| 编辑推荐: |
本文来自于网络,本文主要介绍了如何使用
OpenCV、Python 和深度学习在图像和视频中实现面部识别,以基于深度识别的面部嵌入。
|
|
Face ID 的兴起带动了一波面部识别技术热潮。本文将介绍如何使用
OpenCV、Python 和深度学习在图像和视频中实现面部识别,以基于深度识别的面部嵌入,实时执行且达到高准确度。
想知道怎样用OpenCV、Python和深度学习进行面部识别吗?
这篇文章首先将简单介绍下基于深度学习的面部识别的工作原理,以及“深度度量学习”(deep metric
learning)的概念。接下来我会帮你安装好面部识别需要的库。最后我们会发现,这个面部识别的实现能够实时运行。

▌理解深度学习面部识别嵌入
那么,基于深度学习的面部识别是怎样工作的呢?秘密就是一种叫做“深度度量学习”的技术。
如果你有深度学习的经验,你应该知道,通常情况下训练好的网络会接受一个输入图像,并且给输入的图像生成一个分类或标签。
而在这里,网络输出的并不是单一的标签(也不是图像中的坐标或边界盒),而是输出一个表示特征向量的实数。
对于dlib面部识别网络来说,输出的特征向量为128维(即一个由128个实数组成的列表),用来判断面部。网络的训练是通过三元组进行的:
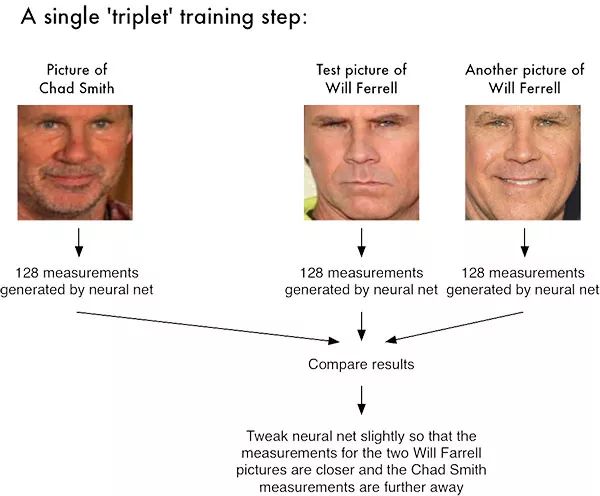
图1:利用深度度量学习进行面部识别需要“三元组训练”。三元组包括三张不同的面部图像,其中两张属于同一个人。神经网络为每张面部图像生成一个128维向量。对于同一个人的两张面部图像,我们调整神经网络使得输出向量的距离度量尽可能接近。
这里我们需要给网络提供三张图片:
其中两张图片是同一个人的面部;第三张图片是从数据集中取得的随机面部图片,并且保证与另外两张图片不是同一个人。以图1为例,这里我们用了三张图片,一张是Chad
Smith,两张是Will Ferrell。
网络会测试这些面部图片,并为每张图片生成128维嵌入(embedding,即qualification)。
接下来,基本思路就是调整神经网络的权重,使得两张Will Ferrell的测量结果尽量接近,而Chad
Smith的测量结果远离。
我们的面部识别网络的架构基于He等人在《Deep Residual Learning for Image
Recognition》中提出的ResNet-34,但层数较少,而且过滤器的数量减少了一半。
网络本身由Davis King在大约300万张图片上训练。在Labeled Faces in the
Wild(LFW)数据集上与其他方法相比,该网络的准确度达到了99.38%。
Davis King(dlib的作者)和Adam Geitgey( 我们即将用到的face_recognition模块的作者)都有文章介绍了基于深度学习的面部识别的工作原理:
High Quality Face Recognition with Deep Metric Learning(Davis)
Modern Face Recognition with Deep Learning( Adam)
强烈建议阅读以上文章,以深入了解深度学习面部嵌入的工作原理。
▌安装面部识别库
为了用Python和OpenCV吸纳面部识别,我们需要安装一些库:
dlib(http://dlib.net/);
face_recognition
(https://github.com/ageitgey/face_recognition)。
由Davis King维护的dlib库包含了“深度度量学习”的实现,用来在实际的识别过程中构建面部嵌入。
Adam Geitgey创建的face_recognition库则封装了dlib的面部识别功能,使之更易用。
我假设你的系统上已经装好了OpenCV。如果没有也不用担心,可以看看我的OpenCV安装指南一文,选择适合你的系统的指南即可。
这里我们来安装dlib和face_recognition库。
注意:下面的安装过程需要在Python虚拟环境中进行。我强烈推荐使用虚拟环境来隔离项目,这是使用Python的好习惯。如果你看了我的OpenCV安装指南,并且安装了virtualenv和virtualenvwrapper,那么只要在安装dlib和face_recognition之前执行workon命令即可。
安装没有GPU支持的dlib
如果你没有GPU,可以用pip安装dlib(参考这篇指南)。
$ workon # optional
$ pip install dlib |
或者从源代码进行编译:
$ workon <your
env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS |
安装有GPU支持的dlib(可选)
如果你有兼容CUDA的GPU,那么可以安装有GPU支持的dlib,这样面部识别能更快、更精确。
我建议从源代码安装dlib,这样可以更精细地控制安装过程:
$ workon <your
env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS
--yes DLIB_USE_CUDA |
安装face_recognition包
face_recognition模块只需简单地使用pip命令即可安装:
$ workon <your
env name here> # optional
$ pip install face_recognition |
安装imutlis
