| БрМЭЦМі: |
БОЮФгк51cto,НщЩмСЫЩюЖШбЇЯАЕФМИКЮбЇЪгНЧЃЌОжЯоадЃЌФтШЫЛЏЛњЦїбЇЯАФЃаЭЕФЗчЯеЃЌОжВПЗКЛЏгыМЋЯоЗКЛЏЕШжЊЪЖЁЃ
|
|
ЩюЖШбЇЯАзюСюШЫОЊбШжЎДІОЭдкгкЫќЪЎЗжМђЕЅЁЃЪЎФъЧАЃЌУЛгаШЫжИЭћгЩЬнЖШЯТНЕЗНЗЈбЕСЗЕФМђЕЅВЮЪ§ФЃаЭОЭПЩвддкЛњЦїИажЊЮЪЬтЩЯЛёЕУОЊШЫЕФНсЙћЁЃЯждкЃЌЪТЪЕжЄУїЃЌФужЛашвЊвЛИігазуЙЛЖрВЮЪ§ЕФФЃаЭЃЌВЂЧвдкзуЙЛДѓЕФЪ§ОнМЏЩЯЪЙгУЬнЖШЯТНЕНјаабЕСЗЁЃ
ЩюЖШбЇЯАЕФМИКЮбЇЪгНЧ
ЩюЖШбЇЯАзюСюШЫОЊбШжЎДІОЭдкгкЫќЪЎЗжМђЕЅЁЃЪЎФъЧАЃЌУЛгаШЫжИЭћгЩЬнЖШЯТНЕЗНЗЈбЕСЗЕФМђЕЅВЮЪ§ФЃаЭОЭПЩвддкЛњЦїИажЊЮЪЬтЩЯЛёЕУОЊШЫЕФНсЙћЁЃЯждкЃЌЪТЪЕжЄУїЃЌФужЛашвЊвЛИігазуЙЛЖрВЮЪ§ЕФФЃаЭЃЌВЂЧвдкзуЙЛДѓЕФЪ§ОнМЏЩЯЪЙгУЬнЖШЯТНЕНјаабЕСЗЁЃе§Шч
Feynman дјОУшЪігюжцФЧбљЃЌЁИЫќВЂВЛИДдгЃЌжЛЪЧКмЖрЖјвбЁЙЁЃ
дкЩюЖШбЇЯАжаЃЌвЛЧаЖМЪЧвЛИіЯђСПЃЌМДвЛЧаЖМЪЧМИКЮПеМфжаЕФвЛИіЕуЁЃФЃаЭЪфШы(ПЩвдЪЧЮФБОЃЌЭМЯёЕШ)КЭФПБъЪзЯШБЛЁИЪИСПЛЏЁЙЃЌМДБфГЩвЛаЉГѕЪМЪфШыЪИСППеМфКЭФПБъЪИСППеМфЁЃЩюЖШбЇЯАФЃаЭжаЕФУПвЛВуЖдЭЈЙ§ЫќЕФЪ§ОнНјааМђЕЅЕФМИКЮБфЛЛЁЃЭЌЪБЃЌФЃаЭЕФВуДЮСДаЮГЩвЛИіЗЧГЃИДдгЕФМИКЮБфЛЛЃЌЗжНтГЩвЛЯЕСаМђЕЅЕФМИКЮБфЛЛЁЃетжжИДдгЕФзЊЛЛГЂЪдНЋЪфШыПеМфвЛДЮвЛИіЕуЕУгГЩфЕНФПБъПеМфЁЃетжжзЊЛЛЪЧЭЈЙ§ВуЕФШЈжиНјааВЮЪ§ЛЏЕФЃЌШЈжиИљОнФЃаЭЕБЧАжДааЕФЧщПіНјааЕќДњИќаТЁЃетжжМИКЮБфЛЛЕФвЛИіЙиМќЬиеїЪЧЫќБиаыЪЧПЩЮЂЗжЕФЃЌетЪЧЮЊСЫЪЙЮвУЧФмЙЛЭЈЙ§ЬнЖШЯТНЕбЇЯАЫќЕФВЮЪ§ЁЃжБЙлЕиЫЕЃЌетвтЮЖзХДгЪфШыЕНЪфГіЕФМИКЮБфаЮБиаыЦНЛЌЧвСЌајЁЊЁЊетЪЧвЛИіживЊЕФдМЪјЬѕМўЁЃ
етжжИДдгЕФМИКЮБфЛЛгІгУЕНЪфШыЪ§ОнЕФећИіЙ§ГЬПЩвдгУШ§ЮЌЕФаЮЪННјааПЩЪгЛЏЃЌНЋЦфЯыЯѓГЩвЛИіШЫЪдЭМНЋШрГЩЭХЕФжНЧђЛжИДЦНећЃКжхАЭАЭЕФжНЧђЪЧФЃаЭПЊЪМЪБЕФЪфШыЪ§ОнЕФИДБОЁЃШЫЖджНЧђЕФУПИіВйзїЯрЕБгквЛВуМђЕЅМИКЮзЊЛЛЕФВйзїЁЃЭъећЕФИЇЦН(жНЧђ)ЖЏзїЫГађЪЧећИіФЃаЭЕФИДдгзЊЛЛЁЃЩюЖШбЇЯАФЃаЭЪЧгУгкНтПЊИпЮЌЪ§ОнИДдгСїаЮЕФЪ§бЇЛњЦїЁЃ
ЩюЖШбЇЯАЕФЩёЦцжЎДІдкгкЃКНЋгявхзЊЛЏЮЊЪИСПЃЌзЊЛЏЮЊМИКЮПеМфЃЌШЛКѓж№НЅбЇЯАНЋвЛИіПеМфгГЩфЕНСэвЛИіПеМфЕФИДдгМИКЮзЊЛЛЁЃФуашвЊЕФжЛЪЧзуЙЛИпЮЌЪ§ЕФПеМфЃЌвдБуВЖзНдЪМЪ§ОнжаШЋВПЕФЙиЯЕЗЖЮЇЁЃ
ЩюЖШбЇЯАЕФОжЯоад
гУетИіМђЕЅВпТдЪЕЯжЕФгІгУГЬађПеМфМИКѕЪЧЮоЯоЕФЁЃШЛЖјЃЌЯжгаЕФЩюЖШбЇЯАММЪѕЖдгкИќЖрЕФгІгУГЬађЭъШЋЮоФмЮЊСІЁЊЁЊМДЪЙЬсЙЉСЫДѓСПЕФШЫЙЄзЂЪЭЪ§ОнЁЃР§ШчЃЌФуПЩвдГЂЪдЪеМЏГЩЧЇЩЯЭђЩѕжСАйЭђЕФЙигкШэМўВњЦЗЬиеїЕФгЂЮФУшЪіЕФЪ§ОнМЏЃЌгЩВњЦЗОРэБраДЃЌвдМАгЩЙЄГЬЪІЭХЖгПЊЗЂЕФЯргІЕФдДДњТыРДТњзуетаЉвЊЧѓЁЃМДЪЙгаСЫетаЉЪ§ОнЃЌФувВЮоЗЈбЕСЗЩюШыЕФбЇЯАФЃЪНШЅМђЕЅЕидФЖСВњЦЗЫЕУїВЂЩњГЩЪЪЕБЕФДњТыПтЁЃетжЛЪЧЦфжаЕФвЛИіР§згЁЃвЛАуРДЫЕЃЌЮоТлФуЭЖШыЖрЩйЪ§ОнЃЌЩюЖШбЇЯАФЃаЭЖМЮоЗЈЪЕЯжШЮКЮашвЊЭЦРэЕФЖЋЮїЃЌШчБрГЬЛђПЦбЇЗНЗЈЕФгІгУЁЊЁЊГЄЦкЙцЛЎКЭРрЫЦЫуЗЈЕФЪ§ОнВйзїЁЃМДЪЙЪЙгУЩюЖШЩёОЭјТчбЇЯАХХађЫуЗЈвВЪЧЗЧГЃРЇФбЕФЁЃ
