| БрМЭЦМі: |
БОЮФРДздгкИіШЫЮЂВЉЃЌБОЮФНщЩмЛљгкregion
proposalЕФR-CNNЯЕСаФПБъМьВтЗНЗЈЪЧЕБЧАФПБъМьВтММЪѕСьгђзюжївЊЕФвЛИіЗжжЇЁЃ
|
|
object detectionЮвЕФРэНтЃЌОЭЪЧдкИјЖЈЕФЭМЦЌжаОЋШЗевЕНЮяЬхЫљдкЮЛжУЃЌВЂБъзЂГіЮяЬхЕФРрБ№ЁЃobject
detectionвЊНтОіЕФЮЪЬтОЭЪЧЮяЬхдкФФРяЃЌЪЧЪВУДетећИіСїГЬЕФЮЪЬтЁЃШЛЖјЃЌетИіЮЪЬтПЩВЛЪЧФЧУДШнвзНтОіЕФЃЌЮяЬхЕФГпДчБфЛЏЗЖЮЇКмДѓЃЌАкЗХЮяЬхЕФНЧЖШЃЌзЫЬЌВЛЖЈЃЌЖјЧвПЩвдГіЯждкЭМЦЌЕФШЮКЮЕиЗНЃЌИќКЮПіЮяЬхЛЙПЩвдЪЧЖрИіРрБ№ЁЃ
object detectionММЪѕЕФбнНјЃК RCNN->SppNET->Fast-RCNN->Faster-RCNN
ДгЭМЯёЪЖБ№ЕФШЮЮёЫЕЦ№
етРягавЛИіЭМЯёШЮЮёЃК
МШвЊАбЭМжаЕФЮяЬхЪЖБ№ГіРДЃЌгжвЊгУЗНПђПђГіЫќЕФЮЛжУЁЃ
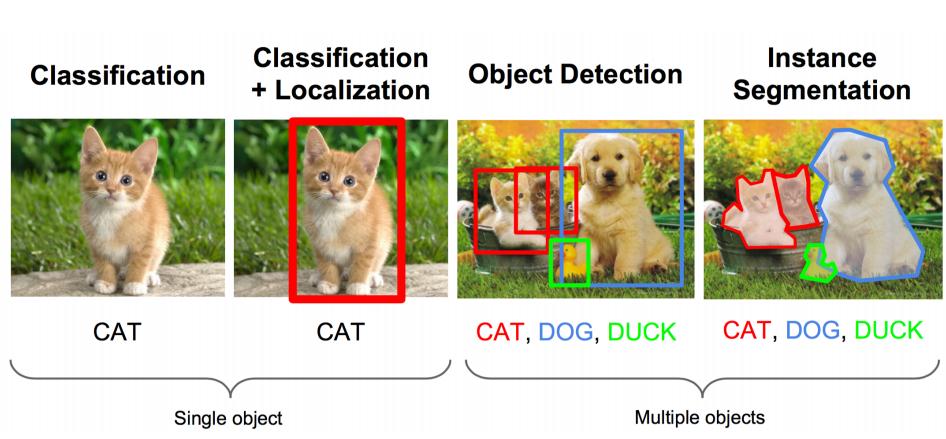
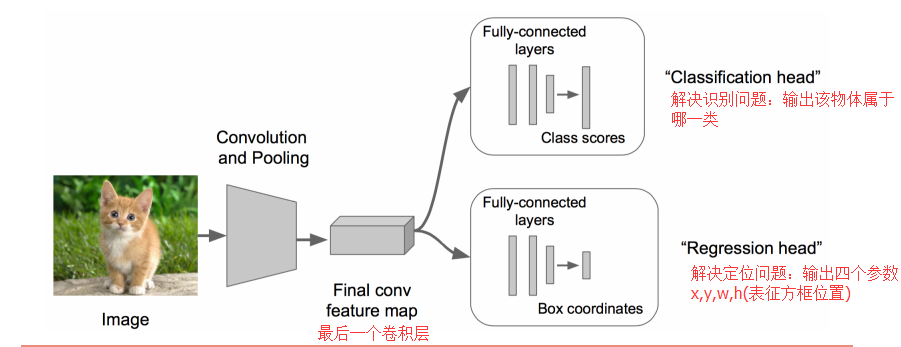
ЩЯУцЕФШЮЮёгУзЈвЕЕФЫЕЗЈОЭЪЧЃКЭМЯёЪЖБ№+ЖЈЮЛ
ЭМЯёЪЖБ№ЃЈclassificationЃЉЃК
ЪфШыЃКЭМЦЌ
ЪфГіЃКЮяЬхЕФРрБ№
ЦРЙРЗНЗЈЃКзМШЗТЪ

ЖЈЮЛЃЈlocalizationЃЉЃК
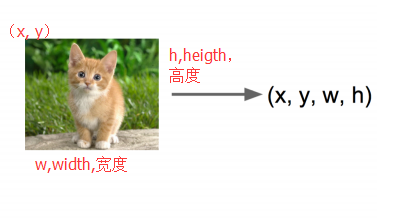
ЪфШыЃКЭМЦЌ ЪфГіЃКЗНПђдкЭМЦЌжаЕФЮЛжУЃЈx,y,w,hЃЉ ЦРЙРЗНЗЈЃКМьВтЦРМлКЏЪ§ intersection-over-union
( IOU )
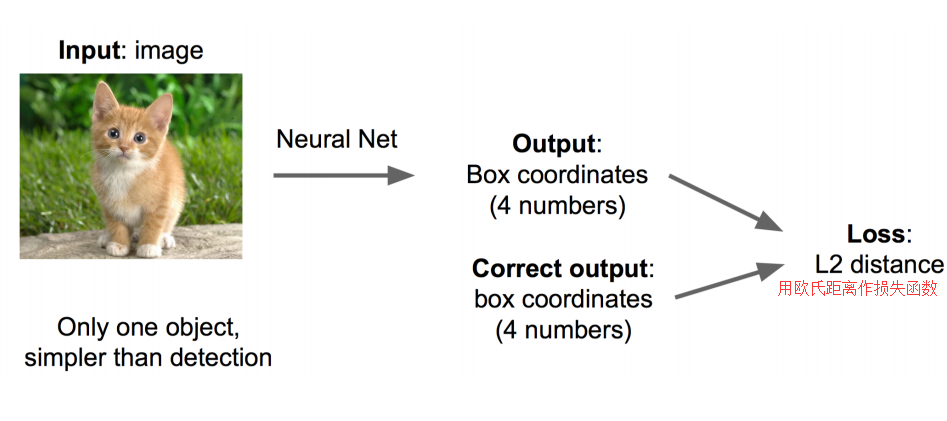
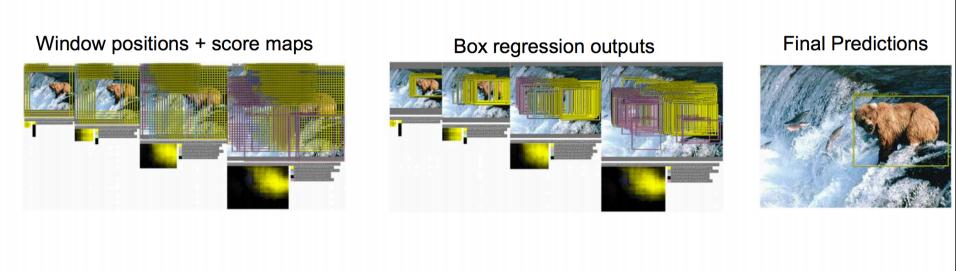
ОэЛ§ЩёОЭјТчCNNвбОАяЮвУЧЭъГЩСЫЭМЯёЪЖБ№ЃЈХаЖЈЪЧУЈЛЙЪЧЙЗЃЉЕФШЮЮёСЫЃЌЮвУЧжЛашвЊЬэМгвЛаЉЖюЭтЕФЙІФмРДЭъГЩЖЈЮЛШЮЮёМДПЩЁЃ
ЖЈЮЛЕФЮЪЬтЕФНтОіЫМТЗгаФФаЉЃП
