| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФЭЈЙ§НщЩм
Language ModelЃЌдѕУДЪЕЯжвдМАгІгУЃЌкЙЪЭСЫШчКЮгУ RNN НЈСЂ
Language Model ЩњГЩЮФБОЁЃ
|
|
ЪВУДЪЧ Language ModelЃП
Language Model ЪЧ NLP ЕФЛљДЁЃЌЪЧгявєЪЖБ№, ЛњЦїЗвыЕШКмЖрNLPШЮЮёЕФКЫаФЁЃ
ВЮПМЃК
ЪЕМЪЩЯЪЧвЛИіИХТЪЗжВМФЃаЭ P ЃЌЖдгкгябдРяЕФУПвЛИізжЗћДЎ S ИјГівЛИіИХТЪ
P(S) ЁЃ
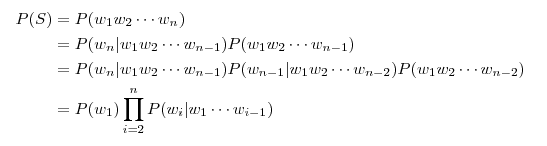
дѕУДЪЕЯжЃПдѕУДгІгУЃП
ЮвУЧЯШбЕСЗвЛИігябдФЃаЭЃЌШЛКѓгУЫќРДЩњГЩОфзгЁЃИааЫШЄЕФЛАПЩвдШЅетРяПДЭъећДњТыЁЃ
1.ЮЪЬтЪЖБ№ЃК
ЮвУЧвЊзіЕФЪЧЃЌгУ RNN ЭЈЙ§вўВиВуЕФЗДРЁаХЯЂРДИјРњЪЗЪ§Он xt,xt?1,...,x1 НЈФЃЁЃ
Р§ШчЃЌЪфШывЛИіЦ№ЪМЮФБОЃК'in palo alto'ЃЌЩњГЩКѓУцЕФ100ИіЕЅДЪЁЃ
Цфжа Palo Alto ЪЧ California ЕФвЛИіГЧЪаЁЃ
2.ФЃаЭЃК
гябдФЃаЭЃКИјСЫ x1, . . . , xtЃЌ ЭЈЙ§МЦЫуЯТУцЕФИХТЪЃЌдЄВт
xt+1ЃК
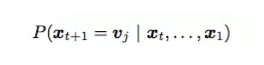
ФЃаЭШчЯТЃК
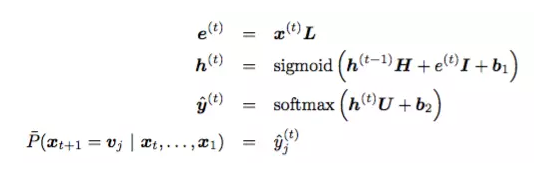
ЦфжаВЮЪ§ЃК
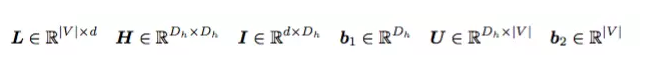
h^t ЪЧtЪБПЬЕФвўВиВуЃЌe^t ЪЧЪфШыВуЃЌОЭЪЧ one-hot ЯђСП
x^t гы L зїгУКѓЕУЕНЕФДЪЯђСПЃЌH ЪЧвўВиВузЊЛЛОиеѓЃЌI ЪЧЪфШыВуДЪБэЪООиеѓЃЌU ЪЧЪфГіВуДЪБэЪООиеѓЃЌb1ЃЌb2
ЪЧ biasesЃЌетМИИіЪЧЮвУЧашвЊбЕСЗЕФВЮЪ§ЁЃ
ЮвУЧгУ cross-entropy loss РДКтСПЮѓВюЃЌЪЙжЎДяЕНзюаЁЃК
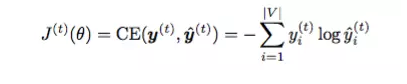
ЮвУЧЭЈЙ§ЦРМл perplexity вВОЭЪЧЯТУцетИіЪНзгЃЌРДЦРМлФЃаЭЕФБэЯжЃК
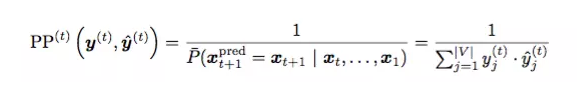
ЕБЮвУЧдкзюаЁЛЏ mean cross-entropy ЕФЭЌЪБЃЌвВДяЕНСЫзюаЁЛЏ
mean perplexity ЕФФПЕФЃЌвђЮЊ perplexity ОЭЪЧ cross entropy
ЕФжИЪ§аЮЪНЁЃОпЬхЭЦЕМВЮПМ
Жд J Чѓдк t ЪБПЬЕФ ИїВЮЪ§ЕФЦЋЕМЃК
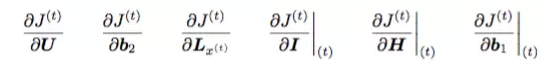
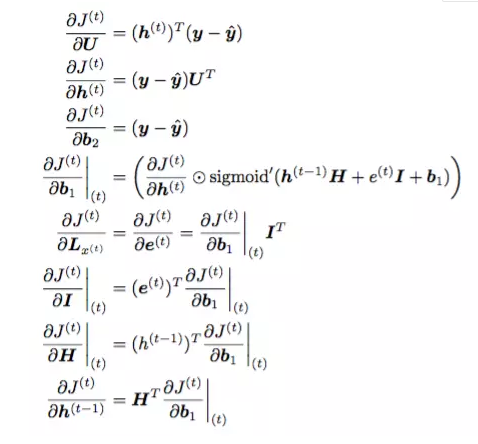
RNN дквЛИіЪБМфЕуЕФ ФЃаЭНсЙЙ ШчЯТЃК
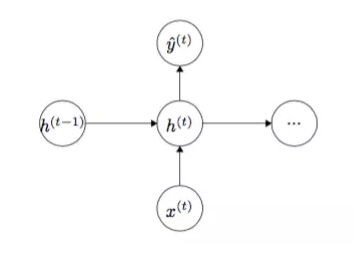
НЋФЃаЭеЙПЊ3ВНЕУЕНШчЯТНсЙЙЃК
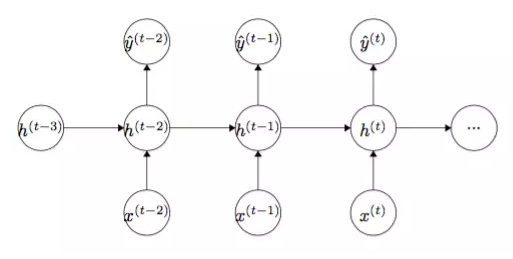
Йигк t ЪБПЬЕФ J Жд tЃ1 ЪБПЬЕФВЮЪ§ LЃЌHЃЌIЃЌb1 ЧѓЕМЃК

НгЯТРДгУ Adam potimizer РДбЕСЗФЃаЭЃЌЕУЕН loss зюаЁЪБЕФВЮЪ§ЁЃ
дйгУбЕСЗКУЕФФЃаЭШЅЩњГЩЮФБОЁЃ
3.ЮФБОЩњГЩЕФЪЕЯж
вЛЙВЕќДњmax epochДЮЃЌ
УПвЛДЮЖМДњШы training Ъ§ОнЃЌбЕСЗФЃаЭЃЌВЂЕУЕН perplexity жЕЃЌ
дйбЁдёзюаЁЕФ valid perplexity ВЂБЃДцЯргІЕФ weightsЃЌ
