| БрМЭЦМі: |
БОЮФРДздгкCSDNЃЌНщЩмСЫЛњЦїбЇЯАЫуЗЈPythonЪЕЯжЕФТпМЛиЙщЁЂBPЩёОЭјТчЁЂK-MeansОлРрЫуЗЈвдМАЖрдЊИпЫЙЗжВМЕШЯрЙижЊЪЖЁЃ
|
|
вЛЁЂЯпадЛиЙщ
ШЋВПДњТы
1ЁЂДњМлКЏЪ§ 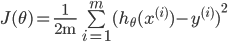
ЦфжаЃК 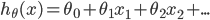
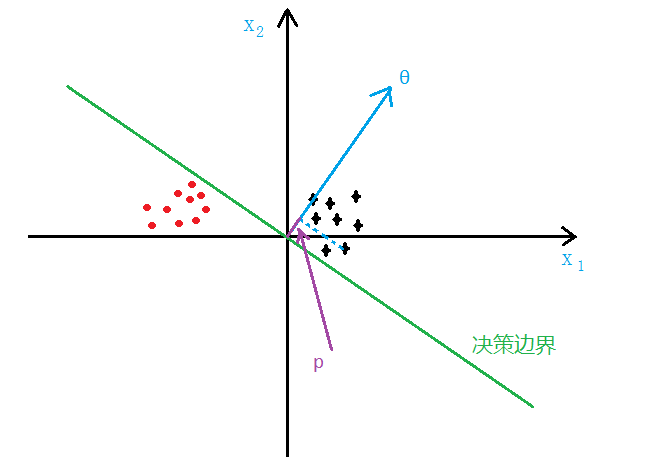
ЯТУцОЭЪЧвЊЧѓГіthetaЃЌЪЙДњМлзюаЁЃЌМДДњБэЮвУЧФтКЯГіРДЕФЗНГЬОрРыецЪЕжЕзюНќ
ЙВгаmЬѕЪ§ОнЃЌЦфжа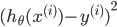 ДњБэЮвУЧвЊФтКЯГіРДЕФЗНГЬЕНецЪЕжЕОрРыЕФЦНЗНЃЌЦНЗНЕФдвђЪЧвђЮЊПЩФмгаИКжЕЃЌе§ИКПЩФмЛсЕжЯћ ДњБэЮвУЧвЊФтКЯГіРДЕФЗНГЬЕНецЪЕжЕОрРыЕФЦНЗНЃЌЦНЗНЕФдвђЪЧвђЮЊПЩФмгаИКжЕЃЌе§ИКПЩФмЛсЕжЯћ
ЧАУцгаЯЕЪ§2ЕФдвђЪЧЯТУцЧѓЬнЖШЪЧЖдУПИіБфСПЧѓЦЋЕМЃЌ2ПЩвдЯћШЅ
ЪЕЯжДњТыЃК
# МЦЫуДњМлКЏЪ§
def computerCost(X,y,theta):
m = len(y)
J = 0
J = (np.transpose(X*theta-y))*(X*theta-y)/(2*m)
#МЦЫуДњМлJ
return J
|
зЂвтетРяЕФXЪЧецЪЕЪ§ОнЧАМгСЫвЛСа1ЃЌвђЮЊгаtheta(0)
2ЁЂЬнЖШЯТНЕЫуЗЈ
ДњМлКЏЪ§Жд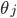 ЧѓЦЋЕМЕУЕНЃК ЧѓЦЋЕМЕУЕНЃК
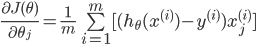
ЫљвдЖдthetaЕФИќаТПЩвдаДЮЊЃК 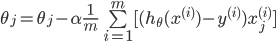
ЦфжаІСЮЊбЇЯАЫйТЪЃЌПижЦЬнЖШЯТНЕЕФЫйЖШЃЌвЛАуШЁ0.01,0.03,0.1,0.3.....
ЮЊЪВУДЬнЖШЯТНЕПЩвдж№ВНМѕаЁДњМлКЏЪ§
МйЩшКЏЪ§f(x)
ЬЉРееЙПЊЃКf(x+Ёїx)=f(x)+f'(x)*Ёїx+o(Ёїx)
СюЃКЁїx=-ІС*f'(x) ,МДИКЬнЖШЗНЯђГЫвдвЛИіКмаЁЕФВНГЄІС
НЋЁїxДњШыЬЉРееЙПЊЪНжаЃКf(x+x)=f(x)-ІС*[f'(x)]2+o(Ёїx)
ПЩвдПДГіЃЌІСЪЧШЁЕУКмаЁЕФе§Ъ§ЃЌ[f'(x)]2вВЪЧе§Ъ§ЃЌЫљвдПЩвдЕУГіЃКf(x+Ёїx)<=f(x)
ЫљвдбизХИКЬнЖШЗХЯТЃЌКЏЪ§дкМѕаЁЃЌЖрЮЌЧщПівЛбљЁЃ
ЪЕЯжДњТы
Hello World!#
ЬнЖШЯТНЕЫуЗЈ
def gradientDescent(X,y,theta,alpha,num_iters):
m = len(y)
n = len(theta)
temp = np.matrix(np.zeros((n,num_iters))) # днДцУПДЮЕќДњМЦЫуЕФthetaЃЌзЊЛЏЮЊОиеѓаЮЪН
J_history = np.zeros((num_iters,1)) #МЧТМУПДЮЕќДњМЦЫуЕФДњМлжЕ
for i in range(num_iters): # БщРњЕќДњДЮЪ§
h = np.dot(X,theta) # МЦЫуФкЛ§ЃЌmatrixПЩвджБНгГЫ
temp[:,i] = theta - ((alpha/m)*(np.dot(np.transpose(X),h-y)))
#ЬнЖШЕФМЦЫу
theta = temp[:,i]
J_history[i] = computerCost(X,y,theta) #ЕїгУМЦЫуДњМлКЏЪ§
print '.',
return theta,J_history
|
3ЁЂОљжЕЙщвЛЛЏ
ФПЕФЪЧЪЙЪ§ОнЖМЫѕЗХЕНвЛИіЗЖЮЇФкЃЌБугкЪЙгУЬнЖШЯТНЕЫуЗЈ
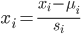
Цфжа 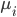 ЮЊЫљгаДЫfetureЪ§ОнЕФЦНОљжЕ ЮЊЫљгаДЫfetureЪ§ОнЕФЦНОљжЕ
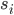 ПЩвдЪЧзюДѓжЕ-зюаЁжЕЃЌвВПЩвдЪЧетИіfeatureЖдгІЕФЪ§ОнЕФБъзМВю ПЩвдЪЧзюДѓжЕ-зюаЁжЕЃЌвВПЩвдЪЧетИіfeatureЖдгІЕФЪ§ОнЕФБъзМВю
ЪЕЯжДњТыЃК
# ЙщвЛЛЏfeature
def featureNormaliza(X):
X_norm = np.array(X) #НЋXзЊЛЏЮЊnumpyЪ§зщЖдЯѓЃЌВХПЩвдНјааОиеѓЕФдЫЫу
#ЖЈвхЫљашБфСП
mu = np.zeros((1,X.shape[1]))
sigma = np.zeros((1,X.shape[1]))
mu = np.mean(X_norm,0) # ЧѓУПвЛСаЕФЦНОљжЕЃЈ0жИЖЈЮЊСаЃЌ1ДњБэааЃЉ
sigma = np.std(X_norm,0) # ЧѓУПвЛСаЕФБъзМВю
for i in range(X.shape[1]): # БщРњСа
X_norm[:,i] = (X_norm[:,i]-mu[i])/sigma[i] # ЙщвЛЛЏ
return X_norm,mu,sigma |
зЂвтдЄВтЕФЪБКђвВашвЊОљжЕЙщвЛЛЏЪ§Он
4ЁЂзюжедЫааНсЙћ
ДњМлЫцЕќДњДЮЪ§ЕФБфЛЏ
5ЁЂЪЙгУscikit-learnПтжаЕФЯпадФЃаЭЪЕЯж
ЕМШыАќ
from sklearn
import linear_model
from sklearn.preprocessing import StandardScaler
#в§ШыЫѕЗХЕФАќ |
ЙщвЛЛЏ
# ЙщвЛЛЏВйзї
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
x_test = scaler.transform(np.array([1650,3])) |
ЯпадФЃаЭФтКЯ
# ЯпадФЃаЭФтКЯ
model = linear_model.LinearRegression()
model.fit(x_train, y) |
дЄВт
#дЄВтНсЙћ
result = model.predict(x_test) |
ЖўЁЂТпМЛиЙщ
ШЋВПДњТы
1ЁЂДњМлКЏЪ§
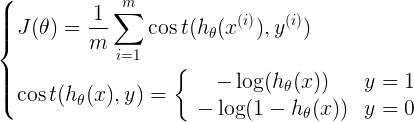
ПЩвдзлКЯЦ№РДЮЊЃК 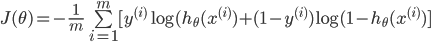 ЦфжаЃК ЦфжаЃК
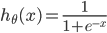
ЮЊЪВУДВЛгУЯпадЛиЙщЕФДњМлКЏЪ§БэЪОЃЌвђЮЊЯпадЛиЙщЕФДњМлКЏЪ§ПЩФмЪЧЗЧЭЙЕФЃЌЖдгкЗжРрЮЪЬтЃЌЪЙгУЬнЖШЯТНЕКмФбЕУЕНзюаЁжЕЃЌЩЯУцЕФДњМлКЏЪ§ЪЧЭЙКЏЪ§
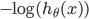 ЕФЭМЯёШчЯТЃЌМДy=1ЪБЃК ЕФЭМЯёШчЯТЃЌМДy=1ЪБЃК
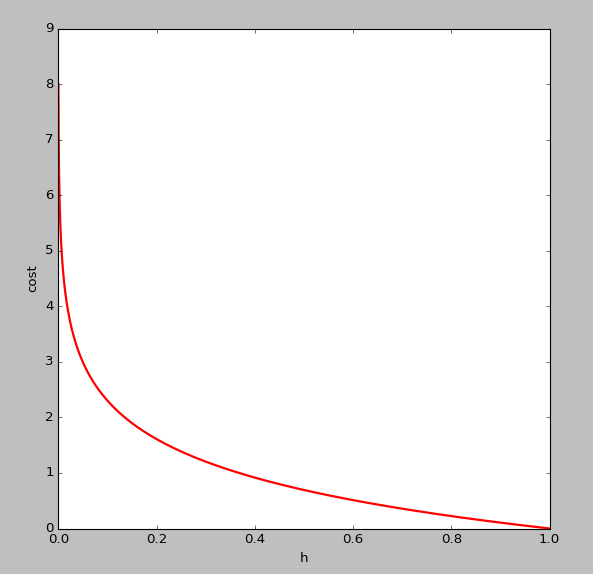
ПЩвдПДГіЃЌЕБ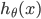 Чїгк1ЃЌy=1,гыдЄВтжЕвЛжТЃЌДЫЪБИЖГіЕФДњМлcostЧїгк0ЃЌШє Чїгк1ЃЌy=1,гыдЄВтжЕвЛжТЃЌДЫЪБИЖГіЕФДњМлcostЧїгк0ЃЌШє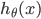 Чїгк0ЃЌy=1,ДЫЪБЕФДњМлcostжЕЗЧГЃДѓЃЌЮвУЧзюжеЕФФПЕФЪЧзюаЁЛЏДњМлжЕ Чїгк0ЃЌy=1,ДЫЪБЕФДњМлcostжЕЗЧГЃДѓЃЌЮвУЧзюжеЕФФПЕФЪЧзюаЁЛЏДњМлжЕ
ЭЌРэ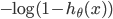 ЕФЭМЯёШчЯТЃЈy=0ЃЉЃК ЕФЭМЯёШчЯТЃЈy=0ЃЉЃК
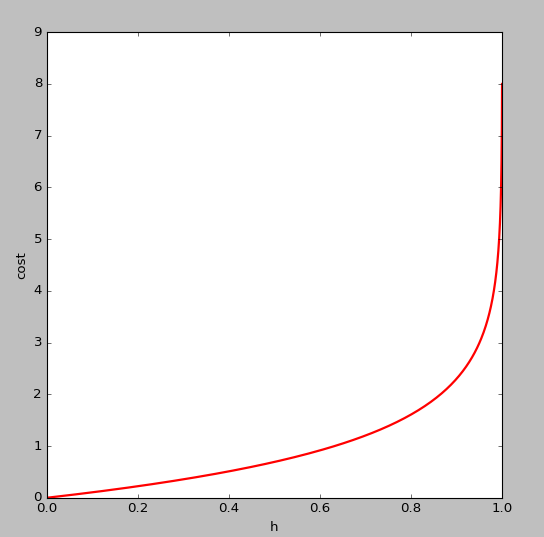
2ЁЂЬнЖШ
ЭЌбљЖдДњМлКЏЪ§ЧѓЦЋЕМЃК 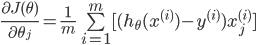
ПЩвдПДГігыЯпадЛиЙщЕФЦЋЕМЪ§вЛжТ
ЭЦЕНЙ§ГЬ

3ЁЂе§дђЛЏ
