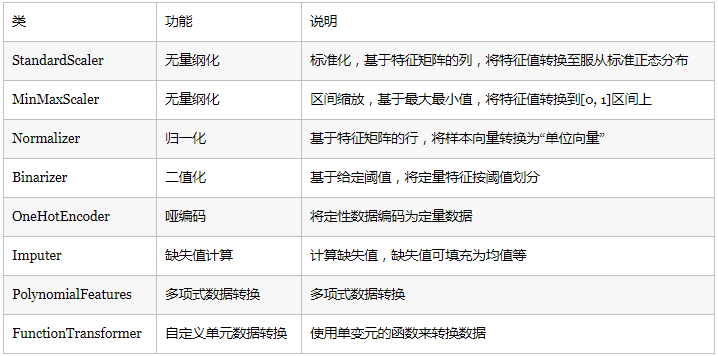
| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжаЪЙгУsklearnжаЕФIRISЃЈ№АЮВЛЈЃЉЪ§ОнМЏРДЖдЬиеїДІРэЙІФмНјааЫЕУїЁЃ
|
|
вЛЁЂЬиеїЙЄГЬЪЧЪВУД гаетУДвЛОфЛАдквЕНчЙуЗКСїДЋЃКЪ§ОнКЭЬиеїОіЖЈСЫЛњЦїбЇЯАЕФЩЯЯоЃЌЖјФЃаЭКЭЫуЗЈжЛЪЧБЦНќетИіЩЯЯоЖјвбЁЃФЧЬиеїЙЄГЬЕНЕзЪЧЪВУДФиЃПЙЫУћЫМвхЃЌЦфБОжЪЪЧвЛЯюЙЄГЬЛюЖЏЃЌФПЕФЪЧзюДѓЯоЖШЕиДгдЪМЪ§ОнжаЬсШЁЬиеївдЙЉЫуЗЈКЭФЃаЭЪЙгУЁЃЭЈЙ§змНсКЭЙщФЩЃЌШЫУЧШЯЮЊЬиеїЙЄГЬАќРЈвдЯТЗНУцЃК
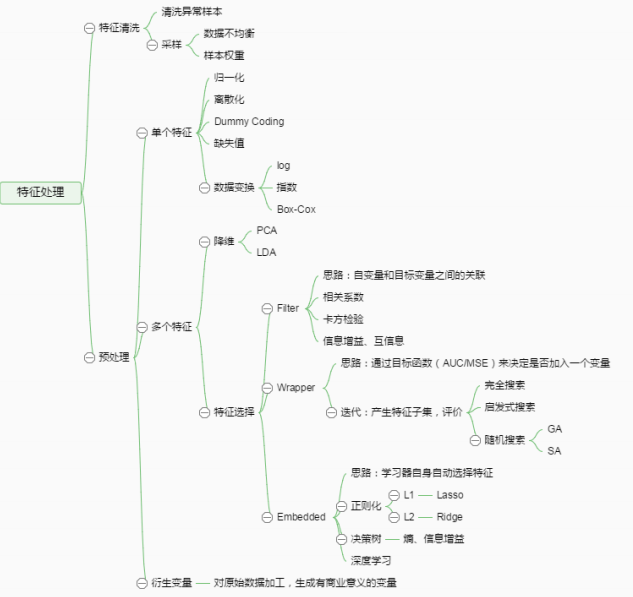
ЬиеїДІРэЪЧЬиеїЙЄГЬЕФКЫаФВПЗжЃЌsklearnЬсЙЉСЫНЯЮЊЭъећЕФЬиеїДІРэЗНЗЈЃЌАќРЈЪ§ОндЄДІРэЃЌЬиеїбЁдёЃЌНЕЮЌЕШЁЃЪзДЮНгДЅЕНsklearnЃЌЭЈГЃЛсБЛЦфЗсИЛЧвЗНБуЕФЫуЗЈФЃаЭПтЮќв§ЃЌЕЋЪЧетРяНщЩмЕФЬиеїДІРэПтвВЪЎЗжЧПДѓЃЁ
БОЮФжаЪЙгУsklearnжаЕФIRISЃЈ№АЮВЛЈЃЉЪ§ОнМЏРДЖдЬиеїДІРэЙІФмНјааЫЕУїЁЃIRISЪ§ОнМЏгЩFisherдк1936ФъећРэЃЌАќКЌ4ИіЬиеїЃЈSepal.LengthЃЈЛЈнрГЄЖШЃЉЁЂSepal.WidthЃЈЛЈнрПэЖШЃЉЁЂPetal.LengthЃЈЛЈАъГЄЖШЃЉЁЂPetal.WidthЃЈЛЈАъПэЖШЃЉЃЉЃЌЬиеїжЕЖМЮЊе§ИЁЕуЪ§ЃЌЕЅЮЛЮЊРхУзЁЃФПБъжЕЮЊ№АЮВЛЈЕФЗжРрЃЈIris
SetosaЃЈЩН№АЮВЃЉЁЂIris VersicolourЃЈдгЩЋ№АЮВЃЉЃЌIris VirginicaЃЈЮЌМЊФсбЧ№АЮВЃЉЃЉЁЃЕМШыIRISЪ§ОнМЏЕФДњТыШчЯТЃК
| from
sklearn.datasets import load_iris
#ЕМШыIRISЪ§ОнМЏ
iris = load_iris()
#ЬиеїОиеѓ
iris.data
#ФПБъЯђСП
iris.target |
2 Ъ§ОндЄДІРэ ЭЈЙ§ЬиеїЬсШЁЃЌЮвУЧФмЕУЕНЮДОДІРэЕФЬиеїЃЌетЪБЕФЬиеїПЩФмгавдЯТЮЪЬтЃК
1ЁЂВЛЪєгкЭЌвЛСПИйЃКМДЬиеїЕФЙцИёВЛвЛбљЃЌВЛФмЙЛЗХдквЛЦ№БШНЯЁЃЮоСПИйЛЏПЩвдНтОіетвЛЮЪЬтЁЃ
2ЁЂаХЯЂШпгрЃКЖдгкФГаЉЖЈСПЬиеїЃЌЦфАќКЌЕФгааЇаХЯЂЮЊЧјМфЛЎЗжЃЌР§ШчбЇЯАГЩМЈЃЌМйШєжЛЙиаФЁАМАИёЁБЛђВЛЁАМАИёЁБЃЌФЧУДашвЊНЋЖЈСПЕФПМЗжЃЌзЊЛЛГЩЁА1ЁБКЭЁА0ЁББэЪОМАИёКЭЮДМАИёЁЃЖўжЕЛЏПЩвдНтОіетвЛЮЪЬтЁЃ
