| БрМЭЦМі: |
БОЮФгкcsdnЃЌНщЩмСЫзюМђЕЅЕФЯпадЗжРрЃЌЖрВуМЖЩёОЭјТчЃЌШчКЮбЕСЗЩёОЭјТчЃЌбЕСЗЫуЗЈЕШЁЃ
|
|
ЮвУЧдкЩшМЦЛњЦїбЇЯАЯЕЭГЪБЃЌЬиБ№ЯЃЭћФмЙЛНЈСЂРрЫЦШЫФдЕФвЛжжЛњжЦЁЃЩёОЭјТчОЭЪЧЦфжавЛжжЁЃЕЋЪЧПМТЧЕНЪЕМЪЧщПіЃЌвЛАуЕФЩёОЭјТчЃЈBPЭјТчЃЉВЛашвЊЩшМЦЕФФЧУДИДдгЃЌВЛашвЊАќКЌЗДРЁКЭЕнЙщЁЃ
ШЫЙЄжЧФмЕФвЛДѓживЊгІгУЃЌЪЧЗжРрЮЪЬтЁЃБОЮФЭЈЙ§ЗжРрЕФР§згЃЌРДНщЩмЩёОЭјТчЁЃ
1.зюМђЕЅЕФЯпадЗжРр
вЛИізюМђЕЅЕФЗжРрЃЌЪЧдкЦНУцЩЯЛвЛЬѕжБЯпЃЌзѓБпЮЊРр0ЃЌгвБпЮЊРр1ЃЌжБЯпБэЪОЮЊ
етЪЧвЛИіЗжРрЦїЃЌЪфШы(x,y)ЃЌФЧУДЃЌвЊЧѓЕФВЮЪ§гаШ§Иі:a,b,cЁЃСэЭтзЂвтcЕФзїгУЃЌШчЙћУЛгаcЃЌетЬѕжБЯпвЛЖЈЛсЙ§дЕуЁЃ
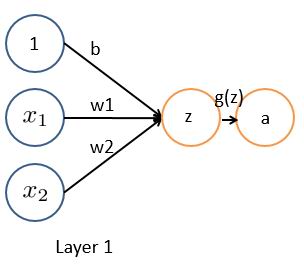
вђДЫЃЌЮвУЧПЩвдЩшМЦвЛИіМђЕЅЕФЩёОЭјТчЃЌАќКЌСНВуЃЌЪфШыВугаШ§ИіНкЕуЃЌДњБэx,y,1ЃЌШ§ЬѕЯпЗжБ№ДњБэa,b,cg(z)ЖдДЋШыЕФжЕxНјааХаБ№ЃЌВЂЪфГіНсЙћЁЃ
ЕЋЪЧЃЌгЩгкzЕФжЕПЩФмЮЊ[],ЮЊСЫЗНБуДІРэЃЌашвЊНЋЦфбЙЫѕЕНвЛИіКЯРэЕФЗЖЮЇЃЌЛЙашsigmoidКЏЪ§:
етбљЕФМЄРјКЏЪ§ЃЌФмЙЛНЋИеВХЕФЧјМфЃЌбЙЫѕЕН
ЁЃ
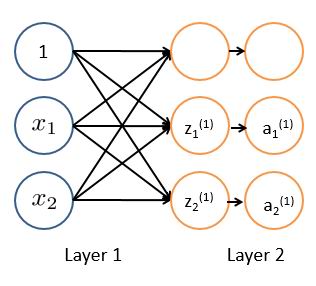
2.ЖрВуМЖЩёОЭјТч
