| 编辑推荐: |
本文于阿里云,神经机器翻译(NMT)是自动翻译的端到端方法,这个方法具有克服传统短语翻译系统缺点的潜力。
|
|
背景:
神经机器翻译(NMT)是自动翻译的端到端方法,这个方法具有克服传统短语翻译系统缺点的潜力。最近,阿里巴巴集团正在为全球电子商务部署NMT服务。
目前,我们正在利用Transformer [1]作为我们NMT系统的主要骨干,因为它对于经典的基于RNN/LSTM模型的高效离线训练具有较高的准确度,因此它成为了系统的核心。尽管Transformer对于离线训练阶段很友好,因为它在时间跨度上打破了依赖性,但对于在线推理来说效率并不高。在我们的生产环境中,已经发现Transformer的初始版本的推理速度在1.5X到2X左右,这比LSTM的版本慢。我们已经进行了几次优化以提高推理性能,例如图层级操作融合,循环不变节点运动[3]。我们观察到一个特殊挑战是批量matmul是提升Transformer的性能的关键点,但目前在cuBLAS中的实现并没有得到很好的优化。
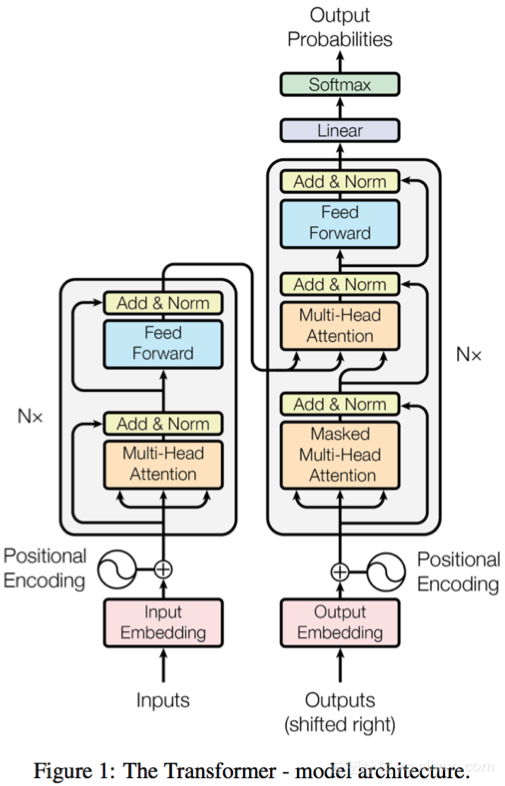
下面表明TVM生成内核(与优化安排表),结果带来了至少13X加速批量MATMUL计算,并启用了futher,这也加快了与运营商的融合。
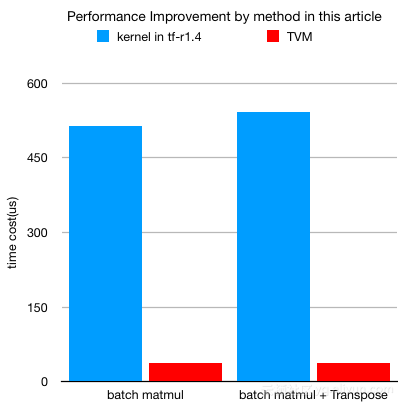
批量Matmul
为什么批量matmul?
在Transformer中,批量matmul被广泛用于计算多头注意力(multi-head attention)。使用批量matmul,注意力层中的多个头可以并行运行,这有助于提高硬件的计算效率。
我们在推理阶段对Transformer模型进行了彻底分析,结果表明批量matmul计算占GPU内核执行时间的30%左右。使用nvprof[2]对cuBLAS的批处理内核进行第一性原理分析,可以清楚地看出当前的执行效果并不理想,并且观察到了一些有趣的现象。
什么是批量matmul?