3ЁЂЖЈадЬиеїВЛФмжБНгЪЙгУЃКФГаЉЛњЦїбЇЯАЫуЗЈКЭФЃаЭжЛФмНгЪмЖЈСПЬиеїЕФЪфШыЃЌФЧУДашвЊНЋЖЈадЬиеїзЊЛЛЮЊЖЈСПЬиеїЁЃзюМђЕЅЕФЗНЪНЪЧЮЊУПвЛжжЖЈаджЕжИЖЈвЛИіЖЈСПжЕЃЌЕЋЪЧетжжЗНЪНЙ§гкСщЛюЃЌдіМгСЫЕїВЮЕФЙЄзїЁЃЭЈГЃЪЙгУбЦБрТыЕФЗНЪННЋЖЈадЬиеїзЊЛЛЮЊЖЈСПЬиеїЃКМйЩшгаNжжЖЈаджЕЃЌдђНЋетвЛИіЬиеїРЉеЙЮЊNжжЬиеїЃЌЕБдЪМЬиеїжЕЮЊЕкiжжЖЈаджЕЪБЃЌЕкiИіРЉеЙЬиеїИГжЕЮЊ1ЃЌЦфЫћРЉеЙЬиеїИГжЕЮЊ0ЁЃбЦБрТыЕФЗНЪНЯрБШжБНгжИЖЈЕФЗНЪНЃЌВЛгУдіМгЕїВЮЕФЙЄзїЃЌЖдгкЯпадФЃаЭРДЫЕЃЌЪЙгУбЦБрТыКѓЕФЬиеїПЩДяЕНЗЧЯпадЕФаЇЙћЁЃ
4ЁЂДцдкШБЪЇжЕЃКШБЪЇжЕашвЊВЙГфЁЃ
5ЁЂаХЯЂРћгУТЪЕЭЃКВЛЭЌЕФЛњЦїбЇЯАЫуЗЈКЭФЃаЭЖдЪ§ОнжааХЯЂЕФРћгУЪЧВЛЭЌЕФЃЌжЎЧАЬсЕНдкЯпадФЃаЭжаЃЌЪЙгУЖдЖЈадЬиеїбЦБрТыПЩвдДяЕНЗЧЯпадЕФаЇЙћЁЃРрЫЦЕиЃЌЖдЖЈСПБфСПЖрЯюЪНЛЏЃЌЛђепНјааЦфЫћЕФзЊЛЛЃЌЖМФмДяЕНЗЧЯпадЕФаЇЙћЁЃ
ЮвУЧЪЙгУsklearnжаЕФpreproccessingПтРДНјааЪ§ОндЄДІРэЃЌПЩвдИВИЧвдЩЯЮЪЬтЕФНтОіЗНАИЁЃ
2.1 ЮоСПИйЛЏ ЮоСПИйЛЏЪЙВЛЭЌЙцИёЕФЪ§ОнзЊЛЛЕНЭЌвЛЙцИёЁЃГЃМћЕФЮоСПИйЛЏЗНЗЈгаБъзМЛЏКЭЧјМфЫѕЗХЗЈЁЃБъзМЛЏЕФЧАЬсЪЧЬиеїжЕЗўДге§ЬЌЗжВМЃЌБъзМЛЏКѓЃЌЦфзЊЛЛГЩБъзМе§ЬЌЗжВМЁЃЧјМфЫѕЗХЗЈРћгУСЫБпНчжЕаХЯЂЃЌНЋЬиеїЕФШЁжЕЧјМфЫѕЗХЕНФГИіЬиЕуЕФЗЖЮЇЃЌР§Шч[0,
1]ЕШЁЃ
2.1.1 БъзМЛЏ БъзМЛЏашвЊМЦЫуЬиеїЕФОљжЕКЭБъзМВюЃЌЙЋЪНБэДяЮЊЃК
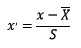
ЪЙгУpreproccessingПтЕФStandardScalerРрЖдЪ§ОнНјааБъзМЛЏЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import StandardScaler
#БъзМЛЏЃЌЗЕЛижЕЮЊБъзМЛЏКѓЕФЪ§Он
StandardScaler().fit_transform(iris.data) |
2.1.2 ЧјМфЫѕЗХЗЈ ЧјМфЫѕЗХЗЈЕФЫМТЗгаЖржжЃЌГЃМћЕФвЛжжЮЊРћгУСНИізюжЕНјааЫѕЗХЃЌЙЋЪНБэДяЮЊЃК
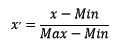
ЪЙгУpreproccessingПтЕФMinMaxScalerРрЖдЪ§ОнНјааЧјМфЫѕЗХЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import MinMaxScaler
#ЧјМфЫѕЗХЃЌЗЕЛижЕЮЊЫѕЗХЕН[0, 1]ЧјМфЕФЪ§Он
MinMaxScaler().fit_transform(iris.data) |