ИеВХеЙЪОСЫзюМђЕЅЕФЖўЗжРрЃЌШчЙћгаЫФИіЗжРрЃЌФЧвЛЬѕЯпОЭЮоЗЈТњзувЊЧѓСЫЁЃЯыЯѓСНЬѕжБЯпЃЌОЭЛсНЋЦНУцЛЎЗжЮЊЫФИіЧјгђЃЌвЛИіШ§НЧЧјгђЯрЕБгкСНИізгЦНУцЧѓНЛМЏЁЃ
вђДЫжБОѕИцЫпЮвУЧЃЌШчЙћгаЖрИіЩёОдЊЃЌФЧУДетбљЕФЮЪЬтФмБэЯжЮЊЮЪЬтЕФЁАТпМгыЁБВйзїЁЃНЋЕквЛНкжаНщЩмЕФЩёОЭјТчЕФЪфГіЃЌдйзівЛИіХаЖЯВуЃЌМДЖрВуЭјТчЁЃ
ЕЋЪЧЃЌШчКЮЪЕЯжТпМгыФиЃПгУЯТУцЕФЭМвЛФПСЫШЛЃК
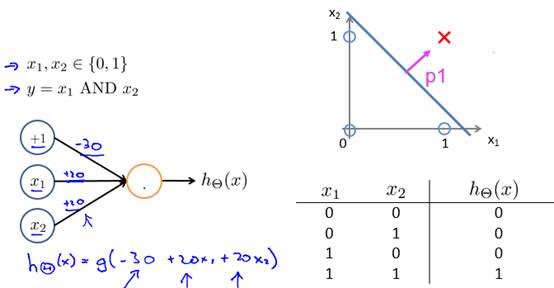
заЯИПДЯТЃЌетЯрЕБгкДДНЈвЛЬѕЯпЃЌГ§ЗЧКЭЖМЕШгк1ЃЌЗёдђЁЃ
НјвЛВНЕиЃЌШчЙћЮвУЧФмЙЛЖдЧјгђЧѓВЂМЏЃЌФЧУДзмПЩвдЖдВЛЭЌЕФзгЧјгђЧѓВЂЁЃЖјЪЕЯжВЂВйзїКЭгыВйзїЪЧРрЫЦЕФЃК 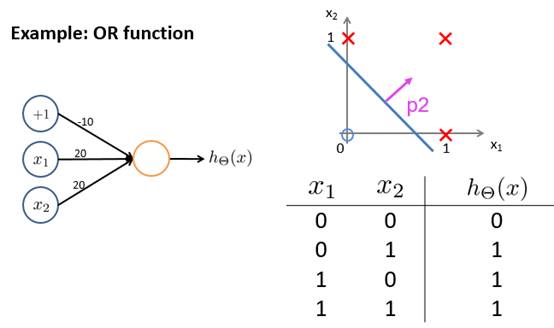
ДЫДІОЭФмПДЕНsigmoidКЏЪ§ЕФзїгУСЫЃЌШчЙћУЛгаЫќЖдЪ§жЕЕФЗХЫѕЃЌВЂКЭгыЕФВйзїОЭЮоЗЈЪЕЯжСЫЁЃ
ЪфГіЛЙФмзїЮЊЯТвЛМЖЕФЪфШыЃЌДгЖјдіМгСЫвЛИівўВуЃЌВњЩњСЫЕЅвўВуЩёОЭјТчЃЌдйИДдгвЛаЉЃЌШчЙћЭјТчВуЪ§ЬиБ№ЖрЃЌдђНазіЩюЖШбЇЯАЭјТчЃЌМђГЦЩюЖШбЇЯАЁЃ 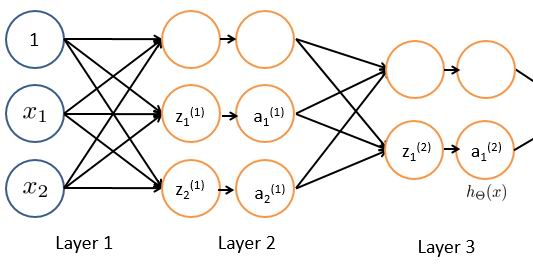
