| БрМЭЦМі: |
БОЮФРДздгкAI,
Machine Learning,ЛњЦїбЇЯАЪЧШЫЙЄжЧФмЕФвЛИіЗжжЇЃЌжївЊЪЧЭЈЙ§Ъ§Он+ЫуЗЈРДбЕСЗЕУГіФЃаЭЃЌдйгУФЃаЭРДдЄВтЪ§ОнЕФвЛжжММЪѕЁЃ
|
|
ЧАбд
Alpha Goдк16Фъвд4:1ЕФеНМЈДђАмСЫРюЪРЪЏЃЌ17Фъгжвд3:0ЕФеНМЈеНЪЄСЫжаЙњЮЇЦхЬьВХПТНрЃЌетецЪЧПЦММНчеёЗмШЫаФЕФНјВНЁЃАщЫцзХУНЬхЕФДѓСПаћДЋЃЌДЫЪТБфГЩСЫИОШцНджЊЕФДѓЪТМўЁЃДѓМвгжПЊЪММЄСвЕФЬжТлЛњЦїШЫЪВУДЪБКђЛсШЁДњШЫРрЭГжЮЪРНчЕФЮЪЬтЁЃ
ЦфЪЕШЫЙЄжЧФмдкЩЯЪРМЭ5ЁЂ60ФъДњОЭПЊЪМНјШыСЫРэТлбаОПНзЖЮЃЌШЫУЧдкВЛЖЯЬНЫїШЫЙЄжЧФмММЪѕЕФЭЌЪБЃЌвВЕЃгЧЦ№ЛњЦїШЫЛсВЛЛсЬцДњШЫРрЁЃШЛЖјЯжЪЕБШРэЯыВаПсЕФЖрЃЌгЩгкЕБЪБИїжжЬѕМўЕФЯожЦЃЈРэТлЛљДЁЁЂММЪѕЛљДЁЁЂЪ§ОнЛљДЁЁЂгВМўадФмЕШЃЉЃЌШЫЙЄжЧФмЯрЙиЕФЯюФПНјЖШЛКТ§ЃЌвВШБЩйЪЕМЪГЩаЇЃЌбаЗЂзЪН№ЁЂЩчЛсЙизЂЖШвВдНРДдНЕЭЃЌШЫЙЄжЧФмНјШыЕквЛДЮЕЭЙШЦкЁЃ
ЕНСЫ80ФъДњЃЌПЈФкЛљУЗТЁДѓбЇЮЊЪ§зжЩшБИЙЋЫОЩшМЦСЫвЛЬзУћЮЊXCONЕФЁАзЈМвЯЕЭГЁБЁЃетЪЧвЛжжЃЌВЩгУШЫЙЄжЧФмГЬађЕФЯЕЭГЃЌПЩвдМђЕЅЕФРэНтЮЊЁАжЊЪЖПт+ЭЦРэЛњЁБЕФзщКЯЃЌXCONЪЧвЛЬзОпгаЭъећзЈвЕжЊЪЖКЭОбщЕФМЦЫуЛњжЧФмЯЕЭГЁЃШЫЙЄжЧФмдйвЛДЮБЛИїЙњеўИЎКЭПЦбаЛњЙЙПДКУЃЌДѓСПЕФзЪН№ЭЖШыЕНбаЗЂжаЃЌЕЋЪЧКУОАВЛГЄЃЌМИФъКѓЫцзХЦЛЙћКЭIBMЙЋЫОбаЗЂГіСЫадФмЧПОЂЕФPCЛњЃЌЕМжТЁАзЈМвЯЕЭГЁББфЕУУЛгаОКељСІЃЌШЫЙЄжЧФмЗЂеЙгжвЛДЮНјШыКЎЖЌЁЃ
ЫцКѓШєИЩФъЃЌШЫЙЄжЧФмЕФЗЂеЙЧїгкЦНЮШКЭЕЭЕїЁЃЪБМфРДЕН21ЪРМЭЃЌЫцзХЛЅСЊЭјЕФЦеМАЃЌДѓСПЪ§ОнБЛЛ§РлЯТРДЃЛФІЖћЖЈТЩвЛДЮгжвЛДЮЕФБЛжЄЪЕЃЌМЦЫуЛњгВМўадФмвдМЋПьЕФЫйЖШдкдіГЄЃЛЁАдЦЁБЕФЦеМАЃЌШУЦеЭЈДѓжквВФмЧсЫЩгЕгаЕїЖШДѓСПЫуСІЕФЛњЛсЃЌШЫЙЄжЧФмВЛдйЪЧПЦбЇМвКЭзЈвЕШЫдБдкЪЕбщЪвВХФмбаОПЕФЖЋЮїСЫЁЃЪ§Он+ЫуСІ+взЕУетМИЗНУцЕФвђЫиНсКЯжЎКѓЃЌНЋШЫЙЄжЧФмдйвЛДЮЭЦЯђСЫИпГБЁЃ