ФПЕФЪЧЮЊСЫЗРжЙЙ§ФтКЯ
дкДњМлКЏЪ§жаМгЩЯвЛЯю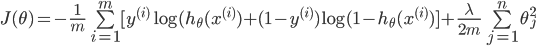
зЂвтjЪЧжи1ПЊЪМЕФЃЌвђЮЊtheta(0)ЮЊвЛИіГЃЪ§ЯюЃЌXжазюЧАУцвЛСаЛсМгЩЯ1Са1ЃЌЫљвдГЫЛ§ЛЙЪЧtheta(0),featureУЛгаЙиЯЕЃЌУЛгаБивЊе§дђЛЏ
е§дђЛЏКѓЕФДњМлЃК
# ДњМлКЏЪ§
def costFunction(initial_theta,X,y,inital_lambda):
m = len(y)
J = 0
h = sigmoid(np.dot(X,initial_theta)) # МЦЫуh(z)
theta1 = initial_theta.copy() # вђЮЊе§дђЛЏj=1Дг1ПЊЪМЃЌВЛАќКЌ0ЃЌЫљвдИДжЦвЛЗнЃЌЧАtheta(0)жЕЮЊ0
theta1[0] = 0
temp = np.dot(np.transpose(theta1),theta1)
J = (-np.dot(np.transpose(y),np.log(h))-np.dot(np.transpose(1-y),np.log(1-h))+temp*inital_lambda/2)/m
# е§дђЛЏЕФДњМлЗНГЬ
return J
|
е§дђЛЏКѓЕФДњМлЕФЬнЖШ
# МЦЫуЬнЖШ
def gradient(initial_theta,X,y,inital_lambda):
m = len(y)
grad = np.zeros((initial_theta.shape[0]))
h = sigmoid(np.dot(X,initial_theta))# МЦЫуh(z)
theta1 = initial_theta.copy()
theta1[0] = 0
grad = np.dot(np.transpose(X),h-y)/m+inital_lambda/m*theta1
#е§дђЛЏЕФЬнЖШ
return grad
|
4ЁЂSаЭКЏЪ§ЃЈМД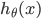 ЃЉ ЃЉ
ЪЕЯжДњТыЃК
# SаЭКЏЪ§
def sigmoid(z):
h = np.zeros((len(z),1)) # ГѕЪМЛЏЃЌгыzЕФГЄЖШвЛжУ
h = 1.0/(1.0+np.exp(-z))
return h
|
5ЁЂгГЩфЮЊЖрЯюЪН
вђЮЊЪ§ОнЕФfetureПЩФмКмЩйЃЌЕМжТЦЋВюДѓЃЌЫљвдДДдьГівЛаЉfetureНсКЯ
eg:гГЩфЮЊ2ДЮЗНЕФаЮЪН: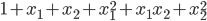
ЪЕЯжДњТыЃК
# гГЩфЮЊЖрЯюЪН
def mapFeature(X1,X2):
degree = 3; # гГЩфЕФзюИпДЮЗН
out = np.ones((X1.shape[0],1)) # гГЩфКѓЕФНсЙћЪ§зщЃЈШЁДњXЃЉ
'''
етРявдdegree=2ЮЊР§ЃЌгГЩфЮЊ1,x1,x2,x1^2,x1,x2,x2^2
'''
for i in np.arange(1,degree+1):
for j in range(i+1):
temp = X1**(i-j)*(X2**j) #ОиеѓжБНгГЫЯрЕБгкmatlabжаЕФЕуГЫ.*
out = np.hstack((out, temp.reshape(-1,1)))
return out
|
6ЁЂЪЙгУscipyЕФгХЛЏЗНЗЈ
ЬнЖШЯТНЕЪЙгУscipyжаoptimizeжаЕФfmin_bfgsКЏЪ§
ЕїгУscipyжаЕФгХЛЏЫуЗЈfmin_bfgsЃЈФтХЃЖйЗЈBroyden-Fletcher-Goldfarb-Shanno
costFunctionЪЧздМКЪЕЯжЕФвЛИіЧѓДњМлЕФКЏЪ§ЃЌ
initial_thetaБэЪОГѕЪМЛЏЕФжЕ,
fprimeжИЖЈcostFunctionЕФЬнЖШ
argsЪЧЦфгрВтВЮЪ§ЃЌвддЊзщЕФаЮЪНДЋШыЃЌзюКѓЛсНЋзюаЁЛЏcostFunctionЕФthetaЗЕЛи
result = optimize.fmin_bfgs(costFunction,
initial_theta, fprime=gradient, args=(X,y,initial_lambda))
|
7ЁЂдЫааНсЙћ
data1ОіВпБпНчКЭзМШЗЖШ
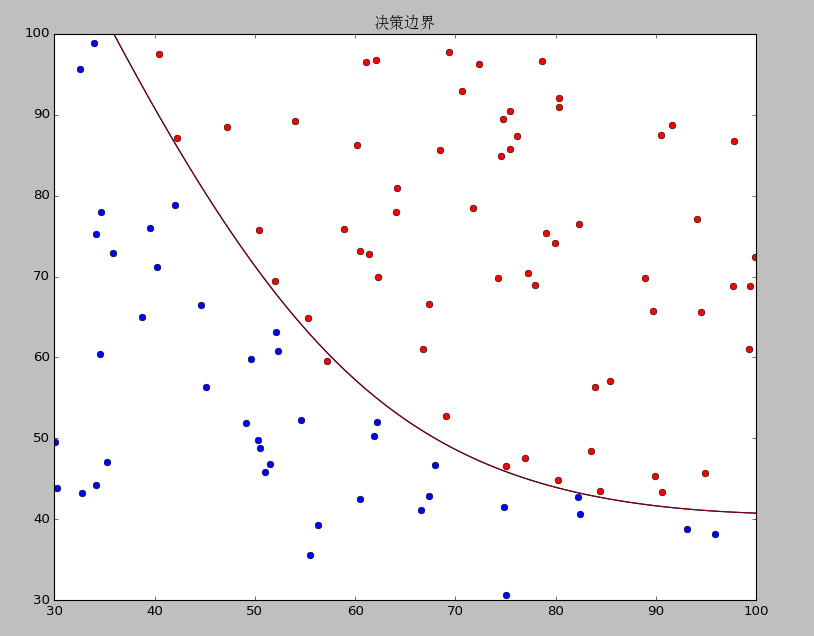

data2ОіВпБпНчКЭзМШЗЖШ 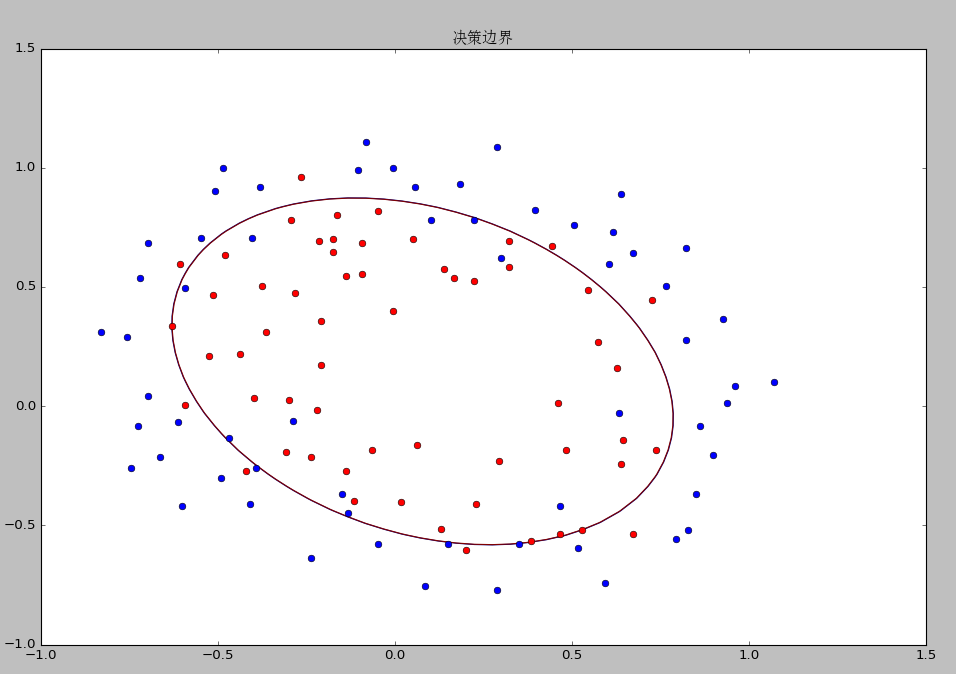

8ЁЂЪЙгУscikit-learnПтжаЕФТпМЛиЙщФЃаЭЪЕЯж
ЕМШыАќ
from sklearn.linear_model
import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
import numpy as np
|
ЛЎЗжбЕСЗМЏКЭВтЪдМЏ
# ЛЎЗжЮЊбЕСЗМЏКЭВтЪдМЏ
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
|
ЙщвЛЛЏ
# ЙщвЛЛЏ
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
|
ТпМЛиЙщ
#ТпМЛиЙщ
model = LogisticRegression()
model.fit(x_train,y_train)
|
дЄВт
# дЄВт
predict = model.predict(x_test)
right = sum(predict == y_test)
predict = np.hstack((predict.reshape(-1,1),y_test.reshape(-1,1)))
# НЋдЄВтжЕКЭецЪЕжЕЗХдквЛПщЃЌКУЙлВь
print predict
print ('ВтЪдМЏзМШЗТЪЃК%f%%'%(right*100.0/predict.shape[0]))
#МЦЫудкВтЪдМЏЩЯЕФзМШЗЖШ
|
ТпМЛиЙщ_ЪжаДЪ§зжЪЖБ№_OneVsAll
ШЋВПДњТы
1ЁЂЫцЛњЯдЪО100ИіЪ§зж
ЮвУЛгаЪЙгУscikit-learnжаЕФЪ§ОнМЏЃЌЯёЫиЪЧ20*20pxЃЌВЪЩЋЭМШчЯТ

ЛвЖШЭМЃК

ЪЕЯжДњТыЃК
# ЯдЪО100ИіЪ§зж
def display_data(imgData):
sum = 0
'''
ЯдЪО100ИіЪ§ЃЈШєЪЧвЛИівЛИіЛцжЦНЋЛсЗЧГЃТ§ЃЌПЩвдНЋвЊЛЕФЪ§зжећРэКУЃЌЗХЕНвЛИіОиеѓжаЃЌЯдЪОетИіОиеѓМДПЩЃЉ
- ГѕЪМЛЏвЛИіЖўЮЌЪ§зщ
- НЋУПааЕФЪ§ОнЕїећГЩЭМЯёЕФОиеѓЃЌЗХНјЖўЮЌЪ§зщ
- ЯдЪОМДПЩ
'''
pad = 1
display_array = -np.ones((pad+10*(20+pad),pad+10*(20+pad)))
for i in range(10):
for j in range(10):
display_array[pad+i*(20+pad):pad+i*(20+pad)+20,pad+j*(20+pad):pad+j*(20+pad)+20]
= (imgData[sum,:].reshape(20,20,order="F"))
# order=FжИЖЈвдСагХЯШЃЌдкmatlabжаЪЧетбљЕФЃЌpythonжаашвЊжИЖЈЃЌФЌШЯвдаа
sum += 1
plt.imshow(display_array,cmap='gray') #ЯдЪОЛвЖШЭМЯё
plt.axis('off')
plt.show()
|
2ЁЂOneVsAll
ШчКЮРћгУТпМЛиЙщНтОіЖрЗжРрЕФЮЪЬтЃЌOneVsAllОЭЪЧАбЕБЧАФГвЛРрПДГЩвЛРрЃЌЦфЫћЫљгаРрБ№ПДзївЛРрЃЌетбљгаГЩСЫЖўЗжРрЕФЮЪЬтСЫ
ШчЯТЭМЃЌАбЭОжаЕФЪ§ОнЗжГЩШ§РрЃЌЯШАбКьЩЋЕФПДГЩвЛРрЃЌАбЦфЫћЕФПДзїСэЭтвЛРрЃЌНјааТпМЛиЙщЃЌШЛКѓАбРЖЩЋЕФПДГЩвЛРрЃЌЦфЫћЕФдйПДГЩвЛРрЃЌвдДЫРрЭЦ...
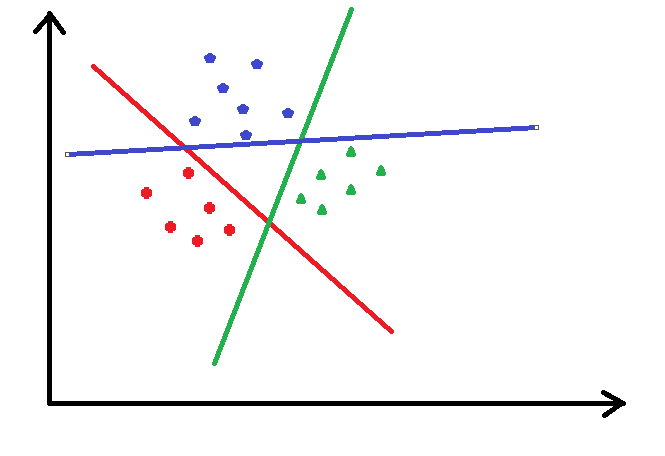
ПЩвдПДГіДѓгк2РрЕФЧщПіЯТЃЌгаЖрЩйРрОЭвЊНјааЖрЩйДЮЕФТпМЛиЙщЗжРр
3ЁЂЪжаДЪ§зжЪЖБ№
ЙВга0-9ЃЌ10ИіЪ§зжЃЌашвЊ10ДЮЗжРр
гЩгкЪ§ОнМЏyИјГіЕФЪЧ0,1,2...9ЕФЪ§зжЃЌЖјНјааТпМЛиЙщашвЊ0/1ЕФlabelБъМЧЃЌЫљвдашвЊЖдyДІРэ
ЫЕвЛЯТЪ§ОнМЏЃЌЧА500ИіЪЧ0,500-1000ЪЧ1,...,ЫљвдШчЯТЭМЃЌДІРэКѓЕФyЃЌЧА500ааЕФЕквЛСаЪЧ1ЃЌЦфгрЖМЪЧ0,500-1000ааЕкЖўСаЪЧ1ЃЌЦфгрЖМЪЧ0....