етЪЧвђЮЊЩюЖШбЇЯАФЃаЭНіНіЪЧНЋвЛИіЯђСППеМфгГЩфЕНСэвЛИіЯђСППеМфЕФМђЕЅСЌајМИКЮБфЛЛСДЁЃЫќПЩвдзіЕФШЋВПОЭЪЧНЋвЛИіЪ§ОнСїаЮ
X гГЩфЕНСэвЛИіСїаЮ YЃЌМйЩшДцдкДг XЕН Y ЕФПЩбЇЯАСЌајБфЛЛЕФЛАЃЌВЂЧвПЩвдЪЙгУУмМЏЕФ XЃКY ВЩбљзїЮЊбЕСЗЪ§ОнЁЃвђДЫЃЌОЁЙмЩюЖШбЇЯАФЃаЭПЩвдБЛНтЪЭЮЊвЛжжГЬађЃЌЗДЙ§РДЫЕЕФЛАЃЌДѓЖрЪ§ГЬађВЛФмБЛБэДяЮЊЩюЖШбЇЯАФЃаЭЁЊЁЊЖдгкДѓЖрЪ§ШЮЮёРДЫЕЃЌвЊУДУЛгаЯргІЕФЪЕМЪДѓаЁЕФЩюЖШЩёОЭјТчРДНтОіШЮЮёЃЌЛђепДцдкетбљЕФЩёОЭјТчЃЌЕЋЫќПЩФмЮоЗЈбЇЯАЃЌМДЯргІЕФМИКЮБфЛЛПЩФмЬЋИДдгЃЌЛђепПЩФмУЛгаКЯЪЪЕФЪ§ОнПЩгУРДбЇЯАЫќЁЃ
ЭЈЙ§ЖбЕўИќЖрВуВЂЪЙгУИќЖрбЕСЗЪ§ОнРДРЉеЙЕБЧАЕФЩюЖШбЇЯАММЪѕЃЌжЛФмдкБэУцЩЯЛКНтвЛаЉЮЪЬтЁЃЫќВЛФмНтОіЩюЖШбЇЯАФЃаЭдкЫћУЧПЩвдБэЪОЕФФкШнжжРрЗЧГЃгаЯоЕФЛљБОЮЪЬтЃЌВЂЧвДѓЖрЪ§БЛЦкЭћПЩбЇЯАЕФГЬађВЛФмБЛБэЪОЮЊЪ§ОнСїаЮЕФСЌајМИКЮБфаЮЁЃ
ФтШЫЛЏЛњЦїбЇЯАФЃаЭЕФЗчЯе
ЕБДњШЫЙЄжЧФмЕФвЛИіЗЧГЃЯжЪЕЕФЗчЯеЪЧШЫУЧЮѓНтСЫЩюЖШбЇЯАФЃаЭЕФзїгУЃЌВЂИпЙРСЫЫћУЧЕФФмСІЁЃШЫРрЫМЮЌЕФвЛИіЛљБОЬиеїЪЧЮвУЧЕФЁИаФжЧРэТлЁЙЃЌЮвУЧЧуЯђгкНЋвтЯђЃЌаХбіКЭжЊЪЖЭЖЩфЕНЮвУЧЩэБпЕФЪТЮяЩЯЁЃдкЮвУЧЕФвтЪЖжаЃЌдкбвЪЏЩЯЛвЛИіаІСГЪЏЭЗОЭЭЛШЛБфЁИПьРжЁЙСЫЁЃгІгУгкЩюЖШбЇЯАЃЌетвтЮЖзХЕБЮвУЧФмЙЛЁИЛљБОГЩЙІЁЙЕФбЕСЗФЃаЭвдЩњГЩгУгкУшЪіЭМЦЌЕФБъЬтЪБЃЌЮвУЧОЭЛсЯраХИУФЃаЭФмЙЛЁИРэНтЁЙЭМЦЌЕФФкШнвдМАЁИРэНтЁЙЫќЫљЩњГЩЕФзжФЛЁЃШЛКѓЃЌЕБбЕСЗЪ§ОнжаГіЯжЕФЭМЯёРрБ№ЧсЮЂЦЋРыЪБЃЌЮвУЧЛсЗЧГЃОЊбШЕиЗЂЯжФЃаЭПЊЪМЩњГЩЭъШЋЛФУ§ЕФБъЬтЁЃ

ЩюЖШбЇЯАЕФОжЯоадКЭЮДРД
гШЦфЪЧЁИЖдПЙадбљБОЁЙжЕЕУЧПЕїЃЌетаЉР§згЪЧвЛИіЩюЖШбЇЯАЭјТчЕФЪфШыбљБОЃЌжМдкгеЦФЃаЭЖдЫќУЧНјааДэЮѓЗжРрЁЃФувбОвтЪЖЕНЃЌПЩвддкЪфШыПеМфжаНјааЬнЖШЩЯЩ§вдЩњГЩзюДѓЛЏФГИіБеЛЗЙ§ТЫЦїМЄЛюЕФЪфШыЃЌетЪЧЮвУЧдкЕк
5 еТжаНщЩмЕФЙ§ТЫЦїПЩЪгЛЏММЪѕЕФЛљДЁЃЌвдМАЕк 8 еТЕФ Deep Dream ЫуЗЈЁЃЭЌбљЃЌЭЈЙ§ЬнЖШЩЯЩ§ЃЌШЫУЧПЩвдЩдЮЂаоИФЭМЯёвдзюДѓЛЏИјЖЈРрЕФРрБ№дЄВтЁЃЭЈЙ§ХФЩувЛеХамУЈЕФЭМЦЌВЂЬэМгвЛИіЁИГЄБлдГЁЙЬнЖШЃЌЮвУЧПЩвдЕУЕНвЛИіЩёОЭјТчЃЌНЋетжЛамУЈЙщРрЮЊГЄБлдГЁЃетжЄУїСЫетаЉФЃаЭЕФДрШѕадЃЌвдМАЫќУЧЕФЪфШыЁЊЁЊЪфГігГЩфгыЮвУЧШЫРрздЩэШЯжЊжЎМфЕФЩюПЬВювьЁЃ
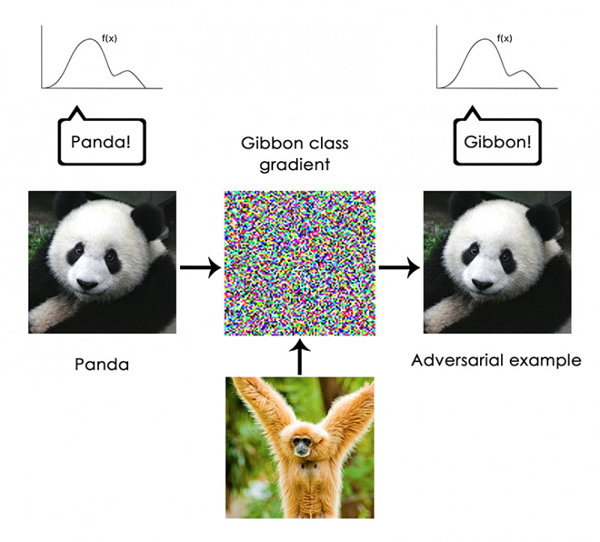
змжЎЃЌЩюЖШбЇЯАФЃаЭВЂВЛРэНтЫћУЧЕФЪфШыЃЌжСЩйУЛгаШЫРрвтЪЖЩЯЕФРэНтЁЃЮвУЧШЫРрЖдЭМЯёЃЌЩљвєКЭгябдЕФРэНтЪЧЛљгкЮвУЧзїЮЊШЫРрЕФИаОѕдЫЖЏЬхбщЁЊЁЊе§ШчЕиЧђЩЯЕФЩњЮяЫљБэЯжЕФвЛбљЁЃЛњЦїбЇЯАФЃаЭЮоЗЈЛёЕУетаЉОбщЃЌвђДЫЮоЗЈвдгыШЫРрвЛжТЕФЪгНЧРДЁИРэНтЁЙЫћУЧЕФЪфШыЁЃ
ЭЈЙ§зЂЪЭДѓСПЕФбЕСЗбљР§РДбЕСЗЮвУЧЕФФЃаЭЃЌЮвУЧШУЫћУЧбЇЯАдкЬиЖЈЪ§ОнМЏЩЯЃЌНЋЪ§ОнгГЩфЕНШЫРрИХФюЕФМИКЮБфЛЛЃЌЕЋетИігГЩфжЛЪЧЮвУЧЭЗФджадЪМФЃаЭЕФМђЕЅИХвЊЃЌетЪЧЮвУЧзїЮЊШЫРрЪЕЬхЕФЬхбщЕУРДЕФЁЊЁЊЫќОЭЯёОЕзгРяЕФвЛИіФЃК§ЕФаЮЯѓЁЃ
