| БрМЭЦМі: |
БОЮФгквыЮФ,ОэЛ§ЩёОЭјТчЪЧвЛжжЪЖБ№КЭРэНтЭМЯёЕФЩёОЭјТчЁЃБОЮФНЋДгВЛЭЌЕФВуДЮРДНщЩмОэЛ§ЩёОЭјТчЁЃ
|
|
БОЮФНЋМЬајЮЊФуНщЩмЙигкОэЛ§ЩёОЭјТчЕФжЊЪЖЁЃЮЊСЫБЃГжЮФеТЕФМђНрадКЭШЋУцадЮвНЋЮЊФуЬсЙЉбаОПТлЮФЕФСДНгЃЌРяБпЛсгаИќЮЊЯъЯИЕФНтЪЭЁЃ
ШЗЖЈПэЖШКЭЬюГф(Stride and Padding)
ШУЮвУЧПДПДзЊЛЛВуЃЌЛЙМЧЕУТЫВЈЦїЁЂНгЪмгђКЭОэЛ§Т№ЃПЯждкЮвУЧПЩвдИФБфСНИіжївЊВЮЪ§РДаоИФУПВуЕФдЫаазДЬЌЁЃдкбЁдёТЫВЈЦїДѓаЁжЎКѓЃЌЛЙвЊбЁдёПэЖШКЭЬюГфЁЃ
гУПэЖШРДПижЦТЫВЈЦїШчКЮдкЪфШыСПЕФЩЯЯТЗЖЮЇФкНјааОэЛ§ЁЃР§ШчЃЌвЛИі7*7ЕФЪфШыСПЃЌвЛИі3*3ЕФТЫВЈЦїЃЈКіТдЕкШ§ЮЌЖШЕФМђЕЅадЃЉЃЌПэЖШЮЊ1ЁЃ
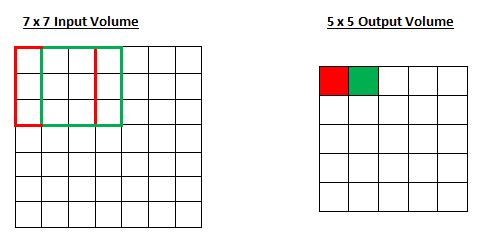
ПДПДФуЪЧЗёФмОЁСІВТГіЫцзХПэЖШдіМгЕН2ЃЌЪфГіСПЛсЗЂЩњЪВУДБфЛЏЁЃ
вђДЫЃЌе§ШчФуЫљПДЕНЕФФЧбљЃЌНгЪмгђЯждкдкСНИіЕЅдЊжЎМфРДЛиБфЛЛЃЌВЂЧвЪфГіЬхЛ§вВЫѕаЁСЫЁЃЧызЂвтЃЌШчЙћЮвУЧЪдЭМНЋПэЖШЕїећЮЊ3ЃЌФЧУДЮвУЧОЭгаМфИєЕФЮЪЬтСЫЃЌЛЙвЊШЗБЃНгЪмгђЪЪКЯЪфШыСПЁЃЭЈГЃРДЫЕЃЌПЊЗЂепШчЙћЯЃЭћНгЪмгђжиЕўНЯЩйЃЌВЂЧвЯЃЭћгаНЯаЁЕФПеМфЮЌЖШЃЌдђЛсдіДѓПэЖШЁЃ
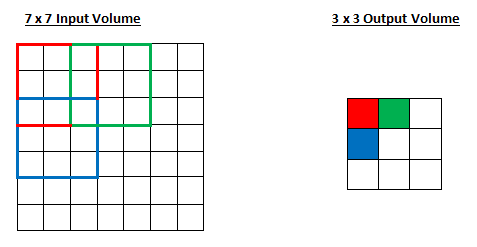
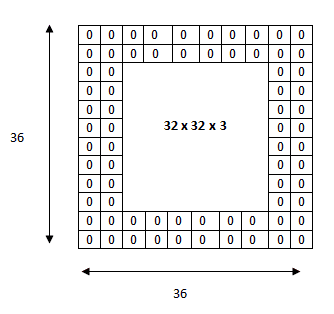
