| БрМЭЦМі: |
БОЮФгк360docЃЌНщЩмСЫЛњЦїбЇЯАЕФЗЖЮЇЃЌЛњЦїбЇЯАЕФЗНЗЈЃЌЛњЦїбЇЯАЕФгІгУЕШЁЃ
|
|
дкНјШые§ЬтЧАЃЌЮвЯыДѓМваФжаПЩФмЛсгавЛИівЩЛѓЃКЛњЦїбЇЯАгаЪВУДживЊадЃЌвджСгквЊдФЖСЭъетЦЊЗЧГЃГЄЕФЮФеТФиЃП
ЮвВЂВЛжБНгЛиД№етИіЮЪЬтЧАЁЃЯрЗДЃЌЮвЯыЧыДѓМвПДСНеХЭМЃК

ЭМ1 ЛњЦїбЇЯАНчЕФжДХЃЖњКЭЛЅСЊЭјНчДѓіљЕФСЊві
етЗљЭМЩЯЕФШ§ШЫЪЧЕБНёЛњЦїбЇЯАНчЕФжДХЃЖњепЁЃжаМфЕФЪЧGeoffrey Hinton, МгФУДѓЖрТзЖрДѓбЇЕФНЬЪкЃЌШчНёБЛЦИЮЊЁАGoogleДѓФдЁБЕФИКд№ШЫЁЃгвБпЕФЪЧYann
LeCun, ХІдМДѓбЇНЬЪкЃЌШчНёЪЧFacebookШЫЙЄжЧФмЪЕбщЪвЕФжїШЮЁЃЖјзѓБпЕФДѓМвЖМКмЪьЯЄЃЌAndrew
NgЃЌжаЮФУћЮтЖїДяЃЌЫЙЬЙИЃДѓбЇИБНЬЪкЃЌШчНёвВЪЧЁААйЖШДѓФдЁБЕФИКд№ШЫгыАйЖШЪзЯЏПЦбЇМвЁЃ
етШ§ЮЛЖМЪЧФПЧАвЕНчжЫЪжПЩШШЕФДѓХЃЃЌБЛЛЅСЊЭјНчДѓіљЧѓЯЭШєПЪЕФЦИЧыЃЌзуМћЫћУЧЕФживЊадЁЃЖјЫћУЧЕФбаОПЗНЯђЃЌдђШЋВПЖМЪЧЛњЦїбЇЯАЕФзгРр--ЩюЖШбЇЯАЁЃ

ЭМ2 гявєжњЪжВњЦЗ
етЗљЭМЩЯУшЪіЕФЪЧЪВУДЃПWindows PhoneЩЯЕФгявєжњЪжCortanaЃЌУћзжРДдДгкЁЖЙтЛЗЁЗжаЪПЙйГЄЕФжњЪжЁЃЯрБШЦфЫћОКељЖдЪжЃЌЮЂШэКмГйВХЭЦГіетИіЗўЮёЁЃCortanaБГКѓЕФКЫаФММЪѕЪЧЪВУДЃЌЮЊЪВУДЫќФмЙЛЬ§ЖЎШЫЕФгявєЃПЪТЪЕЩЯЃЌетИіММЪѕе§ЪЧЛњЦїбЇЯАЁЃЛњЦїбЇЯАЪЧЫљгагявєжњЪжВњЦЗ(АќРЈAppleЕФsiriгыGoogleЕФNow)ФмЙЛИњШЫНЛЛЅЕФЙиМќММЪѕЁЃ
ЭЈЙ§ЩЯУцСНЭМЃЌЮвЯраХДѓМвПЩвдПДГіЛњЦїбЇЯАЫЦКѕЪЧвЛИіКмживЊЕФЃЌгаКмЖрЮДжЊЬиадЕФММЪѕЁЃ
1.вЛИіЙЪЪТЫЕУїЪВУДЪЧЛњЦїбЇЯА
ЛњЦїбЇЯАетИіДЪЪЧШУШЫвЩЛѓЕФЃЌЪзЯШЫќЪЧгЂЮФУћГЦMachine Learning(МђГЦML)ЕФжБвыЃЌдкМЦЫуНчMachineвЛАужИМЦЫуЛњЁЃетИіУћзжЪЙгУСЫФтШЫЕФЪжЗЈЃЌЫЕУїСЫетУХММЪѕЪЧШУЛњЦїЁАбЇЯАЁБЕФММЪѕЁЃЕЋЪЧМЦЫуЛњЪЧЫРЕФЃЌдѕУДПЩФмЯёШЫРрвЛбљЁАбЇЯАЁБФиЃП
ДЋЭГЩЯШчЙћЮвУЧЯыШУМЦЫуЛњЙЄзїЃЌЮвУЧИјЫќвЛДЎжИСюЃЌШЛКѓЫќзёееетИіжИСювЛВНВНжДааЯТШЅЁЃгавђгаЙћЃЌЗЧГЃУїШЗЁЃЕЋетбљЕФЗНЪНдкЛњЦїбЇЯАжаааВЛЭЈЁЃЛњЦїбЇЯАИљБОВЛНгЪмФуЪфШыЕФжИСюЃЌЯрЗДЃЌЫќНгЪмФуЪфШыЕФЪ§Он!
вВОЭЪЧЫЕЃЌЛњЦїбЇЯАЪЧвЛжжШУМЦЫуЛњРћгУЪ§ОнЖјВЛЪЧжИСюРДНјааИїжжЙЄзїЕФЗНЗЈЁЃетЬ§Ц№РДЗЧГЃВЛПЩЫМвщЃЌЕЋНсЙћЩЯШДЪЧЗЧГЃПЩааЕФЁЃ
НгЯТРДетИіР§згРДдДгкЮвецЪЕЕФЩњЛюОбщЃЌЮвдкЫМПМетИіЮЪЬтЕФЪБКђЭЛШЛЗЂЯжЫќЕФЙ§ГЬПЩвдБЛРЉГфЛЏЮЊвЛИіЭъећЕФЛњЦїбЇЯАЕФЙ§ГЬЃЌвђДЫЮвОіЖЈЪЙгУетИіР§згзїЮЊЫљгаНщЩмЕФПЊЪМЁЃетИіЙЪЪТГЦЮЊЁАЕШШЫЮЪЬтЁБЁЃ
ЮввЛИіХѓгбаЁYЃЌЫћВЛЪЧФЧУДЪиЪБЃЌзюГЃМћЕФБэЯжЪЧЫћОГЃГйЕНЁЃЕБгавЛДЮЮвИњЫћдМКУ3ЕужгдкФГИіТѓЕБРЭМћУцЪБЃЌдкЮвГіУХЕФФЧвЛПЬЮвЭЛШЛЯыЕНвЛИіЮЪЬтЃКЮвЯждкГіЗЂКЯЪЪУДЃПЮвЛсВЛЛсгжЕНСЫЕиЕуКѓЃЌЛЙвЊЛЈЩЯ30ЗжжгШЅЕШЫћЃП
ЮвОіЖЈВЩШЁвЛИіВпТдНтОіетИіЮЪЬтЁЃ
ЮвАбЙ§ЭљИњаЁYЯрдМЕФОРњдкФдКЃжажиЯжвЛЯТЃЌПДПДИњЫћЯрдМЕФДЮЪ§жаЃЌГйЕНеМСЫЖрДѓЕФБШР§ЁЃЖјЮвРћгУетРДдЄВтЫћетДЮГйЕНЕФПЩФмадЁЃШчЙћетИіжЕГЌГіСЫЮваФРяЕФФГИіНчЯоЃЌФЧЮвбЁдёЕШвЛЛсдйГіЗЂЁЃ