我们还需要imutils包提供一些遍历的函数。在Python虚拟环境中使用pip即可:
$ workon <your
env name here> # optional
$ pip install imutils |
▌面部识别数据集

图2:利用Python和Bing图像搜索API自动创建的面部识别数据集,图中显示的是电影侏罗纪公园的六个角色。
1993年的《侏罗纪公园》是我最喜欢的电影,为了纪念最新上映的《侏罗纪世界:失落王国》,我们将使用电影中的一些角色进行面部识别:
Alan Grant,古生物学家(22张图像)
Clair Dearing,公园管理人(53张图像)
Ellie Sattler,古生物学家(31张图像)
Ian Malcolm,数学家(41张图像)
John Hammond,商人,侏罗纪公园所有者(36张图像)
Owen Grady,恐龙研究学者(35张图像)
这个数据集只需要30分钟就可以建好。
有了这个数据集,我们可以:
为数据集中的每张图像建立128维嵌入;
利用这些嵌入,从图像和视频中识别每个角色的面部。
▌面部识别项目结构
项目结构可以参考下面的tree命令的输出结果:
$ tree --filelimit
10 --dirsfirst
.
├── dataset
│ ├── alan_grant [22 entries]
│ ├── claire_dearing [53 entries]
│ ├── ellie_sattler [31 entries]
│ ├── ian_malcolm [41 entries]
│ ├── john_hammond [36 entries]
│ └── owen_grady [35 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── output
│ └── lunch_scene_output.avi
├── videos
│ └── lunch_scene.mp4
├── search_bing_api.py
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
├── recognize_faces_video_file.py
└── encodings.pickle
10 directories, 11 files |
该项目有4个顶层目录:
dataset/:包含六个角色的面部图像,用角色名组织到各个子目录中;
examples/:包含三个不属于该数据集的测试图像;
output/:存储经过面部识别处理后的视频,上面有我生成的一个视频,来自于原版《侏罗纪公园》电影的午饭场景;
videos/:输入视频存放于该文件夹中,该文件夹也包含了尚未经过面部识别的“午饭场景”的视频。
根目录下还有6个文件:
search_bing_api.py:第一步就是建立数据集(我已经帮你做好了)。关于利用Bing
API建立数据集的具体方法请参考我这篇文章:https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/;
encode_faces.py:该脚本用来进行面部编码(128维向量);
recognize_faces_image.py:基于数据集生成的编码,对单张图片进行面部识别;
recognize_faces_video.py:对来自摄像头的实时视频流进行面部识别并输出视频文件;
recognize_faces_video_file.py:对硬盘上保存的视频文件进行面部识别,并输出处理后的视频文件。本文不再讨论该脚本,因为它的基本结构与上面识别视频流的脚本相同;
encodings.pickle:该脚本将encode_faces.py生成的面部识别编码序列化并保存到硬盘上。
用search_bing_api.py创建好图像数据集之后,就可以运行encode_faces.py来创建嵌入了。
接下来我们将运行识别脚本来进行面部识别。
▌用OpenCV和深度学习对面部进行编码

图3:利用深度学习和Python进行面部识别。对每一个面部图像,用face_recognition模块的方法生成一个128维实数特征向量。
在识别图像和视频中的面部之前,我们首先需要在训练集中识别面部。要注意的是,我们并不是在训练网络——该网络已经在300万图像的训练集上训练过了。
当然我们可以从头开始训练网络,或者微调已有模型的权重,但那就超出了这个项目的范围。再说,你需要巨量的图像才能从头开始训练网络。
相反,使用预先训练好的网络来给训练集中的218张面部图像建立128维嵌入更容易些。
然后,在分类过程中,只需利用简单的k-NN模型,加上投票,即可确定最终的面部分类,也可以使用其他经典机器学习模型。
现在打开本文“下载”链接中的encode_faces.py文件,看看是如何构建面部嵌入的:
1# import the
necessary packages
2from imutils import paths
3import face_recognition
4import argparse
5import pickle
6import cv2
7import os |
首先需要导入必需的包。这个脚本需要事先安装imutils、face_recognition和OpenCV。请翻到前面“安装面部识别库”一节确保你已经安装了必须的库。
首先用argparse处理运行时传递的命令行参数:
1# construct
