| БрМЭЦМі: |
БОЮФРДдДгкcsdnЃЌНщЩмФЃаЭМЏГЩЕФПђМмЃЌEnsembleЃКBagging
ЃЌEnsemble: BoostingЃЌEnsemble: StackingЕШЁЃ |
|
1. ФЃаЭМЏГЩЕФПђМм
ФЃаЭМЏГЩЕФПђМмЪЧетбљЕФЃЌгаКмЖржжЗжРрЦїЃЌЫќУЧгІИУЪЧВЛЭЌЕФЃЌПЩвдЪЧВЛЭЌЕФЛњЦїбЇЯАЗНЗЈЃЌвВПЩвдЪЧЯрЭЌЕФЗНЗЈЁЃЕЋЪЧЫќУЧзюКУЪЧЛЅВЙЕФЃЌвВОЭЪЧЫЕВЛЪЧЛЅЯрЯрЫЦЕФЁЃУПжжЗжРрЦїЖМгІИУгаздМКЕФЮЛжУЁЃ
2. EnsembleЃКBagging
дкБОНкжаЛсвдФГвЛжжЛњЦїбЇЯАЗНЗЈОйР§ЃЌЕЋЪЧЪЕМЪЩЯетжжМЏГЩЗНЗЈЪЪгУгкШЮКЮЕФЛњЦїбЇЯАЗНЗЈЁЃ
2.1 ЛиЙЫЦЋжУгыЗНВюЕФЙиЯЕ
ЦЋжУгыЗНВюЕФЙиЯЕШчЯТЭМЫљЪО
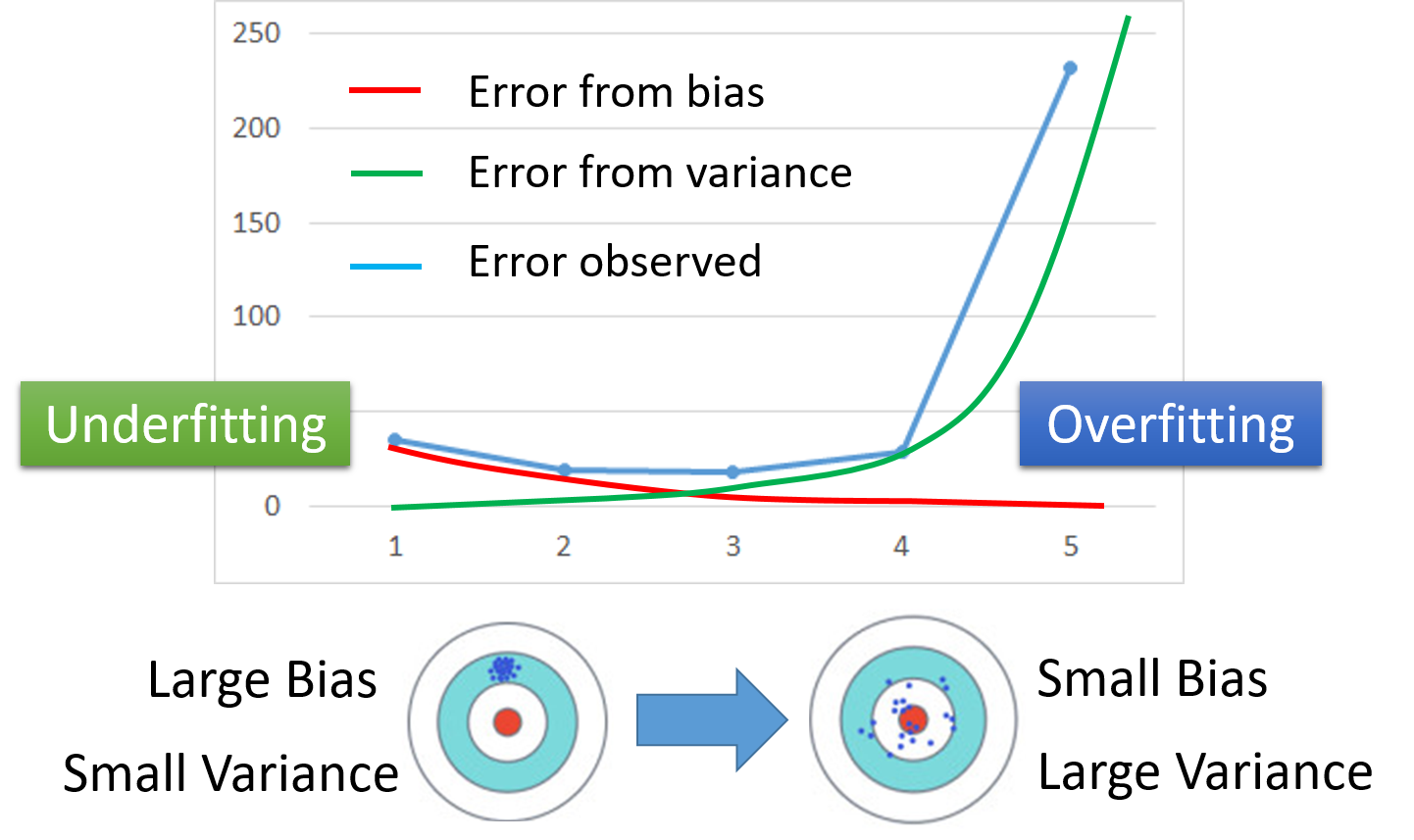
Г§СЫПЩвдКмЭъУРНјааЙЄзїЕФЛњЦїбЇЯАФЃаЭЃЌЪЃЯТЕФФЃаЭДѓжТПЩвдЗжЮЊСНжжЧщПіЃЌМДЧЗФтКЯЃЈUnderfitting
ЃЉКЭЙ§ФтКЯЃЈOverfittingЃЉЁЃЧЗФтКЯЕФЬиЕудкгкЫќОпгаБШНЯаЁЕФЗНВюЃЌЕЋЪЧШДгазХБШНЯДѓЕФЦЋжУЃЈМДгые§ШЗД№АИЕФЦЋРыЗНЯђЃЉЃЛЖјЙ§ФтКЯЫфШЛгазХНЯаЁЕФЦЋжУЃЌЕЋЪЧШДгазХНЯДѓЕФЗНВюЃЌНЋетСНжжЧщПіЛдквЛЦ№ШчЩЯЭМЫљЪОЃЌЫцзХФЃаЭИДдгГЬЖШЕФдіДѓЃЌФЃаЭЕФаЇЙћЛсЯШЬсИпКѓНЕЕЭЁЃ
2.2 BaggingЕФЗНЗЈ
BaggingЕФЗНЗЈШчЯТЭМЫљЪО

ЫћРћгУПЩЗХЛиГщбљзмЙВЛёЕУNИібљБОЃЌжЎКѓбЕСЗNИіЗжРрЦїЃЌЖдгкЛиЙщЮЪЬтШЁетNИіЗжРрЦїЕФОљжЕЃЌЖдгкЗжРрЮЪЬтШУетNИіЗжРрЦїНјааЭЖЦБЃЌ
