| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌБОЮФжївЊНщЩмСЫЛњЦїбЇЯАСьгђЩцМАЕНКмЖрЕФЫуЗЈКЭФЃаЭжавЛаЉГЃМћЕФЫуЗЈЁЃ
|
|
ЛњЦїбЇЯА(Machine Learning, ML)ЪЧвЛУХЖрСьгђНЛВцбЇПЦЃЌЩцМАИХТЪТлЁЂЭГМЦбЇЁЂБЦНќТлЁЂЭЙЗжЮіЁЂЫуЗЈИДдгЖШРэТлЕШЖрУХбЇПЦЁЃзЈУХбаОПМЦЫуЛњдѕбљФЃФтЛђЪЕЯжШЫРрЕФбЇЯАааЮЊЃЌвдЛёШЁаТЕФжЊЪЖЛђММФмЃЌжиаТзщжЏвбгаЕФжЊЪЖНсЙЙЪЙжЎВЛЖЯИФЩЦздЩэЕФадФмЁЃ
бЯИёЕФЖЈвхЃКЛњЦїбЇЯАЪЧвЛУХбаОПЛњЦїЛёШЁаТжЊЪЖКЭаТММФмЃЌВЂЪЖБ№ЯжгажЊЪЖЕФбЇЮЪЁЃетРяЫљЫЕЕФЁАЛњЦїЁБЃЌжИЕФОЭЪЧМЦЫуЛњЃЌЕчзгМЦЫуЛњЃЌжазгМЦЫуЛњЁЂЙтзгМЦЫуЛњЛђЩёОМЦЫуЛњЕШЕШЁЃ
ЛњЦїбЇЯАИХТл
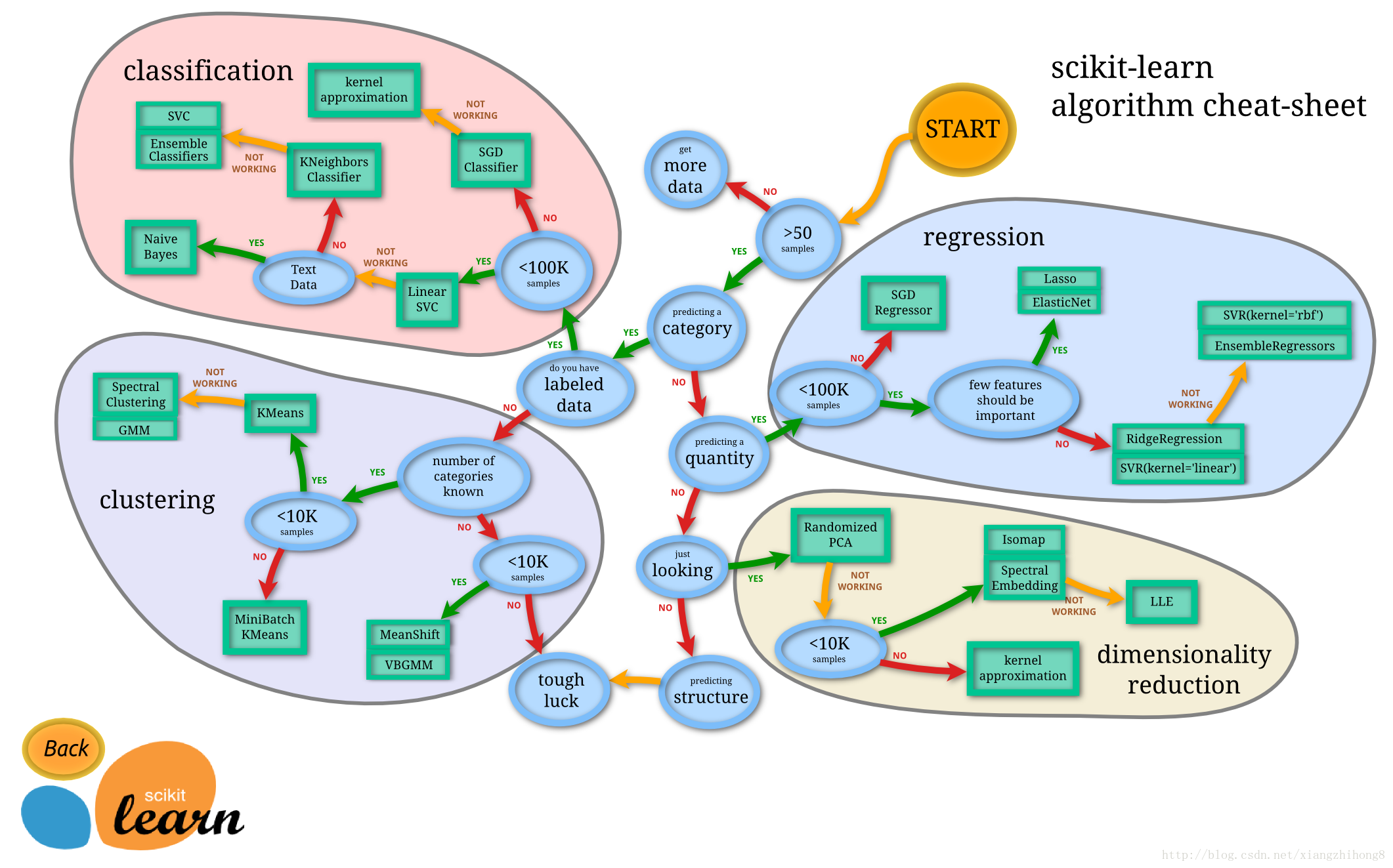
гЩЩЯЭМЫљЪОЃКЛњЦїбЇЯАЗжЮЊЫФДѓПщЃК classification (ЗжРр)ЃЌ clustering (ОлРр),regression
(ЛиЙщ), dimensionality reduction (НЕЮЌ)ЁЃ
classification & regression
ОйвЛИіМђЕЅЕФР§згЃК
ИјЖЈвЛИібљБОЬиеї x, ЮвУЧЯЃЭћдЄВтЦфЖдгІЕФЪєаджЕ y, ШчЙћ y ЪЧРыЩЂЕФ, ФЧУДетОЭЪЧвЛИіЗжРрЮЪЬтЃЌЗДжЎЃЌШчЙћ
y ЪЧСЌајЕФЪЕЪ§, етОЭЪЧвЛИіЛиЙщЮЪЬтЁЃ
ШчЙћИјЖЈвЛзщбљБОЬиеї S={xЁЪRD}, ЮвУЧУЛгаЖдгІЕФ y, ЖјЪЧЯыЗЂОђетзщбљБОдк D ЮЌПеМфЕФЗжВМ,
БШШчЗжЮіФФаЉбљБОППЕФИќНќЃЌФФаЉбљБОжЎМфРыЕУКмдЖ, етОЭЪЧЪєгкОлРрЮЪЬтЁЃ
ШчЙћЮвУЧЯыгУЮЌЪ§ИќЕЭЕФзгПеМфРДБэЪОдРДИпЮЌЕФЬиеїПеМф, ФЧУДетОЭЪЧНЕЮЌЮЪЬтЁЃ
ЮоТлЪЧЗжРрЛЙЪЧЛиЙщЃЌЖМЪЧЯыНЈСЂвЛИідЄВтФЃаЭ HЃЌИјЖЈвЛИіЪфШы x, ПЩвдЕУЕНвЛИіЪфГі y:
y=H(x)