гУФЃаЭзїгУдкЪфШыЕФГѕЪМЮФБОЃЌЩњГЩКѓУцЕФЕЅДЪЁЃ
| def
test_RNNLM():
config = Config()
gen_config = deepcopy(config)
gen_config.batch_size = gen_config.num_steps
= 1
# We create the training model and generative
model
with tf.variable_scope('RNNLM') as scope:
model = RNNLM_Model(config) # вЊбЕСЗЕФmodel
# This instructs gen_model to reuse the same
variables as the model above
scope.reuse_variables()
gen_model = RNNLM_Model(gen_config) # вЊreuseЕФmodel
init = tf.initialize_all_variables()
saver = tf.train.Saver()
with tf.Session() as session:
best_val_pp = float('inf')
best_val_epoch = 0
session.run(init)
for epoch in xrange(config.max_epochs): # ЕќДњmax
epochДЮ
print 'Epoch {}'.format(epoch)
start = time.time()
###
train_pp = model.run_epoch(
session, model.encoded_train,
train_op=model.train_step)
valid_pp = model.run_epoch(session, model.encoded_valid)
# ДњШыencoded trainКЭvalidЪ§ОнЃЌбЕСЗmodelЃЌЕУЕНperplexity
print 'Training perplexity: {}'.format(train_pp)
# training dataКЭvalidation dataЕФ perplexity
print 'Validation perplexity: {}'.format(valid_pp)
if valid_pp < best_val_pp:
best_val_pp = valid_pp
best_val_epoch = epoch
saver.save(session, './ptb_rnnlm.weights') #
бЁдёзюаЁЕФ valid perplexity ВЂБЃДцЯргІЕФweights
if epoch - best_val_epoch > config.early_stopping:
break
print 'Total time: {}'.format(time.time() -
start)
saver.restore(session, 'ptb_rnnlm.weights')
test_pp = model.run_epoch(session, model.encoded_test)
# model.run_epochЃЌбЕСЗетИіmodel
print '=-=' * 5
print 'Test perplexity: {}'.format(test_pp)
print '=-=' * 5
starting_text = 'in palo alto'
while starting_text:
print ' '.join(generate_sentence(
session, gen_model, gen_config, starting_text=starting_text,
temp=1.0)) # гУФЃаЭзїгУдкЪфШыЕФГѕЪМЮФБОЃЌЩњГЩКѓУцЕФЕЅДЪ
starting_text = raw_input('> ')
if __name__ == "__main__":
test_RNNLM()
|
4.ФЃаЭЪЧдѕУДбЕСЗЕФФиЃП
ЪзЯШЕМШыЪ§Он trainingЃЌvalidationЃЌtestЃК
| def
load_data(self, debug=False):
"""Loads starter word-vectors
and train/dev/test data."""
