| БрМЭЦМі: |
БОЮФРДздгкyq.aliyun.com,Javascript
ЪЪКЯзіЛњЦїбЇЯАТ№ЃПетЪЧвЛИіЮЪКХЁЃЕЋУПвЛЮЛПЊЗЂепЖМгІИУСЫНтЛњЦїбЇЯАНтОіЮЪЬтЕФЫМЮЌКЭЗНЗЈЃЌВЂЫМПМЃКЫќНЋЛсИјЮвУЧЕФЙЄзїДјРДЪВУДЃПЭЌбљЃЌЫуЗЈФмСІПЩФмЛсЪЧЯТвЛНзЖЮЙЄГЬЪІЕФБъХфЁЃ
|
|
ЕМгя
БОЮФжМдкЭЈЙ§НВНтЪЖБ№ЪжаДзжЕФДІРэЙ§ГЬЃЌДјЖСепСЫНтЛњЦїбЇЯАНтОіЮЪЬтЕФвЛАуЙ§ГЬЁЃБОЮФЪЪКЯвдЯТБГОАЕФЖСепдФЖСЃК
ФуВЛашвЊОпБИ PythonЁЂC++ ЕФБрГЬФмСІЃКШЋЮФЪЙгУ Javascript зїЮЊБрГЬгябдЃЌЧвВЛвРРЕШЮКЮЕкШ§ЗНПтЪЕЯжЛњЦїбЇЯАЫуЗЈЃЛ
ФуВЛашвЊОпБИЫуЗЈФмСІКЭИпЪ§ЕФБГОАЃЌБОЮФЛњЦїбЇЯАЫуЗЈЕФЪЕЯжВЛЙ§ 20 ааДњТыЁЃ
зїепбЇЪЖгаЯоЃЌЮФеТжаФбУтЛсгаЪшТЉЃЌЛЖгжИе§ЁЃ
ЛњЦїбЇЯАжаЕФ Hello World
ОЭЯёЮвУЧбЇЯАБрГЬгябдвЛбљЃЌЮвУЧЕФЕквЛИіГЂЪдОЭЪЧдкжеЖЫУќСюаажаЪфГіЕФ ЁАHello WorldЁБЁЃЛњЦїбЇЯАжаЕФ
ЁАHello WorldЁБ БуЪЧЪЖБ№ЪжаДзжЪ§ОнМЏЁЃЪжаДзжЪЧаЮШчЯТУцЕФЭМЯёЃК
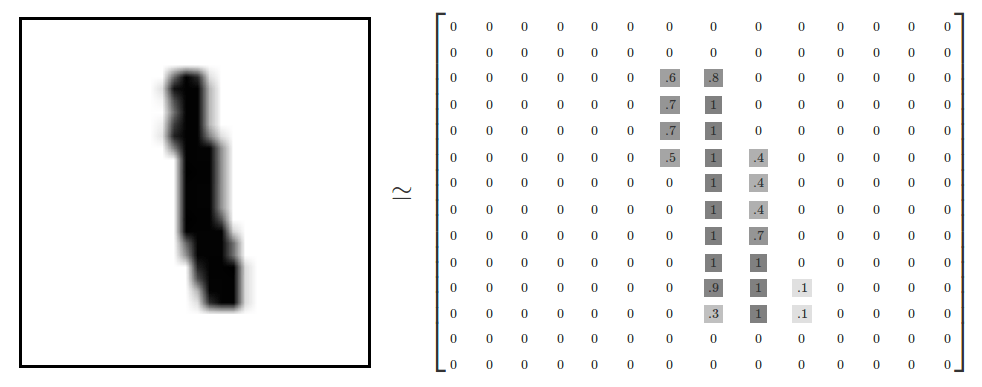
ЮвУЧПЩвдБраДвЛИіЭјвГГЬађЃЌЬсЙЉЪжаДАхЕФЙІФмРДВЖЛёгУЛЇЕФЪфШыЃЌВЂЗЕЛиЮвУЧЪЖБ№ЕФЪ§зжЃКгУЛЇдкЪжаДАхФкаДЯТ
0 ЕН 9 жаЕФШЮвтвЛИіЪ§зжЃЌСэвЛВрдђЯдЪОЮвУЧЪЖБ№ЕФНсЙћЁЃе§Шч Keras.js ЬсЙЉЕФЪОР§ФЧбљ[[1]](#9)ЃК
ШчКЮБраДГіетбљЕФЪжаДЪЖБ№ГЬађРДЛёШЁгУЛЇЕФЪжаДЪфШыВЛЪЧЮвУЧетЦЊЮФеТЕФжиЕуЁЃЮвУЧжиЕуЪЧЃЌЕБЮвУЧЕФГЬађЕУЕНетбљвЛеХЭМЯёЕФЪ§ОнКѓЃЌШчКЮЪЖБ№ГіетзщЪ§ОнБэЪОЕФЪ§зжЃП
Ъ§ОнЕФБэЪОКЭЪеМЏ