жївЊзЂвтЕФЪЧЃЌетжжЗНЗЈжївЊгУдквжжЦФЃаЭЙ§ФтКЯЕФЮЪЬтЃЌБШШчЫЕОіВпЪїЁЃетжжЗНЗЈдкNNЩЯгУЕФВЂВЛЖрЃЌвђЮЊNNЪЕМЪЩЯУЛгаЯыЯѓжаФЧУДШнвзЙ§ФтКЯЃЌЫќЭљЭљЪЧдкбЕСЗМЏЩЯВЛФмЛёЕУ100%
ЕФе§ШЗТЪЕФЁЃ
ЯТУцЪЧвЛИіЪЙгУОіВпЪїНјааЗжРрЕФР§зг
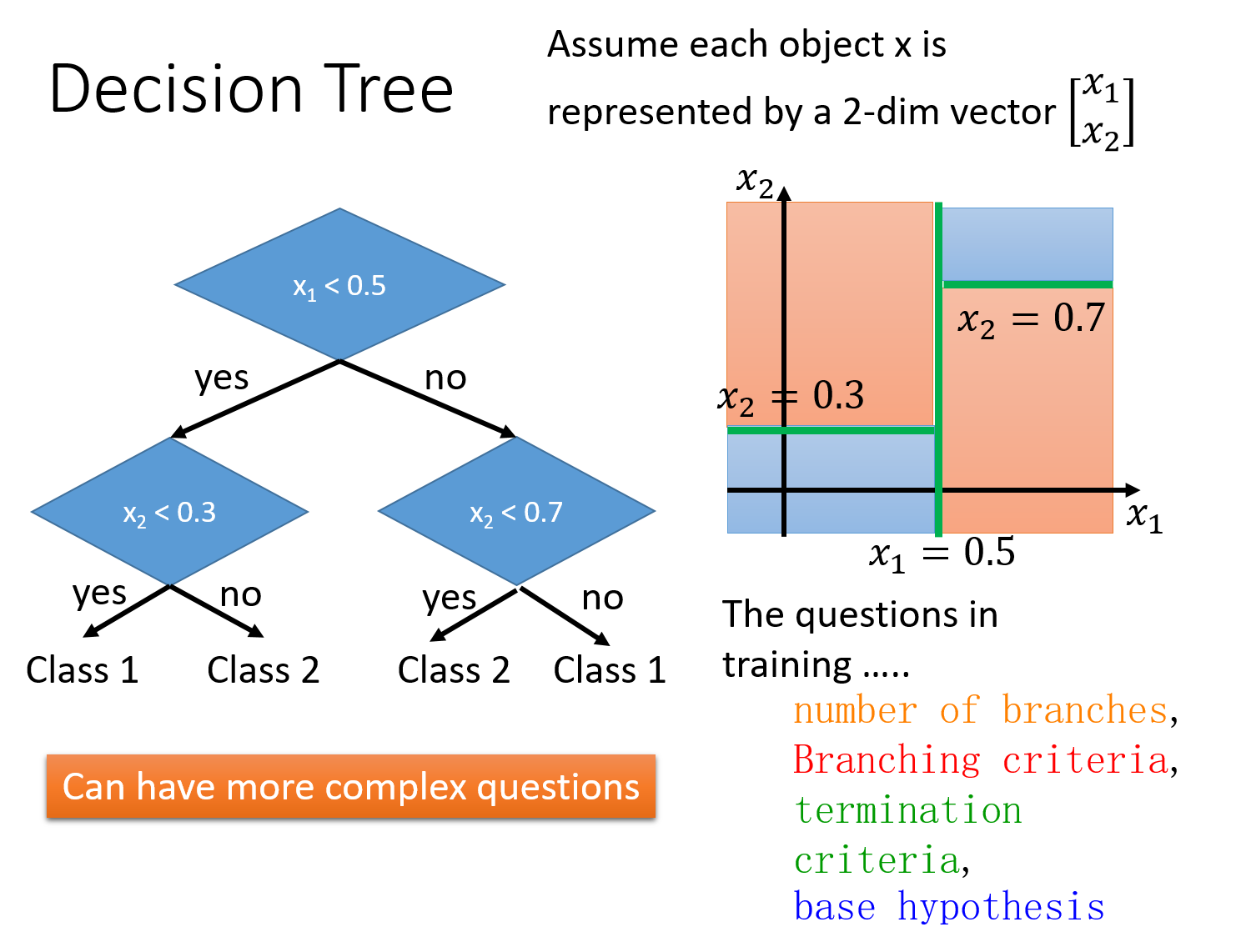
НЋОіВпЪїЛЏГЩЭМаЮЕФаЮЪНШчЩЯЭМЫљЪОЃЌдкаЮГЩвЛИіОіВпЪїЕФЙ§ГЬжаашвЊПМТЧвЛаЉВЮЪ§ЃЌБШШчЫЕЗжжЇЪ§ЃЌЗжжЇЕФБъзМЃЌжежЙзМдђЃЌЛљБОМйЩшЁЃ
ЯТУцЪЧДгЭМЯёжаЕУЕНГѕвєМєгАЕФР§зг

дкетРяжЛЪЧЪЙгУСЫвЛИіЕЅвЛЕФОіВпЪїЃЌЩЯУцЪЧВЛЭЌЩюЖШЛёЕУаЇЙћЃЌПЩвдПДЕНЕБЪїЕФЩюЖШДяЕН20ВуЕФЪБКђЛёЕУСЫКмКУЕФаЇЙћЁЃ
2.3 ЫцЛњЩСжЃЈRandom ForestЃЉ
ЫцЛњЩСжБуЪЧ bagging ЕФвЛИіКмКУЕФР§згЃЌШчЯТЭМЫљЪО

ОіВпЪїКмШнвздкбЕСЗМЏЩЯЛёЕУ0ДэЮѓТЪЕФНсЙћЃЌвђЮЊШчЙћвЛИівЖзгНкЕуЖдгІвЛИіР§згЕФЛАЃЌКмШнвзЛсЕУЕНетбљЕФНсЙћЁЃетЪЧОЭвЊЖдОіВпЪїВЩгУ
bagging ЕФЗНЗЈЃЌЪЕМЪЩЯвВОЭЪЧЪЙгУСЫЫцЛњЩСжЕФЗНЗЈЁЃдкЫцЛњЩСжжаНіНіНјаажиВЩбљЪЧВЛЙЛЕФЃЌвђЮЊНіНіЪЙгУжиВЩбљЛсЪЙбЕСЗГіЕФЪїжЎМфКмЯёЃЛЮЊСЫЪїжЎМфИќВЛЯёЃЌЛЙвЊОіЖЈФФаЉЬиадгУгкЗжРрЃЌФФаЉЬиадВЛгУгкЗжРрЁЃШчЩЯУцЕФБэИёЫљЪОЃЌЕквЛИіЗжРрКЏЪ§НіНіЪЙгУ
[Math Processing Error]
СНИіЪ§ОнЃЌКѓУцЕФЖМЪЧвЛбљЕФЃЌжЛЪЧбЁдёСЫвЛаЉЪ§ОнЃЌЫљвддкЪЙгУбщжЄМЏЕФЪБКђПЩвджБНгЪЙгУФЧаЉУЛгагУРДбЕСЗЕФЪ§ОнНјааВтЪдЃЌБШШчЫЕЪЙгУf2
