| 编辑推荐: |
本文来自于个人博客,本文为深度学习课程笔记,通过流程图,详细介绍了深度学习模型的基本结构,希望对您的学习有所帮助。
|
|
深度学习的基本步骤:定义模型-->定义损失函数-->找到优化方法
课程大纲

1、熟悉定义符号(略过)

2、RNN

简单地说就是

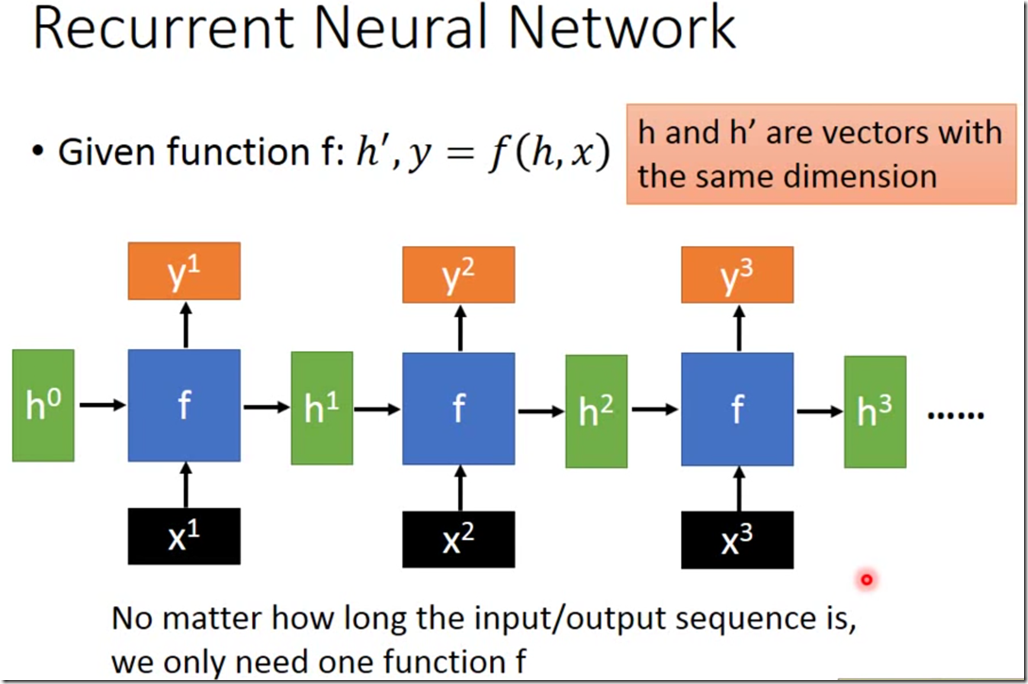
RNN可以看做是一个function反复迭代。
为什么不用feedFord network,因为我们输入的sequence可能会比较长,这样的话feedFord
network可能就会参数很多,容易导致过拟合。
