| БрМЭЦМі: |
БОЮФРДздгкcloud.tencent.comЃЌзїепвдЧГЯдвзЖЎЕФгябдКЭЧхЮњЕФЪОР§КЭДњТыНЬФуДгЭЗПЊЪМзпЙ§вЛИіЛњЦїбЇЯАжЎТУЃЌВЂЧвИНЯъЯИЕФДњТыЃЌДѓМвПЩвдЪеВиКЭбЇЯАЁЃ |
|
етЪЧвЛЦЊЭъШЋЪжАбЪжНјааЛњЦїбЇЯАЯюФПЙЙНЈЕФНЬГЬЃЌАќКЌЃК1. Ъ§ОнЧхРэКЭИёЪНЛЏ
2. ЬНЫїадЪ§ОнЗжЮі 3. ЬиеїЙЄГЬКЭЬиеїбЁдё 4. дкадФмжИБъЩЯБШНЯМИжжЛњЦїбЇЯАФЃаЭ 5. ЖдзюМбФЃаЭжДааГЌВЮЪ§Еїећ
6. дкВтЪдМЏКЯжаЦРЙРзюМбФЃаЭ 7. НтЪЭФЃаЭНсЙћ 8. ЕУГіНсТлЁЃНёЬьЪЧЃЈ1-3ЃЉДгЪ§ОнЧхРэЃЌЕНЪ§ОнЗжЮіЃЌЕНЬиеїЙЄГЬЃЌдйЕНBaselineЕФЙЙНЈ.

ЁЊЁЊPutting the machine learning pieces together
дФЖСвЛБОЪ§ОнПЦбЇЪщМЎЛђбЇЯАвЛУХЯрЙиЕФПЮГЬЃЌФуПЩФмИаОѕФугаСЫЖРСЂЕФЫщЦЌЃЌЕЋВЛжЊЕРШчКЮНЋЫќУЧЦДдквЛЦ№ЁЃЯывЊМЬајЭЦНјЯТШЅВЂНтОіЭъећЕФЛњЦїбЇЯАЮЪЬтПЩФмСюШЫЭћЖјЩњЮЗЃЌЕЋЭъГЩЕквЛИіЯюФПКѓНЋЪЙФугааХаФгІЖдШЮКЮЪ§ОнПЦбЇЮЪЬтЁЃБОЯЕСаЮФеТНЋНщЩмЁЊЁЊЪЙгУСЫецЪЕЪРНчЪ§ОнМЏЕФЛњЦїбЇЯАЯюФПЕФЭъећНтОіЗНАИЃЌШУФуСЫНтЫљгаЫщЦЌЪЧШчКЮЦДНгдквЛЦ№ЕФЁЃ
ЮвУЧНЋАДеевЛАуЛњЦїбЇЯАЕФЙЄзїСїГЬж№ВННјааЃК
1. Ъ§ОнЧхРэКЭИёЪНЛЏ
2. ЬНЫїадЪ§ОнЗжЮі
3. ЬиеїЙЄГЬКЭЬиеїбЁдё
4. дкадФмжИБъЩЯБШНЯМИжжЛњЦїбЇЯАФЃаЭ
5. ЖдзюМбФЃаЭжДааГЌВЮЪ§Еїећ
6. дкВтЪдМЏКЯжаЦРЙРзюМбФЃаЭ
7. НтЪЭФЃаЭНсЙћ
8. ЕУГіНсТл
АДееЩЯЪіСїГЬЃЌЮвУЧНЋНщЩмУПИіВНжшШчКЮНјШыЕНЯТвЛВНЃЌвдМАШчКЮгУPythonЪЕЯжУПИіВПЗжЁЃЭъећЕФЯюФПдкGitHubЩЯПЩвдевЕНЃЌЕквЛИіnotebookдкетРяЁЃ
ЕквЛЦЊЮФеТНЋКИЧВНжш1-3ЃЌЦфгрЕФФкШнНЋдкКѓУцЕФЮФеТжаНщЩмЁЃ
GitHubЭъећЯюФПСДНгЃК
ЮЪЬтЖЈвх
БрТыжЎЧАЕФЕквЛВНЪЧСЫНтЮвУЧЪдЭМНтОіЕФЮЪЬтКЭПЩгУЕФЪ§ОнЁЃдкетИіЯюФПжаЃЌЮвУЧНЋЪЙгУЙЋЙВПЩгУЕФХІдМЪаЕФНЈжўФмдДЪ§ОнЁО1ЁПЁЃ
ФПБъЪЧЪЙгУФмдДЪ§ОнНЈСЂвЛИіФЃаЭЃЌРДдЄВтНЈжўЮяЕФEnergy Star ScoreЃЈФмдДжЎаЧЗжЪ§ЃЉЃЌВЂНтЪЭНсЙћвдевГігАЯьЦРЗжЕФвђЫиЁЃ
Ъ§ОнАќРЈEnergy Star ScoreЃЌвтЮЖзХетЪЧвЛИіМрЖНЛиЙщЛњЦїбЇЯАШЮЮёЃК
МрЖНЃКЮвУЧПЩвджЊЕРЪ§ОнЕФЬиеїКЭФПБъЃЌЮвУЧЕФФПБъЪЧбЕСЗПЩвдбЇЯАСНепжЎМфгГЩфЙиЯЕЕФФЃаЭЁЃ
ЛиЙщЃКEnergy Star ScoreЪЧвЛИіСЌајБфСПЁЃ
ЮвУЧЯывЊПЊЗЂвЛИіФЃаЭЃЌдкзМШЗадЩЯЁЊЁЊЫќПЩвдЪЕЯждЄВтEnergy Star ScoreЃЌВЂЧвНсЙћНгНќецЪЕжЕЁЃдкНтЪЭЩЯЁЊЁЊ
ЮвУЧПЩвдРэНтФЃаЭЕФдЄВтЁЃ
вЛЕЉЮвУЧжЊЕРСЫФПБъЃЌдкЩюШыЭкОђЪ§ОнВЂЙЙНЈФЃаЭЪБЃЌОЭПЩвдгУЫќРДжИЕМЮвУЧЕФОіВпЁЃ
Ъ§ОнЧхЯД
гыДѓЖрЪ§Ъ§ОнПЦбЇПЮГЬЫљЯраХЕФЯрЗДЃЌВЂЗЧУПИіЪ§ОнМЏЖМЪЧвЛзщЭъУРЕФЙлВтЪ§ОнЃЌУЛгаШБЪЇжЕЛђвьГЃжЕЃЈФуПЩвдВщПДФуЕФmtcarsЁО2ЁПКЭirisЪ§ОнМЏЁО3ЁПЃЉЁЃ