+f4зщГЩЫцЛњЩСжЃЌгУЪ§Онx1НјааМьбщЃЌетжжЗНЗЈНазі Out-of-bagЃЌЫћПДВЛдк bag жаЕФР§згЕФБэЯжШчКЮЃЌРДХаЖЯЯждкФЃаЭЕФБэЯжШчКЮЃЌетжжЗНЗЈЕФвЛИіКУДІдкгкЃЌЫќПЩвдВЛгУдйЪТЯШЧавЛИібщжЄМЏГіРДЃЌжБНгЪЙгУУЛгаБЛгУЕНЕФЪ§ОнНјаабщжЄОЭКУЃЌЫцЛњЩСжЕФвЛИіЕФЪЕбщНсЙћШчЯТЭМЫљЪО

етРязмЙВЪЙгУСЫ100ИіЪїЙЙГЩЕФЫцЛњЩСжЃЌДгЪЕбщНсЙћжаПЩвдПДЕНЃЌНЯЮЊЧГВуЕФЪїШдШЛВЛФмЛёЕУКмКУЕФаЇЙћЃЌЕЋЪЧЫќПЩвдЪЙЕУНсЙћИќЮЊЦНЛЌЁЃ
3. Ensemble: Boosting
гы Bagging гаЫљВЛЭЌЃЌBoostingЕФФПЕФВЛЪЧЮЊСЫвжжЦЙ§ФтКЯЃЌЖјЪЧЮЊСЫЬсИпШѕЕФЗжРрЦїЕФадФмЁЃЫќПЩвдБЃжЄЃЌжЛвЊФуЪЙгУЕФЗжРрЦїдкбЕСЗЪ§ОнЩЯЕФЮѓВюаЁгк50%ЃЌЭЈЙ§Boosting
жЎКѓФуЕУЗжРрЦїЕФе§ШЗТЪзюжезмЛсЕН0ЁЃ
Boosting ЕФОпЬхПђМмШчЯТ

ЪзЯШЫћЛсЛёЕУЕквЛИіЗжРрЦї f1(x)ЃЌШЛКѓевЕНЕкЖўИіЗжРрЦї f2(x)
РДАяжњЕквЛИіЗжРрЦї f1(x)ЁЃетИіЕкЖўИіЗжРрЦїЪЧЪВУДбљЕФЛњЦїбЇЯАЫуЗЈЖМКУЃЌжЛвЊФмЙЛАяЕН ЕквЛИіЗжРрЦї
f1(x) ЬсИпећЬхЕФадФмЃЛШЛЖјШчЙћ f2(x) гы f1(x) ЪЧКмЯрЫЦЕФЛАЃЌФЧУДЫќУЧОЭУЛгаАьЗЈАяжњЫћКмЖрЃЌЮвУЧЯЃЭћЮвУЧЕУЕНЕФ
f2(x) гы f1(x) ЪЧЛЅВЙЕФЁЃШЛКѓЮвУЧОЭЕУЕНСЫЕкЖўИіЗжРрЦї f2(x) ЃЌзюКѓзщКЯЫљгаЕФЗжРрЦїЁЃШЛЖјетЦфжагаКмживЊЕФЪЧЃЌЗжРрЦїЪЧашвЊАДЫГађбЇЯАЕФЃЌВЛЯёжЎЧАЕФЗжРрЦїЪЧПЩвдЗжПЊбЇЯАЕФЁЃ
3.1 ФЧШчКЮЛёЕУВЛЭЌЕФЗжРрЦїФиЃП
