| БрМЭЦМі: |
БОЮФРДздгкcloud.tencent.comЃЌзїепвдЧГЯдвзЖЎЕФгябдКЭЧхЮњЕФЪОР§КЭДњТыНЬФуДгЭЗПЊЪМзпЙ§вЛИіЛњЦїбЇЯАжЎТУЃЌВЂЧвИНЯъЯИЕФДњТыЃЌДѓМвПЩвдЪеВиКЭбЇЯАЁЃ |
|
дкЭјЩЯевЕНСЫУРЭХвЛЮЛНаИЖЧчДЈЭЌбЇаЉЕФpptЃЌРяУцгавЛЗљУшЪігУЛЇЬиеїЙЄГЬЕФЭМЃЌИаОѕзмНсЕУЛЙЪЧБШНЯЕНЮЛЕФЁЃЯждкАбЭМЦЌЬљГіРДЃК
етеХЭМНЋгУЛЇЬиеїЙЄГЬРяЕФДѓУцЛљБОЖМФвРЈСЫЁЃвђЮЊpptБОЩэзіЕУБШНЯМђЕЅЃЌЯждкЮвУЧЪдЭМеыЖдЭМРяЕФУПвЛЯюЃЌНсКЯОпЬхЕФвЕЮёГЁОАЃЌзіИіБШНЯЯъЯИЕФЗжЮіЁЃ
1.дЪМЪ§ОнЬсШЁ
дзїепЛЭМЕФЪБКђНЋЕквЛЯюУќУћЮЊЬиеїЬсШЁЃЌЮвОѕЕУзїепЯыБэДяЕФБОвтгІИУЪЧДгФФЛёЕУЯрЙиЪ§ОнЃЌЫљвдНадЪМЪ§ОнЬсШЁПЩФмИќЮЊКЯЪЪвЛаЉЁЃ
1.вЕЮёlogs
етВПЗжЪ§ОнПЯЖЈЪЧЪЕМЪгІгУГЁОАЕФДѓЭЗЁЃжЛвЊЪЧИіITЙЋЫОЃЌУПМвПЯЖЈЖМгаздМКЕФШежОЛђепвЕЮёЪ§ОнЁЃЯёЕчЩЬЭјеОЕФЖЉЕЅЪ§ОнвЛАуЖМЪЧДцдкmysql/oracle/sqlserverЕШЪ§ОнПтжаЃЌгУЛЇфЏРРitem/searchЕШааЮЊЕФЪ§ОнвЛАуЖМгаЯргІЕФШежОНјааМЧТМЁЃФУЕНетаЉЪ§ОнжЎКѓОЭПЩвдНјааКѓајЕФЗжЮіЭкОђЖЏзїСЫЁЃ
2.webЙЋПЊЪ§ОнзЅШЁ
етВПЗжЪ§ОнОЭЪЧЭЈЙ§ХРГцзЅШЁЕФЪ§ОнСЫЃЌБШШчзюГЃМћЕФЫбЫїв§ЧцзЅШЁЭјеОФкШнгУгкЫїв§ЕФФЧаЉЫбЫїв§ЧцХРГцЁЃ
ПДЕНЙ§вЛаЉгаШЄЕФЪ§ОнЃК2013ФъРДздIncapsulaвЛЗнЛЅСЊЭјБЈИцЯдЪОЃЌФПЧАга61.5%ЕФЛЅСЊЭјСїСПВЛЪЧгЩШЫРрВњЩњЕФЃЌШчЙћФуЖСЕНСЫетЦЊЮФеТЃЌФуОЭЪЧФЧИіЩйЪ§ХЩЃЈШЫРрЃЉЁЃЛЛОфЛАЫЕЃЌЪЕМЪЩЯЛЅСЊЭјСїСПДѓВПЗжЖМЪЧХРГцВњЩњЕФЁЃЁЃЁЃ
е§вђЮЊЯждкХРГцвбОЗКРФГЩджЃЌЫљвдКмЖрЭјеОЯожЦХРГцЕФХРШЁЁЃЫљвдДѓМвЪЙгУХРГцЕФЪБКђЃЌвВОЁПЩФмЮФУїЪЙгУЃЌзівЛжЛЮФУїЕФХРГцЁЃЁЃЁЃ
http://blog.csdn.net/bitcarmanlee/article/details/51824080
етЪЧжЎЧАаДЙ§ЕФвЛИіМђЕЅЕФХРШЁємЪТАйПЦЖЮзгЕФХРГцЃЌЙЉДѓМвВЮПМЁЃ
3.ЕкШ§ЗНКЯзї
етВПЗжУЛгаЬЋЖрПЩЫЕЕФЁЃЕБздМКЪ§ОнВЛЙЛЕФЧщПіЯТЃЌПЩвдЭЈЙ§ФГаЉЧўЕРгыЦфЫћЙЋЫОЛђепзЈУХЕФЪ§ОнЙЋЫОКЯзїЃЌЛёЕУЯрЙиЪ§ОнЁЃР§ШчЙуИцЯЕЭГжаЃЌКмЖрЙЋЫОЖМЛсЪЙгУУыеыЛђепAdmasterжЎРрЕФЕкШ§ЗНМрВтЛњЙЙЕФЪ§ОнЁЃ