RNN的一个好处是参数少,有可能比较难train,但是你一旦在training data上获得比较好的结果,在testing
data上的效果通常也不会差。
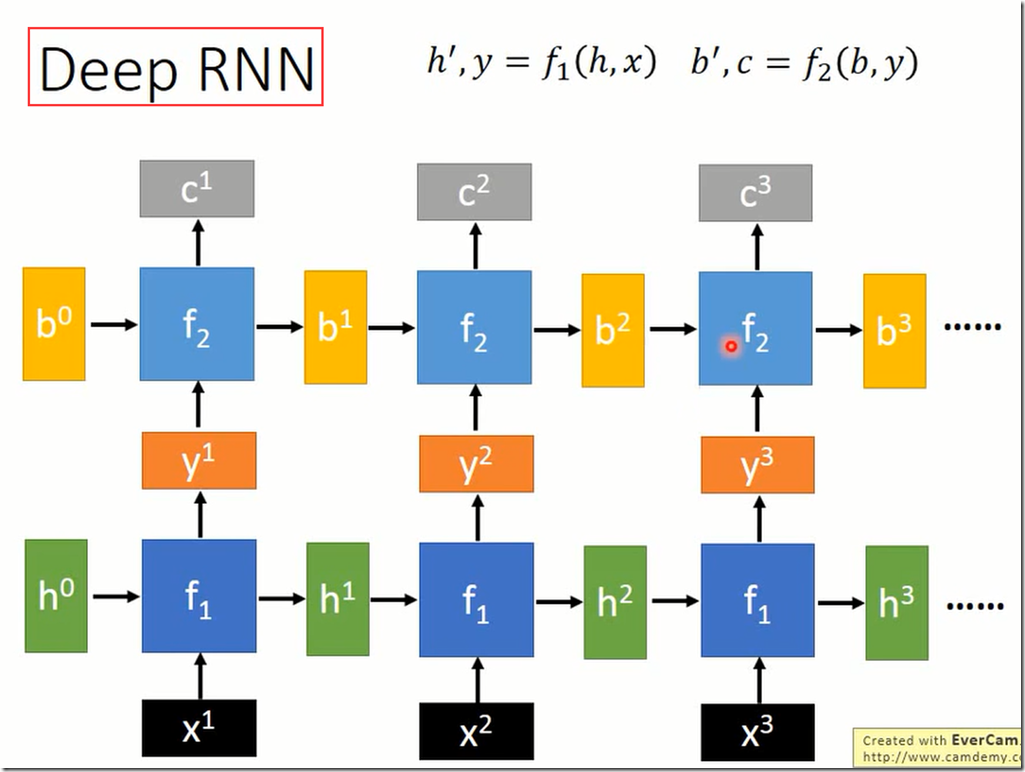
Deep RNN要注意到一点是 f1的输出和f2的输入的维度必须一致,这样才好拼接到一起。
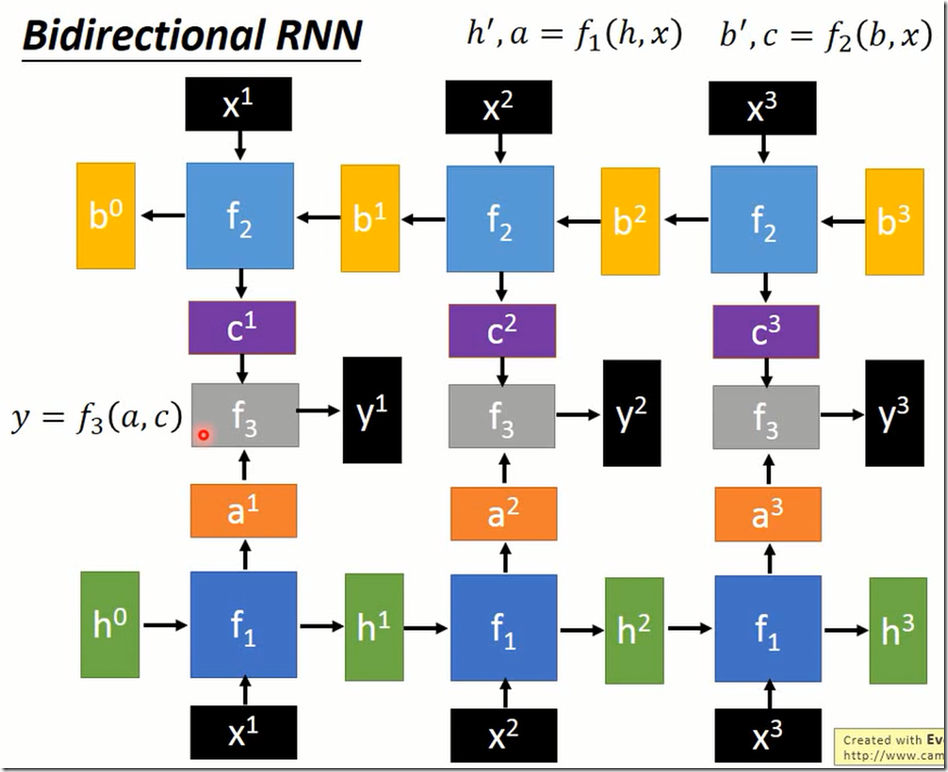
双向RNN。就是要加入一个f3,将f1的输出和f2的输出整合在一起。至于f1和f2不必一样,你可以随便设计。
下面介绍一些具体的应用