ВЛЭЌЕФжЛЪЧдкЗжРрЮЪЬтжа, y ЪЧРыЩЂЕФ; ЖјдкЛиЙщЮЪЬтжа y ЪЧСЌајЕФЁЃЫљвдзмЕУРДЫЕЃЌСНжжЮЪЬтЕФбЇЯАЫуЗЈЖМКмРрЫЦЁЃЫљвддкетИіЭМЦзЩЯЃЌЮвУЧПДЕНдкЗжРрЮЪЬтжагУЕНЕФбЇЯАЫуЗЈЃЌдкЛиЙщЮЪЬтжавВФмЪЙгУЁЃЗжРрЮЪЬтзюГЃгУЕФбЇЯАЫуЗЈАќРЈ
SVM (жЇГжЯђСПЛњ) , SGD (ЫцЛњЬнЖШЯТНЕЫуЗЈ), Bayes (БДвЖЫЙЙРМЦ), Ensemble,
KNN ЕШЁЃЖјЛиЙщЮЪЬтвВФмЪЙгУ SVR, SGD, Ensemble ЕШЫуЗЈЃЌвдМАЦфЫќЯпадЛиЙщЫуЗЈЁЃ
clustering
ОлРрвВЪЧЗжЮібљБОЕФЪєад, гаЕуРрЫЦclassification, ВЛЭЌЕФОЭЪЧclassification
дкдЄВтжЎЧАЪЧжЊЕР y ЕФЗЖЮЇ, ЛђепЫЕжЊЕРЕНЕзгаМИИіРрБ№, ЖјОлРрЪЧВЛжЊЕРЪєадЕФЗЖЮЇЕФЁЃЫљвд classification
вВГЃГЃБЛГЦЮЊ supervised learning, ЖјclusteringОЭБЛГЦЮЊ unsupervised
learningЁЃ
clustering ЪТЯШВЛжЊЕРбљБОЕФЪєадЗЖЮЇЃЌжЛФмЦОНшбљБОдкЬиеїПеМфЕФЗжВМРДЗжЮібљБОЕФЪєадЁЃетжжЮЪЬтвЛАуИќИДдгЁЃЖјГЃгУЕФЫуЗЈАќРЈ
k-means (K-ОљжЕ), GMM (ИпЫЙЛьКЯФЃаЭ) ЕШЁЃ
dimensionality reduction
НЕЮЌЪЧЛњЦїбЇЯАСэвЛИіживЊЕФСьгђ, НЕЮЌгаКмЖрживЊЕФгІгУ, ЬиеїЕФЮЌЪ§Й§Ип, ЛсдіМгбЕСЗЕФИКЕЃгыДцДЂПеМф,
НЕЮЌОЭЪЧЯЃЭћШЅГ§ЬиеїЕФШпгр, гУИќМгЩйЕФЮЌЪ§РДБэЪОЬиеї. НЕЮЌЫуЗЈзюЛљДЁЕФОЭЪЧPCAСЫ, КѓУцЕФКмЖрЫуЗЈЖМЪЧвдPCAЮЊЛљДЁбнЛЏЖјРДЁЃ
ЛњЦїбЇЯАГЃМћЫуЗЈ
ЛњЦїбЇЯАСьгђЩцМАЕНКмЖрЕФЫуЗЈКЭФЃаЭЃЌетРяхрбЁвЛаЉГЃМћЕФЫуЗЈЃК
е§дђЛЏЫуЗЈЃЈRegularization AlgorithmsЃЉ
МЏГЩЫуЗЈЃЈEnsemble AlgorithmsЃЉ
ОіВпЪїЫуЗЈЃЈDecision Tree AlgorithmЃЉ