жЎЧАеыЖдвЛИіЯпадВЛПЩЗжЕФЧјгђЃЌашвЊНЋЦфБфЛЛЕНИќИпЮЌЖШЕФПеМфШЅДІРэЁЃЕЋШчЙћгУЩёОЭјТчЃЌФузмПЩвдЭЈЙ§nЬѕжБЯпЃЌНЋећИіЧјМфЮЇЦ№РДЁЃжЛвЊжБЯпЪ§СПЙЛЖрЃЌзмФмЛцжЦГіШЮвтИДдгЕФЧјгђЁЃУПвЛИізгЧјгђЖМЪЧЭЙгђЃК 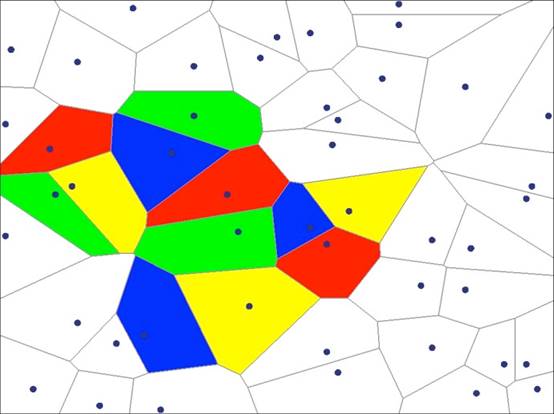
МђжБВЛФмИќПсЃЁЯТУцетеХЭМзмНсСЫВЛЭЌРраЭЕФЩёОЭјТчОпБИЕФЙІФмЃК 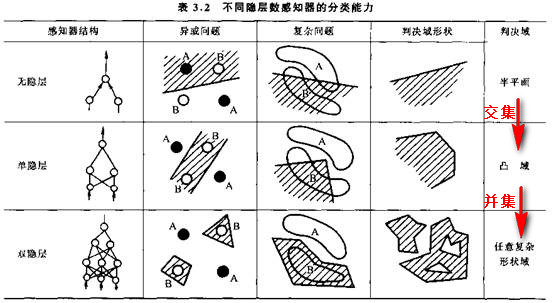
Ъ§бЇМвжЄУїСЫЃЌЫЋвўВуЩёОЭјТчФмЙЛНтОіШЮвтИДдгЕФЗжРрЮЪЬтЁЃЕЋЮвУЧЕФЮЪЬтЕНДЫЮЊжЙСЫТ№ЃПВЛМћЕУЃЁ
етРяЛЙгаМИИіЮЪЬтЃК
вьЛђШчКЮЪЕЯжЃПвьЛђПЯЖЈЪЧВЛФмЭЈЙ§вЛЬѕжБЯпЧјЗжЕФЃЌвђДЫЕЅВуЭјТчЮоЗЈЪЕЯжвьЛђЃЌЕЋСНВуЃЈАќКЌвЛИівўВуЃЉОЭПЩвдСЫЁЃ
Й§ФтКЯЮЪЬтЃКЙ§ЖрЕФвўВуНкЕуЃЌПЩФмЛсНЋбЕСЗМЏРяЕФЕуШЋВПЮЇНјШЅЃЌетбљЯЕЭГОЭУЛгаРЉеЙадСЫЁЃШчКЮЗРжЙЙ§ФтКЯЃП
ШчКЮбЕСЗЃКШчКЮМЦЫуГіКЯРэЕФЩёОЭјТчВЮЪ§ЃПЃЈвўВуНкЕуЪ§ЃЉ
3.ШчКЮбЕСЗЩёОЭјТч
ШчЙћвЛИіЦНУцЃЌга6ИіЕуЃЌЗжГЩШ§РрЁЃШчКЮЩшМЦФиЃП 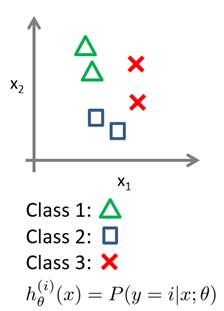
вЛжжзюПёБЉЕФЗНЗЈЃЌЪЧЖдУПвЛИіЕуЖМгУЫФЬѕЯпЮЇЦ№РДЃЌжЎКѓЃЌдйЖдСљИіЧјгђСНСНШЁВЂМЏЁЃаЮГЩЯТУцетеХГЌИДдгЕФЭМЃК 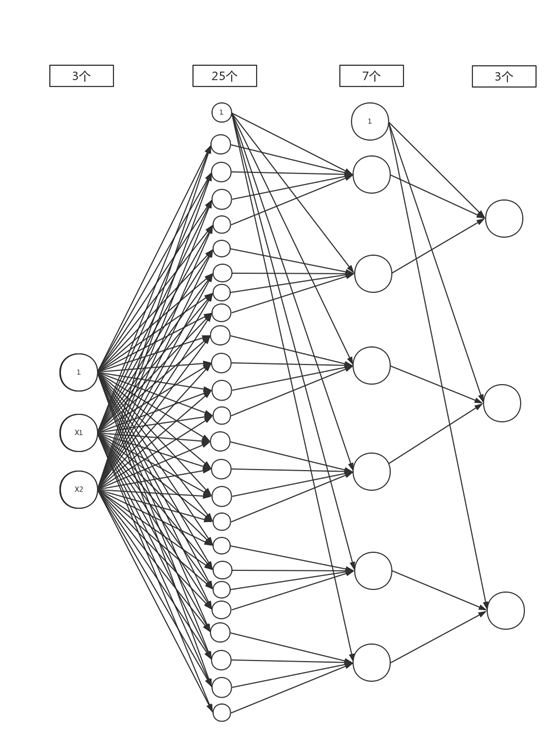
НтЪЭвЛЯТЮЊЪВУДвЊгаетУДЖрИіНкЕуЃК
