| БрМЭЦМі: |
БОЮФгкcloud.tencent.comЃЌНщЩмСЫЕфаЭЫуЗЈЃЌCLIQUEОлРрЫуЗЈЃЌWaveClusterЫуЗЈЃЌWaveClusterОлРрЫуЗЈЕШЁЃ
|
|
ЫзЛАЫЕЃКЁАЮявдРрОлЃЌШЫвдШКЗжЁБЃЌдкЛњЦїбЇЯАжаЃЌОлРрЫуЗЈЪЧвЛжжЮоМрЖНЗжРрЫуЗЈЁЃОлРрЫуЗЈКмЖрЃЌАќРЈЛљгкЛЎЗжЕФОлРрЫуЗЈЃЈШчЃКkmeansЃЉЃЌЛљгкВуДЮЕФОлРрЫуЗЈЃЈШчЃКBIRCHЃЉЃЌЛљгкУмЖШЕФОлРрЫуЗЈЃЈШчЃКDBScanЃЉЃЌЛљгкЭјИёЕФОлРрЫуЗЈЕШЕШЁЃЛљгкЛЎЗжКЭВуДЮОлРрЗНЗЈЖМЮоЗЈЗЂЯжЗЧЭЙУцаЮзДЕФДиЃЌеце§ФмгааЇЗЂЯжШЮвтаЮзДДиЕФЫуЗЈЪЧЛљгкУмЖШЕФЫуЗЈЃЌЕЋЛљгкУмЖШЕФЫуЗЈвЛАуЪБМфИДдгЖШНЯИпЃЌ1996ФъЕН2000ФъМфЃЌбаОПЪ§ОнЭкОђЕФбЇепУЧЬсГіСЫДѓСПЛљгкЭјИёЕФОлРрЫуЗЈЃЌЭјИёЗНЗЈПЩвдгааЇМѕЩйЫуЗЈЕФМЦЫуИДдгЖШЃЌЧвЭЌбљЖдУмЖШВЮЪ§УєИаЁЃ
ЕфаЭЫуЗЈ
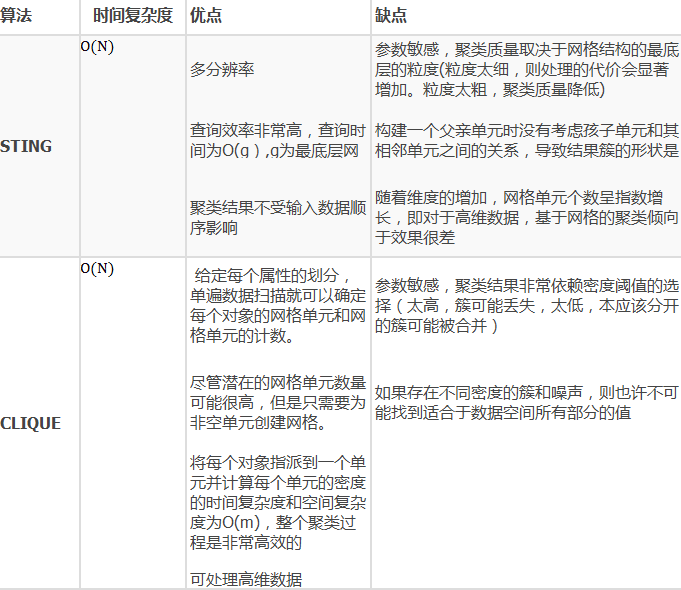
STINGЃКЛљгкЭјИёЖрЗжБцТЪЃЌНЋПеМфЛЎЗжЮЊЗНаЮЕЅдЊЃЌЖдгІВЛЭЌЗжБцТЪ
CLIQUEЃКНсКЯЭјИёКЭУмЖШОлРрЕФЫМЯыЃЌзгПеМфОлРрДІРэДѓЙцФЃИпЮЌЖШЪ§Он
WaveClusterЃКгУаЁВЈЗжЮіЪЙДиЕФБпНчБфЕУИќМгЧхЮњ
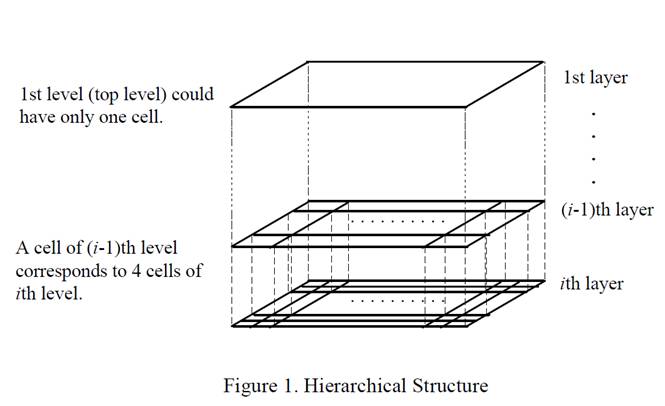
етаЉЫуЗЈгУВЛЭЌЕФЭјИёЛЎЗжЗНЗЈЃЌНЋЪ§ОнПеМфЛЎЗжГЩЮЊгаЯоИіЕЅдЊЃЈcellЃЉЕФЭјИёНсЙЙ,ВЂЖдЭјИёЪ§ОнНсЙЙНјааСЫВЛЭЌЕФДІРэЃЌЕЋКЫаФВНжшЪЧЯрЭЌЕФЃК
1ЁЂ ЛЎЗжЭјИё
2ЁЂ ЪЙгУЭјИёЕЅдЊФкЪ§ОнЕФЭГМЦаХЯЂЖдЪ§ОнНјаабЙЫѕБэДя
3ЁЂ ЛљгкетаЉЭГМЦаХЯЂХаЖЯИпУмЖШЭјИёЕЅдЊ
4ЁЂ зюКѓНЋЯрСЌЕФИпУмЖШЭјИёЕЅдЊЪЖБ№ЮЊДи
Statistical Information Grid(STING)ЫуЗЈ