2.1.3 БъзМЛЏгыЙщвЛЛЏЕФЧјБ№ МђЕЅРДЫЕЃЌБъзМЛЏЪЧвРееЬиеїОиеѓЕФСаДІРэЪ§ОнЃЌЦфЭЈЙ§Чѓz-scoreЕФЗНЗЈЃЌНЋбљБОЕФЬиеїжЕзЊЛЛЕНЭЌвЛСПИйЯТЁЃЙщвЛЛЏЪЧвРееЬиеїОиеѓЕФааДІРэЪ§ОнЃЌЦфФПЕФдкгкбљБОЯђСПдкЕуГЫдЫЫуЛђЦфЫћКЫКЏЪ§МЦЫуЯрЫЦадЪБЃЌгЕгаЭГвЛЕФБъзМЃЌвВОЭЪЧЫЕЖМзЊЛЏЮЊЁАЕЅЮЛЯђСПЁБЁЃЙцдђЮЊl2ЕФЙщвЛЛЏЙЋЪНШчЯТЃК
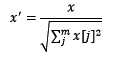
ЪЙгУpreproccessingПтЕФNormalizerРрЖдЪ§ОнНјааЙщвЛЛЏЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import Normalizer
#ЙщвЛЛЏЃЌЗЕЛижЕЮЊЙщвЛЛЏКѓЕФЪ§Он
Normalizer().fit_transform(iris.data) |
2.2 ЖдЖЈСПЬиеїЖўжЕЛЏ ЖЈСПЬиеїЖўжЕЛЏЕФКЫаФдкгкЩшЖЈвЛИіуажЕЃЌДѓгкуажЕЕФИГжЕЮЊ1ЃЌаЁгкЕШгкуажЕЕФИГжЕЮЊ0ЃЌЙЋЪНБэДяШчЯТЃК
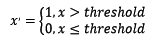
ЪЙгУpreproccessingПтЕФBinarizerРрЖдЪ§ОнНјааЖўжЕЛЏЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import Binarizer
#ЖўжЕЛЏЃЌуажЕЩшжУЮЊ3ЃЌЗЕЛижЕЮЊЖўжЕЛЏКѓЕФЪ§Он
Binarizer(threshold=3).fit_transform(iris.data)
|
2.3 ЖдЖЈадЬиеїбЦБрТы гЩгкIRISЪ§ОнМЏЕФЬиеїНдЮЊЖЈСПЬиеїЃЌЙЪЪЙгУЦфФПБъжЕНјаабЦБрТыЃЈЪЕМЪЩЯЪЧВЛашвЊЕФЃЉЁЃЪЙгУpreproccessingПтЕФOneHotEncoderРрЖдЪ§ОнНјаабЦБрТыЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import OneHotEncoder
#бЦБрТыЃЌЖдIRISЪ§ОнМЏЕФФПБъжЕЃЌЗЕЛижЕЮЊбЦБрТы
КѓЕФЪ§OneHotEncoder().fit_transform(iris.target
.reshape((-1,1)))
|
2.4 ШБЪЇжЕМЦЫу гЩгкIRISЪ§ОнМЏУЛгаШБЪЇжЕЃЌЙЪЖдЪ§ОнМЏаТдівЛИібљБОЃЌ4ИіЬиеїОљИГжЕЮЊNaNЃЌБэЪОЪ§ОнШБЪЇЁЃЪЙгУpreproccessingПтЕФImputerРрЖдЪ§ОнНјааШБЪЇжЕМЦЫуЕФДњТыШчЯТЃК
| from
numpy import vstack, array, nan
from sklearn.preprocessing import Imputer
#ШБЪЇжЕМЦЫуЃЌЗЕЛижЕЮЊМЦЫуШБЪЇжЕКѓЕФЪ§Он
#ВЮЪ§missing_valueЮЊШБЪЇжЕЕФБэЪОаЮЪНЃЌФЌШЯЮЊNaN
#ВЮЪ§strategyЮЊШБЪЇжЕЬюГфЗНЪНЃЌФЌШЯЮЊmeanЃЈОљжЕЃЉ
Imputer().fit_transform(vstack((array([nan,
nan, nan, nan]), iris.data))) |
2.5 Ъ§ОнБфЛЛ ГЃМћЕФЪ§ОнБфЛЛгаЛљгкЖрЯюЪНЕФЁЂЛљгкжИЪ§КЏЪ§ЕФЁЂЛљгкЖдЪ§КЏЪ§ЕФЁЃ4ИіЬиеїЃЌЖШЮЊ2ЕФЖрЯюЪНзЊЛЛЙЋЪНШчЯТЃК