МйЩшЮвИњаЁYдМЙ§5ДЮЃЌЫћГйЕНЕФДЮЪ§ЪЧ1ДЮЃЌФЧУДЫћАДЪБЕНЕФБШР§ЮЊ80%ЃЌЮваФжаЕФуажЕЮЊ70%ЃЌЮвШЯЮЊетДЮаЁYгІИУВЛЛсГйЕНЃЌвђДЫЮвАДЪБГіУХЁЃШчЙћаЁYдк5ДЮГйЕНЕФДЮЪ§жаеМСЫ4ДЮЃЌвВОЭЪЧЫћАДЪБЕНДяЕФБШР§ЮЊ20%ЃЌгЩгкетИіжЕЕЭгкЮвЕФуажЕЃЌвђДЫЮвбЁдёЭЦГйГіУХЕФЪБМфЁЃ
етИіЗНЗЈДгЫќЕФРћгУВуУцРДПДЃЌгжГЦЮЊОбщЗЈЁЃдкОбщЗЈЕФЫМПМЙ§ГЬжаЃЌЮвЪТЪЕЩЯРћгУСЫвдЭљЫљгаЯрдМЕФЪ§ОнЁЃвђДЫвВПЩвдГЦжЎЮЊвРОнЪ§ОнзіЕФХаЖЯЁЃвРОнЪ§ОнЫљзіЕФХаЖЯИњЛњЦїбЇЯАЕФЫМЯыИљБОЩЯЪЧвЛжТЕФЁЃ
ИеВХЕФЫМПМЙ§ГЬЮвжЛПМТЧЁАЦЕДЮЁБетжжЪєадЁЃдкецЪЕЕФЛњЦїбЇЯАжаЃЌетПЩФмЖМВЛЫуЪЧвЛИігІгУЁЃвЛАуЕФЛњЦїбЇЯАФЃаЭжСЩйПМТЧСНИіСПЃКвЛИіЪЧвђБфСПЃЌвВОЭЪЧЮвУЧЯЃЭћдЄВтЕФНсЙћЃЌдкетИіР§згРяОЭЪЧаЁYГйЕНгыЗёЕФХаЖЯЁЃСэвЛИіЪЧздБфСПЃЌвВОЭЪЧгУРДдЄВтаЁYЪЧЗёГйЕНЕФСПЁЃ
МйЩшЮвАбЪБМфзїЮЊздБфСПЃЌЦЉШчЮвЗЂЯжаЁYЫљгаГйЕНЕФШезгЛљБОЖМЪЧаЧЦкЮхЃЌЖјдкЗЧаЧЦкЮхЧщПіЯТЫћЛљБОВЛГйЕНЁЃгкЪЧЮвПЩвдНЈСЂвЛИіФЃаЭЃЌРДФЃФтаЁYГйЕНгыЗёИњШезгЪЧЗёЪЧаЧЦкЮхЕФИХТЪЁЃМћЯТЭМЃК
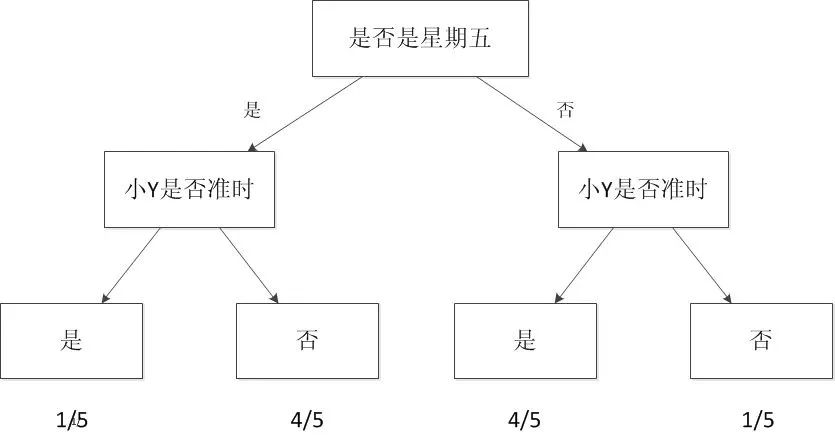
ЭМ3 ОіВпЪїФЃаЭ
етбљЕФЭМОЭЪЧвЛИізюМђЕЅЕФЛњЦїбЇЯАФЃаЭЃЌГЦжЎЮЊОіВпЪїЁЃ
ЕБЮвУЧПМТЧЕФздБфСПжЛгавЛИіЪБЃЌЧщПіНЯЮЊМђЕЅЁЃШчЙћАбЮвУЧЕФздБфСПдйдіМгвЛИіЁЃР§ШчаЁYГйЕНЕФВПЗжЧщПіЪБЪЧдкЫћПЊГЕЙ§РДЕФЪБКђ(ФуПЩвдРэНтЮЊЫћПЊГЕЫЎЦННЯГєЃЌЛђепТЗНЯЖТ)ЁЃгкЪЧЮвПЩвдЙиСЊПМТЧетаЉаХЯЂЁЃНЈСЂвЛИіИќИДдгЕФФЃаЭЃЌетИіФЃаЭАќКЌСНИіздБфСПгывЛИівђБфСПЁЃ
дйИќИДдгвЛЕуЃЌаЁYЕФГйЕНИњЬьЦјвВгавЛЖЈЕФдвђЃЌР§ШчЯТгъЕФЪБКђЃЌетЪБКђЮвашвЊПМТЧШ§ИіздБфСПЁЃ
ШчЙћЮвЯЃЭћФмЙЛдЄВтаЁYГйЕНЕФОпЬхЪБМфЃЌЮвПЩвдАбЫћУПДЮГйЕНЕФЪБМфИњгъСПЕФДѓаЁвдМАЧАУцПМТЧЕФздБфСПЭГвЛНЈСЂвЛИіФЃаЭЁЃгкЪЧЮвЕФФЃаЭПЩвддЄВтжЕЃЌР§ШчЫћДѓИХЛсГйЕНМИЗжжгЁЃетбљПЩвдАяжњЮвИќКУЕФЙцЛЎЮвГіУХЕФЪБМфЁЃдкетбљЕФЧщПіЯТЃЌОіВпЪїОЭЮоЗЈКмКУЕижЇГХСЫЃЌвђЮЊОіВпЪїжЛФмдЄВтРыЩЂжЕЁЃЮвУЧПЩвдгУНк2ЫљНщЩмЕФЯпаЭЛиЙщЗНЗЈНЈСЂетИіФЃаЭЁЃ
ШчЙћЮвАбетаЉНЈСЂФЃаЭЕФЙ§ГЬНЛИјЕчФдЁЃБШШчАбЫљгаЕФздБфСПКЭвђБфСПЪфШыЃЌШЛКѓШУМЦЫуЛњАяЮвЩњГЩвЛИіФЃаЭЃЌЭЌЪБШУМЦЫуЛњИљОнЮвЕБЧАЕФЧщПіЃЌИјГіЮвЪЧЗёашвЊГйГіУХЃЌашвЊГйМИЗжжгЕФНЈвщЁЃФЧУДМЦЫуЛњжДааетаЉИЈжњОіВпЕФЙ§ГЬОЭЪЧЛњЦїбЇЯАЕФЙ§ГЬЁЃ
ЭЈЙ§ЩЯУцЕФЗжЮіЃЌПЩвдПДГіЛњЦїбЇЯАгыШЫРрЫМПМЕФОбщЙ§ГЬЪЧРрЫЦЕФЃЌВЛЙ§ЫќФмПМТЧИќЖрЕФЧщПіЃЌжДааИќМгИДдгЕФМЦЫуЁЃЪТЪЕЩЯЃЌЛњЦїбЇЯАЕФвЛИіжївЊФПЕФОЭЪЧАбШЫРрЫМПМЙщФЩОбщЕФЙ§ГЬзЊЛЏЮЊМЦЫуЛњЭЈЙ§ЖдЪ§ОнЕФДІРэМЦЫуЕУГіФЃаЭЕФЙ§ГЬЁЃОЙ§МЦЫуЛњЕУГіЕФФЃаЭФмЙЛвдНќЫЦгкШЫЕФЗНЪННтОіКмЖрСщЛюИДдгЕФЮЪЬтЁЃ
ШУЮвУЧАбЛњЦїбЇЯАЕФЙ§ГЬгыШЫРрЖдРњЪЗОбщЙщФЩЕФЙ§ГЬзіИіБШЖдЁЃ
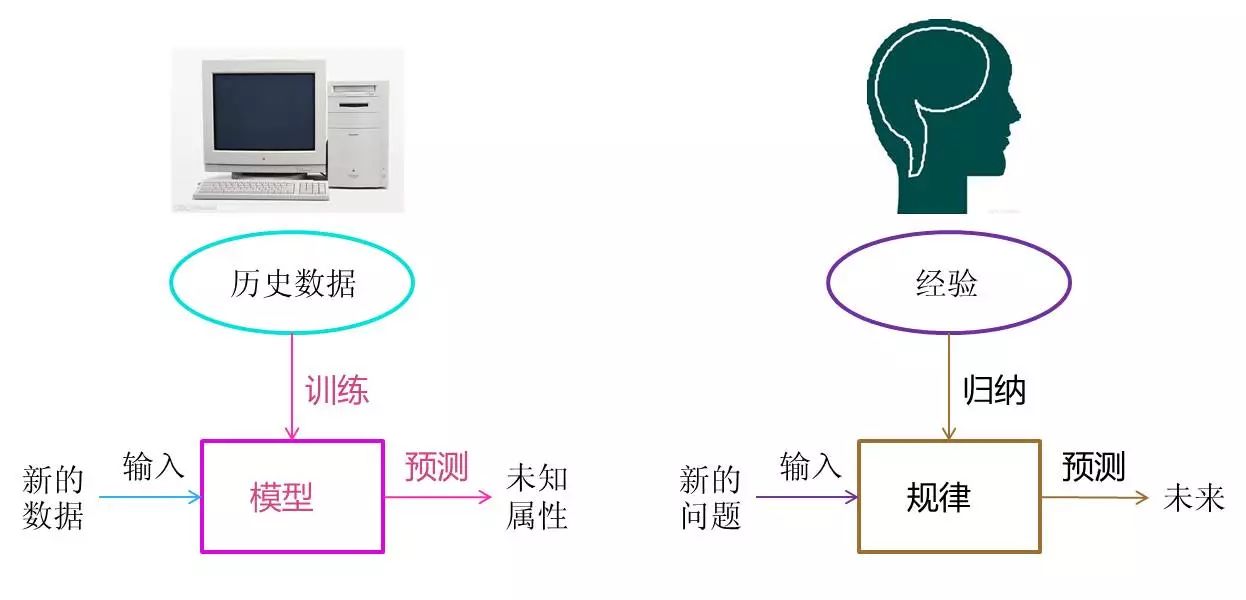
ЭМ4 ЛњЦїбЇЯАгыШЫРрЫМПМЕФРрБШ
ЛњЦїбЇЯАжаЕФЁАбЕСЗЁБгыЁАдЄВтЁБЙ§ГЬПЩвдЖдгІЕНШЫРрЕФЁАЙщФЩЁБКЭЁАЭЦВтЁБЙ§ГЬЁЃЭЈЙ§етбљЕФЖдгІЃЌЮвУЧПЩвдЗЂЯжЃЌЛњЦїбЇЯАЕФЫМЯыВЂВЛИДдгЃЌНіНіЪЧЖдШЫРрдкЩњЛюжабЇЯАГЩГЄЕФвЛИіФЃФтЁЃгЩгкЛњЦїбЇЯАВЛЪЧЛљгкБрГЬаЮГЩЕФНсЙћЃЌвђДЫЫќЕФДІРэЙ§ГЬВЛЪЧвђЙћЕФТпМЃЌЖјЪЧЭЈЙ§ЙщФЩЫМЯыЕУГіЕФЯрЙиадНсТлЁЃ
