| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФЯъЯИНщЩмСЫЬиеїЙЄГЬКЭЬиеїЬсШЁШчКЮЗЂЛгзїгУ,ЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ
|
|
ЁАЬиеїЙЄГЬЁБетИіЛЊРіЕФЪѕгяЃЌЫќвдОЁПЩФмШнвзЕиЪЙФЃаЭДяЕНСМКУадФмЕФЗНЪНЃЌРДШЗБЃФуЕФдЄВтвђзгБЛБрТыЕНФЃаЭжаЁЃР§ШчЃЌШчЙћФугавЛИіШеЦкзжЖЮзїЮЊвЛИідЄВтвђзгЃЌВЂЧвЫќдкжмФЉгыЦНШеЕФЯьгІЩЯгазХКмДѓЕФВЛЭЌЃЌФЧУДвдетжжЗНЪНБрТыШеЦкЃЌЫќИќШнвзШЁЕУКУЕФаЇЙћЁЃ
ЕЋЪЧЃЌетШЁОігкаэЖрЗНУцЁЃ
ЪзЯШЃЌЫќЪЧвРРЕФЃаЭЕФЁЃР§ШчЃЌШчЙћРрБпНчЪЧвЛИіЖдНЧЯпЃЌФЧУДЪїПЩФмЛсдкЗжРрЪ§ОнМЏЩЯгіЕНТщЗГЃЌвђЮЊЗжРрБпНчЪЙгУЕФЪЧЪ§ОнЕФе§НЛЗжНтЃЈаБЪїГ§ЭтЃЉЁЃ
ЦфДЮЃЌдЄВтБрТыЙ§ГЬДгЮЪЬтЕФЬиЖЈбЇПЦжЊЪЖжаЪмвцзюДѓЁЃдкЮвИеВХСаОйЕФР§згжаЃЌФуашвЊСЫНтЪ§ОнФЃЪНЃЌШЛКѓИФЩЦдЄВтвђзгЕФИёЪНЁЃЬиеїЙЄГЬгыЭМЯёДІРэЁЂаХЯЂМьЫївдМАRNAБэДяЦзЕШДѓВЛЯрЭЌЁЃФуашвЊСЫНтЙигкетИіЮЪЬтЕФвЛаЉаХЯЂЃЌВЂЧвгУФуЕФЬиЖЈЪ§ОнМЏРДзіКУЬиеїЙЄзїЁЃ
ЯТУцЪЧвЛаЉбЕСЗМЏЕФЪ§ОнЃЌЪЙгУСНИідЄВтвђзгРДНЈСЂвЛИіЖўЗжРрЯЕЭГФЃаЭЃЈЮвЛсдкКѓУцНвЯўЪ§ОнРДдДЃЉЃК
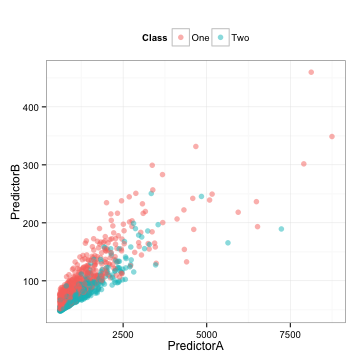
етРяЛЙгаЮвУЧНЋдкЯТУцЪЙгУЕНЕФЯрЙиВтЪдМЏЁЃ
ЮвУЧПЩвдЕУЕНвдЯТНсТлЃК
1.етаЉЪ§ОнЪЧИпЖШЯрЙиЕФЃЈЯрЙиЯЕЪ§=0.85ЃЉЁЃ
2.УПИідЄВтвђзгЫЦКѕЪЧЯђгвЧуаБЕФЁЃ
3.ЫќУЧЫЦКѕЪЧЖраХЯЂЕФЃЌДгФГжжвтвхЩЯРДЫЕЃЌФуЛђаэПЩвдЛГівЛЬѕЖдНЧЯпРДЧјЗжРрБ№ЁЃ
ШЁОігкЮвУЧбЁдёЪЙгУЕФФЃаЭЃЌСНИідЄВтвђзгЕФЯрЙиадПЩФмЛсРЇШХЮвУЧЁЃЭЌбљЃЌЮвУЧгІИУМьВщЕЅИідЄВтвђзгЪЧЗёживЊЁЃЮЊСЫКтСПетвЛЕуЃЌЮвУЧНЋжБНгЪЙгУдкдЄВтЪ§ОнЩЯЕФROCЧњЯпЯТЗНЕФУцЛ§ЁЃ