зїЮЊвЛУћЛњЦїбЇЯАЪЕМљепЃЌЧыЪМжезЂвтетвЛЕуЃЌгРдЖВЛвЊЯнШыетбљвЛИіЯнкхЃЌМДЯраХЩёОЭјТчРэНтЫћУЧЫљжДааЕФШЮЮёЁЊЁЊЫћУЧВЛЛсЕФЃЌжСЩйВЛЛсвдЖдЮвУЧгавтвхЕФЗНЪНРэНтЁЃВЛЭЌгкЮвУЧЯыНЬЫћУЧЕФШЮЮёЃЌЫћУЧБЛбЕСЗРДжДааИќЮЊЯСеЕФШЮЮёЃКНіНіНЋбЕСЗМЏЪфШыж№ЕугГЩфЕНбЕСЗФПБъжаЁЃЯђЫћУЧеЙЪОШЮКЮЦЋРыбЕСЗЪ§ОнЕФЖЋЮїЃЌЫћУЧНЋИјГізюЛФУ§ЕФНсЙћЁЃ
ОжВПЗКЛЏгыМЋЯоЗКЛЏ
ЩюЖШбЇЯАФЃаЭжаДгЪфШыЕНЪфГіЕФжБНгМИКЮБфаЮЃЌгыШЫРрЫМПМКЭбЇЯАЕФЗНЪНжЎМфМИКѕЪЧЭъШЋВЛЭЌЕФЁЃетВЛНіНіЪЧШЫРрДгздЩэЕФОбщжабЇЯАЖјВЛЪЧЭЈЙ§УїШЗЕФбЕСЗЪЕР§РДбЇЯАЕФЮЪЬтЁЃГ§СЫбЇЯАЙ§ГЬВЛЭЌжЎЭтЃЌЛљБОБэеїЕФаджЪвВДцдкИљБОВювьЁЃ
ШЫРрФмзіЕФдЖдЖВЛжЛЪЧЯёЩюЖШЩёОЭјТчЛђРЅГцФЧбљАбМДЪБДЬМЄгГЩфГЩМДЪБЗДгІЁЃШЫУЧЮЌГжзХЙигкФПЧАДІОГЁЂЙигкЫћУЧздМККЭЦфЫћШЫЕФИДдгГщЯѓФЃаЭЃЌВЂЧвПЩвдЪЙгУетаЉФЃаЭРДдЄВтВЛЭЌЕФПЩФмЗЂЩњЕФЮДРДВЂжДааГЄЦкЙцЛЎЁЃЫћУЧФмЙЛНЋвбжЊЕФИХФюКЯВЂдквЛЦ№ЃЌРДБэЪОЫћУЧвдЧАДгЮДОРњЙ§ЕФЪТЮяЃЌР§ШчУшЛцДЉзХХЃзаПуЕФТэЃЌЛђЯыЯѓШчЙћЫћУЧжаСЫВЪЦБОЭЛсзіЪВУДЁЃетжжДІРэМйЩшЕФФмСІЃЌРЉеЙСЫЮвУЧЕФаФжЧФЃаЭПеМфЃЌЪЙЦфдЖдЖГЌГіЮвУЧПЩвджБНгЬхбщЕНЕФЪТЮяПеМфЃЌзмЖјбджЎЃЌНјааГщЯѓКЭЭЦРэЃЌПЩвдЫЕЪЧШЫРрШЯжЊЕФОіЖЈадЬиеїЁЃЮвГЦжЎЮЊЁИМЋЯоЗКЛЏЁЙЃКетЪЧвЛжждкУцЖдЮДОРњЕФЧщПіЪБЃЌЪЙгУКмЩйЕФЪ§ОнЩѕжСИљБОУЛгааТЕФЪ§ОнОЭФмЪЪгІаТЧщПіЕФФмСІЁЃ
етгыЩюЖШЭјТчЫљзіЕФаЮГЩЯЪУїЖдБШЃЌЮвГЦжЎЮЊЁИОжВПЗКЛЏЁЙЃКШчЙћаТЪфШыгыбЕСЗЪБПДЕНЕФТдгаВЛЭЌЃЌдђгЩЩюЖШЭјТчжДааЕФДгЪфШыЕНЪфГіЕФгГЩфСЂТэЪЇШЅвтвхЁЃР§ШчЃЌРДЫМПМетбљвЛЮЪЬтЃЌЯывЊбЇЯАЪЙЛ№М§дкдТЧђЩЯзХТНЕФКЯЪЪЕФЗЂЩфВЮЪ§ЁЃШчЙћФувЊЪЙгУЩюВуЭјТчРДЭъГЩетЯюШЮЮёЃЌЮоТлЪЧЪЙгУМрЖНбЇЯАЛЙЪЧдіЧПбЇЯАНјаабЕСЗЃЌФуЖМашвЊгУЪ§ЧЇФЫжСЪ§АйЭђДЮЕФЗЂЩфЪдбщНјаабЕСЗЃЌвВОЭЪЧЫЕЃЌФуашвЊНЋФЃаЭжУгкУмМЏЕФЪфШыВЩбљЕуПеМфЃЌвдБубЇЯАДгЪфШыПеМфЕНЪфГіПеМфЕФПЩППгГЩфЁЃ
ЯрБШжЎЯТЃЌШЫРрПЩвдРћгУЫћУЧЕФГщЯѓФмСІРДЬсГіЮяРэФЃаЭЁЊЁЊЛ№М§ПЦбЇЁЊЁЊВЂЕУГівЛИіШЗЧаЕФНтОіЗНАИЃЌжЛашвЛДЮЛђМИДЮЪдбщМДПЩЛёЕУдТЧђЩЯЕФЛ№М§ЕФЗЂЩфВЮЪ§ЁЃЭЌбљЃЌШчЙћФуПЊЗЂСЫвЛИіПижЦШЫЬхЕФЩюЖШЭјТчЃЌвЊЫќФмЙЛдкГЧЪажаАВШЋЕиМнЪЛЦћГЕВЂВЛБЛЦфЫћЦћГЕзВЃЌФЧУДетИіЭјТчНЋВЛЕУВЛЁИЫРЭіЁЙЪ§ЧЇДЮдкИїжжГЁОАжаЃЌжБЕНЫќПЩвдЭЦЖЯГіЦћГЕКЭЮЃЯеВЂжЦЖЈЪЪЕБЕФЛиБмДыЪЉЁЃЗХЕНвЛИіаТЕФГЧЪаЃЌЭјТчНЋВЛЕУВЛжиаТбЇЯАвбжЊЕФДѓВПЗжжЊЪЖЁЃСэвЛЗНУцЃЌШЫРрОЭВЛБиЭЈЙ§ЫРЭіРДбЇЯААВШЋЕФааЮЊЃЌетвЊЙщЙІгкЫћУЧЖдМйЩшЧщОГЕФГщЯѓНЈФЃЕФФмСІЁЃ
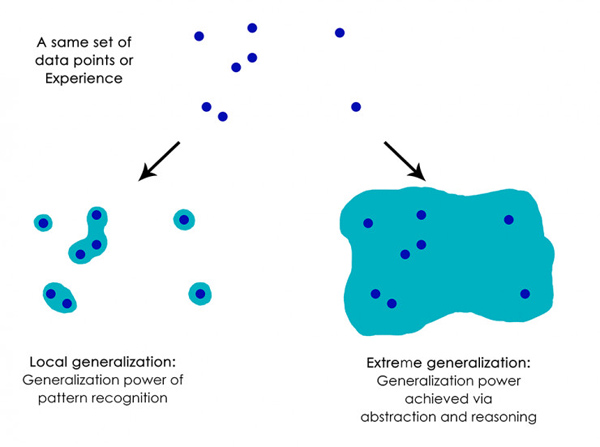
ОжВПЗКЛЏЃКФЃЪНЪЖБ№МЖБ№ЕФЗКЛЏФмСІ; МЋЯоЗКЛЏЃКгЩГщЯѓКЭЭЦРэЕУЕНЕФЗКЛЏФмСІ
змжЎЃЌОЁЙмЮвУЧдкЛњЦїИажЊЗНУцШЁЕУСЫНјеЙЃЌЕЋЮвУЧРыШЫРрМЖБ№ЕФ AI ЛЙКмдЖЃКЮвУЧЕФФЃаЭжЛФмжДааОжВПЗКЛЏЃЌвЊЪЪгІвЛжжаТГЁОАБиаыгыдЪМЪ§ОнСЊЯЕЕФКмНєУмЃЌЖјШЫРрШЯжЊФмЙЛМЋЯоЗКЛЏЃЌПьЫйЪЪгІШЋаТЕФЧщПіЃЌЛђЮЊГЄЦкЕФЮДРДЧщПізіГіЙцЛЎЁЃ
