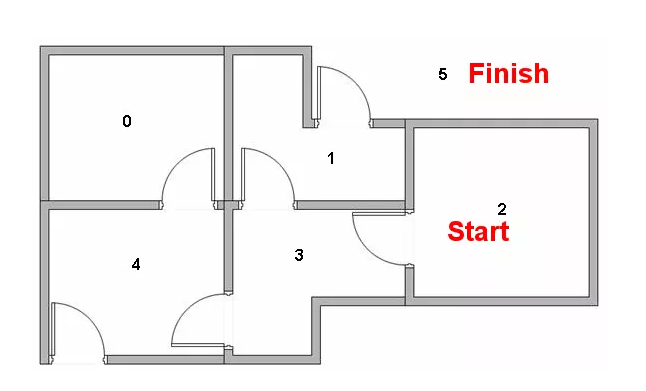
现在,假设我们的初始位置是state1,首先检查一下我们的R矩阵,在R矩阵中发现从state1可以到2个位置:state3、state5,我们随机选择一个方向,比如我们现在从1到5,我们可以用公式
Q(state, action) = R(state, action) + Gamma * Max[Q(next
state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5,
5)]= 100 + 0.8 * 0 = 100
来计算出Q(1,5), 因为Q矩阵是初始化为0,所以 Q(5,1),
Q(5,4),Q(5,5)都是0,所以Q(1,5)的值为100,现在5变成了当前状态,因为5已经是最终状态了,所以,这个场景就结束鸟,Q矩阵变成如下
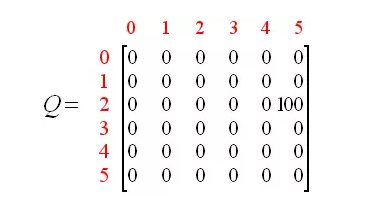
然后我们再随机的选择一个状态,比如现在选了状态3为我们的初始状态,好啦,来看我们R矩阵;有3个可能性的1、2、4我们随机的选择1,继续用公式计算:
Q(state, action) = R(state, action) + Gamma * Max[Q(next
state, all actions)]
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)]= 0
+ 0.8 * Max(0, 100) = 80
然后,更新矩阵,矩阵变成了这个样子
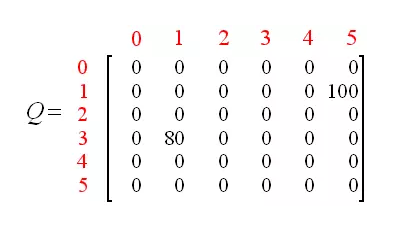
我们的当前状态变成了1,1并不是最终状态,所以算法还是要往下执行,此时,观察R矩阵,1有1->3,
1->5两个选择,子这里我们选择 1->5这个action有着较高回报,所以我们选择了1->5,
重新计算Q(1,5)的值
Q(state, action) = R(state, action) + Gamma * Max[Q(next
state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(1, 2), Q(1, 5)]= 0
+ 0.8 * Max(0, 100) = 80
为什么要重新计算呢?因为某些值可能会发生变化,计算完后更新矩阵
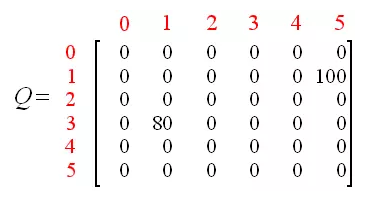
因为5已经是最终状态了,所以结束我们本次场景迭代。
经过循环迭代,我们得出了最终结果,是这个样子的

经过正则化处理,矩阵最终会变成这个样子
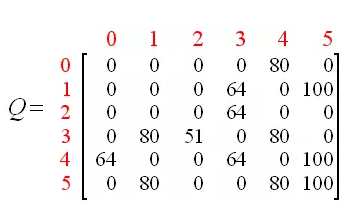
强化学习到此结束。我们的机器人自动学习到了最优的路径,就是按照最大奖励值的路径就可以啦
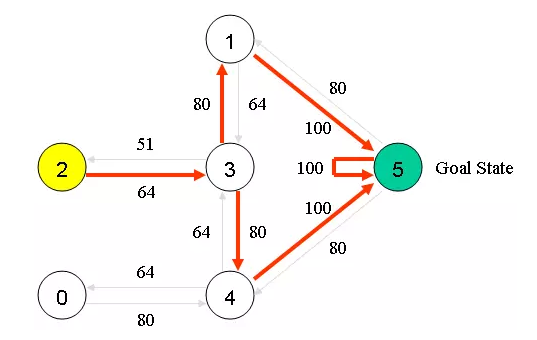
如图红线所示,代表了各个点到达终点的最优路径
这是一个级简的算法,隐藏了很多细节,出去吹NB是够了,实践上实现起来还是有许多问题的。
下面就是细节代码了,对实现刚兴趣的继续往下看。
我们之前说了,选择动作的依据是“选择一个最大可能性的action”,那么这个动作要怎么选呢?
我们选择最大收益的那个值,比如在R矩阵中,总是选择值最大的那个
算法我们可以通过代码来表示就是这样

大家想一下这样是否会存在问题呢?当然有,如果有几个最大值怎么处理呢?,如果有几个最大值的话我们就随机的取一个呗

是不是这样就可以了呢?大家想一下,万一在当前动作收益很小,小收益到达的状态的后续action可能会更大,所以,我们不能直接选取最大的收益,而是需要使用一个新的技术来探索,在这里,我们使用了epsilon,首先我们用产生一个随机值,如果这个随机值小于epsilon,那么下一个action会是随机动作,否则采用组大值,代码如下

但实际上这种做法还是有问题的,问题是即使我们已经学习完毕了,已经知道了最优解,当我们选择一个动作时,它还是会继续采取随机的动作。有许多方法可以克服这个,比较有名称之为mouse
learns: 没循环一次就减少epsilon的值,这样随着学习的进行,随机越来越不容易触发,从而减少随机对系统的影响,常用的减少方法有以下几种,大家可以根据情况选用
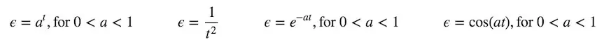
|