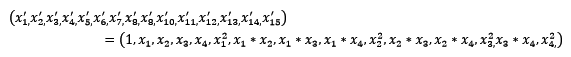
ЪЙгУpreproccessingПтЕФPolynomialFeaturesРрЖдЪ§ОнНјааЖрЯюЪНзЊЛЛЕФДњТыШчЯТЃК
| from
sklearn.preprocessing import PolynomialFeatures
#ЖрЯюЪНзЊЛЛ
#ВЮЪ§degreeЮЊЖШЃЌФЌШЯжЕЮЊ2
PolynomialFeatures().fit_transform(iris.data)
|
ЛљгкЕЅБфдЊКЏЪ§ЕФЪ§ОнБфЛЛПЩвдЪЙгУвЛИіЭГвЛЕФЗНЪНЭъГЩЃЌЪЙгУpreproccessingПтЕФFunctionTransformerЖдЪ§ОнНјааЖдЪ§КЏЪ§зЊЛЛЕФДњТыШчЯТЃК
| from
numpy import log1p
from sklearn.preprocessing import FunctionTransformer
#здЖЈвхзЊЛЛКЏЪ§ЮЊЖдЪ§КЏЪ§ЕФЪ§ОнБфЛЛ
#ЕквЛИіВЮЪ§ЪЧЕЅБфдЊКЏЪ§
FunctionTransformer(log1p).fit_transform(iris.data)
|
2.6 ЛиЙЫ
3 ЬиеїбЁдё ЕБЪ§ОндЄДІРэЭъГЩКѓЃЌЮвУЧашвЊбЁдёгавтвхЕФЬиеїЪфШыЛњЦїбЇЯАЕФЫуЗЈКЭФЃаЭНјаабЕСЗЁЃЭЈГЃРДЫЕЃЌДгСНИіЗНУцПМТЧРДбЁдёЬиеїЃК
1ЁЂЬиеїЪЧЗёЗЂЩЂЃКШчЙћвЛИіЬиеїВЛЗЂЩЂЃЌР§ШчЗНВюНгНќгк0ЃЌвВОЭЪЧЫЕбљБОдкетИіЬиеїЩЯЛљБОЩЯУЛгаВювьЃЌетИіЬиеїЖдгкбљБОЕФЧјЗжВЂУЛгаЪВУДгУЁЃ
2ЁЂЬиеїгыФПБъЕФЯрЙиадЃКетЕуБШНЯЯдМћЃЌгыФПБъЯрЙиадИпЕФЬиеїЃЌгІЕБгХбЁбЁдёЁЃГ§ЗНВюЗЈЭтЃЌБОЮФНщЩмЕФЦфЫћЗНЗЈОљДгЯрЙиадПМТЧЁЃ
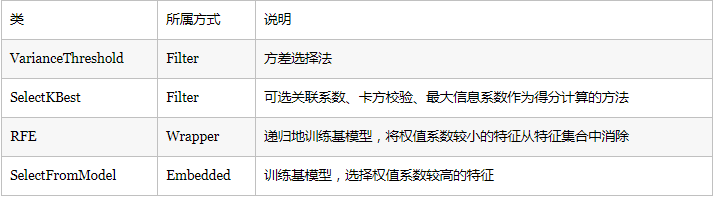
ИљОнЬиеїбЁдёЕФаЮЪНгжПЩвдНЋЬиеїбЁдёЗНЗЈЗжЮЊ3жжЃК
1ЁЂFilterЃКЙ§ТЫЗЈЃЌАДееЗЂЩЂадЛђепЯрЙиадЖдИїИіЬиеїНјааЦРЗжЃЌЩшЖЈуажЕЛђепД§бЁдёуажЕЕФИіЪ§ЃЌбЁдёЬиеїЁЃ
2ЁЂWrapperЃКАќзАЗЈЃЌИљОнФПБъКЏЪ§ЃЈЭЈГЃЪЧдЄВтаЇЙћЦРЗжЃЉЃЌУПДЮбЁдёШєИЩЬиеїЃЌЛђепХХГ§ШєИЩЬиеїЁЃ
3ЁЂEmbeddedЃКЧЖШыЗЈЃЌЯШЪЙгУФГаЉЛњЦїбЇЯАЕФЫуЗЈКЭФЃаЭНјаабЕСЗЃЌЕУЕНИїИіЬиеїЕФШЈжЕЯЕЪ§ЃЌИљОнЯЕЪ§ДгДѓЕНаЁбЁдёЬиеїЁЃРрЫЦгкFilterЗНЗЈЃЌЕЋЪЧЪЧЭЈЙ§бЕСЗРДШЗЖЈЬиеїЕФгХСгЁЃ
ЮвУЧЪЙгУsklearnжаЕФfeature_selectionПтРДНјааЬиеїбЁдёЁЃ
3.1 Filter 3.1.1 ЗНВюбЁдёЗЈ ЪЙгУЗНВюбЁдёЗЈЃЌЯШвЊМЦЫуИїИіЬиеїЕФЗНВюЃЌШЛКѓИљОнуажЕЃЌбЁдёЗНВюДѓгкуажЕЕФЬиеїЁЃЪЙгУfeature_selectionПтЕФVarianceThresholdРрРДбЁдёЬиеїЕФДњТыШчЯТЃК
