| БрМЭЦМі: |
БОЮФРДдДгкinfoqЃЌНщЩмСЫАйЗжЮЛЕФКУДІКЭВЛзуЃЌгІгУЪ§ОнЃЌдЄВтФЃаЭКЭвьГЃжЕЕШЁЃ |
|
ЙиМќвЊЕу
дкЩюШыСЫНтЪЙгУЛњЦїбЇЯАРДСЫНтШэМўЯЕЭГааЮЊжЎЧАЃЌБиаыЯШСЫНтДЋЭГЕФЪБМфађСаЗНЗЈЁЃ
ЪБМфађСаЪ§ОнЕФжЕШБЪЇПЩФмЛсдкЗжЮіЪБЕМжТвтЭтНсЙћЃЌPandasПтПЩвдАяЮЊФуЬюГфКЯРэЕФФЌШЯжЕЁЃ
ЕБШЫУЧдкЪЙгУФуЕФЗўЮёЪБЃЌФугІИУЦкЭћЪ§ОнОпгаМОНкадЁЃдкЩшМЦдЄВтЫуЗЈЪБвЊПМТЧЕНетвЛЕуЁЃ
ЧызЂвтФуЮЊвьГЃМьВтЩшжУЕФуажЕЁЃдкЕЅИіЗўЮёЦїЩЯВЛЬЋПЩФмЗЂЩњЕФЪТМўдкЖдгІгУГЬађНјааРЉеЙжЎКѓКмПЩФмЛсЗЂЩњЁЃ
дкЗжЮіЪБМфађСаЪБЃЌашвЊСЫНтФуЯывЊЪЕЯжЕФФПБъЁЃШЗБЃВЛвЊжЛЪЧЪЙгУМђЕЅЕФШЗЖЈадSQLЗжЮіЙЄОпЁЃСЫНтФуЕФЫуЗЈЕФааЮЊЃЌСЫНтФуЪЧЗёе§дкздЖЏЛЏЖдЫуЗЈЕФНтЪЭЃЌЛђепФуЪЧЗёе§дкНЋЪ§ОнзЊЛЛЮЊдЄВтВаВюВЂЪЙгУЫќУЧЁЃ
дк2018ФъQCon.aiДѓЛсЩЯЃЌDavid AndrzejewskiГЪЯжСЫЁАЭЈЙ§ЛњЦїбЇЯАКЭЪБМфађСаЪ§ОнРДРэНтШэМўЯЕЭГааЮЊЁБЕФбнНВЁЃDavidЪЧSumo
LogicЕФЙЄГЬОРэЃЌSumo LogicЪЧвЛИіЛљгкдЦЕФЛњЦїЪ§ОнЗжЮіЦНЬЈЁЃдЫааШэМўЯЕЭГЃЈШчгІгУГЬађЛђдЦШКМЏЃЉЕФПЊЗЂШЫдБПЩвдНЋSumo
LogicзїЮЊШежОМЧТМЕФКѓЖЫЁЃSumo LogicЮЊЛњЦїЪ§ОнЬсЙЉГжајжЧФмЁЃ
ЮвУЧЪЙгУШэМўРДНтОіКмЖрЮЪЬтЃЌЖјШЫЙЄжЧФмММЪѕПЊЪМНјШыЕНШэМўЪРНчЁЃдкЩюШыбаОПЛњЦїбЇЯАЖдШэМўЯЕЭГааЮЊЕФгАЯьжЎЧАЃЌБиаыЯШСЫНтДЋЭГЕФЪБМфађСаЗНЗЈЁЃСЫНтДЋЭГЗНЗЈЕФОжЯоадПЩвдШУФудкбЁдёММЪѕЪБзіГіУїжЧЕФШЈКтЁЃЪзЯШЃЌЮЪЮЪздМКЪЧЗёжЊЕРвЊЭъГЩЪВУДШЮЮёЁЃШЛКѓдйЪдзХЮЪздМКЪЧЗёПЩвдЭЈЙ§МђЕЅЛђШЗЖЈадЕФЗжЮіРДЪЕЯжетвЛФПБъЁЃжЛгадкЦфЫћЗНЗЈВЛПЩааЕФЧщПіЯТВХПМТЧЪЧЗёЪЙгУЛњЦїбЇЯАЁЃ
