| 编辑推荐: |
本文于网络,文章讲解了使用TensorFlow如何来构建神经网络及
图像识别与卷积神经网络的详细描述。
|
|
tensor:张量,是tensorflow的数据模型。在tensorflow中可以简单理解为多位数组,表示计算节点,是tensorflow管理数据的形式。但是在tensorflow中,张量的实现并不是直接采用数组的形式,它仅仅是对运算结果的引用。
张量的三个主要属性:name、shape(维度)、type(类型)。
(Note:常量可以看成是一种永远输出固定值的计算,所以可以用计算表示数据)
flow:以流的方式
TensorFlow保持节点不变,仅仅改变节点的数据,或者说数据在节点之间流动。
tensorflow支持n台机器m个cpu,k个gpu(n,m,k为任意整数)。
计算图:计算图是tensorflow的基础,在计算图中,节点表示计算,而边表示相互之间的依赖关系。
计算图的使用:
使用分为两个阶段:构建计算图和执行计算
(1)构建计算图
定义数据和计算节点以及它们之间的依赖。通过tf.get_default_graph来维护默认的计算图,通过g
= tf.Graph来生成计算图,通过g.device()来查看gpu。
(2)执行计算
tensorflow运行模型:会话
会话拥有和管理TensorFlow程序运行时的所有资源。
使用会话来管理资源时,要注意释放资源。
TensorFlow可以自动生成默认的计算图,但不能自动生成默认的会话,需要手动指定默认的会话。
ConfigProto Protocol Buffer工具:可以配置需要生成的会话,类似并行的线程数、gpu分配策略和运算超时时间等参数。
使用TensorFlow来构建神经网络
前向传播算法:
最简单的前向传播算法是全连接网络结构的前向传播算法。
全连接:相邻两层之间任意两个节点之间都有连接。
W表示神经网络的参数。
在TensorFlow中,声明函数tf.Variable给权重赋初始值。使用tf.initialize_all_variables函数,不需要将变量一个一个初始化,而且会自动处理变量之间的依赖关系。
集合(collection):管理不同类别的资源。表3-1表示了TensorFlow维护的所有集合的列表。
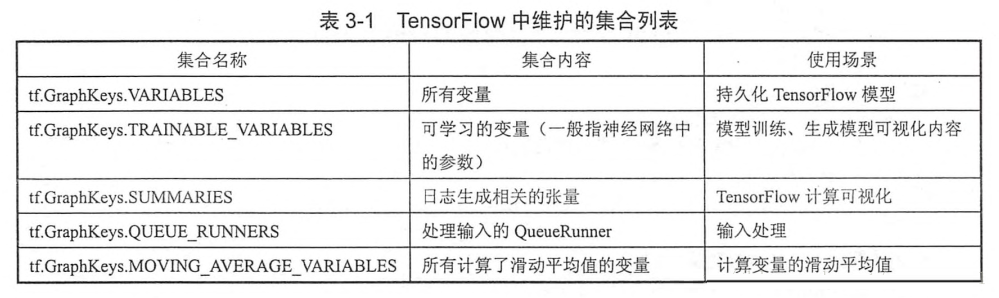
变量的两个重要属性:维度和类型。
类型一旦被确定,不能改变,不同类型的赋值将会报错。
虽然TensorFlow支持更改变量的维度,但是这种应用在实践中比较罕见。
神经网络优化算法中,最常用的是反向传播算法(backpropagation)
