| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌБОЮФДѓжТЗжГЩСНДѓВПЗжЃЌЕквЛВПЗжГЂЪдНЋБОЮФЩцМАЕФЗжРрЦїЭГвЛЕНЩёОдЊРрФЃаЭжаЃЌЕкЖўВПЗжВћЪіОэЛ§ЩёОЭјТчЃЈCNNЃЉЕФЗЂеЙМђЪіКЭФПЧАЕФЯрЙиЙЄзїЁЃ
|
|
ЧАбд
БОЮФЩцМАЕФЗжРрЦїЃЈЗжРрЗНЗЈЃЉгаЃК
ЯпадЛиЙщ
ТпМЛиЙщЃЈМДЩёОдЊФЃаЭЃЉ
ЩёОЭјТчЃЈNNЃЉ
жЇГжЯђСПЛњЃЈSVMЃЉ
ОэЛ§ЩёОЭјТчЃЈCNNЃЉ
ДгЩёОдЊЕФНЧЖШРДПДЃЌЩЯЪіЗжРрЦїЖМПЩвдПДГЩЩёОдЊЕФвЛВПЗжЛђепЩёОдЊзщГЩЕФЭјТчНсЙЙЁЃ
ИїЗжРрЦїМђЪі
ТпМЛиЙщ
ЫЕТпМЛиЙщжЎЧАашвЊМђЪівЛЯТЯпадЛиЙщЁЃ
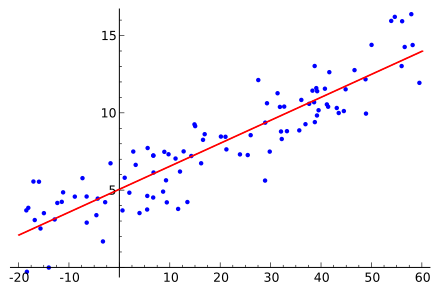
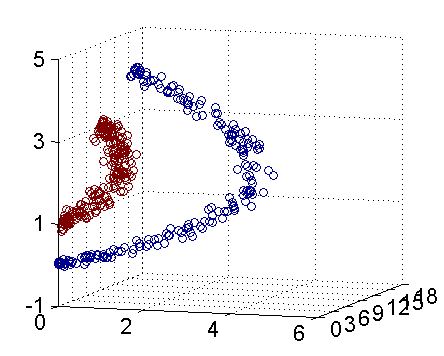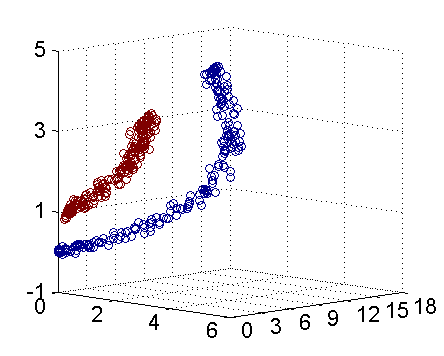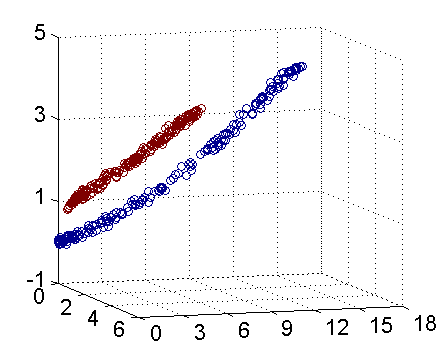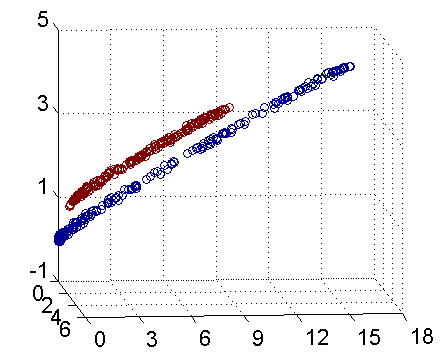
ЭМ1 ЕЅБфСПЕФЯпадЛиЙщ
ЭМ1жаУшЪіСЫвЛИіЕЅБфСПЕФЯпадЛиЙщФЃаЭЃКРЖЕуДњБэздБфСПxЕФЗжВМЁЊЁЊЯдШЛxГЪЯжЯпадЗжВМЁЃгкЪЧЮвУЧПЩвдгУЯТУцЕФЪНзгЖдЦфНјааФтКЯЃЌМДЮвУЧЕФФПБъКЏЪ§ПЩвдаДГЩ:
ДгЕЅБфСПЕНЖрБфСПФЃаЭЃЌашвЊНЋБфГЩЯђСПЃЌЭЌЪБШЈживВашвЊБфГЩЯђСПЁЃ
ЖјвЛАуЯпадЛиЙщЕФЫ№ЪЇКЏЪ§ЛсгУХЗЪЯОрРыРДНјааКтСПЃЌМДГЃЫЕЕФзюаЁЖўГЫЗЈЃЌЕЅИібљБОЕФЫ№ЪЇКЏЪ§ПЩвдаДГЩЃК
ЖјТпМЛиЙщЃЌПЩвдМђЕЅРэНтГЩЯпадЛиЙщЕФНсЙћМгЩЯСЫвЛИіsigmoidКЏЪ§ЁЃ
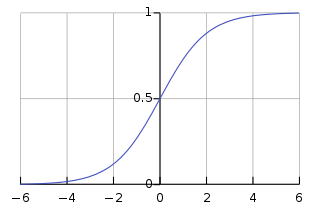
ЭМ2 sigmoid КЏЪ§ЭМЯё