ШЫРрФмЙЛДгЭМЯёжаЛёЕУаХЯЂЃЌЕЋГЬађШчКЮжЊЕР A ЭМЪЧБэЪО 1ЃЌB ЭМЪЧБэЪО 2 ЃПвђДЫЮвУЧашвЊШЗЖЈЪ§ОнЕФБэЪОЗНЪНЃКгУдѕбљЕФвЛжжЗНЪНРДдкГЬађжаБэДявЛеХАзЕзКкзжЕФЭМЯёЫќЕФЯёЫиЕуЗжВММАЕуЕФКкАзЖШЃП
ЙлВь Keras.js ЕФЪОР§ЃЌФуЛсЗЂЯжЪжаДАхЕФУцЛ§ЪЧ 240px * 240pxЁЃМДЪжаДАхФкга
57,600 ИіЯёЫиЕуЁЃЮвУЧПЩвдАбЫќУЧЦНЦЬПЊРДЃЌВЂЧвгУ 0 ЕН 1 ЕФЪ§жЕБэЪОУПИіЕуЕФКкАзЖШЃЌЦфжадННгНќ
1 дђБэЪОИУЯёЫиЕудНКкЃЌФЧУДОЭПЩвдгУвЛИіЪ§жЕОиеѓРДБэЪОЪжаДзжЃК
ЪжаДАхГЬађЛёЕУгУЛЇЕФЪфШыВЂЩњГЩЭМЯёКѓЃЌЪЖБ№ГЬађНЋЭМЯёзЊЛЛГЩЮвУЧашвЊЕФЪ§ОнИёЪНЁЃЭМЯёЪЖБ№ЪЧСэвЛИіЙуЗКЕФПЮЬтЃЌдкетРяВЛдйеЙПЊЁЃЮвУЧЛсжБНгЪЙгУ
MNIST Ъ§ОнМЏ[[2]](#9)ЃЌЫќЕФЪ§ОнБэЪОЗНЪНе§ШчЩЯУцЫљУшЪіЕФФЧбљЃЌжЛЪЧ MNIST Ъ§ОнМЏжаУПвЛеХЭМЦЌЪЧАќКЌ
28 * 28 ИіЯёЫиЕуЕФЁЃ
ШЗЖЈСЫЪ§ОнЕФБэЪОЗНЪНЃЌНгЯТРДЮвУЧЛЙашвЊЖдУПИіЪ§ОнЕФЪЕМЪКЌвхНјааБъЪЖЁЃ
ЛиЯывЛЯТЮвУЧздМКЪЧШчКЮШЯЪЖетаЉЪ§зжЕФЃПМДЮвУЧЪЧдѕбљШЯЖЈЭМЯёжаЕФ 1 аЮзДБэЪОЕФОЭЪЧЪ§зж 1ЃПЁЊЁЊЁЊЁЊЪТЮяЕФШЯЪЖЁЃШЯжЊЪЧгЩЫћШЫНЬг§ЕФЁЃ
ЭЌбљЃЌдкЛњЦїбЇЯАжаЃЌЮвУЧвВашвЊЁАНЬг§ЁБЛњЦїЃКA етбљЕФЯёЫиЕуХХађОЭЪЧ 1ЃЌ B етбљЕФЯёЫиЕуХХађЪЧ
2ЁЃетОЭЪЧбЕСЗЪ§ОнЁЃ
ЮЊСЫЪеМЏбЕСЗЪ§ОнЃЌЮвУЧПЩвдЫцЛњевШЫдкЪжаДЪЖБ№ГЬађжаЛЪ§зжЃЌШЛКѓБъЪЖЫќЕФНсЙћЃЌзюжевдШЮКЮЕФаЮЪНЃЈЮФБОЁЂБэИё...ЃЉДЂДцЁЃвдЪжаДзжЮЊР§ЃЌЮвУЧПЩвдгУЮФБОЕФЗНЪНДцДЂЃЌИёЪНПЩвдЪЧетбљЃК
0 0 0.3 0 1 0
... n(=28) | 4
1 0 0.1 0 0 0 ... n(=28) | 6
....