TensorFlow提供了placeholder机制来避免因为常量过多而导致的计算图过大的问题。placeholder机制用于提供输入数据,相当于定义了一个位置,这个位置中的数据在程序运行时再指定。palceholder的类型需要指定,同时也不可以改变。维度信息可以根据提供的数据推导得出,所以不一定给出。在运行时,需要提供一个feed_dict(一种字典类型的)类型的数据赋值。
TensorFlow支持7种不同的优化器,可以对TRAINABLE_VARIABLES集合中的变量进行优化。
深度学习两个重要特性:多层、非线性
多层:加入隐藏层,可以认为从输入特征中提取了更高维的特征,实际上具有组合特征提取的功能。
TensorFlow支持7种不同的非线性激活函数,同时用户也可以使用自己定义的激活函数,来保证深度学习的非线性。
经典损失函数:通常使用交叉熵来描述两个概率之间的距离,通过刻画概率分布q来表达概率分布p的困难程度,当交叉熵作为神经网络的损失函数时,则p代表的是正确答案,q代表的是预测值。为了将神经网络的输出变成概率分布,softmax回归是最常用的方法。对于回归问题,最常用的损失函数是均方误差。回归问题一般只有一个输出节点。
在TensorFlow中还可以自定义损失函数。
神经网络优化算法:反向传播算法和梯度下降算法
反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,是训练神经网络的核心算法。梯度下降算法的计算时间太长,通常采用随机梯度下降和梯度下降方法的折中:batch梯度下降。
注:梯度下降算法不一定能保证达到局部最优值。
学习率的设置
Tensorflow使用集合来解决因参数过多而带来的损失函数过长容易出错的问题。
滑动平均模型:在tensorflow中,使用tf.train.ExponentialMovingAverage来实现。初始化时,需要提供衰减率(decay)来控制更新的速度。
数据集:
train:训练模型。
validation:从train数据集中分离出来,在训练过程中作为测试数据,因为选用测试集来选取参数可能会导致神经网络模型过度拟合测试数据。
test:判断一个神经网络的模型的效果最终是通过测试数据来评判的。
tensorflow中主要通过tf.get_variable和tf.variable_scope来通过变量名称获取变量。tf.get_variable变量名称是一个必填的参数,tf.Variable变量名称是一个可选的参数。
通过命名空间可以解决变量名冲突的问题,比如第一层和第二层神经网络中都定义了weights这个变量,则会冲突,如果先定义两个命名空间:layer1和layer2,则在各自的命名空间中定义变量解决命名冲突问题。
