| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌБОЮФеыЖдГЁОАЯТЕФМЦЫуЬиЕуЖдЩюЖШбЇЯАПђМмНјааЩшМЦКЭгХЛЏЁЃ
|
|
вЛЃЎ злЪі
ЩюЖШбЇЯАБШДЋЭГЕФТпМЛиЙщгазХИќЧПЕФФЃаЭПЬЛФмСІЃЌЭЌЪБвВДјРДСЫМЦЫуСІАйБЖЬсЩ§ЕФашЧѓЁЃЯрБШЭМЯёЁЂгявєЁЂЪгЦЕЕШСьгђЃЌЫбЫїЁЂЙуИцЁЂЭЦМіЕШГЁОАгазХЖРЬиЕФГЁОАЬиЕу:
бљБОЙцФЃКЭЬиеїПеМфЭЈГЃЗЧГЃОоДѓЃЌЧЇвкбљБОЁЂАйвкЬиеїВЂВЛКБМћЃЌЭЌЪБДцдкДѓСПЕФЯЁЪшЬиеїзїЮЊEmbeddingЪфШыЁЃетОЭвЊЧѓЮвУЧеыЖдДЫГЁОАЯТЕФМЦЫуЬиЕуЖдЩюЖШбЇЯАПђМмНјааЩшМЦКЭгХЛЏЁЃ
ЮвУЧЛљгкTensorFlowдкЫбЫїЁЂЙуИцЁЂЭЦМіГЁОАЯТНјааСЫЩюЖШЕФгХЛЏгыдіЧПЃЌФкВПЯюФПУћГЦЮЊTensorFlowRSЃЌжївЊЕФГЩЙћШчЯТЃК
(1) НтОіСЫдЩњTFЫЎЦНРЉеЙФмСІВЛзуЕФЮЪЬтЁЃдкЮвУЧЕФВтЪджаЃЌОјДѓЖрЪ§ЫбЫїЙуИцФЃаЭЕФбЕСЗадФмЬсЩ§дкЪЎБЖвдЩЯЃЌФГаЉФЃаЭЕФМЋЯоадФмзюИпПЩЬсЩ§АйБЖЁЃ
(2) жЇГжЭъБИЕФдкЯпбЇЯАгявхЃЌФЃаЭБфИќЪЕЪБаДГіЃЛЯЁЪшЬиеїЮоашзіСЌајIDЛЏЃЌПЩвджБНгЪЙгУдЪМЬиеїБэеїНјаабЕСЗЃЌДѓЗљМђЛЏСЫЬиеїЙЄГЬЕФИДдгЖШЁЃ
(3) вьВНбЕСЗЕФЬнЖШаое§гХЛЏЦїЃЈgrad-compensation optimizerЃЉЃЌгааЇМѕЩйСЫвьВНДѓЙцФЃВЂЗЂв§Ц№ЕФбЕСЗаЇЙћЫ№ЪЇЁЃ
(4) МЏГЩСЫИпаЇЕФGraph EmbeddingЁЂMemory NetworkЁЂCross MediaЕШЖржжИпМЖбЕСЗФЃЪНЁЃ
(5) ФЃаЭПЩЪгЛЏЯЕЭГDeepInSightЬсЙЉЩюЖШФЃаЭбЕСЗЕФЖрЮЌЖШПЩЪгЛЏЗжЮіЁЃ
ЖўЃЎ TensorFlowRSЗжВМЪНМмЙЙ
дкЪЙгУTensorFlowЕФЙ§ГЬжаЮвУЧЗЂЯжTFзїЮЊвЛИіЗжВМЪНбЕСЗЯЕЭГгаСНИіжївЊЕФЮЪЬтЃК
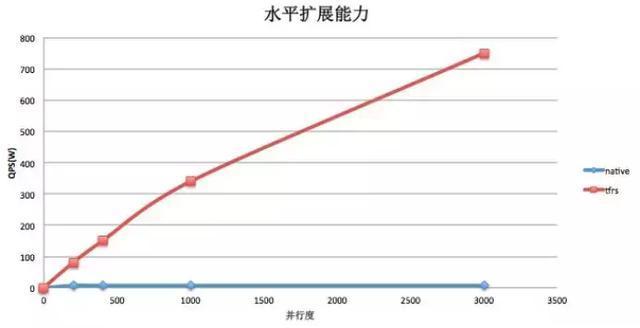
1. ЫЎЦНРЉеЙФмСІВюЃКдкДѓВПЗжФЃаЭЕФадФмВтЪджа,ЮвУЧЗЂЯжЫцзХЪ§ОнВЂааЖШЕФдіМгЃЌЕЅИіworkerЕФбљБОДІРэQPSМБОчЯТНЕЁЃЕБworkerЪ§СПдіДѓЕНвЛЖЈЙцФЃЕФЪБКђЃЌЯЕЭГећЬхQPSВЛдйгадіГЄЩѕжСгаЫљЯТНЕЁЃ