ЛиЙщЃЈRegressionЃЉ
ШЫЙЄЩёОЭјТчЃЈArtificial Neural NetworkЃЉ
ЩюЖШбЇЯАЃЈDeep LearningЃЉ
жЇГжЯђСПЛњЃЈSupport Vector MachineЃЉ
НЕЮЌЫуЗЈЃЈDimensionality Reduction AlgorithmsЃЉ
ОлРрЫуЗЈЃЈClustering AlgorithmsЃЉ
ЛљгкЪЕР§ЕФЫуЗЈЃЈInstance-based AlgorithmsЃЉ
БДвЖЫЙЫуЗЈЃЈBayesian AlgorithmsЃЉ
ЙиСЊЙцдђбЇЯАЫуЗЈЃЈAssociation Rule Learning AlgorithmsЃЉ
ЭМФЃаЭЃЈGraphical ModelsЃЉ### е§дђЛЏЫуЗЈЃЈRegularization AlgorithmsЃЉе§дђЛЏЫуЗЈЪЧСэвЛжжЗНЗЈЃЈЭЈГЃЪЧЛиЙщЗНЗЈЃЉЕФЭиеЙЃЌетжжЗНЗЈЛсЛљгкФЃаЭИДдгадЖдЦфНјааГЭЗЃЃЌЫќЯВЛЖЯрЖдМђЕЅФмЙЛИќКУЕФЗКЛЏЕФФЃаЭЁЃе§дђЛЏжаЮвУЧНЋБЃСєЫљгаЕФЬиеїБфСПЃЌЕЋЪЧЛсМѕаЁЬиеїБфСПЕФЪ§СПМЖЃЈВЮЪ§Ъ§жЕЕФДѓаЁІШ(j)ЃЉЁЃетИіЗНЗЈЗЧГЃгааЇЃЌЕБЮвУЧгаКмЖрЬиеїБфСПЪБЃЌЦфжаУПвЛИіБфСПЖМФмЖддЄВтВњЩњвЛЕугАЯьЁЃЫуЗЈЪЕР§ЃК
СыЛиЙщЃЈRidge RegressionЃЉ
зюаЁОјЖдЪеЫѕгыбЁдёЫузгЃЈLASSOЃЉ
GLASSO
ЕЏадЭјТчЃЈElastic NetЃЉ
зюаЁНЧЛиЙщЃЈLeast-Angle RegressionЃЉ
МЏГЩЫуЗЈЃЈEnsemble algorithmsЃЉ
МЏГЩЗНЗЈЪЧгЩЖрИіНЯШѕЕФФЃаЭМЏГЩФЃаЭзщЃЌЦфжаЕФФЃаЭПЩвдЕЅЖРНјаабЕСЗЃЌВЂЧвЫќУЧЕФдЄВтФмвдФГжжЗНЪННсКЯЦ№РДШЅзіГівЛИізмЬхдЄВтЁЃетРрЫуЗЈгжГЦдЊЫуЗЈ(meta-algorithm)ЁЃзюГЃМћЕФМЏГЩЫМЯыгаСНжжbaggingКЭboostingЁЃ
boosting
ЛљгкДэЮѓЬсЩ§ЗжРрЦїадФмЃЌЭЈЙ§МЏжаЙизЂБЛвбгаЗжРрЦїЗжРрДэЮѓЕФбљБОЃЌЙЙНЈаТЗжРрЦїВЂМЏГЩЁЃ
bagging
ЛљгкЪ§ОнЫцЛњжиГщбљЕФЗжРрЦїЙЙНЈЗНЗЈЁЃ
