| 编辑推荐: |
本文于微信,介绍一下可微编程的一些相关的概念,可微编程的工作都是基于优化的过程展开,然后寻找它和神经网络之间的关系等。
|
|

今天的汇报将从上面四个部分展开。
第一部分,介绍一下可微编程的一些相关的概念。
第二部分,介绍我们的第一个工作。现在大多可微编程是把优化过程展开,转换成回复式神经网络。而我们这项工作也是把优化过程展开,发现能够得到新的长短期记忆,再从可微编程角度,找到与长短期记忆网络的连接。
第三部分,介绍我们的第二个工作。现有的绝大多数可微编程的工作都是基于优化的过程展开,然后寻找它和神经网络之间的关系。而我们这项工作是从目标函数进行变形得到一个前向式神经网络。
第四部分,是我们对于这些研究问题的一些思考。


首先介绍一下可微编程是什么呢?简单来说,就是把神经网络当成一种语言,而不是一个简单的机器学习的方法,从而描述我们客观世界的概念以及概念之间的关系。这种观点无限地提高了神经网络的地位。

LeCun曾在facebook的文章里说:”Deep Learning Is Dead. Long
Live Differentiable Programming!” (深度学习已死,可微编程永生)。
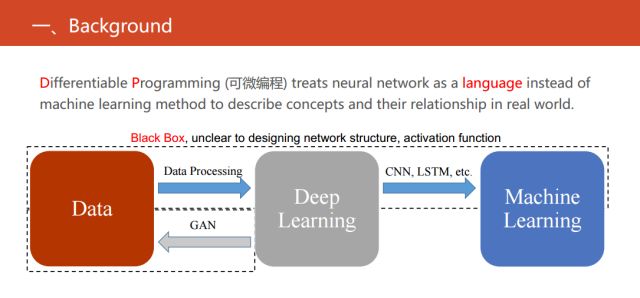
具体的可微编程和现有的深度学习、机器学习又有什么关系呢?这里有一个简单的对比,在上图中显示的三个实体之间发生的三项关系。目前最流行的方法是用深度学习提取特征,然后结合机器学习的一些方法来解决实际当中的一些问题,也可以反过来用深度神经网络拿来直接生成数据,也就是目前最火的生成式对抗网络。
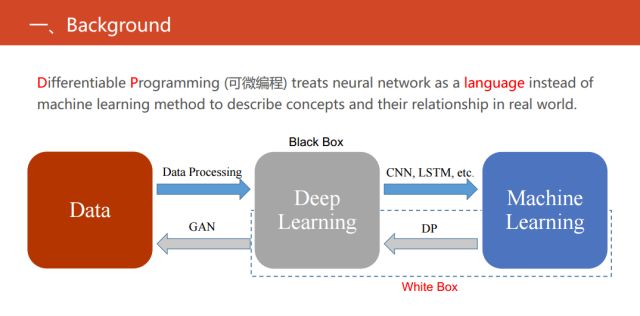
但我们可以发现缺失了一块,也是目前可微编程做的主流工作。缺失的就是把现有的机器学习的方法转化成等价的神经网络,使得同时具有传统的统计机器学习方法的可解释性强以及深度神经网络性能较优等优点。
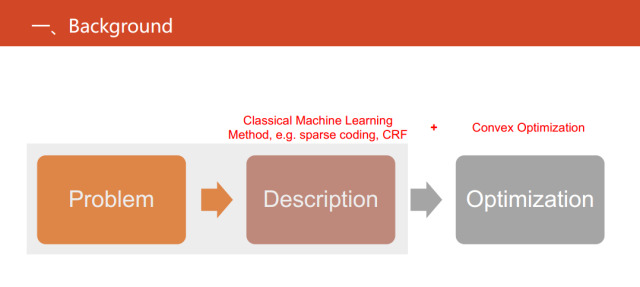
针对现实世界中的一些问题,传统的机器学习的方法思路是首先基于一些假设或者先验知识(比如稀疏编码等),将其形式化成目标函数,再对其进行优化求解。但当得到一个新的目标函数时,我们还需要研究目标函数数学上的性质对其进行优化,如目前最流行的优化方法--凸优划。
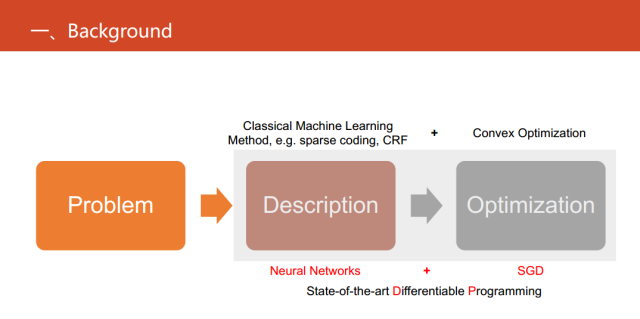
但是这样做饱受诟病的一个原因就是可解释不强。那可微编程可以做什么?其实就把神经网络直接当成一种语言,直接用于替代问题的描述或者说抽象化问题。这样做的好处显而易见,首先,它易于优化。只需要一个SGD或者SGD的变种,而不需要发展出非常复杂的优化的算法。此外,它还易于计算。并且,它也能做端到端的学习。