ЙиМќЕФЫМЯыдкгкЛёЕУВЛЭЌЕФбЕСЗЪ§ОнЁЃжиВЩбљЫфШЛПЩвдЛёЕУВЛЭЌЕФбЕСЗЪ§ОнЃЌЕЋЪЧУПвЛИіЪ§ОнБЛВЩбљЕФДЮЪ§вЛЖЈЪЧећЪ§ЃЌЮвУЧУЛгаАьЗЈНЋвЛИіЪ§ОнВЩбљ2.1ДЮЛђеп0.1ДЮЁЃЫљвдетИіЪБКђОЭвЊВЩгУЖдЪ§ОнжиаТИГШЈжиЕФЗНЗЈРДЛёЕУВЛЭЌЕФЪ§ОнЃЌШчЯТЭМЫљЪО
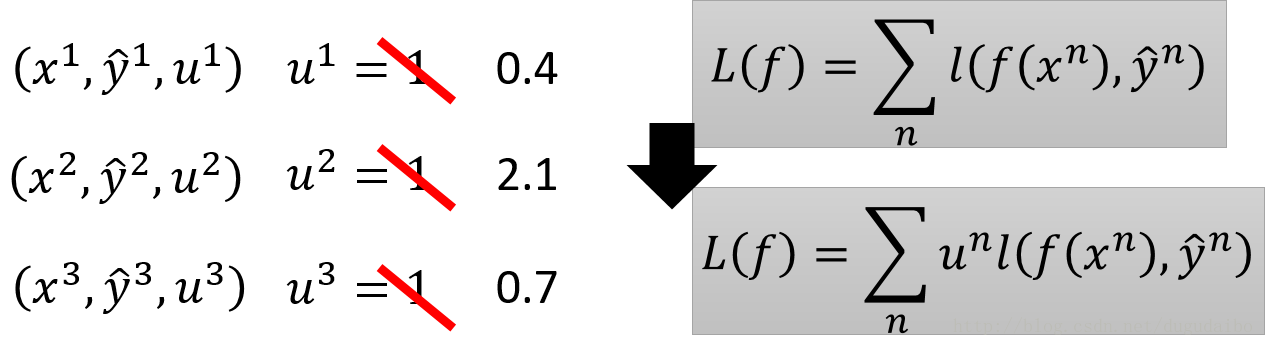
МйЩшдЪМЕФШЈжиЖМЪЧ1ЃЌИќаТжЎКѓЕФШЈжиЮЊЭМжаЫљЪОЕФЪ§ЃЌФЧУДЫ№ЪЇКЏЪ§вВвЊНјааЭЌбљЕФИФБфЃЌдкМЦЫуФГвЛИіЪ§ОнЕФЫ№ЪЇжЕжЎКѓЛЙвЊГЫвдЫћЕФШЈжиЁЃ
3.2 AdaboostЕФЫМЯы
AdaboostЕФЫМЯыдкгкЫќЪЙгУСюЗжРрЦї f1(x) ЪЇАмЕФЪ§ОнНјаабЕСЗЕУЕН
f2(x)ЃЌжЎЫљвд f2(x) ЫљгУЕФЪ§ОнвЊЪЙ f1(x) ЪЇАмЃЌЦфжївЊдвђЪЧЮЊСЫЪЙ f1(x) КЭ
f2(x)ЛЅВЙ ЁЃФЧУДШчКЮевЕНетбљЕФЪ§ОнФиЃП
ЮвУЧЖЈвх f1(x)дкЫќЕФбЕСЗМЏЩЯЕФЮѓВюЮЊ
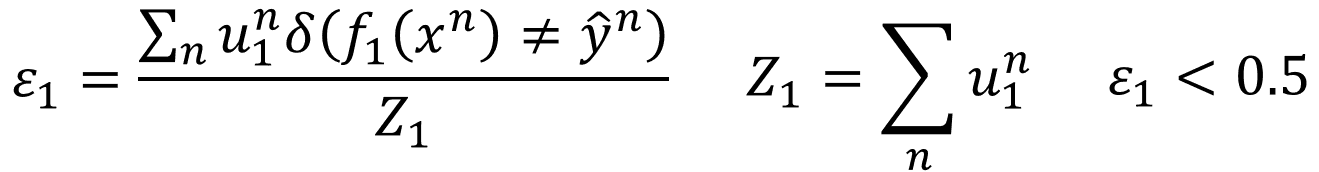
ЗжзгЕФВПЗжвбОЩЯУцЫЕЙ§СЫЃЌЖдгкЗжФИ Z1ЃЌЫћЪЧЫљгаШЈжиЕФКЭЃЌЩЯБъ n
ДњБэетЪЧЕк n ИіЪ§ОнЃЌЯТБъДњБэетЪЧЪЙгУдкЕкМИИіШѕЗжРрЦї f(x) ЃЌЦфжаЕФЗжРрЮѓВюЪЧаЁгк0.5ЕФЃЌвђЮЊШчЙћЗжРрЮѓВюДѓгк0.5ЃЌФЧУДжБНгЗДЙ§РДОЭКУСЫЁЃ
ЖјЫљЮНЕФЪЧдРДЕФЗжРрЦїдкаТЕФЪ§ОнЩЯЪЇАмЕФКЌвхОЭЪЧЃЌдРДЕФЗжРрЦїдкаТЕФЪ§ОнМЏЃЈЕїећЭъШЈжиЕФЪ§ОнМЏЃЉЩЯЕФЗжРрЕФе§ШЗТЪЮЊ50%ЃЌМД

ЪЙ f1(x) ЕФаЇЙћдк f2(x) ЫљЖдгІЕФаТЪ§ОнМЏЩЯШчЭЌЪЧдкЫцЛњВТВтвЛбљЁЃвЛИіОпЬхЕФР§згШчЯТЭМЫљЪО