ДгБОжЪЩЯРДЫЕЃЌМгЩЯsigmoidКЏЪ§ЕФФПЕФдкгкФмЙЛНЋКЏЪ§ЪфГіЕФжЕгђДггГЩфЕНжЎМфЃЌгкЪЧПЩвдЫЕТпМЛиЙщЕФЪфГіФмЙЛДњБэвЛИіЪТМўЗЂЩњЕФИХТЪЁЃ
ТпМЗжРрЕФФПБъКЏЪ§КЭЕЅбљБОЫ№ЪЇКЏЪ§ЪЧЃК
етРяЮЊКЮвЊЪЙгУвЛИіИДдгЕФЫ№ЪЇКЏЪ§етЙЙдьСЫвЛИіЭЙКЏЪ§ЃЌЖјШчЙћжБНгЪЙгУзюаЁЖўГЫНјааЖЈвхЃЌЫ№ЪЇКЏЪ§ЛсБфГЩЗЧЭЙКЏЪ§ЁЃ
ЪЕМЪЩЯТпМЛиЙщФЃаЭЫфШЛУћзжДјгаЛиЙщЃЌЪЕМЪЩЯвЛАугУгкЖўЗжРрЮЪЬтЁЃМДЖдЩшжУвЛИіуажЕЃЈвЛАуЪЧ0.5ЃЉЃЌБуЪЕЯжСЫЖўЗжРрЮЪЬтЁЃ
ЖјТпМЛиЙщФЃаЭЕФСэЭтвЛИіУћГЦЮЊЩёОдЊФЃаЭЁЊЁЊМДЮвУЧШЯЮЊДѓФдЕФЩёОдЊгазХЯёЩЯЪіФЃаЭвЛбљЕФНсЙЙЃКвЛИіЩёОдЊЛсИљОнгыЫќЯрСЌЕФЩёОдЊЕФЪфШыЃЈЃЉзіГіЗДгІЃЌОіЖЈздЩэЕФМЄЛюГЬЖШЃЈвЛАугУsigmoidКЏЪ§КтСПМЄЛюГЬЖШЃЉЃЌВЂНЋМЄЛюКѓЕФЪ§жЕЃЈЃЉЪфГіЕНЦфЫћЩёОдЊЁЃ
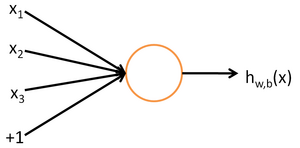
ЭМ3 ТпМЛиЙщФЃаЭЃЌМДЕЅИіЕФЩёОдЊФЃаЭ
ЩёОЭјТчЃЈNeural NetworkЃЌМђГЦNNЃЉ
ТпМЛиЙщЕФОіВпЦНУцЪЧЯпадЕФЃЌЫљвдЃЌЫќвЛАужЛФмЙЛНтОібљБОЪЧЯпадПЩЗжЕФЧщПіЁЃ
ШчЙћбљБОГЪЯжЗЧЯпадЕФЪБКђЃЌЮвУЧПЩвдв§ШыЖрЯюЪНЛиЙщЁЃ

ЭМ4 ЖрЯюЪНЛиЙщНтОібљБОЯпадВЛПЩЗжЕФЧщПіЃЌЭМЦЌРДздAndrew NgЕФMachine LearningПЮГЬЕФПЮМў
ЦфЪЕЃЌЖрЯюЪНЛиЙщвВПЩвдПДГЩЪЧЯпадЛиЙщЛђепТпМЛиЙщЕФвЛИіЬиР§ЁЊЁЊНЋЯпадЛиЙщЛђепТпМЛиЙщЕФЬиеїзЊЛЏЮЊЕШЗЧЯпадЕФЬиеїзщКЯЃЌШЛКѓЖдЦфНјааЯпадЕФФтКЯЁЃ
ЖрЯюЪНЛиЙщЫфШЛФмЙЛНтОіЗЧЯпадЮЪЬтЃЌЕЋашвЊШЫЙЄЙЙдьЗЧЯпадЕФЬиеїЃЌФЧУДЃЌЪЧЗёгавЛжжФЃаЭЃЌМШФмЙЛгІИЖбљБОЗЧЯпадПЩЗжЕФЧщПіЃЌгжЭЌЪБФмЙЛздЖЏЙЙдьЗЧЯпадЕФЬиеїФиЃП