ЫМТЗвЛЃКПДзіЛиЙщЮЪЬт ПДзіЛиЙщЮЪЬтЃЌЮвУЧашвЊдЄВтГіЃЈx,y,w,hЃЉЫФИіВЮЪ§ЕФжЕЃЌДгЖјЕУГіЗНПђЕФЮЛжУЁЃ
ВНжш1:
1.ЯШНтОіМђЕЅЮЪЬтЃЌ ДювЛИіЪЖБ№ЭМЯёЕФЩёОЭјТч
2.дкAlexNet VGG GoogleLenetЩЯfine-tuningвЛЯТ
ВНжш2:
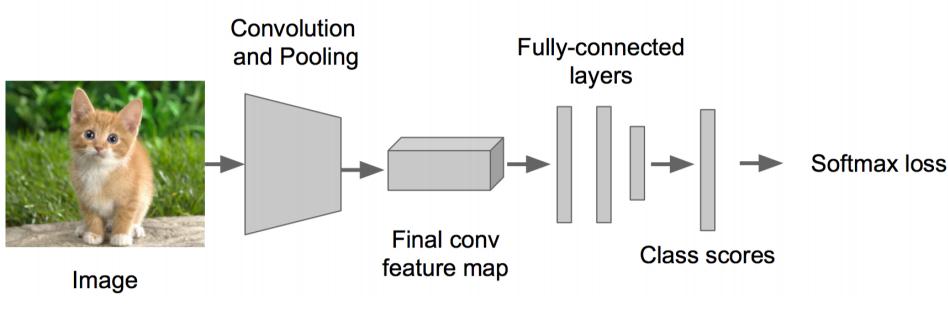
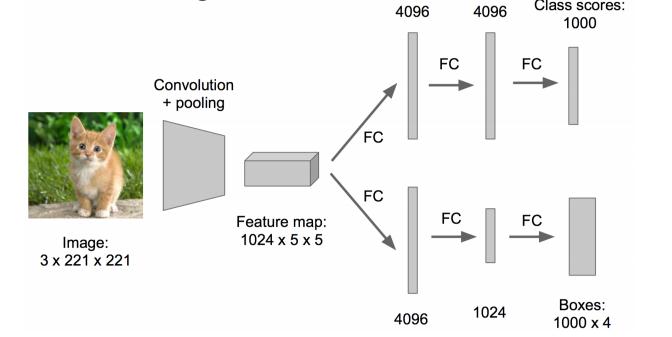
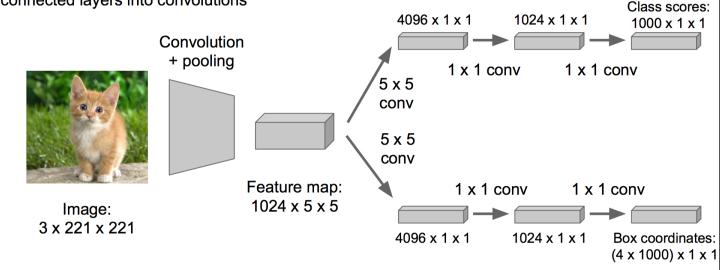
1.дкЩЯЪіЩёОЭјТчЕФЮВВПеЙПЊЃЈвВОЭЫЕCNNЧАУцБЃГжВЛБфЃЌЮвУЧЖдCNNЕФНсЮВДІзїГіИФНјЃКМгСЫСНИіЭЗЃКЁАЗжРрЭЗЁБКЭЁАЛиЙщЭЗЁБЃЉ
2.ГЩЮЊclassification + regressionФЃЪН
ВНжш3:
1.RegressionФЧИіВПЗжгУХЗЪЯОрРыЫ№ЪЇ
2.ЪЙгУSGDбЕСЗ
ВНжш4:
1.дЄВтНзЖЮАб2ИіЭЗВПЦДЩЯ
2.ЭъГЩВЛЭЌЕФЙІФм
етРяашвЊНјааСНДЮfine-tuning
ЕквЛДЮдкALexNetЩЯзіЃЌЕкЖўДЮНЋЭЗВПИФГЩregression headЃЌЧАУцВЛБфЃЌзівЛДЮfine-tuning
RegressionЕФВПЗжМгдкФФЃП
гаСНжжДІРэЗНЗЈЃК
1.МгдкзюКѓвЛИіОэЛ§ВуКѓУцЃЈШчVGGЃЉ
2.МгдкзюКѓвЛИіШЋСЌНгВуКѓУцЃЈШчR-CNNЃЉ
regressionЬЋФбзіСЫЃЌгІЯыЗНЩшЗЈзЊЛЛЮЊclassificationЮЪЬтЁЃ regressionЕФбЕСЗВЮЪ§ЪеСВЕФЪБМфвЊГЄЕУЖрЃЌЫљвдЩЯУцЕФЭјТчВЩШЁСЫгУclassificationЕФЭјТчРДМЦЫуГіЭјТчЙВЭЌВПЗжЕФСЌНгШЈжЕЁЃ
ЫМТЗЖўЃКШЁЭМЯёДАПк
1.ЛЙЪЧИеВХЕФclassification + regressionЫМТЗ
2.длУЧШЁВЛЭЌЕФДѓаЁЕФЁАПђЁБ
3.ШУПђГіЯждкВЛЭЌЕФЮЛжУЃЌЕУГіетИіПђЕФХаЖЈЕУЗж
4.ШЁЕУЗжзюИпЕФФЧИіПђ
зѓЩЯНЧЕФКкПђЃКЕУЗж0.5