МйЩшдЪМЪ§ОнЕФШЈжиЖМЪЧ1ЃЌВЂЧвдкетИіШЈжиЯТбЕСЗГіСЫвЛИіЗжРрЦї f1(x)
ЃЌетИіЪБКђМЦЫуЗжРрЮѓВюОЭЪЧ0.25ЁЃжЎКѓЮвУЧашвЊаоИФбЕСЗЪ§ОнЕФШЈжиЪЙЕУ f1(x)ЪЇаЇЃЈМДЗжРре§ШЗТЪЮЊ0.5ЃЉЁЃОпЬхзіЗЈЪЧНЋЗжРре§ШЗЕФЪ§ОнЕФШЈжиНЕЕЭЃЌЖјНЋЗжРрДэЕФШЈжидіДѓЃЌетОЭЪЙЕУдРДЕФЗжРрЦїЫфШЛЗжРрЛЙЪЧе§ШЗЕФЃЌЕЋЪЧОЙ§СЫМгШЈЧѓКЭжЎКѓЃЌдЪМЗжРрЦїЕФОЭЪЇаЇСЫЃЈе§ШЗТЪжЛга0.5ЃЉЁЃ
ЫљвдбЕСЗЪ§ОнЕФШЈжиИќаТЗНЗЈШчЯТЭМЫљЪО
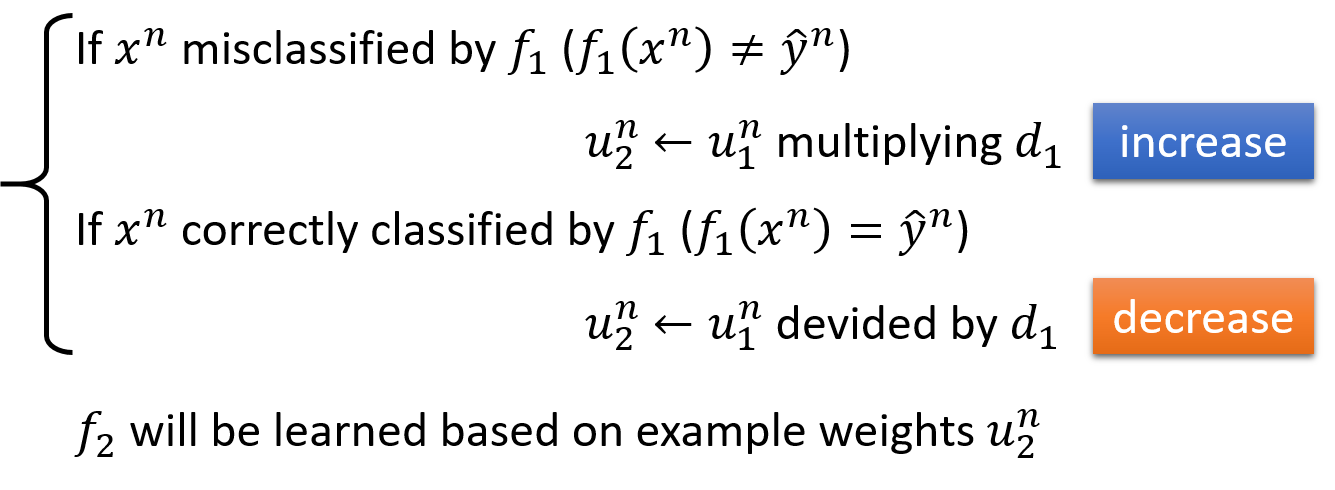
ЮвУЧНЋЗжРре§ШЗЕФЪ§ОнЕФШЈжиГ§вдвЛИіДѓгк1ЕФЪ§ d1ЃЌЖдгкЗжРрДэЮѓЕФЪ§ОнГЫвдвЛИіЯрЭЌЕФШЈжи
d1ЁЃФЧетИіШЈжиОпЬхдѕУДЫуФиЃПМЦЫуЕФЗНЗЈШчЯТЃЌОпЬхЭЦЕМЙ§ГЬЪЁТд
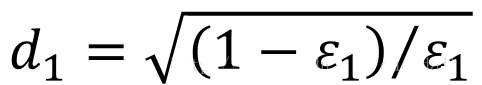
ЦфжаЕФ?ЪЧдкетИіЗжРрКЏЪ§ЩЯЕФЮѓВюЃЌвђЮЊ ?<0.5ЃЌЫљвдМЦЫуГіЕФd1>1
ЁЃ
3.3 AdaboostЕФЫуЗЈСїГЬ
вдЖўЗжРрЮЊР§ЃЌAdaboostЕФЫуЗЈСїГЬШчЯТЭМЫљЪО

ИјЖЈвЛаЉбЕСЗЪ§ОнЃЌБъЧЉЪЧ+1КЭ-1ЃЌГѕЪМЕФШЈжиЖМЪЧ1 ЃЌзмЙВгЩ T
ИіШѕЗжРрЦїзщГЩ AdaboostЁЃЪзЯШЪЙгУШЈжиЮЊ ut ЕФЪ§ОнбЕСЗГіЕк t ИіЗжРрЦїЃЌетЪБ ?t ЪЧгУШЈжиЮЊut
ЕФЪ§ОнбЕСЗГіЕк t ИіЗжРрЦїЕФЮѓВюЃЌжЎКѓМЦЫу dtЁЃШчЙћЗжРре§ШЗОЭГ§вдГЃЪ§ dtЃЌШчЙћЗжРрДэЮѓОЭГЫвдГЃЪ§
dtЃЌвдДЫРДИќаТ ut+1ЁЃ
ШчЙћНЋ d1БэЪОЮЊ ІСt=ln((1??t)/?t????????ЁЬ) ЛсЪЙЕУЗжРрЕФЙ§ГЬБэЪіЮЊИќЮЊМђЕЅЕФаЮЪНЃЌВЮЪ§ИќаТЕФЙ§ГЬПЩвдБэЪОЮЊ