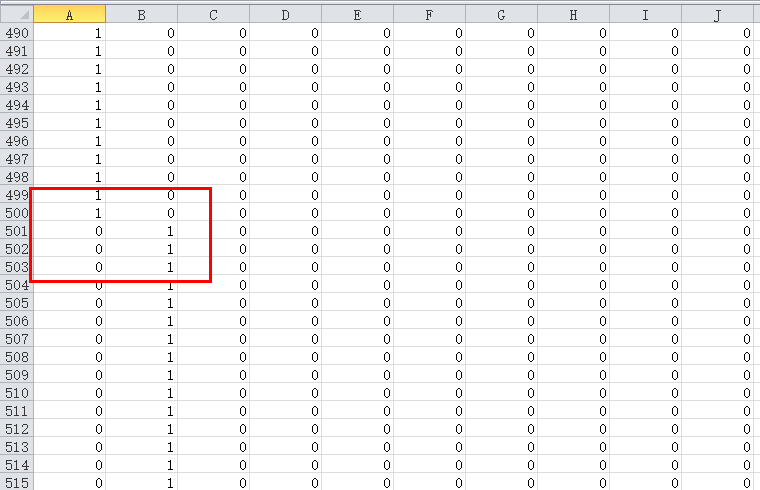
ШЛКѓЕїгУЬнЖШЯТНЕЫуЗЈЧѓНтtheta
ЪЕЯжДњТыЃК
# ЧѓУПИіЗжРрЕФthetaЃЌзюКѓЗЕЛиЫљгаЕФall_theta
def oneVsAll(X,y,num_labels,Lambda):
# ГѕЪМЛЏБфСП
m,n = X.shape
all_theta = np.zeros((n+1,num_labels)) # УПвЛСаЖдгІЯргІЗжРрЕФtheta,ЙВ10Са
X = np.hstack((np.ones((m,1)),X)) # XЧАВЙЩЯвЛСа1ЕФЦЋжУbias
class_y = np.zeros((m,num_labels)) # Ъ§ОнЕФyЖдгІ0-9ЃЌашвЊгГЩфЮЊ0/1ЕФЙиЯЕ
initial_theta = np.zeros((n+1,1)) # ГѕЪМЛЏвЛИіЗжРрЕФtheta
# гГЩфy
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) #
зЂвтreshape(1,-1)ВХПЩвдИГжЕ
#np.savetxt("class_y.csv", class_y[0:600,:],
delimiter=',')
'''БщРњУПИіЗжРрЃЌМЦЫуЖдгІЕФthetaжЕ'''
for i in range(num_labels):
result = optimize.fmin_bfgs(costFunction, initial_theta,
fprime=gradient, args=(X,class_y[:,i],Lambda))
# ЕїгУЬнЖШЯТНЕЕФгХЛЏЗНЗЈ
all_theta[:,i] = result.reshape(1,-1) # ЗХШыall_thetaжа
all_theta = np.transpose(all_theta)
return all_theta
|
4ЁЂдЄВт
жЎЧАЫЕЙ§ЃЌдЄВтЕФНсЙћЪЧвЛИіИХТЪжЕЃЌРћгУбЇЯАГіРДЕФthetaДњШыдЄВтЕФSаЭКЏЪ§жаЃЌУПааЕФзюДѓжЕОЭЪЧЪЧФГИіЪ§зжЕФзюДѓИХТЪЃЌЫљдкЕФСаКХОЭЪЧдЄВтЕФЪ§зжЕФецЪЕжЕ,вђЮЊдкЗжРрЪБЃЌЫљгаЮЊ0ЕФНЋyгГЩфдкЕквЛСаЃЌЮЊ1ЕФгГЩфдкЕкЖўСаЃЌвРДЮРрЭЦ
ЪЕЯжДњТыЃК
# дЄВт
def predict_oneVsAll(all_theta,X):
m = X.shape[0]
num_labels = all_theta.shape[0]
p = np.zeros((m,1))
X = np.hstack((np.ones((m,1)),X)) #дкXзюЧАУцМгвЛСа1
h = sigmoid(np.dot(X,np.transpose(all_theta)))
#дЄВт
'''
ЗЕЛиhжаУПвЛаазюДѓжЕЫљдкЕФСаКХ
- np.max(h, axis=1)ЗЕЛиhжаУПвЛааЕФзюДѓжЕЃЈЪЧФГИіЪ§зжЕФзюДѓИХТЪЃЉ
- зюКѓwhereевЕНЕФзюДѓИХТЪЫљдкЕФСаКХЃЈСаКХМДЪЧЖдгІЕФЪ§зжЃЉ
'''
p = np.array(np.where(h[0,:] == np.max(h, axis=1)[0]))
for i in np.arange(1, m):
t = np.array(np.where(h[i,:] == np.max(h, axis=1)[i]))
p = np.vstack((p,t))
return p
|
5ЁЂдЫааНсЙћ
10ДЮЗжРрЃЌдкбЕСЗМЏЩЯЕФзМШЗЖШЃК 
6ЁЂЪЙгУscikit-learnПтжаЕФТпМЛиЙщФЃаЭЪЕЯж
1ЁЂЕМШыАќ
from scipy import
io as spio
import numpy as np
from sklearn import svm
from sklearn.linear_model import LogisticRegression
|
2ЁЂМгдиЪ§Он
data = loadmat_data("data_digits.mat")
X = data['X'] # ЛёШЁXЪ§ОнЃЌУПвЛааЖдгІвЛИіЪ§зж20x20px
y = data['y'] # етРяЖСШЁmatЮФМўyЕФshape=(5000, 1)
y = np.ravel(y) # ЕїгУsklearnашвЊзЊЛЏГЩвЛЮЌЕФ(5000,)
|
3ЁЂФтКЯФЃаЭ
model = LogisticRegression()
model.fit(X, y) # ФтКЯ
|
4ЁЂдЄВт
predict = model.predict(X)
#дЄВт
print u"дЄВтзМШЗЖШЮЊЃК%f%%"%np.mean(np.float64(predict
== y)*100)
|
5ЁЂЪфГіНсЙћЃЈдкбЕСЗМЏЩЯЕФзМШЗЖШЃЉ

Ш§ЁЂBPЩёОЭјТч
ШЋВПДњТы
1ЁЂЩёОЭјТчmodel
ЯШНщЩмИіШ§ВуЕФЩёОЭјТчЃЌШчЯТЭМЫљЪО
ЪфШыВуЃЈinput layerЃЉгаШ§ИіunitsЃЈx0ЮЊВЙЩЯЕФbiasЃЌЭЈГЃЩшЮЊ1ЃЉ
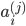 БэЪОЕкjВуЕФЕкiИіМЄРјЃЌвВГЦЮЊЮЊЕЅдЊunit БэЪОЕкjВуЕФЕкiИіМЄРјЃЌвВГЦЮЊЮЊЕЅдЊunit
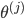 ЮЊЕкjВуЕНЕкj+1ВугГЩфЕФШЈжиОиеѓЃЌОЭЪЧУПЬѕБпЕФШЈжи ЮЊЕкjВуЕНЕкj+1ВугГЩфЕФШЈжиОиеѓЃЌОЭЪЧУПЬѕБпЕФШЈжи
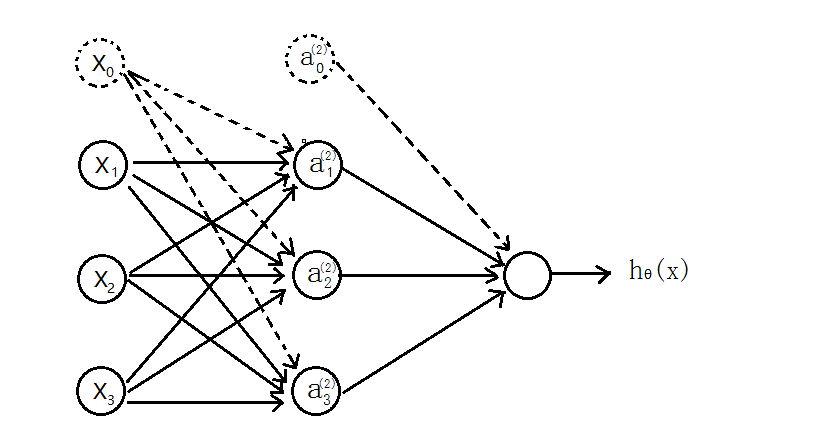
ЫљвдПЩвдЕУЕНЃК
вўКЌВуЃК 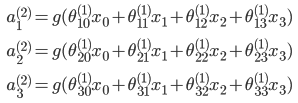
ЪфГіВу
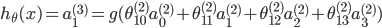 ЦфжаЃЌSаЭКЏЪ§ ЦфжаЃЌSаЭКЏЪ§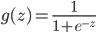 ЃЌвВГЩЮЊМЄРјКЏЪ§ ЃЌвВГЩЮЊМЄРјКЏЪ§
ПЩвдПДГі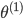 ЮЊ3x4ЕФОиеѓЃЌ ЮЊ3x4ЕФОиеѓЃЌ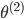 ЮЊ1x4ЕФОиеѓ ЮЊ1x4ЕФОиеѓ
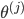 j+1ЕФЕЅдЊЪ§xЃЈjВуЕФЕЅдЊЪ§+1ЃЉ j+1ЕФЕЅдЊЪ§xЃЈjВуЕФЕЅдЊЪ§+1ЃЉ
2ЁЂДњМлКЏЪ§
МйЩшзюКѓЪфГіЕФ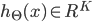 ЃЌМДДњБэЪфГіВугаKИіЕЅдЊ ЃЌМДДњБэЪфГіВугаKИіЕЅдЊ
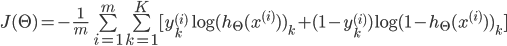 ЦфжаЃЌ
ЦфжаЃЌ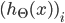 ДњБэЕкiИіЕЅдЊЪфГі ДњБэЕкiИіЕЅдЊЪфГі
гыТпМЛиЙщЕФДњМлКЏЪ§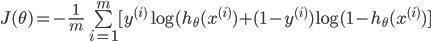 ВюВЛЖрЃЌОЭЪЧРлМгЩЯУПИіЪфГіЃЈЙВгаKИіЪфГіЃЉ ВюВЛЖрЃЌОЭЪЧРлМгЩЯУПИіЪфГіЃЈЙВгаKИіЪфГіЃЉ
3ЁЂе§дђЛЏ
L-->ЫљгаВуЕФИіЪ§
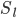 -->ЕкlВуunitЕФИіЪ§ -->ЕкlВуunitЕФИіЪ§
е§дђЛЏКѓЕФДњМлКЏЪ§ЮЊ
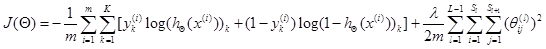
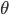 ЙВгаL-1ВуЃЌ ЙВгаL-1ВуЃЌ
ШЛКѓЪЧРлМгЖдгІУПвЛВуЕФthetaОиеѓЃЌзЂвтВЛАќКЌМгЩЯЦЋжУЯюЖдгІЕФtheta(0)
е§дђЛЏКѓЕФДњМлКЏЪ§ЪЕЯжДњТыЃК
# ДњМлКЏЪ§
def nnCostFunction(nn_params,input_layer_size,hidden
_layer_size,num_labels,X,y,Lambda):
length = nn_params.shape[0] # thetaЕФжаГЄЖШ
# ЛЙдtheta1КЭtheta2
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].
reshape(hidden_layer_size,input_layer_size+1)
Theta2 = nn_params[hidden_layer_size*(input_layer_
size+1):length].reshape(num_labels,hidden_layer_size+1)
# np.savetxt("Theta1.csv",Theta1,delimiter=',')
m = X.shape[0]
class_y = np.zeros((m,num_labels))
# Ъ§ОнЕФyЖдгІ0-9ЃЌашвЊгГЩфЮЊ0/1ЕФЙиЯЕ
# гГЩфy
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1)
#
зЂвтreshape(1,-1)ВХПЩвдИГжЕ
'''ШЅЕєtheta1КЭtheta2ЕФЕквЛСаЃЌвђЮЊе§дђЛЏЪБДг1ПЊЪМ'''
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
# е§дђЛЏЯђtheta^2
term = np.dot(np.transpose(np.vstack((Theta1_x.reshape(-1,1),
Theta2_x.reshape(-1,1)))),np.vstack((Theta1_
x.reshape(-1,1),Theta2_x.reshape(-1,1))))
'''е§ЯђДЋВЅ,УПДЮашвЊВЙЩЯвЛСа1ЕФЦЋжУbias'''
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
'''ДњМл'''
J = -(np.dot(np.transpose(class_y.reshape(-1,1))
,np.log(h.reshape(-1,1)))+np.dot(np.transpose(1-class_y.reshape(-1,1)),np.log(1-h.reshape(-1,1)))-Lambda*term/2)/m
return np.ravel(J)
|
4ЁЂЗДЯђДЋВЅBP
ЩЯУце§ЯђДЋВЅПЩвдМЦЫуЕУЕНJ(ІШ),ЪЙгУЬнЖШЯТНЕЗЈЛЙашвЊЧѓЫќЕФЬнЖШ
BPЗДЯђДЋВЅЕФФПЕФОЭЪЧЧѓДњМлКЏЪ§ЕФЬнЖШ
МйЩш4ВуЕФЩёОЭјТч,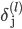 МЧЮЊ-->lВуЕкjИіЕЅдЊЕФЮѓВю МЧЮЊ-->lВуЕкjИіЕЅдЊЕФЮѓВю
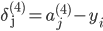 ЁЖ===ЁЗ ЁЖ===ЁЗ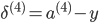 ЃЈЯђСПЛЏЃЉ ЃЈЯђСПЛЏЃЉ
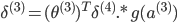
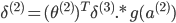
УЛга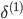 ЃЌвђЮЊЖдгкЪфШыУЛгаЮѓВю ЃЌвђЮЊЖдгкЪфШыУЛгаЮѓВю
вђЮЊSаЭКЏЪ§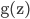 }ЕФЕМЪ§ЮЊЃК }ЕФЕМЪ§ЮЊЃК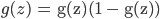 ЃЌЫљвдЩЯУцЕФ ЃЌЫљвдЩЯУцЕФ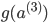 КЭ КЭ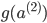 ПЩвддкЧАЯђДЋВЅжаМЦЫуГіРД ПЩвддкЧАЯђДЋВЅжаМЦЫуГіРД
ЗДЯђДЋВЅМЦЫуЬнЖШЕФЙ§ГЬЮЊЃК
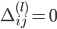 ЃЈ ЃЈ ЪЧДѓаДЕФ ЪЧДѓаДЕФ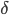 ЃЉ ЃЉ
for i=1-m:
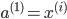
-е§ЯђДЋВЅМЦЫу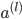 ЃЈl=2,3,4...LЃЉ ЃЈl=2,3,4...LЃЉ
-ЗДЯђМЦЫу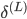 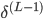 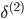 ЃЛ ЃЛ
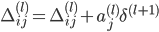
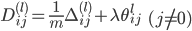
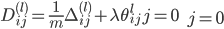
зюКѓ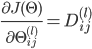 ЃЌМДЕУЕНДњМлКЏЪ§ЕФЬнЖШ ЃЌМДЕУЕНДњМлКЏЪ§ЕФЬнЖШ
ЪЕЯжДњТыЃК
# ЬнЖШ
def nnGradient(nn_params,input_layer_size,hidden_layer_
size,num_labels,X,y,Lambda):
length = nn_params.shape[0]
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].