2. ШБЗІЭъБИЕФЗжВМЪНFailoverЛњжЦЃКTFЛљгкОВЬЌЭиЦЫХфжУРДЙЙНЈclusterЃЌВЛжЇГжЖЏЬЌзщЭјЃЌетОЭвтЮЖзХЕБФГИіpsЛђепworkerЙвЕєжиЦєжЎКѓЃЌШчЙћipЛђепЖЫПкЗЂЩњБфЛЏЃЈР§ШчЛњЦїcrashЃЉЃЌбЕСЗНЋЮоЗЈМЬајЁЃСэЭтTFЕФcheckpointжЛАќКЌserverДцДЂЕФВЮЪ§аХЯЂЃЌВЛАќКЌworkerЖЫЕФзДЬЌЃЌВЛЪЧШЋОжвЛжТадЕФcheckpointЃЌЮоЗЈЪЕЯжExactly-OnceЕШЛљБОЕФFailoverгявхЁЃ
еыЖдЩЯЪіЮЪЬтЃЌTensorFlowRSВЩШЁЕФНтОіЗНАИАќРЈЃК
ЭЈЙ§ЖдНгЖРСЂВЮЪ§ЗўЮёЦїЬсЩ§ЫЎЦНРЉеЙФмСІ
дкЖдTFзіЙ§ЯИжТЕФprofilingжЎКѓЃЌЮвУЧЗЂЯжTFдЩњЕФPSгЩгкЩшМЦКЭЪЕЯжЗНУцЕФЖржждвђЃЈgrpcЃЌlockЃЌgraph-engineЃЉЃЌКмФбДяСМКУЕФЫЎЦНРЉеЙФмСІЁЃгкЪЧЮвУЧОіЖЈЖЊЕєTF-PSЕФАќИЄЃЌжиаТЪЕЯжвЛИіИпадФмЕФВЮЪ§ЗўЮёЦїЃКPS-PlusЁЃДЫЭтЮвУЧЬсЙЉСЫЭъећЕФTF
on PS-PlusЗНАИЃЌПЩвджЇГжгУЛЇдкNative-PSКЭPS-PlusжЎМфздгЩЧаЛЛЃЌВЂЧвЭъШЋМцШнTensorFlowЕФGraphгявхКЭЫљгаAPIЁЃгУЛЇПЩвддкЩюЖШЭјТчДњТывЛааВЛИФЕФЧщПіЯТЃЌНЋВЮЪ§ЗжВМКЭдЫаадкPS-PlusЩЯЃЌЯэЪмИпадФмЕФВЮЪ§НЛЛЛКЭСМКУЕФЫЎЦНРЉеЙФмСІЁЃ
жиаТЩшМЦFailoverЛњжЦЃЌжЇГжЖЏЬЌзщЭјКЭExactly-OnceЕФFailover
TensorFlowRSв§ШыСЫworker stateЃЌдкcheckpointжаДцДЂСЫworkerЕФзДЬЌаХЯЂЃЌworkerжиЦєКѓЃЌЛсДгНгзХЩЯДЮЕФНјЖШМЬајбЕСЗЁЃДЫЭтTensorFlowRSЭЈЙ§zkЩњГЩclusterХфжУЃЌжЇГжСЫЖЏЬЌзщЭјЕФFailoverЁЃаТЕФFailoverЛњжЦПЩвдБЃжЄШЮвтНЧЩЋЙвЕєЕФЧщПіЯТЃЌЯЕЭГЖМФмдкЗжжгМЖЭъГЩFailoverЃЌВЂЧвВЛЖрЫуКЭТЉЫуЪ§Он
TensorFlowRSЕФећЬхМмЙЙШчЭМЫљЪОЃК
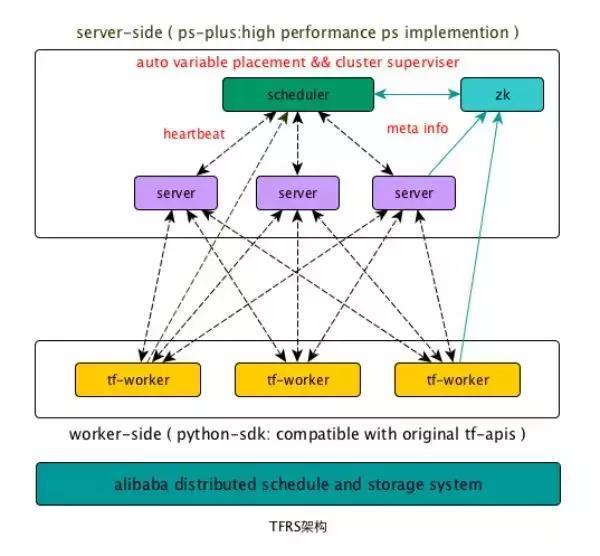
Ш§ЃЎ PS-Plus
PS-PlusЯрЖдгкДЋЭГЕФParameterServerгаШчЯТЬиЕуЃК