模型持久化
目的:让训练结果可以复用(将训练结果保存下来以便以后直接使用)
方式:tf.train.Saver() API
应用:saver.save(path)函数会保存生成三个文件,这是因为tensorflow会将计算图上的结构和参数取值分开保存。
(1)*.ckpt.meta保存计算图的结构
数据格式:元图(MetaGraph)
通过元图来记录计算图中节点的信息以及运行计算图中节点所需要的元数据。MetaGraph是由MetaGraphDef
Protocol Buffer定义的,构成了TensorFlow持久化时的第一个文件。MetaGraphDef类型的定义如下所示:


这里写图片描述
save保存的是二进制文件,可以通过export_meta_graph函数以json格式导出meta文件来查看。
(2)*.ckpt保存程序中每一个变量的取值
文件列表的第一行描述了文件的元信息,比如在这个文件中存储的变量列表。列表剩下的每一行保存了一个变量的片段。TensorFlow提供tf.train.NewCheckpointReader类来查看ckpt文件中保存的变量信息。
(3)checkpoint保存了一个目录下所有的模型文件列表。
该文件的名字是固定的,是tf.train.Saver类自动生成且自动维护的。该文件维护了由tf.train.Saver类持久话的所有TensorFlow生成的模型文件的文件名。
程序默认保存和加载了TensorFlow计算图上定义的全部变量,但有时可能需要保存或加载部分变量。在声明tf.train.Saver类使可以提供一个列表来指定需要保存或加载的变量,同时该类也可以在保存或加载变量时支持对变量的重命名。
TensorFlow也提供了convert_variables_to_constants函数,通过该函数可以将计算图中的变量及其取值通过常量的方式保存,整个计算图可以统一存放在一个文件中。
图像识别问题经典数据集:
MNIST、Cifar、ImageNet
图像识别与卷积神经网络
全连接神经网络无法很好地处理图像数据的原因:
1.全连接神经网络处理图像的最大问题在于全连接层的参数太多,导致计算速度低,还容易导致过拟合的问题。
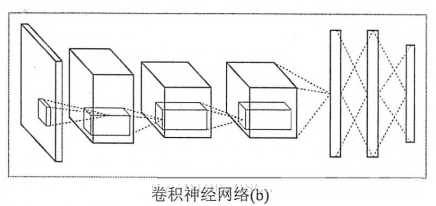
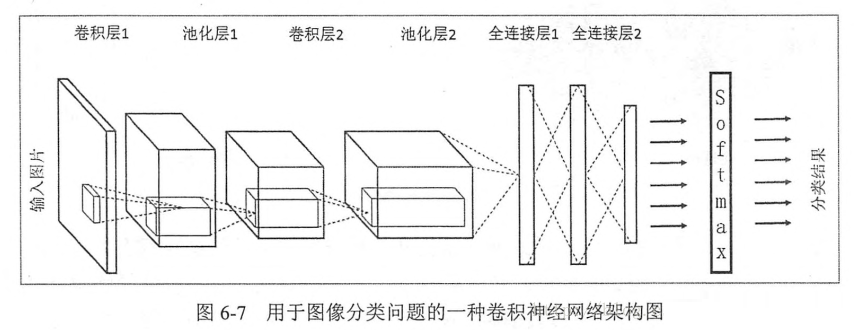
卷积神经网络相邻两层之间只有部分节点相连。卷积神经网络和全连接神经网络的唯一区别就是神经网络中相邻两层的连接方式。