СЫНтШэМўЕФдЫаазДПівдМАЮЊЪВУДЛсЗЂЩњЙЪеЯПЩФмКмРЇФбЁЃЙЋЫОдкВПЪ№ЗўЮёЪБЃЌШчЙћетаЉЗўЮёвРРЕСЫЦфЫћЖрИіжїЛњЩЯЕФЮЂЗўЮёЃЌФЧУДПЩвдСаГіетаЉЮЂЗўЮёжЎМфЕФвРРЕЙиЯЕЃЌВЂЛцжЦГЩЭМБэЃЌетбљгажњгкРэЧхЗўЮёжЎМфЕФЙиЯЕЁЃдкЛцжЦетаЉЭМБъжЎКѓЃЌФуПЩФмЛсЕУЕНвЛИіШЫУЧГЦжЎЮЊЮЂЗўЮёЫРЭіжЎаЧЕФЭМЯёЃК

КмЖргІгУГЬађУПЬьЖМЩњГЩЪ§TBЕФШежОЃЌАќРЈЧЇеззжНкЕФдДДњТыЃЌВЂЧвУПЗжжгЪфГіЪ§АйЭђИіЖШСПжИБъЁЃЪжЖЏЗжЮіетаЉЪ§ОнЪЧВЛЯжЪЕЕФЃЌвђДЫФуашвЊЛњЦїжЧФмЕФАяжњЁЃЕЋЪЧЃЌЭЈЙ§ЗжЮіЪ§ОнРДевГіЯЕЭГдЫаазДПіЪЧвЛЯюМшОоЕФШЮЮёЃЌМДЪЙВЛЪЧВЛПЩФмЭъГЩЁЃгавЛЦЊгаШЄЕФТлЮФЩюШыбаОПСЫЪ§ОнЕФСЃЖШЁЊЁЊЁАЩёОПЦбЇМвПЩвдРэНтвЛИіЮЂДІРэЦїТ№ЃПЁБЁЃТлЮФЕФзїепЪЙгУФЃФтЦїРДЭцДѓН№ИегЮЯЗЁЃвђЮЊЫћУЧПЩвдЗУЮЪФЃФтЕФФкДцЃЌЫљвдПЩвдЗУЮЪЯЕЭГЕФЭъећзДЬЌЁЃДгРэТлЩЯНВЃЌетвтЮЖзХгаПЩФмПЩвдЭЈЙ§ЗжЮіЪ§ОнДгНЯИпВуУцСЫНтЯЕЭГе§дкзіЪВУДЁЃВЛЙ§ЃЌОЁЙметжжВпТдПЩвдЬсЙЉаЁЕФМћНтЃЌЕЋжЛЭЈЙ§ВщПДЪ§ОнЫЦКѕВЂВЛФмШУФуДгИќИпМЖВуДЮЭъШЋРэНтДѓН№ИегЮЯЗЕФдЫаазДЬЌЁЃ
ЕБФуНіЪЙгУдЪМЪ§ОнРДРэНтИДдгЁЂЖЏЬЌЁЂЖрГпЖШЕФЯЕЭГЪБЃЌетжжЦЪЮіБфЕУЗЧГЃживЊЁЃНЋдЪМЪ§ОнОлКЯЕНЪБМфађСаЪгЭМжаПЩвдШУЮвУЧИќШнвзПДЧхЮЪЬтЁЃЙШИшЕФЁАSite