n(=1000) |
ЦфжаУПвЛааДњБэвЛИібЕСЗЪ§ОнЃЌЪЙгУ ЁА|ЁБ ЗжИюЪ§ОнЕФБэЪОКЭЫќЖдгІЕФЪ§зжЁЃ
дкБОЮФжаЮвУЧНЋжБНгЪЙгУ MNIST Ъ§ОнМЏЃЌвђДЫШчКЮЪеМЏЪ§ОндкетРяВЛдйеЙПЊЁЃдкЛњЦїбЇЯАжаОГЃЛсЪЙгУЙЋПЊЕФЪ§ОнМЏРДНјаабЕСЗКЭВтЪдЁЃ
ЭЈЙ§ШЗЖЈЪ§ОнЕФБэЪОКЭЪеМЏЃЌЮвУЧПЩвдСЫНтЕНЕФЪЧЃК
Ъ§ОнЪЧвЛЧаЛњЦїбЇЯАЕФЛљДЁЃЛ
бЕСЗЪ§ОнЕФКУЛЕНЋЛсгАЯьЕНЮвУЧЛњЦїбЇЯАЫуЗЈдЄВтЕФзМШЗТЪЃК
ЯыЯѓвЛЯТШчЙћФГаЉЪ§ОнЮвУЧБъЪЖДэЮѓЃЌАб 1 БъЪЖГЩ 2ЃЛ
ЯыЯѓвЛЯТШчЙћбЕСЗЪ§ОнжагаДѓСПЕФжиИДжЕЃЌЛђФГИіЪ§зжЕФЪ§ОнСПЬиБ№ДѓЖјСэЭтвЛаЉЪ§зжЕФЪ§ОнСПКмаЁЁЃ
зМБИЪ§Он
ЮвУЧЪеМЏЕНЕФЪ§ОнПЩФмЛсвдШЮКЮЕФвЛжжаЮЪНДцДЂЃЌР§ШчЮФБОЁЂБэИёЁЂЖўНјжЦЮФМўЕШЕШЁЃMNIST Ъ§ОнМЏЪЧЪЙгУЖўНјжЦДцДЂЕФЃЌвђДЫдкГЬађжаЮвУЧашвЊНЋЫќзЊЛЛЮЊ
Javascript БШНЯШнвзВйзїЕФЕФЪ§ОнИёЪНЃЌР§ШчЪ§зщЁЃ
БОЮФжаЮвУЧНЋЪЙгУвЛИі NPM Аќ mnist[[3]](#9) ЬсЙЉЕФЃЌвбОзЊЛЛКУЕФЪ§ОнЃЌЫќЕФИёЪНШчЯТЃК
[
{
input: [0, 0.4, 0.5, 0, 0.1, 0, 0, 0, 0, ...,
n], // n = 728
output: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0], // 1
},
{
input: [1, 0.4, 0.5, 0, 0.8, 0, 0.1, 0, 1, ...,
n], // n = 728
output: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0], // 2
},
....
] |
Цфжа input ЪЧЭМЯёЕФЪ§ОнБэЪОЃЌoutput ЪЧЭМЯёЪЕМЪДњБэЕФЪ§зжЁЃoutput ЪЙгУСЫвЛжжНазі
One-Hot ЕФБрТыЗНЪНЃЌЫќвЛЙВга 10 ИіЯюЃЌЮЊ 1 ЕФЯюОЭЪЧЫќБэЪОЕФЪ§зжЃЈЕквЛЯюЮЊ 1 дђДњБэЪЧ