гвЩЯНЧЕФКкПђЃКЕУЗж0.75

зѓЯТНЧЕФКкПђЃКЕУЗж0.6

гвЯТНЧЕФКкПђЃКЕУЗж0.8

ИљОнЕУЗжЕФИпЕЭЃЌЮвУЧбЁдёСЫгвЯТНЧЕФКкПђзїЮЊФПБъЮЛжУЕФдЄВтЁЃ зЂЃКгаЕФЪБКђвВЛсбЁдёЕУЗжзюИпЕФСНИіПђЃЌШЛКѓШЁСНПђЕФНЛМЏзїЮЊзюжеЕФЮЛжУдЄВтЁЃ
вЩЛѓЃК
ПђвЊШЁЖрДѓЃП
ШЁВЛЭЌЕФПђЃЌвРДЮДгзѓЩЯНЧЩЈЕНгвЯТНЧЁЃЗЧГЃДжБЉАЁЁЃ
змНсвЛЯТЫМТЗЃК ЖдвЛеХЭМЦЌЃЌгУИїжжДѓаЁЕФПђЃЈБщРњећеХЭМЦЌЃЉНЋЭМЦЌНиШЁГіРДЃЌЪфШыЕНCNNЃЌШЛКѓCNNЛсЪфГіетИіПђЕФЕУЗжЃЈclassificationЃЉвдМАетИіПђЭМЦЌЖдгІЕФx,y,h,wЃЈregressionЃЉЁЃ
етЗНЗЈЪЕдкЬЋКФЪБМфСЫЃЌзіИігХЛЏЁЃ дРДЭјТчЪЧетбљЕФЃК
гХЛЏГЩетбљЃКАбШЋСЌНгВуИФЮЊОэЛ§ВуЃЌетбљПЩвдЬсЬсЫйЁЃ
ЮяЬхМьВтЃЈObject DetectionЃЉ ЕБЭМЯёгаКмЖрЮяЬхдѕУДАьЕФЃП
ФбЖШПЩЪЧвЛЯТБЉдіАЁЁЃ
ФЧШЮЮёОЭБфГЩСЫЃК
ЖрЮяЬхЪЖБ№+ЖЈЮЛЖрИіЮяЬх
ФЧАбетИіШЮЮёПДзіЗжРрЮЪЬтЃП

ПДГЩЗжРрЮЪЬтгаКЮВЛЭзЃП
1..ФуашвЊевКмЖрЮЛжУЃЌ ИјКмЖрИіВЛЭЌДѓаЁЕФПђ
2.ФуЛЙашвЊЖдПђФкЕФЭМЯёЗжРр
3.ЕБШЛЃЌ ШчЙћФуЕФGPUКмЧПДѓЃЌ ЖїЃЌ ФЧМггЭзіАЩЁ
ПДзіclassificationЃЌ гаУЛгаАьЗЈгХЛЏЯТЃПЮвПЩВЛЯыЪдФЧУДЖрПђФЧУДЖрЮЛжУАЁЃЁ
гаШЫЯыЕНвЛИіКУЗНЗЈЃК
евГіПЩФмКЌгаЮяЬхЕФПђЃЈвВОЭЪЧКђбЁПђЃЌБШШчбЁ1000ИіКђбЁПђЃЉЃЌетаЉПђжЎМфЪЧПЩвдЛЅЯржиЕўЛЅЯрАќКЌЕФЃЌетбљЮвУЧОЭПЩвдБмУтБЉСІУЖОйЕФЫљгаПђСЫЁЃ

ДѓХЃУЧЗЂУїКУЖрбЁЖЈКђбЁПђЕФЗНЗЈЃЌБШШчEdgeBoxesКЭSelective SearchЁЃ вдЯТЪЧИїжжбЁЖЈКђбЁПђЕФЗНЗЈЕФадФмЖдБШЁЃ