Reliability EngineeringЁБЪЧвЛБОЗЧГЃКУЕФВЮПМЪщЃЌПЩвдУтЗбдкЯпдФЖСЁЃ
СЫНтИДдгЁЂЖЏЬЌЁЂЖрГпЖШЕФЯЕЭГЖдгкТжАрД§УќЕФЙЄГЬЪІРДЫЕгШЮЊживЊЁЃЕБЯЕЭГГіЯжЙЪеЯЪБЃЌЫћЛђЫ§БиаыФмЙЛжЊЕРЯЕЭГдкзіЪВУДЁЃЮЊДЫЃЌЙЄГЬЪІМШашвЊдЪМЪ§ОнЃЌвВашвЊПЩЪгЛЏЕФЗНЗЈЃЌвдМАФмЙЛОлКЯЪ§ОнЕФИќИпМЖБ№ЕФжИБъЁЃдкетжжЧщПіЯТЃЌЙЄГЬЪІЭЈГЃашвЊНЋЙЪеЯЗўЮёЦїгыЦфЫћЗўЮёЦїЕФааЮЊзіЖдБШЃЌЛђгызђЬьЕФааЮЊзіЖдБШЃЌЛђгыНјааШэМўИќаТжЎЧАЕФааЮЊзіЖдБШЁЃ
АйЗжЮЛЕФКУДІКЭВЛзу
дкВщПДвЛГЄДЎШежОЪ§ОнЪБЃЌФуВЛЛсжЛПДСЌајМИКСУыЕФЪ§ОнЯИНкЁЃФуПЩвдАДееЪБМфРДСПЛЏЪ§ОнЁЃзюЛљБОЕФЗНЗЈЪЧЪЙгУminЁЂmaxЁЂaverageЁЂsumКЭcountЕШКЏЪ§ЁЃКмЖрШЫдкОлКЯЪ§ОнЪБвВЯВЛЖЪЙгУАйЗжЮЛЁЃАйЗжЮЛЕФгХЪЦдкгкЫќУЧПЩвдгУУїШЗЕФгябдРДБэДяФуЕФЪ§ОнЁЃР§ШчЃЌЁАМгдивЛИіЧыЧѓзюГЄЕФЪБМфЪЧ4,300КСУыЁБЃЌетОфЛАКмОЋШЗЃЌЕЋЮоЗЈгУРДШЗЖЈЫќгые§ГЃВйзїжЎМфгаЖрЩйВюОрЁЃЕЋЪЧЃЌШчЙћЫЕГЩЁАp99аЁгк2,000КСУыЁБЃЌЫќОЭПЩвдИцЫпЮвУЧЃЌВЛГЌЙ§1ЃЅЕФПЭЛЇЧыЧѓашвЊГЌЙ§СНУыЕФМгдиЪБМфЁЃ
АйЗжЮЛЕФШБЕуЪЧФбвдНЋЪ§ОнзщКЯГЩгавтвхЕФЖЋЮїЁЃЫфШЛ50ЃЅзѓгвЕФжЕЧїгкЮШЖЈЃЌЕЋНЯИпЕФАйЗжЮЛЛсгаКмДѓВювьЃЌВЂЧвПЩФмжЕЛсГЪЯжГіГЄЮВЗжВМЁЃСэвЛИіЮЪЬтЪЧКмШнвзОЭОлКЯГЩЖдМИИіЪ§ОнМЏЕФМђЕЅЗжЮіЁЃФуПЩвдЛљгкСНИіЪ§ОнМЏЕФзюаЁжЕРДМЦЫуЫќУЧЕФећЬхзюаЁжЕЁЃЕЋЪЧЃЌФуВЛФмМђЕЅЕиЪЙгУАйЗжЮЛЗНЗЈЁЃДгЪ§бЇНЧЖШРДНВЃЌЮвУЧВЛПЩФмНЋЪ§ОнМЏXЕФp95гыЪ§ОнМЏYЕФp95зщКЯдквЛЦ№ЁЃетвтЮЖзХШчЙћУЛгаНјвЛВНЕФЗжЮіЃЌжЛЪЧзщКЯЖрИіЪ§ОнМЏВЂВЛвЛЖЈЪЧгавтвхЕФЁЃ