0ЃЌЕкЖўЯюЮЊ 1 дђДњБэЪЧ 2 ЃЌвдДЫРрЭЦЃЉЁЃ
бЁдёвЛжжЫуЗЈ
ЭЈЙ§ЩЯУцЕФЪ§ОнзМБИЃЌЮвУЧвбОАбвЛИіЯжЪЕжаЕФЮЪЬтзЊЛЏГЩСЫвЛИіЪ§бЇЮЪЬтЃКИјЖЈ 728 Иі 0 ЕН 1
жЎМфЪ§жЕЕФЬиеїЃЌгІИУНЋЫќЗжРрЕН 0 ~ 9 ФФИіЪ§зжжаЃП
етОЭЪЧЛњЦїбЇЯАжаЕФжївЊШЮЮёЁЊЁЊЗжРрЁЃгаКмЖрЕФЛњЦїбЇЯАЫуЗЈПЩвдгУРДНтОіЗжРрЮЪЬтЃЌЮФБОНЋЪЙгУ k-НќСкЫуЗЈ(k-NN)[[4]](#9)РДНтОіетИіЮЪЬтЃЌвђЮЊЫќЗЧГЃгааЇЧвШнвзРэНтЁЃ
k-НќСкЫуЗЈИХЪі
дквЛИі 10 * 10 ЕФЖўЮЌЦНУцФкЛвЛЬѕЯпАбЫќЗжГЩ 2 ИіЧјгђ(A/B)ЁЃМйЩшЮвУЧВЛжЊЕРЯпЪЧШчКЮЛЕФЃЌЕЋЯжвбжЊга
4 ИіЕуЃЌa ЕузјБъЪЧ (1, 1) ЪєгкЧјгђ AЃЌb ЕузјБъЪЧ (2, 2) ЪєгкЧјгђ AЃЌc ЕузјБъЪЧ
(9, 9) ЪєгкЧјгђ BЃЌd ЕузјБъЪЧ (8, 8) ЪєгкЧјгђ BЁЃетЪБКђдйИјЖЈвЛИі e ЕузјБъЪЧ
(8.5, 8.5) ЃЌЧыЮЪЫќзюгаПЩФмдкФФИіЧјгђФкЃП
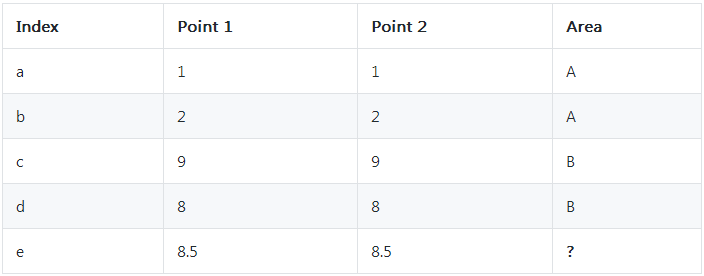
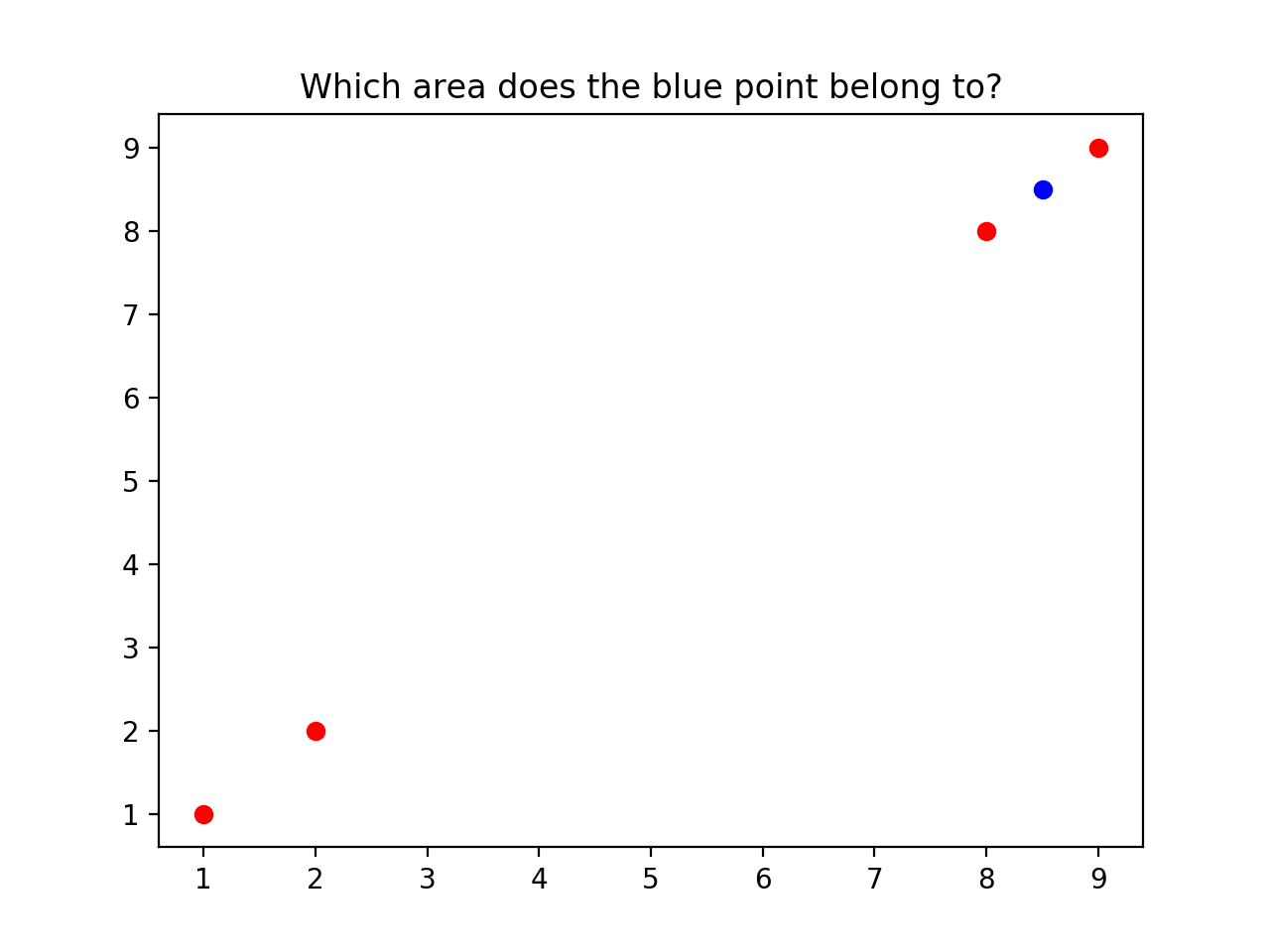
ЖўЮЌЦНУцЭМЪОР§
ОјДѓЖрЪ§ШЫЖМЛсЫЕЁАПЩФмЪЧ BЁБЁЃЮвУЧЪЧШчКЮетИіД№АИЕФЃПЁЊЁЊвђЮЊЫќКЭ c, d ЁАПДЦ№РДИќНгНќвЛаЉЃЌИќгаПЩФмдкЭЌвЛИіЧјгђЁБЁЃЭЌбљЕФЭЦТлПЩвдбгЩьжСШ§ЮЌЁЂЫФЮЌЩѕжСИќЖрЮГЖШЕФЪ§ОнжаЁЃMNIST
ЕФЪ§ОнБэЪООЭЪЧ 728 ИіЬиеїЕФЖрЮГЪ§ОнЃЌk-НќСкЫуЗЈЭЌбљЪЪгУЁЃ
ДцдквЛИібЕСЗбљБОМЏЃЌВЂЧвбљБОМЏжаУПИіЪ§ОнЖМДцдкБъЧЉЃЌМДЮвУЧжЊЕРбљБОМЏжаУПвЛЪ§ОнгыЫљЪєЗжРрЕФЖдгІЙиЯЕЁЃЪфШыУЛгаБъЧЉЕФаТЪ§ОнКѓЃЌНЋаТЪ§ОнЕФУПИіЬиеїгыбљБОМЏжаЪ§ОнЖдгІЕФЬиеїНјааБШНЯЃЌШЛКѓЫуЗЈЬсШЁбљБОЬиеїзюНќСкЕФЗжРрБъЧЉЁЃвЛАуРДЫЕЃЌЮвУЧжЛбЁдёбљБОЪ§ОнМЏжаЧА