ЫуЗЈЪЕР§ЃК
Boosting
Bootstrapped AggregationЃЈBaggingЃЉ
AdaBoost
ВуЕўЗКЛЏЃЈStacked GeneralizationЃЉЃЈblendingЃЉ
ЬнЖШЭЦНјЛњЃЈGradient Boosting MachinesЃЌGBMЃЉ
ЬнЖШЬсЩ§ЛиЙщЪїЃЈGradient Boosted Regression TreesЃЌGBRTЃЉ
ЫцЛњЩСжЃЈRandom ForestЃЉзмНсЃКЕБЯШзюЯШНјЕФдЄВтМИКѕЖМЪЙгУСЫЫуЗЈМЏГЩЁЃЫќБШЪЙгУЕЅИіФЃаЭдЄВтГіРДЕФНсЙћвЊОЋШЗЕФЖрЁЃЕЋЪЧИУЫуЗЈашвЊДѓСПЕФЮЌЛЄЙЄзїЁЃЯъЯИНВНтЃКЛњЦїбЇЯАЫуЗЈжЎМЏГЩЫуЗЈ###
ОіВпЪїЫуЗЈЃЈDecision Tree AlgorithmЃЉОіВпЪїбЇЯАЪЙгУвЛИіОіВпЪїзїЮЊвЛИідЄВтФЃаЭЃЌЫќНЋЖдвЛИі
itemЃЈБэеїдкЗжжЇЩЯЃЉЙлВьЫљЕУгГЩфГЩЙигкИУ item ЕФФПБъжЕЕФНсТлЃЈБэеїдквЖзгжаЃЉЁЃОіВпЪїЭЈЙ§АбЪЕР§ДгєоНкЕуХХСаЕНФГИівЖзгНсЕуРДЗжРрЪЕР§ЃЌвЖзгНсЕуМДЮЊЪЕР§ЫљЪєЕФЗжРрЁЃЪїЩЯЕФУПвЛИіНсЕужИЖЈСЫЖдЪЕР§ЕФФГИіЪєадЕФВтЪдЃЌВЂЧвИУНсЕуЕФУПвЛИіКѓМЬЗжжЇЖдгІгкИУЪєадЕФвЛИіПЩФмжЕЁЃЗжРрЪЕР§ЕФЗНЗЈЪЧДгетПУЪїЕФИљНкЕуПЊЪМЃЌВтЪдетИіНсЕуЕФЪєадЃЌШЛКѓАДееИјЖЈЪЕР§ЕФЪєаджЕЖдгІЕФЪїжІЯђЯТвЦЖЏЁЃШЛКѓетИіЙ§ГЬдквдаТНсЕуЕФИљЕФзгЪїЩЯжиИДЁЃЫуЗЈЪЕР§ЃК
ЗжРрКЭЛиЙщЪїЃЈClassification and Regression TreeЃЌCARTЃЉ
Iterative Dichotomiser 3ЃЈID3ЃЉ
C4.5 КЭ C5.0ЃЈвЛжжЧПДѓЗНЗЈЕФСНИіВЛЭЌАцБОЃЉ
ЛиЙщЃЈRegressionЃЉЫуЗЈ
ЛиЙщЪЧгУгкЙРМЦСНжжБфСПжЎМфЙиЯЕЕФЭГМЦЙ§ГЬЁЃЕБгУгкЗжЮівђБфСПКЭвЛИі ЖрИіздБфСПжЎМфЕФЙиЯЕЪБЃЌИУЫуЗЈФмЬсЙЉКмЖрНЈФЃКЭЗжЮіЖрИіБфСПЕФММЧЩЁЃОпЬхвЛЕуЫЕЃЌЛиЙщЗжЮіПЩвдАяжњЮвУЧРэНтЕБШЮвтвЛИіздБфСПБфЛЏЃЌСэвЛИіздБфСПВЛБфЪБЃЌвђБфСПБфЛЏЕФЕфаЭжЕЁЃзюГЃМћЕФЪЧЃЌЛиЙщЗжЮіФмдкИјЖЈздБфСПЕФЬѕМўЯТЙРМЦГівђБфСПЕФЬѕМўЦкЭћЁЃ
