| 编辑推荐: |
本文来自于网络,介绍了如何选择并训练模型,处理数据,以及在终端移动设备上工程化落地深度神经网络并做GPU加速,。
|
|
前言
AI无疑是近几年的超级风口,“All in AI“等押宝AI的口号层出不穷,AI的风头一时无两。实现AI有很多种途径方法,这其中深度学习神经网络被认为是最有可能实现AI的途径。作为工程人出身的我们,更是迫切需要主动去迎接AI时代的到来,带着智能图像识别的需求,我们尝试去工程化深度神经网络并最终落地,当中的一些实践经验通过本文记录下来。
MobileNet模型
MobileNet是谷歌为移动终端设备专门设计的高效深度神经网络模型,整个模型的参数量以及运算量都控制的比较小,并且在图像分类和物体检测等任务上均有着非常不错的效果。基于MobileNet模型在移动终端设备上良好的性能,我们最终选择使用MobileNet来实现图片分类的功能(PS:我们选择的MobileNet版本是MobileNet
V1,因此这里的MobileNet指的是MobileNet V1)。
MobileNet的模型结构如下图所示:
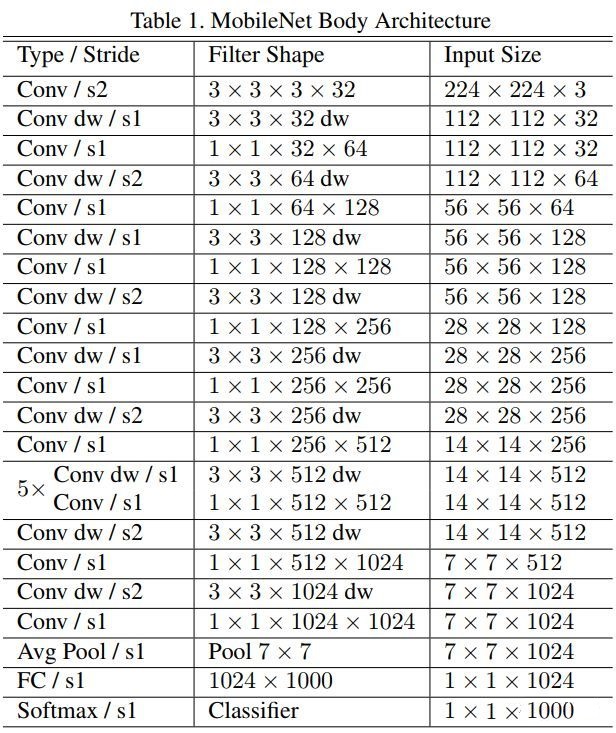
MobileNet是基于深度可分离卷积的,即把一个标准的卷积拆分成一个深度卷积(depthwise
convolution)和一个逐点卷积(pointwise convolution),如图:
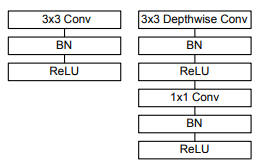
MobileNet在第一层普通卷积层后,后面进行了多次深度可分离卷积,这么做的好处是在保留了图像特征的同时大幅度降低了模型的参数量和计算量。这是如何做到的呢?