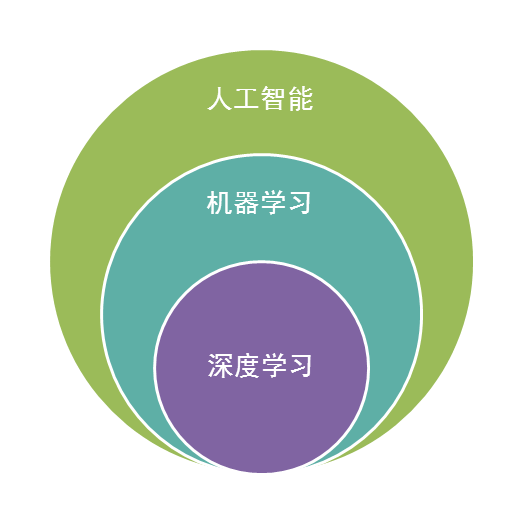
2.ЛњЦїбЇЯАЕФЗЖЮЇ
ЦфЪЕЃЌЛњЦїбЇЯАИњФЃЪНЪЖБ№ЃЌЭГМЦбЇЯАЃЌЪ§ОнЭкОђЃЌМЦЫуЛњЪгОѕЃЌгявєЪЖБ№ЃЌздШЛгябдДІРэЕШСьгђгазХКмЩюЕФСЊЯЕЁЃ
ДгЗЖЮЇЩЯРДЫЕЃЌЛњЦїбЇЯАИњФЃЪНЪЖБ№ЃЌЭГМЦбЇЯАЃЌЪ§ОнЭкОђЪЧРрЫЦЕФЃЌЭЌЪБЃЌЛњЦїбЇЯАгыЦфЫћСьгђЕФДІРэММЪѕЕФНсКЯЃЌаЮГЩСЫМЦЫуЛњЪгОѕЁЂгявєЪЖБ№ЁЂздШЛгябдДІРэЕШНЛВцбЇПЦЁЃвђДЫЃЌвЛАуЫЕЪ§ОнЭкОђЪБЃЌПЩвдЕШЭЌгкЫЕЛњЦїбЇЯАЁЃЭЌЪБЃЌЮвУЧЦНГЃЫљЫЕЕФЛњЦїбЇЯАгІгУЃЌгІИУЪЧЭЈгУЕФЃЌВЛНіНіОжЯодкНсЙЙЛЏЪ§ОнЃЌЛЙгаЭМЯёЃЌвєЦЕЕШгІгУЁЃ
ЯТЭМЪЧЛњЦїбЇЯАЫљЧЃГЖЕФвЛаЉЯрЙиЗЖЮЇЕФбЇПЦгыбаОПСьгђЁЃ

ЭМ5 ЛњЦїбЇЯАгыЯрЙибЇПЦ
ФЃЪНЪЖБ№
ФЃЪНЪЖБ№=ЛњЦїбЇЯАЁЃСНепЕФжївЊЧјБ№дкгкЧАепЪЧДгЙЄвЕНчЗЂеЙЦ№РДЕФИХФюЃЌКѓепдђжївЊдДздМЦЫуЛњбЇПЦЁЃ
Ъ§ОнЭкОђ
Ъ§ОнЭкОђ=ЛњЦїбЇЯА+Ъ§ОнПтЁЃетМИФъЪ§ОнЭкОђЕФИХФюЪЕдкЪЧЬЋЖњЪьФмЯъЁЃМИКѕЕШЭЌгкГДзїЁЃЕЋЗВЫЕЪ§ОнЭкОђЖМЛсДЕаъЪ§ОнЭкОђШчКЮШчКЮЃЌР§ШчДгЪ§ОнжаЭкГіН№згЃЌвдМАНЋЗЯЦњЕФЪ§ОнзЊЛЏЮЊМлжЕЕШЕШЁЃЕЋЪЧЃЌЮвОЁЙмПЩФмЛсЭкГіН№згЃЌЕЋЮввВПЩФмЭкЕФЪЧЁАЪЏЭЗЁБАЁЁЃетИіЫЕЗЈЕФвтЫМЪЧЃЌЪ§ОнЭкОђНіНіЪЧвЛжжЫМПМЗНЪНЃЌИцЫпЮвУЧгІИУГЂЪдДгЪ§ОнжаЭкОђГіжЊЪЖЃЌЕЋВЛЪЧУПИіЪ§ОнЖМФмЭкОђГіН№згЕФЃЌЫљвдВЛвЊЩёЛАЫќЁЃвЛИіЯЕЭГОјЖдВЛЛсвђЮЊЩЯСЫвЛИіЪ§ОнЭкОђФЃПщОЭБфЕУЮоЫљВЛФм(етЪЧIBMзюЯВЛЖДЕаъЕФ)ЃЌЧЁЧЁЯрЗДЃЌвЛИігЕгаЪ§ОнЭкОђЫМЮЌЕФШЫдБВХЪЧЙиМќЃЌЖјЧвЫћЛЙБиаыЖдЪ§ОнгаЩюПЬЕФШЯЪЖЃЌетбљВХПЩФмДгЪ§ОнжаЕМГіФЃЪНжИв§вЕЮёЕФИФЩЦЁЃДѓВПЗжЪ§ОнЭкОђжаЕФЫуЗЈЪЧЛњЦїбЇЯАЕФЫуЗЈдкЪ§ОнПтжаЕФгХЛЏЁЃ
ЭГМЦбЇЯА
ЭГМЦбЇЯАНќЫЦЕШгкЛњЦїбЇЯАЁЃЭГМЦбЇЯАЪЧИігыЛњЦїбЇЯАИпЖШжиЕўЕФбЇПЦЁЃвђЮЊЛњЦїбЇЯАжаЕФДѓЖрЪ§ЗНЗЈРДздЭГМЦбЇЃЌЩѕжСПЩвдШЯЮЊЃЌЭГМЦбЇЕФЗЂеЙДйНјЛњЦїбЇЯАЕФЗБШйВ§ЪЂЁЃР§ШчжјУћЕФжЇГжЯђСПЛњЫуЗЈЃЌОЭЪЧдДздЭГМЦбЇПЦЁЃЕЋЪЧдкФГжжГЬЖШЩЯСНепЪЧгаЗжБ№ЕФЃЌетИіЗжБ№дкгкЃКЭГМЦбЇЯАепжиЕуЙизЂЕФЪЧЭГМЦФЃаЭЕФЗЂеЙгыгХЛЏЃЌЦЋЪ§бЇЃЌЖјЛњЦїбЇЯАепИќЙизЂЕФЪЧФмЙЛНтОіЮЪЬтЃЌЦЋЪЕМљЃЌвђДЫЛњЦїбЇЯАбаОПепЛсжиЕубаОПбЇЯАЫуЗЈдкМЦЫуЛњЩЯжДааЕФаЇТЪгызМШЗадЕФЬсЩ§ЁЃ
МЦЫуЛњЪгОѕ
МЦЫуЛњЪгОѕ=ЭМЯёДІРэ+ЛњЦїбЇЯАЁЃЭМЯёДІРэММЪѕгУгкНЋЭМЯёДІРэЮЊЪЪКЯНјШыЛњЦїбЇЯАФЃаЭжаЕФЪфШыЃЌЛњЦїбЇЯАдђИКд№ДгЭМЯёжаЪЖБ№ГіЯрЙиЕФФЃЪНЁЃМЦЫуЛњЪгОѕЯрЙиЕФгІгУЗЧГЃЕФЖрЃЌР§ШчАйЖШЪЖЭМЁЂЪжаДзжЗћЪЖБ№ЁЂГЕХЦЪЖБ№ЕШЕШгІгУЁЃетИіСьгђЪЧгІгУЧАОАЗЧГЃЛ№ШШЕФЃЌЭЌЪБвВЪЧбаОПЕФШШУХЗНЯђЁЃЫцзХЛњЦїбЇЯАЕФаТСьгђЩюЖШбЇЯАЕФЗЂеЙЃЌДѓДѓДйНјСЫМЦЫуЛњЭМЯёЪЖБ№ЕФаЇЙћЃЌвђДЫЮДРДМЦЫуЛњЪгОѕНчЕФЗЂеЙЧАОАВЛПЩЙРСПЁЃ
гявєЪЖБ№
гявєЪЖБ№=гявєДІРэ+ЛњЦїбЇЯАЁЃгявєЪЖБ№ОЭЪЧвєЦЕДІРэММЪѕгыЛњЦїбЇЯАЕФНсКЯЁЃгявєЪЖБ№ММЪѕвЛАуВЛЛсЕЅЖРЪЙгУЃЌвЛАуЛсНсКЯздШЛгябдДІРэЕФЯрЙиММЪѕЁЃФПЧАЕФЯрЙигІгУгаЦЛЙћЕФгявєжњЪжsiriЕШЁЃ
здШЛгябдДІРэ