Д№АИЪЧгаЕФЃЌетИіФЃаЭОЭЪЧЩёОЭјТчЁЃ
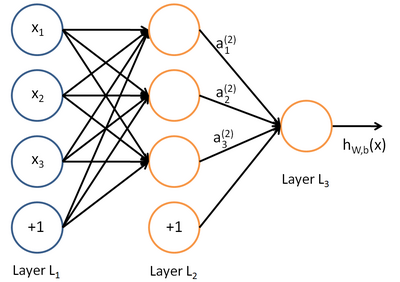
ЭМ5 ДјвЛИівўВуЕФЩёОЭјТчФЃаЭ
ШчЭМ5ЫљЪОЃЌУПИідВШІЖМЪЧвЛИіЩёОдЊЃЈЛђепЫЕЪЧвЛИіТпМЛиЙщФЃаЭЃЉЁЃЫљвдЩёОЭјТчПЩвдПДГЩЁАЯпадзщКЯ-ЗЧЯпадМЄЛюКЏЪ§-ЯпадзщКЯ-ЗЧЯпадМЄЛюКЏЪ§ЁЁБетбљЕФНЯЮЊИДдгЭјТчНсЙЙЃЌЫќЕФОіВпУцЪЧИДдгЕФЃЌгкЪЧФмЙЛЪЪгІбљБОЗЧЯпадПЩЗжЕФЧщПіЁЃ
СэвЛЗНУцЃЌЭМ5жажаМфвЛСаЕФГШЩЋЩёОдЊЙЙГЩЕФВуДЮЮвУЧГЩЮЊвўВуЁЃЮвУЧШЯЮЊвўВуЕФЩёОдЊЖддЪМЬиеїНјааСЫзщКЯЃЌВЂЬсШЁГіРДСЫаТЕФЬиеїЃЌЖјетИіЙ§ГЬЪЧФЃаЭдкбЕСЗЙ§ГЬжаздЖЏЁАбЇЯАЁБГіРДЕФЁЃ
ЩёОЭјТчЕФfomulationЯрЖдНЯЮЊИДдгЃЌвбОГЌГіБОЮФЕФЗЖЮЇЃЌПЩВЮПМStandfordЕФЩюЖШбЇЯАНЬГЬ
жЇГжЯђСПЛњЃЈМђГЦSVMЃЉ
ЩёОЭјТчЕФГіЯжвЛЖШв§Ц№баОПШШГБЃЌЕЋЩёОЭјТчгаЫќЕФШБЕуЃК
вЛАуРДЫЕашвЊДѓСПЕФбЕСЗбљБО
ДњМлКЏЪ§БпНчИДдгЃЌЗЧЭЙЃЌДцдкЖрИіОжВПзюгХжЕЁЃ
ВЮЪ§втвхФЃК§ЃЌБШШчвўВуЕФЩёОдЊИіЪ§гІИУШЁЖрЩйвЛжБУЛгаЖЈТлЁЃ
ЧГВуЩёОЭјТчЖдгкЬиеїбЇЯАЕФБэДяФмСІгаЯоЁЃ
ЩюВуЩёОЭјТчЕФВЮЪ§ЗБЖрЃЌвЛЗНУцШнвзЕМжТЙ§ФтКЯЮЪЬтЃЌСэвЛЗНУцвђЮЊбЕСЗЪБМфЙ§ГЄЖјЕМжТВЛПЩбЇЯАЁЃ
гкЪЧЃЌдкЩЯЪРМЭ90ФъДњSVMБЛЬсГіРДКѓЃЌЩёОЭјТчвЛЖШЫЅТфСЫЁЃ
ФЧУДSVMЪЧЪВУДЃП
SVMЃЌИќзМШЗЕФЫЕЪЧL-SVMЃЌБОжЪЩЯвРШЛЪЧвЛИіЯпадЗжРрЦїЃЌSVMЕФКЫаФЫМЯыдкгкЫќЕФЗжРрзМдђЁЊЁЊзюДѓМфИєЃЈmax
marginЃЉ.