ЯжЪЕЪРНчЕФЪ§ОнКмТвЃЌетвтЮЖзХдкЮвУЧПЊЪМЗжЮіжЎЧАЃЌЮвУЧашвЊЧхРэВЂНЋЦфзЊЛЛЮЊПЩНгЪмЕФИёЪНЁО4ЁПЁЃЪ§ОнЧхРэЃЌЪЧДѓЖрЪ§ЪЕМЪЕФЪ§ОнПЦбЇЮЪЬтжаВЛОпЮќв§СІЃЌЕЋБиВЛПЩЩйЕФвЛВПЗжЁЃ
ЪзЯШЃЌЮвУЧПЩвдНЋЪ§ОнгУPandas DataFrameМгдиВЂВщПДЃК
import pandas
as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_
Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head() |
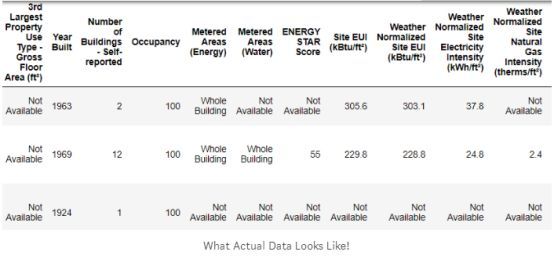
етЪЧАќКЌ60СаЕФЭъећЪ§ОнЕФзгМЏЁЃ ЮвУЧвбОПЩвдПДЕНМИИіЮЪЬтЃКЪзЯШЃЌЮвУЧжЊЕРЮвУЧЯывЊдЄВтЕФEnergy
Star ScoreЕФЧщПіЃЌЕЋЮвУЧВЛжЊЕРШЮКЮвЛСаЕФКЌвхЁЃ ЫфШЛетВЛвЛЖЈЪЧИіЮЪЬтЁЊЁЊЮвУЧЭЈГЃПЩвддкУЛгаШЮКЮБфСПжЊЪЖЕФЧщПіЯТДДНЈвЛИізМШЗЕФФЃаЭЁЊЁЊЮвУЧЯыАбжиЕуЗХдкФЃаЭЕФПЩНтЪЭадЩЯЃЌЖјжСЩйСЫНтвЛаЉСаПЩФмЪЧживЊЕФЁЃ
Ц№ГѕЃЌЮвДгГѕДДНзЖЮЕУЕНШЮЮёЪБЃЌЮвВЛЯыЮЪЫљгаЕФСаУћЪЧЪВУДвтЫМЃЌЫљвдЮвВщПДСЫcsvЮФМўЕФУћГЦЃЌ

ВЂОіЖЈЫбЫїЁАLocal Law 84ЁБЁЃ ЫљвддкЩЯЮФЮвНтЪЭЁЊЁЊетЪЧХІдМЗЈТЩвЊЧѓЕФЃЌЫљгаОпгавЛЖЈЙцФЃЕФНЈжўЮяБЈИцЦфФмдДЪЙгУЧщПіЁЃ
ЙигкСаЕФИќЖрЫбЫїФкШндкетРяЁЃ вВаэПДвЛИіЮФМўУћЪЧвЛИіУїЯдЕФПЊЪМЃЌЕЋЖдЮвРДЫЕЃЌетЪЧЬсабФувЊЗХТ§ЫйЖШЃЌетбљФуВХВЛЛсДэЙ§ШЮКЮживЊЕФЖЋЮїЃЁ
ЮвУЧВЛашвЊбаОПЫљгаЕФСаЕФЖЈвхЃЌЕЋЮвУЧжСЩйгІИУСЫНтEnergy Star ScoreЃЌЫќБЛУшЪіЮЊЃК
ИљОнБЈИцФъЖШжаЃЌздЮвБЈИцЕФФмдДЪЙгУЧщПіЖјНјааЕФ1жС100АйЗжЮЛЕФХХУћЁЃ Energy Star ScoreЪЧгУгкБШНЯНЈжўЮяФмаЇЕФЯрЖдЖШСПЁЃЁО5ЁП
етНтОіСЫЕквЛИіаЁЮЪЬтЃЌЕЋЕкЖўИіЮЪЬтЪЧШБЩйЕФжЕБЛБрТыЮЊЁАNot AvailableЁБЁЃ етЪЧPythonжаЕФвЛИізжЗћДЎЃЌетвтЮЖзХЩѕжСАќКЌЪ§зжЕФСаЖМНЋБЛДцДЂЮЊobjectЪ§ОнРраЭЃЌвђЮЊPandasЛсНЋАќКЌШЮКЮзжЗћДЎЕФСазЊЛЛЮЊЫљгадЊЫиЖМЮЊзжЗћДЎЕФСаЁЃЮвУЧПЩвдЪЙгУdataframe.infoЃЈЃЉЗНЗЈРДВщПДСаЕФЪ§ОнРраЭЃК
# See the column
data types and non-missing values
data.info() |
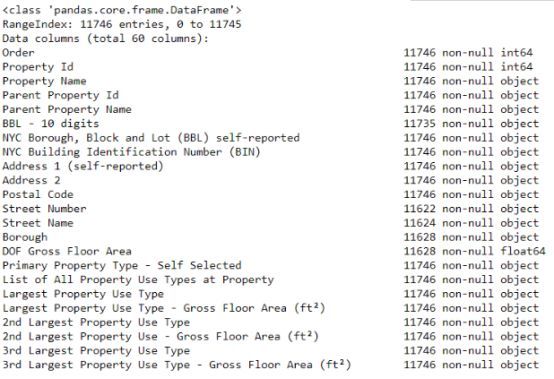
ЕБШЛЃЌвЛаЉУїШЗАќКЌЪ§зжЃЈР§Шчft2ЃЉЕФСаБЛДцДЂЮЊobjectРраЭЁЃ ЮвУЧВЛФмЖдзжЗћДЎНјааЪ§жЕЗжЮіЃЌвђДЫБиаыНЋЦфзЊЛЛЮЊЪ§зжЃЈЬиБ№ЪЧИЁЕуЪ§ЃЉЪ§ОнРраЭЃЁ
етРягавЛИіМђЖЬЕФPythonДњТыЃЌгУВЛЪЧЪ§зжЃЈnp.nanЃЉДњЬцЫљгаЁАNot AvailableЁБЬѕФПЃЌnp.nanПЩвдБЛНтЪЭЮЊЪ§зжЃЌетбљОЭПЩвдНЋЯрЙиСазЊЛЛЮЊfloatЪ§ОнРраЭЃК
# Replace all
occurrences of Not Available with numpy not a
number
data = data.replace({'Not Available': np.nan})