k ИізюЯрЫЦЕФЪ§ОнЃЌетОЭЪЧ k-НќСкЫуЗЈЕФ k ЕФГіДІЁЃ
ЁЊЁЊЁЖЛњЦїбЇЯАЪЕеНЁЗk НќСкЫуЗЈ
СНИіЯђСПжЎМфЕФОрРыПЩвдЭЈЙ§ХЗМИРяЕУОрРыЙЋЪНЧѓЕУЃК
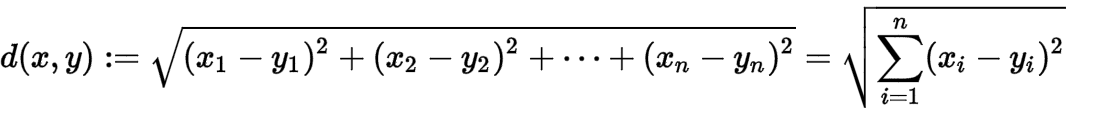
гкЪЧЪЕЯжвЛИі k-NN ЫуЗЈОЭКмМђЕЅСЫЃК
| function classify(x,
trainingData, labels, k) {
// ШЗЖЈФПБъЕу x гыбЕСЗЪ§ОнжаУПИіЕуЕФОрРыЃЈХЗМИРяЕУОрРыЙЋЪНЃЉ
const distances =[];
trainingData.forEach(element => {
let distance = 0;
element.forEach((value, index) => {
const diff = x[index] - value;
distance += (diff * diff);
});
distances.push(Math.sqrt(distance));
});
// НЋбЕСЗЪ§ОнАДеегы x ЕуЕФОрРыДгНќЕНдЖХХађ
const sortedDistIndicies = distances
.map((value, index) => {
return {value, index};
})
.sort((a, b) => a.value - b.value );
// ШЗЖЈЧА k ИіЕуРрБ№ЕФГіЯжЦЕТЪ
const classCount = {};
for (let i = 0; k > i; i++) {
const voteLabel = labels[sortedDistIndicies[i].index];
classCount[voteLabel] = (classCount[voteLabel]
|| 0) + 1;
}
// ЗЕЛиГіЯжЦЕТЪзюИпЕФРрБ№зїЮЊЕБЧАЕуЕФдЄВтЗжРр
let predictedClass = '';
let topCount = 0;
for (const voteLabel in classCount) {
if (classCount[voteLabel] > topCount) {
predictedClass = voteLabel;
topCount = classCount[voteLabel];
}
}