ПЩФметвЛВЈШШГБгжЪЧШЫЙЄжЧФмЗЂеЙЪЗЩЯЕФвЛИіВЈЗхЃЌЮДРДШЫЙЄжЧФмЛЙгаКмГЄЕФТЗвЊзпЁЃЕЋФПЧАЕФШЫЙЄжЧФмЗЂеЙвбОЛнМАЕНЩЬвЕСьгђЃЌдкетбљвЛжжММЪѕ+ЩЬвЕЕФНсКЯжаЃЌЮвИіШЫЛЙЪЧКмПДКУетДЮРЫГБЕФЁЃгШЦфЪЧдкПДЙ§ЁЖзюЧПДѓФдЁЗжаЃЌАйЖШдкЭМЯёЁЂвєЦЕЗНУцЕФШЫЙЄжЧФмММЪѕЗЂеЙЕНетбљвЛИіЫЎЦНжЎКѓЃЈЭМЯёЪЖБ№вбОГЌГЌдНСЫШЫРрДѓФдЖдЭМЯёЕФЪЖБ№ФмСІЃЌЩљвєЪЖБ№вВМИКѕКЭШЫРрзюИпЫЎЦНГжЦНЃЉЃЌКмЯЃЭћздМКвВПЩвдгаЛњЛсЩцзуЕНетИіСьгђжаЁЃ
ЛњЦїбЇЯАЛљДЁШыУХжЊЪЖ
ИеПЊЪМНгДЅЛњЦїбЇЯАЃЌЗЂЯжЛљДЁРэТлжаКУЖрЖМЪЧДѓбЇРябЇЙ§ЕФЪ§РэжЊЪЖЃЈвЛжБвдРДРЇШХЮвЕФЁАДѓбЇЮЊЪВУДвЊбЇетаЉЖЋЮїЁБЕФУеЭХзмЫуБЛНтПЊСЫЃКЃЉЁЃЮвИіШЫзіСЫWebПЊЗЂНќЪЎдиЃЌДѓВПЗжЪЧгІгУМЖЕФЃЌКмЩйЩцМАЪ§РэЫуЗЈЃЌПДРДНёКѓЛЙвЊТ§Т§ЪАЦ№етаЉжЊЪЖЁЃВЛЙ§ИеПЊЪМШыУХПЩвдбађНЅНјЃЌЯШХЊЖЎЛњЦїбЇЯАЪЧдѕУДЛиЪТЃЌЖЏЪжзівЛИіЁАHello
worldЁБЃЌШЛКѓдйж№ВНЩюШыдРэВуУцЕФжЊЪЖЁЃ
вЊЩцзуЛњЦїбЇЯАЃЌзюКУЛсвЛжжБрГЬгябдЃЌетЕуЩЯЮвУЧГЬађдБгаЯШЬьгХЪЦЁЃФПЧАгУгкЛњЦїбЇЯАЕФжїСїгябдЪЧPythonКЭRЃЌRЮвИіШЫЛЙУЛбаОПЙ§ЃЌИіШЫОѕЕУPythonЪЧвЛИіБШНЯКУЕФбЁдёЃЌСїааЖШИпЁЂЩЯЪжФбЖШЕЭЁЂПЦбЇМЦЫуРрПтЗсИЛЁЂгяЗЈОЋМђЃЌШчЙћБОЩэОЭгаЦфЫћУцЯђЖдЯѓЕФБрГЬгябдЛљДЁЃЌВЛЕНвЛжмОЭПЩвдЛљБОеЦЮеPythonСЫЁЃ
ЛњЦїбЇЯАДгДгвЕЗжВМРДПДЃЌПЩвдЗжГЩЛљДЁЫуЗЈбаОПЃЈЩшМЦЪІЃЉКЭгІЃЈbanЃЉгУЃЈzhuanЃЉСНИіСьгђЃЌЦфжаДѓВПЗжШЫЖМЪЧдкгІЃЈbanЃЉгУЃЈzhuanЃЉетИіСьгђЁЃ
ШчЙћДгММЪѕВуУцРДПДЃЌЛњЦїбЇЯАЗжГЩМрЖНбЇЯАЁЂЮоМрЖНбЇЯАвдМААыМрЖНбЇЯАЁЃШчКЮРДЧјЗжФиЃПЪзЯШНтЪЭЯТЛњЦїбЇЯАжаЕФМИИіУћДЪЁЃ
1.ЬиадЃЈFeaturesЃЉ - ЦфЪЕОЭЪЧЪ§Он