ШУЮвУЧПДПДЬюГфВПЗжЃЌЕЋЪЧдкПЊЪМжЎЧАЃЌШУЮвУЧПМТЧвЛИіГЁОАЁЃЕБФуАбШ§Иі5*5*3ЕФТЫВЈЦїгІгУЕНвЛИі32*32*3ЕФЪфШыСПЪБЛсЗЂЩњЪВУДФиЃПЪфГіСПЛсЪЧ28*28*3ЁЃзЂвтЃЌПеМфЮЌЖШМѕЩйСЫЁЃЕБЮвУЧБЃГжгІгУзЊЛЛВуЪБЃЌЪфГіСПЕФДѓаЁНЋБШЮвУЧЯыЯѓЕФМѕЩйЕФПьЁЃдкЮвУЧЭјТчЕФЧАУцЕФФЧаЉВужаЃЌЮвУЧЯыОЁПЩФмЖрЕиБЃДцдЪМЪфШыСПЕФаХЯЂЃЌетбљЮвУЧОЭПЩвдЬсШЁФЧаЉЕЭМЖЕФЬиадСЫЁЃетбљЫЕАЩЃЌЮвУЧЯыгІгУЭЌбљЕФзЊЛЛВуЃЌЕЋЯывЊЕФЪфГіСПвЊБЃГждк32
x 32 x 3ЁЃвЊзіЕНетвЛЕуЃЌЮвУЧПЩвдЖдИУВугІгУвЛИіДѓаЁЮЊ2ЕФСуЬюГфЁЃСуЬюГфдкБпНчЩЯвдСуЮЊЪфШыЕФСПЁЃШчЙћЮвУЧПМТЧСНИіжаЕФвЛИіСуЬюГфЃЌФЧУДетНЋЛсЕМжТвЛИі36*36*3ЕФЪфШыСПЁЃ
ШчЙћФугавЛИіЮЊ1ЕФПэЖШЃЌВЂЧвФуАбСуЬюГфЕФДѓаЁЩшжУЮЊ:
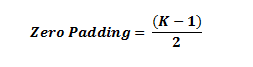
ЕБТЫВЈЦїЕФДѓаЁЮЊKЪБЃЌЪфШыСПКЭЪфГіСПНЋЪМжеОпгаЯрЭЌЕФПеМфЮЌЖШЁЃ
ЖдгкШЮКЮИјЖЈЕФзЊЛЛВуЕФЪфГіСПЕФМЦЫуЙЋЪНЪЧ:
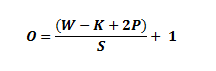
ЩЯУцЕФЙЋЪНжаЃЌOЪЧЪфГіЕФИпЖШ/ГЄЖШЃЌWЪЧЪфШыЕФИпЖШ/ГЄЖШЃЌKЪЧТЫВЈЦїЕФДѓаЁЃЌPЪЧЬюГфЃЌSЪЧПэЖШЁЃ
бЁдёВЮЪ§(Choosing Hyperparameters)
ЮвУЧШчКЮжЊЕРгУСЫЖрЩйВуЃЌгаЖрЩйзЊЛЛВуЃЌТЫВЈЦїЕФДѓаЁЪЧЖрЩйЃЌЛђепПэЖШКЭЬюГфЪЧЪВУДжЕФиЃПетаЉЮЪЬтЮвУЧЖМВЛжЊЯўЃЌвђЮЊЭјТчНЋдкКмДѓГЬЖШЩЯвРРЕгкФуЕФЪ§ОнРраЭЁЃЪ§ОнПЩвдИљОнДѓаЁЁЂЭМЯёЕФИДдгЖШЁЂЭМЯёДІРэШЮЮёЕФРраЭвдМАИќЖрЕФВЛЭЌвђЫиЖјБфЛЏЁЃЕБПДзХФуЕФЪ§ОнМЏЪБЃЌвЛИіПМТЧШчКЮбЁдёВЮЪ§ЕФЗНЪНЪЧдквЛИіЪЪЕБЕФЙцФЃевЕНе§ШЗЕФДДНЈЭМЯёГщЯѓЕФзщКЯЁЃ