(1)ИпадФмЃКPS-PlusЭЈЙ§жЧФмВЮЪ§ЗжХфЃЌСуПНБДЃЌseastarЕШЖрЯюММЪѕЃЌНјвЛВНЬсЩ§СЫЕЅЬЈserverЕФЗўЮёФмСІКЭЯЕЭГећЬхЕФЫЎЦНРЉеЙФмСІЁЃдкЪЕВтжаЃЌдк64coreЕФЛњЦїЩЯЕЅИіserverФмЧсЫЩгУТњ55+ЕФКЫаФЃЌдкdenseГЁОАЯТioФмДђТњЫЋ25GЭјПЈЃЌЯЕЭГећЬхдк
1~4000 worker ЕФЗЖЮЇФкЖМОпгаНќЫЦЯпадЕФЫЎЦНРЉеЙФмСІ
(2)ИпЖШСщЛюЃКPS-PlusгЕгаЭъЩЦЕФUDFНгПкЃЌгУЛЇПЩЪЙгУSDKПЊЗЂЖЈжЦЛЏЕФUDFВхМўЃЌВЂЧвПЩвдЭЈЙ§МђЕЅЕФC++вдМАPythonНгПкНјааЕїгУЁЃ
(3)ЭъБИЕФдкЯпбЇЯАжЇГжЃКPS-PlusжЇГжЗЧIDЛЏЬиеїбЕСЗЃЌЬиеїЖЏЬЌдіЩОЃЌвдМАФЃаЭдіСПЪЕЪБЕМГіЕШжЇГХдкЯпбЇЯАЕФживЊЬиадЁЃ
ЯТУцДгжабЁШЁМИЕузіБШНЯЯъЯИЕФНщЩмЃК
1. жЧФмВЮЪ§ЗжХф
ВЮЪ§ЗжХфВпТд(variable placement)ЃЌОіЖЈСЫШчКЮНЋвЛИіВЮЪ§ЧаЗжВЂЗХжУЕНВЛЭЌЕФserverЩЯЁЃplacementВпТдЕФКУЛЕдкИпВЂЗЂЕФЧщПіЯТЖдPSЕФећЬхадФмгазХжиДѓЕФгАЯьЁЃДЋЭГParameterServerЕФplacementЗНАИЪЧгЩЯЕЭГдЄЯШЪЕЯжМИжжГЃМћЕФplacementЫуЗЈЃЈБШШчЦНОљЧаЗж+roundrobinЃЉЃЌЛђепгЩгУЛЇдкДДНЈВЮЪ§ЕФЪБКђЪжЙЄЛЎЗжЃЌЭљЭљУЛгазлКЯПМТЧШЋОжЕФВЮЪ§ЙцФЃЁЂServerЕФИКдиЕШЁЃ
PS-PlusЪЕЯжСЫЛљгкФЃФтЭЫЛ№ЫуЗЈЕФЦєЗЂЪНВЮЪ§ЗжХфВпТдЃЌКѓајвВдкПМТЧЪЕЯжЛљгкдЫааЪБИКдиЃЌЖЏЬЌrebalanceЕФplacementВпТдЁЃPS-PlusЕФplacementЩшМЦгаШчЯТгХЕуЃК
злКЯПМТЧСЫШЋОжВЮЪ§ЕФshapeаХЯЂЃЌдкcpuЃЌФкДцЃЌЭјТчДјПэЕШЯожЦЬѕМўЯТИјГіСЫНќЫЦзюгХЕФplacementЗНАИЃЌБмУтСЫЪжЙЄЗжХфдьГЩЕФВЛОљдШЁЂШШЕуЕШЮЪЬтЁЃ
ећИіВЮЪ§ЗжХфЙ§ГЬгЩЯЕЭГФкВПздЖЏЭъГЩЃЌгУЛЇЮоашХфжУМДПЩЛёЕУНгНќзюгХЕФадФмЃЌгУЛЇЮоашСЫНтPSЕзВуЪЕЯжЕФОпЬхЯИНкЁЃ