return predictedClass;
} |
ВтЪдЫуЗЈ
ЮЊСЫбщжЄЮвУЧЕФЫуЗЈЕФаЇЙћЃЌЮвУЧашвЊЖдЦфНјааВтЪдЁЃетОЭашвЊв§ШыВтЪдЪ§ОнЁЃдкЛњЦїбЇЯАжаЭЈГЃЛсНЋЪеМЏЕНЕФЪ§ОнЭЈЙ§вЛЖЈЕФЗНЗЈЛЎЗжЮЊбЕСЗЪ§ОнКЭВтЪдЪ§ОнШЛКѓгУгкбЕСЗКЭВтЪдЁЃШчКЮЛЎЗжЪ§ОндкетРяВЛеЙПЊЃЌдкБОЪОР§жаЃЌЮвУЧАДее
80:20 ЕФБШР§РДЛЎЗжбЕСЗКЭВтЪдЪ§ОнЃЌЛЅГтадКЭЫцЛњадгЩ MNIST ПтНјааБЃжЄЁЃ
ФУЕНбЕСЗКЭВтЪдЪ§ОнКѓЮвУЧОЭПЩвдЖдЩЯвЛВНБраДЕФЫуЗЈНјааВтЪдСЫЃЌЮвУЧгУДэЮѓТЪРДЦРЙРЫуЗЈЕФПЩППадЃЌДэЮѓТЪдНЕЭдђдНПЩППЃК
| const classify
= require('./kNN');
// 1. ЪеМЏЪ§ОнЃККіТдЃЌжБНгЪЙгУ MNIST
const mnist = require('mnist');
// 2. зМБИЪ§Он
let trainingImages = [];
let labels = [];
// ЛЎЗжЪ§Он
const trainingCount = 8000;
const testCount = 2000;
const set = mnist.set(trainingCount, testCount);
const trainingSet = set.training;
const testSet = set.test;
// ЮЊЮвУЧЕФ k-NN ЫуЗЈзМБИЬиЖЈЕФЪ§ОнИёЪН
trainingSet.forEach(({input, output}) =>
{
// One-Hot to number
const number = output.indexOf(output.reduce((max,
activation) => Math.max(max, activation),
0));
trainingImages.push(input);
labels.push(number);
});
// 3. ЗжЮіЪ§ОнЃКдкУќСюаажаМьВщЪ§ОнЃЌШЗБЃЫќЕФИёЪНЗћКЯвЊЧѓ
console.log('trainingImages', JSON.stringify(trainingImages));
console.log('labels', JSON.stringify(labels));
// 4. ВтЪдЫуЗЈ