STINGЫуЗЈЕФКЫаФЫМЯыЃКЪзЯШЮвУЧЯШЛЎЗжвЛаЉВуДЮЃЌУПИіВуДЮЩЯЮвУЧИљОнЮЌЖШЛђепИХФюЗжВуВЛЭЌЕФcellЃЌЪЕМЪЩЯетРяЕФУПИіВуДЮЖдгІЕФЪЧбљБОЕФвЛИіЗжБцТЪЁЃУПИіИпВуЕФcellдкЦфЯТвЛВужаБЛЖдгІЕУЛЎЗжГЩЖрИіcellЃЌУПИіcellЮвУЧЖММЦЫуГіЫќЕФЭГМЦаХЯЂЃЌЙРМЦГіЫќЕФЗжВМЁЃРћгУетбљЕФНсЙЙЃЌЮвУЧКмШнвзНјааВщбЏЃЌБШШчЮвУЧВщбЏОпгаФГаЉЪєадЕФбљБОЃЌЮвУЧДгЩЯЕНЯТПЊЪМЃЌИљОнcellЕФЭГМЦаХЯЂМЦЫуqueryдкУПИіcellЕФжУаХЧјМфЃЌевГізюДѓЕФФЧИіcellЃЌШЛКѓЕНЯТвЛВуЃЌвРДЮжБжСЕНзюЕзВуЁЃетбљЕФКУДІЪЧЃЌЮвУЧВЛгУМЦЫуЫљгаЕФбљБОЃЌЫуЗЈУПНјвЛВуЖМЛсХзЦњВЛЯрЙиЕФбљБОЃЌЫљашЕФМЦЫуСПЛсдНРДдНЩйЃЌФЧУДЫйЖШОЭЛсКмПьЁЃ
етжжЗНЗЈЫфШЛВЛЪЧвЛжжЯдШЛЕФОлРрЗЈЃЌЕЋЫќШЗЪЕПЩвдгУРДОлРрЃЌвђЮЊqueryЗЕЛиЕФбљБОЪЕМЪЩЯОЭЪЧФГвЛОлРрЁЃQueryБОжЪЩЯгкОлРрЮЪЬтЪЧгаЕШМладЕФЁЃ
STINGЫуЗЈЕФСНИіВЮЪ§ЃК
ЭјИёЕФВНГЄЁЊЁЊШЗЖЈПеМфЭјИёЛЎЗж
УмЖШуажЕЁЊЁЊЭјИёжаЖдЯѓЪ§СПДѓгкЕШгкИУуажЕБэЪОИУЭјИёЮЊГэУмЭјИё
STINGЭјИёНЈСЂСїГЬ
1 .ЪзЯШЮвУЧЯШЛЎЗжвЛаЉВуДЮЃЌАДВуДЮЛЎЗжЭјИё
2 .МЦЫузюЕзВуЕЅЮЛЭјИёЕФЭГМЦаХЯЂЃЈШчОљжЕЃЌзюДѓжЕКЭзюаЁжЕЃЉЃЛ
ЭјИёжаЭГМЦаХЯЂЃК
n ЁЊЁЊ ЭјИёжаЖдЯѓЪ§ФП
m ЁЊЁЊ ЭјИёжаЫљгажЕЕФЦНОљжЕ
s ЁЊЁЊ ЭјИёжаЪєаджЕЕФБъзМЦЋВю
min ЁЊЁЊ ЭјИёжаЪєаджЕЕФзюаЁжЕ
max ЁЊЁЊ ЭјИёжаЪєаджЕЕФзюДѓжЕ
distribution ЁЊЁЊ ЭјИёжаЪєаджЕЗћКЯЕФЗжВМРраЭЁЃШче§ЬЌЗжВМЃЌОљдШЗжВМЃЌжИЪ§ЗжВМ
1ЃЉзюЕзВуЕФЕЅдЊВЮЪ§жБНггЩЪ§ОнМЦЫуЃЌИИЕЅдЊИёЭГМЦаХЯЂгЩЦфЖдгІЕФзгЕЅдЊИёМЦЫуЃЌОпЬхМЦЫуЙЋЪНМћ2ЃЉ3ЃЉ
2ЃЉИИЕЅдЊИёМЦЫуЙЋЪНШчЯТ
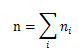
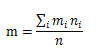
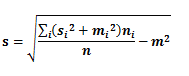
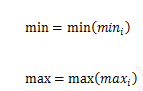
3ЃЉИИЕЅдЊИёdistribution МЦЫуЗНЪН
ЩшdistЮЊЖдгІзгЕЅдЊИёЖрЪ§ЕФЗжВМРраЭЃЌМЦЫуconfl