PartitionгЩПђМмздЖЏЭъГЩЃЌдкЩЯВуЫуЗЈДњТыЃЌШчTFДњТыжаЃЌВЛашвЊЖюЭтЪЙгУPartitionedVariableЕШЛњжЦЃЌЪЙгУМђЕЅЗНБуЁЃ
2. ШЅIDЛЏЬиеїжЇГж
ФПЧАжїСїЕФЩюЖШбЇЯАПђМмЖМЪЧвдСЌајЕФФкДцРДДцДЂбЕСЗВЮЪ§ЃЌЭЈЙ§ЦЋвЦСПЃЈIDжЕЃЉРДбАжЗЕНОпЬхЕФШЈжиЁЃЮЊСЫБмУтФкДцЕФРЫЗбЃЌашвЊЖдЬиеїзіДг0ПЊЪМЕФСЌајIDЛЏБрТыЃЌетвЛЙ§ГЬЮвУЧГЦжЎЮЊЬиеїIDЛЏЁЃЬиеїIDЛЏЪЧвЛИіЗЧГЃИДдгЕФЙ§ГЬЃЌгШЦфЪЧЕБбљБОКЭЬиеїЪ§СПЗЧГЃХгДѓЕФЪБКђЃЌЬиеїIDЛЏЛсеМгУДѓСПЕФЪБМфКЭЛњЦїзЪдДЃЌИјбљБОЙЙНЈДјРДСЫКмДѓЕФИДдгЖШЁЃ
PS-PlusФкВПЪЕЯжСЫвЛИіЖЈжЦЛЏЕФhashmapЃЌеыЖдВЮЪ§НЛЛЛГЁОАзіСЫзЈУХЕФгХЛЏЃЌдкжЇГжЬиеїЖЏЬЌдіЩОЕФЭЌЪБЬсЙЉСЫГЌИпЕФадФмЁЃЭЈЙ§hashmapЃЌPS-PlusжБНгЪЕЯжСЫЖдЗЧIDЬиеїЕФжЇГжЃЌМЋДѓЕФМђЛЏСЫбљБОЙЙНЈЕФИДдгЖШЁЃ
3. ЭЈаХВугХЛЏ
ЖдгкParameter ServerМмЙЙЃЌбгГйЪЧгАЯьећЬхадФмЕФживЊдвђЁЃгШЦфЪЧдкФЃаЭИДдгЖШВЛИпЕФЧщПіЯТЃЌФЃаЭМЦЫуВПЗжЭљЭљдк10~100msСПМЖЃЌФЧУДзмЬхЭЈаХЕФбгГйОЭГЩЮЊвЛИіЙиМќвђЫиЁЃ
дкДЋЭГЕФpipelineЯпГЬФЃаЭЃЌИпВЂЗЂЧщПіЯТжаЖЯКЭЯпГЬЩЯЯТЮФЧаЛЛЛсЕМжТКмДѓЕФПЊЯњЃЌЭЌЪБЛсв§Ц№ДѓСПЕФcache-line
missЁЃДЫЭтЃЌИпЦЕЕФЫјОКељЪЧДјРДбгГйЕФзюжївЊдвђжЎвЛЃЌМДБуЪЧИїРрSpinLockЁЂЖСаДЫјЕШгХЛЏвВВЂВЛФмгааЇЯћГ§етИіЮЪЬтЁЃЮвУЧШЯЮЊpolling
+ run to completionЪЧвЛИіе§ШЗЕФбЁдёЃЌВЂЧвЩшМЦСЫЮвУЧЕФећЬхЭЈаХВуМмЙЙЁЃдкаТЕФЭЈаХВужаЃЌЮвУЧЪЙгУСЫSeastarзїЮЊЕзВуЕФПђМмЁЃЖдгкServerЁЂWorkerЩЯЕФconnectionЃЌЖМбЯИёБЃжЄconnectionАѓЖЈЕНЙЬЖЈЕФЯпГЬЃЌЭЌЪБЯпГЬгыCPUКЫаФАѓЖЈЁЃRequestЁЂresponseжБНгВЩгУrun
to completionЕФЗНЪНдкЕБЧАЯпГЬДІРэЁЃећЬхМмЙЙШчЯТЭМЫљЪОЃК
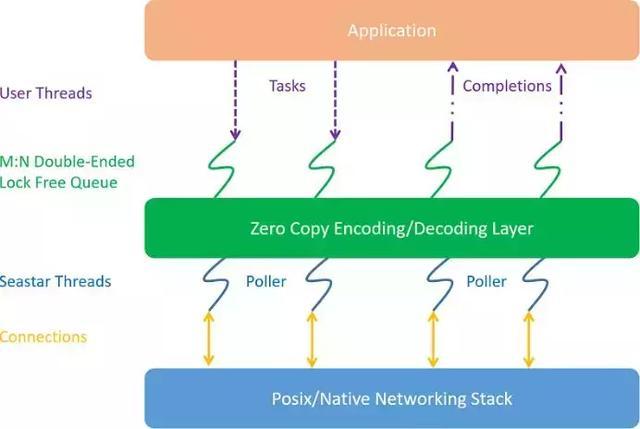