ЯТУцЪЧУПвЛИідЄВтвђзгЕФЕЅБфСПКаЭМЃЈдкЖдЪ§ГпЖШЩЯЃЉЃК
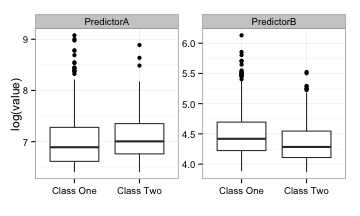
етСНИіРржЎМфгавЛаЉЯИЮЂЕФВюБ№ЃЌЕЋЪЧгаКмЖржиЕўВПЗжЁЃдЄВтФЃаЭAКЭBЕФROCЧњЯпУцЛ§ЗжБ№ЪЧ0.61КЭ0.59ЁЃетИіНсЙћВЂВЛКУЁЃ
ФЧЮвУЧФмзіЪВУДЃПжїГЩЗжЗжЮіЃЈPCAЃЉЪЧвЛжждЄДІРэЕФЗНЗЈЃЌЫќвдДДНЈаТЕФзлКЯдЄВтвђзгЃЈМДжївЊГЩЗжЛђPC'sЃЉЕФЗНЪНа§зЊдЄВтЪ§ОнЁЃЫќЭЈЙ§етбљЕФЗНЪНЗжЮіЃКЕквЛИіГЩЗжеМдЄВтЪ§ОнжаДѓЖрЪ§ЃЈЯпадЃЉБфСПЛђаХЯЂЕФБШжиЁЃдкЬсШЁЕквЛИіГЩЗжжЎКѓЃЌЕкЖўИіГЩЗжвдЭЌбљЕФЗНЪНРДДІРэЪЃЯТЕФЪ§ОнЃЌВЂЧввРДЮЯТШЅЁЃЖдгкетаЉЪ§ОнЃЌгаСНжжПЩФмЕФзщГЩВПЗжЃЈвђЮЊжЛгаСНИідЄВтвђзгЃЉЁЃвдетжжЗНЪНЪЙгУPCAЭЈГЃБЛГЦЮЊЬиеїЬсШЁЁЃ
ЮвУЧРДМЦЫуЯТетаЉГЩЗжЃК
| >
library(caret)
> head(example_train) |
|
PredictorA PredictorB Class
2 3278.726 154.89876 One
3 1727.410 84.56460 Two
4 1194.932 101.09107 One
12 1027.222 68.71062 Two
15 1035.608 73.40559 One
16 1433.918 79.47569 One |
| >
pca_pp <- preProcess(example_train[, 1:2],
+ method = c("center", "scale",
"pca"))
+ pca_pp |
| Call:
preProcess.default(x = example_train[, 1:2],
method = c("center",
"scale", "pca"))
Created from 1009 samples and 2 variables
Pre-processing: centered, scaled, principal
component signal extraction
PCA needed 2 components to capture 95 percent
of the variance |
| >
train_pc <- predict(pca_pp, example_train[,
1:2])