假设对一张DF×DF×M的图像做卷积,标准的卷积操作是图像的每个通道分别和每个卷积核对应的通道做卷积,如下图,这是N个通道数是M的DK×DK卷积核:
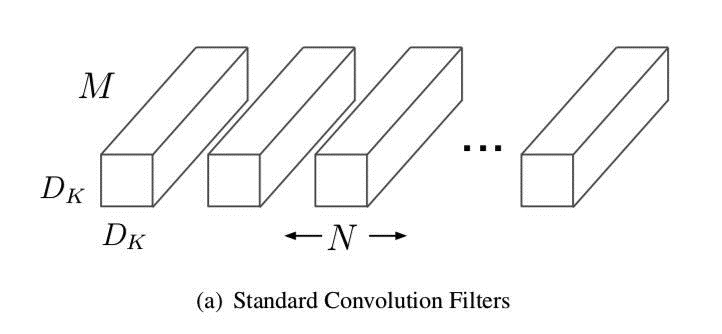
这里面的参数量是DK×DK×M×N,卷积操作的计算量是DK×DK×M×N×DF×DF。
如果换成深度可分离卷积来处理,那么第一步先做深度卷积,下图是M个通道数是1的DK×DK卷积核:
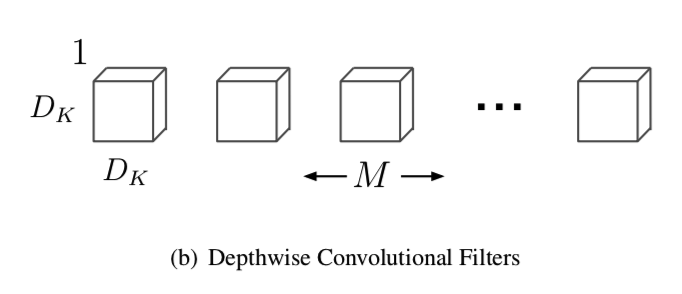
深度卷积的卷积核的通道数是1,图像的每个通道直接和每个卷积核下的唯一通道做卷积,参数量是DK×DK×M,卷积操作的计算量是DK×DK×M×DF×DF。假设深度卷积的填充方式是SAME卷积,即卷积输出的尺寸和输入尺寸相同,深度卷积这一步得到的还是一张DK×DK×M的图。
紧接着做逐点卷积,下图是N个通道数是M的1×1卷积核:
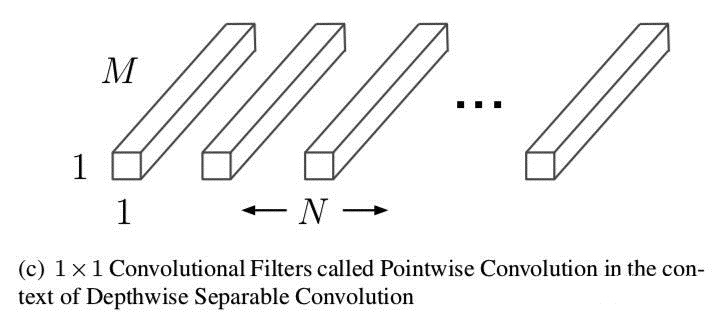
这里面的参数量是1×1×M×N,卷积操作的计算量是1×1×M×N×DF×DF。
因此,深度可分离卷积的总参数量是DK×DK×M+M×N,减少到标准卷积的
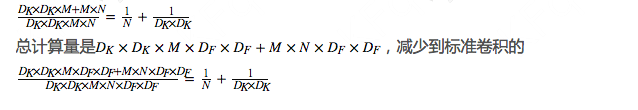
在大幅减少了卷积的计算量和参数量的情况下,它的准确率只下降了1%左右,如下图所示:

以上我们可以看出,MobileNet模型非常高效,且整个结构非常的精巧,实现一个深度可分离卷积跟实现一个标准卷积差不多,下面是一段深度卷积的简单C语言实现:
int output_count
= output_width * output_height * input_channel;
float *output = (float *)malloc(output_count *
sizeof(float));
int index = 0;
for (int i = 0; i < output_height; ++i)
{
for (int j = 0; j < output_width; ++j) {
for (int k = 0; k < input_channel; ++k) {
float sum = bias[k];
for (int m = 0; m < kernel_size; ++m) {
for (int n = 0; n < kernel_size; ++n) {
int ypos = i * stride + m - padding;
int xpos = j * stride + n - padding;
if (ypos < 0 || ypos >= input_height)
{
continue;
}
if (xpos < 0 || xpos >= input_width) {
continue;
}
float x = input[ypos * input_width * input_channel
+ xpos * input_channel + k];
float w = weights[(m * kernel_size + n) * input_channel
+ k];
sum += w * x;
}
}
sum = fmax(sum, 0.f);
sum = fmin(sum, 6.f);
output[index++] = sum;
}
}
} |
训练模型
MobileNet是开源
(https://github.com/tensorflow/models/blob
/master/research/slim/nets/mobilenet_v1.py)的,TensorFlow对MobileNet有非常好的支持(毕竟都是谷歌自己的东西),基于TensorFlow的slim模块代码实现非常的简洁优雅,并且还公开了预训练好的模型。但预训练好的模型是用于识别1001种类别,并不是我们自己想要的图片类别,为此,我们需要专门训练出用于识别指定图片类别的MobileNet模型。
收集数据
想要训练得到一个模型,首先就要为模型训练准备好数据,第一步就是收集数据了。我们目前收集数据的方式主要有以下几种:
1.开源数据集