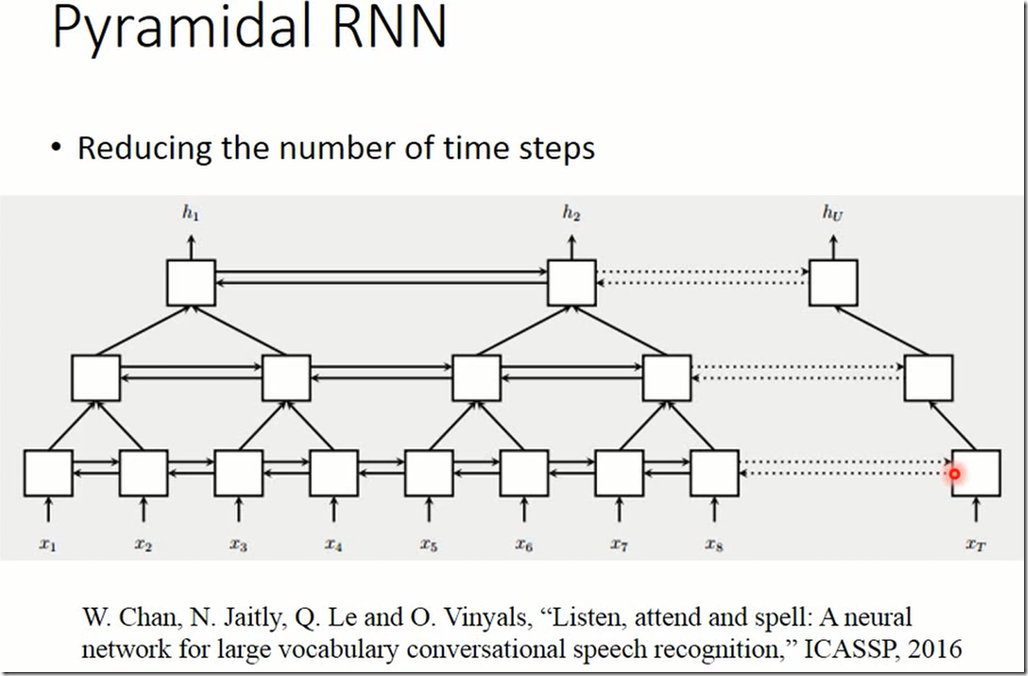
这个是直接用sqe2sqe的语音识别。第一层是bi-rnn,第二层是将若干第一层的输出(合起来)作为输出,也是bi-rnn,后面都这样下去。这种结够比单纯的深度bi-rnn更容易训练。第二层block虽然需要处理若干第一层block的输出,但是这种法有利于做并行加速。RNN很难做并行,因为下一个节点必须得等第一个节点的输出才能进行,而pyramidal
rnn里高层的block,序列变短了,每个block中虽然运算量较大,但是可以用并行运算加速。