| <span
style="font-size:10px;">from sklearn.feature_selection
import VarianceThreshold
#ЗНВюбЁдёЗЈЃЌЗЕЛижЕЮЊЬиеїбЁдёКѓЕФЪ§Он
#ВЮЪ§thresholdЮЊЗНВюЕФуажЕ
VarianceThreshold(threshold=3).fit_transform(iris.data)</span>
|
3.1.2 ЯрЙиЯЕЪ§ЗЈ ЪЙгУЯрЙиЯЕЪ§ЗЈЃЌЯШвЊМЦЫуИїИіЬиеїЖдФПБъжЕЕФЯрЙиЯЕЪ§вдМАЯрЙиЯЕЪ§ЕФPжЕЁЃгУfeature_selectionПтЕФSelectKBestРрНсКЯЯрЙиЯЕЪ§РДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#бЁдёKИізюКУЕФЬиеїЃЌЗЕЛибЁдёЬиеїКѓЕФЪ§Он
#ЕквЛИіВЮЪ§ЮЊМЦЫуЦРЙРЬиеїЪЧЗёКУЕФКЏЪ§ЃЌИУКЏЪ§ЪфШыЬиеїОиеѓКЭФПБъЯђСПЃЌЪфГіЖўдЊзщЃЈЦРЗжЃЌPжЕЃЉЕФЪ§зщЃЌЪ§зщЕкiЯюЮЊЕкiИіЬиеїЕФЦРЗжКЭPжЕЁЃдкДЫЖЈвхЮЊМЦЫуЯрЙиЯЕЪ§
#ВЮЪ§kЮЊбЁдёЕФЬиеїИіЪ§
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x,
Y), X.T)).T, k=2).fit_transform(iris.data, iris.target) |
3.1.3 ПЈЗНМьбщ ОЕфЕФПЈЗНМьбщЪЧМьбщЖЈадздБфСПЖдЖЈадвђБфСПЕФЯрЙиадЁЃМйЩшздБфСПгаNжжШЁжЕЃЌвђБфСПгаMжжШЁжЕЃЌПМТЧздБфСПЕШгкiЧввђБфСПЕШгкjЕФбљБОЦЕЪ§ЕФЙлВьжЕгыЦкЭћЕФВюОрЃЌЙЙНЈЭГМЦСПЃК
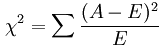
етИіЭГМЦСПЕФКЌвхМђЖјбджЎОЭЪЧздБфСПЖдвђБфСПЕФЯрЙиадЁЃгУfeature_selectionПтЕФSelectKBestРрНсКЯПЈЗНМьбщРДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#бЁдёKИізюКУЕФЬиеїЃЌЗЕЛибЁдёЬиеїКѓЕФЪ§Он
SelectKBest(chi2, k=2).fit_transform(iris.data,
iris.target) |
3.1.4 ЛЅаХЯЂЗЈ
ОЕфЕФЛЅаХЯЂвВЪЧЦРМлЖЈадздБфСПЖдЖЈадвђБфСПЕФЯрЙиадЕФЃЌЛЅаХЯЂМЦЫуЙЋЪНШчЯТЃК
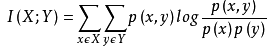
ЮЊСЫДІРэЖЈСПЪ§ОнЃЌзюДѓаХЯЂЯЕЪ§ЗЈБЛЬсГіЃЌЪЙгУfeature_selectionПтЕФSelectKBestРрНсКЯзюДѓаХЯЂЯЕЪ§ЗЈРДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import SelectKBest
from minepy import MINE
#гЩгкMINEЕФЩшМЦВЛЪЧКЏЪ§ЪНЕФЃЌЖЈвхmicЗНЗЈНЋЦфЮЊКЏЪ§ЪНЕФЃЌЗЕЛивЛИіЖўдЊзщЃЌЖўдЊзщЕФЕк2ЯюЩшжУГЩЙЬЖЈЕФPжЕ0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