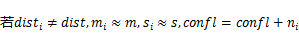
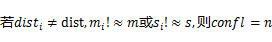
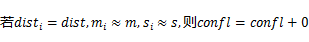
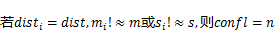
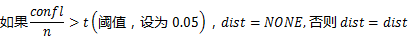
ЪОР§ЃКИљОнвдЯТзгЭјИёМЦЫуИИЭјИёЕФВЮЪ§
n = 220
m = (20.1100)+(19.750+2160+20.510)/220=2260/220=20.27
s = 2.37
min = 3.8
max = 40
dist = NORMAL
3 .ДгзюЕзВуж№ВуМЦЫуЩЯвЛВуУПИіИИЕЅдЊИёЕФЭГМЦаХЯЂЃЌжБЕНзюЖЅВуЃЛ
4 .ЭЌЪБИљОнУмЖШуажЕБъМЧГэУмЭјИё
STINGВщбЏЫуЗЈВНжшЃК
ЃЈ1ЃЉ ДгвЛИіВуДЮПЊЪМ
ЃЈ2ЃЉ ЖдгкетвЛИіВуДЮЕФУПИіЕЅдЊИёЃЌЮвУЧМЦЫуВщбЏЯрЙиЕФЪєаджЕЁЃ
ЃЈ3ЃЉ ДгМЦЫуЕФЪєаджЕвдМАдМЪјЬѕМўЯТЃЌЮвУЧНЋУПвЛИіЕЅдЊИёБъМЧГЩЯрЙиЛђепВЛЯыЙиЁЃ(ВЛЯрЙиЕФЕЅдЊИёВЛдйПМТЧЃЌЯТвЛИіНЯЕЭВуЕФДІРэОЭжЛМьВщЪЃгрЕФЯрЙиЕЅдЊ)
ЃЈ4ЃЉ ШчЙћетвЛВуЪЧЕзВуЃЌФЧУДзЊЃЈ6ЃЉЃЌЗёдђзЊЃЈ5ЃЉ
ЃЈ5ЃЉ ЮвУЧгЩВуДЮНсЙЙзЊЕНЯТвЛВуЃЌвРееВНжш2Нјаа
ЃЈ6ЃЉ ВщбЏНсЙћЕУЕНТњзуЃЌзЊЕНВНжш8ЃЌЗёдђЃЈ7ЃЉ
ЃЈ7ЃЉ ЛжИДЪ§ОнЕНЯрЙиЕФЕЅдЊИёНјвЛВНДІРэвдЕУЕНТњвтЕФНсЙћЃЌзЊЕНВНжшЃЈ8ЃЉ
ЃЈ8ЃЉ ЭЃжЙ
CLIQUEОлРрЫуЗЈ
CLIQUEЫуЗЈЪЧНсКЯСЫЛљгкУмЖШКЭЛљгкЭјИёЕФОлРрЫуЗЈЃЌвђДЫМШФмЙЛЗЂЯжШЮвтаЮзДЕФДиЃЌгжПЩвдДІРэИпЮЌЪ§ОнЁЃ
CLIQUEЫуЗЈКЫаФЫМЯыЃКЪзЯШЩЈУшЫљгаЭјИёЁЃЕБЗЂЯжЕквЛИіУмМЏЭјИёЪБЃЌБувдИУЭјИёПЊЪМРЉеЙЃЌРЉеЙддђЪЧШєвЛИіЭјИёгывбжЊУмМЏЧјгђФкЕФЭјИёСкНгВЂЧвЦфЦфздЩэвВЪЧУмМЏЕФЃЌдђНЋИУЭјИёМгШыЕНИУУмМЏЧјгђжаЃЌжЊЕРВЛдйгаетбљЕФЭјИёБЛЗЂЯжЮЊжЙЁЃЃЈУмМЏЭјИёКЯВЂЃЉ