дкSeastarЕФЛљДЁЩЯЃЌЮвУЧзіСЫКмЖрЙІФмЁЂадФмЕФИФНјКЭгХЛЏЃЌетРязівЛаЉМђвЊЕФНщЩмЁЃ
ЭтВПЯпГЬНЛЛЅЖгСаЁЃЮвУЧНшМјSeastarКЫаФжЎМфЕФНЛЛЅЛњжЦЃЌЬсЙЉСЫвЛИі M:N ЮоЫјЩњВњепЯћЗбепЖгСаЃЌгУгкЭтВПЯпГЬгыSeastarФкВПЯпГЬНјааНЛЛЅЁЃЯрБШДЋЭГЖгСаадФмгаМЋДѓЕФЬсЩ§ЁЃ
аДЧыЧѓЫГађЕїЖШЁЃДгЭтВПЯпГЬpollЕНЕФаДЧыЧѓЃЌШчЙћжБНгЕїгУSeastarЕФаДНгПкЃЌЛсЕМжТаДbufferЮоЗЈБЃжЄгаађЁЃЮвУЧЭЈЙ§ЖгСаЛњжЦЕФИФдьЃЌздЖЏБЃжЄСЫаДЫГађЃЌЭЌЪБЛљБОВЛЫ№ЪЇЖрconnectionЕФВЂЗЂаДЕФадФмЁЃ
СщЛюЕФБрНтТыВуЁЃЮвУЧЬсЙЉСЫвЛЬзБрНтТыВуЕФГщЯѓНгПкЃЌЗНБугУЛЇЪЙгУЃЌДгЖјВЛашвЊНшжњprotobufЕШДЋЭГЕФађСаЛЏЁЂЗДађСаЛЏЕФЕкШ§ЗНПтЃЌЭЌЪБвВБмУтСЫprotobufЕФвЛаЉадФмЮЪЬтЁЃ
ЫФЃЎадФмВтЪд
ЮвУЧВтЪдСЫTensorFlowRSдкDenseвдМАWDE(Wide-Deep-Embedding)СНжжОЕфФЃаЭЕФадФмжИБъЃК
1.ФЃаЭЫЕУїЃК
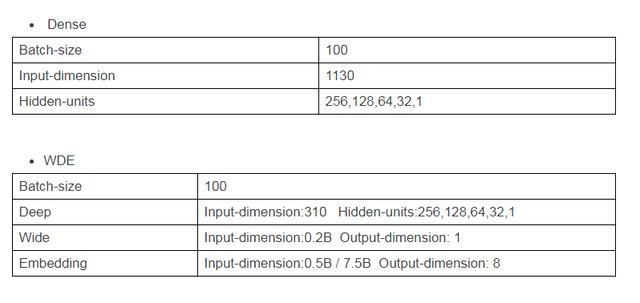
2.ВтЪдНсЙћЃК
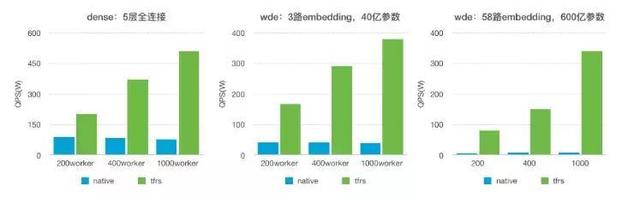
3.WDEФЃаЭЯТNative-TFгыTFRSЫЎЦНРЉеЙФмСІБШНЯ
Юх. дкЯпбЇЯА
вдFtrlЮЊДњБэЃЌдкЯпбЇЯАНќФъРДдкЙЄвЕНчПЊЪМБЛДѓЙцФЃгІгУЃЌЫќЪЧЙЄГЬгыЫуЗЈЕФЩюШыНсКЯЃЌИГгшФЃаЭЪЕЪБВЖзНЯпЩЯСїСПБфЛЏЕФФмСІЃЌдквЛаЉЖдЪБаЇадвЊЧѓКмИпЕФГЁОАЃЌгаЪЎЗжДѓЕФМлжЕЁЃ
ЩюЖШФЃаЭКЭLRФЃаЭвЛбљЃЌЖддкЯпбЇЯАгазХЭЌбљЧПСвЕФашЧѓЃЌШЛЖјФПЧАжїСїЕФЩюЖШбЇЯАПђМмЖМШБЗІЖддкЯпбЇЯАЕФжЇГжЁЃTensorFlowRSЭЈЙ§ЖдНгPS-PlusЃЌИјГіСЫвЛЬзЭъећЕФЖЫЕНЖЫЕФдкЯпбЇЯАНтОіЗНАИЃЌИГгшСЫTFжЇГжЧЇвкЙцФЃЗЧIDЛЏЬиеїдкЯпбЕСЗЕФФмСІЁЃ
TFRSеыЖддкЯпбЇЯАЕФГЁОАзіСЫзЈУХЩшМЦКЭгХЛЏЃЌОпЬхАќРЈЃК
1. ЗЧIDЛЏЬиеїжЇГж
