| 编辑推荐: |
本文来自于juejin.im,文章带我们了解到了深度学习中多任务学习的基本原理。带你对这个有个新的认识。
|
|
介绍
为什么是多任务学习?
当你在思考新事物的时候,他们通常会利用他们以前的经验和获得的知识来加速现在的学习过程。当我们学习一门新语言的时候,尤其是相关的语言时,我们通常会使用我们一级学过的语言知识来加快这一门新语言的学习过程。这个过程也可以用另一种方式来理解
—— 学习一种新的语言可以帮助你更好的理解和说出自己的想法。
我们的大脑会同时学习多种不同的任务,无论我们是想将英文翻译成中文,还是想将中文翻译成德语,我们都是使用相同的大脑架构,也就是我们自己的脑袋。同理在我们的机器学习模型中,如果我们采用的是同一个网络来同时完成这两个任务,那么我们就可以把这个任务称为
“多任务学习”。
“多任务学习” 是最近几年或者说未来几年非常有趣和令人兴奋的一个研究领域,因为这个学习模式从根本上减少了学习新概念所需的数据量。深度学习其中一个最伟大的地方是,我们可以利用模型之间的参数共享来优化我们的模型,而这种方法在多任务学习中将显得尤为突出。
在我们开始这个领域的学习之前,我遇到了一些障碍 —— 虽然我们很容易理解实现多任务学习所需要的网络架构,但是我们很难弄清楚在
TensorFlow 中是如何实现它的。除了 TensorFlow 中的标准网络之外,我们做任何事情都需要对其工作原理有一个很好的立即,但是网上大多数的教程都是没有一个很好的指导教学功能。我希望以下教程可以简单解释一些关键概念,并帮助学习困难的你。
我们需要做什么
通过一个例子了解 TensorFlow 的计算图。使用 TensorFlow 进行多任务学习。如果你已经了解了
TensorFlow 的计算图,那么你可以跳过这部分。
了解我们如何使用计算图进行多任务学习。我们将通过一个例子来说明如何调整一个简单的计算图来完成多任务学习。
用一个简单例子来理解计算图
TensorFlow 的计算图能让 TensorFlow 运行的更加快,它是深度学习中一个很重要的组成部分,虽然这个组成部分时常让人感到困惑。
计算图可以能容易整理清楚模型的组织架构,这对我们进行多任务学习是非常有意义的。首先,让我们先来理解一些有关多任务学习的概念吧。
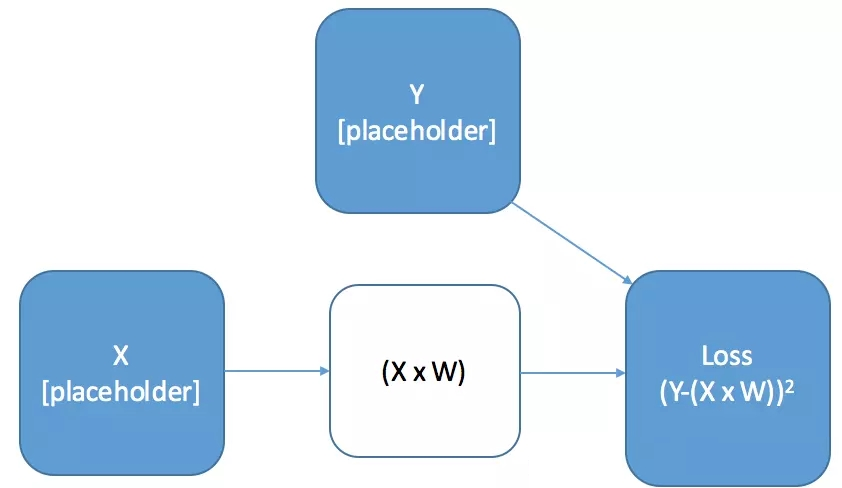
一个简单例子:线性变换
我们将对计算图进行简单的计算 —— 对输入数据进行线性变换,并计算平方根损失。
# Import Tensorflow
and numpy
import tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Create Placeholders For X And Y (for feeding
in data)
X = tf.placeholder("float",[10, 10],name="X")
# Our input is 10x10
Y = tf.placeholder("float", [10, 1],name="Y")
# Our output is 10x1
# Create a Trainable Variable, "W",
our weights for the linear transformation
initial_W = np.zeros((10,1))
W = tf.Variable(initial_W, name="W",
dtype="float32")
# Define Your Loss Function
Loss = tf.pow(tf.add(Y,-tf.matmul(X,W)),2,name="Loss") |
上面这张图和代码有几点需要强调:
如果我们现在运行这个代码,我们不会得到任何输出。请记住,计算图只是一个模板 —— 它上面都不做。如果我们想要一个计算输出,那么我们必须告诉
TensorFlow 使用 Session 来进行运行。
我们还没有明显创建计算图对象。你可能会希望我们必须在某处创建一个图像对象,以便 TensorFlow