在神经网络以深度学习为标志复出之后,最早的可微编程的工作应该是Yann LeCun的ISTA。求解稀疏编码这个目标函数的优化方法有非常多,ISTA是其中非常有名的一个。上图中间红框标注的公式就是ISTA的核心,具体细节可以阅读文章《Learning
fast approximations of sparse coding》。

观察上图中红色方框的公式,可以看到Z是依赖于前一步的Z值。这在数学上就等价于一个动力学系统或者一个迭代过程,而动力学系统本质上就是回复式神经网络的数学本质。因此,进一步地把右下角公式简单地变形等价成RNN,这是神经网络复出以来最为知名的一个可微编程的工作。

随后有很多的进展,比如2016年NIPS上的文章《Attend, Infer, Repeat: Fast
Scene Understanding with Generative Models》关于生成模型的工作,这项工作也是目前比较热门的研究。
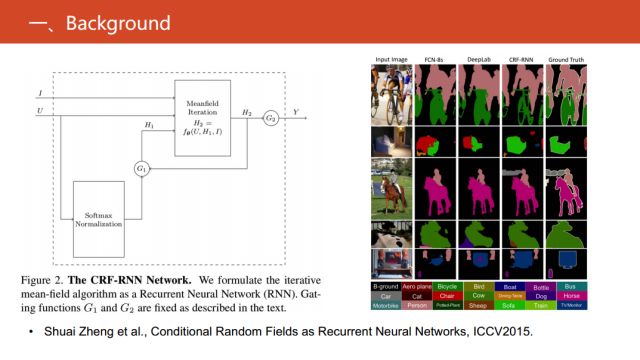
另外,在2015的ICCV上《Conditional Random Fields as Recurrent
Neural Networks》文章中提出,把条件随机场的求解变形成了循环神经网络的相关运算,在图像语义分割上实现了突破。
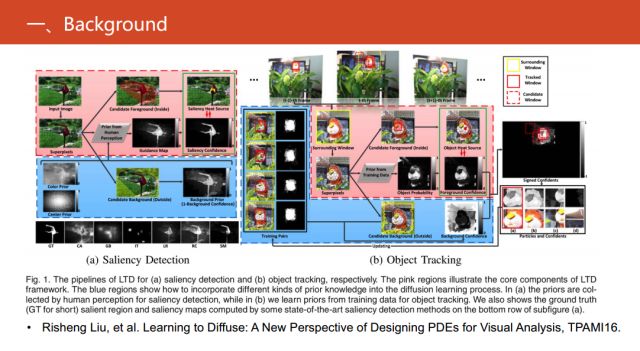
在2016的TPAMI上《Learning to Diffuse: A New Perspective
of Designing PDEs for Visual Analysis》文章中,提出的PDE工作在多个任务视觉上取得很好的效果。
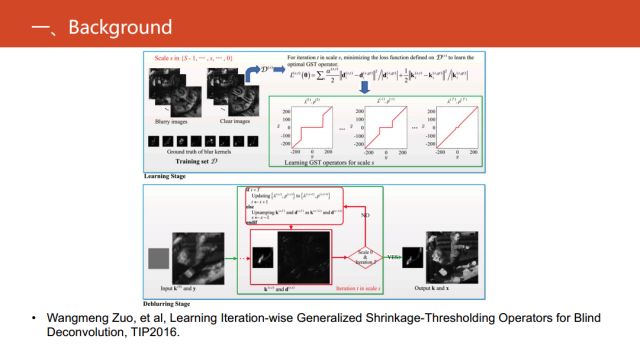