ReLU (БЛЕїећЕФЯпадЕЅдЊ)Ву
дкУПИізЊЛЛВуЕФКѓУцЃЌОЭЪЧГЃЙцЕФгІгУЗЧЯпадВуЃЈЛђМЄЛюВуЃЉЁЃетвЛВуЕФФПЕФЪЧЗЧЯпадЕив§ШывЛИіЯЕЭГЃЌетИіЯЕЭГЛљБОЩЯЪЧдкзЊЛЛВувЛжБМЦЫуЯпадВйзїЃЈжЛЪЧдЊЫиЗНЪНЕФГЫЗЈКЭМгЗЈдЫЫуЃЉЁЃ
дкжЎЧАЃЌвЛжБгУЕФЪЧЗЧЯпадКЏЪ§ЃЌШчtanhКЭsigmoidЃЌЕЋбаОПШЫдБЗЂЯжReLUВуЕФаЇТЪдЖдЖИќКУЃЌетЪЧвђЮЊдкЖдОЋЖШУЛгаВњЩњЯджјВЛЭЌЕФЧщПіЯТЃЌЭјТчФмбЕСЗЕФИќПьЃЈвђЮЊМЦЫуаЇТЪИќИпЃЉЁЃЫќвВгажњгкЛККЭЯћЪЇЬнЖШЕФТщЗГЃЌетЪЧвЛИіЮЪЬтЃЌвђЮЊНЯЕЭВуЕФЭјТчбЕСЗЪЧЗЧГЃЛКТ§ЕФЃЌвђЮЊдкетаЉВуРяЬнЖШГЪжИЪ§МЖБ№ЕФЯТНЕВуЃЈНтЪЭетИіЮЪЬтПЩФмГЌГіСЫБОЮФЕФЗЖЮЇЃЌЕуЛїетРяКЭетРяРДВщПДОпЬхЕФНтЪЭКЭУшЪіЃЉЁЃReLUВуЕїгУКЏЪ§fЃЈxЃЉ=
maxЃЈ0ЃЌxЃЉРДЬсЙЉЪфШыСПЕФЫљгажЕЁЃЛљБОЩЯРДЫЕЃЌетвЛВуИеКУИФБфЫљгаЕФИКМЄЛюЮЊ0ЁЃетвЛВудкВЛгАЯьзЊЛЛВуЕФНгЪмгђЕФЧщПіЯТЃЌЬсИпСЫФЃаЭКЭећИіЭјТчЕФЗЧЯпадЕФЪєадЁЃ
ГиЛЏВуЃЈPooling LayersЃЉ
ОЙ§вЛаЉReLUВуЃЌПЊЗЂепПЩвдбЁдёгІгУвЛИіГиЛЏВуЃЌЫќвВБЛГЦЮЊЫѕМѕВЩбљВуЁЃдкетвЛРрБ№жаЃЌвВгаЦфЫќМИИіВуЕФбЁдёЃЌгызюДѓГиЛЏЃЈmaxpoolingЃЉвЛЦ№ЪЧзюЪмЛЖгЕФЁЃетЛљБОЩЯашвЊвЛИіТЫВЈЦїЃЈЭЈГЃДѓаЁЮЊ2*2ЃЉКЭЯрЭЌГпДчЕФПэЖШЁЃШЛКѓНЋЦфгІгУгкЪфШыСПКЭдкУПИігаТЫВЈЦїОэЛ§ЕФзгЧјгђжаЪфГіЕФзюДѓЪ§СПЁЃ
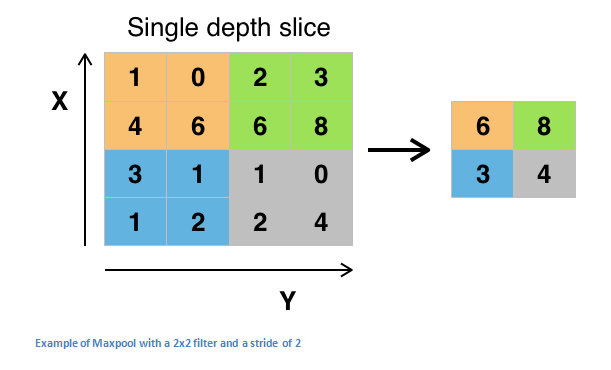