# Iterate through the columns
for col in list(data.columns):
# Select columns that should be numeric
if ('ft2' in col or 'kBtu' in col or 'Metric
Tons CO2e' in col
or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score'
in col):
# Convert the data type to float
data[col] = data[col].astype(float) |
вЛЕЉСаЪЧЪ§зжЃЌЮвУЧОЭПЩвдПЊЪМНјааЕїВщЪ§ОнЁЃ
ШБЩйЪ§ОнКЭвьГЃжЕ
Г§СЫВЛе§ШЗЕФЪ§ОнРраЭЭтЃЌДІРэецЪЕЪРНчЪ§ОнЪБЕФСэвЛИіГЃМћЮЪЬтЪЧШБЪЇжЕЁЃ етПЩФмЪЧгЩгкаэЖрдвђв§Ц№ЕФЃЌдкЮвУЧбЕСЗЛњЦїбЇЯАФЃаЭжЎЧАБиаыЬюаДЛђЩОГ§ЁЃЪзЯШЃЌШУЮвУЧСЫНтУПСажагаЖрЩйШБЪЇжЕЃЈЧыВЮдФnotebookжаЕФДњТыЃЉЁЃ
ЃЈЮЊСЫДДНЈетИіБэЃЌЮвЪЙгУСЫетИіStack OverflowТлЬГЕФвЛИіКЏЪ§ЁО6ЁПЃЉЁЃ
ОЁЙмЮвУЧзмЪЧЯЃЭћаЁаФЩОГ§аХЯЂЃЌЕЋШчЙћСажаШБЪЇжЕЕФБШР§КмИпЃЌФЧУДЫќЖдЮвУЧЕФФЃаЭПЩФмВЛЛсгагУЁЃЩОГ§СаЕФуажЕгІИУШЁОігкЪЕМЪЮЪЬтЃЌВЂЧвЖдгкДЫЯюФПЃЌЮвУЧНЋЩОГ§ШБЪЇжЕГЌЙ§50ЃЅЕФСаЁЃ
ДЫЪБЃЌЮвУЧПЩФмЛЙЯывЊвЦГ§вьГЃжЕЁЃетаЉвьГЃПЩФмЪЧгЩгкЪ§ОнЪфШыжаЕФЦДаДДэЮѓЃЌЕЅЮЛжаЕФДэЮѓЃЌЛђепЫќУЧПЩФмЪЧКЯЗЈЕЋЪЧМЋЖЫЕФжЕЁЃЖдгкетИіЯюФПЃЌЮвУЧНЋИљОнМЋЖЫвьГЃжЕЕФЖЈвхРДЯћГ§вьГЃЃК
1. the first quartile ? 3 ? interquartile range
2. he third quartile + 3 ? interquartile range
ЃЈгаЙиЩОГ§СаКЭвьГЃЕФДњТыЃЌЧыВЮдФnotebookЃЉЁЃ дкЪ§ОнЧхРэКЭвьГЃЧхГ§Й§ГЬНсЪјЪБЃЌЮвУЧЪЃЯТ11,000ЖрИіНЈжўЮяКЭ49ИіЬиеїЁЃ
ЬНЫїадЪ§ОнЗжЮі
ЯждкЃЌЪ§ОнЧхРэетИіЗІЮЖЕЋБивЊЕФВНжшвбОЭъГЩЃЌЮвУЧПЩвдМЬајЬНЫїЮвУЧЕФЪ§ОнЃЁЬНЫїадЪ§ОнЗжЮіЃЈEDAЃЉЪЧвЛИіПЊЗХЪНЕФЙ§ГЬЃЌЮвУЧПЩвдМЦЫуЭГМЦЪ§ОнЃЌВЂЛЭМШЅЗЂЯжЪ§ОнжаЕФЧїЪЦЃЌвьГЃЃЌФЃЪНЛђЙиЯЕЁЃЃЈtrends,
anomalies, patterns, or relationshipsЃЉ
МђЖјбджЎЃЌEDAЕФФПБъЪЧСЫНтЮвУЧЕФЪ§ОнПЩвдИцЫпЮвУЧЪВУДЁЃЫќЭЈГЃвдИпВуИХЪіПЊЪМЃЌдкЮвУЧЗЂЯжгаШЄЕФЪ§ОнВПЗжКѓЃЌдйЫѕаЁЕНЬиЖЈЕФЧјгђЁЃетаЉЗЂЯжБОЩэПЩФмКмгавтЫМЃЌЛђепПЩвдгУгкЭЈжЊЮвУЧЕФНЈФЃбЁдёЃЌР§ШчАяжњЮвУЧОіЖЈЪЙгУФФаЉЬиеїЁЃ
ЕЅБфСПЭМ
ФПБъЪЧдЄВтEnergy Star ScoreЃЈНЋЦфжиаТУќУћЮЊscoreЃЉЃЌвђДЫКЯРэЕФПЊЪМЪЧМьВщДЫБфСПЕФЗжВМЁЃжБЗНЭМЪЧПЩЪгЛЏЕЅИіБфСПЗжВМЕФМђЕЅЖјгааЇЕФЗНЗЈЃЌЪЙгУmatplotlibКмШнвзЁЃ
import matplotlib.pyplot
as plt
# Histogram of the Energy Star Score
plt.style.use('fivethirtyeight')
plt.hist(data['score'].dropna(), bins = 100, edgecolor
= 'k');