在2016的TIP《Learning Iteration-wise Generalized Shrinkage-Thresholding
Operators for Blind Deconvolution》里,针对盲卷积这个问题,发展出能够实现稀疏编码的回复神经网络。
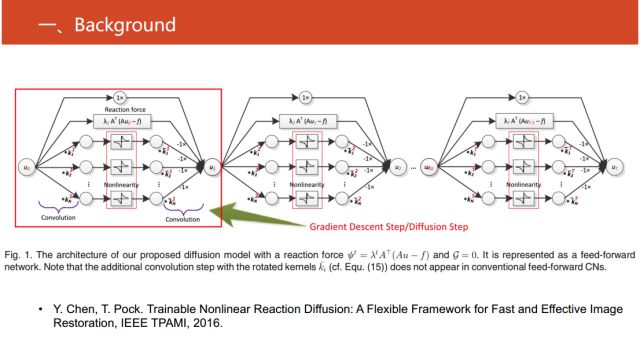
在2016的IEEE TPAMI的《Trainable Nonlinear Reaction Diffusion:
A Flexible Framework for Fast and Effective Image
Restoration》文章中,对图像重构工作进行了这方面研究。
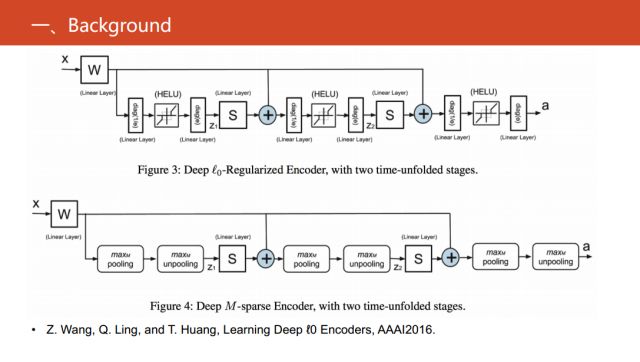
在2016年的AAAI文章《Learning Deep ?0 Encoders》中对0范数的优化问题,进行变形和等价建议的回复式神经网络。
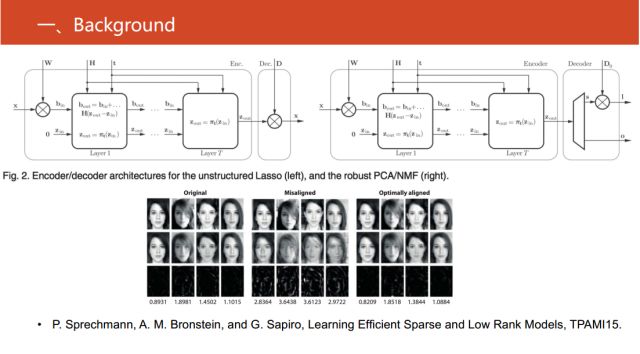
在2015年TPAMI文章《Learning Efficient Sparse and Low Rank
Models》中,对使用深度神经网络来实现稀疏模型和非负矩阵分解之间建模的回复式神经网络。

将这些研究进行归纳总结,就是把一些现有的统计机器学习方法,特别是现有的优化过程展开,形成一个简单的神经网络,且其中大多都是一个简单的回复式神经网络。从而使它能享有传统机器学习的优点,比如端到端学习,同时兼具易于优化以及高可解释性等优点。
我相信这样介绍大家可以有一个直观的概念。目前可微编程就是对传统的机器学习的一个逆向的过程,由于传统的机器学习的结构非常清晰,对逆向过程可以产生的神经网络,就可以知道哪一个激活函数的作用是什么,每一层的输出、目的是什么,这也是现有的深度学习方法所不具备的优势。