卷积神经网络主要由5中结构组成:
1.输入层
整个神经网络的输入,在图像处理中,输入一般代表一张图片的像素矩阵。在图6-7中,最左侧的三维矩阵就代表一张图片。三维矩阵的长和宽代表图像的大小,深度代表了图像的色彩通道。从输入层开始,卷积神经网络通过不同的神经网络结构将上一层的三维矩阵转化为下一层的三维矩阵,知道最后的全连接层。
2.卷积层
卷积层是卷积神经网络中最重要的部分。卷积层中每一个节点的输入只是上一层神经网络的一小块,这个小块常用的大小有3??3或5??5,一般来说经过卷积层处理过的节点矩阵会变得更深。
3.池化层
池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。池化层可以进一步缩小最好全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
4.全连接层
经过多轮卷积层和池化层的处理之后,卷积神经网络的最后一般会是由1-2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层处理只好,可以认为图像中的信息已经被抽象成了信息含量更高的特征。
5.Softmax层(pooling层)
Softmax层主要用于分类问题。
卷积层详细介绍:
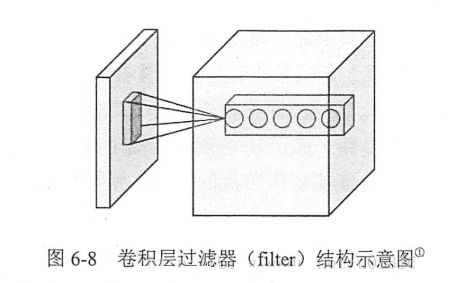
过滤器(filter)或者内核(kernel):卷积层神经网络结构中最重要的部分。过滤器可以将当前层神经网路上的一个子节点转化为下一层神经网络上的一个单位节点矩阵。
单位节点矩阵:长和宽都为1,但深度不限的节点矩阵。
过滤器的尺寸:指的是一个过滤器输入节点矩阵的大小,而深度指的是输出单位节点矩阵的深度。
过滤器的前向传播过程:通过左侧小矩阵中的节点计算出右侧单位矩阵中节点的过程。下面将给出一个过滤器的前向传播过程的具体样例。在这个样例中将展示如歌通过过滤器将一个2×2×32×2×3的节点矩阵变化为一个1×1×51×1×5的单位节点矩阵。这个过滤器的前向传播过程和全连接层相似,总共需要2×2×3×5+5=652×2×3×5+5=65个参数,其中最后的+5为偏置项参数的个数。假设使用wix,y,zwx,y,zi来表示对于输出单位节点矩阵中的第i个节点,过滤器输入节点(x,y,x)(x,y,x)的权重,使用bibi表示第ii个输出节点对应的偏置项参数,那么单位矩阵中的第ii个节点的取值g(i)g(i)为:
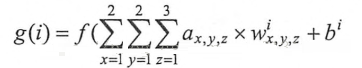
其中ax,y,zax,y,z为过滤器中节点x,y,zx,y,z的取值,ff为激活函数。