plt.xlabel('Score'); plt.ylabel('Number of Buildings');
plt.title('Energy Star Score Distribution'); |
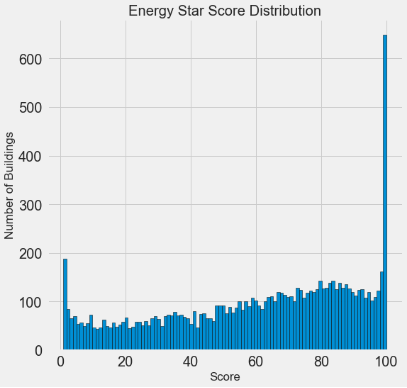
етПДЦ№РДКмПЩвЩЃЁ Energy Star ScoreЪЧАйЗжЮЛЪ§ЃЌетвтЮЖзХЮвУЧЦкЭћПДЕНвЛИіЭГвЛЕФЗжВМЃЌМДУПИіЕУЗжЗжХфИјЯрЭЌЪ§СПЕФНЈжўЮяЁЃШЛЖјЃЌВЛГЩБШР§ЕФНЈжўЮяОпгазюИпЕФ100ЗжЛђзюЕЭЕФ1ЗжЃЈЖдгкEnergy
Star ScoreРДЫЕИќИпБэЪОдНКУЃЉЁЃ
ШчЙћЮвУЧЛиЕНscoreЕФЖЈвхЃЌЮвУЧЛсПДЕНЫќЛљгкЁАздЮвБЈИцФмСПЪЙгУЁБЃЌетПЩФмНтЪЭСЫЗжЪ§ЦЋИпЁЊЁЊвЊЧѓНЈжўЮяЫљгаепБЈИцздМКЕФФмдДЪЙгУЧщПіОЭЯёвЊЧѓбЇЩњдкВтЪджаБЈИцздМКЕФЗжЪ§ЃЁ
вђДЫЃЌетПЩФмВЛЪЧКтСПНЈжўФмаЇЕФзюПЭЙлБъзМЁЃ
ШчЙћЮвУЧгаЮоЯоЕФЪБМфЃЌЮвУЧПЩФмЯывЊЕїВщЮЊЪВУДетУДЖрНЈжўЮягаЗЧГЃИпКЭЗЧГЃЕЭЕФЗжЪ§ЁЊЁЊЮвУЧПЩвдЭЈЙ§бЁдёетаЉНЈжўЮяВЂВщПДЫќУЧЕФЙВЭЌЕуЁЃЕЋЪЧЃЌЮвУЧЕФФПБъжЛЪЧдЄВтЗжЪ§ЃЌЖјВЛЪЧЩшМЦИќКУЕФНЈжўЮяЦРЗжЗНЗЈЃЁ
ЮвУЧПЩвддкЮвУЧЕФБЈИцжаМЧЯТЗжЪ§ОпгаПЩвЩЗжВМЃЌЕЋЮвУЧжївЊЙизЂдЄВтЗжЪ§ЁЃ
бАевЙиЯЕ
EDAЕФжївЊВПЗжЪЧЫбЫїЬиеїКЭФПБъжЎМфЕФЙиЯЕЁЃгыФПБъЯрЙиЕФБфСПЖдФЃаЭКмгагУЃЌвђЮЊЫќУЧПЩгУгкдЄВтФПБъЁЃЭЈЙ§ЪЙгУseabornПтЕФУмЖШЭМПЩвдМьВщФПБъЩЯЕФЗжРрБфСПЃЈНіВЩгУгаЯоЕФвЛзщжЕЃЉЕФаЇЙћЁЃ
УмЖШЭМПЩвдБЛШЯЮЊЪЧЦНЛЌЕФжБЗНЭМЃЌвђЮЊЫќЯдЪОСЫЕЅИіБфСПЕФЗжВМЁЃЮвУЧПЩвдАДРрБ№ЖдУмЖШЭМНјаазХЩЋЃЌвдВщПДЗжРрБфСПШчКЮИФБфЗжВМЁЃЯТУцЕФДњТыДДНЈСЫвЛИігУНЈжўЮяРраЭЃЈНіЯогкОпгаГЌЙ§100ИіЪ§ОнЕуЕФНЈжўЮяРраЭЃЉзХЩЋЕФEnergy
Star ScoreУмЖШЭМЃК
# Create a list
of buildings with more than 100 measurements
types = data.dropna(subset=['score'])
types = types['Largest Property Use Type'].value_counts()
types = list(types[types.values > 100].index)
# Plot of distribution of scores for building
categories
figsize(12, 10)
# Plot each building
for b_type in types:
# Select the building type
subset = data[data['Largest Property Use Type']
== b_type]
# Density plot of Energy Star scores
sns.kdeplot(subset['score'].dropna(),
label = b_type, shade = False, alpha = 0.8);
# label the plot
plt.xlabel('Energy Star Score', size = 20);
plt.ylabel('Density',
size = 20);
plt.title('Density Plot of Energy Star Scores
by Building Type',
size = 28); |
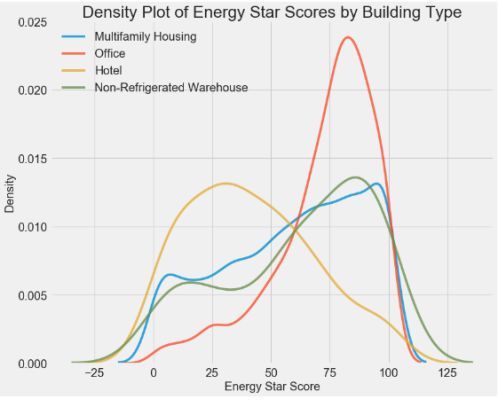