ЫуЗЈЪЕР§ЃК
ЦеЭЈзюаЁЖўГЫЛиЙщЃЈOrdinary Least Squares RegressionЃЌOLSRЃЉ
ЯпадЛиЙщЃЈLinear RegressionЃЉ
ТпМЛиЙщЃЈLogistic RegressionЃЉ
ж№ВНЛиЙщЃЈStepwise RegressionЃЉ
ЖрдЊздЪЪгІЛиЙщбљЬѕЃЈMultivariate Adaptive Regression SplinesЃЌMARSЃЉ
БОЕиЩЂЕуЦНЛЌЙРМЦЃЈLocally Estimated Scatterplot SmoothingЃЌLOESSЃЉ
ШЫЙЄЩёОЭјТч
ШЫЙЄЩёОЭјТчЪЧЪмЩњЮяЩёОЭјТчЦєЗЂЖјЙЙНЈЕФЫуЗЈФЃаЭЁЃЫќЪЧвЛжжФЃЪНЦЅХфЃЌГЃБЛгУгкЛиЙщКЭЗжРрЮЪЬтЃЌЕЋгЕгаХгДѓЕФзггђЃЌгЩЪ§АйжжЫуЗЈКЭИїРрЮЪЬтЕФБфЬхзщГЩЁЃ
ШЫЙЄЩёОЭјТчЃЈANNЃЉЬсЙЉСЫвЛжжЦеБщЖјЧвЪЕМЪЕФЗНЗЈДгбљР§жабЇЯАжЕЮЊЪЕЪ§ЁЂРыЩЂжЕЛђЯђСПКЏЪ§ЁЃШЫЙЄЩёОЭјТчгЩвЛЯЕСаМђЕЅЕФЕЅдЊЯрЛЅСЌНгЙЙГЩЃЌЦфжаУПИіЕЅдЊгавЛЖЈЪ§СПЕФЪЕжЕЪфШыЃЌВЂВњЩњЕЅвЛЕФЪЕжЕЪфГіЁЃ
ЫуЗЈЪЕР§ЃК
ИажЊЦї
ЗДЯђДЋВЅ
Hopfield ЭјТч
ОЖЯђЛљКЏЪ§ЭјТчЃЈRadial Basis Function NetworkЃЌRBFNЃЉ
ЩюЖШбЇЯАЃЈDeep LearningЃЉ
ЩюЖШбЇЯАЪЧШЫЙЄЩёОЭјТчЕФзюаТЗжжЇЃЌЫќЪмвцгкЕБДњгВМўЕФПьЫйЗЂеЙЁЃ
жкЖрбаОПепФПЧАЕФЗНЯђжївЊМЏжагкЙЙНЈИќДѓЁЂИќИДдгЕФЩёОЭјТчЃЌФПЧАгааэЖрЗНЗЈе§дкОлНЙАыМрЖНбЇЯАЮЪЬтЃЌЦфжагУгкбЕСЗЕФДѓЪ§ОнМЏжЛАќКЌКмЩйЕФБъМЧЁЃ
ЫуЗЈЪЕР§ЃК
ЩюВЃЖњзШТќЛњЃЈDeep Boltzmann MachineЃЌDBMЃЉ
Deep Belief NetworksЃЈDBNЃЉ
ОэЛ§ЩёОЭјТчЃЈCNNЃЉ