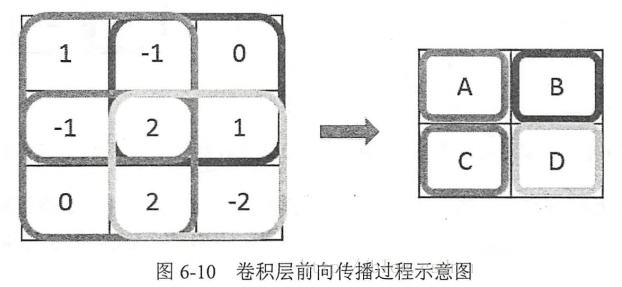
卷积层结构的前向传播过程就是通过将一个过滤器从神经网络当前层的左上角移动到右下角,并且在移动过程中计算每一个对应的单位矩阵得到的。
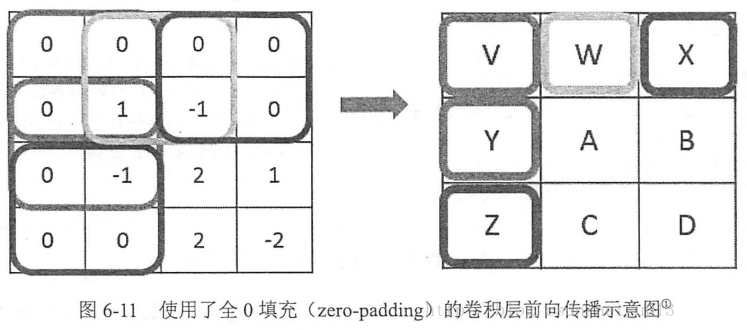
当过滤器的大小不为1×11×1时,卷积层前向传播得到的矩阵尺寸要小于当前层矩阵的尺寸。为了避免尺寸的变化,可以额在当前层矩阵的边界上加入全0填充。这样可以保持卷积层前向传播结果矩阵的大小和当前层矩阵一致。
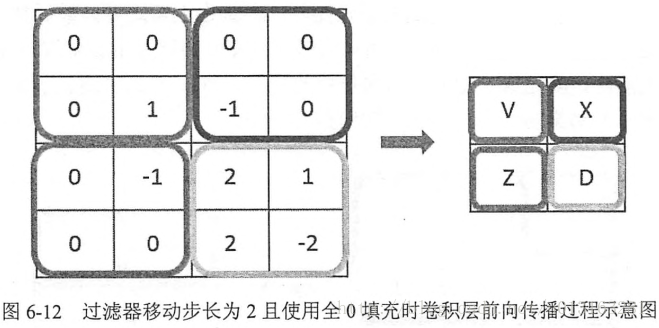
除了使用全0填充,还可以通过设置过滤器移动的步长来调整结果矩阵的大小。
卷积神经网络一个非常重要的性质:每一个卷积层中使用的过滤器中的参数都是一样的,这样做由以下优点:
1.共享过滤器的参数可以使图像上的内容不受位置的影响。
2.可以巨幅减少神经网络上的参数。
3.卷积层的参数个数和图片的大小无关,纸盒过滤器的尺寸、深度和当前层节点矩阵的深度有关,可以很好地扩展到更大的图像数据上。
池化层
池化层前向传播的过程也是通过移动一个类似过滤去的结构完成的。不过池化层采用更加简单的最大值或平均值运算。
最大池化层:使用最大值操作的池化层。
平均池化层:使用平均值操作的池化层。
优势:
1.可以非常有效地缩小矩阵的尺寸,从而减少最好全连接层中的参数。
2.加快计算速度
3.防止过拟合问题
池化层过滤器与卷积层过滤器类似,也需要人工设定过滤器的尺寸、是否使用全0填充以及过滤器移动的步长等设置,而且这些设置的意义一样。
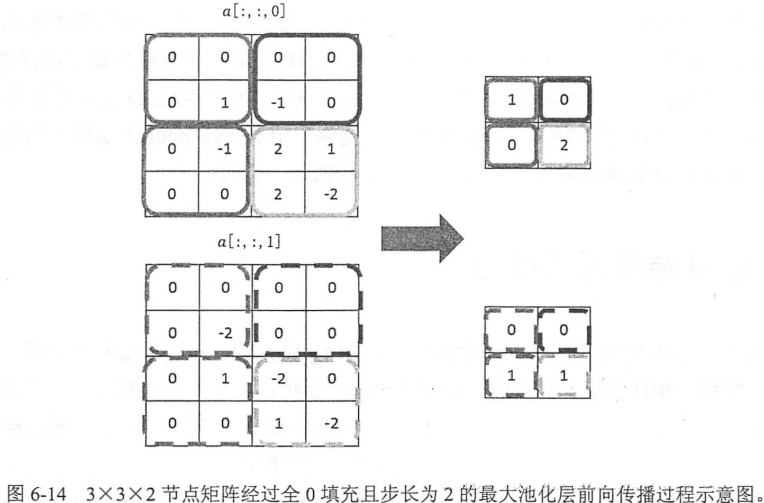
池化层过滤器和卷积层过滤器移动方式的唯一的区别在于卷积层使用的过滤器是横跨整个深度的,而池化层使用的过滤器只影响一个深度上的节点。所以池化层的过滤器除了在长和宽这两个维度移动之外,它还需要在深度这个维度移动。
经典的卷积神经网络模型
LeNet-5和Inception-3
上面的正则表达式总结了一些经典的用于图片分类问题的卷积神经网络架构。其中++表示一层或多层,??表示没有或一层。卷积神经网络输出之前一般会经过1-2个全连接层。
一般过滤器的边长不会超过5,但有些卷积神经网络结构中,处理输入的卷积层中使用了边长为7甚至是11的过滤器。
在过滤器的深度上,大部分卷积神经网络都采用逐层递增的方式。卷积层的步长一般为1,但有些模型也会使用2,或者3作为步长。
池化层配置相对简单,用的最多的是最大化池化层,池化层的过滤器边长一般为2或者3,步长一般也为2或者3.