ЮвУЧПЩвдПДЕННЈжўРраЭЖдEnergy Star ScoreгажиДѓгАЯьЁЃ АьЙЋТЅЭљЭљгаНЯИпЕФЗжЪ§ЃЌЖјОЦЕъЕФЗжЪ§НЯЕЭЁЃетИцЫпЮвУЧЃЌЮвУЧгІИУдкНЈФЃжаАќКЌНЈжўРраЭЃЌвђЮЊЫќШЗЪЕЖдФПБъгагАЯьЁЃ
зїЮЊЗжРрБфСПЃЌЮвУЧНЋВЛЕУВЛЖдНЈжўЮяРраЭНјааone-hotБрТыЁЃ
ЭЌЩЯЃЌПЩвдЯдЪОзджЮЪаеђЕФEnergy Star ScoreЃК
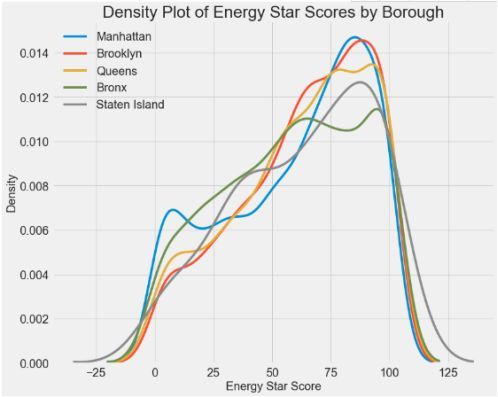
зджЮЪаеђЖдНЈжўРраЭЕФЦРЗжЫЦКѕУЛгаЬЋДѓЕФгАЯьЁЃ ОЁЙмШчДЫЃЌЮвУЧПЩФмЯЃЭћНЋЦфФЩШыЮвУЧЕФФЃаЭжаЃЌвђЮЊИїЧјжЎМфДцдкЯИЮЂЕФВювьЁЃ
ЮЊСЫСПЛЏБфСПжЎМфЕФЙиЯЕЃЌЮвУЧПЩвдЪЙгУPearsonЯрЙиЯЕЪ§ЁЃЫќПЩвдгУРДКтСПСНИіБфСПжЎМфЕФЯпадЙиЯЕЕФЧПЖШКЭЗНЯђЁЃ
+1ЗжЪЧЭъУРЕФЯпаде§ЯрЙиЙиЯЕЃЌ-1ЗжЪЧЭъУРЕФИКЯпадЙиЯЕЁЃ ЯрЙиЯЕЪ§ЕФМИИіжЕШчЯТЫљЪОЃК
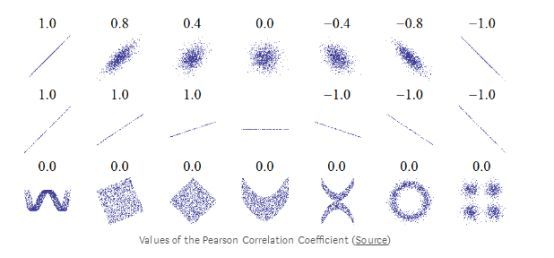
ЫфШЛЯрЙиЯЕЪ§ЮоЗЈВЖзНЗЧЯпадЙиЯЕЃЌЕЋЫќЪЧПЊЪММЦЫуБфСПШчКЮЯрЙиЕФКУЗНЗЈЁЃ дкPandasжаЃЌЮвУЧПЩвдЧсЫЩМЦЫуЪ§ОнПђжаШЮКЮСажЎМфЕФЯрЙиадЃК
# Find all correlations
with the score and sort
correlations_data = data.corr()['score'].sort_values() |
гыФПБъЕФзюИКУцЃЈзѓЃЉКЭзюе§УцЃЈгвЃЉЯрЙиадЃК

ЬиеїгыФПБъжЎМфДцдкМИИіЧПСвЕФИКЯрЙиадЃЌЖјEUIЖдФПБъзюЮЊИКУцЁЃЃЈетаЉВтСПЗНЗЈдкМЦЫуЗНЪНЩЯТдгаВЛЭЌЃЉEUIЁЊЁЊФмдДЪЙгУЧПЖШЃЈEnergy
Use IntensityЃЉЁЊЁЊЪЧНЈжўЮяЪЙгУЕФФмдДСПГ§вдНЈжўЮяЕФЦНЗНгЂГпЁЃЫќвтЮЖзХКтСПвЛИіНЈжўЃЌаЇТЪдНЕЭдНКУЁЃжБЙлЕиЫЕЃЌетаЉЯрЙиадЪЧгавтвхЕФЃКЫцзХEUIЕФдіМгЃЌEnergy
Star ScoreЧїгкЯТНЕЁЃ
ЫЋБфСПЭМ
ЮЊСЫПЩЪгЛЏСНИіСЌајБфСПжЎМфЕФЙиЯЕЃЌЮвУЧЪЙгУЩЂЕуЭМЁЃЮвУЧПЩвддкЕуЕФбеЩЋжаАќКЌИНМгаХЯЂЃЌР§ШчЗжРрБфСПЁЃР§ШчЃЌЯТУцЕФЭМБэЯдЪОСЫВЛЭЌНЈжўЮяРраЭЕФEnergy
Star Scoreгыsite EUIЕФЙиЯЕЃК
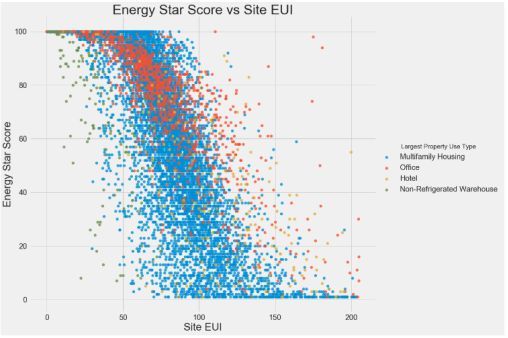
етИіЭМШУЮвУЧПЩвдПДЕН-0.7ЕФЯрЙиЯЕЪ§ЁЃ ЫцзХSite EUIМѕЩйЃЌEnergy Star ScoreдіМгЃЌетжжЙиЯЕдкНЈжўРраЭжаБЃГжЮШЖЈЁЃ
ЮвУЧНЋзіЕФзюКѓЕФЬНЫїадplotБЛГЦЮЊPairs PlotЁЃетЪЧвЛИіКмКУЕФЬНЫїЙЄОпЃЌвђЮЊЫќПЩвдШУЮвУЧПДЕНЖрИіБфСПЖджЎМфЕФЙиЯЕвдМАЕЅИіБфСПЕФЗжВМЁЃдкетРяЃЌЮвУЧЪЙгУseabornПЩЪгЛЏПтКЭPairGridКЏЪ§РДДДНЈЩЯШ§НЧЩЯОпгаЩЂЕуЭМЕФХфЖдЭМЃЌЖдНЧЯпЩЯЕФжБЗНЭМвдМАЯТШ§НЧаЮЩЯЕФЖўЮЌКЫУмЖШЭМКЭЯрЙиЯЕЪ§ЁЃ
# Extract the
columns to plot
plot_data = features[['score', 'Site EUI (kBtu/ft2)',
'Weather Normalized Source EUI (kBtu/ft2)',
'log_Total GHG Emissions (Metric Tons CO2e)']]
# Replace the inf with nan
plot_data = plot_data.replace({np.inf: np.nan,