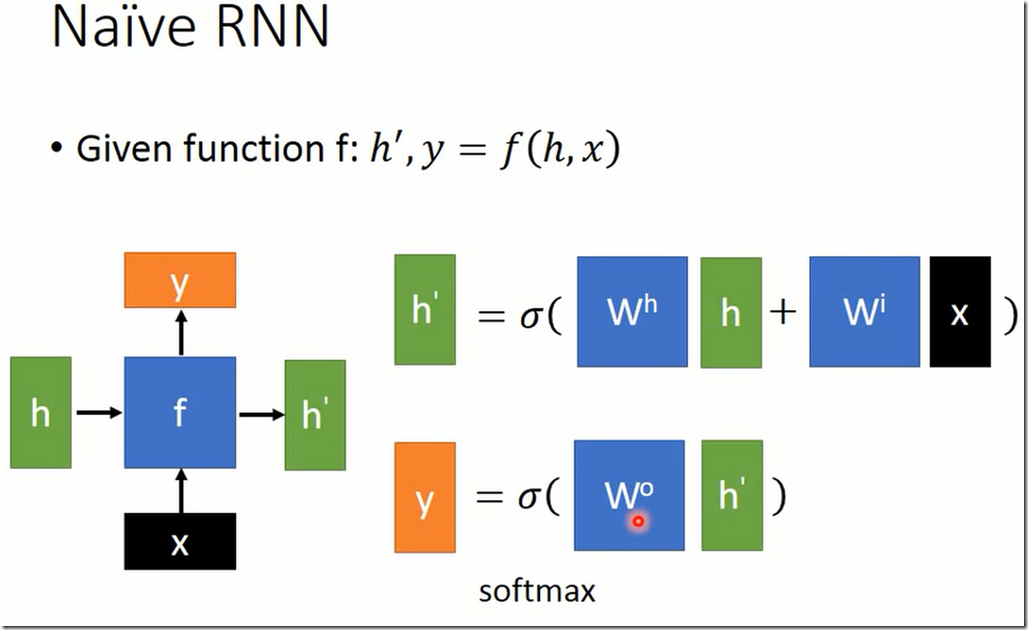
最简单的RNN运算如上图。
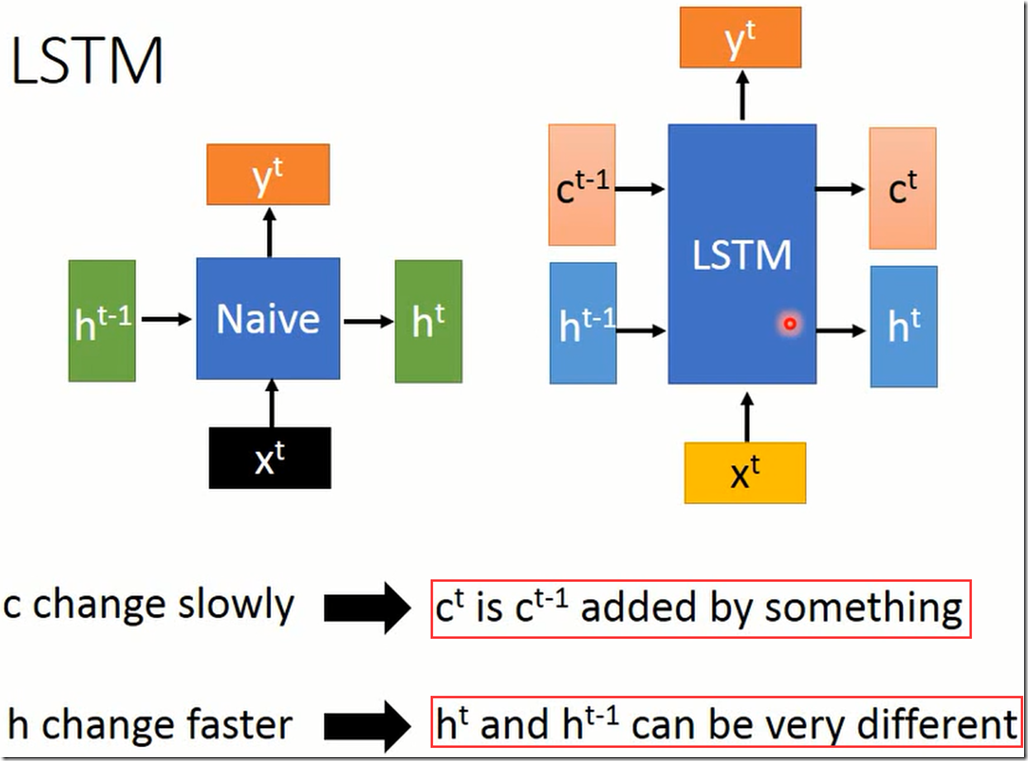
C变化较慢,可以记住时间比较久的信息。
也可以把C拿下来一块运算。一般W中对应于C的参数都是对角矩阵。
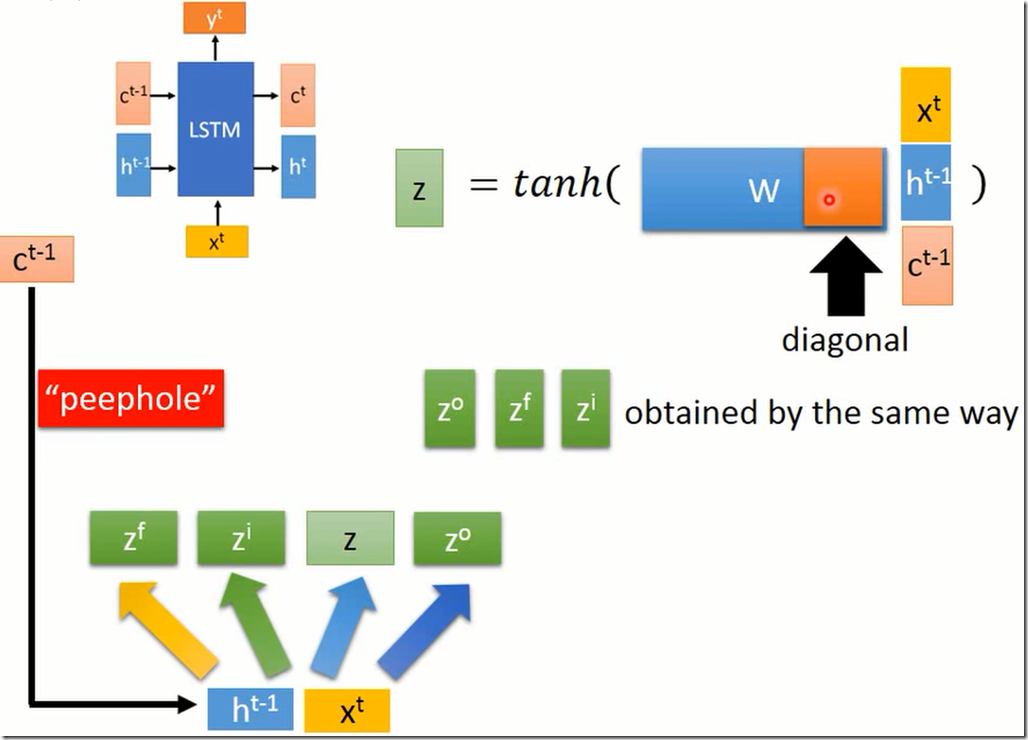
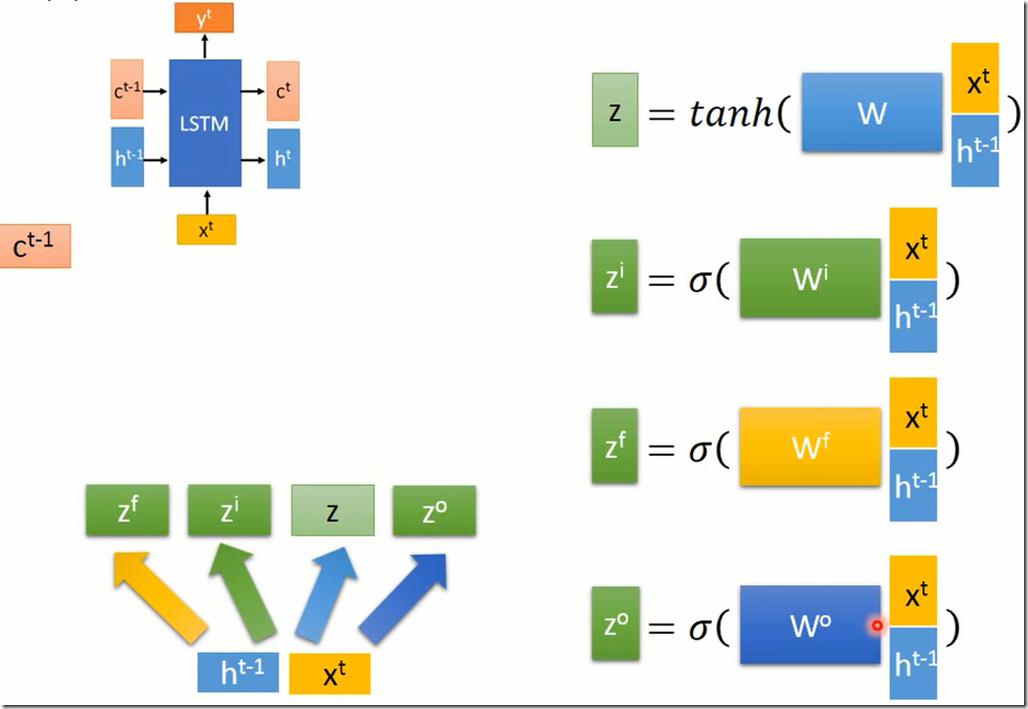
然后如下运算
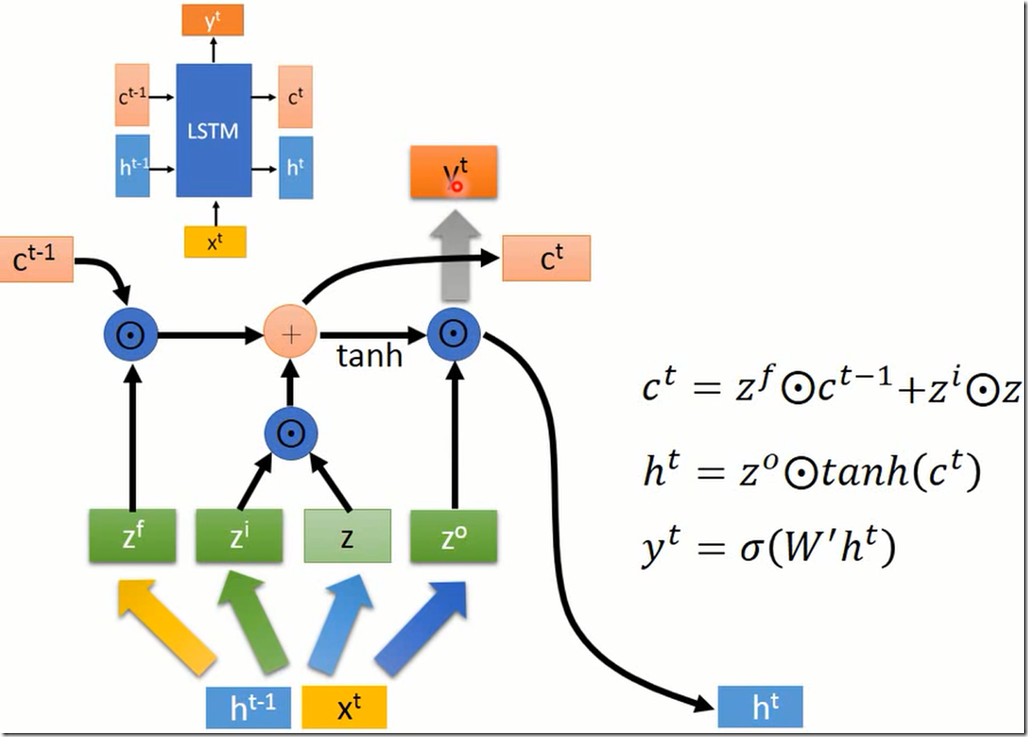