目前,有许多开源数据集可以供我们使用,比较著名的开源数据集有ImageNet、MS-COCO、CIFAR-10等等,这些数据集拥有着大量的图片数据,比如ImageNet就有超过1400万张图片以及上万种图片类别,我们可以在这些数据集里寻找指定类别的图片数据。
2.数据上报
用户上报的数据当中,有大量的图片url数据,查询拿到一堆符合特征的图片url数据后,我们就可以通过图片url数据去下载到批量的图片数据。
3.爬虫抓取
此外,我们还通过爬虫的方式去抓取一些图片数据,比如到一些图库网站,百度图片等去爬虫抓取。许多功能齐全的网络爬虫框架可供使用,比如scrapy、pyspider
、grab等,这些爬虫框架大部分是基于Python语言的,Python语言简单好用,实现爬虫技术非常地简便,我们甚至可以自己实现一个简单的爬虫工具去抓取目标数据。
预处理数据
这一步其实是非常繁琐耗时的,人工对大量的图片数据做筛选分类非常耗费时间精力且极易出错。在预处理数据的实践过程中,我们用的比较多的有两种方式:
1.分工筛选分类
把收集到的图片数据分成好几批,每个人认领一批,所谓人多力量大在这里就体现的淋漓尽致了。
2.使用数据标注工具
使用数据标注工具可以大幅度提升图片标注的效率,目前比较常用的有Labelme、labelImg等,这些项目大多数是开源的,当这些工具不满足我们的特定需求时,我们可以在开源项目的基础上直接修改使用。
模型训练
收集并得到预处理的数据后,我们就可以开始训练模型的工作了。要训练出一个好的模型,除了好的数据,还需要应用到各式各样的训练算法和技巧,而这些工作神经网络框架已经帮我们做好了,我们所要做的是熟练使用神经网络框架的API和使用方法,并喂给数据,就可以启动训练工作了。这里使用的神经网络框架是Tensorflow,Tensorflow提供了丰富的资料和工具支持,比如通过TensorBoard,训练过程的准确率收敛情况、模型的图等都可以很直观的看到。
训练出一个效果不错的模型需要多次尝试和优化,并不是一蹴而就的,我们在实操训练过程中遇到了不少问题。
1.过拟合
训练时的准确率很高,但拿去跑训练数据以外的数据时,准确率却很低。这种情况下, 一种方式是通过增加正则项、dropout等技术手段去避免过拟合,另一种方式是研究识别出错的图片数据特征,增加数据的多样性并清除脏数据。
2.欠拟合
训练时的准确率比较低,不能收敛到一个满意的准确率水平。很多时候可以通过调整学习率、增加训练次数和减少正则化参数等等调节超参数的手段就可以解决。
3.训练速度慢
模型训练的时间耗时非常长,不能快速获取和验证模型。一方面可以通过硬件GPU加速的方式来加快训练次数,一方面是增加中断逻辑,准确率达到某个阀值时强行停止训练。
4.内存不足
训练过程中内存不足退出。我们后面采取分块训练的方式,避免一次装载所有数据,绕开了内存不足退出的问题。
迁移学习
很多时候,并没有足够丰富和优质的数据来供我们去训练模型,而迁移学习是一种能非常有效解决数据量过少的解决方案,能极大缩减训练耗时,又能取得良好的准确率结果,效果显著,非常适合我们这种缺乏数据的情况。
基于预训练好的MobileNet模型,我们在它最后一层输出层接上自己的一层全连接层,这层全连接层也就变成新的输出层。训练前,先计算并缓存好原MobileNet模型的输出层结果,训练时,只需要训练原输出层到新输出层之间的权重值即可。迁移学习即MobileNet的迁移实现可以参考这里的代码实现
(https://github.com/tensorflow/hub/blob/master/
examples/image_retraining/retrain.py)。
训练后模型的图所下图所示:
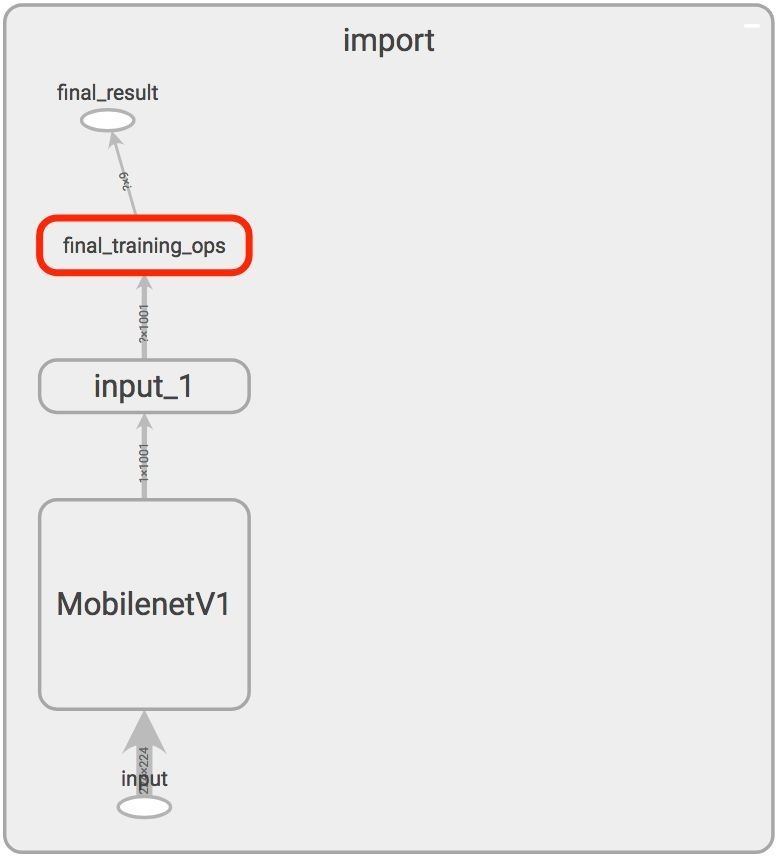
红框即为新增加的层。
终端部署
上面我们训练得到的模型是Tensorflow的模型,为了能在终端设备跑Tensorflow的模型,Tensorflow推出了Tensorflow
Mobile和Tensorflow Lite两套移动设备解决方案。相比较而言,Tensorflow
Lite更轻量级,但支持的节点ops有限,而Tensorflow Mobile虽然会重一点,但能在Tensorflow上跑的模型基本都能在Tensorflow
Mobile上跑。我们在Tensorflow Mobile上跑过Inception V3和MobileNet模型,但包大小比较大,而Tensorflow