2.Ъ§ОнЧхЯД
ФУЕНдЪМЪ§ОнвдКѓЃЌЖддЪМЪ§ОнНјааЧхЯДЪБЗЧГЃживЊЕФВНжшЁЃвђЮЊЛёЕУЕФдЪМЪ§ОнРяУцгаЗЧГЃЖрЕФдрЪ§ОнЩѕжСДэЮѓЪ§ОнЃЌШчЙћВЛЖдетаЉЪ§ОнНјааДІРэЃЌЛсМЋДѓЕигАЯьзюКѓФЃаЭЕФаЇЙћЁЃЫљвдЪ§ОнЧхЯДЪБЗЧГЃживЊЕФвЛИіВНжшЁЃ
1.вьГЃжЕЗжЮіЙ§ТЫ
ЙЫУћЫМвхЃЌвьГЃжЕЗжЮіЙ§ТЫЪЧЗжЮіМьбщЪ§ОнжаЪЧЗёгаДэЮѓЪ§ОнЛђепВЛКЯРэЕФЪ§ОнЁЃШчЙћгаЃЌдђНЋетаЉЪ§ОнЬоГ§ЁЃГЃМћЕФвьГЃжЕЗжЮіЗНЗЈга;
1)МђЕЅЭГМЦСПЗжЮіЗНЗЈ
ПЩвдЖдБфСПзівЛИіУшЪіадЕФЭГМЦгыЗжЮіЃЌШЛКѓВщПДЪ§ОнЪЧЗёКЯРэЁЃР§ШчБШНЯГЃгУЕФЭГМЦСПАќРЈзюДѓжЕгызюаЁжЕЃЌШчЙћБфСПГЌЙ§СЫзюДѓжЕзюаЁжЕЕФЗЖЮЇЃЌФЧетИіжЕОЭЮЊвьГЃжЕЁЃР§ШчФъСфЪєадЃЌШчЙћФГШЫЬюаДЮЊ200Лђеп-1ЃЌетЯдШЛЖМЪЧЪєгквьГЃжЕЕФЗЖГыЁЃ
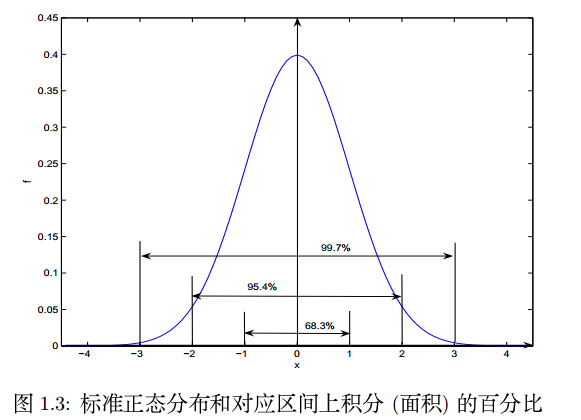
2)3ІвІвддђ
ШчЙћЪ§ОнЕФЗжВМЗўДгИпЫЙЗжВМ(е§ЬЌЗжВМ)ЃЌ3ддђЪЧжИЃЌВтСПжЕШчЙћгыЦНОљжЕЕФЦЋВюГЌЙ§3Ів3ІвЃЌМДЮЊвьГЃжЕЁЃРэТлвРОнШчЯТЃК
ЕБXЁЋN(0,1)ЃЌp{-1ЁмXЁм1}=0.683ЃЌp{-2ЁмXЁм2}=0.954ЃЌp{-3ЁмXЁм3}=0.997ЁЃФЧУДШчЙћЫцЛњБфСПXXЗўДге§ЬЌЗжВМЃЌДгІЬ-3ІвЕНІЬ+3ІвЕФЧјМфФкЃЌИХТЪУмЖШЧњЯпЯТЕФУцЛ§еМзмУцЛ§ЕФ99.7%ЁЃЛЛОфЛАЫЕЃЌЫцЛњБфСПXXТфдкІЬ-3ІвЕНІЬ+3ІвЕФЧјМфЭтЕФИХТЪжЛга0.3%ЁЃетОЭЪЧ3ІвІвддђЁЃ
дРэКмМђЕЅЃЌЕЋЪЧЗЧГЃЪЕМЪЃЌШ§ИіБъзМВювдЭтЕФЪ§ОнОЭПЩвдШЯЮЊЪЧвьГЃжЕСЫЁЃСэЭтЃЌЭЌбЇУЧЧыЖдвЛЯТШ§ИіЪ§зжУєИаЃК0.683,0.954,0.997ЁЃ
етВПЗжФкШнзюКѓИјвЛеХИпЫЙЗжВМЕФЧњЯпЭМ:
2.Ъ§ОнРраЭМьВщ
етвЛИіВНжшФмБмУтКѓајГіЯжЕФКмЖрЮЪЬтЁЃР§ШчФъСфетИіЪєадЃЌгІИУШЋЪЧЪ§жЕРраЭЁЃЕЋЪЧКмЖрЪБКђетИізжЖЮГіЯжСЫзжЗћДЎРраЭЕФжЕЃЌКмУїЯдетОЭЪЧвьГЃжЕЃЌашвЊНјааЯргІЕФДІРэЁЃБШШчИљОнЩэЗнжЄКХРДНјааМЦЫуЃЌЛђепИјИіЬиЪтЕФжЕ-99РДБъЪЖЕШЕШЁЃ
3.ЧхЯДЛЛааЗћжЦБэЗћПеИёЕШЬиЪтзжЗћ