下面给大家介绍一下我们的第一个工作。我们这项工作从可微编程出发,来研究稀疏编码的优化方法—ISTA
。

目前,常见的对L1范数优化的方法具有四个局限性:
第一,在优化过程中,对于每一个变量的更新都是采用固定的学习率。所以没有考虑优化变量的每个维度之间的不同。
第二, 这些优化过程并没有考虑历史信息。但是在优化这个研究邻域里已经有大量的工作证明如果考虑历史信息,能够加速算法的收敛。
基于这两点不足,我们提出了自适应的ISTA算法。

还有两个不足是什么呢?
第三,在稀疏编码推理过程中,计算代价很高。
第四,稀疏表示矩阵计算和字典学习是两个分隔开的步骤。但现在流行端到端的训练,也就是同时优化步骤,这样做可能会产生次优的解。
而这两个不足,正好是可微编程能够克服的问题。因此基于这些问题,我们对自适应的ISTA变形和展开提出新的神经网络——SC2Net。


左边是ISTA的关键的优化步骤,基于此,我们引进了动量向量(i(t),f(t))。这就是标准的受益于现代的优化的一些相关的方法,通过引入这两个量,从而解决非自适应更新问题和没有考虑历史信息的不足。更进一步来看,这里存在一个问题,i(t),f(t)如果是两个向量的话,只能确定它的值。使用传统的机器学习方法进行训练,我们人为指定它的值。在研究中,发现可以把这两个向量当成两个变量从数据中学习,就产生了我们提出的自适应ISTA。
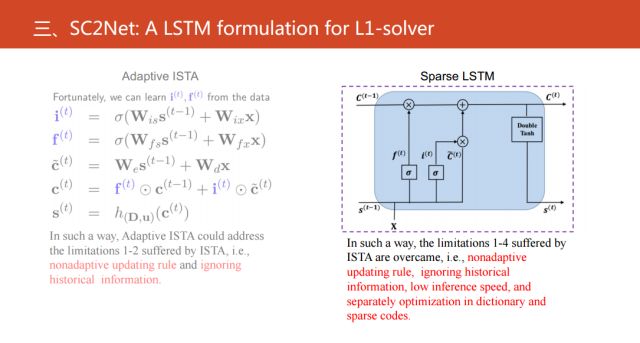
同时,我们还发现这种自适应ISTA可以等价于新的长短期记忆神经网络。具体来看,我们可以认为i和f是等价于LSTM中的input
gate 和output gate。但是需要注意的是,和经典的LSTM相比,自适应的ISTA是没有output
gate。
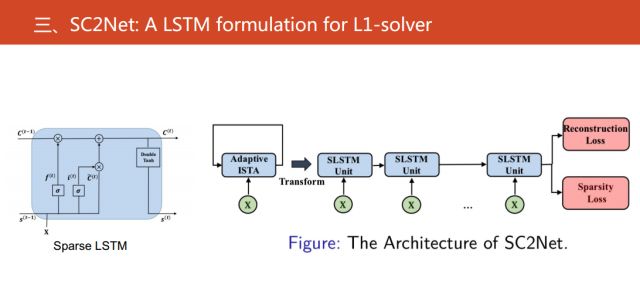
基于以上,我们就组建了Sparse LSTM,并且构建了相应的神经网络结构。
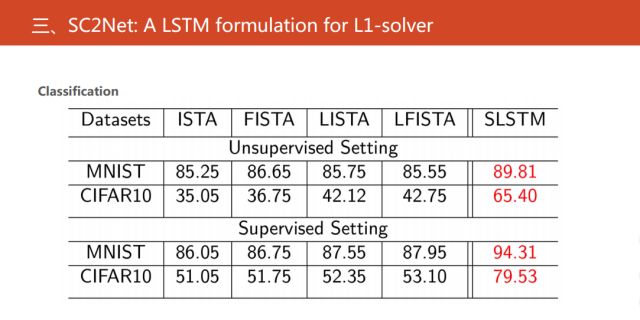
接下来,展示我们的实验结果。在无监督和有监督的特征提取的情况下,对网络的分类性能进行验证。