дкдкЯпбЇЯАЕФГЁОАЯТзіЬиеїЪЕЪБIDЛЏЪЧБШНЯИДдгЕФЃЌашвЊвЛИіГЌИпадФмЕФШЋОжЕФIDЩњГЩЦїЃЌетИјбљБОЩњГЩДјРДСЫКмДѓЕФИДдгЖШЁЃTensorFlowRSРћгУPS-PlusжБНгЪЕЯжСЫЖдЗЧIDЬиеїЕФжЇГжЃЌМЋДѓЕФМђЛЏСЫЪЕЪБбљБОЙЙНЈЕФИДдгЖШЁЃ
2. ЬиеїЖЏЬЌдіЩО
дкдкЯпбЕСЗЕФГЁОАЯТЃЌбЕСЗШЮЮёЛсвдserviceЕФаЮЪНГЄЦкдЫааЃЌдкбЕСЗЙ§ГЬжаЃЌВЛЖЯЛсгааТЬиеїМгШыЕНФЃаЭжаЃЌЮЊСЫБЃжЄбЕСЗПЩвдГЄЦкНјааЖјВЛЛсвђЮЊаТЬиеїЕФВЛЖЯМгШыЕМжТOOMЃЌPS-PlusдкжЇГжЬиеїЖЏЬЌЬэМгЕФЭЌЪБЃЌЛЙЬсЙЉСЫФЌШЯЕФЬиеїЩОГ§ВпТдЃЌПЩвдНЋЕЭЦЕЛђепЕЭШЈжиЕФЬиеїЩОГ§ЕєЃЌгУЛЇЛЙПЩвдЭЈЙ§UDFЖЈжЦЗћКЯздЩэвЕЮёашЧѓЕФЩОГ§ВпТд
3. ФЃаЭдіСПЪЕЪБЕМГі
дкЯпбЇЯАФЃаЭИќаТЕФГЃМћЗНЪНгаШЋСПКЭдіСПСНжжЁЃдкФЃаЭВЮЪ§НЯЖрЕФЧщПіЯТЃЌШЋСПИќаТЕФЗНЪНЛсЖддкЯпЯЕЭГЕФДјПэДјРДОоДѓЕФбЙСІЃЌЖјНЕЕЭИќаТЦЕТЪгжЛсЪЙФЃаЭЕФЪЕаЇадНЕЕЭЁЃPS-PlusжЇГжвдШЮвтЦЕТЪНЋФЃаЭдіСПВПЗжЪЕЪБаДГіЕНЯћЯЂЖгСаЃЌдкДѓЗљМѕЩйЭјТчIOЕФЭЌЪБЪЕЯжСЫеце§втвхЩЯЕФФЃаЭЪЕЪБИќаТЁЃ
4. AUC Decay
дкдкЯпбЇЯАЕФГЁОАЯТЃЌЮвУЧЯЃЭћдкбЕСЗЕФЙ§ГЬжаОЭПЩвдОЁПьЕФЗЂЯжФЃаЭБОЩэЕФвьГЃЃЌЖјВЛЪЧЕШФЃаЭИќаТЕНЯпЩЯжЎКѓЁЃвђДЫЮвУЧашвЊгавЛаЉЗНЗЈРДЦРЙРФЃаЭдкбЕСЗЙ§ГЬжаЕФ
AUCЕШжИБъЁЃTFРяФЌШЯЕФstreaming aucЕФЪЕЯждкРњЪЗЪ§ОнРлЛ§СЫвЛЖЈСПЕФЪБКђЃЌЮоЗЈМАЪБЗДгІЕБЧАФЃаЭЕФзДЬЌЃЌЗДРЁгаКмДѓЕФжЭКѓадЁЃвђДЫЮвУЧв§ШыСЫаТЕФAUCМЦЫуЛњжЦЃКAUC
DecayЁЃAUC DecayБОжЪЩЯЪЧвЛжжЬиЪтЕФMoving AverageЃЌЭЈЙ§ЛљгкЪБМфЕФМѕвцЗНЪНЃЌШѕЛЏРњЪЗбљБОКЭФЃаЭдкЕБЧАAUCМЦЫужаЕФБШжиЃЌвдДяЕНИќПьЗДгІФЃаЭБфЛЏЕФФПЕФ
Сљ. ДѓЙцФЃбЕСЗГЁОАЯТЕФЪеСВаЇЙћгХЛЏ
1. ЮЪЬтВћЪі
ДѓЪ§ОнФЃаЭв§ШыСЫЗжВМЪНВЂаабЕСЗЃЌЭЌВНВЂаабЕСЗЪмГЄЮВworkerЕФжЦдМЃЌВЂЗЂЪ§ШнвзЪмЯоЁЃвьВНВЂааЪЧПьЫйбЕСЗЕФжїСїЁЃвьВНВЂаабЕСЗДђЦЦСЫЦеЭЈSGDбЕСЗЕФДЎааадЃЌМЦЫуЕФЬнЖШгыИќаТЕФФЃаЭВЛЪЧбЯИёвЛжТЃЌв§ШыСЫЬнЖШdelayЕФЮЪЬтЁЃ