живЊЕФЪБМфађСаИХФю
зюЛљБОЕФЪБМфађСаМрПиЪЧБШНЯЪБМфвЦЮЛЁЃШчЙћФувЊНЋвЛИіШКМЏЕФаДШыбгГйгыЧАвЛЬьЯрЭЌжїЛњЕФаДШыбгГйНјааБШНЯЃЌетвЛЕуОЭгШЮЊживЊЁЃЫќвВПЩвдгыДАПкЪ§ОнНсКЯдквЛЦ№ЃЌГЦЮЊЁААДЪБМфЗжзщЁБЁЃИќЖраХЯЂПЩвддкTyler
AkidauЕФ2016ФъТхЩМэЖQConЕФбнНВжаевЕНЃЌЫћЛљгкApache BeamЬжТлСЫетИіИХФюЁЃ
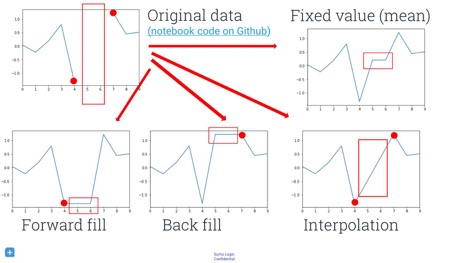
ДІРэШБЪЇЕФЪ§ОнвВКмживЊЁЃдкгІгУЛњЦїбЇЯАжЎЧАЃЌФуБиаыжЊЕРШчКЮДІРэШБЪЇжЕЁЃЪЙгУГЃЪ§жЕЃЈШчСуЛђЮоЧюДѓЃЉРДДњЬцШБЪЇжЕПЩФмЛсЕМжТвтЭтНсЙћЁЃЕЋЪЧЃЌШчЙћВЛДІРэШБЪЇжЕПЩФмЛсдкдЫааЪБВњЩњвьГЃЁЃетИіЮЪЬтПЩвдЭЈЙ§ЪЙгУPythonЕФPandasЪ§ОнЗжЮіПтРДНтОіЃЌЫќМђжБОЭЪЧДІРэЪ§ОнВйзїЮЪЬтЕФШ№ЪПОќЕЖЁЃФуПЩвдЪЙгУfillna()ЗНЗЈЃЌИУЗНЗЈЛсЬсЙЉвЛаЉКЯРэЕФФЌШЯжЕЁЃашвЊзЂвтЕФЪЧЃЌгаКмЖргаШЄЕФЗНЗЈПЩвдЬюВЙЪ§ОнжаЕФПеАзЃЌЛЙгаЦфЫћКмЖрПЩвдЪЙгУЕФбаОПГЩЙћКЭЗНЗЈЁЃгааЉСьгђГЦЦфЮЊЁАдЄВтЁБШБЪЇЪ§ОнЃЌгааЉСьгђГЦЦфЮЊЁАВхВЙЁБЁЂЁАЭЦЖЯЁБЛђЁАГщбљЁБЁЃФуПЩвдНјааЯђЧАЬюГфЃЌЛиЬюЛђВхШыЁЃ
гІгУЪ§Он