ГиЛЏВуЕФЦфЫћбЁЯюЪЧЦНОљГиЛЏКЭL2-normГиЛЏЁЃетИіВуБГКѓЕФжБЙлРэНтЪЧЃЌвЛЕЉЮвУЧжЊЕРвЛИіЬиЖЈЕФЬиеїЪЧдкдЪМЪфШыСПжаЃЈНЋЛсгавЛИіИпМЄЛюжЕЃЉЃЌЫќЕФШЗЧаЮЛжУВЂВЛЯёЫќЯрЖдгкЦфЫќЬиеїЕФЮЛжУФЧУДживЊЁЃПЩвдЯыЯѓЃЌетвЛВуМЋДѓЕиМѕЩйСЫЪфШыСПЕФПеМфЮЌЖШЃЈГЄЖШКЭПэЖШЕФБфЛЏЃЌЖјВЛЪЧЩюЖШЃЉЁЃетгаСНИіжївЊФПЕФЁЃЪзЯШЃЌВЮЪ§ЛђШЈжиЕФЪ§СПМѕЩйСЫ75%ЃЌДгЖјНЕЕЭСЫМЦЫуЕФГЩБОЁЃЦфДЮЃЌЫќНЋПижЦЙ§ЖШФтКЯЃЌетжИЕФЪЧЕБвЛИіФЃаЭБЛЕїећЕНбЕСЗбљБОЪБЃЌЫќВЛФмКмКУЕиЮЊбщжЄКЭВтЪдМЏНјааБъзМЛЏЁЃЙ§ЖШФтКЯЕФБэЯжЪЧЃЌгавЛИіФЃаЭЃЌдкбЕСЗМЏЩЯЕУЕН100%Лђ99%ЕФБэЯжЃЌЕЋдкВтЪдЪ§ОнЩЯжЛга50%ЁЃ
Dropout Layers
ЯждкЃЌDropout LayersдкЩёОЭјТчжагавЛИіЗЧГЃЬиЪтЕФЙІФмЁЃдкЩЯвЛНкжаЃЌЮвУЧЬжТлСЫЙ§ЖШФтКЯЕФЮЪЬтЃЌбЕСЗНсЪјКѓЃЌЭјТчЕФШЈжиБЛЕїећЕНСЫвбИјЕФбЕСЗбљБОЃЌЕБЬсЙЉСЫаТЕФбЕСЗбљБОЪБЭјТчОЭжДааЕФВЛФЧУДКУСЫЁЃDropoutЕФЯыЗЈдкБОжЪЩЯЪЧЙ§гкМђЕЅЛЏЕФЁЃетвЛВуЁАЩОГ§ЁБвЛИіЫцЛњМЄЛюМЏЃЌЭЈЙ§НЋЫќУЧЩшжУЮЊСуЁЃМДЪЙФГаЉМЄЛюБЛЩОГ§СЫЃЌЭјТчвВгІИУФмЙЛЮЊЬиЖЈЕФбљБОЬсЙЉе§ШЗЕФЗжРрЛђЪфГіЁЃЫќШЗБЃЭјТчБфЕУВЛЁАЪЪКЯЁБбЕСЗЪ§ОнЃЌДгЖјгажњгкЛКНтЙ§ЖШФтКЯЕФЮЪЬтЁЃвЛИіживЊЕФзЂвтЪТЯюЪЧЃЌетвЛВуНігУгкбЕСЗЦкМфЃЌЖјВЛЪЧдкВтЪдЦкМфЪЙгУЁЃ
ЭјТчВуЕФЭјТчЃЈNetwork in Network LayersЃЉ