Lite整个引擎占的包大小大概1M左右,机器发热情况也好很多,并且是支持MobileNet的,因此我们最终选择了Tensorflow
Lite。
模型转换
不管是在Tensorflow Lite还是在Tensorflow Mobile跑,Tensorflow的模型都需要使用Tensorflow提供的工具转换,压缩模型大小并调整内存布局,转换后的模型才能适合在移动终端设备上跑。
Tensorflow的模型一般为pb格式,图数据和参数数据都固化在pb文件里,Tensorflow提供了命令行,可以把pb文件转化成Tensorflow
Lite支持的tflite文件。要顺利运行命令行,需要先安装构建工具Bazel(https://bazel.build/),接着执行:
bazel run --config=opt
\
//tensorflow/contrib/lite/toco:toco -- \
--input_file=/tmp/mobilenet_v1_0.50_128/frozen_graph.pb
\
--output_file=/tmp/foo.tflite \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--inference_type=FLOAT \
--input_shape=1,128,128,3 \
--input_array=input \
--output_array=MobilenetV1/Predictions/Reshape_1 |
以上例子是用于转换Float版本的模型,为了减包,我们使用的是Quantized版本的模型。Float版本里权重参数是用4个字节的float类型表示的,而Quantized版本里权重参数用1个字节的uint8类型表示,模型大小是Float版本的四分之一。转换成Quantized版本的示例如下:
bazel run --config=opt
\
//tensorflow/contrib/lite/toco:toco -- \
--input_file=/tmp/some_quantized_graph.pb \
--output_file=/tmp/foo.tflite \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--inference_type=QUANTIZED_UINT8 \
--input_shape=1,128,128,3 \
--input_array=input \
--output_array=MobilenetV1/Predictions/Reshape_1
\
--mean_value=128 \
--std_value=127 |
终端运行模型
通过模型转换操作后,我们得到了一个可以在Tensorflow Lite跑的tflite文件。Tensorflow
Lite支持iOS和Android两大手机平台,架构如下图所示:
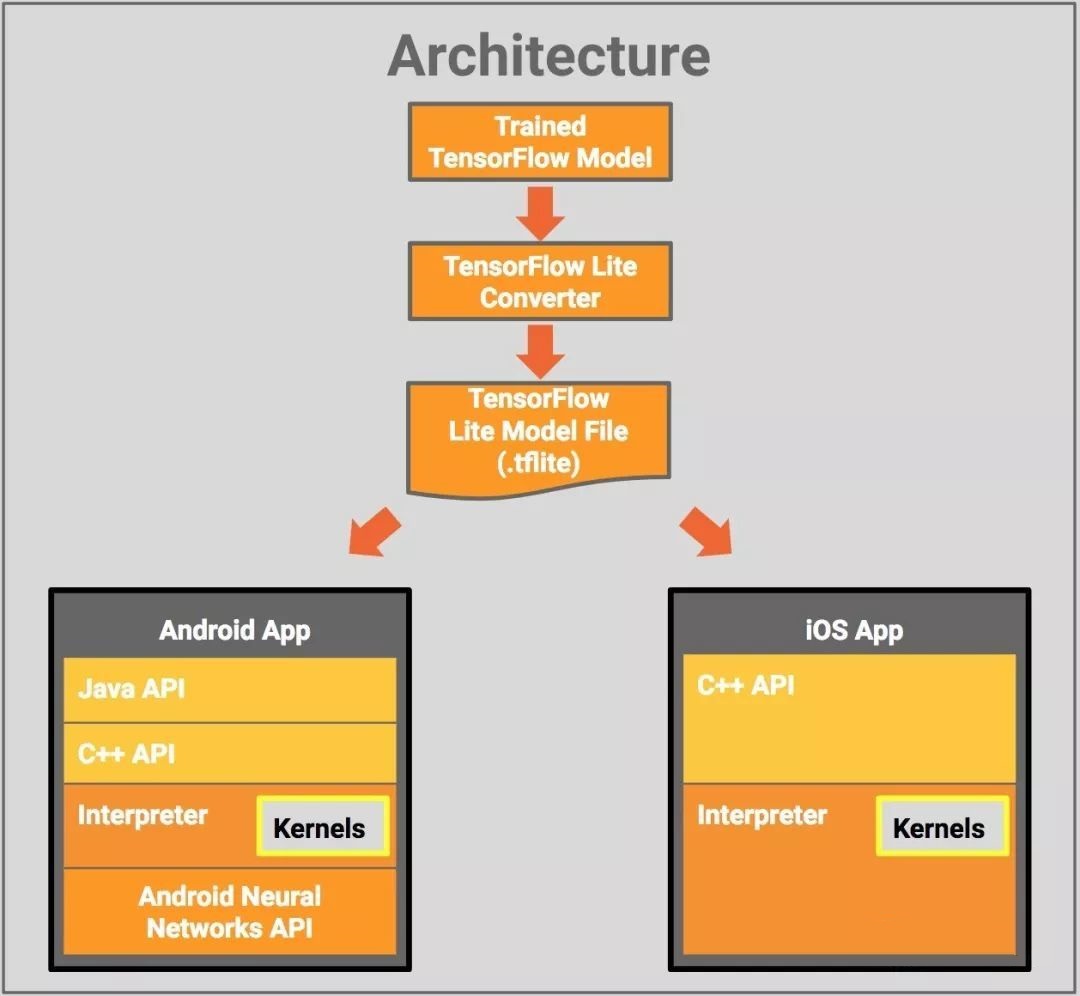
Tensorflow Lite在Android上是以.so的形式集成进app,iOS上则是以静态库.a的形式集成进app。集成了Tensorflow
Lite库的app就可以调用相关API来加载并运行模型。此外,官方提供了Tensorflow Lite的sample例子
(https://github.com/tensorflow/tensorflow/tree/
master/tensorflow/contrib/lite/examples),以iOS平台为例,首先是加载模型和图像分类信息:
NSString* graph_path
= FilePathForResourceName(model_file_name, @"tflite");
model = tflite::FlatBufferModel::BuildFromFile([graph_path
UTF8String]);
if (!model) {
LOG(FATAL) << "Failed to mmap model
" << graph_path;
}
LOG(INFO) << "Loaded model " <<
graph_path;
model->error_reporter();