здШЛгябдДІРэ=ЮФБОДІРэ+ЛњЦїбЇЯАЁЃздШЛгябдДІРэММЪѕжївЊЪЧШУЛњЦїРэНтШЫРрЕФгябдЕФвЛУХСьгђЁЃдкздШЛгябдДІРэММЪѕжаЃЌДѓСПЪЙгУСЫБрвыдРэЯрЙиЕФММЪѕЃЌР§ШчДЪЗЈЗжЮіЃЌгяЗЈЗжЮіЕШЕШЃЌГ§ДЫжЎЭтЃЌдкРэНтетИіВуУцЃЌдђЪЙгУСЫгявхРэНтЃЌЛњЦїбЇЯАЕШММЪѕЁЃзїЮЊЮЈвЛгЩШЫРрздЩэДДдьЕФЗћКХЃЌздШЛгябдДІРэвЛжБЪЧЛњЦїбЇЯАНчВЛЖЯбаОПЕФЗНЯђЁЃАДееАйЖШЛњЦїбЇЯАзЈМвгрПЕФЫЕЗЈЁАЬ§гыПДЃЌЫЕАзСЫОЭЪЧАЂУЈКЭАЂЙЗЖМЛсЕФЃЌЖјжЛгагябдВХЪЧШЫРрЖРгаЕФЁБЁЃШчКЮРћгУЛњЦїбЇЯАММЪѕНјааздШЛгябдЕФЕФЩюЖШРэНтЃЌвЛжБЪЧЙЄвЕКЭбЇЪѕНчЙизЂЕФНЙЕуЁЃ
ПЩвдПДГіЛњЦїбЇЯАдкжкЖрСьгђЕФЭтбгКЭгІгУЁЃЛњЦїбЇЯАММЪѕЕФЗЂеЙДйЪЙСЫКмЖржЧФмСьгђЕФНјВНЃЌИФЩЦзХЮвУЧЕФЩњЛюЁЃ
3.ЛњЦїбЇЯАЕФЗНЗЈ
ЃЈ1ЃЉЛиЙщЫуЗЈ
дкДѓВПЗжЛњЦїбЇЯАПЮГЬжаЃЌЛиЙщЫуЗЈЖМЪЧНщЩмЕФЕквЛИіЫуЗЈЁЃдвђгаСНИіЃКвЛ.ЛиЙщЫуЗЈБШНЯМђЕЅЃЌНщЩмЫќПЩвдШУШЫЦНЛЌЕиДгЭГМЦбЇЧЈвЦЕНЛњЦїбЇЯАжаЁЃЖў.ЛиЙщЫуЗЈЪЧКѓУцШєИЩЧПДѓЫуЗЈЕФЛљЪЏЃЌШчЙћВЛРэНтЛиЙщЫуЗЈЃЌЮоЗЈбЇЯАФЧаЉЧПДѓЕФЫуЗЈЁЃЛиЙщЫуЗЈгаСНИіживЊЕФзгРрЃКМДЯпадЛиЙщКЭТпМЛиЙщЁЃ
ЯпадЛиЙщЃЌвВОЭЪЧЁАШчКЮФтКЯГівЛЬѕжБЯпзюМбЦЅХфЮвЫљгаЕФЪ§ОнЃПЁБ
вЛАуЪЙгУЁАзюаЁЖўГЫЗЈЁБРДЧѓНтЁЃЁАзюаЁЖўГЫЗЈЁБЕФЫМЯыЪЧетбљЕФЃЌМйЩшЮвУЧФтКЯГіЕФжБЯпДњБэЪ§ОнЕФецЪЕжЕЃЌЖјЙлВтЕНЕФЪ§ОнДњБэгЕгаЮѓВюЕФжЕЁЃЮЊСЫОЁПЩФмМѕаЁЮѓВюЕФгАЯьЃЌашвЊЧѓНтвЛЬѕжБЯпЪЙЫљгаЮѓВюЕФЦНЗНКЭзюаЁЁЃзюаЁЖўГЫЗЈНЋзюгХЮЪЬтзЊЛЏЮЊЧѓКЏЪ§МЋжЕЮЪЬтЁЃКЏЪ§МЋжЕдкЪ§бЇЩЯЮвУЧвЛАуЛсВЩгУЧѓЕМЪ§ЮЊ0ЕФЗНЗЈЁЃЕЋетжжзіЗЈВЂВЛЪЪКЯМЦЫуЛњЃЌПЩФмЧѓНтВЛГіРДЃЌвВПЩФмМЦЫуСПЬЋДѓЁЃ
МЦЫуЛњПЦбЇНчзЈУХгавЛИібЇПЦНаЁАЪ§жЕМЦЫуЁБЃЌзЈУХгУРДЬсЩ§МЦЫуЛњНјааИїРрМЦЫуЪБЕФзМШЗадКЭаЇТЪЮЪЬтЁЃР§ШчЃЌжјУћЕФЁАЬнЖШЯТНЕЁБвдМАЁАХЃЖйЗЈЁБОЭЪЧЪ§жЕМЦЫужаЕФОЕфЫуЗЈЃЌвВЗЧГЃЪЪКЯРДДІРэЧѓНтКЏЪ§МЋжЕЕФЮЪЬтЁЃЬнЖШЯТНЕЗЈЪЧНтОіЛиЙщФЃаЭжазюМђЕЅЧвгааЇЕФЗНЗЈжЎвЛЁЃДгбЯИёвтвхЩЯРДЫЕЃЌгЩгкКѓЮФжаЕФЩёОЭјТчКЭЭЦМіЫуЗЈжаЖМгаЯпадЛиЙщЕФвђзгЃЌвђДЫЬнЖШЯТНЕЗЈдкКѓУцЕФЫуЗЈЪЕЯжжавВгагІгУЁЃ
ТпМЛиЙщЪЧвЛжжгыЯпадЛиЙщЗЧГЃРрЫЦЕФЫуЗЈЃЌЕЋЪЧЃЌДгБОжЪЩЯНВЃЌЯпаЭЛиЙщДІРэЕФЮЪЬтРраЭгыТпМЛиЙщВЛвЛжТЁЃЯпадЛиЙщДІРэЕФЪЧЪ§жЕЮЪЬтЃЌвВОЭЪЧзюКѓдЄВтГіЕФНсЙћЪЧЪ§зжЃЌР§ШчЗПМлЁЃЖјТпМЛиЙщЪєгкЗжРрЫуЗЈЃЌвВОЭЪЧЫЕЃЌТпМЛиЙщдЄВтНсЙћЪЧРыЩЂЕФЗжРрЃЌР§ШчХаЖЯетЗтгЪМўЪЧЗёЪЧРЌЛјгЪМўЃЌвдМАгУЛЇЪЧЗёЛсЕуЛїДЫЙуИцЕШЕШЁЃ
ЃЈ2ЃЉЩёОЭјТч
ЩёОЭјТч(вВГЦжЎЮЊШЫЙЄЩёОЭјТчЃЌANN)ЫуЗЈЪЧ80ФъДњЛњЦїбЇЯАНчЗЧГЃСїааЕФЫуЗЈЃЌВЛЙ§дк90ФъДњжаЭОЫЅТфЁЃЯждкЃЌаЏзХЁАЩюЖШбЇЯАЁБжЎЪЦЃЌЩёОЭјТчжизАЙщРДЃЌжиаТГЩЮЊзюЧПДѓЕФЛњЦїбЇЯАЫуЗЈжЎвЛЁЃ
ЩёОЭјТчЕФЕЎЩњЦ№дДгкЖдДѓФдЙЄзїЛњРэЕФбаОПЁЃдчЦкЩњЮяНчбЇепУЧЪЙгУЩёОЭјТчРДФЃФтДѓФдЁЃЛњЦїбЇЯАЕФбЇепУЧЪЙгУЩёОЭјТчНјааЛњЦїбЇЯАЕФЪЕбщЃЌЗЂЯждкЪгОѕгыгявєЕФЪЖБ№ЩЯаЇЙћЖМЯрЕБКУЁЃдкBPЫуЗЈ(МгЫйЩёОЭјТчбЕСЗЙ§ГЬЕФЪ§жЕЫуЗЈ)ЕЎЩњвдКѓЃЌЩёОЭјТчЕФЗЂеЙНјШыСЫвЛИіШШГБЁЃBPЫуЗЈЕФЗЂУїШЫжЎвЛЪЧЧАУцНщЩмЕФЛњЦїбЇЯАДѓХЃGeoffrey
Hinton(ЭМ1жаЕФжаМфеп)ЁЃ
ОпЬхЫЕРДЃЌЩёОЭјТчЕФбЇЯАЛњРэЪЧЪВУДЃПМђЕЅРДЫЕЃЌОЭЪЧЗжНтгыећКЯЁЃдкжјУћЕФHubel-WieselЪдбщжаЃЌбЇепУЧбаОПУЈЕФЪгОѕЗжЮіЛњРэЪЧетбљЕФЁЃ