#бЁдёKИізюКУЕФЬиеїЃЌЗЕЛиЬиеїбЁдёКѓЕФЪ§Он
SelectKBest(lambda X, Y: array(map(lambda x:mic(x,
Y), X.T)).T, k=2).fit_transform(iris.data, iris.target) |
3.2.1 ЕнЙщЬиеїЯћГ§ЗЈ ЕнЙщЯћГ§ЬиеїЗЈЪЙгУвЛИіЛљФЃаЭРДНјааЖрТжбЕСЗЃЌУПТжбЕСЗКѓЃЌЯћГ§ШєИЩШЈжЕЯЕЪ§ЕФЬиеїЃЌдйЛљгкаТЕФЬиеїМЏНјааЯТвЛТжбЕСЗЁЃЪЙгУfeature_selectionПтЕФRFEРрРДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#ЕнЙщЬиеїЯћГ§ЗЈЃЌЗЕЛиЬиеїбЁдёКѓЕФЪ§Он
#ВЮЪ§estimatorЮЊЛљФЃаЭ
#ВЮЪ§n_features_to_selectЮЊбЁдёЕФЬиеїИіЪ§
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data,
iris.target) |
3.3 Embedded 3.3.1 ЛљгкГЭЗЃЯюЕФЬиеїбЁдёЗЈ ЪЙгУДјГЭЗЃЯюЕФЛљФЃаЭЃЌГ§СЫЩИбЁГіЬиеїЭтЃЌЭЌЪБвВНјааСЫНЕЮЌЁЃЪЙгУfeature_selectionПтЕФSelectFromModelРрНсКЯДјL1ГЭЗЃЯюЕФТпМЛиЙщФЃаЭЃЌРДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
#ДјL1ГЭЗЃЯюЕФТпМЛиЙщзїЮЊЛљФЃаЭЕФЬиеїбЁдё
SelectFromModel(LogisticRegression(penalty="l1",
C=0.1)).fit_transform(iris.data, iris.target)
|
L1ГЭЗЃЯюНЕЮЌЕФдРэдкгкБЃСєЖрИіЖдФПБъжЕОпгаЭЌЕШЯрЙиадЕФЬиеїжаЕФвЛИіЃЌЫљвдУЛбЁЕНЕФЬиеїВЛДњБэВЛживЊЁЃЙЪЃЌПЩНсКЯL2ГЭЗЃЯюРДгХЛЏЁЃОпЬхВйзїЮЊЃКШєвЛИіЬиеїдкL1жаЕФШЈжЕЮЊ1ЃЌбЁдёдкL2жаШЈжЕВюБ№ВЛДѓЧвдкL1жаШЈжЕЮЊ0ЕФЬиеїЙЙГЩЭЌРрМЏКЯЃЌНЋетвЛМЏКЯжаЕФЬиеїЦНЗжL1жаЕФШЈжЕЃЌЙЪашвЊЙЙНЈвЛИіаТЕФТпМЛиЙщФЃаЭЃК
| from
sklearn.linear_model import LogisticRegression
class LR(LogisticRegression):
def __init__(self, threshold=0.01, dual=False,
tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False,
n_jobs=1):
#ШЈжЕЯрНќЕФуажЕ
self.threshold = threshold
LogisticRegression.__init__(self, penalty='l1',
dual=dual, tol=tol, C=C,
fit_intercept=fit_intercept, intercept_scaling=intercept_scaling,
class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start,