-np.inf: np.nan})
# Rename columns
plot_data = plot_data.rename(columns = {'Site
EUI (kBtu/ft2)':
'Site EUI',
'Weather Normalized Source EUI (kBtu/ft2)':
'Weather Norm EUI',
'log_Total GHG Emissions (Metric Tons CO2e)':
'log GHG Emissions'})
# Drop na values
plot_data = plot_data.dropna()
# Function to calculate correlation coefficient
between two columns
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# Create the pairgrid object
grid = sns.PairGrid(data = plot_data, size =
3)
# Upper is a scatter plot
grid.map_upper(plt.scatter, color = 'red', alpha
= 0.6)
# Diagonal is a histogram
grid.map_diag(plt.hist, color = 'red', edgecolor
= 'black')
# Bottom is correlation and density plot
grid.map_lower(corr_func);
grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds)
# Title for entire plot
plt.suptitle('Pairs Plot of Energy Data', size
= 36, y = 1.02); |
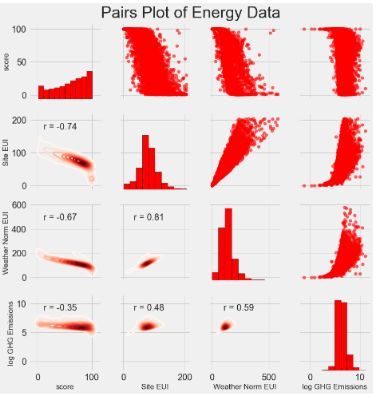
вЊВщПДБфСПжЎМфЕФНЛЛЅЃЌЮвУЧВщеваагыСаЯрНЛЕФЮЛжУЁЃР§ШчЃЌвЊВщПДWeather EUorm EUIгыscoreЕФЯрЙиадЃЌЮвУЧВщПДWeather
EUorm EUIааКЭscoreСаЃЌВЂВщПДЯрЙиЯЕЪ§ЮЊ-0.67ЁЃ Г§СЫПДЦ№РДКмПсжЎЭтЃЌжюШчетаЉЭМПЩвдАяжњЮвУЧОіЖЈдкНЈФЃжагІИУАќКЌФФаЉБфСПЁЃ
ЬиеїЙЄГЬКЭбЁдё
ЬиеїЙЄГЬКЭбЁдёЭЈГЃЛсЮЊЛњЦїбЇЯАЮЪЬтЭЖШызюДѓЕФЪБМфЁЃЪзЯШЃЌШУЮвУЧРДЖЈвхетСНИіШЮЮёЪЧЪВУДЃК
ЬиеїЙЄГЬЃКЛёШЁдЪМЪ§ОнВЂЬсШЁЛђДДНЈаТЬиеїЕФЙ§ГЬЁЃетПЩФмвтЮЖзХашвЊЖдБфСПНјааБфЛЛЃЌР§ШчздШЛЖдЪ§КЭЦНЗНИљЃЌЛђепЖдЗжРрБфСПНјааone-hotБрТыЃЌвдБуЫќУЧПЩвддкФЃаЭжаЪЙгУЁЃ
вЛАуРДЫЕЃЌЮвШЯЮЊЬиеїЙЄГЬЪЧДгдЪМЪ§ОнДДНЈИНМгЬиеїЁЃ
ЬиеїбЁдёЃКбЁдёЪ§ОнжазюЯрЙиЕФЬиеїЕФЙ§ГЬЁЃдкЬиеїбЁдёжаЃЌЮвУЧЩОГ§ЬиеївдАяжњФЃаЭИќКУЕизмНсаТЪ§ОнВЂДДНЈИќОпПЩНтЪЭадЕФФЃаЭЁЃвЛАуРДЫЕЃЌЮвШЯЮЊЬиеїбЁдёЪЧМѕШЅЬиеїЃЌЫљвдЮвУЧжЛСєЯТФЧаЉзюживЊЕФЬиеїЁЃ
ЛњЦїбЇЯАФЃаЭжЛФмДгЮвУЧЬсЙЉЕФЪ§ОнжабЇЯАЃЌвђДЫШЗБЃЪ§ОнАќКЌЮвУЧШЮЮёЕФЫљгаЯрЙиаХЯЂжСЙиживЊЁЃШчЙћЮвУЧУЛгаИјФЃаЭЬсЙЉе§ШЗЕФЪ§ОнЃЌФЧУДЮвУЧНЋЫќЩшжУЮЊЪЇАмЃЌЮвУЧВЛгІИУЦкЭћЫќбЇЯАЃЁ
ЖдгкетИіЯюФПЃЌЮвУЧНЋВЩШЁвдЯТЙІФмЩшМЦВНжшЃК
One-hotБрТыЗжРрБфСПЃЈborough and property use typeЃЉЁЃ
ЬэМгЪ§жЕБфСПЕФздШЛЖдЪ§зЊЛЛЁЃ