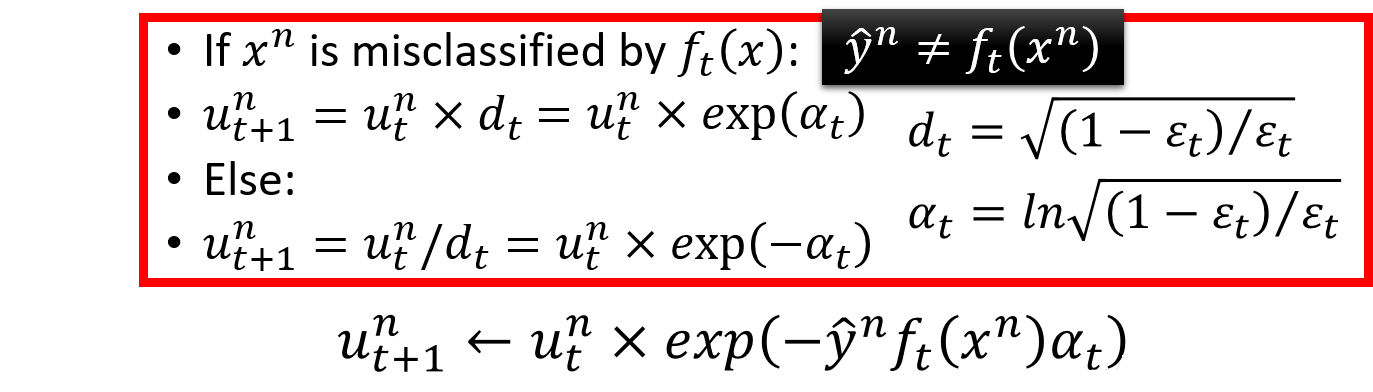
НЋЩЯЪіЗжЮЊСНжжЧщПіЬжТлЕФЙ§ГЬБэЪОЮЊЪЕМЪБъЧЉгыдЄВтБъЧЉЕФГЫЛ§ЕФвЛИіЕШЪНЃЌЫљвдВЛжБНгЪЙгУ
d1
ЃЌЖјЪЧЪЙгУЦфжИЪ§ЕФаЮЪНжївЊЪЧЮЊСЫМЦЫуБэДяМђЕЅЧхЮњЁЃ
дкНЋЕУЕНЕФ N ИіФЃаЭМЏГЩдквЛЦ№ЕФЙ§ГЬжаЃЌгавдЯТСНжжЗНЗЈ

ЦфжаЕквЛжжЗНЗЈЁАUniform weightЁБЪЧЕШШЈжиЕиПДД§УПвЛИіЕФНсЙћЃЌетЪЧвЛжжБШНЯВЛКУЕФЗНЗЈЃЌИќКУЕФЗНЗЈЪЧНЋЫќУЧАДееШЈжи
ІСt зщКЯдквЛЦ№ЃЌШчЩЯЭМЁАNon-niform weightЁБЫљЪОЁЃетРяЪЙгУ ІСt зїЮЊШЈжижБОѕЩЯЪЧКЯРэЕФЃЌвђЮЊ
ІСtдНДѓЫЕУїЦфЫљЖдгІЕФШѕЗжРрЦїЕФДэЮѓТЪдНаЁЃЌвВОЭЪЧЫЕЗжРраЇЙћдНКУЃЌЫќОЭгІИУОпгаНЯДѓЕФШЈжиЁЃЫљвдЗжРрЦїЕФДэЮѓТЪдНаЁЃЌдкзюКѓЭЖЦБЕФЪБКђШЈжиОЭдНДѓЁЃ
ЯТУцНЋвдвЛИіОпЬхЕФР§згНјааЫЕУїЃЌдкетРяЮвУЧзмЙВЪЙгУ3ИіЗжРрЦїЃЌЗжРрЦїЪЙгУжЛЛвЛЬѕЯпЕФ decision
stump
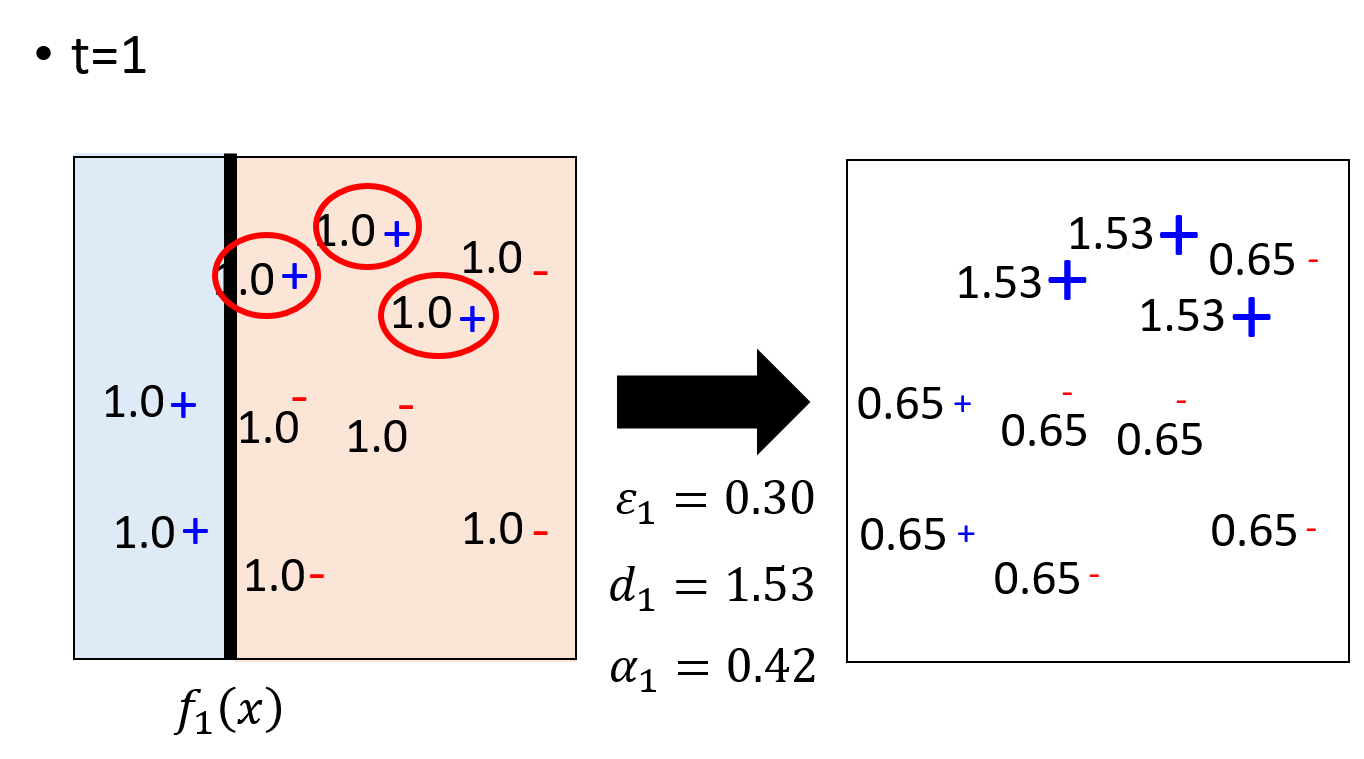
ЪзЯШНјааЗжРрЃЌБпНчШчзѓЭМЫљЪОЃЌетИіЪБКђЕФЮѓВюЪЧ0.3ЃЌМЦЫу d1ЃЌжЎКѓНЋЗжРре§ШЗЕФЪ§ОнГ§вд
d1ЃЌНЋЗжРре§ШЗЕФГЫвд d1ЃЌИќаТЪ§ОнЕФШЈжиШчЩЯЭМгвВПЗжЫљЪОЃЌДЫЪБЕквЛЗжРрЦїЕФШЈжиОЭЪЧ ІС1ЁЃ
жЎКѓИљОнИњаТШЈжиКѓЕФЪ§ОнбЕСЗЕкЖўИіЗжРрЦї
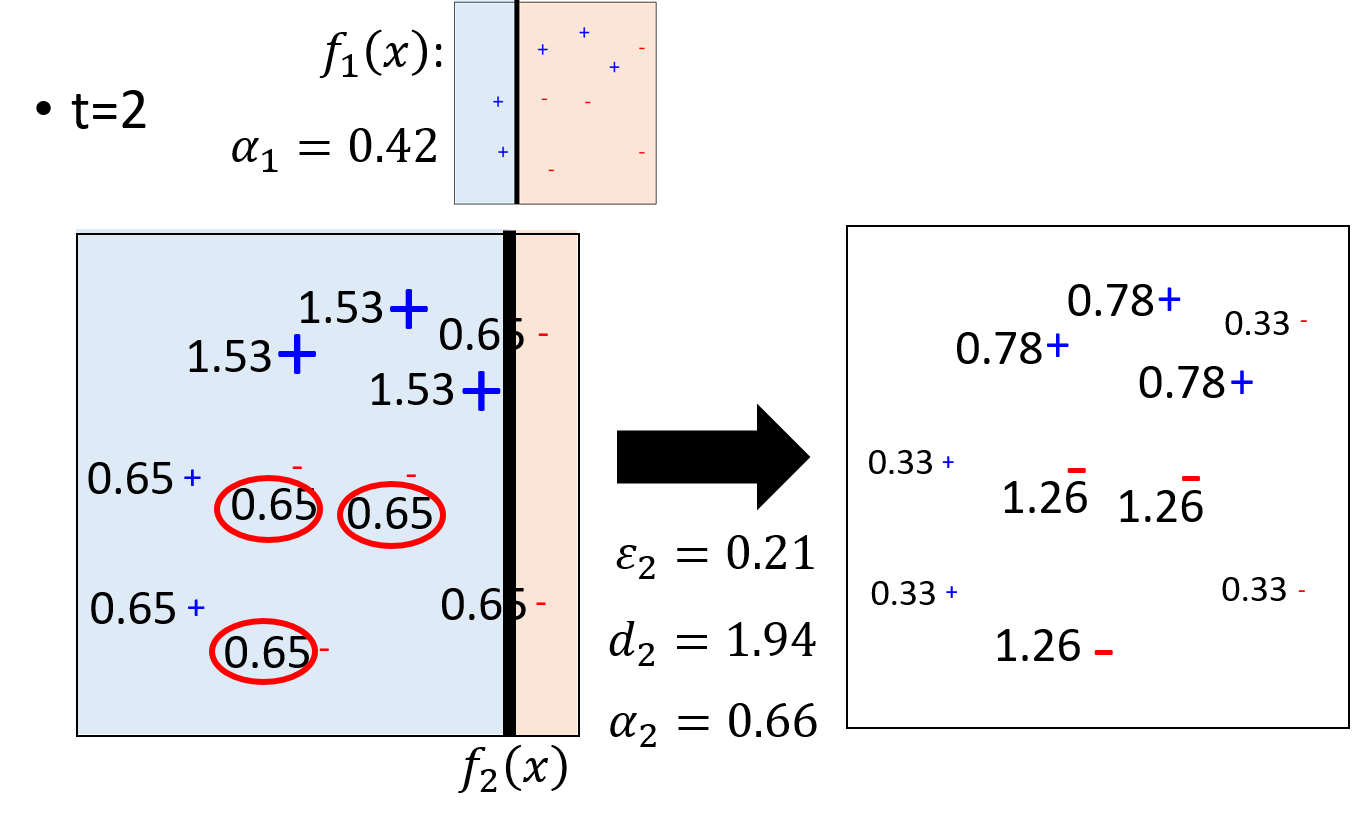