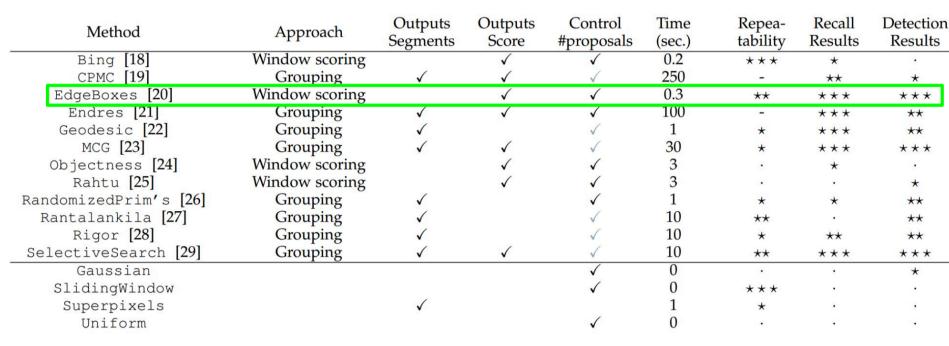
гавЛИіКмДѓЕФвЩЛѓЃЌЬсШЁКђбЁПђгУЕНЕФЫуЗЈЁАбЁдёадЫбЫїЁБЕНЕздѕУДбЁГіетаЉКђбЁПђЕФФиЃП
ФЧИіОЭЕУКУКУПДПДЫќЕФТлЮФСЫЃЌетРяОЭВЛНщЩмСЫЁЃ
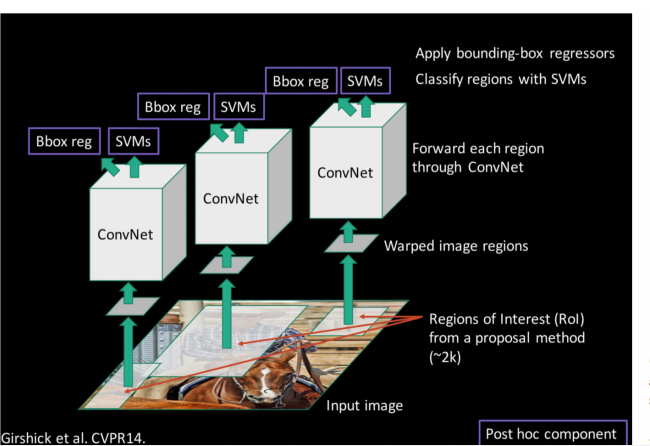
R-CNNКсПеГіЪР ЛљгквдЩЯЕФЫМТЗЃЌRCNNЕФГіЯжСЫЁЃ
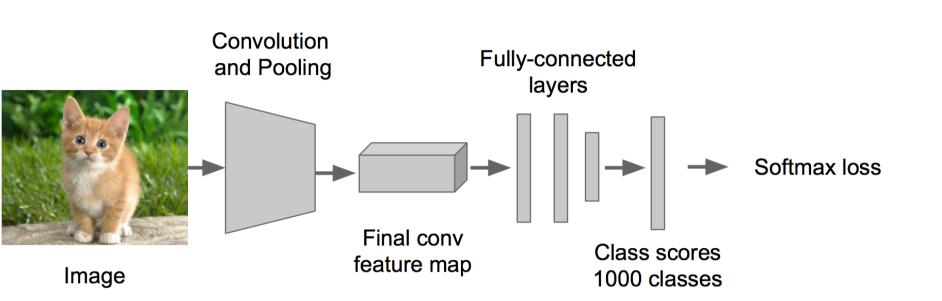
ВНжшвЛЃКбЕСЗЃЈЛђепЯТдиЃЉвЛИіЗжРрФЃаЭЃЈБШШчAlexNetЃЉ
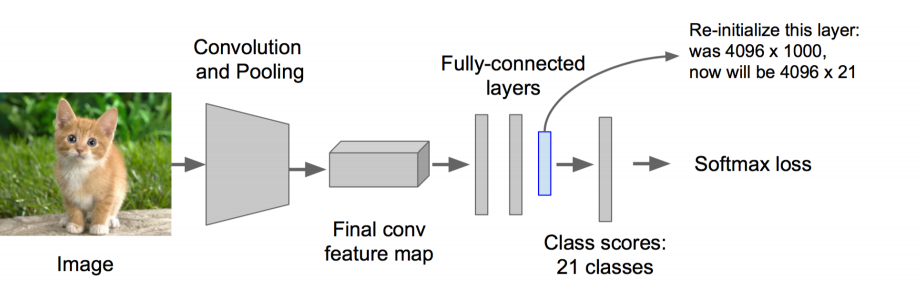
ВНжшЖўЃКЖдИУФЃаЭзіfine-tuning
1.НЋЗжРрЪ§Дг1000ИФЮЊ20
2.ШЅЕєзюКѓвЛИіШЋСЌНгВу
ВНжшШ§ЃКЬиеїЬсШЁ
1.ЬсШЁЭМЯёЕФЫљгаКђбЁПђЃЈбЁдёадЫбЫїЃЉ
2.ЖдгкУПвЛИіЧјгђЃКаое§ЧјгђДѓаЁвдЪЪКЯCNNЕФЪфШыЃЌзівЛДЮЧАЯђдЫЫуЃЌНЋЕкЮхИіГиЛЏВуЕФЪфГіЃЈОЭЪЧЖдКђбЁПђЬсШЁЕНЕФЬиеїЃЉДцЕНгВХЬ
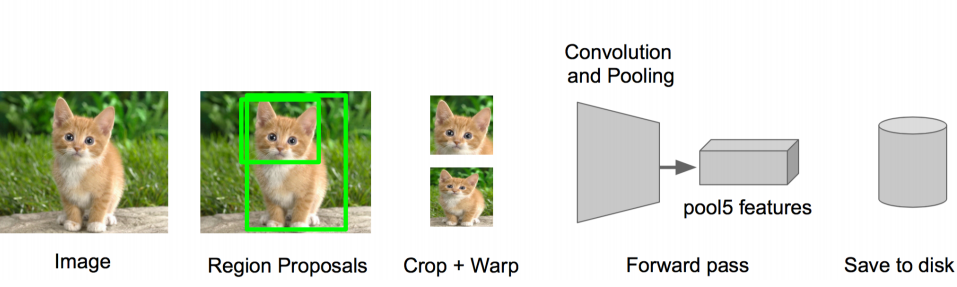
ВНжшЫФЃК
бЕСЗвЛИіSVMЗжРрЦїЃЈЖўЗжРрЃЉРДХаЖЯетИіКђбЁПђРяЮяЬхЕФРрБ№
УПИіРрБ№ЖдгІвЛИіSVMЃЌХаЖЯЪЧВЛЪЧЪєгкетИіРрБ№ЃЌЪЧОЭЪЧpositiveЃЌЗДжЎnagative БШШчЯТЭМЃЌОЭЪЧЙЗЗжРрЕФSVM
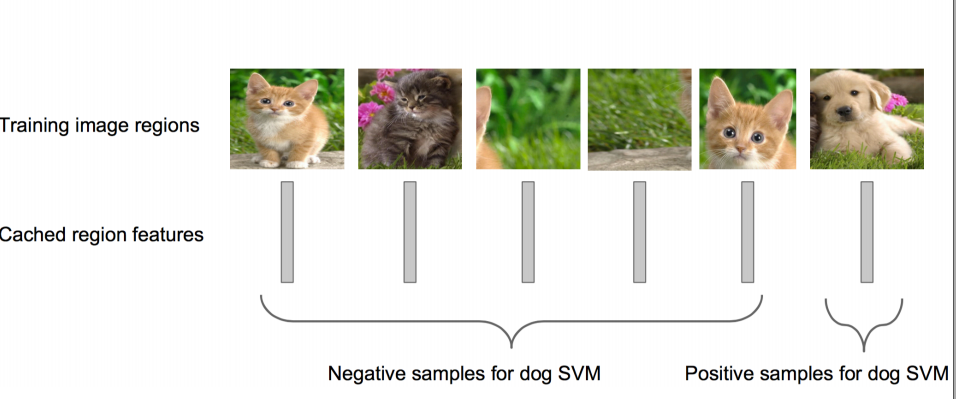
ВНжшЮхЃК
ЪЙгУЛиЙщЦїОЋЯИаое§КђбЁПђЮЛжУЃК
ЖдгкУПвЛИіРрЃЌбЕСЗвЛИіЯпадЛиЙщФЃаЭШЅХаЖЈетИіПђЪЧЗёПђЕУЭъУРЁЃ

RCNNЕФНјЛЏжаSPP NetЕФЫМЯыЖдЦфЙБЯзКмДѓЃЌетРявВМђЕЅНщЩмвЛЯТSPP NetЁЃ
SPP Net SPPЃКSpatial Pyramid PoolingЃЈПеМфН№зжЫўГиЛЏЃЉ ЫќЕФЬиЕугаСНИі:
1.НсКЯПеМфН№зжЫўЗНЗЈЪЕЯжCNNsЕФЖдГпЖШЪфШыЁЃ вЛАуCNNКѓНгШЋСЌНгВуЛђепЗжРрЦїЃЌЫћУЧЖМашвЊЙЬЖЈЕФЪфШыГпДчЃЌвђДЫВЛЕУВЛЖдЪфШыЪ§ОнНјааcropЛђепwarpЃЌетаЉдЄДІРэЛсдьГЩЪ§ОнЕФЖЊЪЇЛђМИКЮЕФЪЇецЁЃSPP
NetЕФЕквЛИіЙБЯзОЭЪЧНЋН№зжЫўЫМЯыМгШыЕНCNNЃЌЪЕЯжСЫЪ§ОнЕФЖрГпЖШЪфШыЁЃ
ШчЯТЭМЫљЪОЃЌдкОэЛ§ВуКЭШЋСЌНгВужЎМфМгШыСЫSPP layerЁЃДЫЪБЭјТчЕФЪфШыПЩвдЪЧШЮвтГпЖШЕФЃЌдкSPP
layerжаУПвЛИіpoolingЕФfilterЛсИљОнЪфШыЕїећДѓаЁЃЌЖјSPPЕФЪфГіГпЖШЪМжеЪЧЙЬЖЈЕФЁЃ
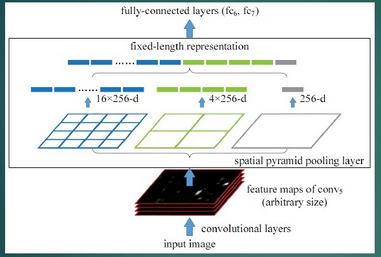
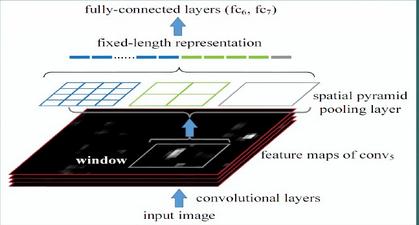
2.жЛЖддЭМЬсШЁвЛДЮОэЛ§Ьиеї дкR-CNNжаЃЌУПИіКђбЁПђЯШresizeЕНЭГвЛДѓаЁЃЌШЛКѓЗжБ№зїЮЊCNNЕФЪфШыЃЌетбљЪЧКмЕЭаЇЕФЁЃ
ЫљвдSPP NetИљОнетИіШБЕузіСЫгХЛЏЃКжЛЖддЭМНјаавЛДЮОэЛ§ЕУЕНећеХЭМЕФfeature mapЃЌШЛКѓевЕНУПИіКђбЁПђzaifeature
mapЩЯЕФгГЩфpatchЃЌНЋДЫpatchзїЮЊУПИіКђбЁПђЕФОэЛ§ЬиеїЪфШыЕНSPP layerКЭжЎКѓЕФВуЁЃНкЪЁСЫДѓСПЕФМЦЫуЪБМфЃЌБШR-CNNгавЛАйБЖзѓгвЕФЬсЫйЁЃ
Fast R-CNN SPP NetецЪЧИіКУЗНЗЈЃЌR-CNNЕФНјНзАцFast R-CNNОЭЪЧдкRCNNЕФЛљДЁЩЯВЩФЩСЫSPP
NetЗНЗЈЃЌЖдRCNNзїСЫИФНјЃЌЪЙЕУадФмНјвЛВНЬсИпЁЃ
R-CNNгыFast RCNNЕФЧјБ№гаФФаЉФиЃП
ЯШЫЕRCNNЕФШБЕуЃКМДЪЙЪЙгУСЫselective searchЕШдЄДІРэВНжшРДЬсШЁЧБдкЕФbounding
boxзїЮЊЪфШыЃЌЕЋЪЧRCNNШдЛсгабЯжиЕФЫйЖШЦПОБЃЌдвђвВКмУїЯдЃЌОЭЪЧМЦЫуЛњЖдЫљгаregionНјааЬиеїЬсШЁЪБЛсгажиИДМЦЫуЃЌFast-RCNNе§ЪЧЮЊСЫНтОіетИіЮЪЬтЕЎЩњЕФЁЃ