let errorCount = 0;
const startTime = Date.now();
testSet.forEach(({input, output}, key) =>
{
const number = output.indexOf(output.reduce((max,
activation) => Math.max(max, activation),
0));
const predicted = classify(input, trainingImages,
labels, 3);
const result = predicted == number;
console.log(`${key}. number is ${number}, predicted
is ${predicted}, result is ${result}`);
if (!result) {
errorCount++;
}
});
console.log(`The total number of errors is:
${errorCount}`);
console.log(`The total error rate is: ${errorCount/testCount}`);
console.log(`Spend: ${(Date.now() - startTime)
/ 1000}s`); |
ШчЮовтЭтЃЌФуЕФжеЖЫНЋЛсЪфГіетбљЕФНсЙћЃК

зюжеДэЮѓТЪЕФжЕДѓдМЪЧ 5%ЁЃетИіНсЙћКУТ№ЃПВЂВЛКУЁЃЮвУЧПЩвдЭЈЙ§ИФБф k ЕФжЕЁЂИФБфбЕСЗбљБОЕФЪ§ФПгАЯь
k-НќСкЫуЗЈЕФДэЮѓТЪЃЌЖСепПЩвдГЂЪдИФБфетаЉБфСПжЕЙлВьДэЮѓТЪЕФБфЛЏЁЃЪЕМЪЩЯЃЌжЛвЊНЋ k-НќСкЫуЗЈЩдМгИФСМЃЌЮвУЧОЭФмЙЛАбДэЮѓТЪНЕЕН
1% вдЯТЃЁ
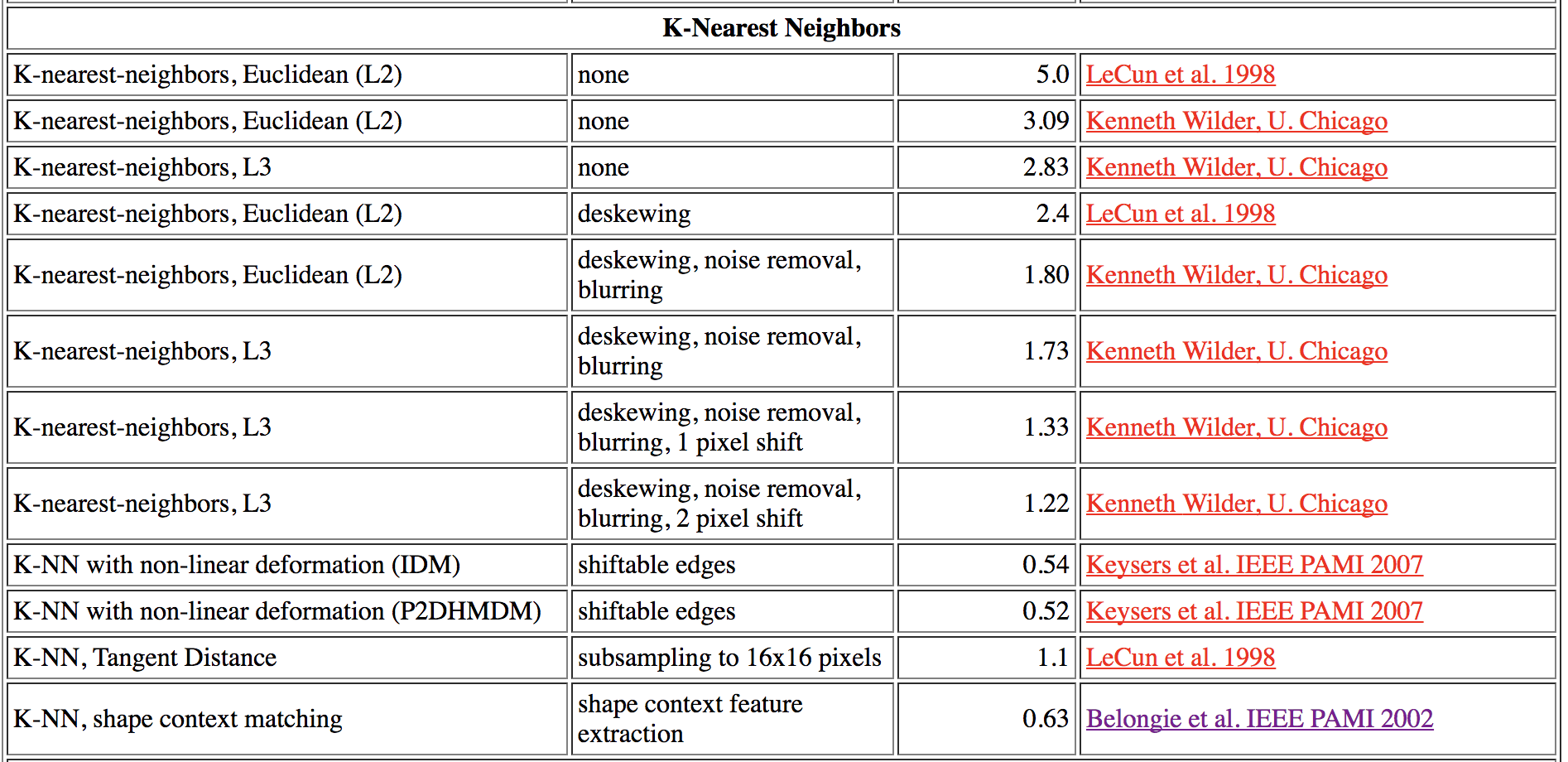
БэИёжаСаГіСЫвЛаЉ k-НќСкЫуЗЈЖд MNIST
Ъ§ОнМЏНјааВтЪдЕФДэЮѓТЪ
ЮвУЧвВгІИУзЂвтЕНЕФЪЧЃЌЮвУЧЕФЫуЗЈдк 8000 ЬѕбЕСЗЪ§ОнМЏКЭ 2000 ЬѕВтЪдЪ§ОнМЏЩЯНјааВтЪдЃЌдЫааСЫ
325 УыЃЁетЪЧвЛИіКмВюЕФНсЙћЁЃдкЪЕМЪЩњВњЛЗОГжаЃЌЮвУЧВЛНігІИУЙизЂзМШЗТЪвВгІИУЙизЂЫуЗЈЕФжДаааЇТЪЁЃ
ЪЙгУЫуЗЈ