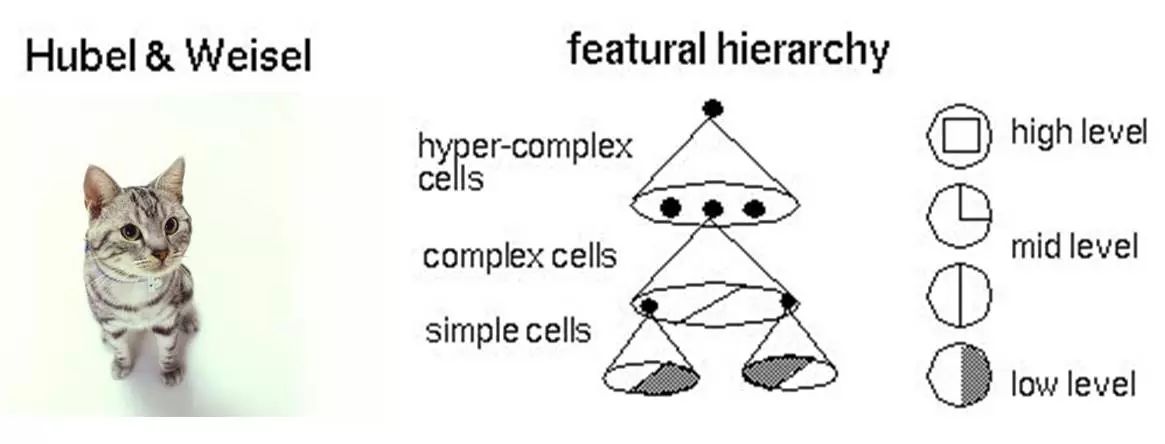
ЭМ6 Hubel-WieselЪдбщгыДѓФдЪгОѕЛњРэ
БШЗНЫЕЃЌвЛИіе§ЗНаЮЃЌЗжНтЮЊЫФИіелЯпНјШыЪгОѕДІРэЕФЯТвЛВужаЁЃЫФИіЩёОдЊЗжБ№ДІРэвЛИіелЯпЁЃУПИіелЯпдйМЬајБЛЗжНтЮЊСНЬѕжБЯпЃЌУПЬѕжБЯпдйБЛЗжНтЮЊКкАзСНИіУцЁЃгкЪЧЃЌвЛИіИДдгЕФЭМЯёБфГЩСЫДѓСПЕФЯИНкНјШыЩёОдЊЃЌЩёОдЊДІРэвдКѓдйНјааећКЯЃЌзюКѓЕУГіСЫПДЕНЕФЪЧе§ЗНаЮЕФНсТлЁЃетОЭЪЧДѓФдЪгОѕЪЖБ№ЕФЛњРэЃЌвВЪЧЩёОЭјТчЙЄзїЕФЛњРэЁЃ
ШУЮвУЧПДвЛИіМђЕЅЕФЩёОЭјТчЕФТпММмЙЙЁЃдкетИіЭјТчжаЃЌЗжГЩЪфШыВуЃЌвўВиВуЃЌКЭЪфГіВуЁЃЪфШыВуИКд№НгЪеаХКХЃЌвўВиВуИКд№ЖдЪ§ОнЕФЗжНтгыДІРэЃЌзюКѓЕФНсЙћБЛећКЯЕНЪфГіВуЁЃУПВужаЕФвЛИідВДњБэвЛИіДІРэЕЅдЊЃЌПЩвдШЯЮЊЪЧФЃФтСЫвЛИіЩёОдЊЃЌШєИЩИіДІРэЕЅдЊзщГЩСЫвЛИіВуЃЌШєИЩИіВудйзщГЩСЫвЛИіЭјТчЃЌвВОЭЪЧ'ЩёОЭјТч'ЁЃ
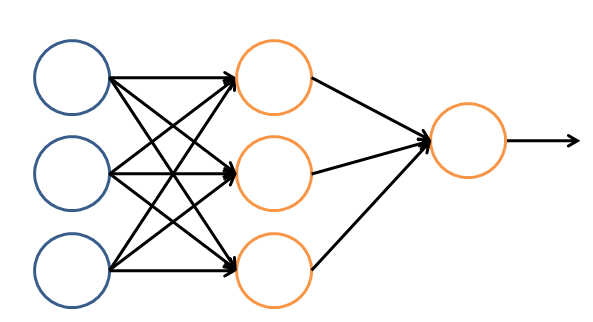
ЭМ7 ЩёОЭјТчЕФТпММмЙЙ
дкЩёОЭјТчжаЃЌУПИіДІРэЕЅдЊЪТЪЕЩЯОЭЪЧвЛИіТпМЛиЙщФЃаЭЃЌТпМЛиЙщФЃаЭНгЪеЩЯВуЕФЪфШыЃЌАбФЃаЭЕФдЄВтНсЙћзїЮЊЪфГіДЋЪфЕНЯТвЛИіВуДЮЁЃЭЈЙ§етбљЕФЙ§ГЬЃЌЩёОЭјТчПЩвдЭъГЩЗЧГЃИДдгЕФЗЧЯпадЗжРрЁЃ
ЯТЭМЛсбнЪОЩёОЭјТчдкЭМЯёЪЖБ№СьгђЕФвЛИіжјУћгІгУЃЌетИіГЬађНазіLeNetЃЌЪЧвЛИіЛљгкЖрИівўВуЙЙНЈЕФЩёОЭјТчЁЃЭЈЙ§LeNetПЩвдЪЖБ№ЖржжЪжаДЪ§зжЃЌВЂЧвДяЕНКмИпЕФЪЖБ№ОЋЖШгыгЕгаНЯКУЕФТГАєадЁЃ

ЭМ8 LeeNetЕФаЇЙћеЙЪО
гвЯТЗНЕФЗНаЮжаЯдЪОЕФЪЧЪфШыМЦЫуЛњЕФЭМЯёЃЌЗНаЮЩЯЗНЕФКьЩЋзжбљЁАanswerЁБКѓУцЯдЪОЕФЪЧМЦЫуЛњЕФЪфГіЁЃзѓБпЕФШ§ЬѕЪњжБЕФЭМЯёСаЯдЪОЕФЪЧЩёОЭјТчжаШ§ИівўВиВуЕФЪфГіЃЌПЩвдПДГіЃЌЫцзХВуДЮЕФВЛЖЯЩюШыЃЌдНЩюЕФВуДЮДІРэЕФЯИНкдНЕЭЃЌР§ШчВу3ЛљБОДІРэЕФЖМвбОЪЧЯпЕФЯИНкСЫЁЃLeNetЕФЗЂУїШЫОЭЪЧЧАЮФНщЩмЙ§ЕФЛњЦїбЇЯАЕФДѓХЃYann
LeCun(ЭМ1гвеп)ЁЃ
НјШы90ФъДњЃЌЩёОЭјТчЕФЗЂеЙНјШыСЫвЛИіЦПОБЦкЁЃЦфжївЊдвђЪЧОЁЙмгаBPЫуЗЈЕФМгЫйЃЌЩёОЭјТчЕФбЕСЗЙ§ГЬШдШЛКмРЇФбЁЃвђДЫ90ФъДњКѓЦкжЇГжЯђСПЛњ(SVM)ЫуЗЈШЁДњСЫЩёОЭјТчЕФЕиЮЛЁЃ
ЃЈ3ЃЉSVMЃЈжЇГжЯђСПЛњЃЉ
жЇГжЯђСПЛњЫуЗЈЪЧЕЎЩњгкЭГМЦбЇЯАНчЃЌЭЌЪБдкЛњЦїбЇЯАНчДѓЗХЙтВЪЕФОЕфЫуЗЈЁЃ
жЇГжЯђСПЛњЫуЗЈДгФГжжвтвхЩЯРДЫЕЪЧТпМЛиЙщЫуЗЈЕФЧПЛЏЃКЭЈЙ§ИјгшТпМЛиЙщЫуЗЈИќбЯИёЕФгХЛЏЬѕМўЃЌжЇГжЯђСПЛњЫуЗЈПЩвдЛёЕУБШТпМЛиЙщИќКУЕФЗжРрНчЯпЁЃЕЋЪЧШчЙћУЛгаФГРрКЏЪ§ММЪѕЃЌдђжЇГжЯђСПЛњЫуЗЈзюЖрЫуЪЧвЛжжИќКУЕФЯпадЗжРрММЪѕЁЃ
ЕЋЪЧЃЌЭЈЙ§ИњИпЫЙЁАКЫЁБЕФНсКЯЃЌжЇГжЯђСПЛњПЩвдБэДяГіЗЧГЃИДдгЕФЗжРрНчЯпЃЌДгЖјДяГЩКмКУЕФЕФЗжРраЇЙћЁЃЁАКЫЁБЪТЪЕЩЯОЭЪЧвЛжжЬиЪтЕФКЏЪ§ЃЌзюЕфаЭЕФЬиеїОЭЪЧПЩвдНЋЕЭЮЌЕФПеМфгГЩфЕНИпЮЌЕФПеМфЁЃ
Р§ШчЯТЭМЫљЪОЃК
ЭМ9 жЇГжЯђСПЛњЭМР§
ЮвУЧШчКЮдкЖўЮЌЦНУцЛЎЗжГівЛИідВаЮЕФЗжРрНчЯпЃПдкЖўЮЌЦНУцПЩФмЛсКмРЇФбЃЌЕЋЪЧЭЈЙ§ЁАКЫЁБПЩвдНЋЖўЮЌПеМфгГЩфЕНШ§ЮЌПеМфЃЌШЛКѓЪЙгУвЛИіЯпадЦНУцОЭПЩвдДяГЩРрЫЦаЇЙћЁЃвВОЭЪЧЫЕЃЌЖўЮЌЦНУцЛЎЗжГіЕФЗЧЯпадЗжРрНчЯпПЩвдЕШМлгкШ§ЮЌЦНУцЕФЯпадЗжРрНчЯпЁЃгкЪЧЃЌЮвУЧПЩвдЭЈЙ§дкШ§ЮЌПеМфжаНјааМђЕЅЕФЯпадЛЎЗжОЭПЩвдДяЕНдкЖўЮЌЦНУцжаЕФЗЧЯпадЛЎЗжаЇЙћЁЃ