2.ЗжРрЦїЃЈClassifierЃЉ - ЦфЪЕОЭЪЧЫуЗЈ
3.БъЧЉЃЈLabelsЃЉ - ЦфЪЕОЭЪЧжжРр
4.ФЃаЭ(Models) - ЦфЪЕОЭЪЧзюжеЪфГіЕФЗжРрЙЋЪН
МрЖНбЇЯАЃЌОЭЪЧдкгаБъЧЉЕФЧАЬсЯТЃЌевЕНвЛжжзюКЯЪЪЕФЗжРрЦїЃЌЗжЮіЬиадКЭБъЧЉжЎМфЕФЙиЯЕЁЃ
ЮоМрЖНбЇЯАЃЌОЭЪЧУЛгаБъЧЉЕФЧАЬсЯТЃЌНЋЪ§ОнНјааОлРр(Clusting)ЁЃ
АыМрЖНбЇЯАЃЌОЭЪЧВПЗжЬиадгаБъЧЉЃЌВПЗждђУЛгаЕФзДПіЃЈДѓВПЗжЬиадПЩФмЪЧУЛгаБъЧЉЕФЧщПіЃЉЯТНјааЗжРрЁЃ
МрЖНбЇЯАЯрЖдРДЫЕзюМђЕЅЃЌгЩвбжЊЬиадКЭБъЧЉЃЌРћгУКЯЪЪЕФЗжРрЦїбЕСЗГіФЃаЭЃЌдйвдФЃаЭЬзгУЕНЪ§ОнжаРДдЄВтГіЪ§ОнЕФБъЧЉЁЃЕБШЛЃЌЗжРрЦїВЂВЛашвЊЮвУЧздМКРДЗЂУїДДдьЃЌЮвУЧДѓВПЗжШЫвВУЛетИіФмСІзіетаЉЪТЧщЃЌЫљгаЕФРэТлбаОПЁЂПЦбЇТлжЄЁЂДњТыЪЕЯжЖМЪЧЯжГЩЕФЁЃPythonжагаКмЖрЯрЙиРрПтЃЌБШШчscikit-learnЁЃгІгУВуУцЕФЛњЦїбЇЯАЃЌЦфЪЕОЭЪЧЭЈЙ§ВЛЭЃЕФЕїВЮЃЈЪеМЏИќЖрЕФЪ§ОнЁЂБфЛЛЫуЗЈЁЂбЁШЁКЯЪЪЕФЬиеїЪ§ОнЕШЙЄзїЃЉРДевЕНвЛжжИќОЋзМЕФдЄВтФЃаЭЕФЙЄзїЁЃ
Hello World In Machine Learning
МйЩшЮвУЧЯждкашвЊЧјЗжЦЄЧђЃЈвджБОЖ15cm-25cmжЎМфЕФЧђЮЊР§ЃЉКЭЬ№ЙЯЕФЭМЦЌЃЌШчЙћЪЧДЋЭГЕФгВБрТыЕФЗНЪНРДаДДњТыЕФЛАЃЌПЩФмашвЊаДМИАйЩЯЧЇИіif-elseВХФмЭъГЩвЛИіЛљБОЕФЫуЗЈЃЌЖјЧвПЩРЉеЙадЬиБ№ВюЃЌБШШчШчЙћЭМЦЌЪЧКкАзЕФЛђепЭМЦЌжагаИЩШХЮяЦЗЃЌФЧПЩФмашвЊаоИФдДДњТыЃЌЬэМгИќЖрЕФif-elseРДдіМгзМШЗЖШЁЃИќдуЕФЪЧЃЌеце§жДааЕФЪБКђЛсгіЕНКмЖрЪТЯШУЛгадЄСЯЕНЕФЬиЪтЧщПіЁЃ
ЕЋШчЙћЭЈЙ§ЛњЦїбЇЯАЃЌетИіЪТЧщПЩФмОЭЛсБфЕУКмМђЕЅЁЃДѓжТВНжшШчЯТЃК
1.НЋЭМЦЌзЊЛЛГЩЬиеїЯђСПЃЈетИіНјНзжЊЪЖВЛдкБОЦЊжаЩцМАЃЉ
2.ОіЖЈвЛжжКЯЪЪЕБЧАГЁОАЕФЗжРрЦї
3.НсКЯ1жаЕУЕНЕФЬиеїКЭ2жаЕУЕНЕФЗжРрЦїбЕСЗГіФЃаЭ