reshape(hidden_layer_size,input_layer_size+1).copy()
# етРяЪЙгУcopyКЏЪ§ЃЌЗёдђЯТУцаоИФThetaЕФжЕЃЌnn_paramsвВЛсвЛЦ№аоИФ
Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].
reshape(num_labels,hidden_layer_size+1).copy()
m = X.shape[0]
class_y = np.zeros((m,num_labels)) # Ъ§ОнЕФyЖдгІ0-9ЃЌашвЊгГЩфЮЊ0/1ЕФЙиЯЕ
# гГЩфy
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) #
зЂвтreshape(1,-1)ВХПЩвдИГжЕ
'''ШЅЕєtheta1КЭtheta2ЕФЕквЛСаЃЌвђЮЊе§дђЛЏЪБДг1ПЊЪМ'''
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
Theta1_grad = np.zeros((Theta1.shape)) #ЕквЛВуЕНЕкЖўВуЕФШЈжи
Theta2_grad = np.zeros((Theta2.shape)) #ЕкЖўВуЕНЕкШ§ВуЕФШЈжи
'''е§ЯђДЋВЅЃЌУПДЮашвЊВЙЩЯвЛСа1ЕФЦЋжУbias'''
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
'''ЗДЯђДЋВЅЃЌdeltaЮЊЮѓВюЃЌ'''
delta3 = np.zeros((m,num_labels))
delta2 = np.zeros((m,hidden_layer_size))
for i in range(m):
#delta3[i,:] = (h[i,:]-class_y[i,:])*sigmoidGradient(z3[i,:])
# ОљЗНЮѓВюЕФЮѓВюТЪ
delta3[i,:] = h[i,:]-class_y[i,:] # НЛВцьиЮѓВюТЪ
Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:]
.reshape(1,-1)),a2[i,:].reshape(1,-1))
delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x
)*sigmoidGradient(z2[i,:])
Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:]
.reshape(1,-1)),a1[i,:].reshape(1,-1))
Theta1[:,0] = 0
Theta2[:,0] = 0
'''ЬнЖШ'''
grad = (np.vstack((Theta1_grad.reshape(-1,1),
Theta2_grad.reshape(-1,1)))+Lambda*np.vstack
((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/m
return np.ravel(grad)
|
5ЁЂBPПЩвдЧѓЬнЖШЕФдвђ
ЪЕМЪЪЧРћгУСЫСДЪНЧѓЕМЗЈдђ
вђЮЊЯТвЛВуЕФЕЅдЊРћгУЩЯвЛВуЕФЕЅдЊзїЮЊЪфШыНјааМЦЫу
ДѓЬхЕФЭЦЕМЙ§ГЬШчЯТЃЌзюжеЮвУЧЪЧЯыдЄВтКЏЪ§гывбжЊЕФyЗЧГЃНгНќЃЌЧѓОљЗНВюЕФЬнЖШбизХДЫЬнЖШЗНЯђПЩЪЙДњМлКЏЪ§зюаЁЛЏЁЃПЩЖдееЩЯУцЧѓЬнЖШЕФЙ§ГЬЁЃ

ЧѓЮѓВюИќЯъЯИЕФЭЦЕМЙ§ГЬЃК
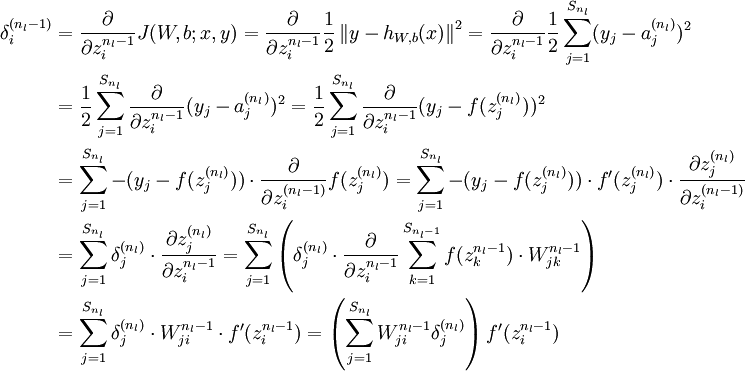
6ЁЂЬнЖШМьВщ
МьВщРћгУBPЧѓЕФЬнЖШЪЧЗёе§ШЗ
РћгУЕМЪ§ЕФЖЈвхбщжЄЃК
ЧѓГіРДЕФЪ§жЕЬнЖШгІИУгыBPЧѓГіЕФЬнЖШЗЧГЃНгНќ
бщжЄBPе§ШЗКѓОЭВЛашвЊдйжДаабщжЄЬнЖШЕФЫуЗЈСЫ
ЪЕЯжДњТыЃК
# МьбщЬнЖШЪЧЗёМЦЫуе§ШЗ
# МьбщЬнЖШЪЧЗёМЦЫуе§ШЗ
def checkGradient(Lambda = 0):
'''ЙЙдьвЛИіаЁаЭЕФЩёОЭјТчбщжЄЃЌвђЮЊЪ§жЕЗЈМЦЫуЬнЖШКмРЫ
ЗбЪБМфЃЌЖјЧвбщжЄе§ШЗКѓжЎКѓОЭВЛдйашвЊбщжЄСЫ'''
input_layer_size = 3
hidden_layer_size = 5
num_labels = 3
m = 5
initial_Theta1 = debugInitializeWeights(input_layer_size,
hidden_layer_size);
initial_Theta2 = debugInitializeWeights
(hidden_layer_size,num_labels)
X = debugInitializeWeights(input_layer_size-1,m)
y = 1+np.transpose(np.mod(np.arange(1,m+1), num_labels))
#
ГѕЪМЛЏy
y = y.reshape(-1,1)
nn_params = np.vstack((initial_Theta1.reshape(-1,1),
initial_Theta2.reshape(-1,1)))
#еЙПЊtheta
'''BPЧѓГіЬнЖШ'''
grad = nnGradient(nn_params, input_layer_size,
hidden_layer_size,
num_labels, X, y, Lambda)
'''ЪЙгУЪ§жЕЗЈМЦЫуЬнЖШ'''
num_grad = np.zeros((nn_params.shape[0]))
step = np.zeros((nn_params.shape[0]))
e = 1e-4
for i in range(nn_params.shape[0]):
step[i] = e
loss1 = nnCostFunction(nn_params-step.reshape(-1,1),
input_layer_size, hidden_layer_size,
num_labels, X, y,
Lambda)
loss2 = nnCostFunction(nn_params+step.reshape(-1,1),
input_layer_size, hidden_layer_size,
num_labels, X, y,
Lambda)
num_grad[i] = (loss2-loss1)/(2*e)
step[i]=0
# ЯдЪОСНСаБШНЯ
res = np.hstack((num_grad.reshape(-1,1),
grad.reshape(-1,1)))
print res
|
7ЁЂШЈжиЕФЫцЛњГѕЪМЛЏ
ЩёОЭјТчВЛФмЯёТпМЛиЙщФЧбљГѕЪМЛЏthetaЮЊ0,вђЮЊШєЪЧУПЬѕБпЕФШЈжиЖМЮЊ0ЃЌУПИіЩёОдЊЖМЪЧЯрЭЌЕФЪфГіЃЌдкЗДЯђДЋВЅжавВЛсЕУЕНЭЌбљЕФЬнЖШЃЌзюжежЛЛсдЄВтвЛжжНсЙћЁЃ
ЫљвдгІИУГѕЪМЛЏЮЊНгНќ0ЕФЪ§
ЪЕЯжДњТы
# ЫцЛњГѕЪМЛЏШЈжиtheta
def randInitializeWeights(L_in,L_out):
W = np.zeros((L_out,1+L_in)) # ЖдгІthetaЕФШЈжи
epsilon_init = (6.0/(L_out+L_in))**0.5
W = np.random.rand(L_out,1+L_in)*2*epsilon_init-epsilon_init
# np.random.rand(L_out,1+L_in)ВњЩњL_out*(1+L_in)ДѓаЁЕФЫцЛњОиеѓ
return W
|
8ЁЂдЄВт
е§ЯђДЋВЅдЄВтНсЙћ
ЪЕЯжДњТы
# дЄВт
def predict(Theta1,Theta2,X):
m = X.shape[0]
num_labels = Theta2.shape[0]
#p = np.zeros((m,1))
'''е§ЯђДЋВЅЃЌдЄВтНсЙћ'''
X = np.hstack((np.ones((m,1)),X))
h1 = sigmoid(np.dot(X,np.transpose(Theta1)))
h1 = np.hstack((np.ones((m,1)),h1))
h2 = sigmoid(np.dot(h1,np.transpose(Theta2)))
'''
ЗЕЛиhжаУПвЛаазюДѓжЕЫљдкЕФСаКХ
- np.max(h, axis=1)ЗЕЛиhжаУПвЛааЕФзюДѓжЕЃЈЪЧФГИіЪ§зжЕФзюДѓИХТЪЃЉ
- зюКѓwhereевЕНЕФзюДѓИХТЪЫљдкЕФСаКХЃЈСаКХМДЪЧЖдгІЕФЪ§зжЃЉ
'''
#np.savetxt("h2.csv",h2,delimiter=',')