n_jobs=n_jobs)
#ЪЙгУЭЌбљЕФВЮЪ§ДДНЈL2ТпМЛиЙщ
self.l2 = LogisticRegression(penalty='l2', dual=dual,
tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling,
class_weight = class_weight, random_state=random_state,
solver=solver, max_iter=max_iter, multi_class=multi_class,
verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
def fit(self, X, y, sample_weight=None):
#бЕСЗL1ТпМЛиЙщ
super(LR, self).fit(X, y, sample_weight=sample_weight)
self.coef_old_ = self.coef_.copy()
#бЕСЗL2ТпМЛиЙщ
self.l2.fit(X, y, sample_weight=sample_weight)
cntOfRow, cntOfCol = self.coef_.shape
#ШЈжЕЯЕЪ§ОиеѓЕФааЪ§ЖдгІФПБъжЕЕФжжРрЪ§ФП
for i in range(cntOfRow):
for j in range(cntOfCol):
coef = self.coef_[i][j]
#L1ТпМЛиЙщЕФШЈжЕЯЕЪ§ВЛЮЊ0
if coef != 0:
idx = [j]
#ЖдгІдкL2ТпМЛиЙщжаЕФШЈжЕЯЕЪ§
coef1 = self.l2.coef_[i][j]
for k in range(cntOfCol):
coef2 = self.l2.coef_[i][k]
#дкL2ТпМЛиЙщжаЃЌШЈжЕЯЕЪ§жЎВюаЁгкЩшЖЈЕФуажЕЃЌЧвдкL1жаЖдгІЕФШЈжЕЮЊ0
if abs(coef1-coef2) < self.threshold and
j != k and self.coef_[i][k] == 0:
idx.append(k)
#МЦЫуетвЛРрЬиеїЕФШЈжЕЯЕЪ§ОљжЕ
mean = coef / len(idx)
self.coef_[i][idx] = mean
return self |
ЪЙгУfeature_selectionПтЕФSelectFromModelРрНсКЯДјL1вдМАL2ГЭЗЃЯюЕФТпМЛиЙщФЃаЭЃЌРДбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.feature_selection import SelectFromModel
#ДјL1КЭL2ГЭЗЃЯюЕФТпМЛиЙщзїЮЊЛљФЃаЭЕФЬиеїбЁдё
#ВЮЪ§thresholdЮЊШЈжЕЯЕЪ§жЎВюЕФуажЕ
SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data,
iris.target) |
3.3.2 ЛљгкЪїФЃаЭЕФЬиеїбЁдёЗЈ
ЪїФЃаЭжаGBDTвВПЩгУРДзїЮЊЛљФЃаЭНјааЬиеїбЁдёЃЌЪЙгУfeature_selectionПтЕФSelectFromModelРрНсКЯGBDTФЃаЭЃЌРДбЁдёЬиеїЕФДњТыШчЯТЃК
| </pre><pre
name="code" class="python">from
sklearn.