ШчЙћдЪМЪ§ОнФГаЉзжЖЮжаДцдкЛЛааЗћПеИёжЦБэЗћЕШЬиЪтзжЗћЃЌОјДѓВПЗжЧщПіЯТЛсгАЯьКѓУцНјвЛВНЕФЗжЮіЁЃЫљвддкЪ§ОнЧхЯДНзЖЮЃЌИљОнвЕЮёашЧѓДІРэЕєетаЉЬиЪтзжЗћЪЧКмгаБивЊЕФЁЃР§ШчдкДѓВПЗжГЁОАжаЃЌЧхЯДЕєзжЗћДЎжаЕФЛЛааЗћЃЌЖМЪЧКмБивЊЕФЁЃ
3.Ъ§ОндЄДІРэ
дкдЭМжаЃЌзїепНЋетвЛВНУќУћЮЊжЕДІРэЃЌБэДяЕФвтЫМгІИУЪЧвЛжТЕФЁЃетвЛВНЕФДІРэЙ§ГЬЗЧГЃживЊЃЌЩцМАЕНЕФЕувВБШНЯЖрЃЌЮЊДѓМвбЁдёвЛаЉГЃМћЕФвЛвЛЕРРДЁЃ
1.Ъ§ОнЦНЛЌ
вђЮЊЯждкЛњЦїбЇЯАЕФжїСїЪЧЭГМЦЛњЦїбЇЯАЃЌМШШЛЪЧЭГМЦЃЌздШЛОЭРыВЛПЊИХТЪЕФМЦЫуЁЃР§ШчдкЖдЮФБОНјааЗжРрЪБЃЌгяСЯПтБЯОЙЪЧгаЯоЕФЁЃМйЩшw1w1,w2w2,w3w3УЛдкгяСЯПтжаГіЯжЙ§ЃЌФЧИљОнзюДѓЫЦШЛЙРМЦMLEЃЌетаЉДЪГіЯжЕФИХТЪЮЊ0ЁЃЕЋЪЧЪЕМЪЩЯетаЉДЪГіЯжЕФИХТЪПЯЖЈЪЧВЛЮЊ0ЕФЁЃЯёзюДѓЫЦШЛЙРМЦРяЩцМАЕНКмЖрИХТЪЕФСЌГЫМЦЫуЃЌШчЙћвЛИіИХТЪЮЊ0ЃЌОЭЛсЕМжТећЬхМЦЫуНсЙћЮЊ0ЁЃетЪБКђЃЌОЭашвЊЮвУЧЖдЪ§ОнНјааЦНЛЌСЫЁЃ
ЦНЛЌЕФЫуЗЈгаКмЖрЁЃзюМђЕЅЕФЦНЛЌЗНЪНЪєгкМг1ЦНЛЌСЫЃЌОЭЪЧИјУПжжЧщПіГіЯжЕФДЮЪ§ЖММгЩЯ1ЃЌетбљОЭБмУтСЫИХТЪЮЊ0ЕФЧщПіЁЃетжжЗНЪНМђЕЅДжБЉЃЌЪЕМЪЪЙгУЕФаЇЙћвЛАувВВЛЛсЬиБ№РэЯыЁЃЕБШЛЛЙгаGood-turningЦНЛЌЃЌЯпадВхжЕЦНЛЌЃЈLinear
Interpolation SmoothingЃЉЕШЦфЫћЫуЗЈЃЌИљОнОпЬхЕФвЕЮёГЁОАНјаабЁдёЁЃ
2.ЙщвЛЛЏ
ЙщвЛЛЏвВЪЧГЃМћЕФЪ§ОндЄДІРэВйзїЁЃ
3.РыЩЂЛЏ
РыЩЂЛЏЪЧАбСЌајаЭЕФЪ§ОнЗжЮЊШєИЩЖЮЃЌЪЧЪ§ОнЗжЮігыЪ§ОнЭкОђжаОГЃВЩгУЕФвЛжжЗНЗЈЁЃЖдЪ§ОнНјааРыЩЂЛЏЃЌзюДѓЕФКУДІОЭЪЧгааЉЫуЗЈжЛНгЪмРыЩЂаЭБфСПЁЃР§ШчОіВпЪїЃЌЦгЫиБДвЖЫЙЕШЫуЗЈЃЌВЛФмвдСЌајаЭБфСПЮЊЪфШыЁЃШчЙћЪфШыЪБСЌајаЭЪ§ОнЃЌБиаывЊЯШОЙ§РыЩЂЛЏДІРэЁЃ
ГЃМћЕФРыЩЂЛЏЗНЪНгаЕШОргыЕШЦЕРыЩЂЛЏЃЌЖМБШНЯШнвзРэНтЁЃЕШОрОЭЪЧНЋСЌајаЭЫцЛњБфСПЕФШЁжЕЗЖЮЇОљдШЛЎЮЊnЕШЗнЃЌУПЗнЕФМфОрЯрЕШЁЃР§ШчФъСфБОРДЪЧИіСЌајжЕЃЌгУЕШОрРыЩЂЛЏвдКѓЃЌ1-10ЃЌ10-20ЃЌ20-30ЃЌ30-40ЕШИїЛЎЮЊвЛзщЁЃЖјЕШЦЕдђЪЧАбЙлВьЕуОљЗжЮЊnЕШЗнЃЌУПЗнРяУцАќКЌЕФбљБОЯрЭЌЁЃР§Шчга1ЭђИібљБОЃЌНЋбљБОАДВЩбљЪБМфЫГађХХСаЃЌШЛКѓАДвЛЧЇИібљБОЮЊвЛзщЃЌНЋШЋВПЕФбљБОЗжЮЊЪЎЕШЗнЁЃ