the argument parser and parse the arguments
2ap = argparse.ArgumentParser()
3ap.add_argument("-i", "--dataset",
required=True,
4 help="path to input directory of faces
+ images")
5ap.add_argument("-e", "--encodings",
required=True,
6 help="path to serialized db of facial encodings")
7ap.add_argument("-d", "--detection-method",
type=str, default="cnn",
8 help="face detection model to use: either
`hog` or `cnn`")
9args = vars(ap.parse_args()) |
如果你之前没有用过PyImageSearch,你可以多读读我的博客文章,就明白上面这段代码了。首先利用argparse分析命令行参数,在命令行上执行Python程序时,可以在终端中给脚本提供格外的信息。第2-9行不需要做任何改动,它们只是为了分析终端上的输入。如果不熟悉这些代码,可以读读我这篇文章
。
下面逐一列出参数:
--dataset:数据集的路径(利用search_bing_api.py创建的数据集);
--encodings:面部编码将被写到该参数所指的文件中;
--detection-method:首先需要检测到图像中的面部,才能对其进行编码。两种面部检测方法为hog或cnn,因此该参数只接受这两个值。
现在参数已经定义好了,我们可以获得数据集文件的路径了(同时进行两个初始化):
1# grab the
paths to the input images in our dataset
2print("[INFO] quantifying faces...")
3imagePaths = list(paths.list_images(args["dataset"]))
4
5# initialize the list of known encodings and
known names
6knownEncodings = []
7knownNames = [] |
行3用输入数据集的路径,建立了一个列表imagePaths。
我们还需要在循环开始之前初始化两个列表,分别是knownEncodings和knownNames。这两个列表分别包含面部编码数据和数据集中相应人物的名字(行6和行7)。
现在可以依次循环侏罗纪公园中的每个角色了!
1# loop over
the image paths
2for (i, imagePath) in enumerate(imagePaths):
3 # extract the person name from the image path
4 print("[INFO] processing image {}/{}".format(i
+ 1,
5 len(imagePaths)))
6 name = imagePath.split(os.path.sep)[-2]
7
8 # load the input image and convert it from BGR
(OpenCV ordering)
9 # to dlib ordering (RGB)
10 image = cv2.imread(imagePath)
11 rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) |
这段代码会循环218次,处理数据集中的218张面部图像。行2在所有图像路径中进行循环。
接下来,行6要从imagePath中提取人物的名字(因为子目录名就是人物名)。
然后将imagePath传递给cv2.imread(行10),读取图像保存到image中。
OpenCV中的颜色通道排列顺序为BGR,但dlib要求的顺序为RGB。由于face_recognition模块使用了dlib,因此在继续下一步之前,行11转换了颜色空间,并将转换后的新图像保存在rgb中。
接下来定位面部位置并计算编码:
1 # detect the
(x, y)-coordinates of the bounding boxes
2 # corresponding to each face in the input image
3 boxes = face_recognition.face_locations(rgb,
4 model=args["detection_method"])
5
6 # compute the facial embedding for the face
7 encodings = face_recognition.face_encodings(rgb,
boxes)
8
9 # loop over the encodings
10 for encoding in encodings:
11 # add each encoding + name to our set of known
names and
12 # encodings
13 knownEncodings.append(encoding)
14 knownNames.append(name) |
这段代码是最有意思的部分!