дкДюНЈШежОМЧТМЯЕЭГЪБашвЊПМТЧШчКЮЩшжУЙЬЖЈуажЕОЏБЈЁЃЩшжУОЏБЈЕФФПЕФЪЧдкЭјеОГіЯжЙЪеЯЛђЗЂЩњЦфЫћвтЭтЪТМўЪБФмЙЛЛНабФГШЫЁЃдкПЊЗЂОЏБЈЯЕЭГЪБЃЌКмЖрШЫЛсЦИЧыПЩвдЮЊЯЕЭГЩшжУКЯРэуажЕЕФСьгђзЈМвЁЃР§ШчЃЌФуПЩвдЩшжУвЛИіОЏБЈЃЌдк5ЃЅЕФЧыЧѓашвЊСНУывдЩЯЕФДІРэЪБМфЪБДЅЗЂОЏБЈЃЌДЫЪБЫќЛсЭЈжЊе§дкД§УќЕФЙЄГЬЪІЁЃ
ШЛЖјЃЌШЫРрзЈМвФбвдРЉеЙЁЃФуПЩФмЯЃЭћФмЙЛздЖЏНЋЛњЦїааЮЊгыЦфЫћЛњЦїааЮЊНјааБШНЯЃЌгШЦфЪЧЕБФугаКмЖрЛњЦїВЂЪфГіКмЖрЪБМфађСаЪБЁЃФуЮоЗЈздМКЗжЮіКЭБШНЯЫљгаЕФЪБМфађСаЃЌВЂЧвЕБЛњЦїЗЧГЃЖрЪБЃЌИќВЛПЩФметбљзіСЫЁЃДЫЪБЃЌФуПЩвдГЂЪдгІгУЛњЦїбЇЯАЁЃ
дЄВтФЃаЭКЭвьГЃжЕ
вЛжжЗНЗЈЪЧЪЙгУдЄВтНЈФЃНјаавьГЃжЕМьВтЁЃЭЈЙ§дЄВтЛњЦїЕФе§ГЃааЮЊЃЌОЭПЩвддкЛњЦїЕФааЮЊГЌГідЄВтНсЙћЗЖЮЇЪБМьВтГіЫќУЧЁЃЕЋЪЧЃЌдкФмЙЛЪЕЯжетбљЕФВйзїжЎЧАЃЌФуашвЊПМТЧКмЖрвђЫиЁЃФуашвЊЮЪздМКЫФИіЙиМќЮЪЬтЃК
етжжааЮЊЪЧЗёгаЙцТЩадЃП
ШчКЮЮЊетжжааЮЊНЈФЃЃП
ШчКЮЛљгкЦкЭћЖЈвхжївЊЦЋВюЃП
МьВтвтЭтЧщПіКЭЦЋВюЪЧЗёецЕФКмгаМлжЕЃП
дкНјаадЄВтНЈФЃЪБашвЊПМТЧЕФживЊЪТЯюЪЧЪ§ОнЕФМОНкадЛђНкзрЁЃШЮКЮгаШЫРрВЮгыЕФЗўЮёЖМгаЧБдкЕФНкзрЁЃР§ШчЃЌДѓЖрЪ§ШЫдкЙЄзїжаЪЙгУSumo
LogicЃЌетвтЮЖзХШЮКЮИјЖЈЙњМвЕФSumo LogicЪЙгУЪ§ОнНЋЯдЪОГідке§ГЃЙЄзїЪБМфФкгаДѓСПЕФЛюЖЏЃЌЕЋдкетаЉЪБМфжЎЭтВЛЛсгаЬЋЖрЛюЖЏЁЃЕЋЪЧЃЌNetflixЕФЪЙгУЪ§ОнПЩФмЛсЯдЪОГіЯрЗДЕФЧїЪЦЁЃФуПЩвдЭЈЙ§ЪжЖЏЕїећЪ§ОнЛђЪЙгУИЕРявЖБфЛЛЖдДЫНјааНЈФЃЃЌвВгаКмЖрШЫЛсЪЙгУвўВиТэЖћПЩЗђФЃаЭЁЃ
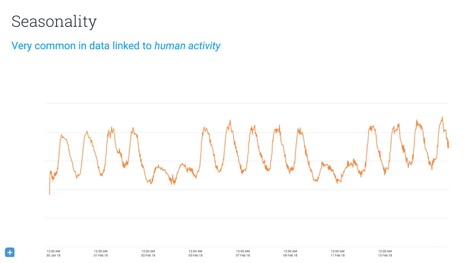