ЫуЗЈдйМЬајЩЈУшЭјИёВЂжиИДЩЯЪіЙ§ГЬЃЌжБЕНЫљгаЭјИёБЛБщРњЁЃвдздЖЏЕиЗЂЯжзюИпЮЌЕФзгПеМфЃЌИпУмЖШОлРрДцдкгкетаЉзгПеМфжаЃЌВЂЧвЖддЊзщЕФЪфШыЫГађВЛУєИаЃЌЮоашМйЩшШЮКЮЙцЗЖЕФЪ§ОнЗжВМЃЌЫќЫцЪфШыЪ§ОнЕФДѓаЁЯпадЕиРЉеЙЃЌЕБЪ§ОнЕФЮЌЪ§діМгЪБОпгаСМКУЕФПЩЩьЫѕадЁЃ
ИпЮЌЪ§ОнОлРрЕФФбЕудкгкЃК
ЪЪгУгкЦеЭЈМЏКЯЕФОлРрЫуЗЈЃЌдкИпЮЌЪ§ОнМЏКЯжааЇТЪМЋЕЭ
гЩгкИпЮЌПеМфЕФЯЁЪшадвдМАзюНќСкЬиадЃЌИпЮЌЕФПеМфжаЛљБОВЛДцдкЪ§ОнДи
ОлРрЕФФПБъЪЧНЋећИіЪ§ОнМЏЛЎЗжЮЊЖрИіЪ§ОнДиЃЈОлРрЃЉЃЌЖјЪЙЕУЦфРрФкЯрЫЦадзюДѓЃЌРрМфЯрЫЦадзюаЁЃЌЕЋдкИпЮЌПеМфжаКмЖрЧщПіЯТОрРыЖШСПвбОЪЇаЇЃЌетЪЙЕУОлРрЕФИХФюЪЇШЅСЫвтвхЁЃСэвЛЗНУцЃЌНЈСЂЫїв§НсЙЙКЭВЩгУЭјИёЛЎЗжЗНЗЈЪЧКмЖрДѓЪ§ОнМЏОлРрЫуЗЈЬсИпаЇТЪЕФжївЊВпТдЃЌЕЋдкИпЮЌПеМфжаЫїв§НсЙЙЕФЪЇаЇКЭЭјИёЪ§ЫцЮЌЪ§ГЪжИЪ§МЖдіГЄЕФЮЪЬтвВЪЙЕУетаЉВпТдВЛдйгааЇЁЃ
CLIQUEЪЖБ№КђбЁЫбЫїПеМфЕФжївЊВпТдЪЧЪЙгУГэУмЕЅдЊЙигкЮЌЖШЕФЕЅЕїадЁЃетЛљгкЦЕЗБФЃЪНКЭЙиСЊЙцдђЭкОђЪЙгУЕФЯШбщаджЪЁЃдкзгПеМфОлРрЕФБГОАЯТЃЌЕЅЕїадГТЪіШчЯТЃК
вЛИіk-ЮЌЃЈ>1ЃЉЕЅдЊcжСЩйгаIИіЕуЃЌНіЕБcЕФУПИіЃЈk-1ЃЉ-ЮЌЭЖгАЃЈЫќЪЧЃЈk-1ЃЉ-ЮЌЕЅдЊЃЉжСЩйга1ИіЕуЁЃПМТЧЯТЭМЃЌЦфжаЧЖШЫЪ§ОнПеМфАќКЌ3ИіЮЌЃКage,salary,vacation.
Р§ШчЃЌзгПеМфageКЭsalaryжаЕФвЛИіЖўЮЌЕЅдЊАќКЌlИіЕуЃЌНіЕБИУЕЅдЊдкУПИіЮЌЃЈМДЗжБ№дкageКЭsalaryЩЯЕФЭЖгАЖМжСЩйАќКЌlИіЕу).
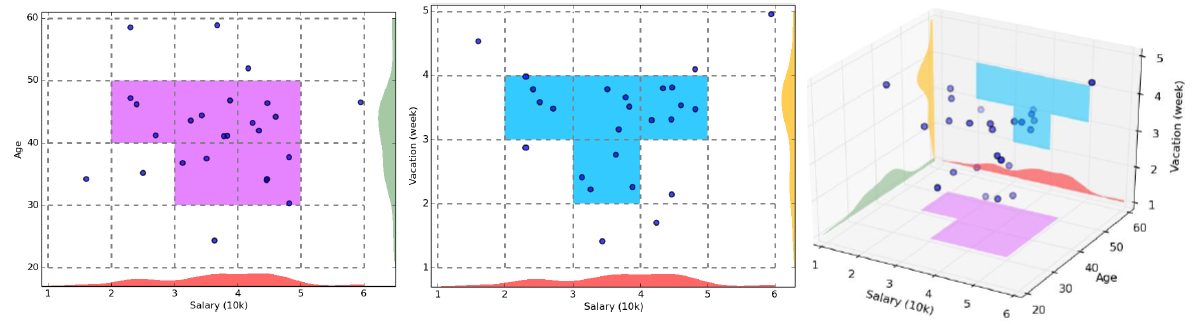
CLIQUEЫуЗЈЕФСНИіВЮЪ§ЃК
ЭјИёЕФВНГЄЁЊЁЊШЗЖЈПеМфЭјИёЛЎЗж
УмЖШуажЕЁЊЁЊЭјИёжаЖдЯѓЪ§СПДѓгкЕШгкИУуажЕБэЪОИУЭјИёЮЊГэУмЭјИё
CLIQUEЫуЗЈСїГЬЃК
1ЁЂ ЖдnЮЌПеМфНјааЛЎЗжЃЌЖдУПвЛИіЮЌЖШЕШСПЛЎЗжЃЌНЋШЋПеМфЛЎЗжЮЊЛЅВЛЯрНЛЕФЭјИёЕЅдЊ