每次循环都会检测一个面部图像(或者一张图像中有多个面部,我们假设这些面部都属于同一个人,但如果你使用自己的图像的话,这个假设有可能不成立,所以一定要注意)。
比如,假设rgb里的图像是Ellie Sattler的脸。
行3和4查找面部位置,返回一个包含了许多方框的列表。我们给face_recognition.face_locations方法传递了两个参数:
rgb:RGB图像;
model:cnn或hog(该值包含在命令行参数字典中,赋给了detection_method键)。CNN方法比较准确,但速度较慢;HOG比较快,但不太准确。
然后,在行7,我们要将Ellie Sattler的面部的边界盒boxes转换成128个数字。这个步骤就是将面部编码成向量,可以通过face_recognition.face_encodings方法实现。
接下来秩序将Ellie Sattler的encoding和name添加到恰当的列表中(knownEncodings或knownNames)。
然后对数据集中所有218张图像进行这一步骤。
提取这些编码encodings的目的就是要在另一个脚本中利用它们进行面部识别。现在来看看怎么做:
1# dump the
facial encodings + names to disk
2print("[INFO] serializing encodings...")
3data = {"encodings": knownEncodings,
"names": knownNames}
4f = open(args["encodings"], "wb")
5f.write(pickle.dumps(data))
6f.close() |
行3构建了一个字典,它包含encodings和names两个键。
行4-6将名字和编码保存到硬盘中,供以后使用。
怎样才能在终端上运行encode_faces.py脚本?
要创建面部嵌入,可以从终端执行以下命令:
| 要创建面部嵌入,可以从终端执行以下命令:
1$ python encode_faces.py --dataset dataset
--encodings encodings.pickle
2[INFO] quantifying faces...
3[INFO] processing image 1/218
4[INFO] processing image 2/218
5[INFO] processing image 3/218
6...
7[INFO] processing image 216/218
8[INFO] processing image 217/218
9[INFO] processing image 218/218
10[INFO] serializing encodings...
11$ ls -lh encodings*
12-rw-r--r--@ 1 adrian staff 234K May 29 13:03
encodings.pickle |
从输出中课件,它生成了个名为encodings.pickle的文件,该文件包含了数据集中每个面部图像的128维面部嵌入。
在我的Titan X GPU上,处理整个数据集花费了一分钟多一点,但如果只使用CPU,就要做好等待很久的心理准备。
在我的Macbook Pro上(没有GPU),编码218张图像需要21分20秒。
如果你有GPU并且编译dlib时选择了支持GPU,那么速度应该会快得多。
▌识别图像中的面部

图4:John Hammond的面部识别,使用了Adam Geitgey的深度学习Python模块face_recognition。
现在已经给数据集中的每张图像建好了128维面部嵌入,我们可以用OpenCV、Python和深度学习进行面部识别了。
打开recognize_faces_image.py,插入以下代码(或者从本文的”下载“部分下载代码和相关的图像):
1# import the
necessary packages
2import face_recognition
3import argparse
4import pickle
5import cv2
6
7# construct the argument parser and parse the
arguments
8ap = argparse.ArgumentParser()
9ap.add_argument("-e", "--encodings",
required=True,
10 help="path to serialized db of facial
encodings")
11ap.add_argument("-i", "--image",
required=True,
12 help="path to input image")
13ap.add_argument("-d", "--detection-method",
type=str, default="cnn",
14 help="face detection model to use: either
`hog` or `cnn`")
15args = vars(ap.parse_args()) |
这段代码首先导入了必需的包(行2-5)。face_recognition模块完成主要工作,OpenCV负责加载图像、转换图像,并显示处理之后的图像。
行8-15负责分析三个命令行参数:
--encodings:包含面部编码的pickle文件的路径;
--image:需要进行面部识别的图像;
--detection-method:这个选项应该很熟悉了。可以根据系统的能力,选择hog或cnn之一。追求速度的话就选择hog,追求准确度就选择cnn。
注意:在树莓派上必须选择hog,因为内存容量不足以运行CNN方法。
接下来要加载计算好的编码和面部名称,然后为输入图像构建128维面部编码:
1# load the
known faces and embeddings
2print("[INFO] loading encodings...")
3data = pickle.loads(open(args["encodings"],
"rb").read())
4
5# load the input image and convert it from BGR
to RGB
6image = cv2.imread(args["image"])
7rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
8
9# detect the (x, y)-coordinates of the bounding
boxes corresponding
10# to each face in the input image, then compute
the facial embeddings
11# for each face
12print("[INFO] recognizing faces...")
