| 编辑推荐: |
本文来自于微信号rgznai100,这份指导包含了具体的学习思路,包括所遇到的难点以及多种详细的解决方法。
|
|
人工神经网络当下非常流行。与任何流行的事物一样,人工神经网络也收到了不少质疑。它究竟是卖弄玄虚,还是真正可以使无数人获益的新技术呢?
为了让大家入门神经网络,我从一个并不太了解的专业数据科学家的角度,和大家分享我的学习过程,希望对你们有所帮助。
需要注意的是,本文中所涉及的示例都是用R语言写的代码。
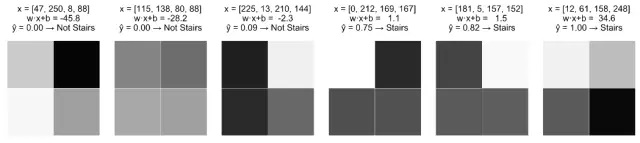
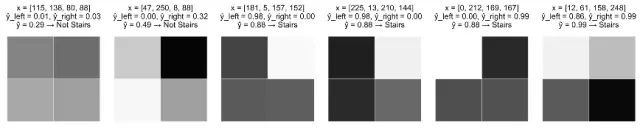
让我们从一个动机问题开始思考。这里是一个灰度图片的集合,每个2×2的像素网格的像素取值都是在0(白)到255(黑)之间。我们的目标是构建一个模型,用“阶梯”的模式来识别图片。

在这里,我们来探讨如何找到一个能够合理拟合数据的模型感兴趣。
方法一:预处理
对每张图片,我们标记像素X1,X2,X3,X4 , 并生成一个输入向量X=[X1 X2 X3 X4],作为我们模型的输入值。我们希望我们的模型能够预测“True”(图像具有阶梯模式)或为“False”(图像不具有阶梯模式)。

方法二:单层感知器(模型迭代0次)
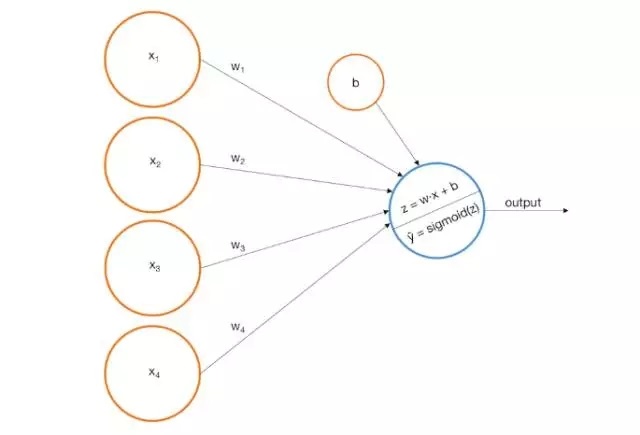
单层感知器是我们可以构建的一个简单模型。当一个感知器使用线性权重组合的输入时,可以得到一个预测值。如果预测的数值超过所选用的阈值,感知器则会判定为“True”,否则判定为“False”。更具体的说,

我们可以将它重新表示为如下形式:
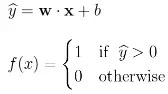
这里表示预测值。
图形上,我们可以将感知器表示为一个由输入到输出的节点。
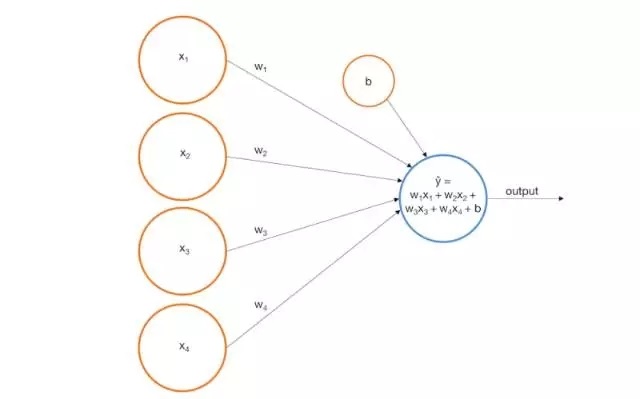
例如,我们假定构建如下的感知器:
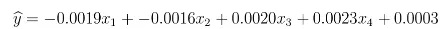
这里可以看到感知器是如何在我们的训练图像上执行的。
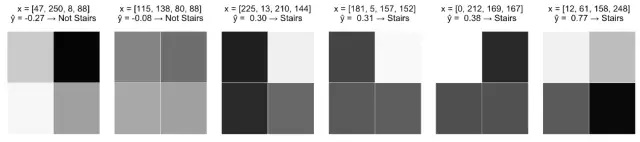
这是合理的结果,肯定优于随机猜测的效果。所有的阶梯模式在其底部都有带有深色阴影的像素,能支持X3和X4采用更大的正系数。尽管如此,这个模型还是存在一些明显的问题。
该模型输出一个实数,它的值与自然的概念相关(值越大隐含着有更大的可能性说明图像表现为阶梯模式),但是将这些值解释为概率值是没有依据的,特别当它们的取值范围在[0,1]之外。
该模型无法捕捉到变量之间非线性的关系。
为了解这个问题,可以考虑以下的假设情况:
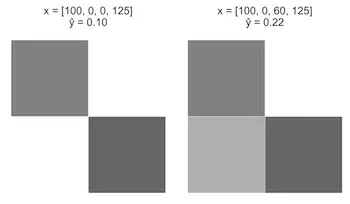
情况A:从一张图像开始,x = [100, 0, 0, 125],从0增至60.
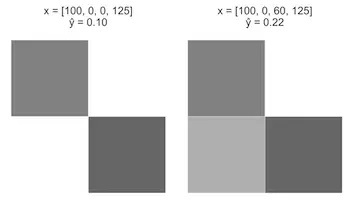
情况B:从最后一张图像开始,x = [100, 0, 60, 125],从60增至120.