2ЁЂ МЦЫуУПИіЭјИёЕФУмЖШЃЌИљОнИјЖЈЕФуажЕЪЖБ№ГэУмЭјИёКЭЗЧГэУмЭјИёЃЌЧвжУЫљгаЭјИёГѕЪМзДЬЌЮЊЁАЮДДІРэЁБ
CLIQUEВЩгУздЯТЖјЩЯЕФЪЖБ№ЗНЪНЃЌЪзЯШШЗЖЈЕЭЮЌПеМфЕФЪ§ОнУмМЏЕЅдЊЃЌЕБШЗЖЈСЫk-1ЮЌжаЫљгаЕФУмМЏЕЅдЊЃЌkЮЌПеМфЩЯЕФПЩФмУмМЏЕЅдЊОЭПЩвдШЗЖЈЁЃвђЮЊЃЌЕБФГвЛЕЅдЊЕФЪ§ОндкkЮЌПеМфжаЪЧУмМЏЕФЃЌФЧУДдкШЮвЛk-1ЮЌПеМфжаЖМЪЧУмМЏЕФЁЃШчЙћЪ§ОндкФГвЛk-1ЮЌПеМфжаВЛУмМЏЃЌФЧУДЪ§ОндкkЮЌПеМфжавВЪЧВЛУмМЏ
3ЁЂ БщРњЫљгаЭјИёЃЌХаЖЯЕБЧАЭјИёЪЧЗёЮЊЁАЮДДІРэЁБЃЌШєВЛЪЧЁАЮДДІРэЁБзДЬЌЃЌдђДІРэЯТвЛИіЭјИёЃЛШєЪЧЁАЮДДІРэЁБзДЬЌЃЌдђНјааВНжш4~8ДІРэЃЌжБЕНЫљгаЭјИёДІРэЭъГЩЃЌзЊЕНВНжш8
4ЁЂ ИФБфЭјИёБъМЧЮЊЁАвбДІРэЁБЃЌШєЪЧЗЧГэУмЭјИёЃЌдђзЊЕНВНжш2
5ЁЂ ШєЪЧГэУмЭјИёЃЌдђНЋЦфИГгшаТЕФДиБъМЧЃЌДДНЈвЛИіЖгСаЃЌНЋИУГэУмЭјИёжУгкЖгСажа
6ЁЂ ХаЖЯЖгСаЪЧЗёЮЊПеЃЌШєПеЃЌдђДІРэЯТвЛИіЭјИёЃЌзЊЕНЕк2ВНЃЛШєЖгСаВЛЮЊПеЃЌдђНјааШчЯТДІРэ
1ЃЉ ШЁЖгЭЗЕФЭјИёдЊЫиЃЌМьВщЦфЫљгаСкНгЕФгаЁАЮДДІРэЁБЕФЭјИё
2ЃЉ ИќИФЭјИёБъМЧЮЊЁАвбДІРэЁБ
3ЃЉ ШєСкНгЭјИёЮЊГэУмЭјИёЃЌдђНЋЦфИЛдЃЕБЧАДиБъМЧЃЌВЂНЋЦфМгШыЖгСа
4ЃЉ зЊЕНВНжш5
7ЁЂ УмЖШСЌЭЈЧјгђМьВщНсЪјЃЌБъМЧЯрЭЌЕФГэУмЭјИёзщГЩУмЖШСЌЭЈЧјгђЃЌМДФПБъДи
8ЁЂ аоИФДиБъМЧЃЌНјааЯТвЛИіДиЕФВщевЃЌзЊЕНЕк2ВН
9ЁЂ БщРњећИіЪ§ОнМЏЃЌНЋЪ§ОндЊЫиБъМЧЮЊЫљгаЭјИёДиБъМЧжЕ
ЪОР§ЃКвдЯТЪЧУмЖШуажЕЮЊ4ЕФНсЙћ
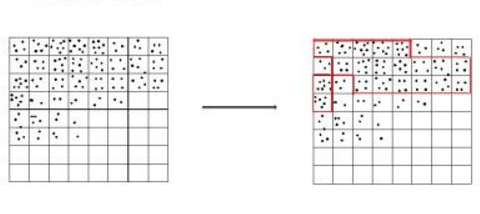
WaveClusterЫуЗЈ
РыЩЂаЁВЈБфЛЛDWT(Discrete Wavelet Transform)
РыЩЂаЁВЈDWT(Discrete Wavelet Transform)ЃК
x0,x1,x2,x3=90,70,100,70
ЮЊСЫДяЕНбЙЫѕаЇЙћЃЌШЁ (x0+x1)/2ЁЁ (x0-x1)/2 РДДњБэаТЕФx0,x1
90,70 БэЪОЮЊ 80,10ЁЁ80МДЦНОљЪ§ЃЈЦЕТЪЃЉЃЌ10ЪЧаЁЗЖЮЇВЈЖЏЪ§ЃЈеёЗљЃЉ