Stacked Auto-Encoders
жЇГжЯђСПЛњЃЈSupport Vector MachinesЃЉ
жЇГжЯђСПЛњЪЧвЛжжМрЖНЪНбЇЯА (Supervised Learning)ЕФЗНЗЈЃЌжївЊгУдкЭГМЦЗжРр (Classification)ЮЪЬтКЭЛиЙщЗжЮі
(Regression)ЮЪЬтЩЯЁЃжЇГжЯђСПЛњЪєгквЛАуЛЏЯпадЗжРрЦїЃЌвВПЩвдБЛШЯЮЊЪЧЬсПЫТхЗђЙцЗЖЛЏЃЈTikhonov
RegularizationЃЉЗНЗЈЕФвЛИіЬиР§ЁЃетзхЗжРрЦїЕФЬиЕуЪЧЫћУЧФмЙЛЭЌЪБзюаЁЛЏОбщЮѓВюгызюДѓЛЏМИКЮБпдЕЧјЃЌвђДЫжЇГжЯђСПЛњвВБЛГЦЮЊзюДѓБпдЕЧјЗжРрЦїЁЃЯждкЖрМђГЦЮЊSVMЁЃ
ИјЖЈвЛзщбЕСЗЪТР§ЃЌЦфжаУПИіЪТР§ЖМЪєгкСНИіРрБ№жаЕФвЛИіЃЌжЇГжЯђСПЛњЃЈSVMЃЉбЕСЗЫуЗЈПЩвддкБЛЪфШыаТЕФЪТР§КѓНЋЦфЗжРрЕНСНИіРрБ№жаЕФвЛИіЃЌЪЙздЩэГЩЮЊЗЧИХТЪЖўНјжЦЯпадЗжРрЦїЁЃ
SVM ФЃаЭНЋбЕСЗЪТР§БэЪОЮЊПеМфжаЕФЕуЃЌЫќУЧБЛгГЩфЕНвЛЗљЭМжаЃЌгЩвЛЬѕУїШЗЕФЁЂОЁПЩФмПэЕФМфИєЗжПЊвдЧјЗжСНИіРрБ№ЁЃ
НЕЮЌЫуЗЈЃЈDimensionality Reduction AlgorithmsЃЉ
ЫљЮНЕФНЕЮЌОЭЪЧжИВЩгУФГжжгГЩфЗНЗЈЃЌНЋдИпЮЌПеМфжаЕФЪ§ОнЕугГЩфЕНЕЭЮЌЖШЕФПеМфжаЁЃНЕЮЌЕФБОжЪЪЧбЇЯАвЛИігГЩфКЏЪ§
f : x->yЃЌЦфжаxЪЧдЪМЪ§ОнЕуЕФБэДяЃЌФПЧАзюЖрЪЙгУЯђСПБэДяаЮЪНЁЃ yЪЧЪ§ОнЕугГЩфКѓЕФЕЭЮЌЯђСПБэДяЃЌЭЈГЃyЕФЮЌЖШаЁгкxЕФЮЌЖШЃЈЕБШЛЬсИпЮЌЖШвВЪЧПЩвдЕФЃЉЁЃfПЩФмЪЧЯдЪНЕФЛђвўЪНЕФЁЂЯпадЕФЛђЗЧЯпадЕФЁЃ
етвЛЫуЗЈПЩгУгкПЩЪгЛЏИпЮЌЪ§ОнЛђМђЛЏНгЯТРДПЩгУгкМрЖНбЇЯАжаЕФЪ§ОнЁЃаэЖретбљЕФЗНЗЈПЩеыЖдЗжРрКЭЛиЙщЕФЪЙгУНјааЕїећЁЃ
ЫуЗЈЪЕР§ЃК
жїГЩЗжЗжЮіЃЈPrincipal Component Analysis (PCA)ЃЉ