ЕквЛВуЃКx,yдйМгbias,Ш§Иі
ЕкЖўВуЃКУПИіЕуашвЊЫФЬѕЯпЮЇЦ№РДЃЌМгЩЯbiasЃЌзмЙВ4*6+1=25Иі
ЕкШ§ВуЃКвЛИіНкЕуДІгкИУРрЕФЬѕМўЪЧдкЫФЬѕЯпЕФжаМфЃЈНЛМЏЃЉЃЌвђДЫУПЫФИіЕуЛуГЩвЛИіЕуЃЌ24/
4+1 = 7Иі
ЕкЫФВуЃКШ§ЗжРрЮЪЬтЃЌашвЊЖдУПСНИіЧјгђЧѓВЂМЏЃЌвђДЫашвЊ6 /2+1
= 4Иі
ЕЋетбљЕФНтЗЈЃЌЪЙгУСЫ3+25+7+4=39ИіНкЕуЃЌашвЊ111ИіВЮЪ§ЁЃетбљЕФЯЕЭГЗЧГЃИДдгЃЌЖдЮДжЊНкЕуМИКѕУЛгаШЮКЮРЉеЙадЁЃ
заЯИЫМПМетИіЮЪЬтЃЌ ЮвУЧФмЙЛЭЈЙ§ИќЩйЕФНкЕуКЭВуЪ§ЃЌРДМђЛЏетИіЮЪЬтТяЃПжЛвЊШ§ЬѕжБЯпОЭПЩвдЃЁНкЕуЪ§СПДѓДѓМѕЩйЁЃВЛНібЕСЗаЇТЪИќИпЃЌЖјЧвПЩРЉеЙФмСІКмЧПЁЃЖдИќИДдгЕФР§згЃЌЮвУЧгжВЛЪЧЩёЯЩЃЌдѕУДжЊЕРЩшМЦМИИівўВуКЭЖрЩйИіНкЕуФиЃП
ЫљЮНГЌВЮЪ§ЃЌОЭЪЧФЃаЭжЎЭтЕФВЮЪ§ЃЌдкетИіР§згжаЃЌОЭЪЧвўВуЕФЪ§СПКЭНкЕуЕФЪ§СПЁЃЭЈГЃРДЫЕЃЌЯпадЗжРрЦїЃЈЛиЙщЃЉжЛашвЊСНВуМДПЩЃЌЖдгквЛАуЕФЗжРрЮЪЬтЃЌШ§ВузуЙЛЁЃ
вЛИіШ§ВуЕФЩёОЭјТчЃЌЪфШыКЭЪфГіНкЕуЕФЪ§СПвбОШЗЖЈЃЌФЧШчКЮШЗЖЈжаМфВуЃЈвўВуЃЉЕФНкЕуЪ§СПФиЃПвЛАугаМИИіОбщЃК
вўВуНкЕуЪ§СПвЛЖЈвЊаЁгкN-1(NЮЊбљБОЪ§)