дкФЃаЭжаЃЌЗжРрБфСПЕФOne-hotБрТыЪЧБивЊЕФЁЃЛњЦїбЇЯАЫуЗЈЮоЗЈРэНтЯёЁАofficeЁБетбљЕФНЈжўРраЭЃЌвђДЫШчЙћНЈжўЮяЪЧАьЙЋЪвЃЌдђБиаыНЋЦфМЧТМЮЊ1ЃЌЗёдђНЋЦфМЧТМЮЊ0ЁЃ
ЬэМгзЊЛЛЬиеїПЩвдАяжњЮвУЧЕФФЃаЭбЇЯАЪ§ОнжаЕФЗЧЯпадЙиЯЕЁЃВЩгУЦНЗНИљЃЌздШЛЖдЪ§ЛђЬиеїЕФДЮУнЪЧЪ§ОнПЦбЇжаЕФГЃМћзіЗЈЃЌвВЪЧЛљгкСьгђжЊЪЖЛђдкЪЕМљжазюгааЇЕФЗНЗЈЁЃетРяЮвУЧНЋЪЙгУЪ§зжЬиеїЕФздШЛЖдЪ§ЁЃ
вдЯТДњТыбЁдёЪ§зжЬиеїЃЌЖдетаЉЬиеїНјааЖдЪ§зЊЛЛЃЌбЁдёСНИіЗжРрЬиеїЃЌЖдетаЉЬиеїНјааone-hotБрТыЃЌШЛКѓНЋСНИіЬиеїНсКЯдквЛЦ№ЁЃетЫЦКѕашвЊзіКмЖрЙЄзїЃЌЕЋдкpandasжаЯрЖдМђЕЅЃЁ
# Copy the original
data
features = data.copy()
# Select the numeric columns
numeric_subset = data.select_dtypes('number')
# Create columns with log of numeric columns
for col in numeric_subset.columns:
# Skip the Energy Star Score column
if col == 'score':
next
else:
numeric_subset['log_' + col] = np.log(numeric_subset[col])
# Select the categorical columns
categorical_subset = data[['Borough', 'Largest
Property Use Type']]
# One hot encode
categorical_subset = pd.get_dummies(categorical_subset)
# Join the two dataframes using concat
# Make sure to use axis = 1 to perform a column
bind
features = pd.concat([numeric_subset, categorical_subset],
axis = 1) |
дкетИіЙ§ГЬжЎКѓЃЌЮвУЧгаГЌЙ§11,000ИіОпга110СаЃЈЬиеїЃЉЕФЙлВтжЕЃЈНЈжўЮяЃЉЁЃВЂЗЧЫљгаетаЉЬиеїЖМПЩФмЖддЄВтEnergy
Star ScoreгагУЃЌЫљвдЯждкЮвУЧНЋзЊЯђЬиеїбЁдёДгЖјШЅГ§вЛаЉБфСПЁЃ
ЬиеїбЁдё
ЮвУЧЪ§ОнжаЕФ110ИіЬиеїжаЕФаэЖрЬиеїЪЧЖргрЕФЃЌвђЮЊЫќУЧБЫДЫИпЖШЯрЙиЁЃ Р§ШчЃЌвдЯТЪЧSite EUIгыWeather
Normalized SiteEUIЕФЯрЙиЯЕЪ§ЮЊ0.997ЕФЭМЁЃ
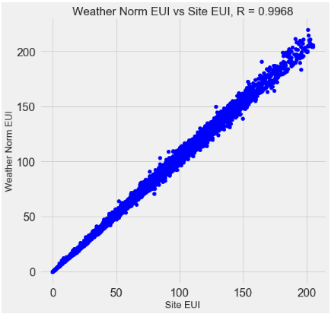
ЯрЛЅЧПЯрЙиЕФЬиеїБЛГЦЮЊЙВЯпЃЌЯћГ§етаЉЬиеїЖджаЕФвЛИіБфСПЭЈГЃПЩвдАяжњЛњЦїбЇЯАФЃаЭЭЦЙуВЂИќвзгкНтЪЭЁЃЃЈЮвгІИУжИГіЃЌЮвУЧе§дкЬжТлЬиеїгыЦфЫћЬиеїЕФЯрЙиадЃЌЖјВЛЪЧгыФПБъЕФЯрЙиадЃЌетгажњгкЮвУЧЕФФЃаЭЃЁЃЉ
гааэЖрЗНЗЈПЩвдМЦЫуЬиеїжЎМфЕФЙВЯпадЃЌЦфжазюГЃМћЕФЪЧЗНВюРЉДѓвђзгЁЃдкетИіЯюФПжаЃЌЮвУЧНЋЪЙгУЯрЙиЯЕЪ§РДЪЖБ№КЭЩОГ§ЙВЯпЬиеїЁЃШчЙћЫќУЧжЎМфЕФЯрЙиЯЕЪ§Дѓгк0.6ЃЌЮвУЧНЋЗХЦњвЛЖдЬиеїжаЕФвЛИіЁЃЖдгкЪЕЯжЃЌПДПДnotebookЃЈКЭетИіstack
overflowД№АИЃЉ
ЫфШЛетИіуажЕПЩФмПДЦ№РДЪЧШЮвтЕФЃЌЕЋЮвГЂЪдСЫМИИіВЛЭЌЕФуажЕЃЌетИібЁдёВњЩњСЫзюКУЕФФЃаЭЛњЦїбЇЯАЪЧвЛИіОбщадСьгђЃЌЭЈЙ§ЪдбщРДЗЂЯжадФмзюКУЕФЃЁЬиеїбЁдёКѓЃЌЮвУЧЪЃЯТ64ИіЬиеїКЭ1ИіФПБъЁЃ