4.гУФЃаЭжаЕФЙЋЪНдЄВтЪ§ОнЃЌЙРЫуГіЦфЪєгкФГИіБъЧЉЕФПЩФмадЃЌзюДѓПЩФмадЕФФЧИіМДФЃаЭЭЦЫуГіЕФНсЙћ
Ъ§ОнзМБИ
зЊЛЛЙ§ГЬТдЃЌМйЩшЙВNЬѕЪ§ОнЃЌзЊЛЛЕУЕНЕФЬиадШчЯТЃК
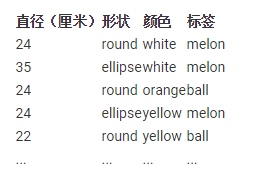
ЪЕЯжДњТы
| features
= [
[24, 'round', 'white'],
[35, 'ellipse', 'white'],
[24, 'round', 'orange'],
[24, 'ellipse', 'yellow'],
[22, 'round', 'yellow'],
...
]
labels = ['melon', 'melon', 'ball', 'melon',
'ball']
|
ЮвУЧжЊЕРЃЌМЦЫуЛњДІРэЛљДЁЪ§ОнРраЭЕФЫйЖШЃЌгЩПьМАТ§ЮЊЃКboolЁЂintЁЂfloatЁЂstring...ЃЌвђДЫЃЌЮвУЧдкДІРэЪ§ОнЕФЙ§ГЬжаЃЌашвЊАбдЪМЪ§ОнГщЯѓГЩМЦЫуЛњФмзюПьДІРэЕФЪ§ОнРраЭЃЈвђЮЊЛњЦїбЇЯАдЫЫуСПМЋДѓЃЉЁЃвђДЫЩЯУцЕФДњТыОЙ§зЊЛЛжЎКѓЃК
| #
round:1, ellipse:2
# white:1, orange:2, yellow: 3
features = [[24, 1, 1], [35, 2, 1], [24, 1,
2], [24, 2, 3], [22, 1, 3]]
# melon:1, ball: 2
labels = [1, 1, 2, 1, 2] |
етРяЫГБуЬсвЛЯТЃЌДѓВПЗжЛњЦїбЇЯАжаЃЌЖМЪЧвдGPUЕФадФмРДКтСПДІРэЫйЖШЕФЃЌЖјВЛЪЧЮвУЧвЛАуЪЙгУЕФCPUЃЌетЪЧвђЮЊGPUЕФЮяРэМмЙЙКЭCPUВЛвЛбљЃЌGPUЪЧзЈУХЮЊСЫДІРэЭМЯёЖјЩшМЦЕФЃЌЫќЖдИЁЕуЪ§ЕФДІРэЫйЖШЪЧCPUЕФЪ§ЪЎБЖФЫжСЪ§АйБЖЁЃЖјЛњЦїбЇЯАЛљБОЩЯПЩвдПДзіЪЧЖдИЁЕуЪ§ЕФДѓСПдЫЫуЃЌвђДЫGPUИќЪЪКЯдкЛњЦїбЇЯАСьгђБЛЪЙгУЁЃ
ЫуЗЈбЁШЁ
ЛњЦїбЇЯАжаЃЌНтОівЛИіЮЪЬтЕФЫуЗЈВЂВЛЪЧЮЈвЛЕФЃЌЭЌвЛИіЮЪЬтПЩвдЪЪгУВЛЭЌЕФЫуЗЈРДНтОіЃЌвЛАуЖМЛсдкаЇТЪКЭзМШЗТЪжЎМфзіШЈКтЁЃБОР§жаЮвУЧЪЙгУОіВпЪї(Deccision
Tree)зїЮЊClassifierЃЌЙигкОіВпЪїЃЌПЩВЮПМhttps://baike.baidu.com/item/%E5%86%B3%E7%AD%96%E6%A0%91ЁЃ
ЪЕЯжДњТы
| from
sklearn import tree
...