ЕБШЛРыЩЂЛЏЃЌАќРЈЧАУцЕФЙщвЛЛЏЃЌЖМЪЧЛсгаИКУцаЇЙћЕФЃЌетИіИКУцаЇЙћОЭЪЧЛсДјРДаХЯЂЕФЫ№ЪЇЁЃБШШчБОРДЮвУЧБОРДгаЯъОЁЕФФъСфЪ§ОнЃЌдкОіВпЪїЫуЗЈЛђепБДвЖЫЙЫуЗЈжаЮЊСЫЫуЗЈЕФашвЊЃЌВЛЕУвбНЋФъСфБфЮЊЖљЭЏЧрЩйФъзГФъРЯФъетбљЕФРыЩЂБфСПЃЌаХЯЂПЯЖЈОЭВЛШчОпЬхЕФФъСфДѓаЁФЧУДзМШЗгыЯъОЁЁЃЫљвддкЪЙгУЙщвЛЛЏЃЌРыЩЂЛЏЕШЪ§ОнДІРэЗжЮіЪжЖЮЪБЃЌвЊНсКЯОпЬхЕФЪЕМЪЧщПіЃЌНїЩїЪЙгУЁЃ
4.dummy coding
етВПЗжЪЕМЪжаЮвУЛдѕУДЪЙгУЙ§ЃЌКѓајевЯрЙизЪСЯдйНјааВЙГфЁЃ
5.ШБЪЇжЕЬюГф
Ъ§ОнжаФГаЉзжЖЮШБЪЇЪЧЪ§ОнЗжЮіЭкОђжаЗЧГЃЭЗЬлЕФвЛИіЮЪЬтЁЃЯжЪЕЪРНчжаЕФЪ§ОнЭљЭљЗЧГЃдгТвЗЧГЃдрЃЌдЪМЪ§ОнжаФГИізжЖЮЛђепФГаЉзжЖЮШБЪЇЪЧЗЧГЃГЃМћЕФЯжЯѓЁЃЕЋЪЧОЁЙмЪ§ОнгаШБЪЇЃЌЩњЛюЛЙвЊМЬајЃЌЙЄзїЛЙЕУМЬајЁЃУцЖдетжжЧщПіЃЌИУдѕбљМЬајФиЃП
ЗНЗЈвЛЃКЖЊЦњ
зюМђЕЅЕФЗНЪНЃЌШчЙћЗЂЯжЪ§ОнгаШБЪЇЃЌжБНгЩОГ§етИізжЖЮЛђепНЋећИібљБОЖЊЦњЁЃШчЙћДѓВПЗжбљБОЕФФГИізжЖЮЖМШБЪЇЃЌФЧУДКмУїЯдетИізжЖЮОЭЪЧВЛПЩгУзДЬЌЁЃШчЙћФГЬѕбљБОЕФДѓВПЗжзжЖЮЖМШБЪЇЃЌФЧУДКмУїЯдетИібљБООЭЪЧВЛПЩгУзДЬЌЁЃетжжДІРэЗНЪНМђЕЅДжБЉЃЌаЇТЪИпЃЌЕЋЪЧКмУїЯдЪЪгУЗЖЮЇгаЯоЃЌжЛЪЪКЯЪ§ОнШБЪЇНЯЩйЕФЧщПіЁЃШчЙћФГИіЬиеїЬиБ№живЊЃЌЪ§ОнШБЪЇЧщПіЛЙЬиБ№бЯжиЃЌФЧУДУРБ№ЕФАьЗЈЃЌРЯРЯЪЕЪЕжиаТВЩМЏЪ§ОнАЩЁЃ
ЗНЗЈЖўЃКЭГМЦжЕЬюГф
ШчЙћФГИіЪєадШБЪЇЃЌЬиБ№ЪЧЪ§жЕРраЭЕФЪєадЃЌПЩвдИљОнЫљгабљБОЙигкетЮЌЪєадЕФЭГМЦжЕЬюГфЃЌГЃМћЕФгаЦНОљжЕЁЂжажЕЁЂЗжЮЛЪ§ЁЂжкЪ§ЁЂЫцЛњжЕЕШЁЃетжжЗНЪНФбЖШвВВЛДѓЃЌаЇЙћвЛАуЁЃзюДѓЕФИБзїгУОЭЪЧШЫЮЊДјРДСЫВЛЩйдыЩљЁЃ
ЗНЗЈШ§ЃКдЄВтЬюГф
гУЦфЫћБфСПзідЄВтФЃаЭРДдЄВтШБЪЇжЕЃЌаЇЙћвЛАуБШЭГМЦжЕЬюГфвЊКУвЛаЉЁЃЕЋЪЧДЫЗНЗЈгавЛИіИљБОШБЯнЃЌШчЙћЦфЫћБфСПКЭШБЪЇБфСПЮоЙиЃЌдђдЄВтЕФНсЙћЮовтвхЁЃШчЙћдЄВтНсЙћЯрЕБзМШЗЃЌдђгжЫЕУїетИіБфСПЪЧУЛБивЊМгШыНЈФЃЕФЁЃвЛАуЧщПіЯТЃЌНщгкСНепжЎМфЁЃ