жїГЩЗжЛиЙщЃЈPrincipal Component Regression (PCR)ЃЉ
ЦЋзюаЁЖўГЫЛиЙщЃЈPartial Least Squares Regression (PLSR)ЃЉ
Sammon гГЩфЃЈSammon MappingЃЉ
ЖрЮЌГпЖШБфЛЛЃЈMultidimensional Scaling (MDS)ЃЉ
ЭЖгАбАзйЃЈProjection PursuitЃЉ
ЯпадХаБ№ЗжЮіЃЈLinear Discriminant Analysis (LDA)ЃЉ
ЛьКЯХаБ№ЗжЮіЃЈMixture Discriminant Analysis (MDA)ЃЉ
ЖўДЮХаБ№ЗжЮіЃЈQuadratic Discriminant Analysis (QDA)ЃЉ
СщЛюХаБ№ЗжЮіЃЈFlexible Discriminant Analysis
(FDA)ЃЉ
ОлРрЫуЗЈЃЈClustering AlgorithmsЃЉ
ОлРрЫуЗЈЪЧжИЖдвЛзщФПБъНјааЗжРрЃЌЪєгкЭЌвЛзщЃЈврМДвЛИіРрЃЌclusterЃЉЕФФПБъБЛЛЎЗждквЛзщжаЃЌгыЦфЫћзщФПБъЯрБШЃЌЭЌвЛзщФПБъИќМгБЫДЫЯрЫЦЁЃ
гХЕуЪЧШУЪ§ОнБфЕУгавтвхЃЌШБЕуЪЧНсЙћФбвдНтЖСЃЌеыЖдВЛЭЌЕФЪ§ОнзщЃЌНсЙћПЩФмЮогУЁЃ
ЫуЗЈЪЕР§ЃК
K-ОљжЕЃЈk-MeansЃЉ
k-Medians ЫуЗЈ
Expectation Maximi ЗтВу ation (EM)
зюДѓЦкЭћЫуЗЈЃЈEMЃЉ
ЗжВуМЏШКЃЈHierarchical ClsteringЃЉ
БДвЖЫЙЫуЗЈЃЈBayesian AlgorithmsЃЉ
БДвЖЫЙЖЈРэЃЈгЂгяЃКBayes' theoremЃЉЪЧИХТЪТлжаЕФвЛИіЖЈРэЃЌЫќИњЫцЛњБфСПЕФЬѕМўИХТЪвдМАБпдЕИХТЪЗжВМгаЙиЁЃдкгааЉЙигкИХТЪЕФНтЫЕжаЃЌБДвЖЫЙЖЈРэЃЈБДвЖЫЙИќаТЃЉФмЙЛИцжЊЮвУЧШчКЮРћгУаТжЄОнаоИФвбгаЕФПДЗЈЁЃБДвЖЫЙЗНЗЈЪЧжИУїШЗгІгУСЫБДвЖЫЙЖЈРэРДНтОіШчЗжРрКЭЛиЙщЕШЮЪЬтЕФЗНЗЈЁЃ
ЫуЗЈЪЕР§ЃК
ЦгЫиБДвЖЫЙЃЈNaive BayesЃЉ
ИпЫЙЦгЫиБДвЖЫЙЃЈGaussian Naive BayesЃЉ
ЖрЯюЪНЦгЫиБДвЖЫЙЃЈMultinomial Naive BayesЃЉ