бЕСЗбљБОЪ§гІЕБЪЧСЌНгШЈЃЈЪфШыЕНЕквЛвўВуЕФШЈжЕЪ§ФП+ЕквЛвўВуЕНЕкЖўвўВуЕФШЈжЕЪ§ФП+...ЕкNвўВуЕНЪфГіВуЕФШЈжЕЪ§ФПЃЌВЛОЭЪЧБпЕФЪ§СПУДЃЉЕФ2-10БЖЃЈвВгаНВ5-10БЖЕФЃЉЃЌСэЭтЃЌзюКУНЋбљБОНјааЗжзщЃЌЖдФЃаЭбЕСЗЖрДЮЃЌвВБШвЛДЮадШЋВПЫЭШыбЕСЗЧПКмЖрЁЃ
НкЕуЪ§СПОЁПЩФмЩйЃЌМђЕЅЕФЭјТчЗКЛЏФмСІЭљЭљИќЧП
ШЗЖЈвўВуНкЕуЕФЯТЯоКЭЩЯЯоЃЌвРДЮБщРњЃЌевЕНЪеСВЫйЖШНЯПьЃЌЧвадФмНЯИпЕФНкЕуЪ§
ШчКЮБэЪОвЛИіЩёОЭјТчЃПЭјТчгаmВуЃЌУПВуЕФНкЕуЗжБ№ЮЊЃЌНкЕузюЖрЕФВуЃЌгаmИіНкЕуЃЌФЧУДЮвУЧПЩвдНЋЦфБэДяЮЊвЛИіОиеѓW,ЙцФЃЮЊЃЌФкВПгааЉжЕЪЧУЛгаЖЈвхЕФЁЃ
4.бЕСЗЫуЗЈ
ЯпадПЩЗж
ШчЙћЪфШыКЭЪфГіЪЧЯпадЙиЯЕЃЈЛђепЪЧе§ЯрЙиЃЉЃЌФЧУДЯыЯѓЮвУЧдкЕїНквЛИіВЮЪ§ЪБЃЌЕБЪфГіЙ§ДѓЃЌФЧОЭАбЪфШыЕїаЁвЛаЉЃЌЗДжЎЕїДѓвЛаЉЃЌзюКѓЕБЪфГіКЭЮвУЧЯывЊЕФЗЧГЃНгНќЪБЃЌбЕСЗНсЪјЁЃетИіОЭКУБШЃЌдкЦНУцЩЯЃЌШчЙћвЛИіЕуБЛЗжХфЕНСЫДэЮѓЕФЪфГіЃЌОЭгІИУЖджБЯпЦНвЦКЭХЄзЊЃЌМѕЩйИУжБЯпЕНетИіЕуЕФОрРыЃЌДгЖјЪЕЯжжиаТЗжЧјЁЃ
НјвЛВНЕиЃЌШчЙћЯђСПЕФЖрИіЗжСПЛЅЯрЖРСЂЃЌФЧУДЗНЗЈвВКЭЩЯУцЕФРрЫЦЃЌЗжБ№ЕїНкКЭЕФВЮЪ§ЃЌзюжеШУНсЙћНгНќЃЌбЕСЗНсЪјЁЃ
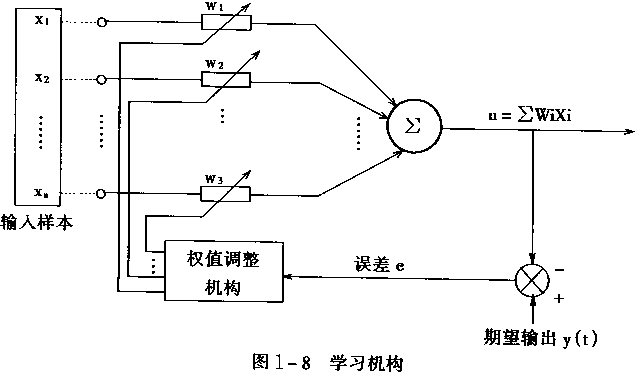