> test_pc <- predict(pca_pp, example_test[,
1:2])
> head(test_pc, 4) |
|
PC1 PC2
1 0.8420447 0.07284802
5 0.2189168 0.04568417
6 1.2074404 -0.21040558
7 1.1794578 -0.20980371 |
ЧызЂвтЃЌЮвУЧдкбЕСЗМЏЩЯМЦЫуСЫЫљгаЕФБивЊаХЯЂЃЌВЂЧвНЋетаЉМЦЫугІгУЕНВтЪдМЏЁЃФЧУДВтЪдМЏЪЧЪВУДбљЕФФиЃП
етЪЧВтЪдМЏдЄВтвђзгМђЕЅЕФа§зЊЁЃ
PCAЪЧЗЧМрЖНЪНЕФЃЌетвтЮЖзХЕБМЦЫуНсЪјЪБЃЌВЛашвЊПМТЧЪфГіРрЁЃдкетРяЃЌROCЧњЯпЕФЯТЗНВПЗжЃЌгУЕквЛИіГЩЗжЕУЕНЕФУцЛ§ЪЧ0.5ЃЌЕкЖўИіГЩЗжЕУЕНЕФУцЛ§ЪЧ0.81ЁЃетаЉНсЙћгыЩЯУцЕФЕуЛьдквЛЦ№ЃЛЕквЛИіГЩЗждкРржаОпгаЫцЛњЛьКЯЕФЬиадЃЌЖјЕкЖўИіГЩЗжЫЦКѕПЩвдКмКУЕиЗжРыРрЁЃСНжжГЩЗжЕФКаЭМЗДгГСЫЭЌбљЕФЧщПіЃК

дкЕкЖўИіГЩЗжжаЃЌСНИіРрЕФЗжРыЖШИќИпЁЃ
етКмгаШЄЁЃЪзЯШЃЌОЁЙмPCAЪЧЗЧМрЖНЪНЕФЃЌЫќЛЙЪЧГЩЙІЕиевЕНСЫвЛИіаТЕФдЄВтвђзгРДЛЎЗжРрБ№ЁЃЦфДЮЃЌетаЉГЩЗжЖдгкетаЉРрБ№ЪЧзюжевЊЕФЃЌЕЋЖдгкдЄВтЦїЖјбддђУЛФЧУДживЊЁЃЭЈГЃPCAВЂВЛЛсБЃжЄШЮКЮГЩЗжЛсИјГізМШЗдЄВтЁЃЕЋдкетРяЃЌЮвУЧКмавдЫЃЌЫќЕУЕНвЛИіВЛДэЕФдЄВтНсЙћЁЃ
ЕЋЪЧЃЌЪдЯыШчЙћгаЩЯАйИідЄВтвђзгЁЃЮвУЧПЩФмжЛашвЊЪЙгУЧАXИіГЩЗжРДЛёШЁдЄВтвђзгжаОјДѓВПЗжЕФаХЯЂЃЌШЛКѓЖЊЦњЦфЫћЕФГЩЗжЁЃдкетИіР§згжаЃЌЕквЛИіГЩЗжеМОндЄВтЦїБфСПЕФ92.4%ЃЌЭЌбљЕФЗНЗЈПЩФмЛсЖЊЦњзюгааЇЕФдЄВтвђзгЁЃ
ЬиеїЙЄГЬЕФЯыЗЈЪЧдѕУДГіЯжЕФФиЃПИјЖЈетСНжждЄВтвђзгЃЌЮвУЧПЩвдЕУЕНЯТУцЫљЪОЕФЩЂЕуЭМЃЌЮвЪзЯШЯыЕНЕФЪТЧщЪЧЁАгаСНИіЯрЙиСЊЕФЃЌе§ЯрЙиВЂЧваБНЛЕФдЄВтвђзгЃЌвЛЧАвЛКѓЕиНјааЗжРрЁБЁЃЦфДЮЮвЯыЕНЕФЪЧЁАРћгУБШР§ЁБЁЃФЧУДЪ§ОнЪЧЪВУДбљЕФФиЃП