# ЪЕР§ЛЏclassifier
clf = tree.DecisionTreeClassifier() |
бЕСЗФЃаЭ
scikit-learnЕФclassifierжаЭЈЙ§ЗНЗЈfit(features, labels)РДбЕСЗФЃаЭЁЃЦфЗЕЛижЕМДЮвУЧЫљашЕФФЃаЭЁЃ
ЪЕЯжДњТы
| ...
clf = tree.fit(features, labels)
... |
дЄВтЪ§Он
гаСЫФЃаЭЃЌЮвУЧОЭПЩвдЖдНёКѓЕФЪ§ОнНјаадЄВтЃЌвдЕУГіlabelжЕЃЌДгЖјДяЕНЖдЦфЙщРрЕФФПЕФЁЃ
ЪЕЯжДњТы
| ...
# МйЩшЯждкгавЛИіЪ§Он[23, 'round', 'white']ЃЌЮвУЧЯыжЊЕРЫћгІИУЪ§ОнЪВУДРраЭЃЌЯШНЋЦфзЊЛЛЮЊ[23,
1, 1], ШЛКѓЕїгУФЃаЭЕФpredictЗНЗЈ
print(clf.predict([[23, 1, 1]]))
... |
ЕУЕНЕФНсЙћЮЊЃК
| #
ДњБэЛњЦїбЇЯАВтЫуЕУГіНсЙћЪЧmelon
[1] |
ЭъећДњТы
| from
sklearn import tree
# round:1, ellipse:2
# white:1, orange:2, yellow: 3
features = [[24, 1, 1], [35, 2, 1], [24, 1,
2], [24, 2, 3], [22, 1, 3]]
# melon:1, ball: 2
labels = [1, 1, 2, 1, 2]
# ЪЕР§ЛЏclassifier
clf = tree.DecisionTreeClassifier()
# бЕСЗ
clf = clf.fit(features, labels)
print(clf.predict([[23, 1, 1]]))
|
КѓМЧ
ЩЯР§жаЃЌШчЙћЭЈЙ§еце§ЕФШЫЙЄжЧФмШтблРДПДЃЌ[23, 'round', 'white']БЛЭЦЫуЮЊmelonЕФзМШЗЖШЦфЪЕВЂВЛИпЃЌвђЮЊ[23,
'round', 'white']ЙщРрЮЊballвВЭъШЋЪЧПЩвдЕФЁЃЩЯЮФЬсЕНЙ§ЃЌЛњЦїбЇЯАЦфЪЕОЭЪЧВЛЭЃЕФбАевКЯЪЪЕФЪ§ОнКЭЫуЗЈвдЬсЩ§зМШЗТЪЕФЙ§ГЬЁЃЯывЊЬсЩ§зМШЗТЪЃЌЮвУЧПЩвдгавдЯТЫМТЗЃК
1.МгДѓбЕСЗбљБОСПЃЈбЕСЗбљБОБиаыКЭбЕСЗаЇТЪзіКУШЈКтЃЌСэЭтЃЌзюКУБмУтжиИДЕФЬиадРЫЗбЫуСІЃЌБШШчгаСЫжБОЖетСаЃЌОЭВЛашвЊАыОЖЁЂжмГЄетбљЕФЬиадСЫЃЌетШ§епДњБэЕФЪЧвЛИівтЫМЃЉ
2.БфЛЛЫуЗЈЃЈПЩвдбЁгУИќИпМЖЕФЫуЗЈЛђепЖрИіЫуЗЈзщКЯЃЌЕЋБиаыдкзМШЗЖШКЭаЇТЪжЎМфзіКУШЈКтЃЉ
3.ГщЯѓГіИќЖрЕФЬиадЪ§ОнЃЈБШШчБОР§жаЃЌШчЙћгаАьЗЈГщЯѓГіжЪСПетбљЕФЬиадЃЌФЧЖдгкдЄВтзМШЗТЪЛсгаМЋДѓЕФЬсЩ§ЃЉ
жСДЫЮЊжЙЃЌЮвУЧЛњЦїбЇЯАЕФHello WorldГЬађвбОЭъГЩСЫЃЌвВЛљБОСЫНтСЫЛњЦїбЇЯАЪЧдѕУДЛиЪТЃЌЪЧВЛЪЧЛЙЭІгавтЫМЕФЃП |