p = np.array(np.where(h2[0,:] == np.max(h2, axis=1)[0]))
for i in np.arange(1, m):
t = np.array(np.where(h2[i,:] == np.max(h2, axis=1)[i]))
p = np.vstack((p,t))
return p
|
9ЁЂЪфГіНсЙћ
ЬнЖШМьВщЃК
ЫцЛњЯдЪО100ИіЪжаДЪ§зж

ЯдЪОtheta1ШЈжи

бЕСЗМЏдЄВтзМШЗЖШ
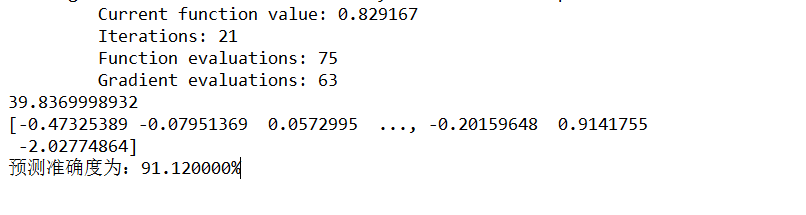
ЙщвЛЛЏКѓбЕСЗМЏдЄВтзМШЗЖШ
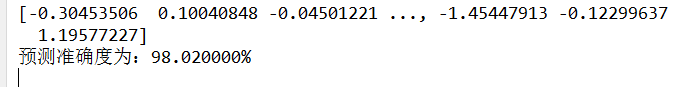
ЫФЁЂSVMжЇГжЯђСПЛњ
1ЁЂДњМлКЏЪ§
дкТпМЛиЙщжаЃЌЮвУЧЕФДњМлЮЊЃК
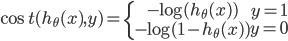
ЦфжаЃК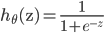 ЃЌ ЃЌ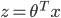
ШчЭМЫљЪОЃЌШчЙћy=1ЃЌcostДњМлКЏЪ§ШчЭМЫљЪО
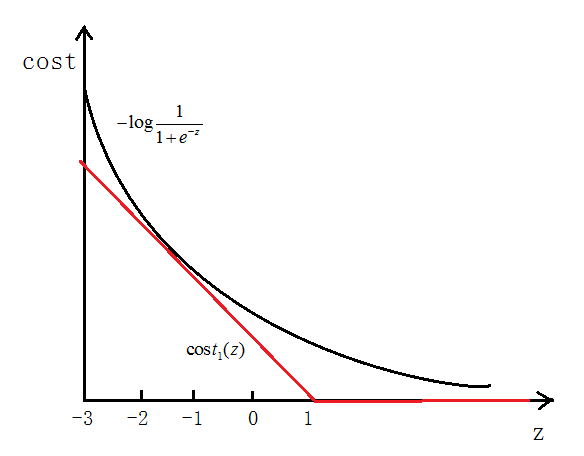
ЮвУЧЯыШУ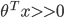 ЃЌМДz>>0ЃЌетбљЕФЛАcostДњМлКЏЪ§ВХЛсЧїгкзюаЁЃЈетЪЧЮвУЧЯывЊЕФЃЉЃЌЫљвдгУЭОжаКьЩЋЕФКЏЪ§ ЃЌМДz>>0ЃЌетбљЕФЛАcostДњМлКЏЪ§ВХЛсЧїгкзюаЁЃЈетЪЧЮвУЧЯывЊЕФЃЉЃЌЫљвдгУЭОжаКьЩЋЕФКЏЪ§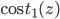 ДњЬцТпМЛиЙщжаЕФcost ДњЬцТпМЛиЙщжаЕФcost
ЕБy=0ЪБЭЌбљЃЌгУ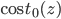 ДњЬц ДњЬц
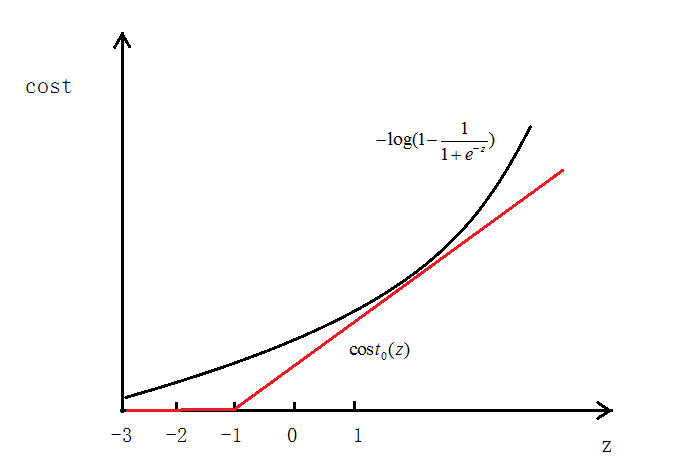
зюжеЕУЕНЕФДњМлКЏЪ§ЮЊЃК
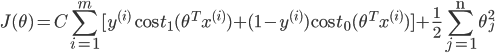
зюКѓЮвУЧЯывЊ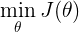
жЎЧАЮвУЧТпМЛиЙщжаЕФДњМлКЏЪ§ЮЊЃК
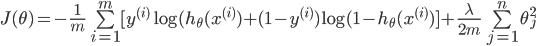
ПЩвдШЯЮЊетРяЕФ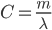 ЃЌжЛЪЧБэДяаЮЪНЮЪЬтЃЌетРяCЕФжЕдНДѓЃЌSVMЕФОіВпБпНчЕФmarginвВдНДѓЃЌЯТУцЛсЫЕУї ЃЌжЛЪЧБэДяаЮЪНЮЪЬтЃЌетРяCЕФжЕдНДѓЃЌSVMЕФОіВпБпНчЕФmarginвВдНДѓЃЌЯТУцЛсЫЕУї
2ЁЂLarge Margin
ШчЯТЭМЫљЪО,SVMЗжРрЛсЪЙгУзюДѓЕФmarginНЋЦфЗжПЊ 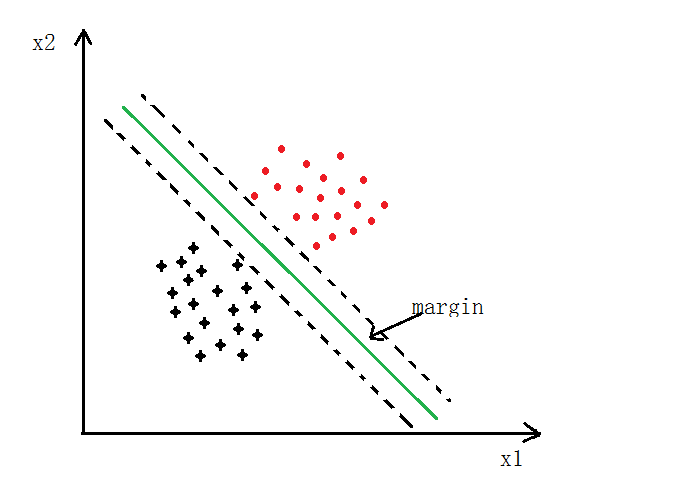
ЯШЫЕвЛЯТЯђСПФкЛ§
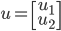 ЃЌ
ЃЌ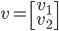
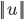 БэЪОuЕФХЗМИРяЕУЗЖЪ§ЃЈХЗЪНЗЖЪ§ЃЉЃЌ
БэЪОuЕФХЗМИРяЕУЗЖЪ§ЃЈХЗЪНЗЖЪ§ЃЉЃЌ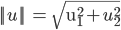
ЯђСПVдкЯђСПuЩЯЕФЭЖгАЕФГЄЖШМЧЮЊpЃЌдђЃКЯђСПФкЛ§ЃК
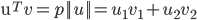
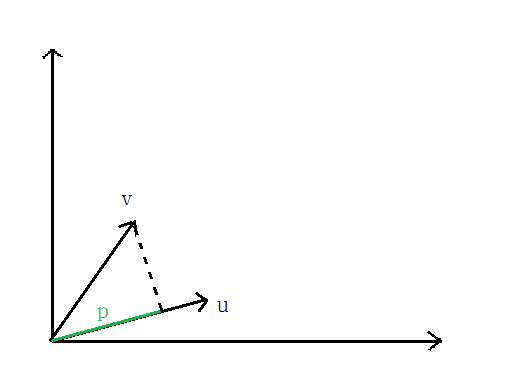
ИљОнЯђСПМаНЧЙЋЪНЭЦЕМвЛЯТМДПЩЃЌ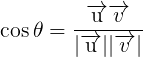
ЧАУцЫЕЙ§ЃЌЕБCдНДѓЪБЃЌmarginвВОЭдНДѓЃЌЮвУЧЕФФПЕФЪЧзюаЁЛЏДњМлКЏЪ§J(ІШ),ЕБmarginзюДѓЪБЃЌCЕФГЫЛ§Яю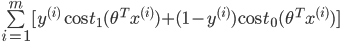 вЊКмаЁЃЌЫљвдНќЫЦЮЊЃК вЊКмаЁЃЌЫљвдНќЫЦЮЊЃК
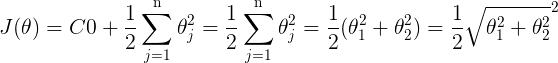 ЃЌ ЃЌ
ЮвУЧзюКѓЕФФПЕФОЭЪЧЧѓЪЙДњМлзюаЁЕФІШ
гЩ
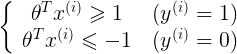 ПЩвдЕУЕНЃК ПЩвдЕУЕНЃК
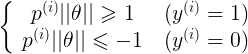 ЃЌpМДЮЊxдкІШЩЯЕФЭЖгА ЃЌpМДЮЊxдкІШЩЯЕФЭЖгА
ШчЯТЭМЫљЪОЃЌМйЩшОіВпБпНчШчЭМЃЌевЦфжаЕФвЛИіЕуЃЌЕНІШЩЯЕФЭЖгАЮЊp,дђ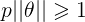 Лђеп Лђеп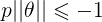 ЃЌШєЪЧpКмаЁЃЌдђашвЊ ЃЌШєЪЧpКмаЁЃЌдђашвЊ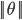 КмДѓЃЌетгыЮвУЧвЊЧѓЕФІШЪЙ КмДѓЃЌетгыЮвУЧвЊЧѓЕФІШЪЙ зюаЁЯрЮЅБГЃЌЫљвдзюКѓЧѓЕФЪЧlarge
margin зюаЁЯрЮЅБГЃЌЫљвдзюКѓЧѓЕФЪЧlarge
margin
3ЁЂSVM KernelЃЈКЫКЏЪ§ЃЉ
ЖдгкЯпадПЩЗжЕФЮЪЬтЃЌЪЙгУЯпадКЫКЏЪ§МДПЩ
ЖдгкЯпадВЛПЩЗжЕФЮЪЬтЃЌдкТпМЛиЙщжаЃЌЮвУЧЪЧНЋfeatureгГЩфЮЊЪЙгУЖрЯюЪНЕФаЮЪН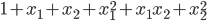 ЃЌSVMжавВгаЖрЯюЪНКЫКЏЪ§ЃЌЕЋЪЧИќГЃгУЕФЪЧИпЫЙКЫКЏЪ§ЃЌвВГЦЮЊRBFКЫ ЃЌSVMжавВгаЖрЯюЪНКЫКЏЪ§ЃЌЕЋЪЧИќГЃгУЕФЪЧИпЫЙКЫКЏЪ§ЃЌвВГЦЮЊRBFКЫ
ИпЫЙКЫКЏЪ§ЮЊЃК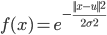
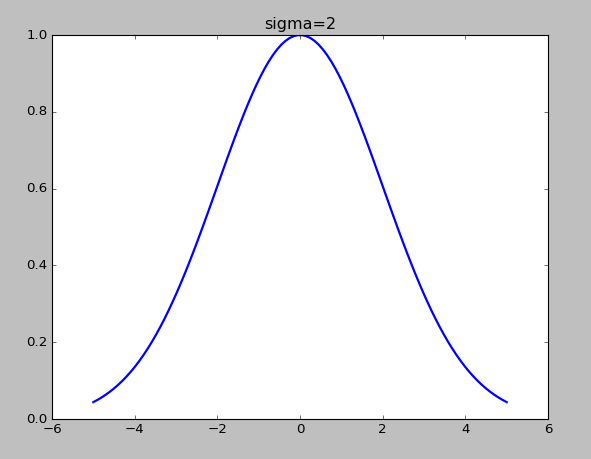
МйЩшШчЭММИИіЕуЃЌ  СюЃК СюЃК
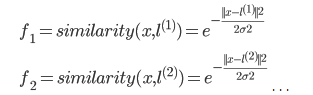
ПЩвдПДГіЃЌШєЪЧxгы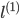 ОрРыНЯНќЃЌ==ЁЗ ОрРыНЯНќЃЌ==ЁЗ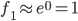 ЃЌЃЈМДЯрЫЦЖШНЯДѓЃЉ ЃЌЃЈМДЯрЫЦЖШНЯДѓЃЉ
ШєЪЧxгы ОрРыНЯдЖЃЌ==ЁЗ ОрРыНЯдЖЃЌ==ЁЗ ЃЌЃЈМДЯрЫЦЖШНЯЕЭЃЉ ЃЌЃЈМДЯрЫЦЖШНЯЕЭЃЉ
ИпЫЙКЫКЏЪ§ЕФІвдНаЁЃЌfЯТНЕЕФдНПь 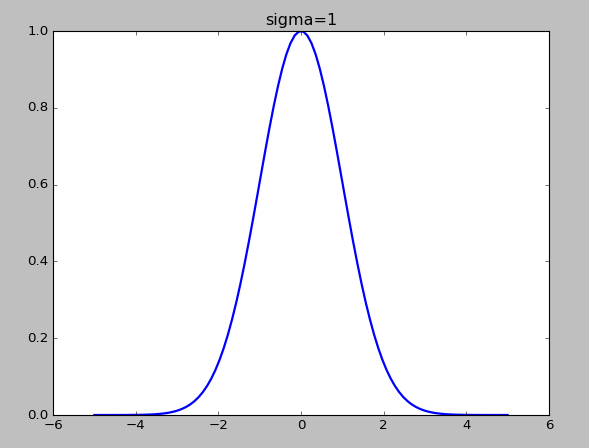
ШчКЮбЁдёГѕЪМЕФ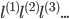
бЕСЗМЏЃК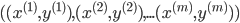
бЁдёЃК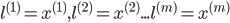
ЖдгкИјГіЕФxЃЌМЦЫуf,СюЃК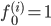 ЫљвдЃК
ЫљвдЃК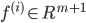
зюаЁЛЏJЧѓГіІШЃЌ
ШчЙћ ЃЌ==ЁЗдЄВтy=1
ЃЌ==ЁЗдЄВтy=1
4ЁЂЪЙгУscikit-learnжаЕФSVMФЃаЭДњТы
ШЋВПДњТы
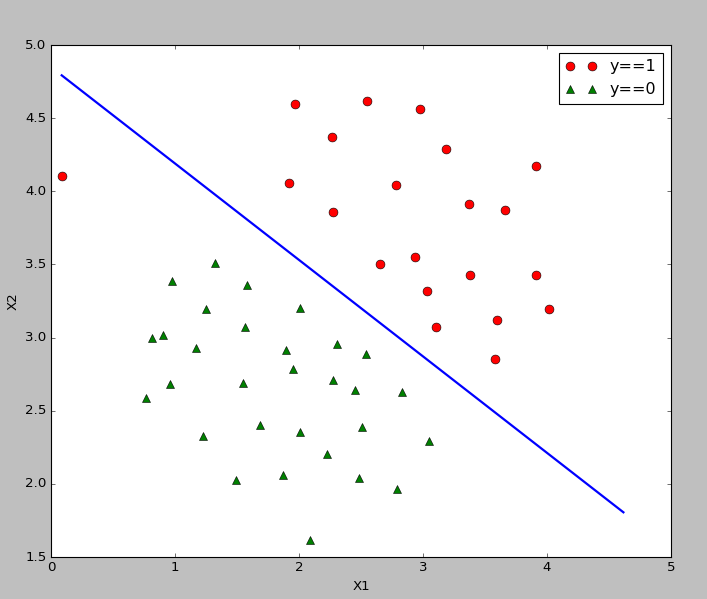
ЯпадПЩЗжЕФ,жИЖЈКЫКЏЪ§ЮЊlinearЃК
'''data1ЁЊЁЊЯпадЗжРр'''
data1 = spio.loadmat('data1.mat')
X = data1['X']
y = data1['y']
y = np.ravel(y)
plot_data(X,y)
model = svm.SVC(C=1.0,kernel='linear').fit(X,y)
# жИЖЈКЫКЏЪ§ЮЊЯпадКЫКЏЪ§
|