Tensorflow-slim工具可以更加简洁地实现一个复杂卷积神经网络,比如Inception-v3模型。
迁移学习:将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。比如可以保留训练好的Inception-v3模型中所有卷积层的参数,只是替换最后一层全连接层,可以解决一个新的图像分类问题。在最后这一层全连接层之前的网络层称之为瓶颈层。
将新的图像通过训练好的卷积神经网络直到瓶颈层的过程可以看成是对图像进行特征提取的过程。
迁移学习相比重新训练的优缺点:
缺点:效果不如完全重新训练。
优点:需要的训练时间和训练样本数要远远小于训练完整的模型。
循环神经网络
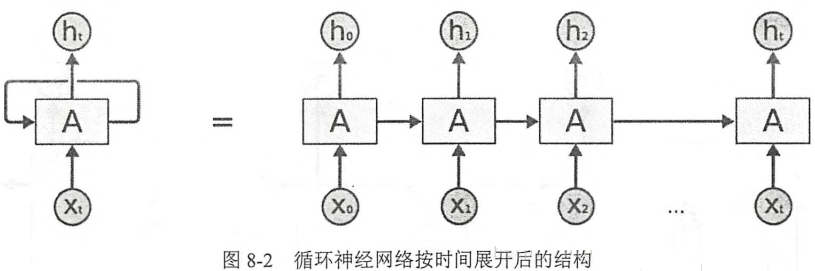
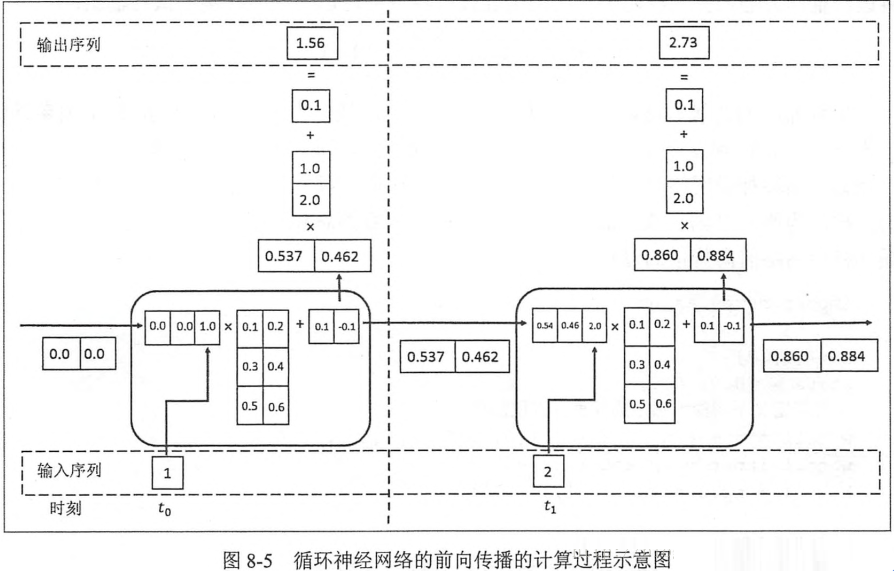
循环神经网络的主要用途是处理和预测序列数据。循环神经网络的隐藏层之间的结点是由连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
长短时记忆网络(LTSM)结构
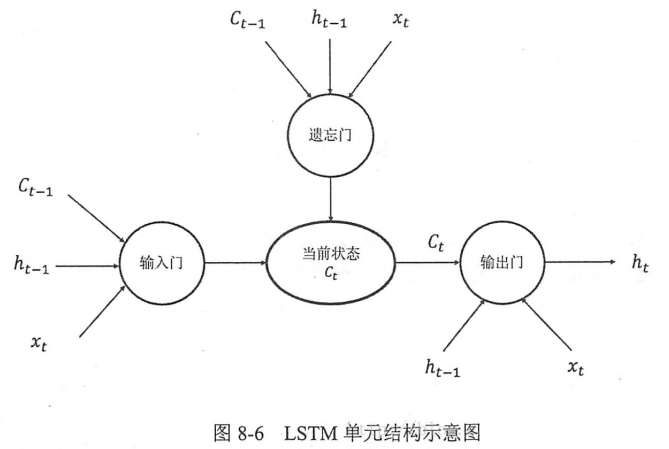
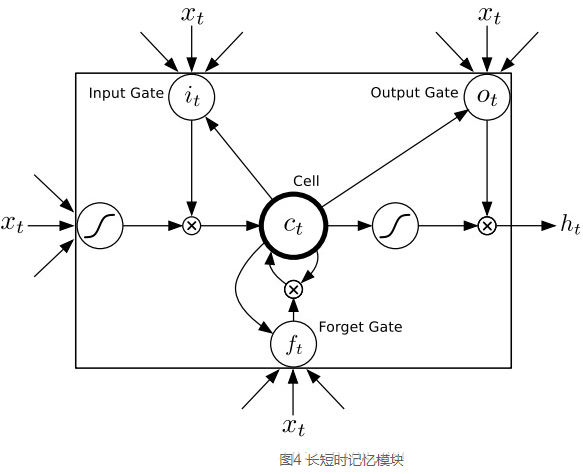
目的:为了解决上下文场景复杂,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制的问题。
“门”结构:使用sigmoid神经网络和一个按位做乘法的操作。