ЗНЗЈЫФЃКНЋБфСПгГЩфЕНИпЮЌПеМф
БШШчадБ№ЃЌгаФаЁЂХЎЁЂШБЪЇШ§жжЧщПіЃЌдђгГЩфГЩ3ИіБфСПЃКЪЧЗёФаЁЂЪЧЗёХЎЁЂЪЧЗёШБЪЇЁЃСЌајаЭБфСПвВПЩвдетбљДІРэЁЃБШШчGoogleЁЂАйЖШЕФCTRдЄЙРФЃаЭЃЌдЄДІРэЪБЛсАбЫљгаБфСПЖМетбљДІРэЃЌДяЕНМИвкЮЌЁЃетбљзіЕФКУДІЪЧЭъећБЃСєСЫдЪМЪ§ОнЕФШЋВПаХЯЂЁЂВЛгУПМТЧШБЪЇжЕЁЂВЛгУПМТЧЯпадВЛПЩЗжжЎРрЕФЮЪЬтЁЃШБЕуЪЧМЦЫуСПДѓДѓЬсЩ§ЁЃЖјЧвжЛгадкбљБОСПЗЧГЃДѓЕФЪБКђаЇЙћВХКУЃЌЗёдђЛсвђЮЊЙ§гкЯЁЪшЃЌаЇЙћКмВюЁЃ(БОаЁНсФкШнРДзджЊКѕ)
6.ЗжДЪ tf/idf
бЯИёвтвхЩЯЫЕЃЌЗжДЪЪєгкNLPЕФЗЖГыЁЃМШШЛдЭМжаЬсЕНСЫЗжДЪtf/idfЃЌЮвУЧОЭМђЕЅНщЩмвЛЯТЁЃ
TF-IDFШЋГЦЮЊterm frequencyЈCinverse document frequencyЁЃTFОЭЪЧterm
frequencyЕФЫѕаДЃЌвтЮЊДЪЦЕЁЃIDFдђЪЧinverse document frequencyЕФЫѕаДЃЌвтЮЊФцЮФЕЕЦЕТЪЁЃtf-idfЭЈГЃгУРДЬсШЁЙиМќДЪЁЃБШШчЃЌЖдвЛИіЮФеТЬсШЁЙиМќДЪзїЮЊЫбЫїДЪЃЌОЭПЩвдВЩгУTF-IDFЫуЗЈЁЃ
вЊевГівЛЦЊЮФеТжаЕФЙиМќДЪЃЌЭЈГЃЕФЫМТЗОЭЪЧЃЌОЭЪЧевЕНГіЯжДЮЪ§зюЖрЕФДЪЁЃШчЙћФГИіДЪКмживЊЃЌЫќгІИУдкетЦЊЮФеТжаЖрДЮГіЯжЁЃгкЪЧЃЌЮвУЧНјааДЪЦЕTFЭГМЦЁЃЕЋЪЧЃЌдкжаЮФЮФЯзРяЃЌЕФЕиЕУСЫЕШРрЫЦЕФДЪЛуГіЯжЕФЦЕТЪвЛЖЈЪЧзюИпЕФЃЌЖјЧветРрДЪУЛЪВУДЪЕМЪЕФКЌвхЃЌЮвУЧОЭНаЫћЭЃгУДЪЃЌвЛАугіЕНЭЃгУДЪОЭНЋЫћШгЕєЁЃ
ШгЕєЭЃгУДЪвдКѓЃЌЮвУЧвВВЛФмМђЕЅЕиШЯЮЊГіЯжЦЕТЪзюИпЕФДЪОЭЪЧЮвУЧЫљашвЊЕФЙиМќзжЁЃШчЙћвЛИіДЪКмЩйМћЃЌЕЋЪЧЫќдкФГИіЮФеТжаЗДИДГіЯжЖрДЮЃЌФЧУДПЩвдШЯЮЊетИіДЪЗДгІСЫетИіЮФеТЕФЬиадЃЌПЩвдАбЫќзїЮЊЙиМќДЪЁЃдкаХЯЂМьЫїжаЃЌетИіШЈжиЗЧГЃживЊЃЌЫќОіЖЈСЫЙиМќДЪЕФживЊЖШЃЌетИіШЈжиНазіФцЮФЕЕЦЕТЪЃЌЫќЕФДѓаЁгывЛИіДЪЕФГЃМћГЬЖШГЩЗДБШЁЃ
дкжЊЕРСЫДЪЦЕКЭШЈжижЎКѓЃЌСНепЯрГЫЃЌОЭЕУЕНвЛИіДЪЕФTF-IDFжЕЃЌФГИіДЪЖдЮФеТЕФживЊаддНИпЃЌЫќЕФTF-IDFжЕОЭдНДѓЁЃЫљвдЃЌХХдкзюЧАУцЕФМИИіДЪЃЌОЭЪЧетЦЊЮФеТЕФЙиМќДЪЁЃ