жЛвЊВтЪдЕФЫуЗЈаЇЙћЗћКЯдЄЦкЃЌЮвУЧОЭПЩвдНЋЫуЗЈВПЪ№ЕНЩњВњЛЗОГНјааЪЙгУСЫЁЃЮвУЧПЩвдНЋЫуЗЈКЭЪжаДЪЖБ№ГЬађНсКЯЦ№РДЃЌЭъГЩвЛећЬзЛёШЁЪфШы
-> ЫуЗЈдЄВт -> ЪфГіНсЙћЕФСїГЬЃКЪзЯШЪжаДЪЖБ№ГЬађНЋгУЛЇЪфШыЕФЭМЯёзЊЛЛЮЊЮвУЧЦкЭћЕФЪ§ОнИёЪНЃЌШЛКѓжДааЮвУЧЕФЫуЗЈЛёШЁдЄВтЕФЗжРрЁЃДњТыПЩФмЪЧетбљЃК
// ЪжаДЪЖБ№ГЬађНЋгУЛЇЪфШыЕФЭМЯёзЊЛЛЮЊЮвУЧЦкЭћЕФЪ§ОнИёЪН
const input = [0, 0.3, 1, 1, 0, 0, 0.2, ...];
// жДааЫуЗЈ
classify(input, trainingImages, labels, 3); |
КмвХКЖЃЌдкжДааЫуЗЈЪБЮвУЧЛЙЪЧПДЕНСЫ trainingImages ЕФДцдкЁЃетвтЮЖзХУПДЮдЄВтЮвУЧЕФЛњЦїЖМашвЊИјбЕСЗЪ§ОнзМБИИёЭтЕФДцДЂПеМфЁЃМйЩшбЕСЗЪ§ОнКмДѓЃЈетКмГЃМћЃЉЃЌдђЛсИјЮвУЧЕФЩњВњЛЗОГЛњЦїдьГЩОоДѓЕФФкДцбЙСІЁЃ
УПДЮЕїгУЫуЗЈЛЙашвЊДЋШыбЕСЗЪ§ОнЕФЗНЪНМДРЫЗбДцДЂПеМфвВВЛгХбХЃЌЫќжЛФмзїЮЊЮвУЧЕФЪОР§НјааЪЙгУЁЃ
НјвЛВНЫМПМ
БОЮФЮвУЧЪЙгУ Javascript ЪЕЯжСЫвЛИіЗЧГЃМђЕЅЕФЛњЦїбЇЯАЫуЗЈЃЌВЂгУЦфРДВтЪд MNIST Ъ§ОнМЏЃЌЭъећДњТыЪЕЯждкетИіВжПтжаЁЃетжЛЪЧвЛИіМђЕЅЕФЪОР§ЃЌЕЋДгжаЮвУЧСЫНтЕНСЫЛњЦїбЇЯАЕФЛљБОИХФюКЭНтОіЮЪЬтЕФвЛАуЙ§ГЬЁЃНјвЛВНЫМПМЃЌЩЯУцЕФСїГЬжаУПвЛВНЖМПЩФмБЛгХЛЏЃК
ЖдгкЪжаДзжЃЌЛЙгаУЛгаЦфЫћЕФЪ§ОнБэЪОЗНЪНЃПР§ШчЮвУЧЗЧвЊгУ 0 ЕН 1 ЕФЪ§жЕРДБэЪОЕуЕФКкАзЖШТ№ЃП
бЕСЗЪ§ОнМЏЪЧдНДѓдНКУТ№ЃПР§ШчЮвУЧНЋЪжаДзжЫљгаЕФЬиеїХХСазщКЯ (28^28) ИіЪ§ОнСПзїЮЊбЕСЗЪ§ОнМЏЃЛ
ШчКЮЕїећЫуЗЈВЮЪ§вдЛёЕУзюМбЕФЪевцЃЈзМШЗТЪКЭаЇТЪЃЉЃП |