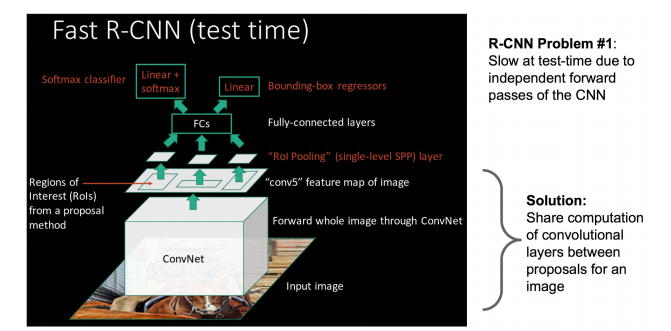
ДѓХЃЬсГіСЫвЛИіПЩвдПДзіЕЅВуsppnetЕФЭјТчВуЃЌНазіROI PoolingЃЌетИіЭјТчВуПЩвдАбВЛЭЌДѓаЁЕФЪфШыгГЩфЕНвЛИіЙЬЖЈГпЖШЕФЬиеїЯђСПЃЌЖјЮвУЧжЊЕРЃЌconvЁЂpoolingЁЂreluЕШВйзїЖМВЛашвЊЙЬЖЈsizeЕФЪфШыЃЌвђДЫЃЌдкдЪМЭМЦЌЩЯжДааетаЉВйзїКѓЃЌЫфШЛЪфШыЭМЦЌsizeВЛЭЌЕМжТЕУЕНЕФfeature
mapГпДчвВВЛЭЌЃЌВЛФмжБНгНгЕНвЛИіШЋСЌНгВуНјааЗжРрЃЌЕЋЪЧПЩвдМгШыетИіЩёЦцЕФROI PoolingВуЃЌЖдУПИіregionЖМЬсШЁвЛИіЙЬЖЈЮЌЖШЕФЬиеїБэЪОЃЌдйЭЈЙ§е§ГЃЕФsoftmaxНјааРраЭЪЖБ№ЁЃСэЭтЃЌжЎЧАRCNNЕФДІРэСїГЬЪЧЯШЬсproposalЃЌШЛКѓCNNЬсШЁЬиеїЃЌжЎКѓгУSVMЗжРрЦїЃЌзюКѓдйзіbbox
regressionЃЌЖјдкFast-RCNNжаЃЌзїепЧЩУюЕФАбbbox regressionЗХНјСЫЩёОЭјТчФкВПЃЌгыregionЗжРрКЭВЂГЩЮЊСЫвЛИіmulti-taskФЃаЭЃЌЪЕМЪЪЕбщвВжЄУїЃЌетСНИіШЮЮёФмЙЛЙВЯэОэЛ§ЬиеїЃЌВЂЯрЛЅДйНјЁЃFast-RCNNКмживЊЕФвЛИіЙБЯзЪЧГЩЙІЕФШУШЫУЧПДЕНСЫRegion
Proposal+CNNетвЛПђМмЪЕЪБМьВтЕФЯЃЭћЃЌдРДЖрРрМьВтецЕФПЩвддкБЃжЄзМШЗТЪЕФЭЌЪБЬсЩ§ДІРэЫйЖШЃЌвВЮЊКѓРДЕФFaster-RCNNзіЯТСЫЦЬЕцЁЃ
ЛвЛЛжиЕуЃК
R-CNNгавЛаЉЯрЕБДѓЕФШБЕуЃЈАбетаЉШБЕуЖМИФЕєСЫЃЌОЭГЩСЫFast R-CNNЃЉЁЃ ДѓШБЕуЃКгЩгкУПвЛИіКђбЁПђЖМвЊЖРздОЙ§CNNЃЌетЪЙЕУЛЈЗбЕФЪБМфЗЧГЃЖрЁЃ
НтОіЃКЙВЯэОэЛ§ВуЃЌЯждкВЛЪЧУПвЛИіКђбЁПђЖМЕБзіЪфШыНјШыCNNСЫЃЌЖјЪЧЪфШывЛеХЭъећЕФЭМЦЌЃЌдкЕкЮхИіОэЛ§ВудйЕУЕНУПИіКђбЁПђЕФЬиеї
дРДЕФЗНЗЈЃК