# Remove any
columns with all na values
features = features.dropna(axis=1, how = 'all')
print(features.shape)
(11319, 65) |
НЈСЂBaseline
ЮвУЧЯждквбОЭъГЩСЫЪ§ОнЧхРэЃЌЬНЫїадЪ§ОнЗжЮіКЭЬиеїЙЄГЬЁЃПЊЪМНЈФЃжЎЧАвЊзіЕФзюКѓвЛВНЪЧНЈСЂвЛИіBaselineЁЃетЪЕМЪЩЯЪЧЮвУЧПЩвдБШНЯЮвУЧЕФНсЙћЕФвЛжжВТВтЁЃШчЙћЛњЦїбЇЯАФЃаЭУЛгаГЌдНетИіВТВтЃЌФЧУДЮвУЧПЩФмБиаыЕУГіНсТлЃЌЛњЦїбЇЯАЖдгкШЮЮёРДЫЕЪЧВЛПЩНгЪмЕФЃЌЛђепЮвУЧПЩФмашвЊГЂЪдВЛЭЌЕФЗНЗЈЁЃ
ЖдгкЛиЙщЮЪЬтЃЌКЯРэЕФBaselineЪЧВТВтВтЪдМЏжаЫљгаЪОР§ЕФбЕСЗМЏЩЯФПБъЕФжажЕЁЃетЩшжУСЫвЛИіШЮКЮФЃаЭЖМвЊГЌдНЕФЯрЖдНЯЕЭЕФБъзМЁЃ
ЮвУЧНЋЪЙгУЕФЖШСПБъзМЪЧЦНОљОјЖдЮѓВюЃЈMean Absolute ErrorЃЉЃЈMAEЃЉЃЌЫќВтСПдЄВтЕФЦНОљОјЖдЮѓВюЁЃгаКмЖрЛиЙщЕФжИБъЃЌЕЋЮвЯВЛЖAndrew
NgЕФНЈвщЁО7ЁПЃЌбЁдёвЛИіжИБъЃЌШЛКѓдкЦРЙРФЃаЭЪБМсГжЪЙгУЫќЁЃЦНОљОјЖдЮѓВюКмШнвзМЦЫуЃЌВЂЧвПЩвдНтЪЭЁЃ
дкМЦЫуBaselineжЎЧАЃЌЮвУЧашвЊНЋЮвУЧЕФЪ§ОнЗжГЩвЛИібЕСЗМЏКЭвЛИіВтЪдМЏЃК
1. бЕСЗМЏЪЧЮвУЧдкбЕСЗЦкМфИјЮвУЧЕФФЃаЭЬсЙЉЬиеївдМАД№АИЕФЁЃФПЕиЪЧШУФЃаЭбЇЯАЬиеїгыФПБъжЎМфЕФгГЩфЁЃ
2. ВтЪдМЏКЯЕФЬиеїгУгкЦРЙРбЕСЗЕФФЃаЭЁЃФЃаЭВЛдЪаэВщПДВтЪдМЏЕФД№АИЃЌВЂЧвжЛФмЪЙгУЬиеїНјаадЄВтЁЃЮвУЧжЊЕРВтЪдМЏЕФД№АИЃЌвђДЫЮвУЧПЩвдНЋВтЪддЄВтгыД№АИНјааБШНЯЁЃ
ЮвУЧНЋЪЙгУ70ЃЅЕФЪ§ОнНјаабЕСЗЃЌ30ЃЅгУгкВтЪдЃК
# Split into
70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features,
targets,
test_size = 0.3,
random_state = 42) |
ЯждкЮвУЧПЩвдМЦЫуГіBaselineЕФадФмЃК
# Function to
calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true - y_pred))
baseline_guess = np.median(y)
print('The baseline guess is a score of %0.2f'
% baseline_guess)
print("Baseline Performance on the test
set: MAE = %0.4f" %
mae(y_test, baseline_guess)) |
The baseline
guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164 |
BaselineЕФЙРМЦдкВтЪдМЏжадМЮЊ25ЗжЁЃ ЕУЗжЗЖЮЇДг1ЕН100ЃЌЫљвдетДњБэ25ЃЅЕФЮѓВюЃЌЯрЕБЕЭЕФвЛИіГЌдНЃЁ
НсТл
дкБОЮФжаЃЌЮвУЧзпЙ§СЫЛњЦїбЇЯАЮЪЬтЕФЧАШ§ИіВНжшЁЃ дкЖЈвхЮЪЬтжЎКѓЃЌЮвУЧЃК
1. ЧхРэВЂИёЪНЛЏдЪМЪ§Он
2. НјааЬНЫїадЪ§ОнЗжЮівдСЫНтЪ§ОнМЏ
3. ПЊЗЂСЫвЛЯЕСаЮвУЧНЋгУгкФЃаЭЕФЬиеї
зюКѓЃЌЮвУЧЛЙЭъГЩСЫНЈСЂЮвУЧПЩвдХаЖЯЮвУЧЕФЛњЦїбЇЯАЫуЗЈЕФBaselineЕФЙиМќВНжшЁЃ |