接下来还进行图像重构,图中显示的是一个重构的误差,越黑就代表误差越小。
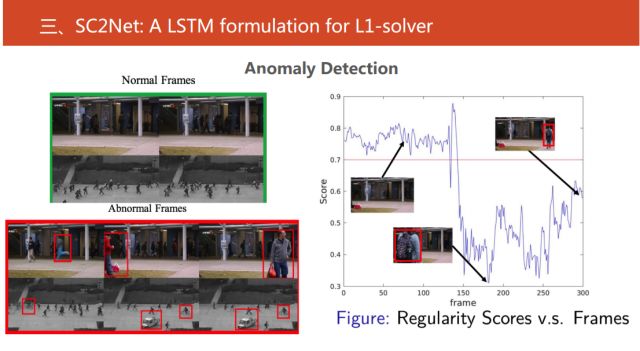
我们还做了视频当中的异常事件的检测,给定一个圈,在圈中的都是正常事件,不在圈中的就是异常事件。接下来使用稀疏重构系数作为指标,找到一定阈值,在这个范围内的都是正常事件,而不在其中的就是异常事件。
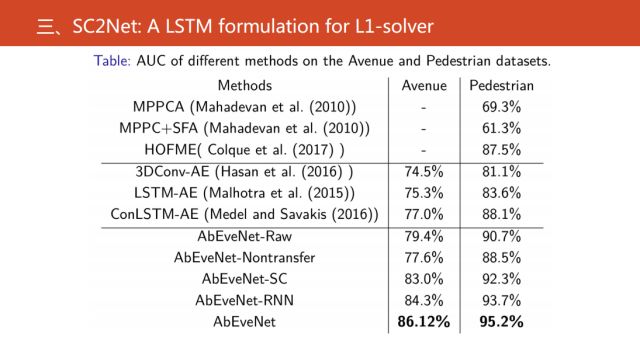
通过实验可以看到,我们的结果是目前是最好的异常事件检测算法。

最后简单地概括一下,相对现有的可微编程,我们是将优化的过程或者说具体的基于LSTM优化的过程和长短期记忆网络,最后掌握了他们之间关系。这对可微编程有一些促进的作用,也可以从另外一个角度理解长短期记忆网络。
刚才我们得到的网络和标准的只有一个区别,就是我们没有Output gate。
相关的代码公开,大家可以扫描上图中的二维码。

第二个工作较之前更进一步,是在聚类这个背景下来扩展,把k-means这个聚类算法转化成为一个前向式记忆网络。不同于现有的可微编程的方法,它是从优化的角度出发,我们直接把k-means聚类算法的目标函数直接进行变形,然后建立对应的神经网络模型。

K-means是什么?
它是在机器学习,计算机视觉,数据挖掘中最为知名的一个算法。主要是利用数据之间的相似性或者不相似性,将数据分为多个簇。最近一二十年,整个聚类的研究领域主要关注的是高维数据的聚类,本质上就是机器学习的共性问题-——线性不可分的问题。

为了解决这个问题,基于核聚类算法,谱聚类,子空间聚类方法,以及近期基于深度神经网络的聚类方法,这些方法都是在解决这个线性不可分的问题。
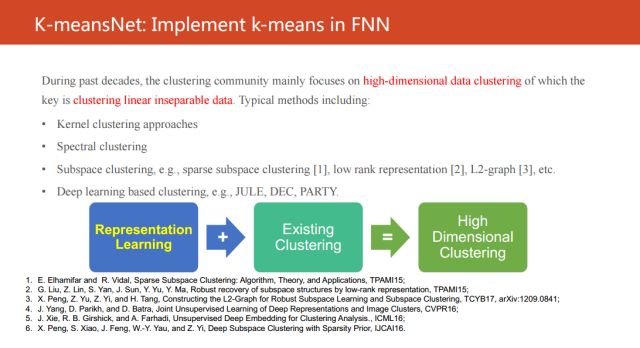
现有的高维聚类方法可以简单地概括成这个图。它们都是用表示学习的方法将不可分的数据投影到另外一个线性可分的空间中,然后再进行聚类。而且现有的研究工作主要都是关注在如何学到一个好的表示。大家都知道,目前深度学习已经成为最为有效的表示学习方法之一,一定意义上可以把“之一”去掉,特别是在数据量较多的情况下。