ЗжДЪгааэЖрПЊдДЕФЙЄОпАќПЩвдЪЙгУЃЌР§ШчжаЮФЗжДЪПЩвдЪЙгУНсАЭЗжДЪЁЃ
4.ЬиеїбЁдё
жегкЕНЮвУЧзюЙиМќЕФЬиеїбЁдёВПЗжСЫЁЃМЧЕУЮвПДЕНЙ§етУДвЛИіЙлЕуЃКВЛТлЪВУДЫуЗЈгыФЃаЭЃЌаЇЙћЕФЩЯЯоЖМЪЧгЩЬиеїРДОіЖЈЕФЃЌЖјВЛЭЌЕФЫуЗЈгыФЃаЭжЛЪЧВЛЖЯЕиШЅБЦНќетИіЩЯЯоЖјвбЁЃЮвздМКЖдетИіЙлЕувВЩювдЮЊШЛЁЃЬиеїбЁдёЕФживЊадгЩДЫОЭПЩМћвЛАпЁЃ
ЬиеїбЁдёЫуЗЈПЩвдБЛЪгЮЊЫбЫїММЪѕКЭЦРМлжИБъЕФНсКЯЁЃЧАепЬсЙЉКђбЁЕФаТЬиеїзгМЏЃЌКѓепЮЊВЛЭЌЕФЬиеїзгМЏДђЗжЁЃ
зюМђЕЅЕФЫуЗЈЪЧВтЪдУПИіЬиеїзгМЏЃЌевЕНОПОЙФФИізгМЏЕФДэЮѓТЪзюЕЭЁЃетжжЫуЗЈашвЊЧюОйЫбЫїПеМфЃЌФбвдЫуЭъЫљгаЕФЬиеїМЏЃЌжЛФмКИЧКмЩйвЛВПЗжЬиеїзгМЏЁЃ
бЁдёКЮжжЦРМлжИБъКмДѓГЬЖШЩЯгАЯьСЫЫуЗЈЁЃЖјЧвЃЌЭЈЙ§бЁдёВЛЭЌЕФЦРМлжИБъЃЌПЩвдАЩЬиеїбЁдёЫуЗЈЗжЮЊШ§РрЃКАќзАРр(wrapper)ЁЂЙ§ТЫРр(filter)КЭЧЖШыРр(embedded)ЗНЗЈЁЃ(БОЖЮУшЪіРДздwikiАйПЦ)
1.embedded ЧЖШыРрЗНЗЈ
ЧЖШыРрЫуЗЈдкФЃаЭНЈСЂЕФЪБКђЃЌЛсПМТЧФФаЉЬиеїЖдгкФЃаЭЕФЙБЯззюДѓЁЃзюЕфаЭЕФМДОіВпЪїЯЕСаЫуЗЈЃЌШчID3ЫуЗЈЁЂC4.5ЫуЗЈвдМАCARTЕШЁЃОіВпЪїЫуЗЈдкЪїЩњГЩЙ§ГЬжаЃЌУПДЮЛибЁдёвЛИіЬиеїЁЃетИіЬиеїЛсНЋдбљБОМЏЛЎЗжГЩНЯаЁЕФзгМЏЃЌЖјбЁдёЬиеїЕФвРОнЪЧЛЎЗжКѓзгНкЕуЕФДПЖШЃЌЛЎЗжКѓзгНкЕудНДПЃЌдђЫЕУїЛЎЗжаЇЙћдНКУЁЃгЩДЫПЩМћОіВпЪїЩњГЩЕФЙ§ГЬвВОЭЪЧЬиеїбЁдёЕФЙ§ГЬЁЃ
СэЭтвЛИіБъзМЕФЧЖШыРрЗНЗЈЪЧе§дђЕФЗНЪНЃЌР§ШчЮвУЧЗДИДЬсЕНL1е§дђЕФЗНЪНПЩвдгУРДзіЬиеїбЁдёЁЃL1е§дђжаЃЌзюКѓЯЕЪ§ЮЊ0ЕФЬиеїЫЕУїЖдФЃаЭЙБЯзКмаЁЃЌЮвУЧБЃСєЯЕЪ§ВЛЮЊ0ЕФЬиеїМДПЩЃЌетбљОЭДяЕНСЫЬиеїбЁдёЕФФПЕФЁЃ
2.wrapper АќзАРрЗНЗЈ
ЗтзАЪНЬиеїбЁдёЪЧРћгУбЇЯАЫуЗЈЕФадФмРДЦРМлЬиеїзгМЏЕФгХСгЁЃвђДЫЃЌЖдгквЛИіД§ЦРМлЕФЬиеїзгМЏЃЌWrapperЗНЗЈашвЊбЕСЗвЛИіЗжРрЦїЃЌИљОнЗжРрЦїЕФадФмЖдИУЬиеїзгМЏНјааЦРМлЁЃWrapperЗНЗЈжагУвдЦРМлЬиеїЕФбЇЯАЫуЗЈЪЧЖржжЖрбљЕФЃЌР§ШчОіВпЪїЁЂЩёОЭјТчЁЂБДвЖЫЙЗжРрЦїЁЂНќСкЗЈвдМАжЇГжЯђСПЛњЕШЕШЁЃ