通常,批量matmul计算在一批矩阵上执行矩阵-矩阵乘法,即所有实例具有相同的尺寸(M,N,K),主要维度(lda,ldb,ldc)以及它们各自的A,B和C矩阵的维度。
批量matmul计算可以更具体地描述如下:

批量matmul的形状(shape)
在语言翻译任务中,批量matmul的形状明显小于其他工作中的正常matmul计算。Transformer中的形状与输入句子的长度和解码器步骤的长度有关。通常情况下,它都是小于30。
至于batch dimension,其大小是一个固定的数字。例如,如果beam size为4的批量尺寸使用16,批量尺寸大小为16
* 4 *head(多头注意的头数,通常为8)。矩阵M,K,N的形状(shape)在[1,最大解码长度]或[1,最大编码长度]。
cuBLAS的批量matmul的性能问题
首先,我们对批量matmul核进行理论FLOPs分析。结果非常有趣:所有批量matmul的计算强度都小于1
TFLOPs。
然后我们通过nvprof分析具有多个形状的批量matmul的cuBLAS性能。下表显示了使用CUDA8.0的NVIDIA
M40 GPU获得的一些指标。
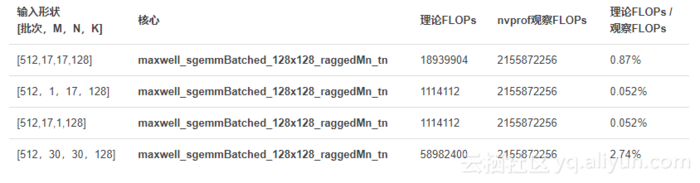
即使具有不同的形状(M,N,K的变化),所有maxwell_sgemmBatched_128x128_raggedMn_tn调用都会执行相同数量的FLOP,这比理论值大得多。可以推断,所有这些不同的形状都可以填充到某种特定的形状中。在所有这些形状中,即使在最好的情况下,理论FLOP仍然只是实际执行FLOP的2.74%,因此大部分计算是相当多余的。同样,另一个cuBLAS内核maxwell_sgemmBatched_64x64_raggedMn_tn的调用也会显示相同的现象。
很明显,cuBLAS的批量执行效率远远不够。因此,我们使用TVM为我们的NMT工作负载生成高效的批处理内核。
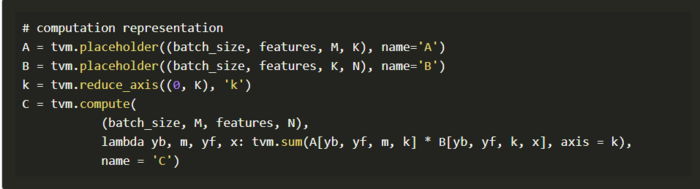
批量matmul计算
在TVM中,一般批量的matmul计算可以被声明为:
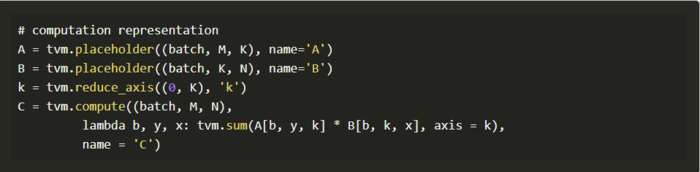
Schedule优化
在对批量matmul计算进行声明之后,我们需要仔细设计我们自己的计划来充分挖掘其性能潜力。
调整块/线程的参数
我们将批量matmul的外部尺寸进行融合,即op维度的BB和FF进行融合,通常在批量matmul计算中称为“批量”维度。然后我们将外部和内部维度按因子(number_thread
* vthread)分解。
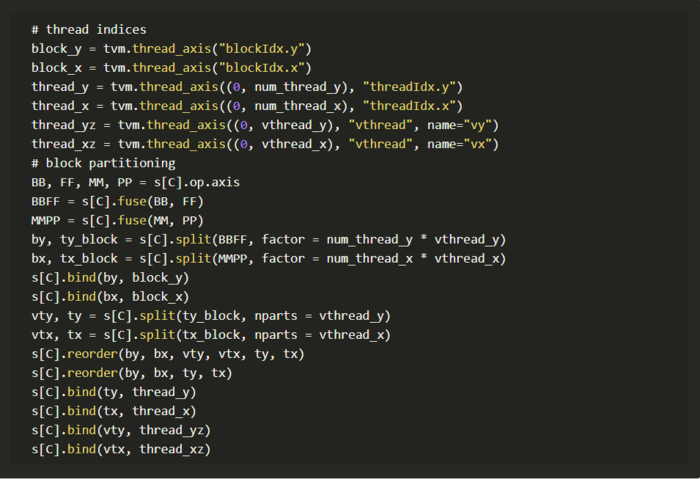
批量matmul中不需要stridged模式,因此虚拟线程数(vthread_y和vthread_x)都被设置为1。
寻找number_thread的最佳组合
以下结果是在配备CUDA8.0的NVIDIA M40 GPU设备上获得的。
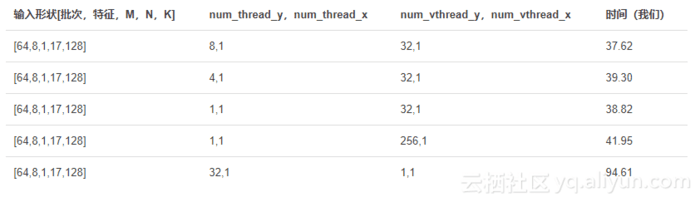
从过去的经验中得知,找到最好的组合(num_thread_y,num_thread_x)是通过强力搜索的方法。在蛮力搜索之后,可以找到当前形状(shape)的最佳组合,经过暴力破解,我们找到了其在当前计算中是num_thread_y=