因此,我们就认为如果表示学习能够用深度神经网络来解决,我们是不是要考虑更多的研究能够实现聚类的神经网络。但是让我们惊讶的是,目前非常少的工作研究能以一个神经网络来实现聚类的,寥寥可数,比较知名一点的比如说自组织映射。

受这个观察的启发,我们思考计划从可微编程的角度对经典的算法进行变形,从而形成一个新的神经网络,从而解决上述的痛点。
这里的公式是k-means的目标函数,其中x是输入,Ω是第j个聚类的中心。我们最终的目标是最小化不同类别之间的相似性,最大化相同类别之间的相似性。

通过对k-means目标函数简单的变形,其实本质上只是把标签只能分配到某一个聚类空间的约束去掉,转变成了输入Xi在第j个聚类中心的概率。

如右图所示的简单变形得到公式(6)和(7),并且我们发现这两个公式是可以等价为一个简洁的前向式神经网络。

如果大家只看左边的神经网络,大家可能会觉得非常不稀奇,好像就是一个很简单的Sigmoid函数,再加上一个隐含层的神经网络。但是如果结合右边的公式来看,就会发现,这么简单的神经网络是等价于K-means的。
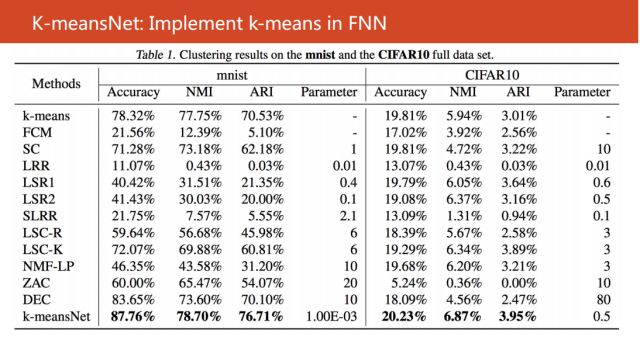
我们在相关的一些数据集上进行验证,比如说我们使用数据mnist和CIFAR10验证神经网络,取得了非常好的效果。
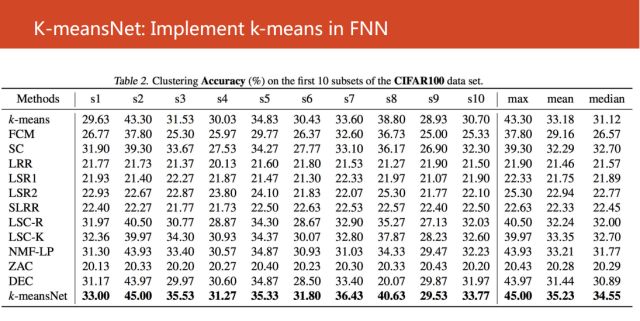
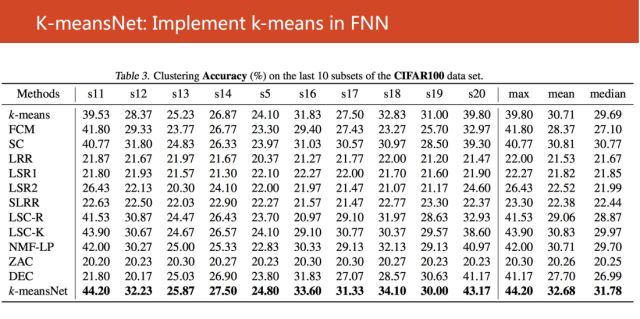
接着我们使用CIFAR100数据的20个子集进行验证,也是取得很不错的结果。
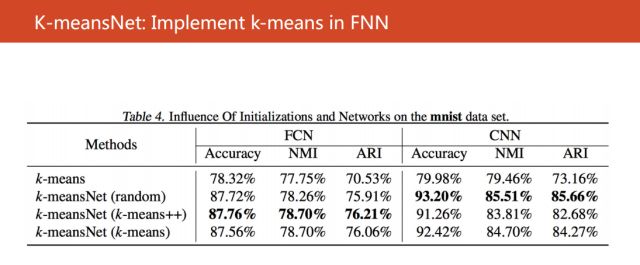
同时我们还考虑使用CNN来发现特征,可以得到超过93%的距离精确度。所以得出一个结论,我们的算法对于距离中心的初始化方法是非常棒的。