ЭЌРэ100,70БэЪОЮЊ85,15
80КЭ85ЪЧОжВПЕФЦНОљжЕЃЌЗДгГЕФЪЧЦЕТЪЃЌНазіЕЭЦЕВПЗжЃЈLow-PassЃЉ
10КЭ15ЪЧаЁЗЖЮЇВЈЖЏЕФЗљЖШЃЌНазіИпЦЕВПЗжЃЈHigh-PassЃЉ
МД90,70,100,70ОЙ§вЛДЮаЁВЈБфЛЛЃЌПЩвдБэЪОЮЊ80,85,10,15ЃЌЕЭЦЕВПЗждкЧА(L)ЃЌИпЦЕВПЗждкКѓ(H)
ЪОР§ЃК
ЖдX=90,70,100,70,80,70,90,80,100,70,90,70,80,90,100,70НјааШ§ДЮаЁВЈБфЛЛЃЌНсЙћШчЯТЫљЪО
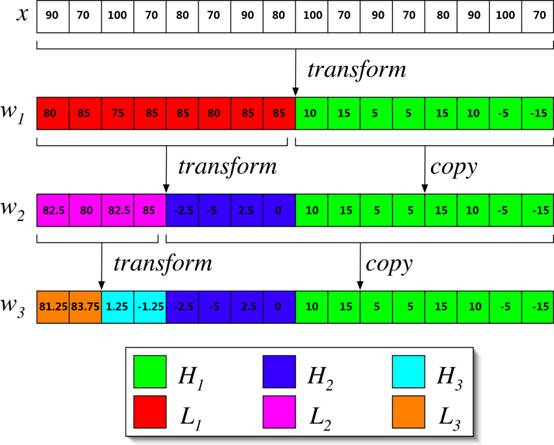
РыЩЂаЁВЈБфЛЛгУгкЖўЮЌЭМЯёДІРэ
ЪОР§ЃК

ЕквЛВНЃЌЖддЪМЭМЯёЕФУПвЛааНјаавЛДЮdwtЃЌЕУЕНаТЕФЬиеїЭМЯёЃЛ
ЕкЖўВНЃЌЖдЕквЛВНЕУЕНЕФЬиеїЭМЯёЕФУПвЛСаНјаавЛДЮdwtЃЌЕУЕННсЙћ
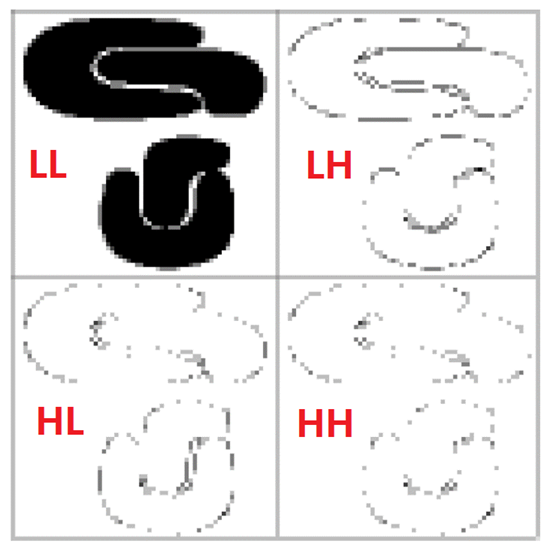
LL: НгНќдЪМЭМЯёЃЈЫѕаЁСЫвЛБЖЃЉЃЛ
LH: ЭМЯёЫЎЦНБпНчаХЯЂ(horizontal edges)ЃЛ
HL: ЭМЯёДЙжББпНчаХЯЂ(vertical edges)ЃЛ
HH: corners
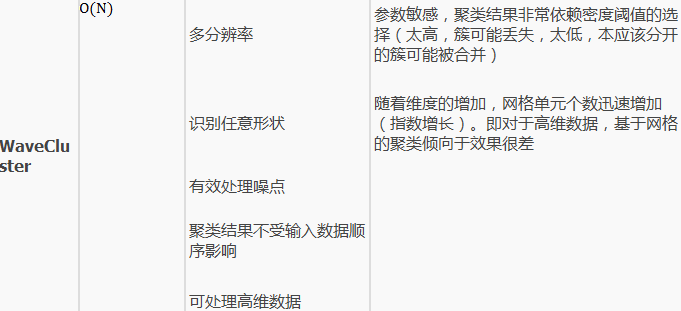
WaveClusterОлРрЫуЗЈ
WaveClusterЫуЗЈЕФКЫаФЫМЯыЪЧНЋЪ§ОнПеМфЛЎЗжЮЊЭјИёКѓЃЌЖдДЫЭјИёЪ§ОнНсЙЙНјаааЁВЈБфЛЛЃЌШЛКѓНЋБфЛЛКѓЕФПеМфжаЕФИпУмЖШЧјгђЪЖБ№ЮЊДиЁЃЛљгкЪ§ОнЕуЪ§ФПДѓгкЭјИёЕЅдЊЪ§ФПЃЈNЁнKЃЉЕФМйЩшЃЌWaveClusterЕФЪБМфИДдгЖШЮЊO(N)ЃЌЦфжаNЮЊЪ§ОнМЏФкЪ§ОнЕуЪ§ФПЃЌKЮЊЭјИёФкЕФЭјИёЕЅдЊЪ§ФПЁЃ
WaveClusterЫуЗЈашвЊСНИіВЮЪ§ЃК
ЭјИёЕФВНГЄЁЊЁЊШЗЖЈПеМфЭјИёЛЎЗж
УмЖШуажЕЁЊЁЊЭјИёжаЖдЯѓЪ§СПДѓгкЕШгкИУуажЕБэЪОИУЭјИёЮЊГэУмЭјИё
WaveClusterЫуЗЈСїГЬ
1 .НЋдЪМПеМфРыЩЂЛЏЮЊЭјзДПеМфЃЌВЂАбдЪМЪ§ОнЗХШыЖдгІЕЅдЊИёЃЌаЮГЩаТЕФЬиеїПеМфЃЛ

2 .ЖдЬиеїПеМфНјаааЁВЈзЊЛЛЃЌМДгУаЁВЈБфЛЛЖддЪМЪ§ОнНјаабЙЫѕ
ЖдУПааНјаааЁВЈБфЛЛЃЌЕУЕН