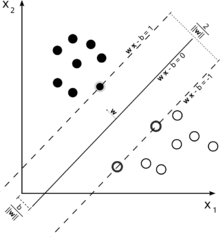
ЭМ6 L-SVMБОжЪЩЯЪЧзюДѓЗжРрМфИєЕФЯпадЗжРрЦї
ЭЌЮЊЯпадЗжРрЦїЕФЭиеЙЃЌТпМЛиЙщКЭL-SVMгазХЧЇЫПЭђТЦЕФЙиЯЕЃЌAndrew NgЕФПЮМўгавЛеХЭМКмЧхЮњЕиАбетСНепЕФДњМлКЏЪ§СЊЯЕЦ№РДСЫЃЈМћЭМ7ЃЉЁЃ
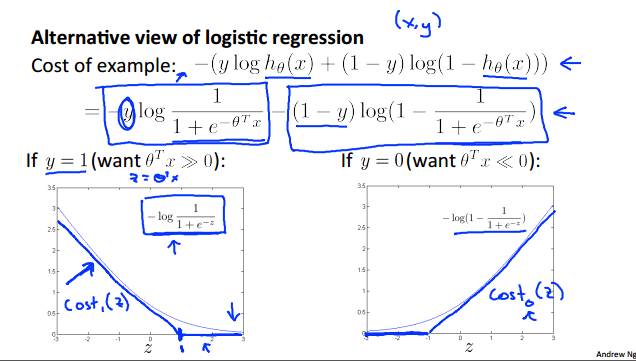
ЭМ7 L-SVMКЭТпМЛиЙщЕФДњМлКЏЪ§ЖдБШЃЌSVMЕФгавЛИіУїЯдЕФзЊелЕу
гЩгкL-SVMЪЧЯпадЗжРрЦїЃЌЫљвдВЛФмНтОібљБОЯпадВЛПЩЗжЕФЮЪЬтЁЃгкЪЧКѓРДШЫУЧв§ШыСЫКЫКЏЪ§ЕФИХФюЃЌгкЪЧЕУЕНСЫK-SVMЃЈKЪЧKernelЕФвтЫМЃЉЁЃДгБОжЪЩЯНВЃЌКЫКЏЪ§ЪЧгУгкНЋдЪМЬиеїгГЩфЕНИпЮЌЕФЬиеїПеМфжаШЅЃЌВЂШЯЮЊдкИпЮЊЬиеїПеМфжаФмЙЛЪЕЯжЯпадПЩЗжЁЃИіШЫШЯЮЊЃЌетИіИњЖрЯюЪНЛиЙщЕФЫМЯыЪЧРрЫЦЕФЃЌжЛВЛЙ§КЫКЏЪ§КРЈЕФЗЖЮЇИќМгЙуЃЌвдМАаЮЪНЩЯИќМггХбХЃЌЪЙЕУЫќФмЙЛБмУтЮЌЪ§джФбЁЃ
ЭМ8 KernelФмЙЛЖдЬиеїНјааЗЧЯпадгГЩф(ЭМЦЌfrom pluskid)
SVMБШЦ№ЩёОЭјТчгазХвдЯТЕФгХЕуЃК
ДњМлКЏЪ§ЪЧЭЙКЏЪ§ЃЌДцдкШЋОжзюгХжЕЁЃ
ФмЙЛгІИЖаЁбљБОМЏЕФЧщПі
ВЛШнвзЙ§ФтКЯЃЌВЂЧвгазХВЛДэЕФЗКЛЏадФмКЭТГАєад
КЫКЏЪ§ЕФв§ШыЃЌНтОіСЫЗЧЯпадЮЪЬтЃЌЭЌЪБЛЙБмУтСЫЮЌЪ§джФб
ИќЖрЙигкSVMЕФФкШнПЩвдВЮПМJulyЕФетЦЊЮФеТЃКжЇГжЯђСПЛњЭЈЫзЕМТлЃЈРэНтSVMЕФШ§ВуОГНчЃЉ
ШЛЖјЃЌЦфЪЕЮвУЧвРШЛПЩвдНЋSVMПДГЩвЛжжЬиЪтЕФЩёОдЊФЃаЭЃК
L-SVMБОжЪЩЯИњЕЅЩёОдЊЃЈМДТпМЛиЙщЃЉФЃаЭЕФзюДѓВюБ№ЃЌжЛЪЧДњМлКЏЪ§ЕФВЛЭЌЃЌЫљвдПЩвдНЋSVMвВРэНтГЩвЛжжЩёОдЊЃЌжЛВЛЙ§ЫќЕФМЄЛюКЏЪ§ВЛЪЧsigmoidКЏЪ§ЃЌЖјЪЧSVMЖРгаЕФвЛжжМЄЛюКЏЪ§ЕФЖЈвхЗНЗЈЁЃ