13boxes = face_recognition.face_locations(rgb,
14 model=args["detection_method"])
15encodings = face_recognition.face_encodings(rgb,
boxes)
16
17# initialize the list of names for each face
detected
18names = [] |
行3从硬盘加载pickle过的编码和名字数据。稍后在实际的面部识别步骤中会用到这些数据。
然后,行6和行7加载输入图像image,并转换其颜色通道顺序(同encode_faces.py脚本一样),保存到rgb中。
接下来,行13-15继续检测输入图像中的所有面部,并计算它们的128维encodings(这些代码也应该很熟悉了)。
现在应该初始化一个列表names,用来保存每个检测的面部。该列表将在下一步填充。
现在遍历面部编码encodings列表:
1# loop over
the facial embeddings
2for encoding in encodings:
3 # attempt to match each face in the input image
to our known
4 # encodings
5 matches = face_recognition.compare_faces(data["encodings"],
6 encoding)
7 name = "Unknown" |
行2开始遍历根据输入图像计算出的面部编码。
接下来见证面部识别的奇迹吧!
在行5和行6,我们尝试利用face_recognition.compare_faces将输入图像中的每个面部(encoding)对应到已知的编码数据集(保存在data["encodings"]中)上。
该函数会返回一个True/False值的列表,每个值对应于数据集中的一张图像。对于我们的侏罗纪公园的例子,数据集中有218张图像,因此返回的列表将包含218个布尔值。
compare_faces函数内部会计算待判别图像的嵌入和数据集中所有面部的嵌入之间的欧几里得距离。
如果距离位于容许范围内(容许范围越小,面部识别系统就越严格),则返回True,表明面部吻合。否则,如果距离大于容许范围,则返回False表示面部不吻合。
本质上我们用了个更”炫酷“的k-NN模型进行分类。具体的实现细节可以参考compare_faces的实现。
最终,name变量会的值就是人的名字。如果没有任何”投票“,则保持"Unknown"不变(行7)。
根据matches列表,可以计算每个名字的”投票“数目(与每个名字关联的True值的数目),计票之后选择最适合的人的名字:
1 # check to
see if we have found a match
2 if True in matches:
3 # find the indexes of all matched faces then
initialize a
4 # dictionary to count the total number of times
each face
5 # was matched
6 matchedIdxs = [i for (i, b) in enumerate(matches)
if b]
7 counts = {}
8
9 # loop over the matched indexes and maintain
a count for
10 # each recognized face face
11 for i in matchedIdxs:
12 name = data["names"][i]
13 counts[name] = counts.get(name, 0) + 1
14
15 # determine the recognized face with the largest
number of
16 # votes (note: in the event of an unlikely
tie Python will
17 # select first entry in the dictionary)
18 name = max(counts, key=counts.get)
19
20 # update the list of names
21 names.append(name) |
如果matches中包含任何True的投票(行2),则需要确定True值在matches中的索引位置。这一步在行6中通过建立一个简单的matchedIdxs列表实现。对于example_01.png来说,它大概是这个样子:
1(Pdb) matchedIdxs
2[35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45,
46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57,
58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69,
71, 72, 73, 74, 75] |
然后初始化一个名为counts的字典,其键为角色的名字,值是投票的数量。
接下来遍历matchedIdxs,统计每个相关的名字,并在counts增加相应的计数值。counts字典可能是这个样子(Ian
Malcolm高票的情况):
1(Pdb) counts
2{'ian_malcolm': 40} |
回忆一下我们的数据集中只有41张图片,因此40分并且没有任何其他投票可以认为非常高了。
取出counts中投票最高的名字,本例中为'ian_malcolm'。
循环的第二次迭代(由于图像中有两个人脸)会取出下面的counts:
1(Pdb) counts
2{'alan_grant': 5} |
尽管这个投票分值较低,但由于这是字典中唯一的人名,所以很可能我们找到了Alan Grant。
注意:这里使用了Python调试器PDB来检查counts字典的值。PDB的用法超出了本文的范围,你可以在Python的文档页面找到其用法。
如下面的图5所示,我们正确识别了Ian Malcolm和Alan Grant,所以这一段代码工作得还不错。
我们来继续循环每个人的边界盒和名字,然后将名字画在输出图像上以供展示之用:
1# loop over
the recognized faces
2for ((top, right, bottom, left), name) in zip(boxes,
names):
3 # draw the predicted face name on the image
4 cv2.rectangle(image, (left, top), (right, bottom),
(0, 255, 0), 2)
5 y = top - 15 if top - 15 > 15 else top +
15
6 cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
7 0.75, (0, 255, 0), 2)
8
9# show the output image
10cv2.imshow("Image", image)
11cv2.waitKey(0) |
行2开始循环检测到的面部边界盒boxes和预测的names。我们调用了zip(boxes, names)以创建一个容易进行循环的对象,每次迭代将得到一个二元组,从中可以提取边界盒坐标和名字。
行4利用边界盒坐标画一个绿色方框。
我们还利用坐标计算了人名文本的显示位置(行5),并将人名的文本画在图像上(行6和行7)。如果边界盒位于图像顶端,则将文本移到边界盒下方(行5),否则文本就被截掉了。
然后显示图像,直到按下任意键为止(行10和11)。
怎样运行面部识别的Python脚本?