ЭјТчВуЕФЭјТчжИЕФЪЧвЛИігІгУ1 x 1ДѓаЁЕФТЫВЈЦїЕФзЊЛЛВуЁЃЪзЯШЃЌМШШЛНгЪмгђЭЈГЃвЊБШЫќУЧгГЩфЕНЕФПеМфДѓЃЌФуПЩФмЯыжЊЕРЮЊЪВУДВуЕФРраЭЛсгаАяжњЁЃШЛЖјЃЌЮвУЧБиаыМЧзЁЃЌетаЉ1x1ОэЛ§ЕФПчЖШЪЧгавЛЖЈЩюЖШЕФЃЌЫљвдПЩвдШЯЮЊЫќЪЧвЛИі1
x 1 x NЕФОэЛ§ЃЌЦфжаNЪЧТЫВЈЦїдкетвЛВужагІгУЕФЪ§СПЁЃ
ЗжРрЁЂЖЈЮЛЁЂМьВщЁЂЗжИюЃЈClassification, Localization,
Detection, SegmentationЃЉ
ЕБЮвУЧжДаавЛИіРрЫЦгкЖдЯѓБОЕиЛЏетбљЕФШЮЮёЪБЃЌВЛНіНіЪЧЩњГЩвЛИіРрБъЧЉЃЌЛЙАќРЈвЛИігУРДУшЪіЖдЯѓдкЭМЦЌжаЮЛжУЕФАќЮЇКаЃЈbounding
boxЃЉЁЃ

ЮвУЧвВгаЖдЯѓМьВтЕФШЮЮёЃЌашвЊЖдЭМЯёжаЕФЫљгаЖдЯѓНјааЖЈЮЛЁЃвђДЫЃЌНЋгаЖрИіАќЮЇКаКЭЖрИіРрБъЧЉЁЃ
зюКѓЃЌЮвУЧЛЙНјааСЫЖдЯѓЗжИюЃЌЦфжаЕФШЮЮёЪЧЪфГівЛИіРрБъЧЉвдМАвЛИіЪфШыЭМЯёжаУПИіЖдЯѓЕФТжРЊЁЃ

ЧЈвЦбЇЯАЃЈTransfer LearningЃЉ
ЯждкЃЌдкЩюЖШбЇЯАЩчЧјЕФвЛИіГЃМћЕФЮѓНтЪЧЃКУЛгаГЌДѓЕФЪ§ОнСПЃЌФуВЛПЩФмДДНЈгааЇЕФЩюЖШбЇЯАФЃаЭЁЃЪ§ОнЙЬШЛЪЧДДНЈЭјТчЕФЙиМќВПЗжЃЌЕЋвВВЛЪЧОіЖЈВПЗжЃЌЧЈвЦбЇЯАЕФЫМЯыгажњгкМѕЩйЪ§ОнашЧѓЁЃЧЈвЦбЇЯАЪЧНгЪмдЄбЕСЗФЃаЭЃЈгЩЦфЫћШЫдкДѓЪ§ОнМЏЩЯбЕСЗЙ§ЕФЭјТчЕФШЈжиКЭВЮЪ§ЃЉВЂгУздМКЕФЪ§ОнМЏЖдФЃаЭНјааЁАЮЂЕїЁБЕФЙ§ГЬЁЃетИіЯыЗЈЪЧетИідЄЯШбЕСЗЕФФЃаЭНЋзїЮЊвЛИіЬиеїЬсШЁЦїЁЃФуНЋЩОГ§ЭјТчЕФзюКѓвЛВуЃЌВЂгУздМКЕФЗжРрЦїРДДњЬцЁЃШЛКѓЖГНсЫљгаЦфЫќВуЕФШЈжиЃЌВЂе§ГЃЕибЕСЗЭјТчЃЈЖГНсетаЉВувтЮЖзХдкЬнЖШЯТНЕ/гХЛЏЙ§ГЬжаВЛИФБфШЈжиЃЉЁЃ