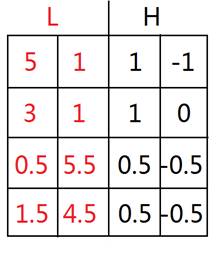
дйЖдУПСаНјаааЁВЈБфЛЛЃЌЕУЕН
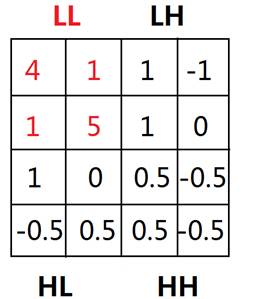
зЂЃКLLПеМфЯрЕБгкЪЧбЙЫѕКѓЕФаХЯЂЃЌБОР§ЪЧ44бЙЫѕЮЊ22
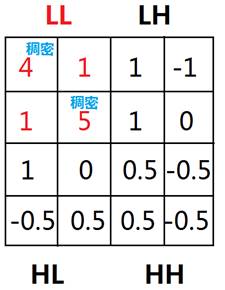
3 .евГіаЁВЈзЊЛЛКѓЕФLLПеМфжаУмЖШДѓгкуажЕЃЈетРяШЁ3ЃЉЕФЭјИёЃЌНЋЦфБъМЧЮЊГэУмЃЛ
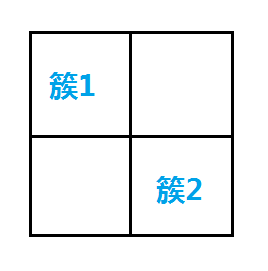
4 .ЖдгкУмЖШЯрСЌЕФЭјИёзїЮЊвЛИіДиЃЌДђЩЯЦфЫљдкДиађКХЕФБъЧЉЃЛ
5 . НЈСЂзЊЛЛЧАКѓЕЅдЊИёЕФгГЩфБэ;
6 .АбдЪМЪ§ОнгГЩфЕНИїздЕФДиЩЯЁЃ
аЁВЈОлРр-аЇТЪ
ОлРрЫуЗЈЖдБШ
ВЛЭЌЕФОлРрЫуЗЈгаВЛЭЌЕФгІгУБГОАЃЌгаЕФЪЪКЯгкДѓЪ§ОнМЏЃЌПЩвдЗЂЯжШЮвтаЮзДЕФОлДиЃЛгаЕФЫуЗЈЫМЯыМђЕЅЃЌЪЪгУгкаЁЪ§ОнМЏЁЃзмЕФРДЫЕЃЌЪ§ОнЭкОђжаеыЖдОлРрЕФЕфаЭвЊЧѓАќРЈЃК
ЃЈ1ЃЉПЩЩьЫѕадЃКЕБЪ§ОнСПДгМИАйЩЯЩ§ЕНМИАйЭђЪБЃЌОлРрНсЙћЕФзМШЗЖШФмвЛжТЁЃ
ЃЈ2ЃЉДІРэВЛЭЌРраЭЪєадЕФФмСІЃКаэЖрЫуЗЈеыЖдЕФЪ§жЕРраЭЕФЪ§ОнЁЃЕЋЪЧЃЌЪЕМЪгІгУГЁОАжаЃЌЛсгіЕНЖўдЊРраЭЪ§ОнЃЌЗжРр/БъГЦРраЭЪ§ОнЃЌађЪ§аЭЪ§ОнЁЃ
ЃЈ3ЃЉЗЂЯжШЮвтаЮзДЕФРрДиЃКаэЖрОлРрЫуЗЈЛљгкОрРыЃЈХЗЪНОрРыЛђТќЙўЖйОрРыЃЉРДСПЛЏЖдЯѓжЎМфЕФЯрЫЦЖШЁЃЛљгкетжжЗНЪНЃЌЮвУЧЭљЭљжЛФмЗЂЯжЯрЫЦГпДчКЭУмЖШЕФЧђзДРрДиЛђепЭЙаЭРрДиЁЃЕЋЪЧЃЌЪЕМЪжаРрДиЕФаЮзДПЩФмЪЧШЮвтЕФЁЃ
ЃЈ4ЃЉГѕЪМЛЏВЮЪ§ЕФашЧѓзюаЁЛЏЃККмЖрЫуЗЈашвЊгУЛЇЬсЙЉвЛЖЈИіЪ§ЕФГѕЪМВЮЪ§ЃЌБШШчЦкЭћЕФРрДиИіЪ§ЃЌРрДиГѕЪМжааФЕуЕФЩшЖЈЁЃОлРрЕФНсЙћЖдетаЉВЮЪ§ЪЎЗжУєИаЃЌЕїВЮЪ§ашвЊДѓСПЕФШЫСІИКЕЃЃЌвВЗЧГЃгАЯьОлРрНсЙћЕФзМШЗадЁЃ
ЃЈ5ЃЉДІРэдыЩљЪ§ОнЕФФмСІЃКдыЩљЪ§ОнЭЈГЃПЩвдРэНтЮЊгАЯьОлРрНсЙћЕФИЩШХЪ§ОнЃЌАќКЌЙТСЂЕуЃЌДэЮѓЪ§ОнЕШЃЌвЛаЉЫуЗЈЖдетаЉдыЩљЪ§ОнЗЧГЃУєИаЃЌЛсЕМжТЕЭжЪСПЕФОлРрЁЃ