这个工作和现有的可微编程不同主要是两点:
第一,我们的研究思路是从目标出发,而不是从优化过程出发进行研究
第二,我们得到的是前向式神经网络,而不是回复式的神经网络。

接下来给大家分享一下我和我的合作伙伴的一些思考。
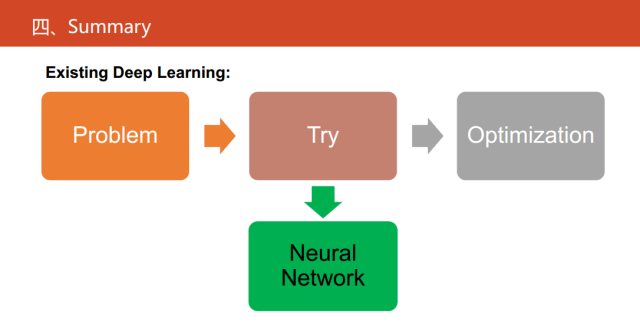
目前,深度学习的研究主要是对通过对一些算法的性能指标不断地试错,最后确定整个网络的结构以及相关的超参,这也是深度学习最为诟病的一点。
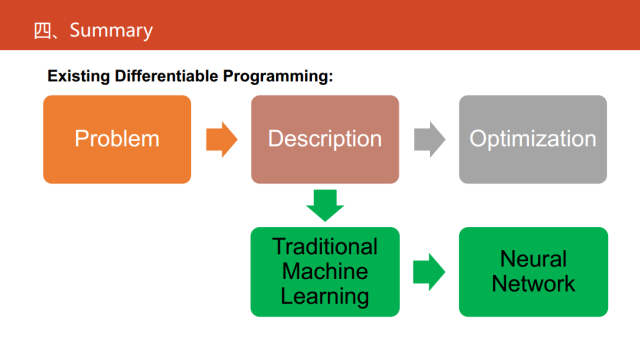
现在深度神经网络已经占据了绝对的优势,可微编程提供了从高解释性的角度去做这件事,它是将神经网络作为一种语言,将传统的算法转化成神经网络以后,一定程度上缓解了一些深度学习的不足。
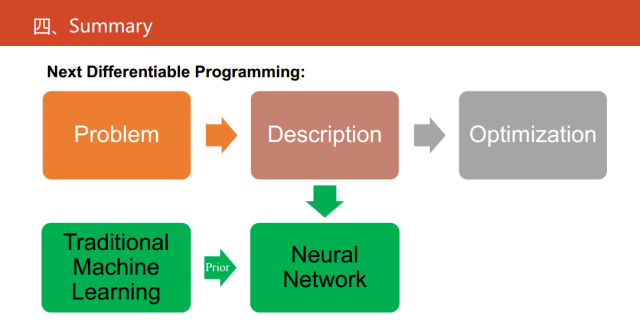
下一步可微编程做什么?现在的可微编程是对传统的继续学习方法的等价或者一种替代物。从问题的描述,再到问题的建模、求解,这是一个很复杂的过程。如果我们对传统的学习的方法,在一定的假设和前提下已经有建好的建模,我们建立等价的神经网络,其实就能走出最容易的一步。
在未来,如果我们真的要贯彻可微编程,就是把它当成一种语言。神经网络应该更进一步,应该直接对问题进行建模,也就是对我们的物理现象进行建模,并且传统的统计机器学习方法有一些先验知识,进而解决我们的一些实际问题。
可能这是更接近于做人工智能这个领域的一个更贴切的思路。
|