ЛљгкОрРыЕФЪБМфађСаЪ§ОнЭкОђ
ЕБФугаЖрЬЈМЦЫуЛњЪБЃЌПЩФмЯЃЭћНЋМЦЫуЛњЕФааЮЊНјааЯрЛЅБШНЯЁЃШчЙћФуПДЕНвЛЬЈЛњЦїГіЯжЦцЙжЕФааЮЊЃЌОЭЛсЯыжЊЕРЦфЫћЛњЦїЕФааЮЊЪЧЗёЯрЭЌЁЃвВаэЫћУЧдЫааЕФЪЧВЛЭЌАцБОЕФШэМўЃЌвВаэЫќУЧдкЭЌвЛИіЪ§ОнжааФжаЃЌЛђепПЩФме§дкЗЂЩњЦфЫћЪТЧщЁЃвЊЗжЮіетаЉЮЪЬтЃЌФуашвЊБШНЯЪБМфађСажЎМфЕФОрРыЁЃ
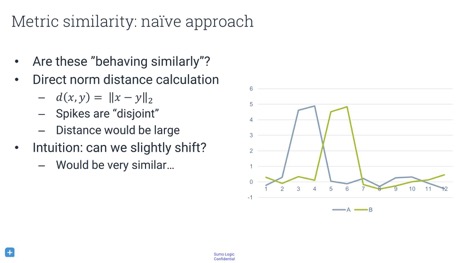
ФугІИУЪЙгУЪВУДжИБъРДШЗЖЈСНИіЪБМфађСажЎМфЕФЯрЫЦадЃПжЛЪЧЭЈЙ§МђЕЅЕФЛљгкЪБМфЕФЯрМѕПЯЖЈЛсЕУГіДэЮѓЕФНсЙћЁЃдкЩЯЭМжаЃЌЫфШЛЪБМфађСаЗЧГЃЯрЫЦЃЌЕЋЕУГіЕФжИБъЛсИцЫпФуЃЌЫќУЧЪЧЭъШЋВЛЭЌЕФЁЃ
ФуПЩвдЪЙгУвЛећЬзжИБъЁЃгавЛжжЗЧГЃСїааЕФММЪѕЃЌНазїЖЏЬЌЪБМфХЄЧњЃЌЫќЛсбЏЮЪФуЮЊСЫШУЪБМфађСаИќКУЕиЖдЦыНЋШчКЮЖдЪБМфађСаНјаааоИФЁЂХЄЧњЛђЦЦЛЕЃЌвдМАФуашвЊЮЊетаЉВйзїИЖГіЪВУДДњМлЁЃгаСЫетИіжИБъЃЌФуОЭПЩвдевЕНNИіОпгазюРрЫЦааЮЊЕФжїЛњЃЌвВПЩвдЛцжЦГіжїЛњЯрЫЦадЭМБэЁЃЭЈЙ§ВщПДЦзОлРрЭМЯёОЭПЩвджЊЕРжїЛњМфЕФНсЙЙЧщПіЁЃ
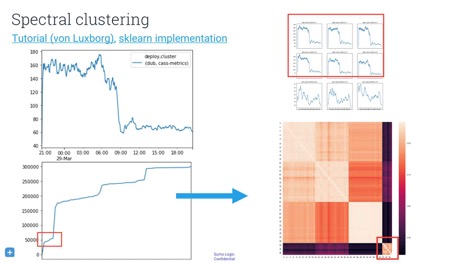
ЪЙгУШежОЪ§ОнНјаавьГЃМьВтКЭЪТМўЗжРр
гавЛаЉЗНЗЈПЩвдгУгкНЋШежОЪ§ОнзЊЛЛЮЊЪБМфађСаЁЃЕБФугЕгаДѓСПЕФАыНсЙЙЛЏзжЗћДЎЪБЃЌПЩвдЖдЯћЯЂНјааМЦЪ§ЛђДгжаЬсШЁаХЯЂЁЃетаЉШежОЪЧНќЫЦЕФГЬађжДааИњзйЁЃФуЕФЛњЦївЛЕЉНјШыЩњВњЛЗОГОЭЮоЗЈдйЪЙгУЕїЪдЦїЃЌжЛФмЭЈЙ§етаЉШежОЯћЯЂЭЦЖЯШэМўЕФааЮЊЁЃШчЙћФуЕФГЬађЕФУПИіЧыЧѓдкГЌЪБЪБЖМЛсДђгЁвЛИізжЗћДЎЃЌОЭПЩвдМЦЫуУПаЁЪБЕФГЌЪБДЮЪ§ЁЃетбљФуОЭПЩвдЕУЕНвЛИіЪБМфађСаЃЌШЛКѓНЋЫќУЧгУдкЗжЮіЩЯЃЁ