в§Щъ
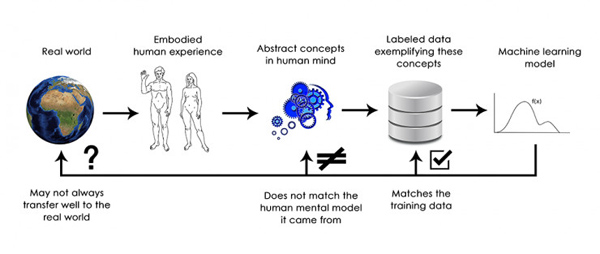
вдЯТЪЧФњгІИУМЧзЁЕФФкШнЃКЕНФПЧАЮЊжЙЃЌЩюЖШбЇЯАЕФЮЈвЛеце§ГЩЙІжЎДІОЭЪЧдкИјЖЈДѓСПШЫЙЄзЂЪЭЪ§ОнЕФЧщПіЯТЃЌЪЙгУСЌајМИКЮБфЛЛНЋПеМф
X гГЩфЕНПеМф Y ЕФФмСІЁЃзіКУетМўЪТЖдгкУПИіаавЕРДЫЕЖМЪЧвЛМўИФБфаавЕгЮЯЗЙцдђЕФЪТЖљЃЌЕЋЫќРыШЫРрМЖБ№ЕФ
AI ЛЙгаКмГЄЕФТЗвЊзпЁЃ
ЮЊСЫНтГ§етаЉОжЯоадВЂПЊЪМгыШЫРрДѓФдНјааОКељЃЌЮвУЧашвЊДгМђЕЅЕФЪфШыЕНЪфГігГЩфзЊЯђЭЦРэКЭГщЯѓЁЃМЦЫуЛњГЬађПЩФмЪЧЖдИїжжЧщПіКЭИХФюНјааГщЯѓНЈФЃЕФвЛИіКЯЪЪЕФЛљДЁЁЃЮвУЧжЎЧАЪщжавбОЫЕЙ§ЃЌЛњЦїбЇЯАФЃаЭПЩвдБЛЖЈвхЮЊЁИПЩбЇЯАГЬађЁЙ;ФПЧАЮвУЧФмбЇЯАЕФГЬађЪєгкЫљгаПЩФмГЬађжаЗЧГЃЯСеКЭЬиЖЈзгМЏЁЃЕЋЪЧШчЙћЮвУЧФмЙЛвдФЃПщЛЏКЭПЩжигУЕФЗНЪНбЇЯАШЮКЮГЬађФи?
МјгкЮвУЧЫљСЫНтЕНЕФЩюЖШЩёОЭјТчЕФЙЄзїЛњжЦЁЂОжЯоадвдМАЕБЧАЕФбаОПзДПіЃЌЮвУЧЪЧЗёПЩвддЄМћЕНЩёОЭјТчдкжаЦкжЎФкНЋШчКЮЗЂеЙФи?етРяЗжЯэвЛаЉЮвЕФИіШЫЯыЗЈЁЃЧызЂвтЮвВЂУЛгаФмдЄВтЮДРДЕФЫЎОЇЧђЃЌЫљвдЮвЫљзіЕФДѓВПЗждЄВтПЩФмЖМНЋЪЇАмЁЃетЭъШЋОЭЪЧвЛЦЊдЄВтадЕФЬћзгЃЌЮвжЎЫљвдЗжЯэетаЉЭЦВтВЂВЛЪЧЯЃЭћЫќУЧдкВЛОУЕФЮДРДЛсБЛжЄУїЪЧе§ШЗЕФЃЌЖјЪЧвђЮЊетаЉдЄВтдкЕБЧАПДРДЗЧГЃгаШЄЖјЧвОпгаЪЕМљадЕФЁЃ
змЕФРДЫЕЃЌЮвдЄМћЕФМИИіжївЊЗНЯђЪЧЃК
1.гыЭЈгУМЦЫуЛњГЬађИќНгНќЕФФЃаЭЃЌНЈСЂдкБШЮвУЧЕБЧАПЩЮЂЗжВувЊЗсИЛЕУЖрЕФЛљдЊжЎЩЯЁЊЁЊетвВЪЧЮвУЧШчКЮСюФЃаЭЛёЕУЭЦРэКЭГщЯѓЕФВпТдЃЌЖјетвЛЕувВЪЧЕБЧАФЃаЭЕФИљБОШѕЕуЁЃ
2.ЪЙЩЯЪіГЩЮЊПЩФмЕФаТЪНбЇЯАВпТдЁЊЁЊЫќПЩвдЪЙЕУФЃаЭАкЭбЕБЧАЕФПЩЮЂЗжБфЛЛЁЃ
3.ашвЊИќЩйЕФШЫРрЙЄГЬЪІВЮгыЕФФЃаЭЁЊЁЊЮоанжЙЕиЕїВЮВЛгІИУГЩЮЊФуЙЄзїЕФвЛВПЗжЁЃ
4.ЖдвдЧАбЇЯАЕФЬиеїКЭМмЙЙНјааИќДѓКЭИќЯЕЭГЛЏЕФИДгУ;ЛљгкПЩИДгУКЭФЃПщЛЏзгГЬађЕФдЊбЇЯАЯЕЭГ(Meta-learning
systems)ЁЃ
ДЫЭтжЕЕУзЂвтЕФЪЧЃЌЮвЕФетаЉЫМПМВЂВЛЪЧеыЖдвбОГЩЮЊМрЖНЪНбЇЯАжїСІЕФЩюЖШбЇЯАЁЃЧЁЧЁЯрЗДЃЌетаЉЫМПМЪЪгУгкШЮКЮаЮЪНЕФЛњЦїбЇЯАЃЌАќРЈЮоМрЖНбЇЯАЁЂздЮвМрЖНбЇЯАКЭЧПЛЏбЇЯАЁЃФуЕФБъЧЉРДздгкФФРявдМАФуЕФбЕСЗбЛЗЪЧЪВУДбљЕФЃЌетаЉЖМВЛживЊЁЃетаЉЛњЦїбЇЯАЕФВЛЭЌЗжжЇжЛЪЧЭЌвЛЙЙдьЕФВЛЭЌЗНУцЁЃНгЯТРДШУЮвУЧПЊЪМЩюШыЬНЬжЁЃ
ФЃаЭМДГЬађ
е§ШчЮвУЧдкЧАвЛЦЊЮФеТжаЫљЬсЕНЕФЃЌЮвУЧдкЛњЦїбЇЯАСьгђПЩвддЄЦкЕФвЛИізЊБфЗЂеЙЪЧЃЌДгДПДтФЃЪНЪЖБ№ВЂЧвжЛФмЪЕЯжОжВПЗКЛЏФмСІ(Local
generalizationЃЌМћЩЯЦЊ)ЕФФЃаЭЃЌзЊЯђФмЙЛЪЕЯжГщЯѓКЭЭЦРэЕФФЃаЭЃЌвВОЭЪЧПЩвдДяЕНжеМЋЕФЗКЛЏФмСІЁЃФПЧАШЫЙЄжЧФмГЬађФмЙЛНјааЕФЛљБОЭЦРэаЮЪНЃЌЖМЪЧгЩШЫРрГЬађдБгВБрТыЕФЃКР§ШчвРППЫбЫїЫуЗЈЁЂЭМаЮДІРэКЭаЮЪНТпМЕФШэМўЁЃОпЬхЖјбдЃЌБШШчдк
DeepMind ЕФ AlphaGo жаЃЌДѓВПЗжЕФЁИжЧФмЁЙЖМЪЧгЩзЈвЕГЬађдБЩшМЦКЭгВБрТыЕФ(ШчУЩЬиПЈТхЪїЫбЫї)ЃЌДгЪ§ОнжабЇЯАжЛЗЂЩњдкзЈУХЕФзгФЃПщ(МлжЕЭјТчКЭВпТдЭјТч)ЁЃЕЋЪЧдкНЋРДЃЌетбљЕФШЫЙЄжЧФмЯЕЭГКмПЩФмЛсБЛЭъШЋбЇЯАЃЌЖјВЛашвЊШЫЙЄНјааВЮгыЁЃ