ЖјвЛИіИажЊЦїНсЙЙПЩБэЪОШчЯТЃК
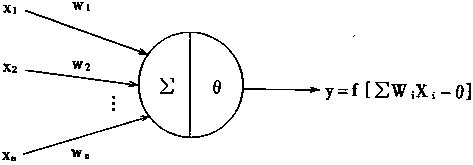
ЗДЫМЩЯУцЕФЙ§ГЬЃЌЮвУЧЪЕМЪЩЯЪЧдкКтСПЮѓВюЃЌИљОнЮѓВюРДаоИФШЈжиЁЃ
ЯпадВЛПЩЗж
ШчЙћЪфШыКЭЪфГіЕФЙиЯЕБШНЯИДдгЃЌШчЖўДЮКЏЪ§ЃЌФЧЕБГЌЙ§x=0ЕФЮЛжУжЎКѓЃЌЗДЖјГЩСЫЕндіСЫЃЌДЫЪБвЛИіЯпадЕФХаЖЯКЏЪ§ОЭВЛЦ№зїгУСЫЁЃвђДЫЃЌЩЯУцЕФЗНЗЈЃЌВЛФмЭЦЙуЕНЫљгаЕФЧАРЁЭјТчжаЁЃ
дѕУДАьЃПФЧОЭжЛФмЪЙгУЬнЖШ(LMS)ЗЈСЫЁЃ
ЬнЖШЗЈЃЌЪЧЖдгкбљБОМЏЃЌевЕНвЛИі,ЪЙЕУгыЪфГіОЁПЩФмНгНќЃЌЦфжаЪЧМЄРјКЏЪ§ЁЃЮѓВюБэЪОЮЊЃК
ЮЊСЫФмЙЛЕїНкЮѓВюe,ЪЙжЎОЁПЩФмаЁЃЌдђашвЊЧѓЦфЕМЪ§ЃЌЗЂЯжЦфЯТНЕЕФЗНЯђЃК
Цфжа:
ЖдЦЋЕМНјааЧѓНтЃК
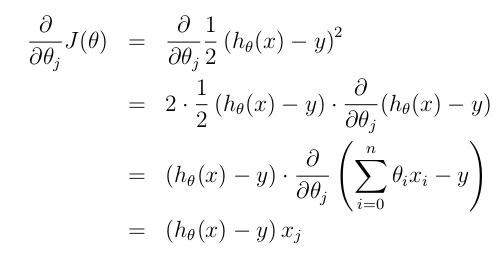
УПДЮЕќДњЕФМЦЫуЙЋЪНЮЊЃК
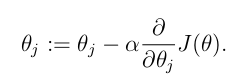
зюжеЃК 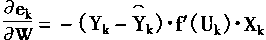
ЦфМИКЮвтвхОЭЪЧЃЌЮѓВюЕФЦЋЕМЃЌЕШгкдкЮЛжУЩЯЕФжЕЃЌГЫвдЮѓВюЃЌдйГЫвдМЄРјКЏЪ§ЕФЦЋЕМЁЃ
ЫљвдЃЌУПДЮЕФШЈжиОиеѓЕФаоИФЃЌгІЕБЭЈЙ§ЧѓЮѓВюЕФЦЋЕМЃЈЬнЖШЃЉРДЪЕЯжЁЃБШжЎЧАЕФжБНгЭЈЙ§ЮѓВюРДЕїећЃЌОпБИИќКУЕФЪЪгІадЁЃ
ЕЋЪЧЃЌетбљЕФЬнЖШЗЈЃЌЖдгкЪЕМЪбЇЯАРДЫЕЃЌаЇТЪЛЙЪЧЬЋТ§ЃЌЮвУЧашвЊИќПьЕФЪеСВЗНЗЈЁЃ