K-SVMжЛЪЧБШЦ№L-SVMЖрСЫвЛИіИКд№гУгкЗЧЯпадБфЛЛЕФКЫКЏЪ§ЃЌетИіИњЩёОЭјТчЕФвўВуЕФЫМЯывВЪЧвЛТіЯрГаЕФЁЃЫљвдK-SVMЪЕМЪЩЯЪЧСНВуЕФЩёОдЊЭјТчНсЙЙЃКЕквЛВуИКд№ЗЧЯпадБфЛЛЃЌЕкЖўВуИКд№ЛиЙщЁЃ
ЁЖЛљгкКЫКЏЪ§ЕФSVMЛњгыШ§ВуЧАЯђЩёОЭјТчЕФЙиЯЕЁЗвЛЮФжаЃЌШЯЮЊетСНепДгБэДяадРДЫЕЪЧЕШМлЕФЁЃЃЈзЂЃКетРяЕФЁАШ§ВуЧАЯђЩёОЭјТчЁБЪЕМЪЩЯЪЧДјвЛИівўВуЕФЩёОЭјТчЃЌЫЕЪЧШ§ВуЪЧвђЮЊЫќАбЭјТчЕФЪфШывВПДГЩвЛИіВуЁЃЃЉ
ОэЛ§ЩёОЭјТч
НќФъРДЃЌЩёОЭјТчгжжиаТаЫЪЂЦ№РДСЫЁЃгШвдЁАОэЛ§ЩёОЭјТчЁБЮЊЦфДњБэЁЃгкЪЧБОЮФЯТУцЕФЦЊЗљжївЊЮЇШЦОэЛ§ЩёОЭјТчНјааеЙПЊЁЃ
ЩњЮябЇЛљДЁ
в§здDeep LearningЃЈЩюЖШбЇЯАЃЉбЇЯАБЪМЧећРэЯЕСажЎЃЈЦпЃЉЁЃ
1962ФъHubelКЭWieselЭЈЙ§ЖдУЈЪгОѕЦЄВуЯИАћЕФбаОПЃЌЬсГіСЫИаЪмвА(receptive field)ЕФИХФюЃЌ1984ФъШеБОбЇепFukushimaЛљгкИаЪмвАИХФюЬсГіЕФЩёОШЯжЊЛњ(neocognitron)ПЩвдПДзїЪЧОэЛ§ЩёОЭјТчЕФЕквЛИіЪЕЯжЭјТчЃЌвВЪЧИаЪмвАИХФюдкШЫЙЄЩёОЭјТчСьгђЕФЪзДЮгІгУЁЃЩёОШЯжЊЛњНЋвЛИіЪгОѕФЃЪНЗжНтГЩаэЖрзгФЃЪНЃЈЬиеїЃЉЃЌШЛКѓНјШыЗжВуЕнНзЪНЯрСЌЕФЬиеїЦНУцНјааДІРэЃЌЫќЪдЭМНЋЪгОѕЯЕЭГФЃаЭЛЏЃЌЪЙЦфФмЙЛдкМДЪЙЮяЬхгаЮЛвЦЛђЧсЮЂБфаЮЕФЪБКђЃЌвВФмЭъГЩЪЖБ№ЁЃ
ЭЈГЃЩёОШЯжЊЛњАќКЌСНРрЩёОдЊЃЌМДГаЕЃЬиеїГщШЁЕФS-дЊКЭПЙБфаЮЕФC-дЊЁЃS-дЊжаЩцМАСНИіживЊВЮЪ§ЃЌМДИаЪмвАгыуажЕВЮЪ§ЃЌЧАепШЗЖЈЪфШыСЌНгЕФЪ§ФПЃЌКѓепдђПижЦЖдЬиеїзгФЃЪНЕФЗДгІГЬЖШЁЃаэЖрбЇепвЛжБжТСІгкЬсИпЩёОШЯжЊЛњЕФадФмЕФбаОПЃКдкДЋЭГЕФЩёОШЯжЊЛњжаЃЌУПИіS-дЊЕФИаЙтЧјжагЩC-дЊДјРДЕФЪгОѕФЃК§СПГЪе§ЬЌЗжВМЁЃШчЙћИаЙтЧјЕФБпдЕЫљВњЩњЕФФЃК§аЇЙћвЊБШжабыРДЕУДѓЃЌS-дЊНЋЛсНгЪметжжЗЧе§ЬЌФЃК§ЫљЕМжТЕФИќДѓЕФБфаЮШнШЬадЁЃЮвУЧЯЃЭћЕУЕНЕФЪЧЃЌбЕСЗФЃЪНгыБфаЮДЬМЄФЃЪНдкИаЪмвАЕФБпдЕгыЦфжааФЫљВњЩњЕФаЇЙћжЎМфЕФВювьБфЕУдНРДдНДѓЁЃЮЊСЫгааЇЕиаЮГЩетжжЗЧе§ЬЌФЃК§ЃЌFukushimaЬсГіСЫДјЫЋC-дЊВуЕФИФНјаЭЩёОШЯжЊЛњЁЃ
ЛљБОЕФЭјТчНсЙЙ
вЛИіНЯЮЊГіУћЕФCNNНсЙЙЮЊLeNet5ЃЌЫќЕФdemoПЩвдВЮПДетИіЭјеОЁЃЭМ9ЪЧLeNetЕФНсЙЙЪОвтЭМЁЃ
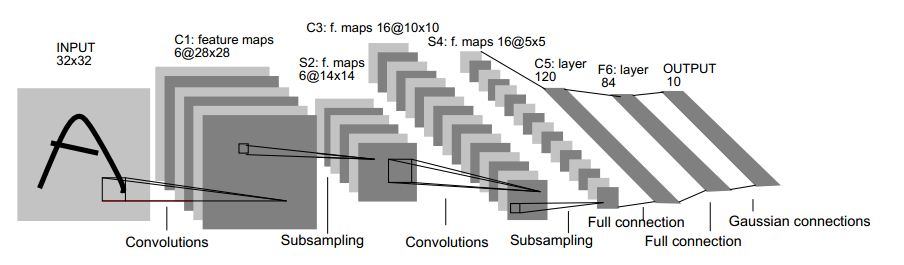
ЭМ9 LeNet5ЕФЭјТчНсЙЙЪОвтЭМ
ЭМжаЕФConvolutionsЖдгІСЫЩЯвЛЖЮЫЕЕФS-дЊЃЌSubsamplingЖдгІСЫЩЯвЛЖЮжаЫЕЕФC-дЊЁЃ
ЖдгкConvolutionВуЕФУПИіЩёОдЊЃЌЫќУЧЕФШЈжЕЖМЪЧЙВЯэЕФЃЌетбљзіЕФКУДІЪЧДѓДѓМѕЩйСЫЩёОЭјТчЕФВЮЪ§ИіЪ§ЁЃ
ЖдгкSamplingВуЕФУПИіЩёОдЊЃЌЫќУЧЪЧЩЯвЛВуConvolutionВуЕФОжВПЗЖЮЇЕФОљжЕ(ЛђепзюДѓжЕ)ЃЌФмЙЛгааЇЕиЬсЙЉОжВПЕФЦНвЦКЭа§зЊВЛБфадЁЃ
ЮЊКЮЩёОЭјТчжиаТаЫЦ№ЃП
ОэЛ§ЩёОЭјТчЪєгквЛжжЩюЖШЕФЩёОЭјТчЃЌШчЩЯЮФЫљЫЕЃЌЩюЖШЩёОЭјТчдкжЎЧАЪЧВЛПЩМЦЫуЕФЃЌжївЊЪЧгЩгкЭјТчВуДЮБфЩюКѓЛсЕМжТЯТУцЮЪЬтЃК
гЩгкЭјТчВЮЪ§діЖрЃЌЕМжТСЫбЯжиЕФЙ§ФтКЯЯжЯѓ
дкбЕСЗЙ§ГЬжаЃЌЖдЩюЖШЭјТчЪЙгУBPЫуЗЈДЋВЅЪБКђЬнЖШбИЫйМѕЩйЃЌЕМжТЧАУцЕФЭјТчЕУВЛЕНбЕСЗЃЌЭјТчФбвдЪеСВЁЃ
ЖјетСНИіЮЪЬтдкФПЧАЖМЕУЕНСЫНЯКУЕФНтОіЃК
ЙВЯэШЈжЕЃКМДЩЯЮФЬсЕНЕФОэЛ§ВуЕФОэЛ§КЫШЈжЕЙВЯэЃЌДѓДѓМѕЩйСЫЭјТчжаВЮЪ§ЕФЪ§СПМЖЁЃ
МгДѓЪ§ОнСПЃКвЛИіЪЧЭЈЙ§жкАќЕФЗНЪНРДдіМгбљБОЕФСПМЖЃЌБШШчЃЌФПЧАImageNetвбОгаСЫ120ЭђЕФДјБъзЂЕФЭМЦЌЪ§ОнЁЃСэвЛИіЪЧЭЈЙ§ЖдвбгаЕФбљБОНјааЫцЛњНиШЁЁЂОжВПШХЖЏЁЂаЁНЧЖШХЄЖЏЕШЗНЗЈЃЌРДБЖдівбгаЕФбљБОЪ§ЁЃ