ЗЧЯпадПЩЗжЕФЃЌФЌШЯКЫКЏЪ§ЮЊrbf
'''data2ЁЊЁЊЗЧЯпадЗжРр'''
data2 = spio.loadmat('data2.mat')
X = data2['X']
y = data2['y']
y = np.ravel(y)
plt = plot_data(X,y)
plt.show()
model = svm.SVC(gamma=100).fit(X,y) # gammaЮЊКЫКЏЪ§ЕФЯЕЪ§ЃЌжЕдНДѓФтКЯЕФдНКУ
|
5ЁЂдЫааНсЙћ
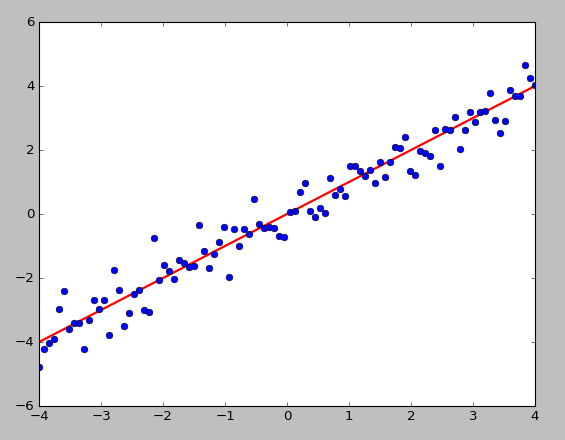
ЯпадПЩЗжЕФОіВпБпНчЃК
ЯпадВЛПЩЗжЕФОіВпБпНчЃК

ЮхЁЂK-MeansОлРрЫуЗЈ
ШЋВПДњТы
1ЁЂОлРрЙ§ГЬ
ОлРрЪєгкЮоМрЖНбЇЯАЃЌВЛжЊЕРyЕФБъМЧЗжЮЊKРр
K-MeansЫуЗЈЗжЮЊСНИіВНжш
ЕквЛВНЃКДиЗжХфЃЌЫцЛњбЁKИіЕузїЮЊжааФЃЌМЦЫуЕНетKИіЕуЕФОрРыЃЌЗжЮЊKИіДи
ЕкЖўВНЃКвЦЖЏОлРржааФЃКжиаТМЦЫуУПИіДиЕФжааФЃЌвЦЖЏжааФЃЌжиИДвдЩЯВНжшЁЃ
ШчЯТЭМЫљЪОЃК
ЫцЛњЗжХфЕФОлРржааФ 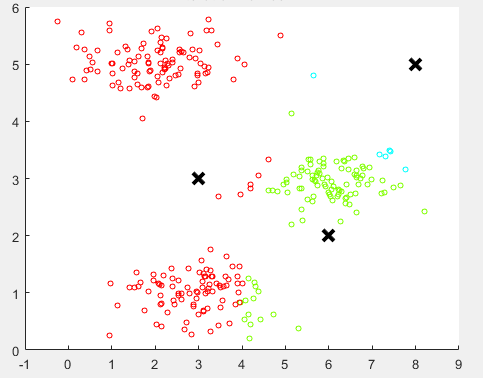
жиаТМЦЫуОлРржааФЃЌвЦЖЏвЛДЮ 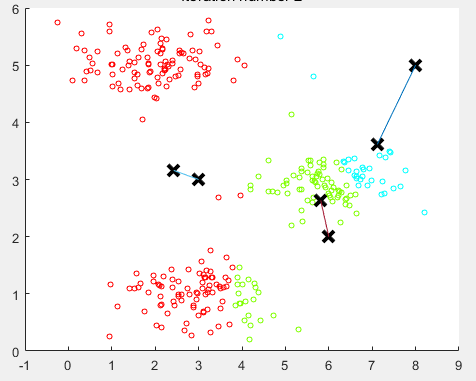
зюКѓ10ВНжЎКѓЕФОлРржааФ 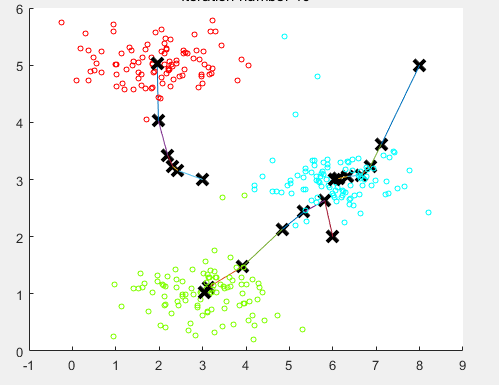
МЦЫуУПЬѕЪ§ОнЕНФФИіжааФзюНќЪЕЯжДњТыЃК
# евЕНУПЬѕЪ§ОнОрРыФФИіРржааФзюНќ
def findClosestCentroids(X,initial_centroids):
m = X.shape[0] # Ъ§ОнЬѕЪ§
K = initial_centroids.shape[0] # РрЕФзмЪ§
dis = np.zeros((m,K)) # ДцДЂМЦЫуУПИіЕуЗжБ№ЕНKИіРрЕФОрРы
idx = np.zeros((m,1)) # вЊЗЕЛиЕФУПЬѕЪ§ОнЪєгкФФИіРр
'''МЦЫуУПИіЕуЕНУПИіРржааФЕФОрРы'''
for i in range(m):
for j in range(K):
dis[i,j] = np.dot((X[i,:]-initial_centroids[j,:]).reshape(1,-1),(X[i,:]-initial_centroids[j,:]).reshape(-1,1))
'''ЗЕЛиdisУПвЛааЕФзюаЁжЕЖдгІЕФСаКХЃЌМДЮЊЖдгІЕФРрБ№
- np.min(dis, axis=1)ЗЕЛиУПвЛааЕФзюаЁжЕ
- np.where(dis == np.min(dis, axis=1).reshape(-1,1))
ЗЕЛиЖдгІзюаЁжЕЕФзјБъ
- зЂвтЃКПЩФмзюаЁжЕЖдгІЕФзјБъгаЖрИіЃЌwhereЖМЛсевГіРДЃЌЫљвдЗЕЛиЪБЗЕЛиЧАmИіашвЊЕФМДПЩЃЈвђЮЊЖдгкЖрИізюаЁжЕЃЌЪєгкФФИіРрБ№ЖМПЩвдЃЉ
'''
dummy,idx = np.where(dis == np.min(dis, axis=1).reshape(-1,1))
return idx[0:dis.shape[0]] # зЂвтНиШЁвЛЯТ
|
МЦЫуРржааФЪЕЯжДњТыЃК
# МЦЫуРржааФ
def computerCentroids(X,idx,K):
n = X.shape[1]
centroids = np.zeros((K,n))
for i in range(K):
centroids[i,:] = np.mean(X[np.ravel(idx==i),:],
axis=0).reshape(1,-1) # Ыїв§вЊЪЧвЛЮЌЕФ,axis=0ЮЊУПвЛСаЃЌidx==iвЛДЮевГіЪєгкФФвЛРрЕФЃЌШЛКѓМЦЫуОљжЕ
return centroids
|
2ЁЂФПБъКЏЪ§
вВНазіЪЇецДњМлКЏЪ§
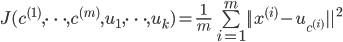
зюКѓЮвУЧЯыЕУЕНЃК
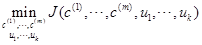
Цфжа БэЪОЕкiЬѕЪ§ОнОрРыФФИіРржааФзюНќЃЌ БэЪОЕкiЬѕЪ§ОнОрРыФФИіРржааФзюНќЃЌ
Цфжа МДЮЊОлРрЕФжааФ МДЮЊОлРрЕФжааФ
3ЁЂОлРржааФЕФбЁдё
ЫцЛњГѕЪМЛЏЃЌДгИјЖЈЕФЪ§ОнжаЫцЛњГщШЁKИізїЮЊОлРржааФ
ЫцЛњвЛДЮЕФНсЙћПЩФмВЛКУЃЌПЩвдЫцЛњЖрДЮЃЌзюКѓШЁЪЙДњМлКЏЪ§зюаЁЕФзїЮЊжааФ
ЪЕЯжДњТыЃК(етРяЫцЛњвЛДЮ)
# ГѕЪМЛЏРржааФ--ЫцЛњШЁKИіЕузїЮЊОлРржааФ
def kMeansInitCentroids(X,K):
m = X.shape[0]
m_arr = np.arange(0,m) # ЩњГЩ0-m-1
centroids = np.zeros((K,X.shape[1]))
np.random.shuffle(m_arr) # ДђТвm_arrЫГађ
rand_indices = m_arr[:K] # ШЁЧАKИі
centroids = X[rand_indices,:]
return centroids
|
4ЁЂОлРрИіЪ§KЕФбЁдё
ОлРрЪЧВЛжЊЕРyЕФlabelЕФЃЌЫљвдВЛжЊЕРеце§ЕФОлРрИіЪ§
жтВПЗЈдђЃЈElbow methodЃЉ
зїДњМлКЏЪ§JКЭKЕФЭМЃЌШєЪЧГіЯжвЛИіЙеЕуЃЌШчЯТЭМЫљЪОЃЌKОЭШЁЙеЕуДІЕФжЕЃЌЯТЭМДЫЪБK=3
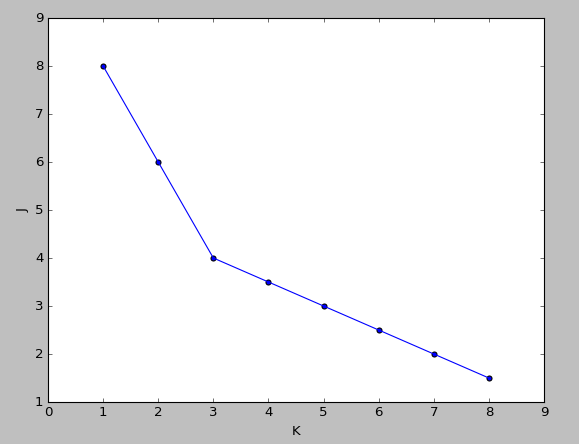
ШєЪЧКмЦНЛЌОЭВЛУїШЗЃЌШЫЮЊбЁдёЁЃ
ЕкЖўжжОЭЪЧШЫЮЊЙлВьбЁдё
5ЁЂгІгУЁЊЁЊЭМЦЌбЙЫѕ
НЋЭМЦЌЕФЯёЫиЗжЮЊШєИЩРрЃЌШЛКѓгУетИіРрДњЬцдРДЕФЯёЫижЕ
жДааОлРрЕФЫуЗЈДњТыЃК
# ОлРрЫуЗЈ
def runKMeans(X,initial_centroids,max_iters,plot_process):
m,n = X.shape # Ъ§ОнЬѕЪ§КЭЮЌЖШ
K = initial_centroids.shape[0] # РрЪ§
centroids = initial_centroids # МЧТМЕБЧАРржааФ
previous_centroids = centroids # МЧТМЩЯвЛДЮРржааФ
idx = np.zeros((m,1)) # УПЬѕЪ§ОнЪєгкФФИіРр
for i in range(max_iters): # ЕќДњДЮЪ§
print u'ЕќДњМЦЫуДЮЪ§ЃК%d'%(i+1)
idx = findClosestCentroids(X, centroids)
if plot_process: # ШчЙћЛцжЦЭМЯё
plt = plotProcessKMeans(X,centroids,previous_centroids)
# ЛОлРржааФЕФвЦЖЏЙ§ГЬ
previous_centroids = centroids # жижУ
centroids = computerCentroids(X, idx, K) # жиаТМЦЫуРржааФ
if plot_process: # ЯдЪОзюжеЕФЛцжЦНсЙћ
plt.show()
return centroids,idx # ЗЕЛиОлРржааФКЭЪ§ОнЪєгкФФИіРр
|
6ЁЂЪЙгУscikit-learnПтжаЕФЯпадФЃаЭЪЕЯжОлРр
ЕМШыАќ
from sklearn.cluster
import KMeans
|
ЪЙгУФЃаЭФтКЯЪ§Он
model = KMeans(n_clusters=3).fit(X)
# n_clustersжИЖЈ3РрЃЌФтКЯЪ§Он
|
ОлРржааФ
centroids =
model.cluster_centers_ # ОлРржааФ
|
7ЁЂдЫааНсЙћ
ЖўЮЌЪ§ОнРржааФЕФвЦЖЏ
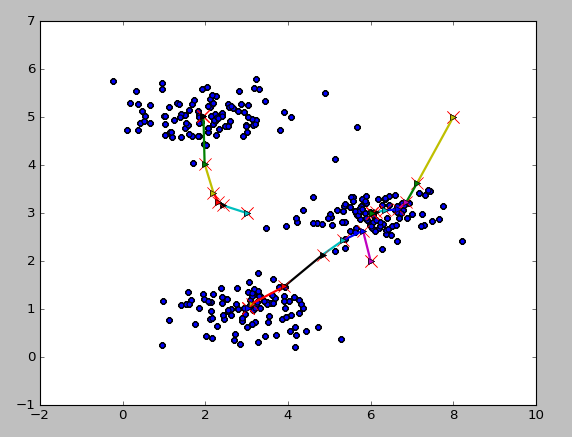
ЭМЦЌбЙЫѕ
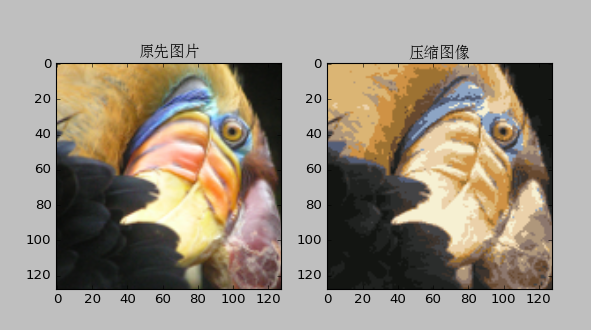
СљЁЂPCAжїГЩЗжЗжЮіЃЈНЕЮЌЃЉ
ШЋВПДњТы
1ЁЂгУДІ
Ъ§ОнбЙЫѕЃЈData CompressionЃЉ,ЪЙГЬађдЫааИќПь
ПЩЪгЛЏЪ§ОнЃЌР§Шч3D-->2DЕШ
......