8和num_thread_x= 32。
将matmul与其他运算融合 通常,现有的“黑盒子”cuBLAS库的调用扮演着通常使用的“op
fusion”优化策略边界的角色。但是,对于生成的高效批量matmul内核,融合边界很容易被破坏,而不仅仅是单元操作,从而可以获得更好的性能改善。
从计算图中可以看到,一个批量matmul总是跟着一个广播加法运算操作或一个转置操作。通过将“加法”或“转置”运算与批量matmul相融合,这可以有效减少内核启动开销和冗余存储器的访问时间。
批量matmul和广播加法融合计算可以声明如下:
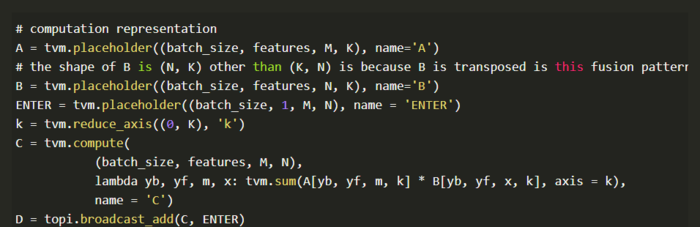
批量matmul和转置融合计算可以声明为:
Fusion的性能
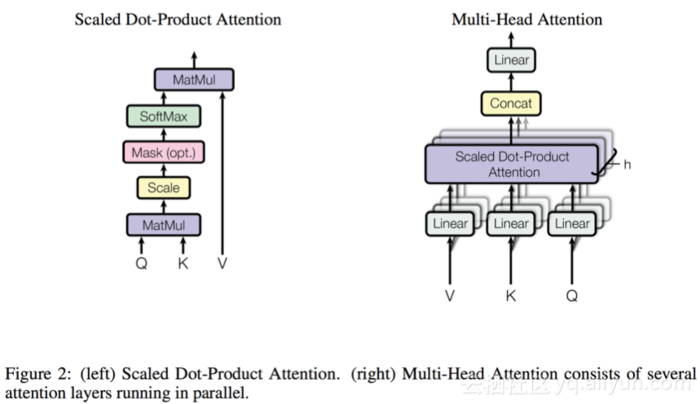
选择[batch = 64,head = 8,M = 1,N = 17,K = 128]的形状(shape)来详细说明生成的代码的性能。选择17作为序列长度,因为它是我们生产场景中的平均输入长度。测试结果如下:
tf-r1.4 BatchMatmul:513.9 us tf-r1.4 BatchMatmul+
Transpose(separate):541.9 us TVM BatchMatmul:37.62us
TVM BatchMatmul+ Transpose(fused):38.39 us 我们可以看到通过内核融合优化带来了1.7倍的提速。
与Tensorflow集成 在我们的工作中,批量matmul的输入形状是有限的。通过这些预定义的形状,我们可以提前生成高度优化的CUDA内核(固定形状计算可以带来最佳的优化潜力)。同时,还会生成适用于大多数形状的一般批量matmul内核,以便为没有相应的提前生成内核的形状提供回退机制。
Tensorflow框架中集成了针对特定形状生成的高效内核和回退机制的内核。我们开发了融合op,比如BatchMatMulTranspose或BatchMatMulAdd,以便使用TVM的运行时,API为特定输入形状启动特定的生成内核或者调用回退内核。图形优化通过自动替换原始批量matmul
+加法/转置模式与融合操作。同时,通过结合更激进的图形优化通道,我们正试图利用TVM为长尾操作模式生成更高效的融合内核,从而进一步加速端到端性能。
总结
在阿里巴巴内部,我们发现TVM是为开发高性能GPU内核以满足我们内部需求的高效工具。在这篇博客中,我们以NMT Transformer模型为例,用TVM来说明了我们的优化策略。首先,通过第一性原理分析找出Transformer模型的问题。然后我们使用TVM生成高度优化的CUDA内核来取代CUBLAS版本(13X加速观察)。接下来,我们利用TVM的内核融合机制融合批量matmul的前/后操作,进一步提升性能(提升了1.7倍的性能)。基于这些生成的内核,开发了一个图形优化通道,用TVM融合内核自动替换原始计算模式,以确保最终用户的优化是透明的,因为作为AI基础架构提供者,我们发现优化策略的透明度对于普及其优化策略是非常重要的。
最后,所有的这些优化都以松散耦合的方式集成到TensorFlow中,将TVM与不同深度学习框架进行不同程度的集成。此外,还有一项工作是将TVM作为TensorFlow的代码后端,我们希望将来可以向社区分享更多结果。
|