ИФБфМЄЛюКЏЪ§ЃКЪЙгУReLU)зїЮЊМЄЛюКЏЪ§ЃЌгЩгкReLUЕФЕМЪ§Ждгке§Ъ§ЪфШыРДЫЕКуЮЊ1ЃЌФмЙЛКмКУЕиНЋЬнЖШДЋЕНЮЛгкЧАУцЕФЭјТчЕБжаЁЃ
DropoutЛњжЦЃКHintonдк2012ЬсГіСЫDropoutЛњжЦЃЌФмЙЛдкбЕСЗЙ§ГЬжаНЋЭЈЙ§ЫцЛњНћжЙвЛАыЕФЩёОдЊБЛаоИФЃЌБмУтСЫЙ§ФтКЯЕФЯжЯѓЁЃ
GPUБрГЬЃКЪЙгУGPUНјаадЫЫуЃЌБШЦ№CPUЪБДњдЫЫуадФмгаСЫЪ§СПМЖЕФЬсЩ§ЁЃ
ЩЯЪіЮЪЬтЕУЕНгааЇНтОіКѓЃЌЩёОЭјТчЕФгХЪЦОЭЕУЕНГфЗжЕФЯдЯжСЫЃК
ИДдгФЃаЭДјРДЕФЧПДѓЕФБэДяФмСІ
гаМрЖНЕФздЖЏЬиеїЬсШЁ
гкЪЧЩёОЭјТчФмЙЛЕУЕНжиаТаЫЦ№ЃЌвВОЭПЩвдНтЪЭСЫЁЃЯТЮФЛсбЁШЁвЛаЉбљР§РДЫЕУїЩёОЭјТчЕФЧПДѓжЎДІЁЃ
CNNбљР§1 AlexNet
дкImageNetОйАьЕФДѓЙцФЃЭМЯёЪЖБ№БШШќILSVRC2012жаЗжРрБШШќжаЃЌHintonЕФбЇЩњAlexДюНЈСЫвЛИі8ВуЕФCNNЃЌзюжеtop-5ЕФТЉБЈТЪЪЧ16%ЃЌХзРыЖјЕкЖўУћЕФ27%ећећга11ИіАйЗжЕуЁЃ
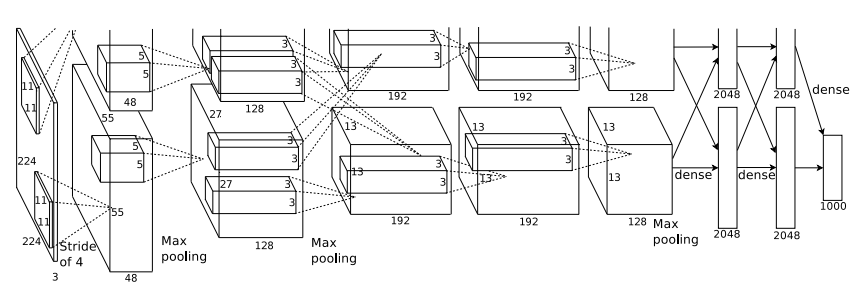
ЭМ10 AlexNetЕФCNNНсЙЙЃЌАќРЈ5ИіОэЛ§ВуЃЌКЭ3ИіШЋСЌНгВуЃЌзюКѓвЛИіsoftmaxЗжРрЦї
етИіЭјТчжагУЕНЕФММЪѕгаЃК
ReLUМЄЛюКЏЪ§
ЖрGPUБрГЬ
ОжВПе§дђЛЏЃЈLocal Response NormalizationЃЉ
жиЕўЕФЯТВЩбљЃЈOverlapping PoolingЃЉ
ЭЈЙ§ЫцЛњНиШЁКЭPCAРДдіМгЪ§Он
Dropout
CNNбљР§2 deconvnet
дкЯТвЛФъЕФБШШќILSVRC2013жаЃЌдкЭЌбљЕФЪ§ОнМЏЭЌбљЕФШЮЮёЯТЃЌMatthewНјвЛВННЋТЉБЈТЪНЕЕНСЫ11%ЁЃЫћЪЙгУСЫвЛИіБЛУќУћЮЊЁАDeconvolutional
NetworkЁБЃЈМђГЦdeconvnetЃЉЕФММЪѕЁЃ
MatthewЕФКЫаФЙЄзїдкгкГЂЪдНЋCNNбЇЯАГіРДЕФЬиеїгГЩфЛидЭМЦЌЃЌРДЖдУПИіОэЛ§ВузюОпгаХаБ№адЕФВПЗжЪЕЯжПЩЪгЛЏЁЊЁЊвВОЭЪЧЃЌЙлВьCNNдкОэЛ§ВужабЇЯАЕНСЫЪВУДЁЃ