知道我们想要创建的具体计算图是什么。事实上,我们可以通过使用 TensorFlow 操作,我们可以告诉
TensorFlow 哪些代码是在图中。
提示:保持计算图分离。你通常会在计算图外面进行相当数量的数据操作和计算,也就是说我们要区分哪些代码是属于计算图的,哪些代码是不属于计算图的。我喜欢把我的计算图放在一个单独的文件里,这样比较容易区分出来。
计算图上的计算是在 TensorFlow 会话中进行的。要从会话中获取结果,你需要提供两件事情:目标结果和输入数据。
目标结果或者操作。你可以告诉 TensorFlow 计算图中哪些部分是要返回值的,并且会自动计算需要运行的内部计算结果。例如,你可以调用操作来初始化变量。
输入通道。在大多数计算中,你将提供临时输入数据。在这种情况下,你可以使用此数据的占位符构建图形,并在计算时输入它。并非所有计算或者操作都需要输入
—— 对于许多人来说,所有信息都包含在计算图中。
# Import Tensorflow
and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Create Placeholders For X And Y (for feeding
in data)
X = tf.placeholder("float",[10, 10],name="X")
# Our input is 10x10
Y = tf.placeholder("float", [10, 1],name="Y")
# Our output is 10x1
# Create a Trainable Variable, "W",
our weights for the linear transformation
initial_W = np.zeros((10,1))
W = tf.Variable(initial_W, name="W",
dtype="float32")
# Define Your Loss Function
Loss = tf.pow(tf.add(Y,-tf.matmul(X,W)),2,name="Loss")
with tf.Session() as sess: # set up the session
sess.run(tf.initialize_all_variables())
Model_Loss = sess.run(
Loss, # the first argument is the name of the
Tensorflow variabl you want to return
{ # the second argument is the data for the
placeholders
X: np.random.rand(10,10),
Y: np.random.rand(10).reshape(-1,1)
})
print(Model_Loss) |
如何使用计算图来进行多任务学习
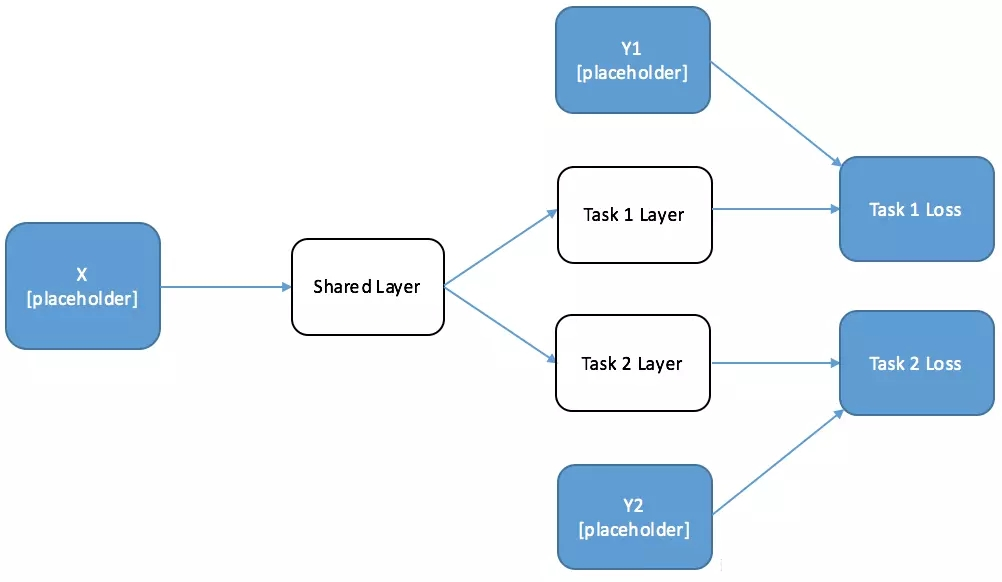
当我们创建一个执行多任务学习的神经网络时,我们希望网络中的某些神经元是被共享的,而网络的其它部分择时针对不同任务而单独设计的。当我们进行训练的时候,我们希望每个独立的任务都可以对共享神经元起到修改功能。
因此,首先,我们先绘制一个简单的双任务网络结构,该网络具有共享层和每个单独任务的特定网络层。我们将用我们的目标将这些输出提供给我们的损失函数。我已经在图中标记出来哪些地方是需要我们进行设计占位符的地方。
# GRAPH CODE
# ============
# Import Tensorflow
import Tensorflow as tf
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10],
name="X")
Y1 = tf.placeholder("float", [10,
1], name="Y1")
Y2 = tf.placeholder("float", [10,
1], name="Y2")