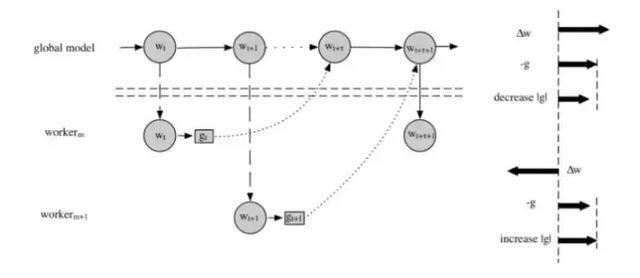
2. ЬнЖШВЙГЅ

в§ШыЯрЙивђзгЪЧвРОнШчЯТЗжЮіЧАЬсЕФЃК
(1)вьВНбЕСЗЪБЃЌДцдквўЪНЕФЬнЖШЖЏСПМгЫйЧщПіВЮМћЁЖAsynchrony begets Momentum,
with an Application to Deep LearningЁЗ,ВЂЗЂдНДѓЃЌвўЪНЖЏСПдНДѓЃЌдьГЩЬнЖШЭљвЛИіЗНЯђЙ§ЖШЧАНјЕФЧщПіЁЃ
(2)ШчЙћВЛЪЧКмРЯЕФw,ЯрЙивђзгЪЧзЊелаХКХЃЌАЕЪОФЃаЭдкЖрИіworkerЕФЖЏСПРлЛ§ЭЦЖЏЯТЧАНјЕФгааЉЙ§ЖШСЫЁЃ
(3)ДцдкзХtradeoff,ЬЋРЯЕФwЃЌаХКХзМШЗТЪЛсЯТНЕЃЌетЪБвЊПижЦ(ЕїаЁ)ЯЕЪ§lambdaЁЃ
вђЮЊ
гыgЕФЯрЙиадОпБИЦеЪЪадЃЌЫљвдПЩвдКЭжїСїЕФsgd-based optimizerНсКЯЃЌЪЪгІВЛЭЌГЁОАЕФВЛЭЌгХЛЏЦїВЂЗЂбЕСЗашЧѓЁЃ
Цп. ЪЕбщНсЙћ
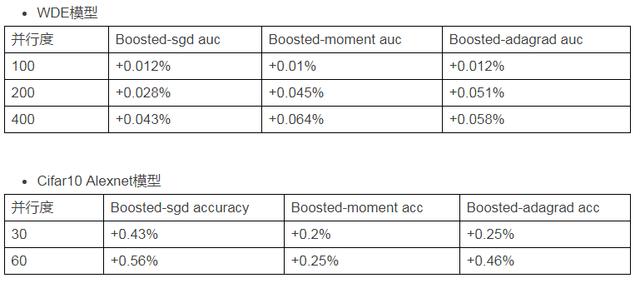
ЮвУЧгУЯрЙиадвђзгboostСЫSGDЁЂMomentumЁЂAdaGradШ§жжЫуЗЈЃЌВЂдкЩњВњЛЗОГКЭЙЋПЊЪ§ОнМЏЩЯзіСЫЪЕбщЃЌЪЕбщНсЙћШчЯТ
АЫЃЎИпМЖбЕСЗФЃЪН
TFRSжаМЏГЩСЫЖржжИпНзбЕСЗФЃЪНЃЌР§ШчGraph EmbeddingЃЌMemory NetworkЃЌCross
Media TrainingЕШЁЃдкБОЮФЮвУЧЛсМђвЊЕФНщЩмвЛЯТЃЌдквдКѓЕФЮФеТжазіЯъЯИЕФВћЪіЁЃ
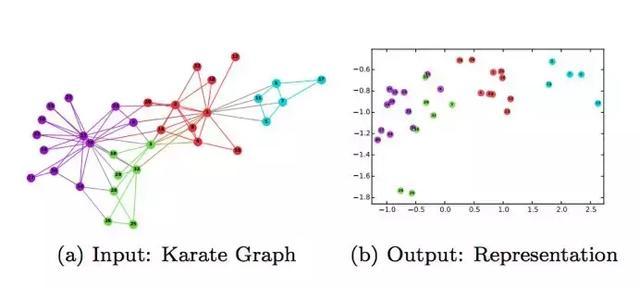
Graph EmbeddingЭМЪЧвЛжжБэеїФмСІМЋЧПЕФЪ§ОнНсЙЙЃЌЕЋЪЧЮоЗЈжБНгзїЮЊЩёОЭјТчЕФЪфШыЁЃTFRSжЇГжбљБОвдЭМЕФаЮЪННјааЪфШыЃЌВЂжЇГжЖржжЫцЛњгЮзпЫуЗЈЖЏЬЌЩњГЩе§ИКбљБОЁЃФПЧАGraph
EmbeddingвбОгІгУдкСЫЫбЫїжБЭЈГЕЕФЯђСПЛЏейЛиЕШЖрИіЯюФПРяЃЌЭЈЙ§дкUser-Query-ItemШ§жжНкЕуЕФвьЙЙгаЯђЭМжаЫцЛњгЮзпЃЌЩњГЩЩюЖШЩёОЭјТчФмЙЛДІРэЕФЯЁЪшЬиеїЁЃзюжебЇЯАГіUserЃЌQueryКЭItemШ§епЕФИпЮЌЯђСПЛЏЕФБэЪОЃЌгУгкЯпЩЯЙуИцЕФЯђСПЛЏейЛиЁЃжЕЕУвЛЬсЕФЪЧЃЌГ§СЫGraph