ЮвУЧе§дкЬНЬжЕФЪЧдЄбЕСЗФЃаЭдкImageNetЩЯбЕСЗЃЈImageNetЪЧвЛИіЪ§ОнМЏЃЌдк1000вдЩЯИіРрРяАќКЌ1400ЭђЗљЭМЯёЃЉЁЃЕБПМТЧЭјТчЩЯФЧаЉНЯЕЭЕФВуЪБЃЌЮвУЧжЊЕРЫќУЧНЋМьВтЕНЯёБпдЕКЭЧњЯпетбљЕФЬиеїЁЃЯждкЃЌГ§ЗЧФугавЛИіЗЧГЃЖРЬиЕФЮЪЬтПеМфКЭЪ§ОнМЏЃЌФуЕФЭјТчвВНЋашвЊМьВтЧњЯпКЭБпдЕЁЃгыЦфЭЈЙ§вЛИіЫцЛњЕФШЈжиГѕЪМЛЏжЕРДбЕСЗећИіЭјТчЃЌЮвУЧПЩвдЪЙгУдЄбЕСЗФЃаЭЕФШЈжиЃЌВЂжТСІгкдкИќживЊЕФВуЃЈИќИпЕФВуЃЉЩЯНјаабЕСЗЁЃШчЙћФуЕФЪ§ОнМЏгыImageNetЭъШЋВЛЭЌЃЌФЧУДФуОЭвЊбЕСЗИќЖрЕФВуВЂЖГНсСНИіНЯЕЭЕФВуЁЃ
Ъ§ОнРЉеЙММЪѕЃЈData Augmentation TechniquesЃЉ
ЯждкЃЌЮвУЧПЩФмЖдЪ§ОндкОэЛ§ЩёОЭјТчжаЕФживЊадУЛЪВУДИаОѕСЫЃЌвђДЫШУЮвУЧЬИТлвЛЯТШУФуЕФЪ§ОнМЏБфДѓЕФЗНЗЈЃЌНіНіЪЧгУСНИіМђЕЅЕФБфЛЛЁЃе§ШчЮвУЧЧАУцЬсЕНЙ§ЕФЃЌЕБМЦЫуЛњгУвЛИіЭМЯёзїЮЊЪфШыЪБЃЌЫќНЋЪфШывЛИіЯёЫижЕЕФЪ§зщЁЃМйЩшећИіЭМЯёБЛзѓвЦ1ИіЯёЫиЁЃЖдФуКЭЮвРДЫЕЃЌетИіБфЛЏЪЧЧБвЦФЌЛЏЕФЁЃШЛЖјЃЌЖдгквЛИіМЦЫуЛњРДЫЕЃЌетвЛИФБфПЩФмЯрЕБЕиживЊЃЌвђЮЊЭМЯёЕФЗжРрЛђБъЧЉВЛЛсИФБфЃЌЖјЪ§зщИФБфСЫЁЃвдИФБфЪ§зщБэЪОЕФЗНЪНИФБфбЕСЗЪ§ОнЕФЗНЗЈЃЌЭЌЪББЃГжБъЧЉЯрЭЌЃЌГЦЮЊЪ§ОнРЉеЙММЪѕЁЃетЪЧвЛжжШЫЙЄРЉеЙЪ§ОнМЏЕФЗНЗЈЁЃШЫУЧЪЙгУЕФвЛаЉСїааЕФРЉеЙЪЧЛвЖШЁЂЫЎЦНЗзЊЁЂДЙжБЗзЊЁЂЫцзїЮяЁЂЩЋПжЛХЁЂЦНвЦЁЂа§зЊЕШЕШЁЃЭЈЙ§НЋЦфжаЕФСНИізЊЛЛгІгУЕНбЕСЗЪ§ОнжаЃЌФуОЭПЩвдЧсЫЩЕиНЋбЕСЗбљБОЕФЪ§СПРЉДѓвЛБЖЛђШ§БЖЁЃ
|