z_i是输入门,决定了z的哪些信息流入,z_f是遗忘门,决定c_t-1的哪些信息遗忘。
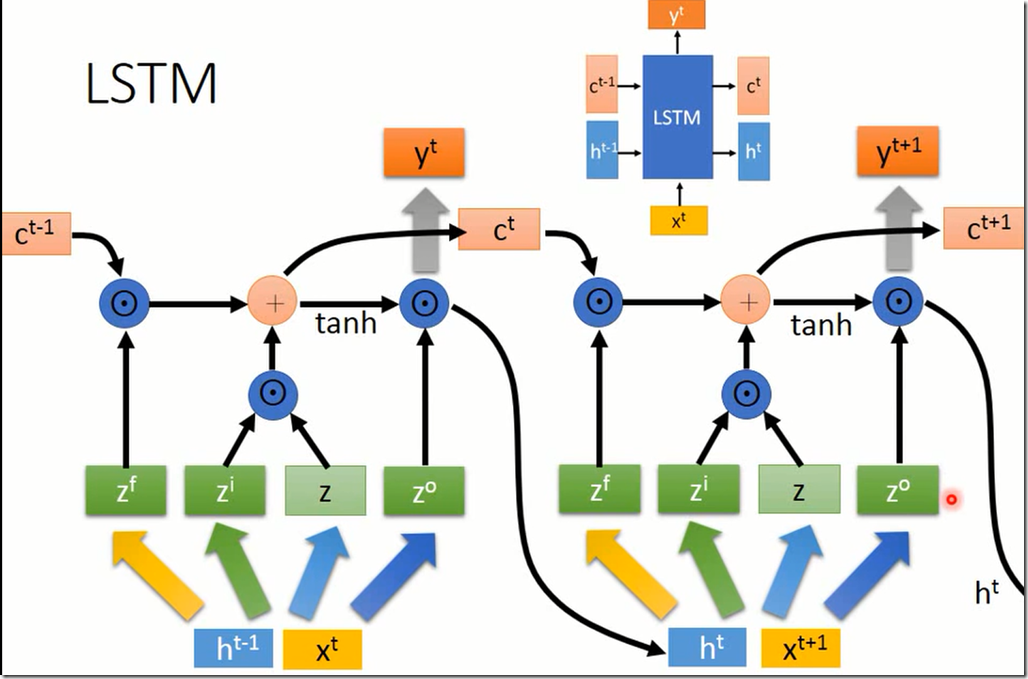
然后就可以反复这个步骤。,以上粗箭头表示乘以一个矩阵,细箭头表示啥也没做。
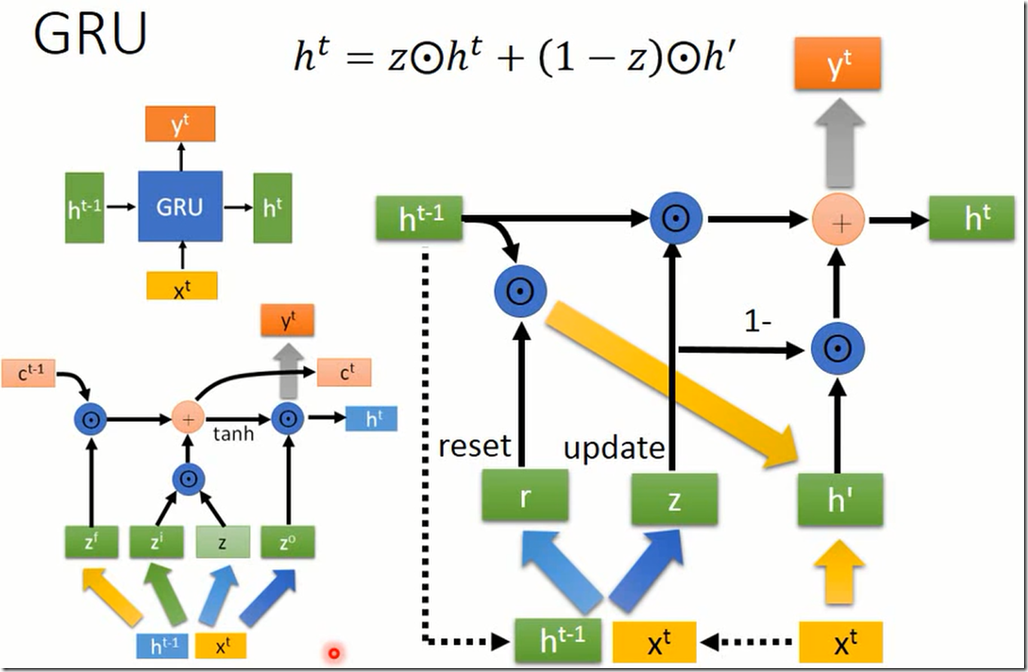
使用例子(下面是一些炼丹心得,详细了解需要认真去读原论文)

简化版的语音识别任务,每一段声音识别成一个因素即可,多分类问题。
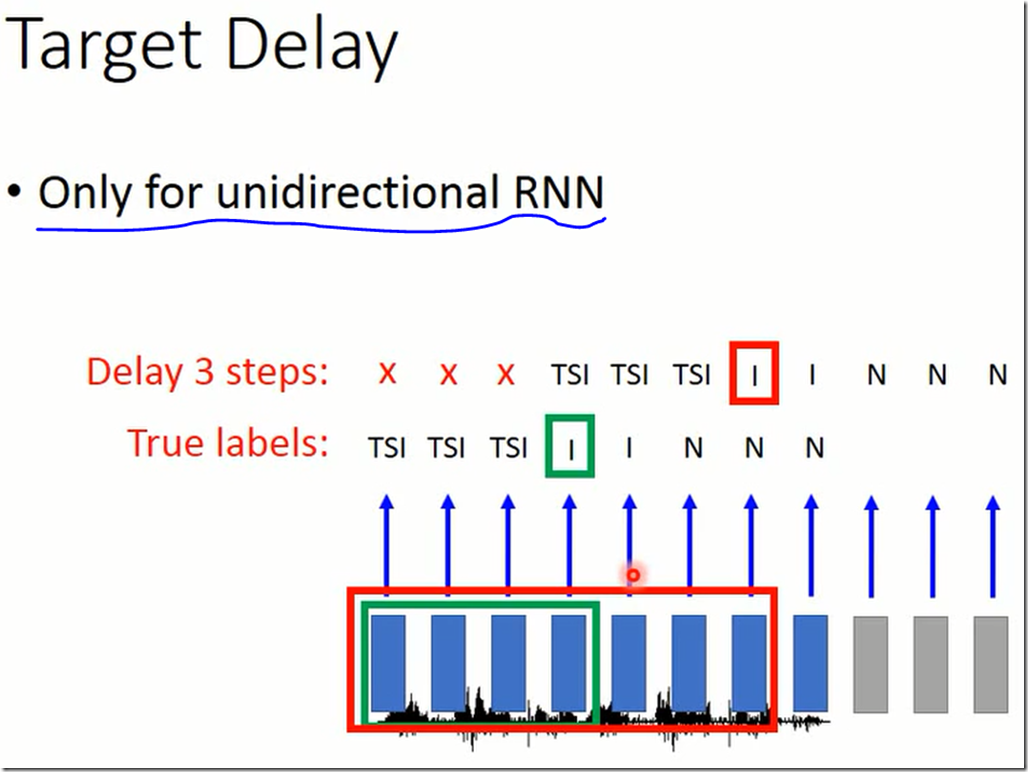
使用单项RNN有一个有效的trick是 Target Delay