ЃЈ6ЃЉдіСПОлРрКЭЖдЪфШыДЮађЕФВЛУєИаЃКвЛаЉЫуЗЈВЛФмНЋаТМгШыЕФЪ§ОнПьЫйВхШыЕНвбгаЕФОлРрНсЙћжаЃЌЛЙгавЛаЉЫуЗЈеыЖдВЛЭЌДЮађЕФЪ§ОнЪфШыЃЌВњЩњЕФОлРрНсЙћВювьКмДѓЁЃ
ЃЈ7ЃЉИпЮЌадЃКгааЉЫуЗЈжЛФмДІРэ2ЕН3ЮЌЕФЕЭЮГЖШЪ§ОнЃЌЖјДІРэИпЮЌЪ§ОнЕФФмСІКмШѕЃЌИпЮЌПеМфжаЕФЪ§ОнЗжВМЪЎЗжЯЁЪшЃЌЧвИпЖШЧуаБЁЃ
ЃЈ8ЃЉПЩНтЪЭадКЭПЩгУадЃКЮвУЧЯЃЭћЕУЕНЕФОлРрНсЙћЖМФмгУЬиЖЈЕФгявхЁЂжЊЪЖНјааНтЪЭЃЌКЭЪЕМЪЕФгІгУГЁОАЯрСЊЯЕЁЃ
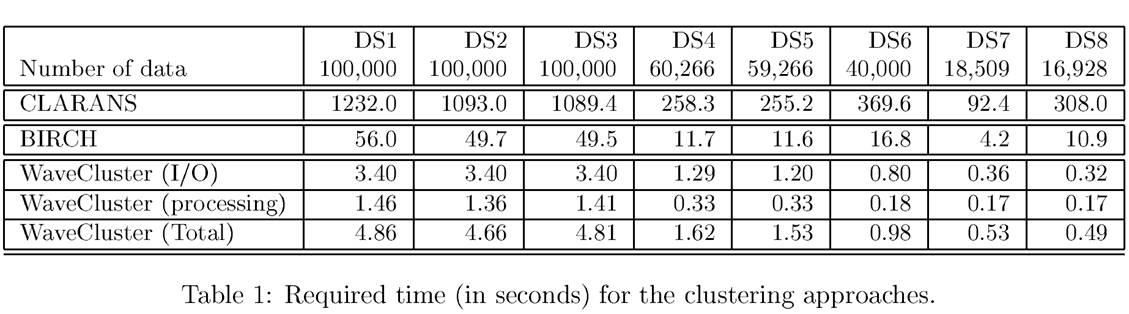
МИжжГЃгУЕФОлРрЫуЗЈДгПЩЩьЫѕадЁЂЪЪКЯЕФЪ§ОнРраЭЁЂИпЮЌадЃЈДІРэИпЮЌЪ§ОнЕФФмСІЃЉЁЂвьГЃЪ§ОнЕФПЙИЩШХЖШЁЂОлРраЮзДКЭЫуЗЈаЇТЪ6ИіЗНУцНјааСЫзлКЯадФмЦРМлЃЌЦРМлНсЙћШчБэ1ЫљЪОЃК
| ЫуЗЈУћГЦ| ЫуЗЈРраЭ| ПЩЩьЫѕад| ЪЪКЯЕФЪ§ОнРраЭ| ИпЮЌад| вьГЃЪ§ОнЕФПЙИЩШХад| ОлРраЮзД|
ЫуЗЈаЇТЪ|
|---------|---------|---------|--------|---------|--------|---------|
|ROCK| ВуДЮОлРр|КмИп |ЛьКЯаЭ |КмИп|КмИп |ШЮвтаЮзД|вЛАу|
|BIRCH|ВуДЮОлРр|НЯИп|Ъ§жЕаЭ |НЯЕЭ |НЯЕЭ |ЧђаЮ |КмИп|
|CURE| ВуДЮОлРр| НЯИп| Ъ§жЕаЭ| вЛАу| КмИп| ШЮвтаЮзД| НЯИп|
| CLARANS| ЛЎЗжОлРр| НЯЕЭ| Ъ§жЕаЭ | НЯЕЭ| НЯИп| ЧђаЮ| НЯЕЭ|
| DENCLUE| УмЖШОлРр| НЯЕЭ| Ъ§жЕаЭ | НЯИп| вЛАу| ШЮвтаЮзД| НЯИп|
| DBSCAN | УмЖШОлРр| вЛАу| Ъ§жЕаЭ | НЯЕЭ | НЯИп| ШЮвтаЮзД | вЛАу|
| WaveCluster| ЭјИёОлРр| КмИп| Ъ§жЕаЭ| КмИп| НЯИп| ШЮвтаЮзД| КмИп|
| OptiGrid| ЭјИёОлРр| вЛАу | Ъ§жЕаЭ | НЯИп| вЛАу| ШЮвтаЮзД | вЛАу|
| CLIQUE | ЭјИёОлРр| НЯИп| Ъ§жЕаЭ| НЯИп| НЯИп| ШЮвтаЮзД| НЯЕЭ|
ЭјИёОлРрЫуЗЈЖдБШ
|