ЭМ10 Ш§ЮЌПеМфЕФЧаИю
жЇГжЯђСПЛњЪЧвЛжжЪ§бЇГЩЗжКмХЈЕФЛњЦїбЇЯАЫуЗЈЃЈЯрЖдЕФЃЌЩёОЭјТчдђгаЩњЮяПЦбЇГЩЗжЃЉЁЃдкЫуЗЈЕФКЫаФВНжшжаЃЌгавЛВНжЄУїЃЌМДНЋЪ§ОнДгЕЭЮЌгГЩфЕНИпЮЌВЛЛсДјРДзюКѓМЦЫуИДдгадЕФЬсЩ§ЁЃгкЪЧЃЌЭЈЙ§жЇГжЯђСПЛњЫуЗЈЃЌМШПЩвдБЃГжМЦЫуаЇТЪЃЌгжПЩвдЛёЕУЗЧГЃКУЕФЗжРраЇЙћЁЃвђДЫжЇГжЯђСПЛњдк90ФъДњКѓЦквЛжБеМОнзХЛњЦїбЇЯАжазюКЫаФЕФЕиЮЛЃЌЛљБОШЁДњСЫЩёОЭјТчЫуЗЈЁЃжБЕНЯждкЩёОЭјТчНшзХЩюЖШбЇЯАжиаТаЫЦ№ЃЌСНепжЎМфВХгжЗЂЩњСЫЮЂУюЕФЦНКтзЊБфЁЃ
ЃЈ4ЃЉОлРрЫуЗЈ
ЧАУцЕФЫуЗЈжаЕФвЛИіЯджјЬиеїОЭЪЧЮвЕФбЕСЗЪ§ОнжаАќКЌСЫБъЧЉЃЌбЕСЗГіЕФФЃаЭПЩвдЖдЦфЫћЮДжЊЪ§ОндЄВтБъЧЉЁЃдкЯТУцЕФЫуЗЈжаЃЌбЕСЗЪ§ОнЖМЪЧВЛКЌБъЧЉЕФЃЌЖјЫуЗЈЕФФПЕФдђЪЧЭЈЙ§бЕСЗЃЌЭЦВтГіетаЉЪ§ОнЕФБъЧЉЁЃетРрЫуЗЈгавЛИіЭГГЦЃЌМДЮоМрЖНЫуЗЈ(ЧАУцгаБъЧЉЕФЪ§ОнЕФЫуЗЈдђЪЧгаМрЖНЫуЗЈ)ЁЃЮоМрЖНЫуЗЈжазюЕфаЭЕФДњБэОЭЪЧОлРрЫуЗЈЁЃ
ШУЮвУЧЛЙЪЧФУвЛИіЖўЮЌЕФЪ§ОнРДЫЕЃЌФГвЛИіЪ§ОнАќКЌСНИіЬиеїЁЃЮвЯЃЭћЭЈЙ§ОлРрЫуЗЈЃЌИјЫћУЧжаВЛЭЌЕФжжРрДђЩЯБъЧЉЃЌЮвИУдѕУДзіФиЃПМђЕЅРДЫЕЃЌОлРрЫуЗЈОЭЪЧМЦЫужжШКжаЕФОрРыЃЌИљОнОрРыЕФдЖНќНЋЪ§ОнЛЎЗжЮЊЖрИізхШКЁЃ
ОлРрЫуЗЈжазюЕфаЭЕФДњБэОЭЪЧK-MeansЫуЗЈЁЃ
ЃЈ5ЃЉНЕЮЌЫуЗЈ
НЕЮЌЫуЗЈвВЪЧвЛжжЮоМрЖНбЇЯАЫуЗЈЃЌЦфжївЊЬиеїЪЧНЋЪ§ОнДгИпЮЌНЕЕЭЕНЕЭЮЌВуДЮЁЃдкетРяЃЌЮЌЖШЦфЪЕБэЪОЕФЪЧЪ§ОнЕФЬиеїСПЕФДѓаЁЁЃ
Р§ШчЃЌЗПМлАќКЌЗПзгЕФГЄЁЂПэЁЂУцЛ§гыЗПМфЪ§СПЫФИіЬиеїЃЌвВОЭЪЧЮЌЖШЮЊ4ЮЌЕФЪ§ОнЁЃПЩвдПДГіРДЃЌГЄгыПэЪТЪЕЩЯгыУцЛ§БэЪОЕФаХЯЂжиЕўСЫЃЌР§ШчУцЛ§=ГЄ
ЁС ПэЁЃЭЈЙ§НЕЮЌЫуЗЈЮвУЧОЭПЩвдШЅГ§ШпграХЯЂЃЌНЋЬиеїМѕЩйЮЊУцЛ§гыЗПМфЪ§СПСНИіЬиеїЃЌМДДг4ЮЌЕФЪ§ОнбЙЫѕЕН2ЮЌЁЃгкЪЧЮвУЧНЋЪ§ОнДгИпЮЌНЕЕЭЕНЕЭЮЌЃЌВЛНіРћгкБэЪОЃЌЭЌЪБдкМЦЫуЩЯвВФмДјРДМгЫйЁЃ
НЕЮЌЫуЗЈЕФжївЊзїгУЪЧбЙЫѕЪ§ОнгыЬсЩ§ЛњЦїбЇЯАЦфЫћЫуЗЈЕФаЇТЪЁЃЭЈЙ§НЕЮЌЫуЗЈЃЌПЩвдНЋОпгаМИЧЇИіЬиеїЕФЪ§ОнбЙЫѕжСШєИЩИіЬиеїЁЃСэЭтЃЌНЕЮЌЫуЗЈЕФСэвЛИіКУДІЪЧЪ§ОнЕФПЩЪгЛЏЃЌР§ШчНЋ5ЮЌЕФЪ§ОнбЙЫѕжС2ЮЌЃЌШЛКѓПЩвдгУЖўЮЌЦНУцРДПЩЪгЁЃНЕЮЌЫуЗЈЕФжївЊДњБэЪЧPCAЫуЗЈ(МДжїГЩЗжЗжЮіЫуЗЈ)ЁЃ
ЃЈ6ЃЉЭЦМіЫуЗЈ
ЭЦМіЫуЗЈЪЧФПЧАвЕНчЗЧГЃЛ№ЕФвЛжжЫуЗЈЃЌдкЕчЩЬНчЃЌШчбЧТэбЗЃЌЬьУЈЃЌОЉЖЋЕШЕУЕНСЫЙуЗКЕФдЫгУЁЃЭЦМіЫуЗЈЕФжївЊЬиеїОЭЪЧПЩвдздЖЏЯђгУЛЇЭЦМіЫћУЧзюИааЫШЄЕФЖЋЮїЃЌДгЖјдіМгЙКТђТЪЃЌЬсЩ§аЇвцЁЃ
ЭЦМіЫуЗЈгаСНИіжївЊЕФРрБ№ЃК
вЛРрЪЧЛљгкЮяЦЗФкШнЕФЭЦМіЃЌЪЧНЋгыгУЛЇЙКТђЕФФкШнНќЫЦЕФЮяЦЗЭЦМіИјгУЛЇЃЌетбљЕФЧАЬсЪЧУПИіЮяЦЗЖМЕУгаШєИЩИіБъЧЉЃЌвђДЫВХПЩвдевГігыгУЛЇЙКТђЮяЦЗРрЫЦЕФЮяЦЗЃЌетбљЭЦМіЕФКУДІЪЧЙиСЊГЬЖШНЯДѓЃЌЕЋЪЧгЩгкУПИіЮяЦЗЖМашвЊЬљБъЧЉЃЌвђДЫЙЄзїСПНЯДѓЁЃ
СэвЛРрЪЧЛљгкгУЛЇЯрЫЦЖШЕФЭЦМіЃЌдђЪЧНЋгыФПБъгУЛЇаЫШЄЯрЭЌЕФЦфЫћгУЛЇЙКТђЕФЖЋЮїЭЦМіИјФПБъгУЛЇЃЌР§ШчаЁAРњЪЗЩЯТђСЫЮяЦЗBКЭCЃЌОЙ§ЫуЗЈЗжЮіЃЌЗЂЯжСэвЛИігыаЁAНќЫЦЕФгУЛЇаЁDЙКТђСЫЮяЦЗEЃЌгкЪЧНЋЮяЦЗEЭЦМіИјаЁAЁЃ