гаЪВУДАьЗЈПЩвдзіЕНетвЛЕу?ШУЮвУЧРДПМТЧвЛИіжкЫљжмжЊЕФЭјТчРраЭЃКЕнЙщбЛЗЩёОЭјТч(RNN)ЁЃживЊЕФвЛЕуЪЧЃЌЕнЙщбЛЗЩёОЭјТчБШЧАРЁЭјТчЕФЯожЦРДЕФЩйЁЃетЪЧвђЮЊЕнЙщбЛЗЩёОЭјТчВЛНіНіЪЧвЛжжМИКЮБфЛЛЃКЫќУЧЪЧдк
for бЛЗФкжиИДгІгУЕФМИКЮБфЛЛЁЃЪБађ for бЛЗБОЩэЪЧгЩШЫРрПЊЗЂепгВБрТыЕФЃКЫќЪЧЭјТчЕФФкжУМйЩшЁЃздШЛЕиЃЌЕнЙщЩёОЭјТчдкЫќУЧПЩвдБэеїЕФФкШнЩЯвРШЛЗЧГЃгаЯоЃЌжївЊЪЧвђЮЊЫќУЧжДааЕФУПвЛВНШдШЛжЛЪЧвЛИіПЩЮЂЗжЕФМИКЮБфЛЛЃЌЖјЫќУЧДгЕБЧАВНЕНЯТвЛВНДЋЫЭаХЯЂЕФЗНЪНЪЧЭЈЙ§СЌајМИКЮПеМф(зДЬЌЯђСП)жаЕФЕуЁЃ
ЯждкЃЌЩшЯывЛЯТЩёОЭјТчНЋвдРрЫЦЕФЗНЪНЁИБрГЬЁЙЃЌБШШч for бЛЗБрГЬЛљдЊЃЌЕЋВЛНіНіЪЧвЛИіДјгагВБрТыЕФМИКЮФкДцгВБрТы
for бЛЗЃЌЖјЪЧвЛДѓзщБрГЬЛљдЊЃЌШЛКѓФЃаЭПЩвдздгЩВйзнетаЉЛљдЊвдРЉеЙЫќУЧЕФДІРэЙІФмЃЌР§Шч if ЗжжЇЁЂwhile
бЛЗЁЂБфСПДДНЈЁЂГЄЦкМЧвфЕФДХХЬДцДЂЁЂХХађВйзїКЭИпМЖЪ§ОнНсЙЙ(ШчСаБэЁЂЭМКЭЩЂСаБэЕШ)ЕШЕШЁЃетбљЕФЭјТчПЩвдБэеїЕФГЬађПеМфНЋдЖдЖДѓгкЕБЧАЩюЖШбЇЯАФЃаЭПЩвдБэеїЕФПеМфЃЌВЂЧвЦфжавЛаЉГЬађЩѕжСПЩвдШЁЕУгХдНЕФЗКЛЏФмСІЁЃ
змЖјбджЎЃЌЮвУЧНЋдЖРыЁИгВБрТыЫуЗЈжЧФмЁЙ(ЪжЙЄШэМў)ЃЌвдМАЁИбЇЯАМИКЮжЧФмЁЙ(ЩюЖШбЇЯА)ЁЃЮвУЧНЋгЕгаЬсЙЉЭЦРэКЭГщЯѓФмСІЕФаЮЪНЛЏЫуЗЈФЃПщЃЌвдМАЬсЙЉЗЧе§ЪНжБОѕКЭФЃЪНЪЖБ№ЙІФмЕФМИКЮФЃПщЁЃећИіЯЕЭГжЛашвЊКмЩйЕФШЫЙЄВЮгыМДПЩЭъГЩбЇЯАЁЃ
ЮвШЯЮЊШЫЙЄжЧФмЯрЙиЕФвЛИізгСьгђПЩФмМДНЋгРДДКЬьЃЌФЧОЭЪЧГЬађКЯГЩ(Program synthesis)ЃЌЬиБ№ЪЧЩёОГЬађКЯГЩ(Neural
program synthesis)ЁЃГЬађКЯГЩАќРЈЭЈЙ§ЪЙгУЫбЫїЫуЗЈ(БШШчдквХДЋБрГЬжаПЩФмЪЧвХДЋЫбЫї)РДздЖЏЩњГЩМђЕЅЕФГЬађЃЌгУвдЬНЫїПЩФмГЬађЕФОоДѓПеМфЁЃЕБевЕНгыашЧѓ(ашЧѓЭЈГЃвдвЛзщЪфШы-ЪфГіЖдНјааЬсЙЉ)ЯрЦЅХфЕФГЬађЪБЃЌЫбЫїНЋЭЃжЙЁЃе§ШчФуЫљЯыЕФЃЌЫќЪЧЗёШУФуЯыЦ№СЫЛњЦїбЇЯАЃКИјГіЪфШы-ЪфГіЖдзїЮЊЁИбЕСЗЪ§ОнЁЙЃЌЮвУЧевЕНвЛИіНЋЪфШыгГЩфЕНЪфГіЕФЁИГЬађЁЙЃЌВЂЧвФмНЋЫќЗКЛЏЕНЦфЫќЪфШыЁЃВЛЭЌжЎДІдкгкЃЌЮвУЧВЛЪЧдкгВБрТыГЬађ(ЩёОЭјТч)жабЇЯАВЮЪ§жЕЃЌЖјЪЧЭЈЙ§РыЩЂЫбЫїЙ§ГЬЩњГЩдДДњТыЁЃ
ЮввЛЖЈЛсЗЧГЃЦкД§дкНгЯТРДЕФМИФъФкетИізгСьгђЛсдйДЮгРДЕкЖўИіДКЬьЁЃЬиБ№ЪЧЃЌЮвЦкД§дкЩюЖШбЇЯАКЭГЬађКЯГЩжЎМфГіЯжвЛИіНЛВцзгСьгђЃЌдкИУСьгђЮвУЧВЛЛсВЩгУЭЈгУгябдЩњГЩГЬађЃЌЖјЪЧдіЧПСЫвЛЬзЗсИЛЕФЫуЗЈдгяЕФЩњГЩЩёОЭјТч(МИКЮЪ§ОнДІРэСї)ЃЌР§Шч
for бЛЗЕШЕШЁЃетгІИУБШжБНгЩњГЩдДДњТыИќМгШнвзДІРэКЭгагУЃЌЫќНЋДѓДѓРЉеЙЛњЦїбЇЯАПЩвдНтОіЕФЮЪЬтЗЖЮЇЁЊЁЊЮвУЧПЩвдИљОнЪЪЕБЕФбЕСЗЪ§ОнздЖЏЩњГЩГЬађПеМфЁЃЗћКХ
AI(Symbolic AI) КЭМИКЮ AI(Geometric AI)ЕФШкКЯЃЌЕБДњЕнЙщЩёОЭјТчПЩвдПДзіЪЧетжжЛьКЯЫуЗЈМИКЮФЃаЭЕФПЊЩНБЧзцЁЃ
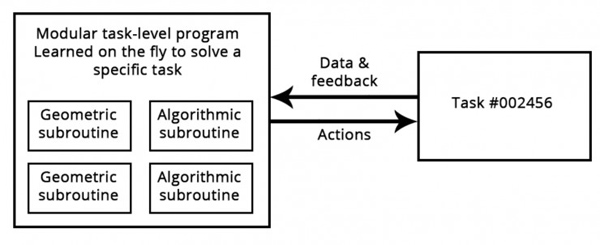
вРППМИКЮЛљдЊ(ФЃЪНЪЖБ№гыжБОѕ)КЭЫуЗЈЛљдЊ(ЭЦРэЁЂЫбЫїКЭДцДЂ)ЕФбЇЯАГЬађ
ГЌдНЗДЯђДЋВЅКЭПЩЮЂЗжВу