在原始声音信号(frame)右端补若干个零(图中是3个),在识别时标签向后延后若干位开始做识别。
以上任务在若干种方法的实验效果
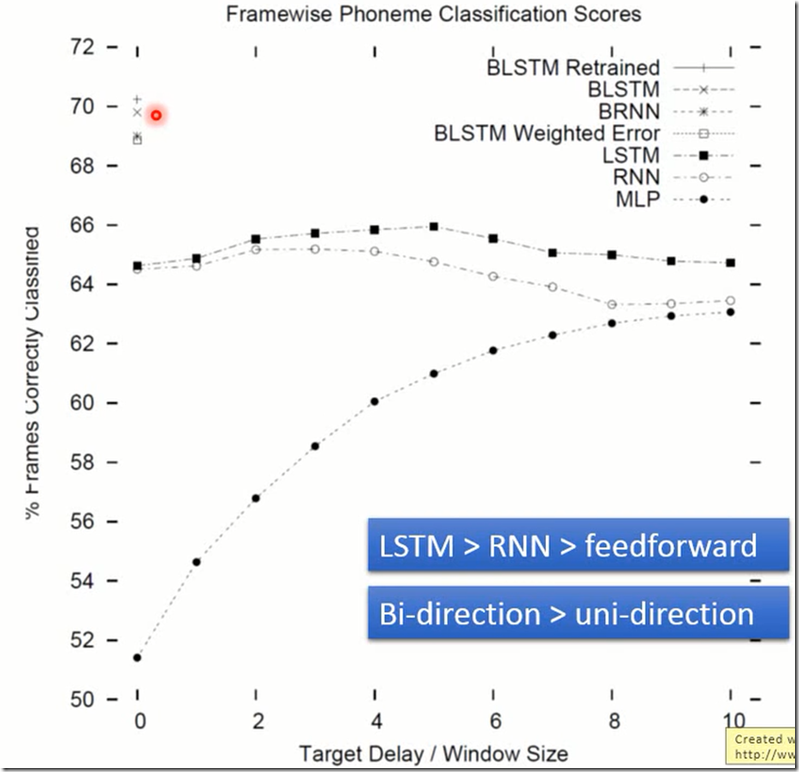
纵轴是分类正确率,横轴Window size是(如果是MLP)是指:如果input是一排frame(每个frame的声音信号可能只有0.01秒),每次判断时将前后若干frame拼接起来作为一个比较长的vector去判断中间一个frame的标签是什么。图中MLP方法的Window
size为10时效果最好。