СНРрЭЦМіЖМгаИїздЕФгХШБЕуЃЌдквЛАуЕФЕчЩЬгІгУжаЃЌвЛАуЪЧСНРрЛьКЯЪЙгУЁЃЭЦМіЫуЗЈжазюгаУћЕФЫуЗЈОЭЪЧаЭЌЙ§ТЫЫуЗЈЁЃ
ЃЈ7ЃЉЦфЫћ
Г§СЫвдЩЯЫуЗЈжЎЭтЃЌЛњЦїбЇЯАНчЛЙгаЦфЫћЕФШчИпЫЙХаБ№ЃЌЦгЫиБДвЖЫЙЃЌОіВпЪїЕШЕШЫуЗЈЁЃЕЋЪЧЩЯУцСаЕФСљИіЫуЗЈЪЧЪЙгУзюЖрЃЌгАЯьзюЙуЃЌжжРрзюШЋЕФЕфаЭЁЃЛњЦїбЇЯАНчЕФвЛИіЬиЩЋОЭЪЧЫуЗЈжкЖрЃЌЗЂеЙАйЛЈЦыЗХЁЃ
ЯТУцзівЛИізмНсЃЌАДеебЕСЗЕФЪ§ОнгаЮоБъЧЉЃЌПЩвдНЋЩЯУцЫуЗЈЗжЮЊМрЖНбЇЯАЫуЗЈКЭЮоМрЖНбЇЯАЫуЗЈЃЌЕЋЭЦМіЫуЗЈНЯЮЊЬиЪтЃЌМШВЛЪєгкМрЖНбЇЯАЃЌвВВЛЪєгкЗЧМрЖНбЇЯАЃЌЪЧЕЅЖРЕФвЛРрЁЃ
МрЖНбЇЯАЫуЗЈЃКЯпадЛиЙщЃЌТпМЛиЙщЃЌЩёОЭјТчЃЌSVM
ЮоМрЖНбЇЯАЫуЗЈЃКОлРрЫуЗЈЃЌНЕЮЌЫуЗЈ
ЬиЪтЫуЗЈЃКЭЦМіЫуЗЈ
Г§СЫетаЉЫуЗЈвдЭтЃЌгавЛаЉЫуЗЈЕФУћзждкЛњЦїбЇЯАСьгђжавВОГЃГіЯжЁЃЕЋЫћУЧБОЩэВЂВЛЫуЪЧвЛИіЛњЦїбЇЯАЫуЗЈЃЌЖјЪЧЮЊСЫНтОіФГИізгЮЪЬтЖјЕЎЩњЕФЁЃФуПЩвдРэНтЫћУЧЮЊвдЩЯЫуЗЈЕФзгЫуЗЈЃЌгУгкДѓЗљЖШЬсИпбЕСЗЙ§ГЬЁЃЦфжаЕФДњБэгаЃКЬнЖШЯТНЕЗЈЃЌжївЊдЫгУдкЯпаЭЛиЙщЃЌТпМЛиЙщЃЌЩёОЭјТчЃЌЭЦМіЫуЗЈжаЃЛХЃЖйЗЈЃЌжївЊдЫгУдкЯпаЭЛиЙщжаЃЛBPЫуЗЈЃЌжївЊдЫгУдкЩёОЭјТчжаЃЛSMOЫуЗЈЃЌжївЊдЫгУдкSVMжаЁЃ
5.ЛњЦїбЇЯАЕФгІгУЁЊЁЊДѓЪ§Он
ЫЕЭъЛњЦїбЇЯАЕФЗНЗЈЃЌЯТУцвЊЬИвЛЬИЛњЦїбЇЯАЕФгІгУСЫЁЃЮовЩЃЌдк2010ФъвдЧАЃЌЛњЦїбЇЯАЕФгІгУдкФГаЉЬиЖЈСьгђЗЂЛгСЫОоДѓЕФзїгУЃЌШчГЕХЦЪЖБ№ЃЌЭјТчЙЅЛїЗРЗЖЃЌЪжаДзжЗћЪЖБ№ЕШЕШЁЃЕЋЪЧЃЌДг2010ФъвдКѓЃЌЫцзХДѓЪ§ОнИХФюЕФаЫЦ№ЃЌЛњЦїбЇЯАДѓСПЕФгІгУЖМгыДѓЪ§ОнИпЖШёюКЯЃЌМИКѕПЩвдШЯЮЊДѓЪ§ОнЪЧЛњЦїбЇЯАгІгУЕФзюМбГЁОАЁЃ
ЦЉШчЃЌЕЋЗВФуФмевЕНЕФНщЩмДѓЪ§ОнФЇСІЕФЮФеТЃЌЖМЛсЫЕДѓЪ§ОнШчКЮзМШЗзМШЗдЄВтЕНСЫФГаЉЪТЁЃР§ШчОЕфЕФGoogleРћгУДѓЪ§ОндЄВтСЫH1N1дкУРЙњФГаЁеђЕФБЌЗЂЁЃ
ЭМ11 GoogleГЩЙІдЄВтH1N1
АйЖШдЄВт2014ФъЪРНчБЃЌДгЬдЬШќЕНОіШќШЋВПдЄВте§ШЗЁЃ
ЭМ12 АйЖШЪРНчБГЩЙІдЄВтСЫЫљгаБШШќНсЙћ
етаЉЪЕдкЬЋЩёЦцСЫЃЌФЧУДОПОЙЪЧЪВУДдвђЕМжТДѓЪ§ОнОпгаетаЉФЇСІЕФФиЃПМђЕЅРДЫЕЃЌОЭЪЧЛњЦїбЇЯАММЪѕЁЃе§ЪЧЛљгкЛњЦїбЇЯАММЪѕЕФгІгУЃЌЪ§ОнВХФмЗЂЛгЦфФЇСІЁЃ
ЛњЦїбЇЯАгыДѓЪ§ОнНєУмСЊЯЕЁЃЕЋЪЧЃЌБиаыЧхабЕФШЯЪЖЕНЃЌДѓЪ§ОнВЂВЛЕШЭЌгкЛњЦїбЇЯАЃЌЭЌРэЃЌЛњЦїбЇЯАвВВЛЕШЭЌгкДѓЪ§ОнЁЃДѓЪ§ОнжаАќКЌгаЗжВМЪНМЦЫуЃЌФкДцЪ§ОнПтЃЌЖрЮЌЗжЮіЕШЕШЖржжММЪѕЁЃЕЅДгЗжЮіЗНЗЈРДПДЃЌДѓЪ§ОнвВАќКЌвдЯТЫФжжЗжЮіЗНЗЈЃК
1.ДѓЪ§ОнЃЌаЁЗжЮіЃКМДЪ§ОнВжПтСьгђЕФOLAPЗжЮіЫМТЗЃЌвВОЭЪЧЖрЮЌЗжЮіЫМЯыЁЃ
2.ДѓЪ§ОнЃЌДѓЗжЮіЃКетИіДњБэЕФОЭЪЧЪ§ОнЭкОђгыЛњЦїбЇЯАЗжЮіЗЈЁЃ
3.СїЪНЗжЮіЃКетИіжївЊжИЕФЪЧЪТМўЧ§ЖЏМмЙЙЁЃ
4.ВщбЏЗжЮіЃКОЕфДњБэЪЧNoSQLЪ§ОнПтЁЃ
вВОЭЪЧЫЕЃЌЛњЦїбЇЯАНіНіЪЧДѓЪ§ОнЗжЮіжаЕФвЛжжЖјвбЁЃОЁЙмЛњЦїбЇЯАЕФвЛаЉНсЙћОпгаКмДѓЕФФЇСІЃЌдкФГжжГЁКЯЯТЪЧДѓЪ§ОнМлжЕзюКУЕФЫЕУїЁЃЕЋетВЂВЛДњБэЛњЦїбЇЯАЪЧДѓЪ§ОнЯТЕФЮЈвЛЕФЗжЮіЗНЗЈЁЃ
дкДѓЪ§ОнЕФЪБДњЃЌгаКУЖргХЪЦДйЪЙЛњЦїбЇЯАФмЙЛгІгУИќЙуЗКЁЃР§ШчЫцзХЮяСЊЭјКЭвЦЖЏЩшБИЕФЗЂеЙЃЌЮвУЧгЕгаЕФЪ§ОндНРДдНЖрЃЌжжРрвВАќРЈЭМЦЌЁЂЮФБОЁЂЪгЦЕЕШЗЧНсЙЙЛЏЪ§ОнЃЌетЪЙЕУЛњЦїбЇЯАФЃаЭПЩвдЛёЕУдНРДдНЖрЕФЪ§ОнЁЃЭЌЪБДѓЪ§ОнММЪѕжаЕФЗжВМЪНМЦЫуMap-ReduceЪЙЕУЛњЦїбЇЯАЕФЫйЖШдНРДдНПьЃЌПЩвдИќЗНБуЕФЪЙгУЁЃжжжжгХЪЦЪЙЕУдкДѓЪ§ОнЪБДњЃЌЛњЦїбЇЯАЕФгХЪЦПЩвдЕУЕНзюМбЕФЗЂЛгЁЃ