2ЁЂ2D-->1DЃЌnD-->kD
ШчЯТЭМЫљЪОЃЌЫљгаЪ§ОнЕуПЩвдЭЖгАЕНвЛЬѕжБЯпЃЌЪЧЭЖгАОрРыЕФЦНЗНКЭЃЈЭЖгАЮѓВюЃЉзюаЁ
зЂвтЪ§ОнашвЊЙщвЛЛЏДІРэ
ЫМТЗЪЧев1ИіЯђСПu,ЫљгаЪ§ОнЭЖгАЕНЩЯУцЪЙЭЖгАОрРызюаЁ
ФЧУДnD-->kDОЭЪЧевkИіЯђСП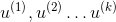 ЃЌЫљгаЪ§ОнЭЖгАЕНЩЯУцЪЙЭЖгАЮѓВюзюаЁ
ЃЌЫљгаЪ§ОнЭЖгАЕНЩЯУцЪЙЭЖгАЮѓВюзюаЁ
eg:3D-->2D,2ИіЯђСП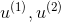 ОЭДњБэвЛИіЦНУцСЫЃЌЫљгаЕуЭЖгАЕНетИіЦНУцЕФЭЖгАЮѓВюзюаЁМДПЩ
ОЭДњБэвЛИіЦНУцСЫЃЌЫљгаЕуЭЖгАЕНетИіЦНУцЕФЭЖгАЮѓВюзюаЁМДПЩ
3ЁЂжїГЩЗжЗжЮіPCAгыЯпадЛиЙщЕФЧјБ№
ЯпадЛиЙщЪЧевxгыyЕФЙиЯЕЃЌШЛКѓгУгкдЄВтy
PCAЪЧеввЛИіЭЖгАУцЃЌзюаЁЛЏdataЕНетИіЭЖгАУцЕФЭЖгАЮѓВю
4ЁЂPCAНЕЮЌЙ§ГЬ
Ъ§ОндЄДІРэЃЈОљжЕЙщвЛЛЏЃЉ
ЙЋЪНЃК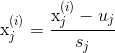
ОЭЪЧМѕШЅЖдгІfeatureЕФОљжЕЃЌШЛКѓГ§вдЖдгІЬиеїЕФБъзМВюЃЈвВПЩвдЪЧзюДѓжЕ-зюаЁжЕЃЉ
ЪЕЯжДњТыЃК
# ЙщвЛЛЏЪ§Он
def featureNormalize(X):
'''ЃЈУПвЛИіЪ§Он-ЕБЧАСаЕФОљжЕЃЉ/ЕБЧАСаЕФБъзМВю'''
n = X.shape[1]
mu = np.zeros((1,n));
sigma = np.zeros((1,n))
mu = np.mean(X,axis=0)
sigma = np.std(X,axis=0)
for i in range(n):
X[:,i] = (X[:,i]-mu[i])/sigma[i]
return X,mu,sigma
|
МЦЫуаЗНВюОиеѓІВЃЈCovariance MatrixЃЉЃК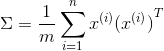
зЂвтетРяЕФІВКЭЧѓКЭЗћКХВЛЭЌ
аЗНВюОиеѓЖдГЦе§ЖЈЃЈВЛРэНте§ЖЈЕФПДПДЯпДњЃЉ
ДѓаЁЮЊnxn,nЮЊfeatureЕФЮЌЖШ
ЪЕЯжДњТыЃК
Sigma = np.dot(np.transpose(X_norm),X_norm)/m
# ЧѓSigma
|
МЦЫуІВЕФЬиеїжЕКЭЬиеїЯђСП
ПЩвдЪЧгУsvdЦцвьжЕЗжНтКЏЪ§ЃКU,S,V = svd(ІВ)
ЗЕЛиЕФЪЧгыІВЭЌбљДѓаЁЕФЖдНЧеѓSЃЈгЩІВЕФЬиеїжЕзщГЩЃЉ[зЂвтЃКmatlabжаКЏЪ§ЗЕЛиЕФЪЧЖдНЧеѓЃЌдкpythonжаЗЕЛиЕФЪЧвЛИіЯђСПЃЌНкЪЁПеМф]
ЛЙгаСНИігЯОиеѓUКЭVЃЌЧв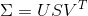
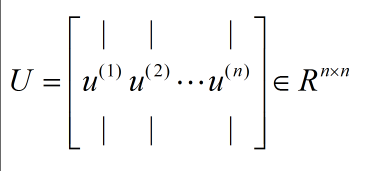
зЂвтЃКsvdКЏЪ§ЧѓГіЕФSЪЧАДЬиеїжЕНЕађХХСаЕФЃЌШєВЛЪЧЪЙгУsvd,ашвЊАДЬиеїжЕДѓаЁжиаТХХСаU
НЕЮЌ
бЁШЁUжаЕФЧАKСаЃЈМйЩшвЊНЕЮЊKЮЌЃЉ
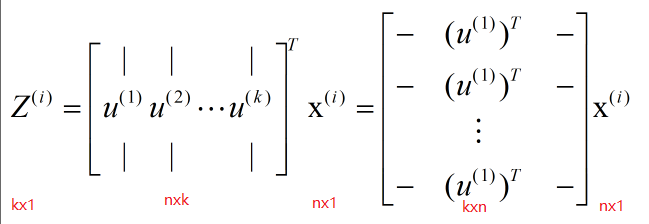
ZОЭЪЧЖдгІНЕЮЌжЎКѓЕФЪ§Он
ЪЕЯжДњТыЃК
# гГЩфЪ§Он
def projectData(X_norm,U,K):
Z = np.zeros((X_norm.shape[0],K))
U_reduce = U[:,0:K] # ШЁЧАKИі
Z = np.dot(X_norm,U_reduce)
return Z
|
Й§ГЬзмНсЃК
Sigma = X'*X/m
U,S,V = svd(Sigma)
Ureduce = U[:,0:k]
Z = Ureduce'*x
5ЁЂЪ§ОнЛжИД
вђЮЊЃК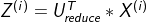
ЫљвдЃК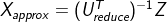 ЃЈзЂвтетРяЪЧXЕФНќЫЦжЕЃЉ
ЃЈзЂвтетРяЪЧXЕФНќЫЦжЕЃЉ
гжвђЮЊUreduceЮЊе§ЖЈОиеѓЃЌЁОе§ЖЈОиеѓТњзуЃК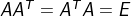 ЃЌЫљвдЃК ЃЌЫљвдЃК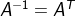 ЁПЃЌЫљвдетРяЃК ЁПЃЌЫљвдетРяЃК
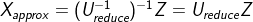
ЪЕЯжДњТыЃК
# ЛжИДЪ§Он
def recoverData(Z,U,K):
X_rec = np.zeros((Z.shape[0],U.shape[0]))
U_recude = U[:,0:K]
X_rec = np.dot(Z,np.transpose(U_recude)) # ЛЙдЪ§ОнЃЈНќЫЦЃЉ
return X_rec
|
6ЁЂжїГЩЗжИіЪ§ЕФбЁдёЃЈМДвЊНЕЕФЮЌЖШЃЉ
ШчКЮбЁдё
ЭЖгАЮѓВюЃЈproject errorЃЉЃК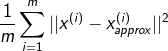
змБфВюЃЈtotal variationЃЉ: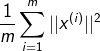
ШєЮѓВюТЪЃЈerror ratioЃЉЃК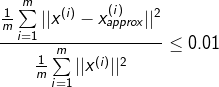 ЃЌдђГЦ99%БЃСєВювьад ЃЌдђГЦ99%БЃСєВювьад
ЮѓВюТЪвЛАуШЁ1%ЃЌ5%ЃЌ10%ЕШ
ШчКЮЪЕЯж
ШєЪЧвЛИіИіЪдЕФЛАДњМлЬЋДѓ
жЎЧАU,S,V = svd(Sigma),ЮвУЧЕУЕНСЫSЃЌетРяЮѓВюТЪerror ratio:
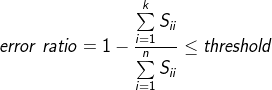
ПЩвдвЛЕуЕудіМгKГЂЪдЁЃ
7ЁЂЪЙгУНЈвщ
ВЛвЊЪЙгУPCAШЅНтОіЙ§ФтКЯЮЪЬтOverfittingЃЌЛЙЪЧЪЙгУе§дђЛЏЕФЗНЗЈЃЈШчЙћБЃСєСЫКмИпЕФВювьадЛЙЪЧПЩвдЕФЃЉ
жЛгадкдЪ§ОнЩЯгаКУЕФНсЙћЃЌЕЋЪЧдЫааКмТ§ЃЌВХПМТЧЪЙгУPCA
8ЁЂдЫааНсЙћ
2ЮЌЪ§ОнНЕЮЊ1ЮЌ
вЊЭЖгАЕФЗНЯђ 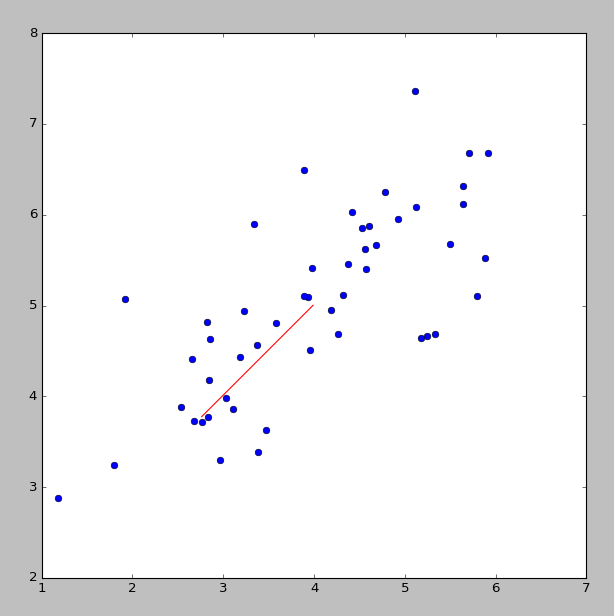
2DНЕЮЊ1DМАЖдгІЙиЯЕ 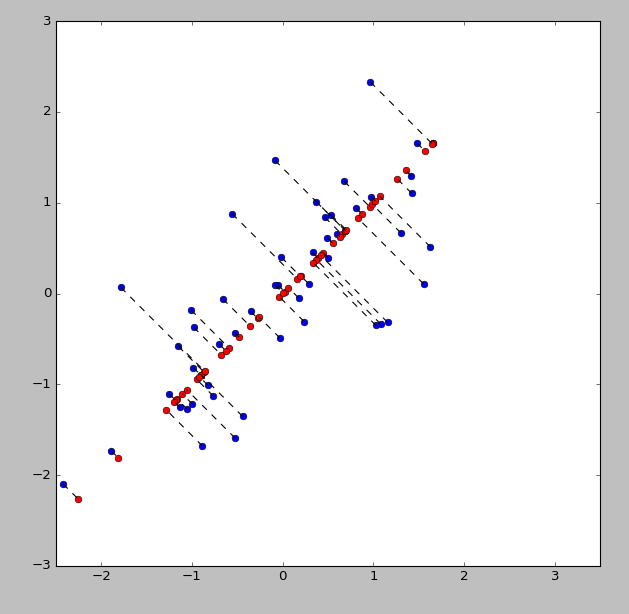
ШЫСГЪ§ОнНЕЮЌ
дЪМЪ§Он 
ПЩЪгЛЏВПЗжUОиеѓаХЯЂ 
ЛжИДЪ§Он 
9ЁЂЪЙгУscikit-learnПтжаЕФPCAЪЕЯжНЕЮЌ
ЕМШыашвЊЕФАќЃК
#-*- coding:
utf-8 -*-
# Author:bob
# Date:2016.12.22
import numpy as np
from matplotlib import pyplot as plt
from scipy import io as spio
from sklearn.decomposition import pca
from sklearn.preprocessing import StandardScaler
|
ЙщвЛЛЏЪ§Он
'''ЙщвЛЛЏЪ§ОнВЂзїЭМ'''
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
|
ЪЙгУPCAФЃаЭФтКЯЪ§ОнЃЌВЂНЕЮЌ
n_componentsЖдгІвЊНЋЕФЮЌЖШ
'''ФтКЯЪ§Он'''
K=1 # вЊНЕЕФЮЌЖШ
model = pca.PCA(n_components=K).fit(x_train) #
ФтКЯЪ§ОнЃЌn_componentsЖЈвхвЊНЕЕФЮЌЖШ
Z = model.transform(x_train) # transformОЭЛсжДааНЕЮЌВйзї
|
Ъ§ОнЛжИД
model.components_ЛсЕУЕННЕЮЌЪЙгУЕФUОиеѓ
'''Ъ§ОнЛжИДВЂзїЭМ'''
Ureduce = model.components_ # ЕУЕННЕЮЌгУЕФUreduce
x_rec = np.dot(Z,Ureduce) # Ъ§ОнЛжИД
|
ЦпЁЂвьГЃМьВт Anomaly Detection
ШЋВПДњТы
1ЁЂИпЫЙЗжВМЃЈе§ЬЌЗжВМЃЉGaussian distribution
ЗжВМКЏЪ§ЃК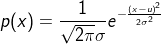
ЦфжаЃЌuЮЊЪ§ОнЕФОљжЕЃЌІвЮЊЪ§ОнЕФБъзМВю
ІвдНаЁЃЌЖдгІЕФЭМЯёдНМт
ВЮЪ§ЙРМЦЃЈparameter estimationЃЉ
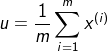
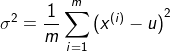
2ЁЂвьГЃМьВтЫуЗЈ
Р§зг
бЕСЗМЏЃК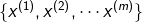 ,Цфжа ,Цфжа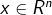
МйЩш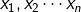 ЯрЛЅЖРСЂЃЌНЈСЂmodelФЃаЭЃК ЯрЛЅЖРСЂЃЌНЈСЂmodelФЃаЭЃК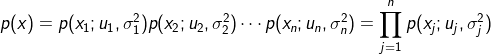
Й§ГЬ
бЁдёОпгаДњБэвьГЃЕФfeature:xi
ВЮЪ§ЙРМЦЃК
МЦЫуp(x),ШєЪЧP(x)<ІХдђШЯЮЊвьГЃЃЌЦфжаІХЮЊЮвУЧвЊЧѓЕФИХТЪЕФСйНчжЕthreshold
етРяжЛЪЧЕЅдЊИпЫЙЗжВМЃЌМйЩшСЫfeatureжЎМфЪЧЖРСЂЕФЃЌЯТУцЛсНВЕНЖрдЊИпЫЙЗжВМЃЌЛсздЖЏВЖзНЕНfeatureжЎМфЕФЙиЯЕ
ВЮЪ§ЙРМЦЪЕЯжДњТы
# ВЮЪ§ЙРМЦКЏЪ§ЃЈОЭЪЧЧѓОљжЕКЭЗНВюЃЉ
def estimateGaussian(X):
m,n = X.shape
mu = np.zeros((n,1))
sigma2 = np.zeros((n,1))
mu = np.mean(X, axis=0) # axis=0БэЪОСаЃЌУПСаЕФОљжЕ
sigma2 = np.var(X,axis=0) # ЧѓУПСаЕФЗНВю
return mu,sigma2
|
3ЁЂЦРМлp(x)ЕФКУЛЕЃЌвдМАІХЕФбЁШЁ
ЖдЦЋаБЪ§ОнЕФДэЮѓЖШСП
вђЮЊЪ§ОнПЩФмЪЧЗЧГЃЦЋаБЕФЃЈОЭЪЧy=1ЕФИіЪ§ЗЧГЃЩйЃЌ(y=1БэЪОвьГЃ)ЃЉЃЌЫљвдПЩвдЪЙгУPrecision/RecallЃЌМЦЫуF1Score(дкCVНЛВцбщжЄМЏЩЯ)
Р§ШчЃКдЄВтАЉжЂЃЌМйЩшФЃаЭПЩвдЕУЕН99%ФмЙЛдЄВте§ШЗЃЌ1%ЕФДэЮѓТЪЃЌЕЋЪЧЪЕМЪАЉжЂЕФИХТЪКмаЁЃЌжЛга0.5%ЃЌФЧУДЮвУЧЪМжедЄВтУЛгаАЉжЂy=0ЗДЖјПЩвдЕУЕНИќаЁЕФДэЮѓТЪЁЃЪЙгУerror
rateРДЦРЙРОЭВЛПЦбЇСЫЁЃ
ШчЯТЭММЧТМЃК 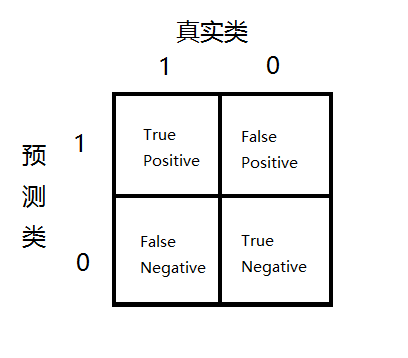
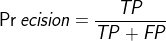 ЃЌМДЃКе§ШЗдЄВте§бљБО/ЫљгадЄВте§бљБО
ЃЌМДЃКе§ШЗдЄВте§бљБО/ЫљгадЄВте§бљБО
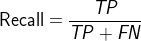 ЃЌМДЃКе§ШЗдЄВте§бљБО/ецЪЕжЕЮЊе§бљБО
ЃЌМДЃКе§ШЗдЄВте§бљБО/ецЪЕжЕЮЊе§бљБО
змЪЧШУy=1(НЯЩйЕФРр)ЃЌМЦЫуPrecisionКЭRecall
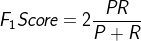
ЛЙЪЧвдАЉжЂдЄВтЮЊР§ЃЌМйЩшдЄВтЖМЪЧno-cancerЃЌTN=199ЃЌFN=1ЃЌTP=0ЃЌFP=0ЃЌЫљвдЃКPrecision=0/0ЃЌRecall=0/1=0ЃЌОЁЙмaccuracy=199/200=99.5%ЃЌЕЋЪЧВЛПЩаХЁЃ
ІХЕФбЁШЁ
ГЂЪдЖрИіІХжЕЃЌЪЙF1ScoreЕФжЕИп
ЪЕЯжДњТы
# бЁдёзюгХЕФepsilonЃЌМДЃКЪЙF1ScoreзюДѓ
def selectThreshold(yval,pval):
'''ГѕЪМЛЏЫљашБфСП'''
bestEpsilon = 0.