ФуПЩФмЯывЊЮЊФГИіЪБМфађСаЕФжЕЩшжУуажЕЁЃЕЋЪЧЃЌФугжВЛЯыЦлЦздМКЃЌБШШчАбвЛИіУЛгавтвхЕФЪТМўЕБГЩЪЧвЛИігаШЄЕФЪТМўЁЃЯыЯѓвЛЯТЃЌФугЕгавЛИіГЌОЋШЗЕФФЃаЭЃЌЫќЛсдкФЃЪНЗЂЩњЕФПЩФмадНіЮЊ0.01ЃЅЪБЗЂЫЭОЏБЈЁЃЕБФуЕФЗўЮёгавЛАйЭђИіЪБМфађСаЪБЃЌДѓдМЛсгавЛАйИіЮѓБЈЁЃBaron
SchwartzдкЫћЕФбнНВЁАЮЊЪВУДУЛШЫЙиаФФуЕФвьГЃМьВтЁБжаЯъЯИНщЩмСЫгІИУгУЪВУДММЪѕРДШЗЖЈуажЕЁЃ
ЩюЖШбЇЯАСьгђНќРДГіЯжСЫКмЖраТНјеЙЃЌФуПЩФмЯЃЭћдкдЄВтКЭвьГЃМьВтЩЯЪЙгУЩюЖШбЇЯАЃЌЕЋЩюЖШбЇЯАШдШЛЮоЗЈШУФуАкЭбРэНтЮЪЬтгђЁЃФуШдШЛашвЊевЕННтОіЮЪЬтЕФЗНЗЈЃЌвЛжжПЩФмЕФЗНЗЈЪЧЪЙгУЕнЙщЩёОЭјТчНјаадЄВтЁЃШчЙћФуХіЧЩПЩвдЗУЮЪДѓСПЕФбЕСЗЪ§ОнЃЌФЧУДетЛсЪЧИіКУжївтЁЃЕЋШчЙћУЛгаЃЌФуЕФЪзвЊШЮЮёгІИУЪЧдкГЂЪдЪЙгУЪ§ОнжЎЧАОлКЯЪ§ОнЁЃ
змжЎЃЌдкМьВщЪ§ОнЗНУцашвЊзіКмЖрЩюШыЕФЙЄзїЁЃЛњЦїгыЮвУЧЕФЩњЛюЯЂЯЂЯрЙиЁЃетаЉЛњЦїВњЩњЪ§ОнЃЌЕЋЗжЮіЪ§ОнКмИДдгЃЌЫљвдЮвУЧашвЊНшжњЛњЦїбЇЯАЁЃЗРжЙдывєКЭЮѓБЈЗЧГЃживЊЃЌвЊзіЕНетвЛЕуЃЌБиаыШЗБЃФуУїАзздМКЯывЊзіЪВУДЃЌвЊжЊЕРЮЊЪВУДУЛгаЪЙгУШЗЖЈадЕФSQLЗжЮіЙЄОпЃЌВЂДгЪ§бЇНЧЖШРэНтФуЫљЪЙгУЕФЗНЗЈЁЃзюКѓЃЌвЊжЊЕРФуздМКЪЧЗёдкздЖЏЛЏНтЪЭФуЕФЫуЗЈЃЌЛђепдкНЋЪ§ОнзЊЛЛЮЊдЄВтВаВюЃЌВЂНЋЦфгУгквьГЃдЄВтЁЃ
|