self.vocab = Vocab()
self.vocab.construct(get_ptb_dataset('train'))
self.encoded_train = np.array(
[self.vocab.encode(word) for word in get_ptb_dataset('train')],
# НЋОфзгgetГЩwordЃЌдйencodeГЩoneЃhotЯђСП
dtype=np.int32)
|
НгЯТРДНЈСЂЩёОЭјТчЃК

ЬэМг embedding ВуЃК
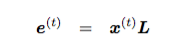
| def
add_embedding(self):
"""Add embedding layer.
variables you will need to create:
L: (len(self.vocab), embed_size)
Returns:
inputs: List of length num_steps, each of whose
elements should be
a tensor of shape (batch_size, embed_size).
"""
# The embedding lookup is currently only implemented
for the CPU
with tf.device('/cpu:0'):
embedding = tf.get_variable(
'Embedding',
[len(self.vocab), self.config.embed_size], trainable=True)
# L: (len(self.vocab), embed_size)
inputs = tf.nn.embedding_lookup(embedding, self.input_placeholder)
# Looks up ids in a list of embedding tensors.
inputs = [
tf.squeeze(x, [1]) for x in tf.split(1, self.config.num_steps,
inputs)] # remove specific dimensions of size
1 at postion=[1]
return inputs
|
ЬэМг RNN ВуЃК
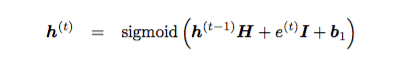
| def
add_model(self, inputs):
with tf.variable_scope('InputDropout'):
inputs = [tf.nn.dropout(x, self.dropout_placeholder)
for x in inputs] # dropout of inputs
with tf.variable_scope('RNN') as scope:
self.initial_state = tf.zeros( # initial state
of RNN
[self.config.batch_size, self.config.hidden_size])
state = self.initial_state
rnn_outputs = []
for tstep, current_input in enumerate(inputs):
# tstep ЖрЩйИіЪБПЬЃЌЖрЩйИіЕЅДЪ
if tstep > 0:
scope.reuse_variables()
RNN_H = tf.get_variable(
'HMatrix', [self.config.hidden_size, self.config.hidden_size])
RNN_I = tf.get_variable(
'IMatrix', [self.config.embed_size, self.config.hidden_size])
RNN_b = tf.get_variable(
'B', [self.config.hidden_size])
state = tf.nn.sigmoid(
tf.matmul(state, RNN_H) + tf.matmul(current_input,
RNN_I) + RNN_b) # етРяstateЪЧЕБЧАЪБПЬЕФвўВиВу
rnn_outputs.append(state) # ВЛЙ§ЫќдкЯТвЛИібЛЗжаОЭБЛгУСЫЃЌЫљвдвВЪЧгУРДДцЩЯвЛЪБПЬвўВиВуЕФ
self.final_state = rnn_outputs[-1]
with tf.variable_scope('RNNDropout'):
rnn_outputs = [tf.nn.dropout(x, self.dropout_placeholder)
for x in rnn_outputs] # dropout of outputs
return rnn_outputs
|
НЈСЂ projection ВуЃК
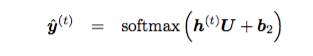
| def
add_projection(self, rnn_outputs):
with tf.variable_scope('Projection'):
U = tf.get_variable(
'Matrix', [self.config.hidden_size, len(self.vocab)])
proj_b = tf.get_variable('Bias', [len(self.vocab)])
outputs = [tf.matmul(o, U) + proj_b for o in
rnn_outputs] # outputsЃНrnn_outputsЃЊUЃЋb2
return outputs
|
гУ cross entropy МЦЫу lossЃК
| def
add_loss_op(self, output):
all_ones = [tf.ones([self.config.batch_size
* self.config.num_steps])]
cross_entropy = sequence_loss( # cross entropy
[output], [tf.reshape(self.labels_placeholder,
[-1])], all_ones, len(self.vocab))
tf.add_to_collection('total_loss', cross_entropy)
loss = tf.add_n(tf.get_collection('total_loss'))
# зюжеЕФloss
return loss
|
гУ Adam зюаЁЛЏ loss:
| ef
add_training_op(self, loss):
optimizer = tf.train.AdamOptimizer(self.config.lr)
train_op = optimizer.minimize(self.calculate_loss)
# гУAdamзюаЁЛЏloss
|
УПвЛДЮбЕСЗКѓЃЌЕУЕНСЫзюаЁЛЏ loss ЯргІЕФ weightsЁЃ
бЕСЗКѓЕФФЃаЭЃЌОЭПЩвдгУРДЩњГЩЮФБОСЫЃК
| while
starting_text:
print ' '.join(generate_sentence(
session, gen_model, gen_config, starting_text=starting_text,
temp=1.0)) # гУФЃаЭзїгУдкЪфШыЕФГѕЪМЮФБОЃЌЩњГЩКѓУцЕФЕЅДЪ
|
|