横轴target delay是(如果是RNN或LSTM)是指label往右shift几个frame。
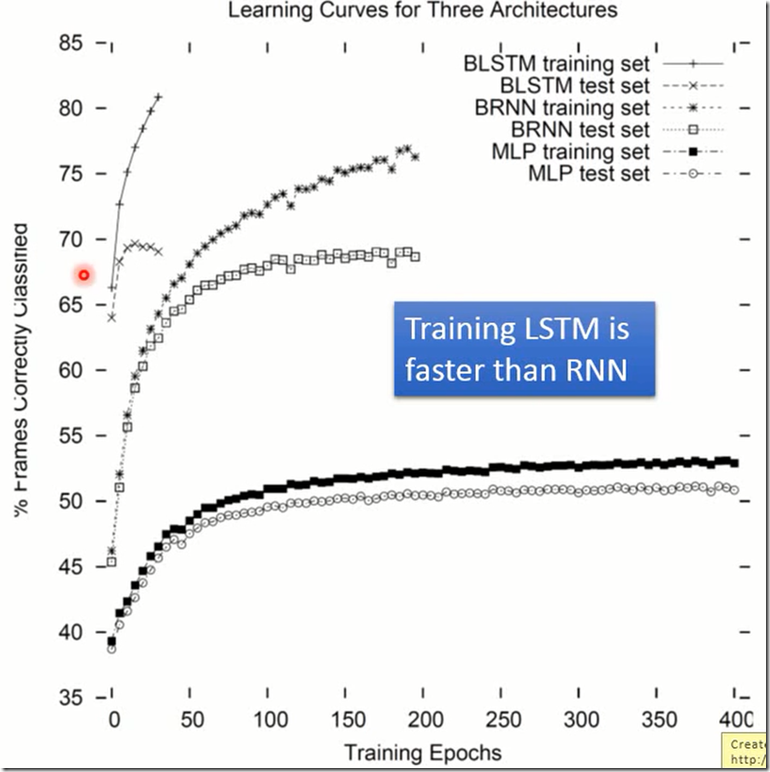
上面这个图的横轴是训练的轮数,从图中可以看出LSTM的训练速度比RNN更快
下面这个图是LSTM的各种架构跑的结果。论文名字叫LSTM 漫游。尝试了各种各样的LSTM架构和参数。

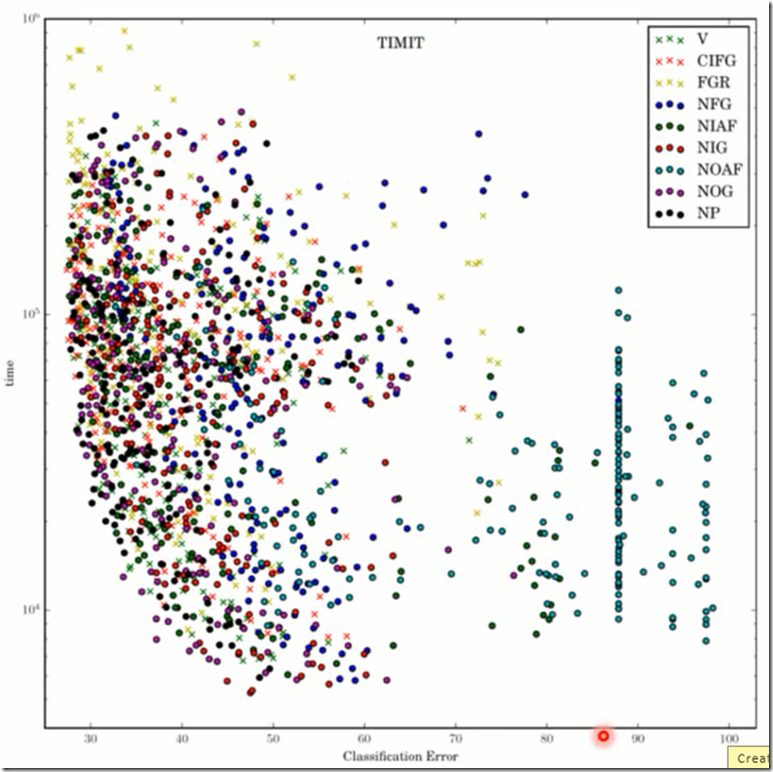
横轴是错误率,纵轴是训练时间。不同的颜色代表不同的LSTM架构,相同的颜色不同的点代表同样的架构,不同的参数。
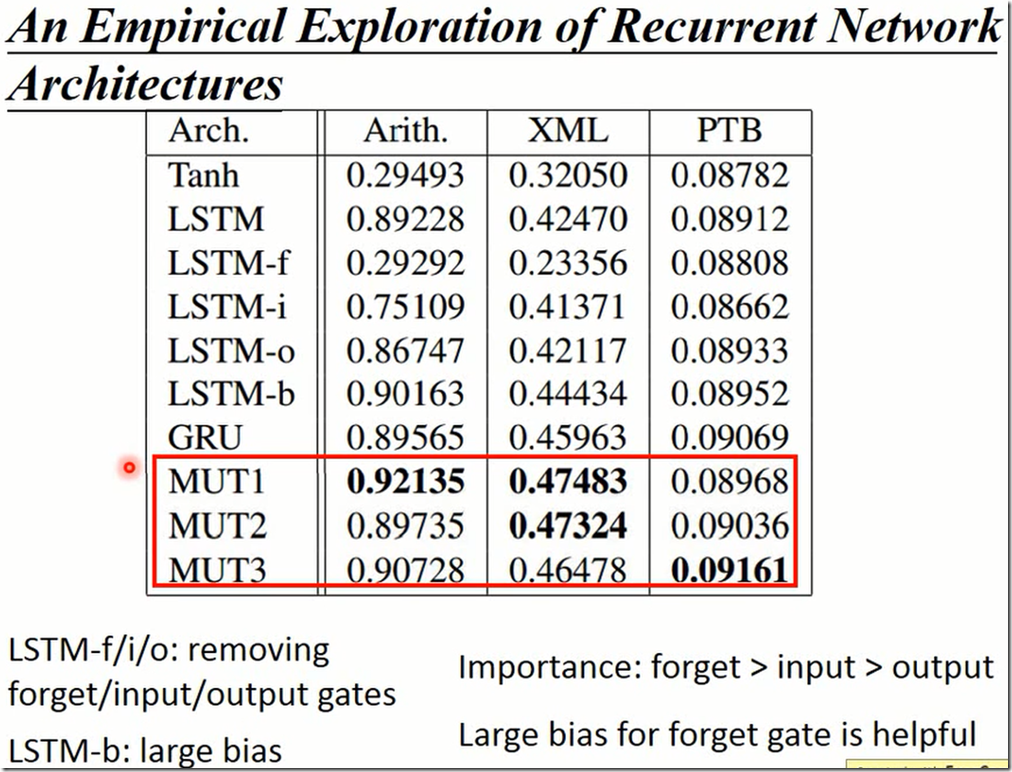