# Define the weights for the layers
shared_layer_weights = tf.Variable([10,20],
name="share_W")
Y1_layer_weights = tf.Variable([20,1], name="share_Y1")
Y2_layer_weights = tf.Variable([20,1], name="share_Y2")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer_weights = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1,Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2,Y2_layer) |
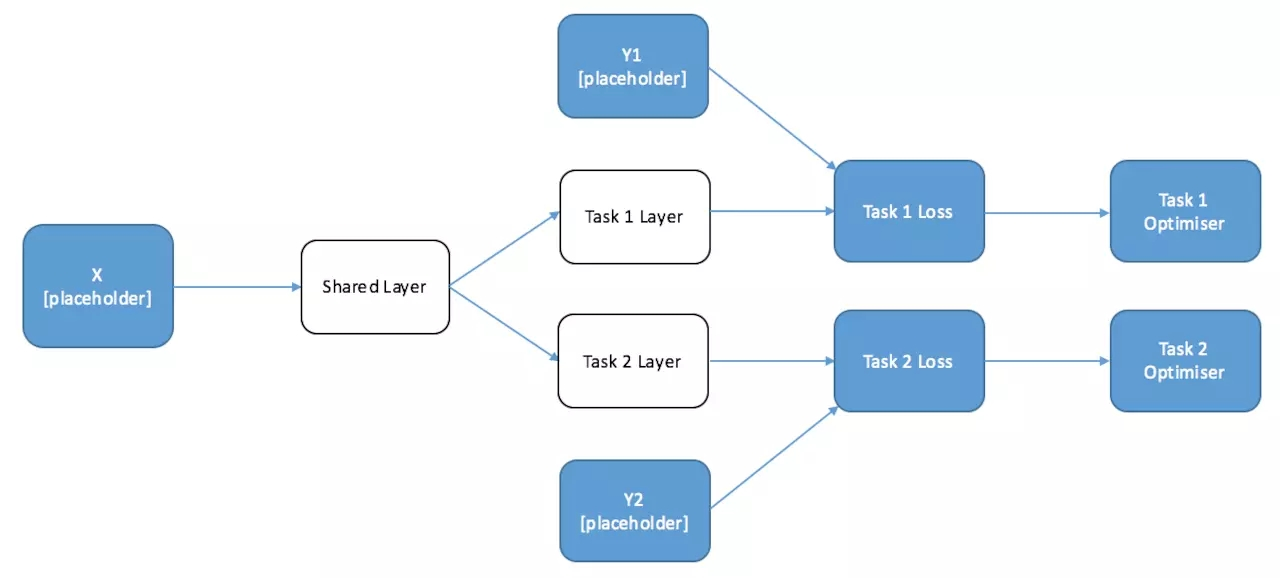
当我们训练这个网络时,我们希望在训练任务 2 的时候,不会改变任务 1 层的参数。但在训练两个中任何一个任务的时候,共享层的参数都会改变。这可能看起来有点困难
—— 通常我们在图中只有一个优化器,因为你只优化一个损失函数。值得庆幸的是,我们可以巧妙的利用图的性质来通过两种方式来训练这种模型。
交替训练
第一种解决方案特别适用于需要一批任务 1 数据,然后再需要一批任务 2 数据的情况。
请记住,TensorFlow 会自动计算出你所需要的操作都需要进行哪些计算,并且只进行这些计算。这意味着如果我们只对其中一个任务定义一个优化器,它将只训练计算该任务所需要的参数
—— 并且将其余的参数单独保留下来。由于任务 1 仅依赖于任务 1 层和共享层,所以任务 2 层的参数是不会改变的。让我们在每个任务结束时画出所需的优化器图表。
# GRAPH CODE
# ============
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10],
name="X")
Y1 = tf.placeholder("float", [10,
20], name="Y1")
Y2 = tf.placeholder("float", [10,
20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights,
name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights,
name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights,
name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
# optimisers
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss) |
我们可以通过交替调用每个任务优化器来进行多任务学习,这意味着我们可以不断地将每个任务的某些信息传送给另一个任务,因为这是通过共享层来完成的。不严格的说,我们正在发现一些任务之间的
“共性”。下面的代码为我们简单的实现了这一个过程。如果你跟着我的思路在一步一步实现,那么你可以复制下面的代码:
# Calculation
(Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
for iters in range(10):
if np.random.rand() < 0.5:
_, Y1_loss = session.run([Y1_op, Y1_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y1_loss)
else:
_, Y2_loss = session.run([Y2_op, Y2_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y2_loss) |
提示:什么时候适合交替训练?