bestF1 = 0.
F1 = 0.
step = (np.max(pval)-np.min(pval))/1000
'''МЦЫу'''
for epsilon in np.arange(np.min(pval),np.max(pval),step):
cvPrecision = pval<epsilon
tp = np.sum((cvPrecision == 1) & (yval ==
1).ravel()).astype(float) # sumЧѓКЭЪЧintаЭЕФЃЌашвЊзЊЮЊfloat
fp = np.sum((cvPrecision == 1) & (yval ==
0).ravel()).astype(float)
fn = np.sum((cvPrecision == 0) & (yval ==
1).ravel()).astype(float)
precision = tp/(tp+fp) # ОЋзМЖШ
recision = tp/(tp+fn) # ейЛиТЪ
F1 = (2*precision*recision)/(precision+recision)
# F1ScoreМЦЫуЙЋЪН
if F1 > bestF1: # аоИФзюгХЕФF1 Score
bestF1 = F1
bestEpsilon = epsilon
return bestEpsilon,bestF1
|
4ЁЂбЁдёЪЙгУЪВУДбљЕФfeatureЃЈЕЅдЊИпЫЙЗжВМЃЉ
ШчЙћвЛаЉЪ§ОнВЛЪЧТњзуИпЫЙЗжВМЕФЃЌПЩвдБфЛЏвЛЯТЪ§ОнЃЌР§Шчlog(x+C),x^(1/2)ЕШ
ШчЙћp(x)ЕФжЕЮоТлвьГЃгыЗёЖМКмДѓЃЌПЩвдГЂЪдзщКЯЖрИіfeature,(вђЮЊfeatureжЎМфПЩФмЪЧгаЙиЯЕЕФ)
5ЁЂЖрдЊИпЫЙЗжВМ
ЕЅдЊИпЫЙЗжВМДцдкЕФЮЪЬт
ШчЯТЭМЃЌКьЩЋЕФЕуЮЊвьГЃЕуЃЌЦфЫћЕФЖМЪЧе§ГЃЕуЃЈБШШчCPUКЭmemoryЕФБфЛЏЃЉ
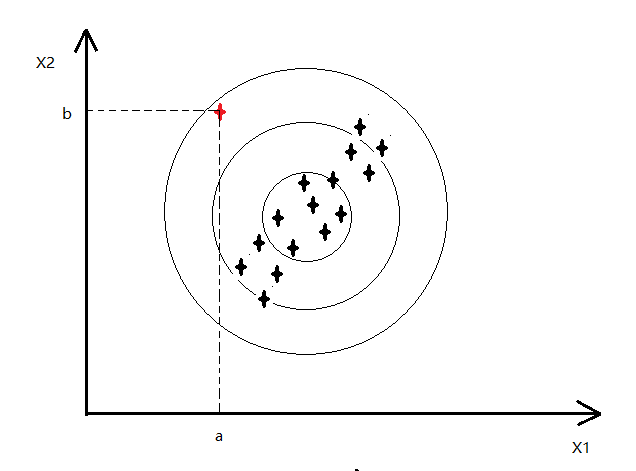
x1ЖдгІЕФИпЫЙЗжВМШчЯТЃК 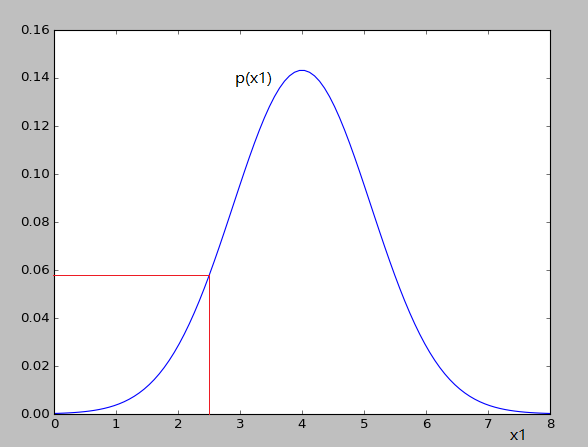
x2ЖдгІЕФИпЫЙЗжВМШчЯТЃК 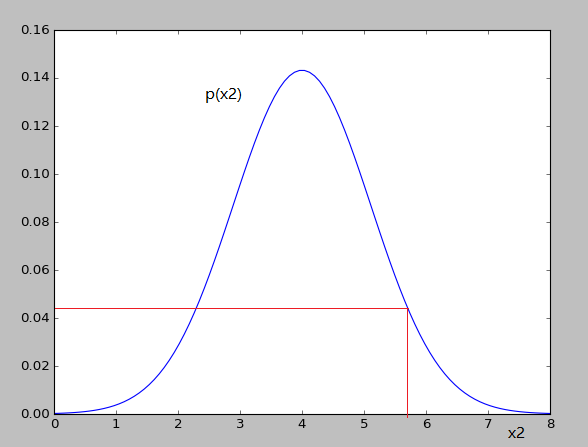
ПЩвдПДГіЖдгІЕФp(x1)КЭp(x2)ЕФжЕБфЛЏВЂВЛДѓЃЌОЭВЛЛсШЯЮЊвьГЃ
вђЮЊЮвУЧШЯЮЊfeatureжЎМфЪЧЯрЛЅЖРСЂЕФЃЌЫљвдШчЩЯЭМЪЧвде§дВЕФЗНЪНРЉеЙ
ЖрдЊИпЫЙЗжВМ
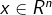 ЃЌВЂВЛЪЧНЈСЂp(x1),p(x2)...p(xn)ЃЌЖјЪЧЭГвЛНЈСЂp(x) ЃЌВЂВЛЪЧНЈСЂp(x1),p(x2)...p(xn)ЃЌЖјЪЧЭГвЛНЈСЂp(x)
ЦфжаВЮЪ§ЃК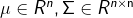 ,ІВЮЊаЗНВюОиеѓ ,ІВЮЊаЗНВюОиеѓ
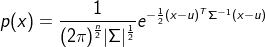
ЭЌбљЃЌ|ІВ|дНаЁЃЌp(x)дНМт
Р§ШчЃК
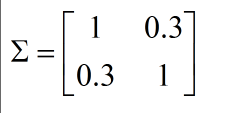
БэЪОx1,x2е§ЯрЙиЃЌМДx1дНДѓЃЌx2вВОЭдНДѓЃЌШчЯТЭМЃЌвВОЭПЩвдНЋКьЩЋЕФвьГЃЕуМьВщГіСЫ
ШєЃК
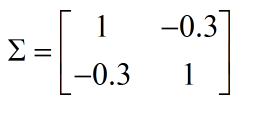
БэЪОx1,x2ИКЯрЙи
ЪЕЯжДњТыЃК
# ЖрдЊИпЫЙЗжВМКЏЪ§
def multivariateGaussian(X,mu,Sigma2):
k = len(mu)
if (Sigma2.shape[0]>1):
Sigma2 = np.diag(Sigma2)
'''ЖрдЊИпЫЙЗжВМКЏЪ§'''
X = X-mu
argu = (2*np.pi)**(-k/2)*np.linalg.det(Sigma2)**(-0.5)
p = argu*np.exp(-0.5*np.sum(np.dot(X,np.linalg.inv
(Sigma2))*X,axis=1))
# axisБэЪОУПаа
return p
|
6ЁЂЕЅдЊКЭЖрдЊИпЫЙЗжВМЬиЕу
ЕЅдЊИпЫЙЗжВМ
ШЫЮЊПЩвдВЖзНЕНfeatureжЎМфЕФЙиЯЕЪБПЩвдЪЙгУ
МЦЫуСПаЁ
ЖрдЊИпЫЙЗжВМ
здЖЏВЖзНЕНЯрЙиЕФfeature
МЦЫуСПДѓЃЌвђЮЊЃК
m>nЛђІВПЩФцЪБПЩвдЪЙгУЁЃЃЈШєВЛПЩФцЃЌПЩФмгаШпгрЕФxЃЌвђЮЊЯпадЯрЙиЃЌВЛПЩФцЃЌЛђепОЭЪЧm<nЃЉ
7ЁЂГЬађдЫааНсЙћ
ЯдЪОЪ§Он 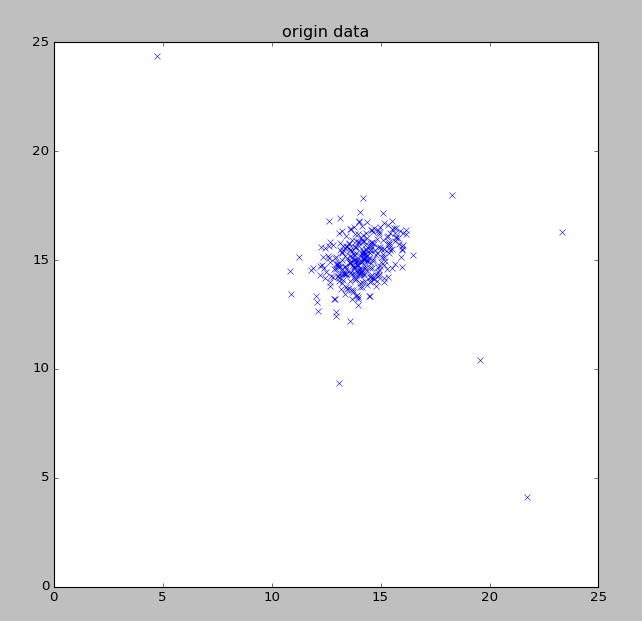
ЕШИпЯп 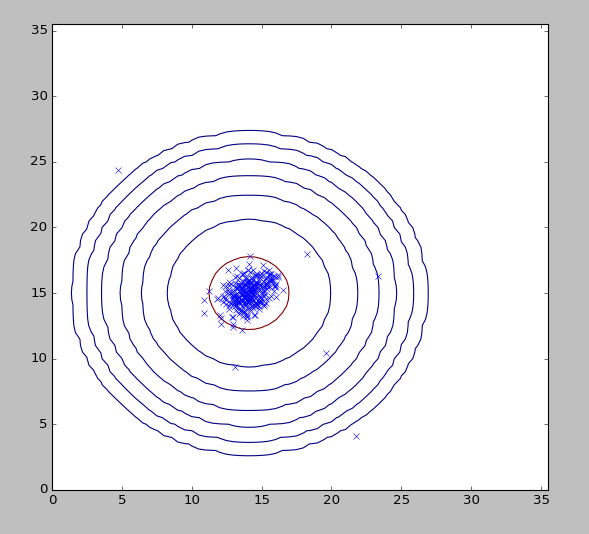
вьГЃЕуБъзЂ 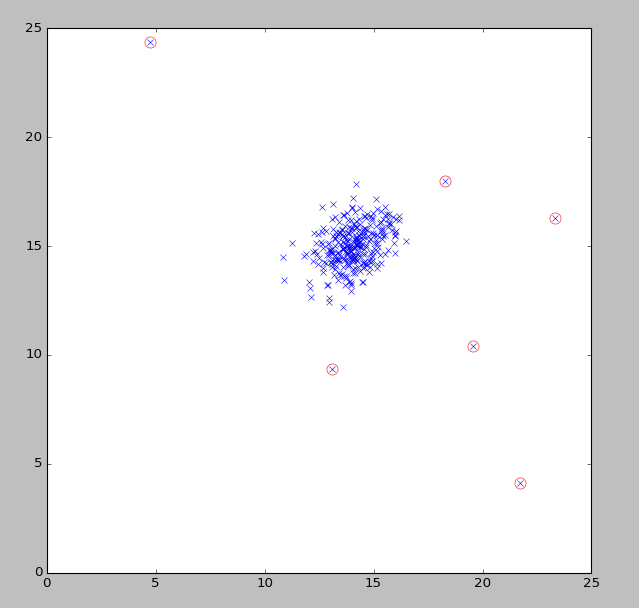
|