ШчЙћЛњЦїбЇЯАФЃаЭБфЕУИќЯёЪЧвЛЖЮГЬађЃЌФЧУДЫќУЧНЋБфЕУВЛдйПЩЮЂЁЊЁЊЕБШЛетаЉГЬађШдШЛЛсНЋСЌајЕФМИКЮВузїЮЊзгГЬађНјааЪЙгУЃЌетЖМЪЧПЩЮЂЕФЃЌЕЋЪЧећИіФЃаЭШДВЛЛсЁЃвђДЫЃЌдкЙЬЖЈЕФгВБрТыЭјТчжаЪЙгУЗДЯђДЋВЅРДЕїећШЈжижЕЮоЗЈГЩЮЊНЋРДбЕСЗФЃаЭЕФЪзбЁАьЗЈЁЊЁЊжСЩйЫќЮоЗЈЯёЯждкетбљЖРеМїЁЭЗЁЃЮвУЧашвЊевГіФмгааЇбЕСЗЗЧЮЂЗжЯЕЭГЕФЗНЗЈЁЃФПЧАЕФЗНЗЈАќРЈгавХДЋЫуЗЈЁЂНјЛЏВпТдЁЂФГаЉЧПЛЏбЇЯАЗНЗЈКЭНЛЬцЗНЯђГЫзгЗЈ(Alternating
direction method of multipliers, ADMM)ЁЃздШЛЖјШЛЕФЃЌЬнЖШЯТНЕЗЈФФЖљвВВЛЛсШЅЁЊЁЊЬнЖШаХЯЂЖдгкгХЛЏПЩЮЂЗжВЮЪ§КЏЪ§змЪЧгагУЕФЁЃЕЋЪЧЮвУЧЕФФЃаЭПЯЖЈЛсБШЕЅДПЕФПЩЮЂВЮЪ§КЏЪ§РДЕФИќМгЧПДѓЃЌвђДЫЫќУЧЕФзджїИФЩЦ(ЁИЛњЦїбЇЯАЁЙжаЕФЁИбЇЯАЁЙ)ашвЊЕФНЋВЛНіНіЪЧЗДЯђДЋВЅЁЃ
ДЫЭтЃЌЗДЯђДЋВЅЪЧЖЫЕНЖЫЕФбЇЯАФЃЪНЃЌетЖдгкбЇЯАСМКУЕФСДЪНзЊЛЛЪЧвЛМўКУЪТЧщЃЌЕЋдкМЦЫуаЇТЪЩЯШДЗЧГЃЕЭаЇЃЌвђЮЊЫќУЛгаГфЗжРћгУЩюЖШЩёОЭјТчЕФФЃПщЛЏЬиадЁЃЮЊСЫЬсИпаЇТЪЃЌгавЛИіЭЈгУЕФВпТдЃКв§ШыФЃПщЛЏвдМАВуДЮНсЙЙЁЃЫљвдЮвУЧПЩвдЭЈЙ§в§ШыЗжРыЕФбЕСЗФЃПщвдМАЫќУЧжЎМфЕФвЛаЉЭЌВНЛњжЦЃЌвдЗжВуЕФЗНЪНзщжЏЦ№РДЃЌДгЖјЪЙЕУЗДЯђДЋВЅМЦЫуИќМгИпаЇЁЃDeepMind
НќЦкЕФЙЄзїЁИКЯГЩЬнЖШЁЙдкФГжжГЬЖШЩЯЗДгГГіСЫетвЛВпТдЁЃЮвдЄЦкВЛОУЕФНЋРДдкетвЛПщНЋгаИќЖрЕФЙЄзїПЊеЙЁЃ
ЮвУЧПЩвддЄМћЕФвЛИіЮДРДОЭЪЧЃЌетаЉФЃаЭНЋБфЕУШЋОжВЛПЩЮЂЗж(ЕЋНЋОпгаОжВППЩЮЂЗжад)ЃЌШЛКѓЭЈЙ§гааЇЕФЫбЫїЙ§ГЬЖјВЛЪЧЬнЖШВпТдНјаабЕСЗЁЃСэвЛЗНУцЃЌЭЈЙ§РћгУвЛаЉИќИпаЇАцБОЕФЗДЯђДЋВЅвдЗЂЛгЬнЖШЯТНЕВпТдЕФзюДѓгХЕуЃЌОжВППЩЮЂЗжЧјгђНЋЕУЕНИќПьЕФбЕСЗЫйЖШЁЃ
здЖЏЛЏЛњЦїбЇЯА
дкНЋРДЃЌФЃаЭМмЙЙНЋФмЙЛЭЈЙ§бЇЯАЪЕЯжЃЌЖјВЛЪЧашвЊгЩЙЄГЬЪІЪжЙЄЩшжУЁЃВЂЧвздЖЏЛЏбЇЯАМмЙЙгыЪЙгУИќЗсИЛЕФЛљдЊКЭГЬађЪНЛњЦїФЃаЭ(Program-like
machine learning models)НЋНсКЯдквЛЦ№ЁЃ
ФПЧАЩюЖШбЇЯАЙЄГЬЪІДѓВПЗжЙЄзїЖМЪЧЪЙгУ Python НХБОРДДІРэЪ§ОнЃЌШЛКѓЛЈЗбКмЖрЕФЪБМфРДЕїећЩюЖШЭјТчЕФМмЙЙКЭГЌВЮЪ§вдЛёЕУвЛИіЛЙЙ§ЕУШЅЕФФЃаЭЁЊЁЊЛђепЫЕЩѕжСЛёЕУвЛИіадФмзюЯШНјЕФФЃаЭЃЌШчЙћетИіЙЄГЬЪІЪЧЙЛалаФВЊВЊЕФЛАЁЃЮугЙжУвЩЃЌетбљЕФзіЗЈВЂЗЧзюМбЕФЃЌЕЋЪЧДЫЪБЩюЖШбЇЯАММЪѕвРШЛПЩвдЗЂЛгвЛЖЈЕФаЇгУЁЃВЛЙ§ВЛавЕФЪЧЃЌЪ§ОнДІРэВПЗжШДКмФбЪЕЯжздЖЏЛЏЃЌвђЮЊЫќЭЈГЃашвЊСьгђжЊЪЖвдМАЖдЙЄГЬЪІЯывЊЕФаЇЙћгаЗЧГЃЧхЮњЕФИпВуДЮРэНтЁЃШЛЖјЃЌГЌВЮЪ§ЕїећЪЧвЛИіЗЧГЃМђЕЅЕФЫбЫїЙ§ГЬЃЌВЂЧвЮвУЧвбОжЊЕРСЫЙЄГЬЪІдкетжжЧщПіЯТЯывЊШЁЕУЪВУДаЇЙћЃКЫќгЩе§дкБЛЮЂЕїЕФЭјТчЕФЫ№ЪЇКЏЪ§ЖЈвхЁЃЩшжУЛљБОЕФЁИAutoMLЁЙЯЕЭГвбОКмГЃМћСЫЃЌЫќНЋИКд№ДѓВПЗжФЃаЭЕФЕїећЁЃЮвЩѕжСдкМИФъЧАЩшжУСЫздМКЕФФЃаЭВЂгЎЕУСЫ
Kaggle ОКШќЁЃ
дкзюЛљБОЕФВуУцЩЯЃЌетбљЕФЯЕЭГПЩвдМђЕЅЕиЕїећеЛжаЖбЕўЕФВуЪ§ЁЂЫГађвдМАУПвЛВужаЕФЕЅдЊЛђепЫЕТЫВЈЦїЕФЪ§СПЁЃетЭЈГЃЪЧЭЈЙ§РрЫЦгк
Hyperopt етбљЕФПтРДЭъГЩЕФЃЌЮвУЧдкЁЖDeep Learning with PythonЁЗЕФЕк