当你为每个不同的任务有不同的数据集的时候,交替训练是一个很好的注意(例如,从英语翻译成法语和从英语翻译成德语)。通过以这种方式设计网络,我们可以提高每项任务的性能,而不需去寻找更多的训练数据。
交替训练是我们最常见的一种情况,因为没有那么多的数据集可以同时满足你两个需求。我们来举一个例子,比如,在机器视觉中,你可能需要执行其中的一项任务是来预测对象是否进行了旋转,而另一个任务可能需要你去改变相机对象。这两个任务显然是相关度。
提示:什么时候不适合交替训练?
交替训练很容易偏向特定的任务,第一种方法是显而易见的。如果你的其中一个任务比别的任务有更大的数据集,那么如果按照数据集的大小比例来进行训练,你的共享层将包含拥有更多数据的任务的信息。
第二种情况并不如此。如果交替进行训练,模型中的最终任务会在参数中产生偏差。你没有任何明显的方法可以克服这个问题,但这确实意味着在你不需要进行交替训练的时候,尽量采用第二种训练方法。
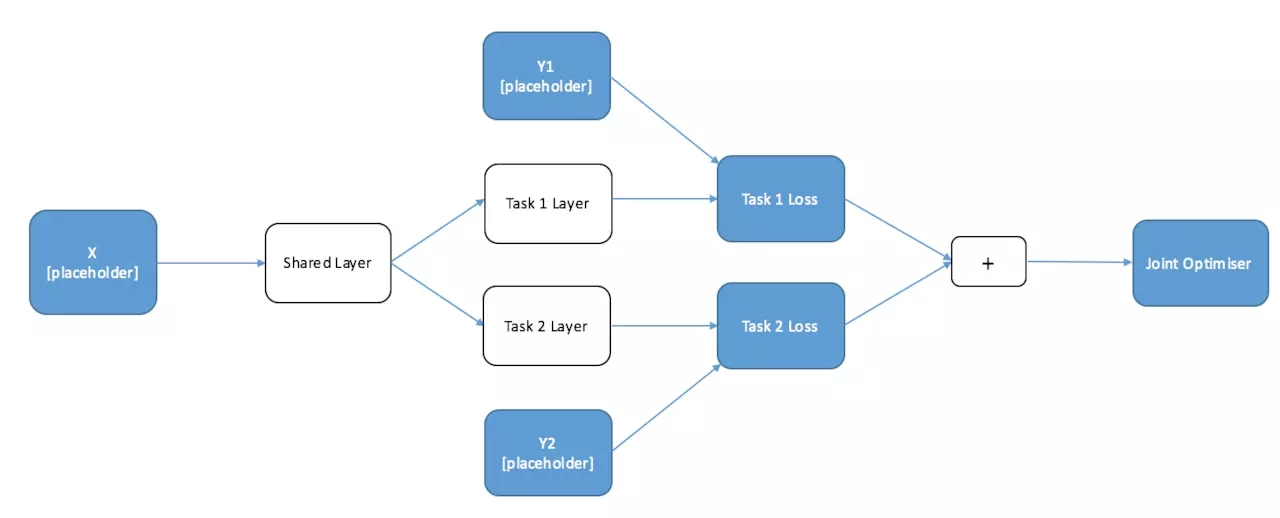
联合训练
当你每个输入都具有多个标签的数据集,那么你真正想要的是联合训练这些任务。问题是,你如何保持各个不同任务之间的独立性?答案非常简单。你只需要将单个任务的损失函数相加并优化就行了。下面是一个图标,显示一个可以联合训练的网络结构,具体代码也如下:
# GRAPH CODE
# ============
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10],
name="X")
Y1 = tf.placeholder("float", [10,
20], name="Y1")
Y2 = tf.placeholder("float", [10,
20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights,
name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights,
name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights,
name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
Joint_Loss = Y1_Loss + Y2_Loss
# optimisers
Optimiser = tf.train.AdamOptimizer().minimize(Joint_Loss)
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
# Joint Training
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
_, Joint_Loss = session.run([Optimiser, Joint_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Joint_Loss) |
总结
在这篇文章中,我们已经了解到了深度学习中多任务学习的基本原理。如果你以前使用过 TensorFlow
并且拥有自己的项目,那么希望这已经足够让你入门开始动手做了。 |