аэЖрКђбЁПђЃЈБШШчСНЧЇИіЃЉ-->CNN-->ЕУЕНУПИіКђбЁПђЕФЬиеї-->ЗжРр+ЛиЙщ
ЯждкЕФЗНЗЈЃК
вЛеХЭъећЭМЦЌ-->CNN-->ЕУЕНУПеХКђбЁПђЕФЬиеї-->ЗжРр+ЛиЙщ
ЫљвдШнвзПДМћЃЌFast RCNNЯрЖдгкRCNNЕФЬсЫйдвђОЭдкгкЃКВЛЙ§ВЛЯёRCNNАбУПИіКђбЁЧјгђИјЩюЖШЭјТчЬсЬиеїЃЌЖјЪЧећеХЭМЬсвЛДЮЬиеїЃЌдйАбКђбЁПђгГЩфЕНconv5ЩЯЃЌЖјSPPжЛашвЊМЦЫувЛДЮЬиеїЃЌЪЃЯТЕФжЛашвЊдкconv5ВуЩЯВйзїОЭПЩвдСЫЁЃ
дкадФмЩЯЬсЩ§вВЪЧЯрЕБУїЯдЕФЃК
Faster R-CNN
Fast R-CNNДцдкЕФЮЪЬтЃК
ДцдкЦПОБЃКбЁдёадЫбЫїЃЌевГіЫљгаЕФКђбЁПђЃЌетИівВЗЧГЃКФЪБЁЃ
ФЧЮвУЧФмВЛФмевГівЛИіИќМгИпаЇЕФЗНЗЈРДЧѓГіетаЉКђбЁПђФиЃП
НтОіЃКМгШывЛИіЬсШЁБпдЕЕФЩёОЭјТчЃЌвВОЭЫЕевЕНКђбЁПђЕФЙЄзївВНЛИјЩёОЭјТчРДзіСЫЁЃ зіетбљЕФШЮЮёЕФЩёОЭјТчНазіRegion
Proposal Network(RPN)ЁЃ
ОпЬхзіЗЈЃК
1.НЋRPNЗХдкзюКѓвЛИіОэЛ§ВуЕФКѓУц
2.RPNжБНгбЕСЗЕУЕНКђбЁЧјгђ
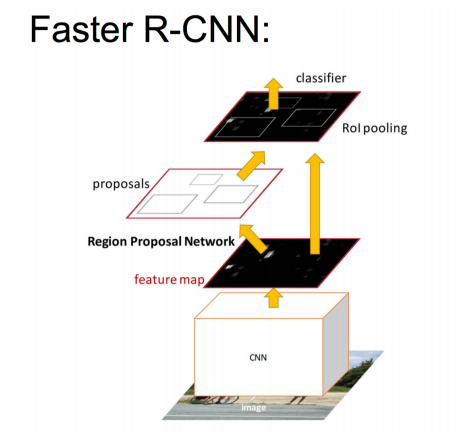
RPNМђНщЃК
1.дкfeature mapЩЯЛЌЖЏДАПк
2.НЈвЛИіЩёОЭјТчгУгкЮяЬхЗжРр+ПђЮЛжУЕФЛиЙщ
3.ЛЌЖЏДАПкЕФЮЛжУЬсЙЉСЫЮяЬхЕФДѓЬхЮЛжУаХЯЂ
4.ПђЕФЛиЙщЬсЙЉСЫПђИќОЋШЗЕФЮЛжУ
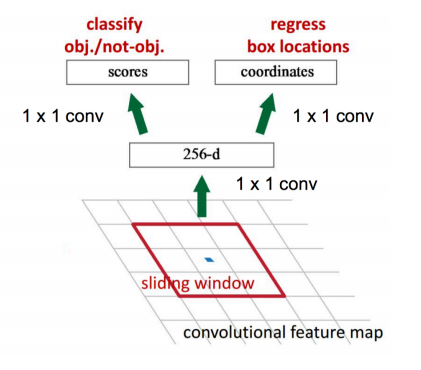
вЛжжЭјТчЃЌЫФИіЫ№ЪЇКЏЪ§;
1. RPN calssification(anchor good.bad)
2. RPN regression(anchor->propoasal)
3. Fast R-CNN classification(over
classes)
4. Fast R-CNN regression(proposal
->box)
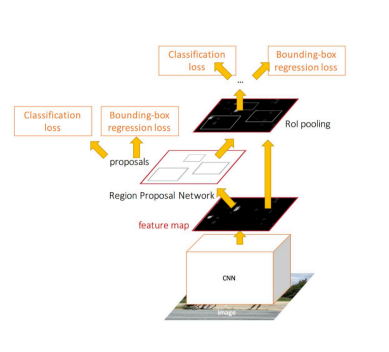
ЫйЖШЖдБШ