7 еТжадјЬжТлЙ§етЕуЁЃЕЋЮвУЧЕФжОЯђПЩвдИќМгдЖДѓЃЌВЂГЂЪдДгСуПЊЪМбЇЯАЪЪЕБЕФМмЙЙЃЌШЛКѓОЁПЩФмМѕЩйЯожЦЬѕМўЁЃетПЩвдЭЈЙ§ЧПЛЏбЇЯАЛђепвХДЋЫуЗЈРДЪЕЯжЁЃ
СэвЛИіживЊЕФ AutoML ЗНЯђЪЧгыФЃаЭШЈживЛЦ№СЊКЯбЇЯАФЃаЭМмЙЙЁЃгЩгкДгЭЗПЊЪМбЕСЗвЛИіШЋаТЕФМмЙЙЃЌВЂЧвЛЙвЊдкУПДЮГЂЪджаЖдМмЙЙНјааЮЂЕїЪЧЗЧГЃКФЪБКЭЕЭаЇЕФЃЌЫљвдвЛИіеце§ЧПДѓЕФ
AutoML ЯЕЭГПЩвддкЭЈЙ§бЕСЗЪ§ОнЗДЯђЕїећФЃаЭЬиеїЕФЭЌЪБЩшЗЈИФНјЬхЯЕНсЙЙЃЌДгЖјЯћГ§ЫљгаЕФМЦЫуШпгрЁЃЕБЮве§дкзЋаДетаЉФкШнЪБЃЌетаЉЗНЗЈвбОПЊЪМГіЯжСЫЁЃ
ЕБетжжЧщПіЗЂЩњЪБЃЌЛњЦїбЇЯАЙЄГЬЪІЕФЙЄзїВЛЛсЯћЪЇЃЌЧЁЧЁЯрЗДЃЌЙЄГЬЪІНЋдкМлжЕДДдьСДЩЯзпЩЯИпЕиЁЃЫћУЧНЋПЊЪМЭЖШыИќЖрОЋСІРДДђдьеце§ЗДгГвЕЮёФПБъЕФИДдгЫ№ЪЇКЏЪ§ЃЌВЂЩюШыРэНтЫћУЧЕФФЃаЭШчКЮгАЯьЫћУЧЫљВПЪ№ЕФЪ§зжЩњЬЌЯЕЭГ(Р§ШчЃЌИКд№ЯћЗбФЃаЭдЄВтНсЙћвдМАВњЩњФЃаЭбЕСЗЪ§ОнЕФгУЛЇ)ЃЌЖјетаЉЮЪЬтФПЧАжЛгаОоЭЗЙЋЫОВХгаЯОЙЫМАЁЃ
жеЩњбЇЯАКЭФЃПщЛЏзгГЬађИДгУ
ШчЙћФЃаЭБфЕУдНРДдНИДдгВЂЧвНЈСЂдкИќЗсИЛЕФЫуЗЈЛљдЊжЎЩЯЃЌФЧУДетжждіМгЕФИДдгЖШНЋашвЊдкВЛЭЌШЮЮёжЎМфЪЕЯжИќКУЕиИДгУадЃЌЖјВЛЪЧУПЕБЮвУЧгаСЫаТШЮЮёЛђепаТЪ§ОнМЏжЎКѓЛЙашвЊДгЭЗПЊЪМбЕСЗаТФЃаЭЁЃЪТЪЕЩЯЃЌаэЖрЪ§ОнМЏЖМвђЮЊЪ§ОнСПВЛЙЛДѓЖјВЛзувджЇГжДгЭЗбЕСЗаТЕФИДдгФЃаЭЃЌВЂЧвашвЊРћгУРДздЯШЧАЪ§ОнМЏжаЕФаХЯЂЁЃОЭЯёФуВЛашвЊдкУПДЮДђПЊвЛБОаТЪщЪБЖМжиаТбЇЯАвЛБщгЂгявЛбљЁЃДЫЭтЃЌгЩгкЕБЧАШЮЮёгывдЧАгіЕНЕФШЮЮёжЎМфПЩФмДцдкДѓСПЕФжиЕўЃЌвђДЫЖдУПИіаТШЮЮёЖМДгЭЗПЊЪМбЕСЗФЃаЭЕФзіЗЈЗЧГЃЕЭаЇЁЃ
ДЫЭтЃЌНќФъРДЗДИДГіЯжЕФвЛИіЯджјЕФЙлВтНсЙћЪЧЃЌбЕСЗЯрЭЌЕФФЃаЭвдЭЌЪБжДааМИИіЫЩЩЂСЌНгЕФШЮЮёЃЌНЋВњЩњвЛИіЖдУПИіШЮЮёЖМИќКУЕФФЃаЭЁЃР§ШчЃЌбЕСЗЯрЭЌЕФЩёОЛњЦїЗвыФЃаЭвдИВИЧДггЂгяЕНЕТгяЁЂЗЈгяЕНвтДѓРћгяЕФЗвыЃЌНЋЕУЕНвЛИіБШЕЅЖРбЕСЗРДЕУИќКУЕФФЃаЭЁЃгжБШШчгыЭМЯёЗжИюФЃаЭвЛЦ№бЕСЗЭМЯёЗжРрФЃаЭЃЌЙВЯэЯрЭЌЕФОэЛ§КЫЃЌДгЖјВњЩњвЛИідкСНЯюШЮЮёжаЖМБэЯжИќКУЕФФЃаЭЃЌЕШЕШЁЃетвЛЕуЗЧГЃжБЙлЃКетаЉПДЦ№РДЫЦКѕВЛЯрЙиЕФШЮЮёжЎМфзмЪЧДцдкзХаХЯЂжиЕўЃЌвђДЫСЊКЯбЕСЗФЃаЭБШЦ№жЛдкФГвЛЬиЖЈШЮЮёЩЯбЕСЗЕФФЃаЭЃЌПЩвдЛёШЁгыУПЯюЕЅЖРШЮЮёгаЙиЕФДѓСПаХЯЂЁЃ
ЮвУЧФПЧАбизХПчШЮЮёФЃаЭИДгУ(Model reuse across tasks)ЕФЗНЯђЫљзіЕФЙЄзїОЭЪЧЃЌРћгУдЄбЕСЗШЈжиФЃаЭРДДІРэГЃМћШЮЮёЃЌР§ШчЪгОѕЬиеїЬсШЁЁЃФуНЋдкЕк
5 еТПДЕНетвЛЕуЁЃдкНЋРДЃЌЮвЯЃЭћетжжЗКЛЏФмСІФмЪЕЯжИќМбЕФЦеЪЪадЃКЮвУЧВЛНіЛсИДгУвдЧАбЇЙ§ЕФЬиеї(згФЃаЭЕФШЈжижЕ)ЃЌЛЙЛсИДгУФЃаЭМмЙЙКЭбЕСЗЙ§ГЬЁЃЫцзХФЃаЭБфЕУдНРДдНЯёГЬађЃЌЮвУЧНЋПЊЪМжигУГЬађзгГЬађ(Program
subroutines)ЃЌБШШчШЫРрБрГЬгябджаЕФКЏЪ§КЭРрЁЃ
ЯыЯыНёЬьШэМўПЊЗЂЕФЙ§ГЬЃКвЛЕЉЙЄГЬЪІНтОіСЫвЛИіЬиЖЈЕФЮЪЬт(Р§Шч Python жаЕФ HTTP ЧыЧѓЮЪЬт)ЃЌЫћУЧЛсНЋЦфДђАќЮЊвЛИіГщЯѓЧвПЩвджигУЕФПтЁЃетбљЮДРДУцСйРрЫЦЮЪЬтЕФЙЄГЬЪІПЩвдЭЈЙ§МђЕЅЕиЫбЫїЯжгаЕФПтЃЌШЛКѓЯТдиВЂдкЯюФПжаЪЙгУЫќРДНтОіЮЪЬтЁЃЯрРрЫЦЕиЃЌдкЮДРДдЊбЇЯА(Meta-learning)ЯЕЭГНЋПЩвдЭЈЙ§ЩИбЁИпМЖПЩжигУПщЕФШЋОжПтРДзщзАШЋаТЕФГЬађЁЃ