жЎКѓШчЭМЛвЛЬѕЗжРрЕФНчЯоЃЌЦфжазѓВрБЛЛЎЗжЮЊе§Р§ЃЌЖјгвВрЛЎЗжЮЊИКР§ЃЌжЎКѓШдШЛМЦЫуДэЮѓЗжРрТЪЕШВЮЪ§ЃЌВЂИќаТбЕСЗМЏЪ§ОнЁЃЦфжаМЦЫуЗжРрТЪЕФЗНЗЈВЛЪЧНЋШ§Иі0.65ЯрМгдкГ§вд3ЃЌЖјЪЧЯрМгжЎКѓГ§вдШЋЬхЕФШЈжиЁЃ
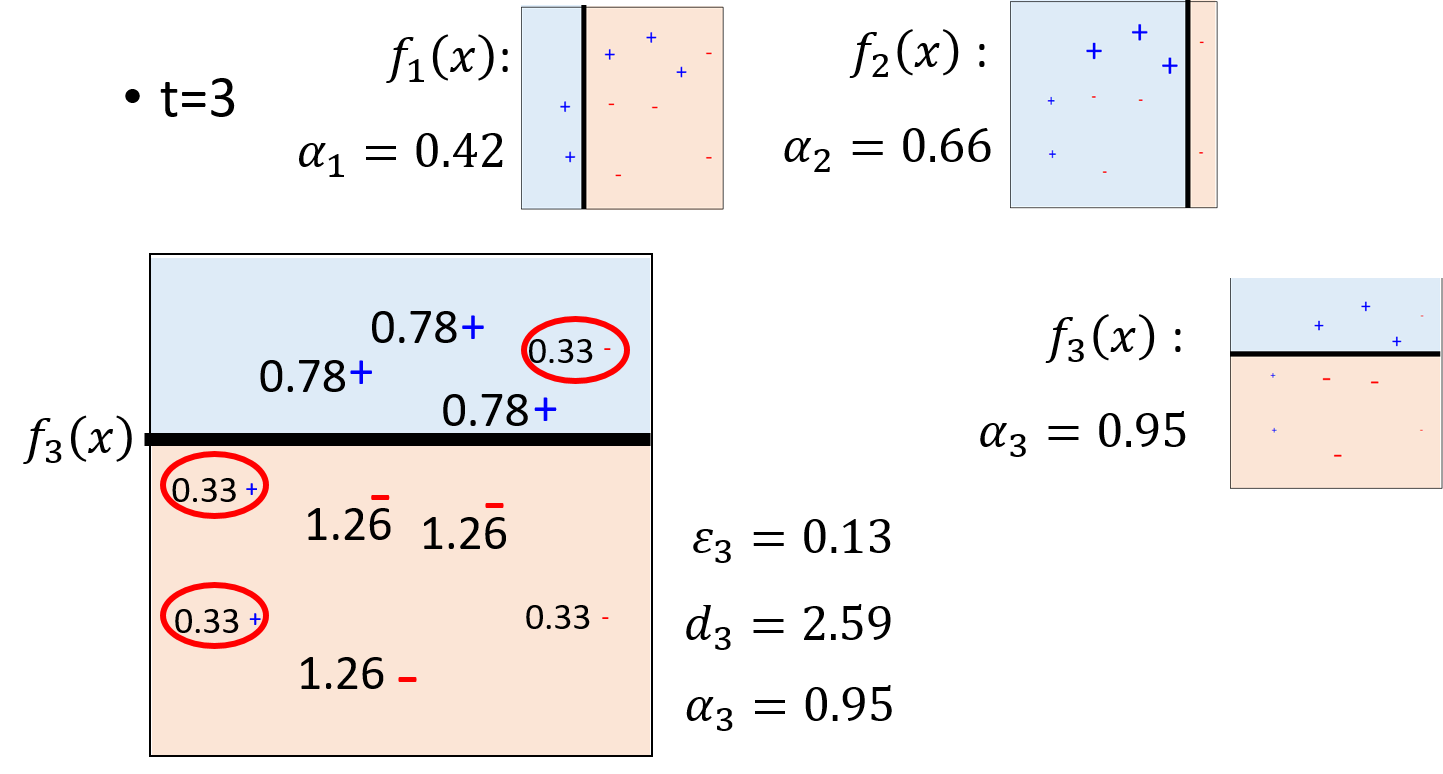
ШЛКѓНЋетШ§ИіЗжРрЦїАДееШЈжизщКЯЦ№РДЃЌШчЯТЭМЫљЪО
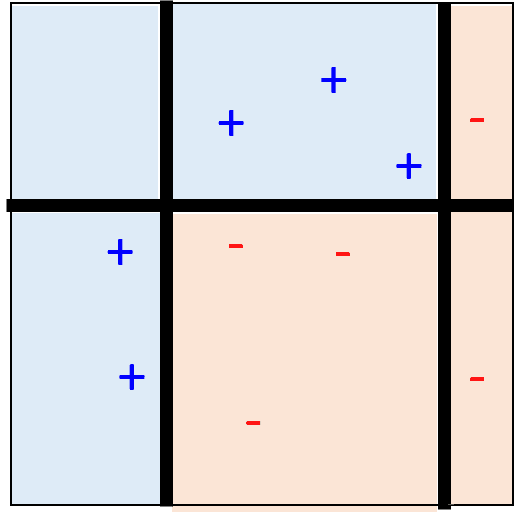
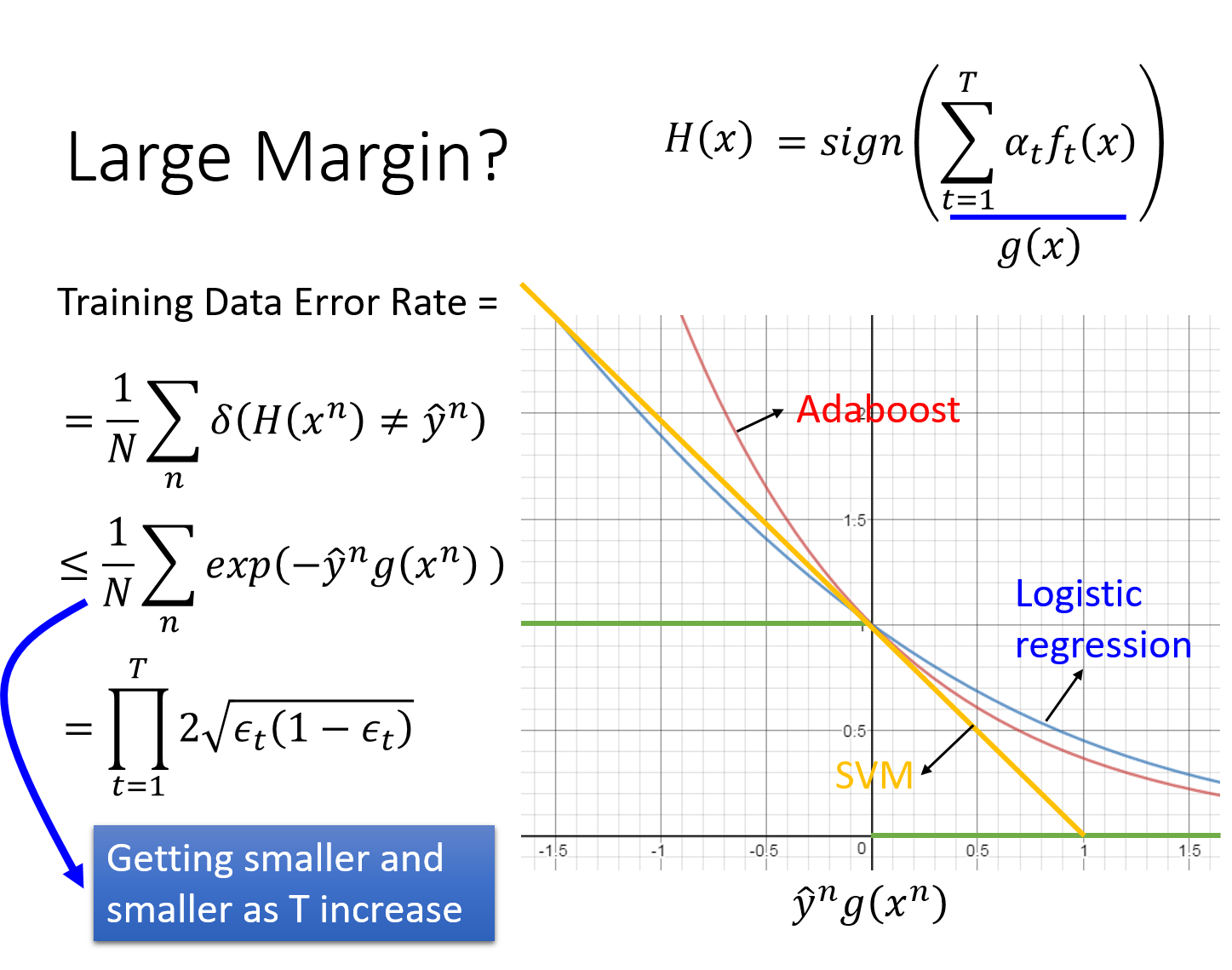
3.4 Adaboost ЕФЯрЙижЄУї
дкетРяЮвУЧашвЊжЄУїЕФЪЧЃЌЫцзХTЕФж№НЅдіМгЃЌH(x)дкбЕСЗМЏЩЯЛёЕУдНРДдНаЁЕФДэЮѓТЪЁЃЦфжа
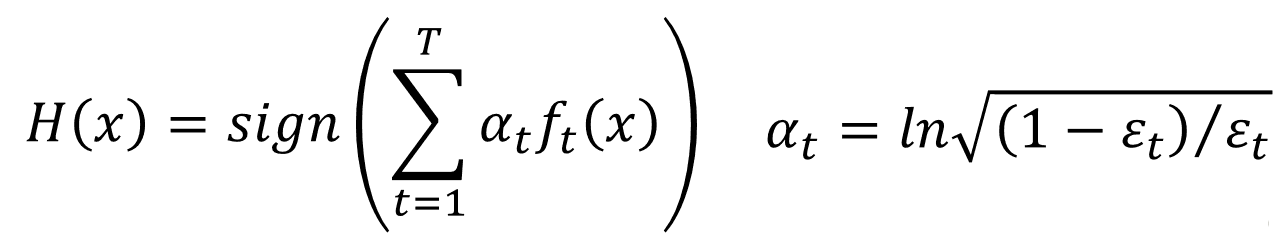
ОпЬхЙ§ГЬТдЁЃ
3.5 Adaboost бЕСЗНсЙћЫЕУї
дкЪЙгУ Adaboost ЕФЙ§ГЬжаЃЌГЃГЃЛсГіЯжШчЯТЕФЧщПі
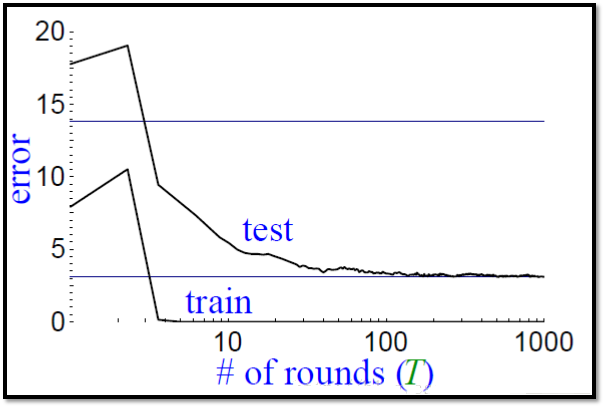
ЮвУЧПЩвдПДЕНЃЌдкбЕСЗМЏЩЯНсЙћКмПь0ДэЮѓЃЛЕЋЪЧИќЮЊЦцЙжЕФЪЧдкбЕСЗЪ§ОнвбОДяЕНзюМбЕФЧщПіЯТЃЌМЬајбЕСЗЕФЛАШдЛсЬсИпВтЪдМЏЩЯЕФе§ШЗТЪЁЃЭЈЙ§ЗжЮіФЃаЭЕФКЏЪ§ЮвУЧПЩвдЗЂЯжШчЯТЕФЙцТЩЁЃ
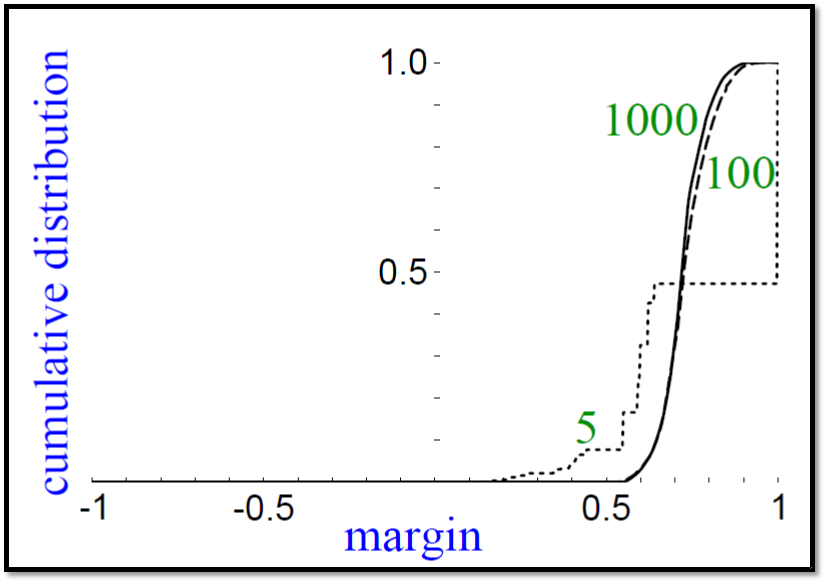
ЭМжаЕФКсзјБъЪЧ margin ЃЌОпЬхЪЧжИКЏЪ§МфОр yg(x)ЃЌЦфжаЕФ
h(x)ЪЧзюКѓЕУЕНЕФЧПЗжРрЦїЃЛзнзјБъЪЧРлМЦЗжВМЃЌЮвУЧПЩвдПДЕНЫцзХЕќДњДЮЪ§ЕФдіМгЃЌЗжРре§ШЗТЪЕФЧњЯпЫцзХжДаа
Adaboost ДЮЪ§ЕФдіЖрЃЌЧњЯпвЛжБдйЯђгвЭЦЃЌвтЮЖзХдйОЁСІЕФЕНдНРДгњКУЕФНсЙћЁЃ
ШчЯТЭМЫљЪО