在终端中,首先用workon命令保证位于正确的Python虚拟环境中(如果你用了虚拟环境的话)。
然后运行该脚本,同时至少提供两个命令行参数。如果选择HoG方式,别忘了传递--detection-method
hog(否则默认会使用深度学习检测方式)。
赶快试试吧!
打开终端并执行脚本,用OpenCV和Python进行面部识别:
1$ python recognize_faces_image.py
--encodings encodings.pickle \
2 --image examples/example_01.png
3[INFO] loading encodings...
4[INFO] recognizing faces... |
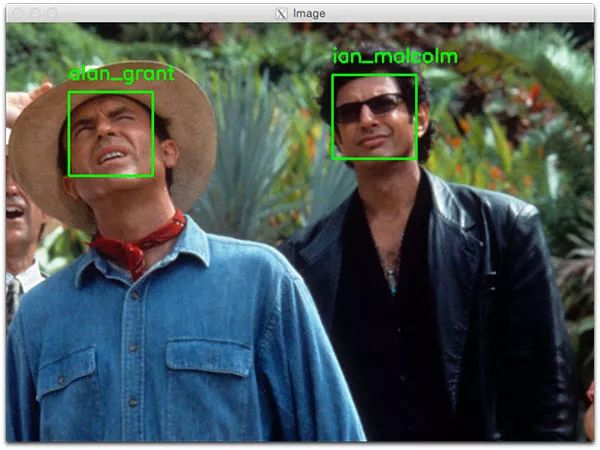
图5:Python + OpenCV + 深度学习方法识别出了Alan Grant和Ian Malcom的面部。
另一个面部识别的例子:
1$ python recognize_faces_image.py
--encodings encodings.pickle \
2 --image examples/example_02.png
3[INFO] loading encodings...
4[INFO] recognizing faces... |
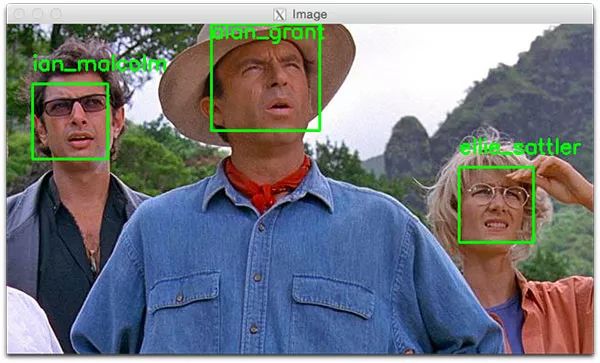
图6:用OpenCV和Python进行面部识别。
▌在视频中进行面部识别

图7:用Python、OpenCV和深度学习在视频中进行面部识别。
我们已经完成了图像中的面部识别,现在来试试在视频中进行(实时)面部识别。
关于性能的重要提示:CNN面部识别器只能在有GPU的情况下实时运行(CPU也可以运行,但视频会非常卡,实际的帧速率不到0.5FPS)。如果你只有CPU,应当考虑使用HoG方式(或者甚至采用OpenCV的Haar层叠方式,以后会撰文说明),以获得较好的速度。
下面的脚本从前面的recognize_faces_image.py脚本中借用了许多代码。因此我将略过之前介绍过的部分,只说明下视频部分,以便于理解。
下载好代码之后,打开recognize_faces_video.py:
1# import the
necessary packages
2from imutils.video import VideoStream
3import face_recognition
4import argparse
5import imutils
6import pickle
7import time
8import cv2
9
10# construct the argument parser and parse the
arguments
11ap = argparse.ArgumentParser()
12ap.add_argument("-e", "--encodings",
required=True,
13 help="path to serialized db of facial
encodings")
14ap.add_argument("-o", "--output",
type=str,
15 help="path to output video")
16ap.add_argument("-y", "--display",
type=int, default=1,
17 help="whether or not to display output
frame to screen")
18ap.add_argument("-d", "--detection-method",
type=str, default="cnn",
19 help="face detection model to use: either
`hog` or `cnn`")
20args = vars(ap.parse_args()) |
行2-8导入包,然后行11-20解析命令行参数。
这里有四个命令行参数,其中两个是介绍过的(--encodings和--detection-method)。另外两个参数是:
--output:视频输出路径;
--display:指示是否将视频帧输出到屏幕的标志。1表示显示到屏幕,0表示不显示。
然后加载编码并启动VideoStream:
1# load the
known faces and embeddings
2print("[INFO] loading encodings...")