EmbeddingЃЌЮвУЧЭЌбљжЇГжЖдЭМЕФНсЙЙНјаабЇЯАЃЌР§ШчдкбЕСЗЙ§ГЬжаЗДРЁЕїећЭМжаЕФБпЕФШЈжиЕШЁЃ
Memory NetworkМЧвфЭјТчзюдчгЩFacebookдк2015ФъЬсГіЃЌгУгкQAЯЕЭГжаЁЃдкБОФЃаЭГіЯжжЎЧАЃЌЛњЦїбЇЯАЕФФЃаЭЖМШБЗІПЩвдЖСШЁКЭаДШыЭтВПжЊЪЖЕФзщМўЁЃЖдКмЖрШЮЮёРДЫЕЃЌетЪЧвЛИіКмЧПЕФЯожЦЁЃБШШчЃЌИјЖЈвЛЯЕСаЪТЪЕЛђЙЪЪТЃЌШЛКѓвЊЧѓЛиД№ЙигкИУжїЬтЕФЮЪЬтЃЌЫфШЛддђЩЯетПЩвдгУRNNЕШФЃаЭНјааДІРэЃЌШЛЖјЫќУЧЕФМЧвфЃЈвўВизДЬЌКЭШЈжиБрТыЃЉЭЈГЃЬЋаЁЃЌВЂЧвВЛФмОЋШЗЕиМЧзЁЙ§ШЅЕФЪТЪЕЁЃдкАЂРяТшТшЫбЫїЙуИцГЁОАЯТЃЌЮвУЧЪЙгУМЧвфЭјТчЖдгУЛЇааЮЊНјааНЈФЃЁЃ
ЯрБШвЛАуЕФдкбљБОзщжЏНзЖЮНјааМЧвфЬхЩњГЩЕФЗНЪНЃЌTFRSЭЈЙ§дкбЕСЗЙ§ГЬжав§ШыЖЏЬЌМЧвфДцДЂФЃПщЃЌжЇГжГЄЖЬЦкМЧвфЃЌДѓЗљЬсИпСЫађСаЛЏРрааЮЊЪ§ОнЕФбЕСЗаЇТЪЁЃ
ОХ. ПЩЪгЛЏФЃаЭЗжЮіЯЕЭГDeepInsight
DeepInsightЪЧвЛИіЩюЖШбЇЯАПЩЪгЛЏжЪСПЦРЙРЯЕЭГЃЌжЇГжбЕСЗНзЖЮФЃаЭФкВПЪ§ОнЕФШЋУцЭИГігыПЩЪгЛЏЗжЮіЃЌгУвдНтОіФЃаЭЦРЙРЁЂЗжЮіЁЂЕїЪдЕШвЛЯЕСаЮЪЬтЃЌЬсИпЩюЖШФЃаЭЕФПЩНтЪЭадЁЃ
ЯТУцЮвУЧЭЈЙ§вЛИіЙ§ФтКЯЕФР§згРДЫЕУїDeepInsightдкФЃаЭжЪСПЗжЮіКЭЮЪЬтЖЈЮЛЗНУцЗЂЛгЕФзїгУЃК
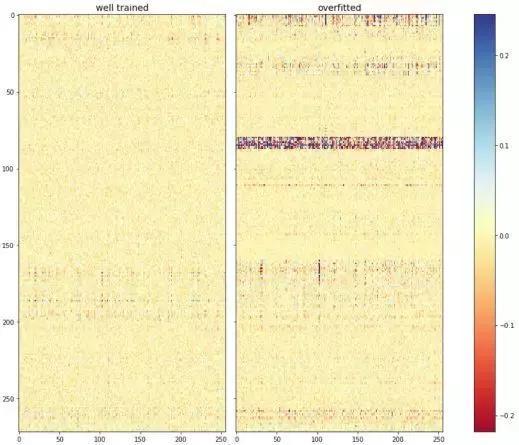
ЩЯЭМЪЧЭЈЙ§DeepInsightЩњГЩЕФЬиеїШЈжиЗжВМ,ДгЭМжаЮвУЧПЩвдПДЕНгвВрЙ§ФтКЯФЃаЭЕФБпШЈжиДѓаЁЗжВМКмВЛОљдШЃЌГіЯжСЫДѓСПШЈжиМЋДѓЕФБпЃЌЧвМЏжадквЛЬѕДјзДЧјгђФкЃЌЦфЮЊФГвЛзщЬиеїЪфШыЫљСЌНгЕФЫљгаБпЃЌетБэУїФЃаЭЙ§ЖШФтКЯСЫИУзщЬиеїЕФаХЯЂЁЃдкЪЙгУе§дђЯюКЭdropoutжЎКѓЃЌЙ§ФтКЯЕФЮЪЬтШдШЛУЛНтОіЃЌвђДЫЮвУЧзюжеЖЈЮЛЕНЮЪЬтГіЯждкИУзщЬиеїЕФЪфШыЩЯЁЃЗЕЛиЫбКќЃЌВщПДИќЖр |