LOG(INFO) << "resolved reporter";
tflite::ops::builtin::BuiltinOpResolver resolver;
LoadLabels(labels_file_name, labels_file_type,
&labels);
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
if (!interpreter) {
LOG(FATAL) << "Failed to construct
interpreter";
}
if (interpreter->AllocateTensors() != kTfLiteOk)
{
LOG(FATAL) << "Failed to allocate
tensors!";
} |
其次是格式化数据输入:
int input =
interpreter->inputs()[0];
uint8_t* out = interpreter->typed_tensor<uint8_t>(input);
for (int y = 0; y < wanted_input_height;
++y) {
uint8_t* out_row = out + (y * wanted_input_width
* wanted_input_channels);
for (int x = 0; x < wanted_input_width; ++x)
{
const int in_x = (y * image_width) / wanted_input_width;
const int in_y = (x * image_height) / wanted_input_height;
uint8_t* in_pixel = in + (in_y * image_width
* image_channels) + (in_x * image_channels);
uint8_t* out_pixel = out_row + (x * wanted_input_channels);
for (int c = 0; c < wanted_input_channels;
++c) {
out_pixel[c] = in_pixel[c];
}
} |
紧接着就可以传入数据作推断预测:
if (interpreter->Invoke()
!= kTfLiteOk) {
LOG(FATAL) << "Failed to invoke!";
} |
最后,取得预测结果并稍作处理:
const int output_size
= 1000;
const int kNumResults = 5;
const float kThreshold = 0.1f;
std::vector<std::pair<float, int>>
top_results;
uint8_t* output = interpreter->typed_output_tensor<uint8_t>(0);
GetTopN(output, output_size, kNumResults, kThreshold,
&top_results); |
到这里,我们已经训练出模型并成功落地到终端了。
GPU加速模型
虽然借助Tensorflow平台和Tensorflow Lite,模型已经可以在终端工作起来做图像识别分类了,但是Tensorflow
Lite是基于CPU去做推断预测的,推断预测的速度不够理想,CPU持续高负载运行还会带来手机发热的问题。于是,我们尝试用GPU去加速跑模型。
GPU编程技术选择
为了让模型在GPU上跑起来,我们需要针对GPU编程。在iOS平台上,我们选择了Metal,Metal能最大限度发挥iOS设备的GPU性能,在Android平台上,我们选择了OpenGL
ES 3.1,OpenGL ES 3.1拥有Compute Shader特性,Android 5.0及以上版本的机器都支持OpenGL
ES 3.1。
提取权重参数
我们需要从tflite文件里面提取出权重参数,才能传入GPU做运算。通过Tensorflow Lite引擎的模型解析功能,把相关的权重参数解析提取出来,并传递给上层,tflite的权重参数存放顺序采用的是NWHC(N:数量,W:宽度,H:高度,C:通道),这里可以按需要看要不要转成NCWH,Caffe采用的就是NCWH的存放顺序。