后面三个MUT1、MUT2、MUT3使用基因演算法去寻找最佳的RNN结构,使用LSTM和GRU的结构为初始基因,使用不同的组合去找。

还有一个比较经典的RNN结构,普通的RNN受输入长度的限制。输入过长时,内存或显存放不下。而下面这个结构Stack
RNN输入可以无限长,它是将输入每N个取出来放到一个function里输出需要存储的information同时输出push、pop、nothing操作。具体详见论文吧。
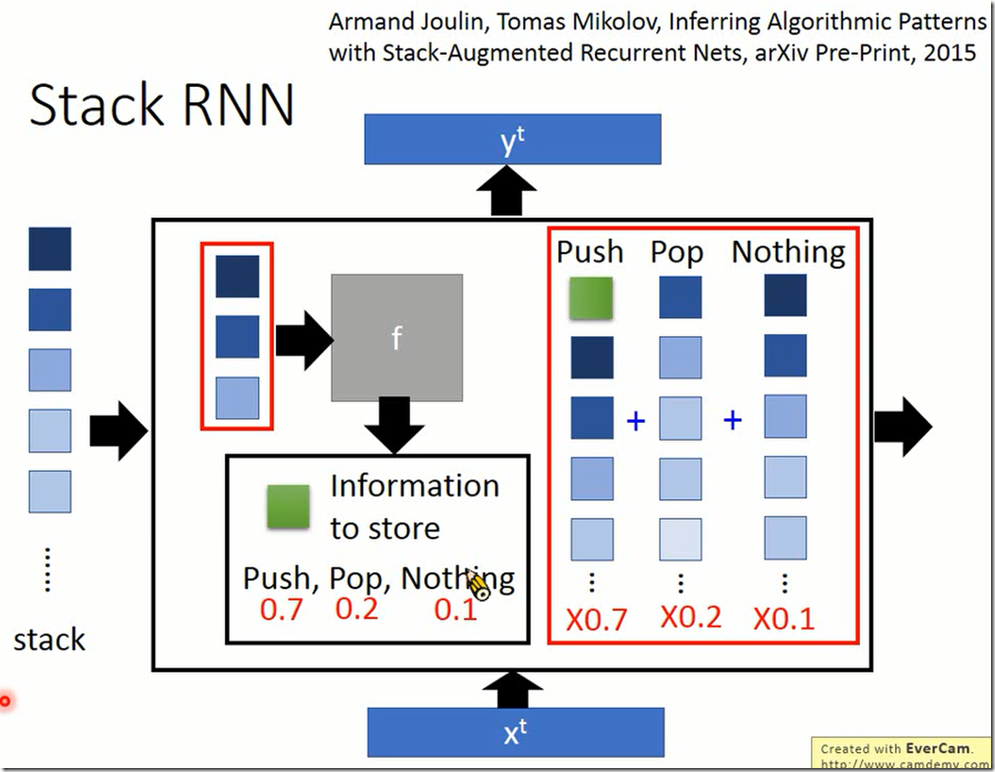
|