3data = pickle.loads(open(args["encodings"],
"rb").read())
4
5# initialize the video stream and pointer to
output video file, then
6# allow the camera sensor to warm up
7print("[INFO] starting video stream...")
8vs = VideoStream(src=0).start()
9writer = None
10time.sleep(2.0) |
我们利用imutils中的VideoStream类来访问摄像头。行8启动视频流。如果系统中有多个摄像头(如内置摄像头和外置USB摄像头),可以将src=0改成src=1等。
稍后会将处理过的视频写到硬盘中,所以这里将writer初始化成None(行9)。sleep两秒让摄像头预热。
接下来启动一个while循环,开始抓取并处理视频帧:
1# loop over
frames from the video file stream
2while True:
3 # grab the frame from the threaded video stream
4 frame = vs.read()
5
6 # convert the input frame from BGR to RGB then
resize it to have
7 # a width of 750px (to speedup processing)
8 rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
9 rgb = imutils.resize(frame, width=750)
10 r = frame.shape[1] / float(rgb.shape[1])
11
12 # detect the (x, y)-coordinates of the bounding
boxes
13 # corresponding to each face in the input frame,
then compute
14 # the facial embeddings for each face
15 boxes = face_recognition.face_locations(rgb,
16 model=args["detection_method"])
17 encodings = face_recognition.face_encodings(rgb,
boxes)
18 names = [] |
循环从行2开始,第一步就是从视频流中抓取一个frame(行4)。
上述代码中剩下的行8-18基本上与前一个脚本相同,只不过这里处理的是视频帧,而不是静态图像。基本上就是读取frame,预处理,检测到面部边界盒boxes,然后给每个边界盒计算encodings。
接下来遍历每个找到的面部的encodings:
1 # loop over
the facial embeddings
2 for encoding in encodings:
3 # attempt to match each face in the input image
to our known
4 # encodings
5 matches = face_recognition.compare_faces(data["encodings"],
6 encoding)
7 name = "Unknown"
8
9 # check to see if we have found a match
10 if True in matches:
11 # find the indexes of all matched faces then
initialize a
12 # dictionary to count the total number of times
each face
13 # was matched
14 matchedIdxs = [i for (i, b) in enumerate(matches)
if b]
15 counts = {}
16
17 # loop over the matched indexes and maintain
a count for
18 # each recognized face face
19 for i in matchedIdxs:
20 name = data["names"][i]
21 counts[name] = counts.get(name, 0) + 1
22
23 # determine the recognized face with the largest
number
24 # of votes (note: in the event of an unlikely
tie Python
25 # will select first entry in the dictionary)
26 name = max(counts, key=counts.get)
27
28 # update the list of names
29 names.append(name) |
在这段代码中依次循环每个encodings,并尝试匹配到已知的面部数据上。如果找到匹配,则计算数据集中每个名字获得的票数。然后取出得票最高的名字,就是该面部对应的名字。这些代码与前面的代码完全相同。
下一段代码循环找到的面部并在周围画出边界盒,并显示人的名字:
1 # loop over
the recognized faces
2 for ((top, right, bottom, left), name) in zip(boxes,
names):
3 # rescale the face coordinates
4 top = int(top * r)
5 right = int(right * r)
6 bottom = int(bottom * r)
7 left = int(left * r)
8
9 # draw the predicted face name on the image