针对GPU编程
准备好权重参数数据后,我们就可以按照MobileNet的结构开始针对GPU编程了。对于习惯CPU编程的我们来说,GPU编程是一项不小的挑战,这要求要能稍微理解GPU的工作原理,才能写出性能高效的GPU代码。
工作组
一个GPU中存在着多个工作组,如下图所示:
一个工作组里有多个线程,如下图所示:
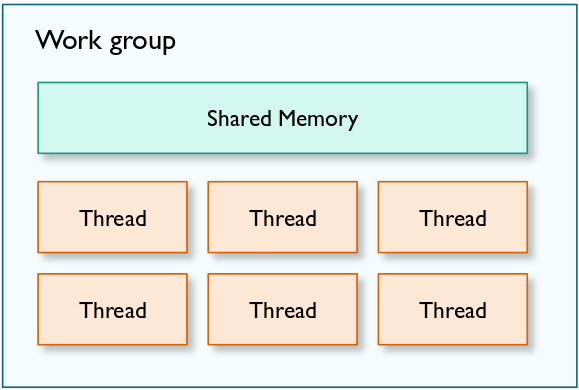
这好比一个工厂有多个车间,一个车间有多部机器的概念。因此,每段GPU代码同时有多个线程在访问,这种并行的工作形式非常适合神经网络的运行。
Shader语言实现
GPU编程语言最常用的有Shader、CUDA等,OpenGL ES采用的是Shader,Metal也是采用Shader,因此实现上可以互相移植参照。这里涉及到的知识点太多,不详细展开了,仅贴下代码片段,以实现一个深度卷积为例,iOS的Metal实现代码片段如下:
kernel void
depthwiseConv_quantized(
texture2d_array<half, access::read> inTexture
[[texture(0)]],
texture2d_array<half, access::write> outTexture
[[texture(1)]],
constant KernelParams& params [[buffer(0)]],
const device int* weights [[buffer(1)]],
const device int4* biasTerms [[buffer(2)]],
ushort3 gid [[thread_position_in_grid]])
{
ushort idx = gid.x;
ushort idy = gid.y;
ushort idz = gid.z;
if (idx >= outTexture.get_width() ||
idy >= outTexture.get_height() ||
idz >= outTexture.get_array_size()) return;
const ushort kernel_size = params.kernelSize;
const ushort input_width = params.inputWidth;
const ushort input_height = params.inputHeight;
const ushort stride = params.stride;
const ushort padding = params.padding;
const int inputOffset = params.inputOffset;
int4 sum = int4(biasTerms[idz]);
for (ushort i = 0; i < kernel_size; ++i)
{
for (ushort j = 0; j < kernel_size; ++j)
{
ushort ypos = gid.y * stride + i - padding;
ushort xpos = gid.x * stride + j - padding;
if (ypos < 0 || ypos >= input_height)
{
continue;
}
if (xpos < 0 || xpos >= input_width) {
continue;
}
int4 input = int4(inTexture.read(ushort2(xpos,
ypos), idz)) - inputOffset;
int wx = int(weights[(idz * 4 + 0) * kernel_size
* kernel_size + i * kernel_size + j]);
int wy = int(weights[(idz * 4 + 1) * kernel_size
* kernel_size + i * kernel_size + j]);
int wz = int(weights[(idz * 4 + 2) * kernel_size