ЫљвдЫфШЛПДРДЗжРре§ШЗТЪвбОДяЕНСЫ100%ЃЌЕЋЪЧЫћЕФ margin ШдШЛУЛгаДяЕНзюМбЃЌдіМг Adaboost
ЕќДњДЮЪ§ШдШЛЛсдіЧПФЃаЭдкВтЪдМЏЩЯЕФБэЯжЁЃЩЯУцЕФЭМБэЪОСЫВЛЭЌЕФЫ№ЪЇКЏЪ§ЕФ up bound ЃЌЮвУЧПЩвдПДЕН
Adaboost МДЪЙдкЗжРре§ШЗЕФЧщПіЯТШдЛсМЬајМгДѓЕФ marginЁЃ
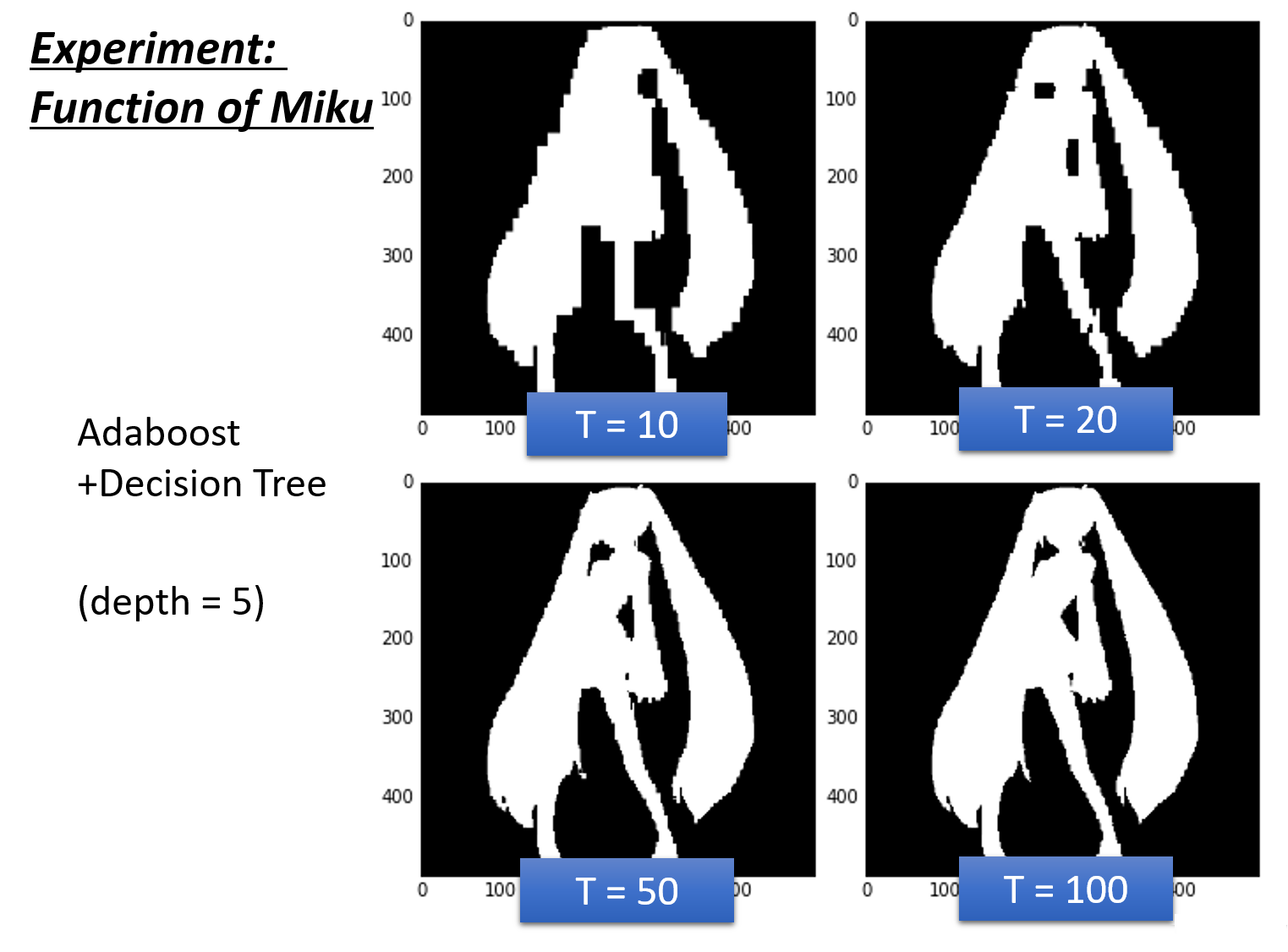
ЭЌбљЖдгкГѕвєЕФМєгАНјааЗжЮіЃЌдкетРяЮвУЧЪЙгУ Adaboost + Decision
Tree ЕФЗНЗЈЃЌЦфжаЫљгаЕФОіВпЪїЖМЪЧЩюЖШЮЊ 5 ЕФОіВпЪїЃЌЪЕбщНсЙћШчЯТЭМЫљЪО
4. Ensemble: Stacking
ШчЙћНЈСЂСЫЖдИіФЃаЭНјааЭЖЦБЕФЛАЃЌГЃгУЕФвЛжжЗНЗЈЪЧжБНгНјааЕШШЈжиЕФЭЖЦБЃЌШчЯТЭМЫљЪО
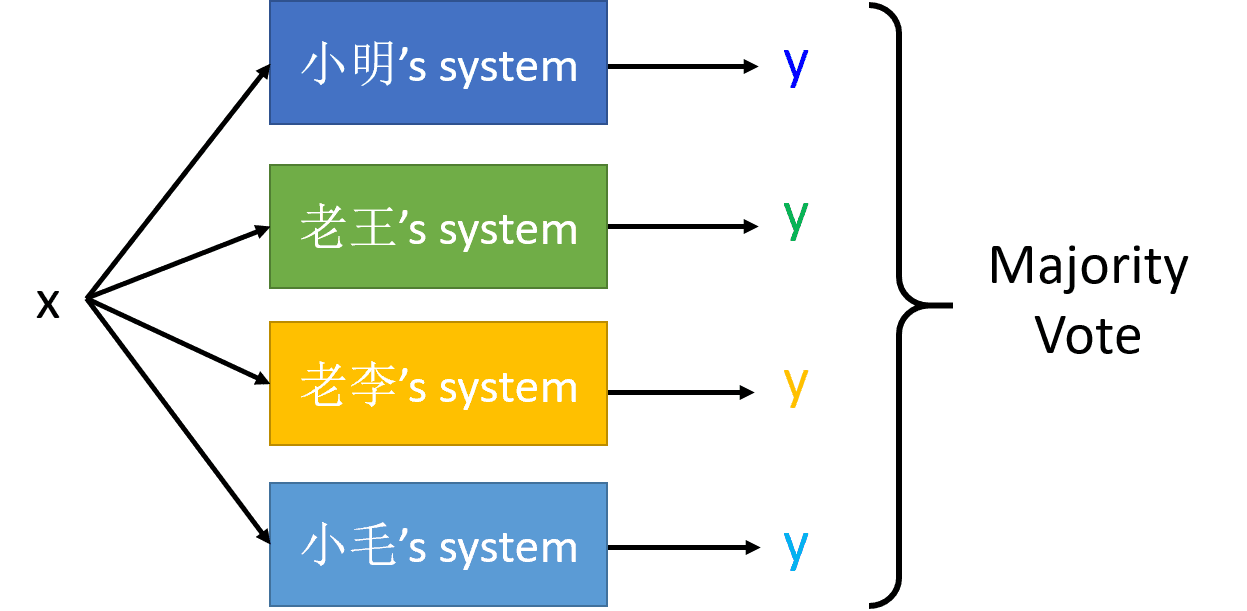
ЕЋЪЧШчЙћетИіЪБКђаЁУЋЕФФЃаЭЪЧБэЯжзюВюЕФЃЌВЩгУЕШШЈжиЕФЗНЗЈНјааЭЖЦБЕФЛАЃЌУїЯдЛсНЕЕЭећЬхФЃаЭЕФадФмЁЃетИіЪБКђОЭПЩвдВЩгУШчЯТЕФАьЗЈНјааИФНј
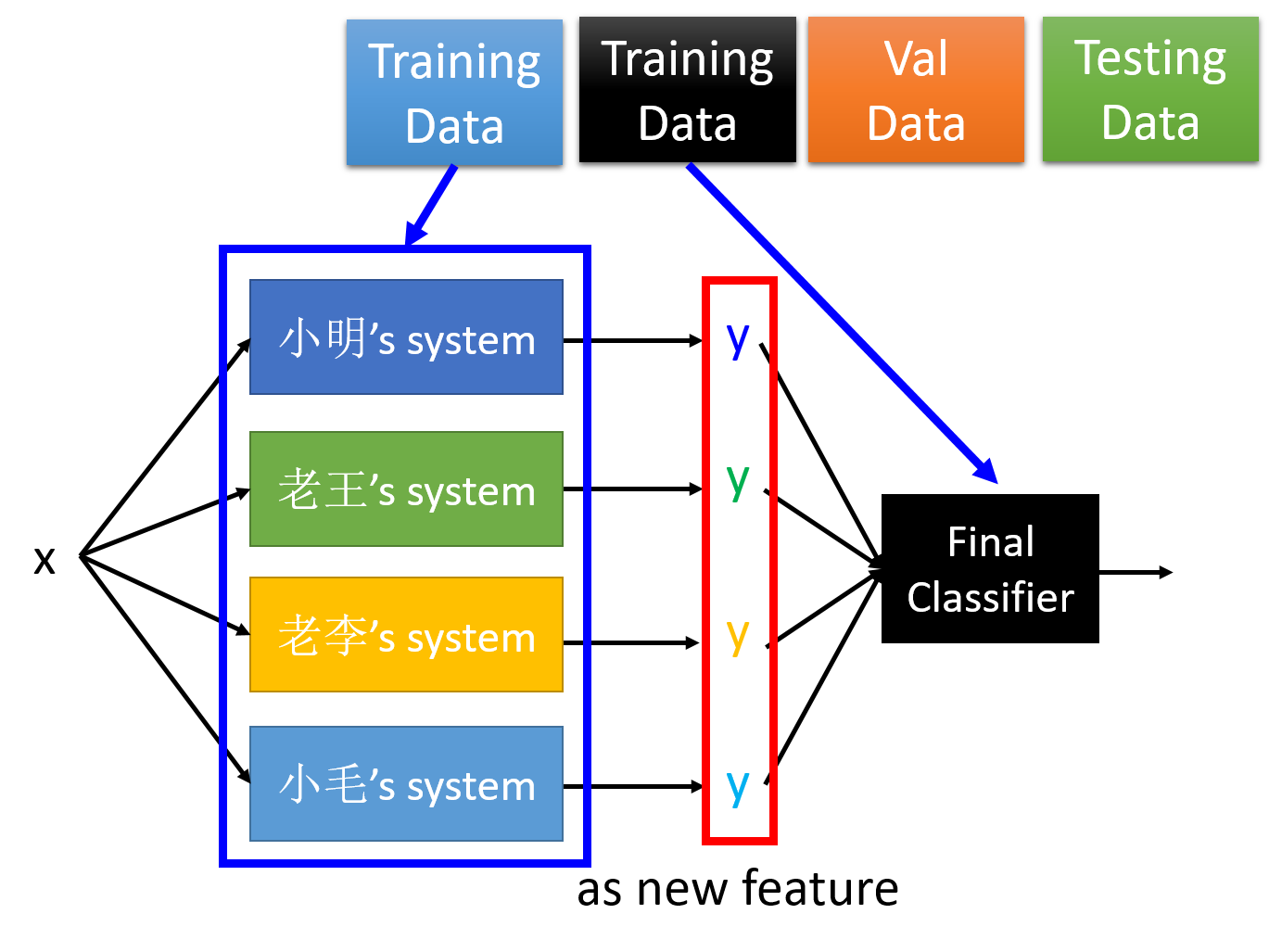
ЮвУЧНЋетЫФИіФЃаЭЕФЪфГізїЮЊ Final Classifier ЕФЪфШыЃЌНЋ Final Classifier
ЕФЪфГізїЮЊзюКѓЕФЗжРрНсЙћЁЃдкбЕСЗЕФЙ§ГЬжаЃЌНЋЪ§ОнЗжЮЊШчЩЯЕФЫФЗжЃЌЪЙгУЕквЛЗнЪ§ОнбЕСЗетИіМђЕЅЕФФЃаЭЃЌжЎКѓЪЙгУКкЩЋЕФЪ§ОнЪфШыжЎЧАбЕСЗЕФФЃаЭЃЌШЛКѓдйгУЫћУЧбЕСЗ
Final Classifier ЃЌетРя Final Classifier ВЩгУЕФЪЧвЛИіНЯЮЊМђЕЅЕФФЃаЭЃЌБШШчЫЕТпМЛиЙщЁЃШЛКѓдйгУКѓУцЕФЪ§ОнНјаабщжЄКЭВтЪдЁЃ |