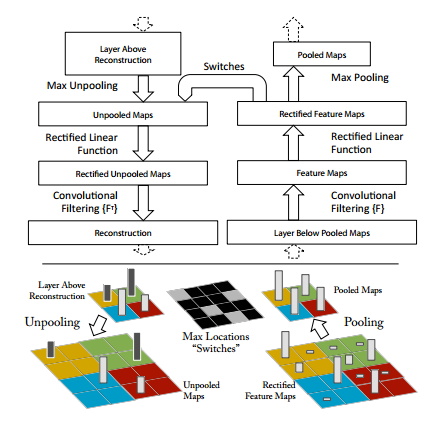
ЭМ11 deconvnetЕФЫМЯыЪЧНЋЭјТчЕФЪфГіЛЙдГЩЪфШы
CNNбљР§3 DeepPose
DeepPoseЕФЙБЯздкгкЫќЖдCNNЪЙгУСЫМЖСЊЕФЫМЯыЃКЪзЯШЃЌПЩвдгУЕквЛВуCNNДѓжТЖЈЮЛГіШЫЮяЕФЙиНкЮЛжУЃЌШЛКѓЪЙгУЗДИДЪЙгУЕкЖўВуЩёОЭјТчЖдЕквЛВуЭјТчНјааЮЂЕїЃЌвдДяЕНОЋЯИЖЈЮЛЕФФПЕФЁЃ
ДгСэЭтвЛИіНЧЖШЃЌетИіЙЄзївВЫЕУїСЫЃЌCNNВЛНіФмЙЛгІИЖЗжРрЮЪЬтЃЌвВФмЙЛгІИЖЖЈЮЛЕФЮЪЬтЁЃ

ЭМ12 DeepPoseЭЈЙ§МЖСЊЕиЪЙгУCNNРДДяЕНОЋЯИЖЈЮЛЙиНкЕФЮЛжУ
CNNбљР§4 CNN vs ШЫЙЄЬиеї
CNN Features off-the-shelf: an Astounding Baseline
for Recognition
ИУЙЄзїжМдкбщжЄCNNЬсШЁГіРДЕФЬиеїЪЧЗёгааЇЃЌгкЪЧзїепзіСЫетбљЕФвЛИіЪЕбщЃКНЋдкILSVRC2013ЕФЗжРр+ЖЈЮЛБШШќжаЛёЪЄЕФOverFeatЭХЖгЪЙгУCNNЬсШЁГіРДЕФЬиеїЃЌМгЩЯвЛИіL-SVMКѓЙЙГЩСЫвЛИіЗжРрЦїЃЌШЅИњИїИіЮяЬхЗжРрЕФЪ§ОнМЏЩЯФПЧАзюКУ(state-of-the-art)ЕФЗНЗЈНјааБШНЯЃЌНсЙћМИКѕШЁЕУСЫШЋУцЕФгХЪЄЁЃ
змНс
БОЮФЖдЪ§ИіЗжРрЦїФЃаЭНјааСЫНщЩмЃЌВЂГЂЪдЭГвЛЕНЩёОдЊЭјТчФЃаЭЕФПђМмжЎжаЁЃ
ЩёОдЊЭјТчФЃаЭЕФЗЂеЙвЛжБЗЂЩњЭЃжЭЃЌжЛЪЧдкжаЭОгазХВЛЭЌЕФЗЂеЙЗНЯђКЭжиЕуЁЃ
ЩёОдЊЭјТчФЃаЭЪЧИіМЋЦфгааЇЕФФЃаЭЃЌНќФъРДгЩгкбљБОЪ§СПКЭМЦЫуадФмЖМЕУЕНСЫМИКЮСПМЖЕФЬсИпЃЌCNNетвЛЩюЖШПђМмЕУвдЗЂЛгЫќЕФгХЪЦЃЌдкМЦЫуЛњЪгОѕЕФЪ§ИіСьгђЖМШЁЕУСЫВЛЗЦЕФГЩОЭЁЃ
ФПЧАРДЫЕЃЌЖдCNNБОЩэЕФбаОПЛЙВЛЙЛЩюШыЃЌCNNаЇЙћЫфШЛгХауЃЌЕЋЖдгкЮвУЧРДЫЕвРШЛЪЧвЛИіКкКазгЁЃХЊЧхГўетИіКкКазгЕФЙЙдьЃЌДгЖјИќКУЕиШЅИФНјЫќЃЌЛсЪЧвЛИіЯрЕБживЊЕФЙЄзїЁЃ |