ЯрЖдгкFilterЗНЗЈЃЌWrapperЗНЗЈевЕНЕФЬиеїзгМЏЗжРрадФмЭЈГЃИќКУЁЃЕЋЪЧвђЮЊWrapperЗНЗЈбЁГіЕФЬиеїЭЈгУадВЛЧПЃЌЕБИФБфбЇЯАЫуЗЈЪБЃЌашвЊеыЖдИУбЇЯАЫуЗЈжиаТНјааЬиеїбЁдёЃЛгЩгкУПДЮЖдзгМЏЕФЦРМлЖМвЊНјааЗжРрЦїЕФбЕСЗКЭВтЪдЃЌЫљвдЫуЗЈМЦЫуИДдгЖШКмИпЃЌгШЦфЖдгкДѓЙцФЃЪ§ОнМЏРДЫЕЃЌЫуЗЈЕФжДааЪБМфКмГЄЁЃ(БШВПЗжФкШнРДздjasonЕФblog)
3.filter Й§ТЫРрЗНЗЈ
Й§ТЫРрЗНЗЈЪЧЪЕМЪжаЪЙгУзюЙуЗКзюЦЕЗБЕФЬиеїбЁдёЗНЗЈЁЃЙ§ТЫЬиеїбЁдёЗНЗЈдЫгУЭГМЦЗНЗЈНЋвЛИіЭГМЦжЕЗжХфИјУПИіЬиеїЃЌетаЉЬиеїАДееЗжЪ§ХХађЃЌШЛКѓОіЖЈЪЧБЛБЃСєЛЙЪЧДгЪ§ОнМЏжаЩОГ§ЁЃ
ПЈЗНвВЪЧГЃМћЕФгУгкзіЬиеїбЁдёЕФЗНЪНЁЃ
СэЭтfisher scoresвВЪЧfilterЙ§ТЫРржаГЃМћЕФжИБъЁЃ
5.ЬиеїзщКЯ
бЯИёвтвхЩЯРДЫЕЃЌЬиеїзщКЯвВЪєгкЬиеїбЁдёЕФвЛВПЗжЁЃШЁЙЄвЕНчзюГЃМћЕФLRФЃаЭЮЊР§ЃЌLRФЃаЭБОжЪЩЯЪЧЙувхЯпадФЃаЭ(ЖдЪ§ЯпадФЃаЭ)ЃЌЪЕЯжМђЕЅЖјЧвШнвзВЂааЃЌМЦЫуЫйЖШвВБШНЯПьЃЌЭЌЪБЪЙгУЕФЬиеїБШНЯКУНтЪЭЃЌдЄВтЪфГіЕФИХТЪдк0гы1жЎМфвВЗЧГЃЗНБувзгУЁЃЕЋЪЧЃЌгывЛАуФЃаЭЕФШнвзoverfittingВЛвЛбљЃЌLRФЃаЭШДЪЧвЛИіunderfittingФЃаЭЃЌвђЮЊLRФЃаЭБОЩэВЛЙЛИДдгЃЌЩѕжСПЩвдЫЕЯрЕБМђЕЅЁЃЖјЯжЪЕжаКмЖрЮЪЬтВЛНіНіЪЧЯпадЙиЯЕЃЌИќЖрЪЧИДдгЕФЗЧЯпадЙиЯЕЁЃетИіЪБКђЃЌЮвУЧОЭЯЃЭћЭЈЙ§ЬиеїзщКЯЕФЗНЪНЃЌРДУшЪіетжжИќЮЊИДдгЕФЗЧЯпадЙиЯЕЁЃ
ФПЧАГЃМћЕФгУгкЬиеїзщКЯЕФЗНЗЈЃК
1.GBDT
2014ФъfacebookЗЂБэСЫвЛЦЊpaperЃЌНВЕФОЭЪЧGBDT+LRгУгкЬиеїзщКЯЃЌЗЂБэвдКѓв§Ц№БШНЯДѓЕФЗДЯьЁЃЮФеТУћЮЊPractical
Lessons from Predicting Clicks on Ads at FacebookЃЌгааЫШЄЕФЭЌбЇУЧПЩвдgoogleвЛАбЁЃ
2.FM
FMЫуЗЈвВЪЧгУгкЖдЬиеїНјаазщКЯЕФвЛжжЗНЪНЁЃ
6.Ъ§ОнНЕЮЌ