feature_selection
import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDTзїЮЊЛљФЃаЭЕФЬиеїбЁдё
SelectFromModel(GradientBoostingClassifier()).
fit_transform(iris.data,
iris.target) |
3.4 ЛиЙЫ
4 НЕЮЌ ЕБЬиеїбЁдёЭъГЩКѓЃЌПЩвджБНгбЕСЗФЃаЭСЫЃЌЕЋЪЧПЩФмгЩгкЬиеїОиеѓЙ§ДѓЃЌЕМжТМЦЫуСПДѓЃЌбЕСЗЪБМфГЄЕФЮЪЬтЃЌвђДЫНЕЕЭЬиеїОиеѓЮЌЖШвВЪЧБиВЛПЩЩйЕФЁЃГЃМћЕФНЕЮЌЗНЗЈГ§СЫвдЩЯЬсЕНЕФЛљгкL1ГЭЗЃЯюЕФФЃаЭвдЭтЃЌСэЭтЛЙгажїГЩЗжЗжЮіЗЈЃЈPCAЃЉКЭЯпадХаБ№ЗжЮіЃЈLDAЃЉЃЌЯпадХаБ№ЗжЮіБОЩэвВЪЧвЛИіЗжРрФЃаЭЁЃPCAКЭLDAгаКмЖрЕФЯрЫЦЕуЃЌЦфБОжЪЪЧвЊНЋдЪМЕФбљБОгГЩфЕНЮЌЖШИќЕЭЕФбљБОПеМфжаЃЌЕЋЪЧPCAКЭLDAЕФгГЩфФПБъВЛвЛбљЃКPCAЪЧЮЊСЫШУгГЩфКѓЕФбљБООпгазюДѓЕФЗЂЩЂадЃЛЖјLDAЪЧЮЊСЫШУгГЩфКѓЕФбљБОгазюКУЕФЗжРрадФмЁЃЫљвдЫЕPCAЪЧвЛжжЮоМрЖНЕФНЕЮЌЗНЗЈЃЌЖјLDAЪЧвЛжжгаМрЖНЕФНЕЮЌЗНЗЈЁЃ
4.1 жїГЩЗжЗжЮіЗЈЃЈPCAЃЉ ЪЙгУdecompositionПтЕФPCAРрбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.decomposition import PCA
#жїГЩЗжЗжЮіЗЈЃЌЗЕЛиНЕЮЌКѓЕФЪ§Он
#ВЮЪ§n_componentsЮЊжїГЩЗжЪ§ФП
PCA(n_components=2).fit_transform(iris.data)
|
4.2 ЯпадХаБ№ЗжЮіЗЈЃЈLDAЃЉ ЪЙгУldaПтЕФLDAРрбЁдёЬиеїЕФДњТыШчЯТЃК
| from
sklearn.lda import LDA
#ЯпадХаБ№ЗжЮіЗЈЃЌЗЕЛиНЕЮЌКѓЕФЪ§Он
#ВЮЪ§n_componentsЮЊНЕЮЌКѓЕФЮЌЪ§
LDA(n_components=2).fit_transform(iris.data,
iris.target) |
4.3 ЛиЙЫ

|