ЕБЯЕЭГЗЂЯжздМКЮЊМИИіВЛЭЌШЮЮёПЊЗЂСЫРрЫЦЕФГЬађзгГЬађЪБЃЌШчЙћФмЙЛОпБИЁИГщЯѓЁЙЕФФмСІЃЌМДзгГЬађЕФПЩжигУАцБОЃЌШЛКѓОЭНЋЦфДцДЂЕНШЋОжПтжжЁЃетбљЕФЙ§ГЬНЋЪЕЯжГщЯѓЕФФмСІЃЌетЪЧЪЕЯжЁИжеМЋЗКЛЏЁЙЕФБивЊзщГЩВПЗжЃКдкВЛЭЌШЮЮёКЭСьгђЗЂЯжгагУЕФзгГЬађПЩвдБЛШЯЮЊЁИГщЯѓЁЙСЫвЛаЉЮЪЬтНтОіЗНАИЕФФГаЉЗНУцЁЃетРяЁИГщЯѓЁЙЕФЖЈвхгыШэМўЙЄГЬжаЕФГщЯѓИХФюЯрЫЦЁЃетаЉзгГЬађПЩвдЪЧМИКЮЕФ(ОпгадЄбЕСЗБэеїЕФЩюЖШбЇЯАФЃПщ)вВПЩвдЪЧЫуЗЈЕФ(ИќНгНќЕБДњШэМўЙЄГЬЪІЪЙгУЕФШэМўПт)ЁЃ
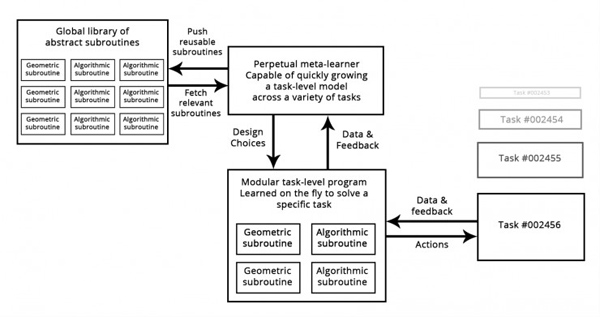
дЊбЇЯАЦїФмЙЛЪЙгУПЩИДгУЛљдЊ(ЫуЗЈКЭМИКЮ)ПьЫйПЊЗЂеыЖдЬиЖЈШЮЮёЕФФЃаЭЃЌДгЖјЪЕЯжЁАМЋЖЫЗКЛЏЁБЁЃ
змНсЃКЖДМћЮДРД
змЖјбджЎЃЌетРяЪЧвЛаЉЮвЖдЛњЦїбЇЯАГЄЦкЗЂеЙЕФЖДМћЃК
1.ФЃаЭНЋИќМгЯёГЬађЃЌВЂЧвНЋОпгадЖдЖГЌГіЮвУЧФПЧАЪЙгУЕФЪфШыЪ§ОнЕФСЌајМИКЮБфЛЛЕФФмСІЁЃетаЉГЬађПЩвдЫЕИќНгНќШЫРрЖджмЮЇЛЗОГКЭздЩэГщЯѓЕФаФРэФЃаЭЃЌВЂЧвгЩгкЦфЗсИЛЕФЫуЗЈаджЪЃЌЫќУЧНЋОпгаИќЧПЕФЗКЛЏФмСІЁЃ
2.ЬиБ№ЪЧЃЌФЃаЭНЋШкКЯЫуЗЈФЃПщКЭМИКЮФЃПщЃЌЫуЗЈФЃПщПЩвдЬсЙЉе§ЪНЭЦРэЁЂЫбЫїКЭГщЯѓФмСІЃЌЖјМИКЮФЃПщПЩвдЬсЙЉЗЧе§ЪНЕФжБОѕКЭФЃЪНЪЖБ№ЙІФмЁЃAlphaGo(вЛИіашвЊДѓСПЪжЖЏШэМўЙЄГЬКЭШЫЮЊЩшМЦОіВпЕФЯЕЭГ)ЬсЙЉСЫвЛИідчЦкЕФР§згЃЌЫќеЙЪОСЫЕБЗћКХ
AI КЭМИКЮ AI ШкКЯжЎКѓНЋЪЧЪВУДбљзгЁЃ
3.ЭЈЙ§ЪЙгУДцДЂдкПЩИДгУзгГЬађШЋОжПт(етЪЧвЛИіЭЈЙ§дкЪ§вдЭђМЦЕФвдЧАЕФШЮЮёКЭЪ§ОнМЏЩЯбЇЯАЕФИпадФмФЃаЭбнБфЖјРДЕФПт)жаЕФФЃПщВПМўЃЌЫќУЧНЋЪЕЯжздЖЏГЩГЄЃЌЖјВЛЪЧгЩШЫРрЙЄГЬЪІЪжЙЄЩшЖЈЁЃгЩгкдЊбЇЯАЯЕЭГШЗЖЈСЫГЃМћЕФЮЪЬтНтОіФЃЪНЃЌЫќУЧНЋБфГЩвЛИіПЩИДгУЕФзгГЬађЁЊЁЊОЭЯёЕБДњШэМўЙЄГЬжаЕФКЏЪ§КЭРрвЛбљЁЊЁЊВЂЬэМгЕНШЋОжПтжаЃЌДгЖјЪЕЯжСЫГщЯѓФмСІЁЃ
4.етИіШЋОжПтКЭЯрЙиСЊЕФФЃаЭГЩГЄЯЕЭГ(Model-growing
system)НЋФмЙЛдкФГжжаЮЪНЩЯЪЕЯжРрШЫЕФЁИМЋЯоЗКЛЏЁЙЃКИјЖЈвЛИіаТШЮЮёЁЂаТЧщПіЃЌЯЕЭГНЋФмЙЛзщзАвЛИіЪЪгУгкаТШЮЮёЕФШЋаТЙЄзїФЃаЭЃЌЖјжЛашвЊКмЩйЕФЪ§ОнЁЃетвЊЙщЙІгк
1) ЗсИЛЕФОпгаЧПЗКЛЏФмСІЕФРрГЬађЛљдЊ(Program-like primitives);2) ОпгаЯрЫЦШЮЮёЕФЗсИЛОбщЁЃОЭЯёШЫРрПЩвдЛЈЗбКмЩйЕФЪБМфЭцКУвЛИіШЋаТИДдгЕФЪгЦЕгЮЯЗвЛбљЃЌвђЮЊЫћУЧгааэЖрвдЧАЕФгЮЯЗОбщЃЌВЂЧввђЮЊДгвдЧАОбщЕУГіЕФФЃаЭЪЧГщЯѓКЭРрГЬађЕФЃЌЖјВЛЪЧДЬМЄКЭааЮЊжЎМфЕФЛљБОгГЩфЁЃ
5.вђДЫЃЌетжжгРОУбЇЯАФЃаЭГЩГЄЯЕЭГ(Perpetually-learning
model-growing system)ПЩвдБЛГЦЮЊЭЈгУШЫЙЄжЧФм(Artificial General
Intelligence, AGI)ЁЃЕЋЪЧВЛвЊЕЃгЧШЮКЮЛњЦїШЫЦєЪОТМНЋЛсНЕСйЃКвђЮЊетЕЅДПжЛЪЧвЛИіЛУЯыЃЌЫќРДздгкШЫУЧЖджЧФмКЭММЪѕЕФвЛЯЕСаЩюПЬЮѓНтЁЃШЛЖјЃЌЖдетЗНУцЕФХњЦРВЂВЛдкБОЦЊЕФЬжТлЗЖГыжЎФкЁЃ
|