НЕЮЌЃЌгжБЛГЦЮЊЮЌЖШЙцдМЁЃЯжЪЕЪРНчжаЕУЕНЕФЪ§ОнвЛАуЖМгаШпгрЃЌвЊУДгавЛаЉЪЧЮогУаХЯЂЃЌвЊУДгавЛаЉЪЧжиИДЕФаХЯЂЃЌЮвУЧеыЖдетВПЗжШпгрЪ§ОнНјаавЛаЉДІРэжЎКѓЃЌПЩвдУїЯдМѕЩйЪ§ОнЕФДѓаЁгыЮЌЖШЕФЖрЩйЁЃИјДѓМвОйИіКмМђЕЅЕФЪЕМЪГЁОАЃЌгУiphoneХФГіРДЕФдЪМееЦЌвЛАуДѓаЁЖМЮЊ2-3MЁЃЕЋЪЧЮвУЧЭЈЙ§qqЛђепЮЂаХЕШЙЄОпДЋЪфетаЉееЦЌЕФЪБКђЃЌЗЂЯжДЋЪфГЩЙІвдКѓетаЉееЦЌЕФДѓаЁОЭБфГЩжЛгаМИЪЎKBСЫЃЌетОЭЪЧвђЮЊдкДЋЪфееЦЌЕФЙ§ГЬжаЃЌЪТЯШЛсЖдееЦЌНјаабЙЫѕЃЌбЙЫѕЭъБЯвдКѓдйНјааДЋЫЭвдНкЪЁБІЙѓЕФДјПэзЪдДЁЃЖјетИіЪ§ОнбЙЫѕЕФЙ§ГЬЃЌЦфЪЕОЭЕШЭЌгкНЕЮЌЕФЙ§ГЬЁЃ
КмУїЯдЪ§ОнОЙ§НЕЮЌДІРэвдКѓЃЌЛсДѓДѓНкдМЪ§ОнДцДЂПеМфЁЃЭЌЪБЃЌвВЛсДѓДѓНЯЩйЪ§ОнЕФКѓајДІРэМЦЫуЪБМфЁЃвђДЫЃЌЪ§ОнНЕЮЌММЪѕЛђепЫЕЪ§ОнбЙЫѕММЪѕЃЌдкЪЕМЪжагаЗЧГЃЙуЗКЕФгІгУЁЃ
вЛАуРДЫЕЃЌЪ§ОнНЕЮЌПЩвдДгСНИіЗНУцРДЪЕЪЉЁЃБШНЯМђЕЅЕФвЛжжЗНЪНЪЧЬсШЁЬиеїзгМЏЃЌШЛКѓгУетВПЗжзгМЏРДБэЪОдгаЪ§ОнЁЃР§ШчЭМЯёДІРэРяУцЃЌШчЙћвЛЗљ128*128ЕФЭМЦЌЃЌжЛгажааФ32*32ЕФВПЗжгаЗЧ0жЕЃЌФЧУДОЭжЛШЁжааФ32*32ЕФВПЗжЁЃСэЭтвЛжжЪЧЭЈЙ§Япад/ЗЧЯпадЕФЗНЪННЋдРДИпЮЌПеМфБфЛЛЕНвЛИіаТЕФПеМфЃЌетИіаТЕФПеМфЮЌЖШБШдРДЕФИпЮЌПеМфвЊаЁЃЌетбљОЭДяЕНСЫНЕЮЌЕФФПЕФЁЃвЛАуДѓМвЬжТлЕФЫљЮННЕЮЌММЪѕЃЌЖМЪЧКѓУцвЛжжЁЃ
1.жїГЩЗжЗжЮі Principal Component Analysis(PCA)
PCAЪЧзюГЃгУЕФЯпадНЕЮЌЗНЗЈЁЃPCAЕФРэТлШЯЮЊЃЌЬиеїЕФжїЗНЯђЃЌЪЧЬиеїЗљЖШБфЛЏзюДѓЕФЗНЯђЃЌМШИФЮЌЖШЩЯЪ§ОнЕФЗНВюзюДѓЁЃетбљОЙ§PCAвдКѓЃЌОЭПЩвдЪЙгУНЯаЁЕФЪ§ОнЮЌЖШЃЌБЃСєзЁНЯЖрЕФдЪ§ОнЕуЕФЬиадЃЌДгЖјДяЕННЕЮЌЕФФПЕФЁЃ
PCAЕФОпЬхЙ§ГЬЃЌвдКѓЛсаДЯрЙиЕФЮФеТзЈУХНщЩмЁЃ
2.ЦцвьжЕЗжНт Singular Value Decomposition(SVD)
SVDвВЪЧЪЕМЪжаЪЙгУЗЧГЃЙуЗКЕФвЛжжЗНЗЈЁЃ
3.ЯпадХаБ№ЗжЮі Linear Discriminant Analysis(LDA)
вдЩЯФкШнЃЌЛљБООЭКИЧСЫгУЛЇЬиеїЙЄГЬЕФИїИіДѓЕФЗНУцЁЃЕБШЛФГИіЪЕМЪЯюФПжаЃЌВЛПЩФмЩЯУцЕФЫљгаЗНЗЈЖМгУЕНЁЃЛЙЪЧЕУНсКЯЪ§ОнЕФОпЬхЧщПігывЕЮёашЧѓЃЌбЁдёзюЪЪКЯздМКЕФЗНЗЈЃЁ
|