6.ЛњЦїбЇЯАЕФзгРрЁЊЁЊЩюЖШбЇЯА
НќРДЃЌЛњЦїбЇЯАЕФЗЂеЙВњЩњСЫвЛИіаТЕФЗНЯђЃЌМДЁАЩюЖШбЇЯАЁБЁЃ
ЫфШЛЩюЖШбЇЯАетЫФзжЬ§Ц№РДЦФЮЊИпДѓЩЯЃЌЕЋЦфРэФюШДЗЧГЃМђЕЅЃЌОЭЪЧДЋЭГЕФЩёОЭјТчЗЂеЙЕНСЫЖрвўВиВуЕФЧщПіЁЃ
дкЩЯЮФНщЩмЙ§ЃЌздДг90ФъДњвдКѓЃЌЩёОЭјТчвбОЯћМХСЫвЛЖЮЪБМфЁЃЕЋЪЧBPЫуЗЈЕФЗЂУїШЫGeoffrey
HintonвЛжБУЛгаЗХЦњЖдЩёОЭјТчЕФбаОПЁЃгЩгкЩёОЭјТчдквўВиВуРЉДѓЕНСНИівдЩЯЃЌЦфбЕСЗЫйЖШОЭЛсЗЧГЃТ§ЃЌвђДЫЪЕгУадвЛжБЕЭгкжЇГжЯђСПЛњЁЃ2006ФъЃЌGeoffrey
HintonдкПЦбЇдгжОЁЖScienceЁЗЩЯЗЂБэСЫвЛЦЊЮФеТЃЌТлжЄСЫСНИіЙлЕуЃК
1.ЖрвўВуЕФЩёОЭјТчОпгагХвьЕФЬиеїбЇЯАФмСІЃЌбЇЯАЕУЕНЕФЬиеїЖдЪ§ОнгаИќБОжЪЕФПЬЛЃЌДгЖјгаРћгкПЩЪгЛЏЛђЗжРрЃЛ
2.ЩюЖШЩёОЭјТчдкбЕСЗЩЯЕФФбЖШЃЌПЩвдЭЈЙ§ЁАж№ВуГѕЪМЛЏЁБ РДгааЇПЫЗўЁЃЁЁ

ЭМ13 Geoffrey HintonгыЫћЕФбЇЩњдкScienceЩЯЗЂБэЮФеТ
ЭЈЙ§етбљЕФЗЂЯжЃЌВЛНіНтОіСЫЩёОЭјТчдкМЦЫуЩЯЕФФбЖШЃЌЭЌЪБвВЫЕУїСЫЩюВуЩёОЭјТчдкбЇЯАЩЯЕФгХвьадЁЃДгДЫЃЌЩёОЭјТчжиаТГЩЮЊСЫЛњЦїбЇЯАНчжаЕФжїСїЧПДѓбЇЯАММЪѕЁЃЭЌЪБЃЌОпгаЖрИівўВиВуЕФЩёОЭјТчБЛГЦЮЊЩюЖШЩёОЭјТчЃЌЛљгкЩюЖШЩёОЭјТчЕФбЇЯАбаОПГЦжЎЮЊЩюЖШбЇЯАЁЃ
ЮФеТПЊЭЗЫљСаЕФШ§ЮЛЛњЦїбЇЯАЕФДѓХЃЃЌВЛНіЖМЪЧЛњЦїбЇЯАНчЕФзЈМвЃЌИќЪЧЩюЖШбЇЯАбаОПСьгђЕФЯШЧ§ЁЃвђДЫЃЌЪЙЫћУЧЕЃШЮИїИіДѓаЭЛЅСЊЭјЙЋЫОММЪѕеЦЖцепЕФдвђВЛНідкгкЫћУЧЕФММЪѕЪЕСІЃЌИќдкгкЫћУЧбаОПЕФСьгђЪЧЧАОАЮоЯоЕФЩюЖШбЇЯАММЪѕЁЃ
ФПЧАвЕНчаэЖрЕФЭМЯёЪЖБ№ММЪѕгыгявєЪЖБ№ММЪѕЕФНјВНЖМдДгкЩюЖШбЇЯАЕФЗЂеЙЃЌГ§СЫБОЮФПЊЭЗЫљЬсЕФCortanaЕШгявєжњЪжЃЌЛЙАќРЈвЛаЉЭМЯёЪЖБ№гІгУЃЌЦфжаЕфаЭЕФДњБэОЭЪЧЯТЭМЕФАйЖШЪЖЭМЙІФмЁЃ
ЭМ14 АйЖШЪЖЭМ
ЩюЖШбЇЯАЪєгкЛњЦїбЇЯАЕФзгРрЁЃЛљгкЩюЖШбЇЯАЕФЗЂеЙМЋДѓЕФДйНјСЫЛњЦїбЇЯАЕФЕиЮЛЬсИпЃЌИќНјвЛВНЕиЃЌЭЦЖЏСЫвЕНчЖдЛњЦїбЇЯАИИРрШЫЙЄжЧФмУЮЯыЕФдйДЮжиЪгЁЃ
7.ЛњЦїбЇЯАЕФИИРрЁЊЁЊШЫЙЄжЧФм
ШЫЙЄжЧФмЪЧЛњЦїбЇЯАЕФИИРрЁЃЩюЖШбЇЯАдђЪЧЛњЦїбЇЯАЕФзгРрЁЃШчЙћАбШ§епЕФЙиЯЕгУЭМРДБэУїЕФЛАЃЌдђЪЧЯТЭМЃК
ЭМ15 ЩюЖШбЇЯАЁЂЛњЦїбЇЯАЁЂШЫЙЄжЧФмШ§епЙиЯЕ
змНсЦ№РДЃЌШЫЙЄжЧФмЕФЗЂеЙОРњСЫШчЯТШєИЩНзЖЮЃЌДгдчЦкЕФТпМЭЦРэЃЌЕНжаЦкЕФзЈМвЯЕЭГЃЌетаЉПЦбаНјВНШЗЪЕЪЙЮвУЧРыЛњЦїЕФжЧФмгаЕуНгНќСЫЃЌЕЋЛЙгавЛДѓЖЮОрРыЁЃжБЕНЛњЦїбЇЯАЕЎЩњвдКѓЃЌШЫЙЄжЧФмНчИаОѕжегкевЖдСЫЗНЯђЁЃЛљгкЛњЦїбЇЯАЕФЭМЯёЪЖБ№КЭгявєЪЖБ№дкФГаЉДЙжБСьгђДяЕНСЫИњШЫЯрцЧУРЕФГЬЖШЁЃ
ШЫЙЄжЧФмЕФЗЂеЙПЩФмВЛНіШЁОігкЛњЦїбЇЯАЃЌИќШЁОігкЧАУцЫљНщЩмЕФЩюЖШбЇЯАЃЌЩюЖШбЇЯАММЪѕгЩгкЩюЖШФЃФтСЫШЫРрДѓФдЕФЙЙГЩЃЌдкЪгОѕЪЖБ№гыгявєЪЖБ№ЩЯЯджјадЕФЭЛЦЦСЫдгаЛњЦїбЇЯАММЪѕЕФНчЯоЃЌвђДЫМЋгаПЩФмЪЧеце§ЪЕЯжШЫЙЄжЧФмУЮЯыЕФЙиМќММЪѕЁЃЮоТлЪЧЙШИшДѓФдЛЙЪЧАйЖШДѓФдЃЌЖМЪЧЭЈЙ§КЃСПВуДЮЕФЩюЖШбЇЯАЭјТчЫљЙЙГЩЕФЁЃвВаэНшжњгкЩюЖШбЇЯАММЪѕЃЌдкВЛдЖЕФНЋРДЃЌвЛИіОпгаШЫРржЧФмЕФМЦЫуЛњецЕФгаПЩФмЪЕЯжЁЃ |