ЦНОљвЛжТвРРЕЙРМЦЦїЃЈAveraged One-Dependence Estimators (AODE)ЃЉ
БДвЖЫЙаХФюЭјТчЃЈBayesian Belief Network (BBN)ЃЉ
БДвЖЫЙЭјТчЃЈBayesian Network (BN)ЃЉ
ЙиСЊЙцдђбЇЯАЫуЗЈЃЈAssociation Rule Learning AlgorithmsЃЉ
ЙиСЊЙцдђбЇЯАЗНЗЈФмЙЛЬсШЁГіЖдЪ§ОнжаЕФБфСПжЎМфЕФЙиЯЕЕФзюМбНтЪЭЁЃБШШчЫЕвЛМвГЌЪаЕФЯњЪлЪ§ОнжаДцдкЙцдђ
{бѓДаЃЌЭСЖЙ}=> {ККБЄ}ЃЌФЧЫЕУїЕБвЛЮЛПЭЛЇЭЌЪБЙКТђСЫбѓДаКЭЭСЖЙЕФЪБКђЃЌЫћКмгаПЩФмЛЙЛсЙКТђККБЄШтЁЃгаЕуРрЫЦгкСЊЯыЫуЗЈЁЃ
ЫуЗЈЪЕР§ЃК
Apriori ЫуЗЈЃЈApriori algorithmЃЉ
Eclat ЫуЗЈЃЈEclat algorithmЃЉ
FP-growth
ЭМФЃаЭЃЈGraphical ModelsЃЉ
ЭМФЃаЭ(GraphicalModels)дкИХТЪТлгыЭМТлжЎМфНЈСЂЦ№СЫСЊвіЙиЯЕЁЃЫќЬсЙЉСЫвЛжжздШЛЙЄОпРДДІРэгІгУЪ§бЇгыЙЄГЬжаЕФСНРрЮЪЬтЁЊЁЊВЛШЗЖЈад(Uncertainty)КЭИДдгад(Complexity)ЮЪ
ЬтЃЌЬиБ№ЪЧдкЛњЦїбЇЯАЫуЗЈЕФЗжЮігыЩшМЦжаАчбнзХживЊНЧЩЋЁЃЭМФЃаЭЕФЛљБОРэФюЪЧФЃПщЛЏЕФЫМЯыЃЌИДдгЯЕЭГЪЧЭЈЙ§зщКЯМђЕЅЯЕЭГНЈЙЙЕФЁЃИХТЪТлЬсЙЉСЫвЛжжеГКЯМСЪЙ
ЯЕЭГЕФИїИіВПЗжзщКЯдквЛЦ№ЃЌШЗБЃЯЕЭГзїЮЊећЬхЕФГжајвЛжТадЃЌЬсЙЉСЫЖржжЪ§ОнНгПкФЃаЭЗНЗЈЁЃ
ЭМФЃаЭЛђИХТЪЭМФЃаЭЃЈPGM/probabilistic graphical modelЃЉЪЧвЛжжИХТЪФЃаЭЃЌвЛИіЭМЃЈgraphЃЉПЩвдЭЈЙ§ЦфБэЪОЫцЛњБфСПжЎМфЕФЬѕМўвРРЕНсЙЙЃЈconditional
dependence structureЃЉЁЃ
ЫуЗЈЪЕР§ЃК
БДвЖЫЙЭјТчЃЈBayesian networkЃЉ
ТэЖћПЩЗђЫцЛњгђЃЈMarkov random fieldЃЉ
СДЭМЃЈChain GraphsЃЉ
зцЯШЭМЃЈAncestral graphЃЉ |