* kernel_size + i * kernel_size + j]);
int ww = int(weights[(idz * 4 + 3) * kernel_size
* kernel_size + i * kernel_size + j]);
sum.x += (input.x * wx);
sum.y += (input.y * wy);
sum.z += (input.z * wz);
sum.w += (input.w * ww);
}
}
sum.x = MultiplyByQuantizedMultiplierSmallerThanOne(sum.x,
params.multiplier,params.shift);
sum.y = MultiplyByQuantizedMultiplierSmallerThanOne(sum.y,
params.multiplier,params.shift);
sum.z = MultiplyByQuantizedMultiplierSmallerThanOne(sum.z,
params.multiplier,params.shift);
sum.w = MultiplyByQuantizedMultiplierSmallerThanOne(sum.w,
params.multiplier,params.shift);
sum += params.outputOffset;
sum = max(0, sum);
sum = min(255, sum);
outTexture.write(half4(sum), gid.xy, idz);
} |
Android的实现代码片段如下:
void main(){
int idx = int(gl_GlobalInvocationID.x);
int idy = int(gl_GlobalInvocationID.y);
int idz = int(gl_GlobalInvocationID.z);
int weightPos = kernelSize * kernelSize * idz;
int sum = bias.data[idz];
int tempx,tempy;
for(int i = 0;i< kernelSize;i++ )
{
tempx = idx*stride + i - padding;
for(int j = 0; j < kernelSize; j++)
{
tempy = idy*stride + j - padding;
if (tempx <0 || tempx >= input_height ||
tempy < 0 || tempy >= input_width) continue;
int weight = weights.data[weightPos + i * kernelSize
+ j];
int inputv = input0.data[tempx * input_width *
output_channel + tempy * output_channel + idz];
sum += (inputv + inputOffset) * (weight);
}
}
sum = MultiplyByQuantizedMultiplierSmallerThanOne(sum,
multiplier,shift);
sum += outputOffset;
sum = max(0, sum);
sum = min(255, sum);
output0.data[idz + idy * output_channel + idx
* output_width * output_channel] = sum;
} |
GPU加速效果
整套GPU实现的逻辑打通后,iOS平台在iPhone X上实际测试到GPU相比CPU的速度提升了4倍;Android平台在华为P9上实际测试到GPU相比CPU的速度提升了3倍。并且实际落地到iOS上去跑时,手机耗电量节省了20%,速度和发热情况提升的效果非常显著。
实践成果
整个实践过程下来,对于如何选择并训练模型,处理数据,以及在终端移动设备上工程化落地深度神经网络并做GPU加速,我们有了丰富的认识和理解,对于这类AI项目有了更多的技术储备,对于AI本身也有了更为深刻的感悟。 |