ROCЧњЯпЯТЗНЕФЯргІУцЛ§ЪЧ0.8ЃЌЫќИњЕкЖўИіГЩЗжЕФНсЙћКмЯрНќЁЃвЛИіЛљгкЪ§ОнЪгОѕЛЏЬНЫїЕФМђЕЅзЊЛЛПЩФмЛсгыУЛгаЦЋВюЕФОбщЫуЗЈаЇЙћЯрЕБЁЃ
етаЉЪ§ОнРДздгкHillЕШШЫЕФЯИАћЗжИюЪЕбщЃЌдЄВтвђзгAЪЧЁАгЩа§зЊЕУЕНЕФЕШаЇдВжБОЖЕФЧђЬхБэУцЁБЃЈБъМЧЮЊEqSphereAreaCh1ЃЉЃЌдЄВтвђзгBЪЧЯИАћКЫЕФжмГЄЃЈPerimCh1ЃЉЁЃвЛИіИпФкКЩИбЁЕФзЈМвЃЌПЩФмЛсздШЛЖјШЛЕФВЩгУетСНжжЯИАћЬиеїЕФБШТЪЃЌвђЮЊЫќЛсДјРДПЦбЇвтвхЩЯСМКУЕФаЇЙћЃЈЮвВЂВЛЪЧФЧИіШЫЃЉЁЃдкетвЛЮЪЬтЕФЗЖЮЇФкЃЌЫќУЧЕФжБОѕгІИУЧ§ЖЏЬиеїЙЄГЬДІРэЁЃ
ШЛЖјЃЌдкБЃжЄжюШчPCAЫуЗЈаЇФмЪБЃЌЛњЦїЛсвђДЫЪмвцЁЃзмЕФРДЫЕЃЌетаЉЪ§ОнжагаНќ60ИідЄВтвђзгЃЌЫќУЧЕФЬиеїКЭEqSphereAreaCh1ЯрНќЁЃЮвЕФИіШЫАЎКУЪЧЁАЛљгкЙВЩњОиеѓЯёЫиПеМфХХСаЕФHaralick
НсЙЙВтСПЁБЁЃЮЊДЫбаОПСЫвЛЖЮЪБМфЁЃЮЪЬтЕФЙиМќЪЧЃЌОГЃгаЬЋЖрЕФЬиеїашвЊЩшМЦЃЌЖјЧвЫќУЧКмПЩФмдквЛПЊЪМОЭКмВЛжБЙлЁЃ
ЬиеїЬсШЁЕФСэвЛЗНУцЙиЯЕЕНЯрЙиадЁЃдкЬиЖЈЪ§ОнМЏЩЯЕФдЄВтвђзгжЎМфЭљЭљгазХИпЖШЯрЙиадЃЌетЪЧКмКУРэНтЕФЁЃБШШчЃЌгаВЛЭЌЕФЗНЗЈРДСПЛЏЯИАћЕФРыаФТЪЃЈБШШчРЩьГЬЖШЃЉЁЃДЫЭтЃЌЯИАћКЫЕФДѓаЁгыЯИАћећЬхДѓаЁЯрЙиЕШЕШЁЃPCAПЩвдЯджјЕиЛКНтЯрЙиадЕФаЇЙћЁЃЪжЖЏВЩгУЖрдЄВтвђзгБШР§ЕФзіЗЈЫЦКѕПЩФмВЛЬЋгааЇЃЌЖјЧвЛсЛЈЗбИќЖрЕФЪБМфЁЃ
ШЅФъЃЌдкЮвжЇГжЕФвЛИіR&DаЁзщжаЃЌзЈзЂгкЦЋВюЗжЮіЃЈМДНЈСЂЮвУЧдЄЯШжЊЕРЕФФЃаЭЃЉКЭзЈзЂгкЗЧЦЋВюЗжЮіЃЈМДШУЛњЦїШЅбАевзюгХФЃаЭЃЉЕФПЦбЇМвжЎМфДцдкзХељвщЁЃЮвЕФЙлЕуДІгкетСНепжЎМфЃЌШЯЮЊЫќУЧжЎМфДцдквЛаЉНЛМЏЁЃвЛЕЉЭкОђЭъБЯЃЌЛњЦїПЩвдНЋаТЕФЁЂгаШЄЕФЬиеїДђЩЯЁАвбжЊЪТЮяЁБЕФБъЧЉЃЌВЂАбЫќУЧзїЮЊжЊЪЖРДЪЙгУЁЃ
|