10 cv2.rectangle(frame, (left, top), (right, bottom),
11 (0, 255, 0), 2)
12 y = top - 15 if top - 15 > 15 else top +
15
13 cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
14 0.75, (0, 255, 0), 2) |
这些代码也完全相同,所以我们只关注与食品有关的代码。
我们还可以将视频帧写到硬盘中,因此来看看是怎样使用OpenCV将视频写到硬盘中的(https://www.pyimagesearch.com/2016/02/22/writing-to-video-with-opencv/):
1 # if the video
writer is None *AND* we are supposed to write
2 # the output video to disk initialize the writer
3 if writer is None and args["output"]
is not None:
4 fourcc = cv2.VideoWriter_fourcc(*"MJPG")
5 writer = cv2.VideoWriter(args["output"],
fourcc, 20,
6 (frame.shape[1], frame.shape[0]), True)
7
8 # if the writer is not None, write the frame
with recognized
9 # faces t odisk
10 if writer is not None:
11 writer.write(frame) |
如果命令行参数提供了输出文件路径(可选),而我们还没有初始化视频的writer(行3),就要先初始化之。
行4初始化了VideoWriter_fourcc。FourCC是一种四字符编码,在这里就是MJPG
四字符编码。
接下来将对象、输出路径、每秒帧数的目标值和帧尺寸传递给VideoWriter(行5和6)。
最后,如果writer存在,就继续将帧写到磁盘中。
下面是是否将面部识别视频帧输出到屏幕的处理:
1 # check to
see if we are supposed to display the output frame
to
2 # the screen
3 if args["display"] > 0:
4 cv2.imshow("Frame", frame)
5 key = cv2.waitKey(1) & 0xFF
6
7 # if the `q` key was pressed, break from the
loop
8 if key == ord("q"):
9 break |
如果设置了display命令行参数,就显示视频帧(行4)并检查退出键("q")是否被按下(行5-8),如果被按下,则break掉循环(行9)。
最后是一些清理工作:
1# do a bit
of cleanup
2cv2.destroyAllWindows()
3vs.stop()
4
5# check to see if the video writer point needs
to be released
6if writer is not None:
7 writer.release() |
行2-7清理并释放屏幕、视频流和视频writer。
准备好运行真正的脚本了吗?
为了演示OpenCV和Python的实时面部识别,打开终端然后执行下面的命令:
1$ python recognize_faces_video.py
--encodings encodings.pickle \
2 --output output/webcam_face_recognition_output.avi
--display 1
3[INFO] loading encodings...
4[INFO] starting video stream... |
视频文件中的面部识别
之前在“面部识别项目结构”一节中说过,下载的代码中还有个名为recognize_faces_video_file.py的脚本。
这个脚本实际上和刚才识别摄像头的脚本相同,只不过它接收视频文件作为输入,然后生成输出视频文件。
我对原版侏罗纪公园电影中经典的“午饭场景”做了面部识别,在该场景中,演员们围在桌子旁边讨论他们对于公园的想法:
1$ python recognize_faces_video_file.py
--encodings encodings.pickle \
2 --input videos/lunch_scene.mp4 --output output/lunch_scene_output.avi
\
3 --display 0 |
注意:别忘了我们的模型是根据原版电影中的四个角色进行训练的:Alan Grant、Ellie Sattler、Ian
Malcolm和John Hammond。模型并没有针对Donald Gennaro(律师)进行训练,所以他的面部被标记为“Unknown”。这个行为是特意的(不是意外),以演示我们的视频识别系统在识别训练过的面部的同时,会把不认识的面部标记为“Unknown”。
▌面部识别代码能运行在树莓派上吗?
从某种意义上,可以。不过有一些限制:
树莓派内存太小,没办法运行更准确的基于CNN的面部检测器;
因此只能用HOG方式;
即使如此,HOG方式在树莓派上也太慢,没办法用于实时面部检测;
所以只能用OpenCV的Haar层叠方式。
即使这样能运行起来,实际的速率也只有1~2FPS,而且就算是这种速率也需要许多技巧。
▌总结
在这篇指南中,我们学习了如何利用OpenCV、Python和深度学习来进行面部识别。此外,我们还利用了Davis
King的dlib库和Adam Geitgey的face_recognition模块,后者对dlib的深度度量学习进行了封装,使得面部识别更容易完成。
我们发现,我们的面部识别实现同时具有以下两个特点:准确,并且能在GPU上实时运行。
最后,希望你喜欢今天的面部识别的文章! |