Faster R-CNNЕФжївЊЙБЯзЪЧЩшМЦСЫЬсШЁКђбЁЧјгђЕФЭјТчRPNЃЌДњЬцСЫЗбЪБЕФбЁдёадЫбЫїЃЌЪЙЕУМьВтЫйЖШДѓЗљЬсИпЁЃ
зюКѓзмНсвЛЯТИїДѓЫуЗЈЕФВНжшЃК RCNN
1. дкЭМЯёжаШЗЖЈдМ1000-2000ИіКђбЁПђ (ЪЙгУбЁдёадЫбЫї)
2. УПИіКђбЁПђФкЭМЯёПщЫѕЗХжСЯрЭЌДѓаЁЃЌВЂЪфШыЕНCNNФкНјааЬиеїЬсШЁ
3. ЖдКђбЁПђжаЬсШЁГіЕФЬиеїЃЌЪЙгУЗжРрЦїХаБ№ЪЧЗёЪєгквЛИіЬиЖЈРр
4. ЖдгкЪєгкФГвЛЬиеїЕФКђбЁПђЃЌгУЛиЙщЦїНјвЛВНЕїећЦфЮЛжУ
Fast RCNN
1. дкЭМЯёжаШЗЖЈдМ1000-2000ИіКђбЁПђ (ЪЙгУбЁдёадЫбЫї)
2. ЖдећеХЭМЦЌЪфНјCNNЃЌЕУЕНfeature map
3. евЕНУПИіКђбЁПђдкfeature mapЩЯЕФгГЩфpatchЃЌНЋДЫpatchзїЮЊУПИіКђбЁПђЕФОэЛ§ЬиеїЪфШыЕНSPP
layerКЭжЎКѓЕФВу
4. ЖдКђбЁПђжаЬсШЁГіЕФЬиеїЃЌЪЙгУЗжРрЦїХаБ№ЪЧЗёЪєгквЛИіЬиЖЈРр
5. ЖдгкЪєгкФГвЛЬиеїЕФКђбЁПђЃЌгУЛиЙщЦїНјвЛВНЕїећЦфЮЛжУ
Faster RCNN
1. ЖдећеХЭМЦЌЪфНјCNNЃЌЕУЕНfeature map
2. ОэЛ§ЬиеїЪфШыЕНRPNЃЌЕУЕНКђбЁПђЕФЬиеїаХЯЂ
3. ЖдКђбЁПђжаЬсШЁГіЕФЬиеїЃЌЪЙгУЗжРрЦїХаБ№ЪЧЗёЪєгквЛИіЬиЖЈРр
4. ЖдгкЪєгкФГвЛЬиеїЕФКђбЁПђЃЌгУЛиЙщЦїНјвЛВНЕїећЦфЮЛжУ
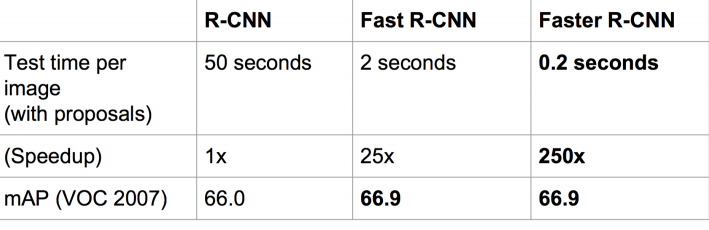
змЕФРДЫЕЃЌДгR-CNN, SPP-NET, Fast R-CNN, Faster R-CNNвЛТЗзпРДЃЌЛљгкЩюЖШбЇЯАФПБъМьВтЕФСїГЬБфЕУдНРДдНОЋМђЃЌОЋЖШдНРДдНИпЃЌЫйЖШвВдНРДдНПьЁЃПЩвдЫЕЛљгкregion
proposalЕФR-CNNЯЕСаФПБъМьВтЗНЗЈЪЧЕБЧАФПБъМьВтММЪѕСьгђзюжївЊЕФвЛИіЗжжЇЁЃ |