功能:‘门’结构让信息有选择性地影响循环神经网络中每个时刻的状态。描述当前输入有多少信息量可以通过这个结构。当门打开时(sigmoid输出为1时),全部信息都可以通过,当门关闭时(sigmoid输出为0时),任何信息都无法通过。
“遗忘门”
功能:让循环神经网络“忘记”之前没有用的信息
过程:“遗忘门”会根据当前的输入xtxt、上一时刻状态ct?1ct?1和上一时刻输出ht?1ht?1共同决定哪一部分记忆需要被遗忘。
“输入门”
功能:在循环神经网络“忘记”了部分之前的状态后,它还需要从当前的输入补充最新的记忆。
过程:根据xtxt、ct?1ct?1和ht?1ht?1决定哪些部分将进入当前时刻的状态ctct。
输出门:
功能:在计算得到新的状态ctct后需要产生当前时刻的输出。
过程:根据最新的状态ctct、上一时刻的输出ht?1ht?1和当前的输入xtxt来决定该时刻的输出htht。
具体的结构可以查看博客:
LSTM结构图
LSTM前向传播和误差反传更新公式
循环神经网络的变种:
双向循环神经网络
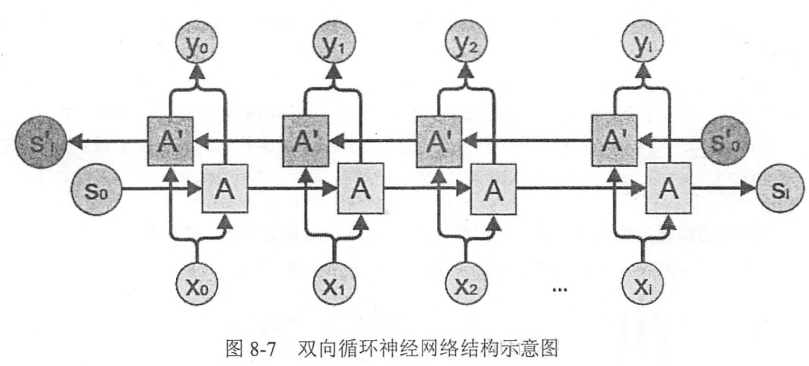
解决问题:有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。比如预测一个语句中缺失的单词不仅需要前文来判断,也需要根据后面的内容。
主体结构:由两个单向循环神经网络的结合。在每一个时刻t,输入会同时提供给这两个方向相反的循环神经网络。
深层循环神经网络
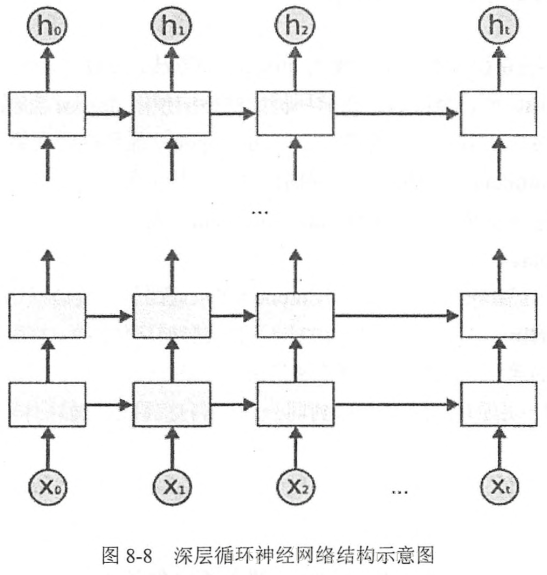
为了增强模型的表达能力,可以将每一个时刻上的循环体重复多次。
|