BPЫуЗЈ
BPЫуЗЈОЭЪЧЫљЮНЕФЗДЯђДЋВЅЫуЗЈЃЌЫќНЋЮѓВюНјааЗДЯђДЋВЅЃЌДгЖјЛёШЁИќИпЕФбЇЯАаЇТЪЁЃетКмЯёЗщЛ№ЬЈЃЌШчЙћЧАЯпеНАмСЫЃЌФЧУДЯћЯЂОЭЭЈЙ§ЗщЛ№ЬЈДЋЕнЛижИЛгВПЃЌжИЛгВПШЅЗДЫМЮЪЬтЃЌзюжеИФБфВпТдЁЃ
ЕЋетДјРДвЛИіЮЪЬтЃЌжаМфВуЕФЮѓВюдѕУДМЦЫуЃПЮвУЧФмМђЕЅЕиНЋШЈжиКЭВаВюЕФГЫЛ§ЃЌЗЕЛиИјЩЯвЛВуНкЕуЃЈетжжЯыЗЈецБЉСІЃЌДгзѓЕНгвКЭДггвЕНзѓЪЧвЛбљЕФЃЉЁЃ 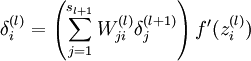
етЯрЕБгкШ§ДЮДЋВЅЃК
-ЕквЛВНЃКДгЧАЯђКѓДЋВЅFP
-ЕкЖўВНЃКЕУЕНжЕzЃЌЮѓВюЮЊy,НЋЮѓВюЗДЯђДЋВЅЃЌЛёЕУУПИіНкЕуЕФЦЋВю$\sigma$
-ЕкШ§ВНЃКдйДЮе§ЯђДЋВЅЃЌЭЈЙ§ЩЯвЛВНЕФ$\sigma$ЃЌдйГЫвдВНГЄЃЌаоИФУПвЛИіЩёОдЊЭЛДЅЕФШЈжиЁЃ
ЯТУцвЛеХЭМеЙЪОСЫЭъећЕФBPЫуЗЈЕФЙ§ГЬЃЌЮвПДСЫВЛЯТ20БщЃК 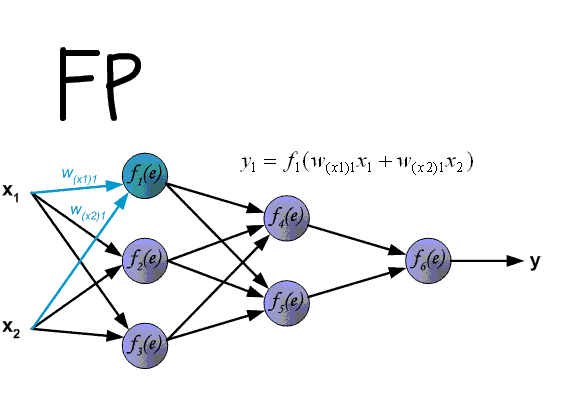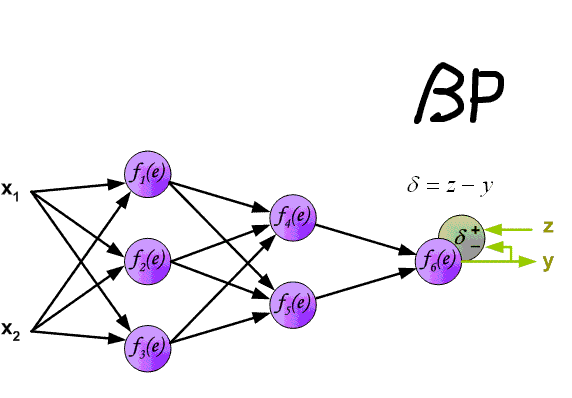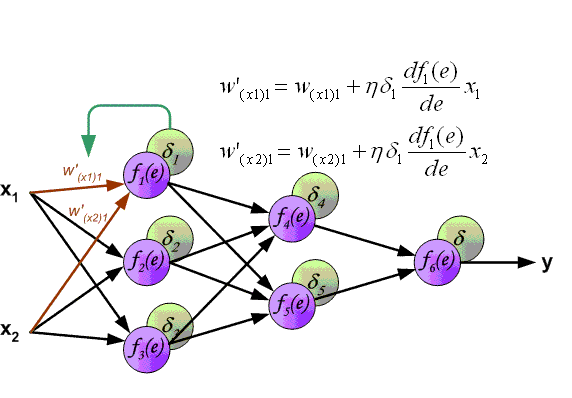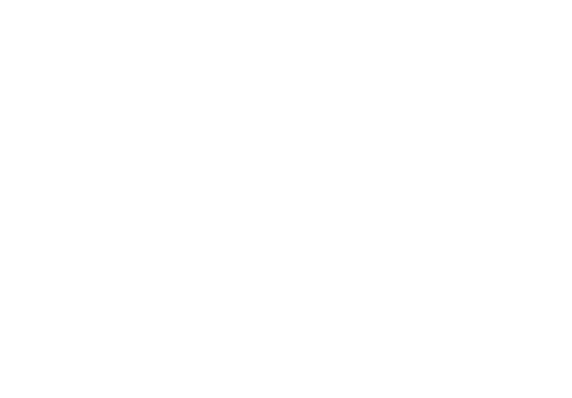
ИќгаШЄЕФЪЧЃЌsigmoidЧѓЕМжЎКѓЃЌЬиБ№ЯёИпЫЙЃЈе§ЬЌЃЉЗжВМЃЌЖјЧвsigmoidЧѓЕМЗЧГЃШнвзЁЃ
|