直观上,相对于情况B来说,情况A的应该会有更大的增幅。然而,由于我们感知器模型只是一个线性等式,对于这两种情况,X3增加了60,而只增加了0.12。
同时,我们的线性感知器还会有更多的问题,但是我们先来解决这两个问题。
问题一:以Sigmoid为激活函数的单层感知器(模型迭代1次):
我们可以通过将我们的感知器包在Sigmoid函数里面(随后选择不同的权重值)来解决上述的问题1和2。回顾下Sigmoid函数是一条垂直方向上界定在0到1之间的S型曲线,因此经常被用来模拟二元事件发生的概率。

顺着这个思路,我们用下面的图片和方程式来更新我们的模型。
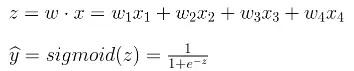
这就是Logistic回归。然而,将这个模型解释为以Sigmoid为激活函数的线性感知器也是很好的,因为这给了我们更多的空间去泛化。此外,由于我们将解释为概率值,所以我们必须相应地更新我们的决策规则。

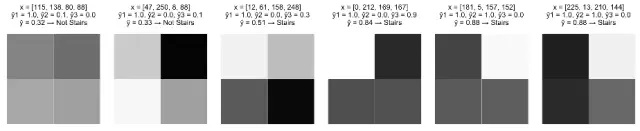
问题二:假定我们提出以下的拟合模型:

对比先前的部分,可以看出这个模型在相同的图像上是如何起作用的。
解决方法:
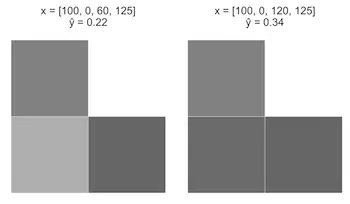
情况A:从一张图像开始,x = [100, 0, 0, 125],从0增至60.
情况B:从最后一张图像开始,x = [100, 0, 60, 125],从60增至120.
请注意,随着的增加,Sigmoid函数是如何引起情况A的“触发”现象(快速增加),但随着z的持续增加,速度会减慢。这与我们的直觉是相一致的,即对于出现阶梯的可能性,情况A应该反映出比情况B更大的增长。
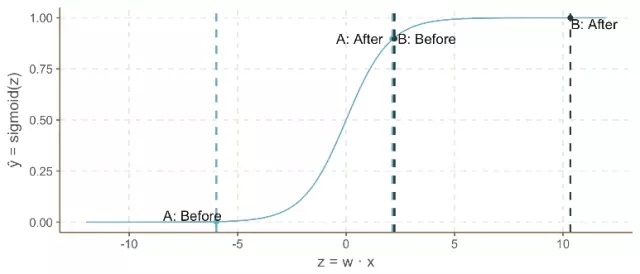
不幸的是,这个模型仍然存在问题:
与每个变量都有单调的关系。如果我们想识别轻微的阴影阶梯,那该怎么办?
该模型不考虑变量的交互问题。假设图像的底部是黑色的,如果左上角的像素是白色,则右上角的像素变暗会增加阶梯出现的可能性。如果左上角的像素是黑色的,则右上角的像素变暗会降低阶梯出现的可能性。换句话说,就是根据其他变量的值,增加X3应该可能增加或减少的值。目前我们的模型还无法实现这一点。
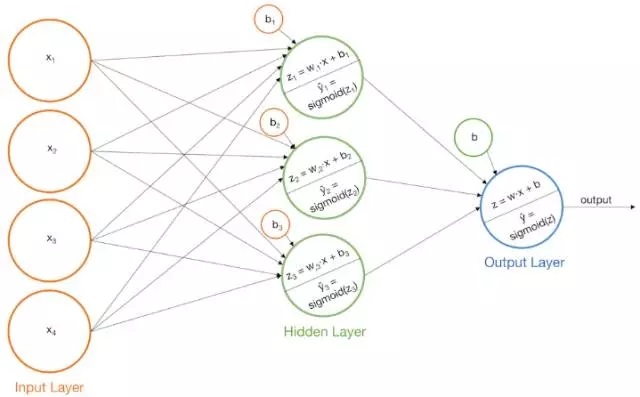
问题三:以Sigmoid为激活函数的单层感知器(模型迭代2次):
我们可以通过在我们感知器模型上额外增加一个层来解决上述的两个问题。我们将以上面的模型为基础构建一系列基本模型,然后将每个基本模型的输出作为输入提供给另一个感知器。这个模型实际上就是一个
“香草型”的神经网络。让我们通过一些例子看看它是如何工作。
例子1:识别阶梯模式
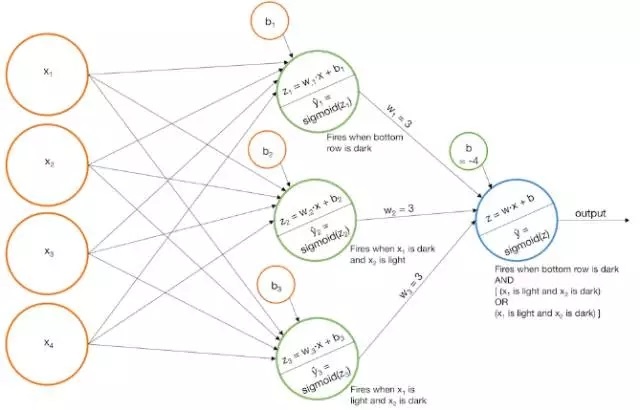
构建一个模型,当左阶梯模式被识别时触发,
构建一个模型,当右阶梯模式被识别时触发,
增大每个基础模型的得分,以便最后的S型函数只有在和都很大时才会被触发。

或者
构建一个模型,当底部为暗色时才触发,
构建一个模型,当左上角像素为暗色且右上角像素为亮色时才触发,
构建一个模型,当左上角像素为亮色且右上角像素为暗色时才触发,
增大基础模型以便最后的sigmoid函数只有在和都很大,或者和都很大时才触发(请注意和无法同时有很大的值)。
例子2:识别带轻微阴影的阶梯
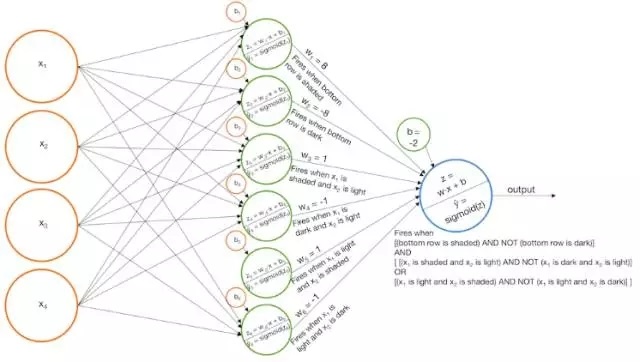
构建一个模型,当底部为阴影,阴影x1和白色x2,阴影x2和白色x1时才被触发,,和
构建一个模型,当底部为暗色,暗色x1和白色x2,暗色x2和白色x1时才被触发, ,和
将模型组合起来以便在使用sigmoid函数压缩之前, “暗色”的标识符能够基本上从 “阴影”标识符中除去。

专业术语注释
单层感知器具有单个的输出层。因此,我们刚刚构建的模型将被称为双层感知器,因为模型的一个输出层,是另一个输出层的输入。然而,我们可以将这些模型称为神经网络,就这方面而言,网络有三层--输入层,隐藏层和输出层。
可替代的激活函数
在我们的例子中,我们使用了一个sigmoid作为激活函数。但是,我们可以使用其他的激活函数。双曲正切函数、
修正线性单元都是常用的选择。激活函数必须是非线性的,否则神经网络将等价于单层的感知器。
多目标分类
通过在最终输出层中使用多个节点,我们可以轻松地将我们的模型扩展成多分类模型。这里用到的想法是,每个输出对应于我们想要预测的类别之一C,我们可以使用Softmax函数将空间中的一个向量映射到中的另一个向量,如此使得向量的元素之和为1,而不是通过sigmoid函数映射空间的一个输出元素并将其压缩在[0,1]之间输出。换句话说,我们可以设计一个网络使得它的输出向量是如此的形式:。
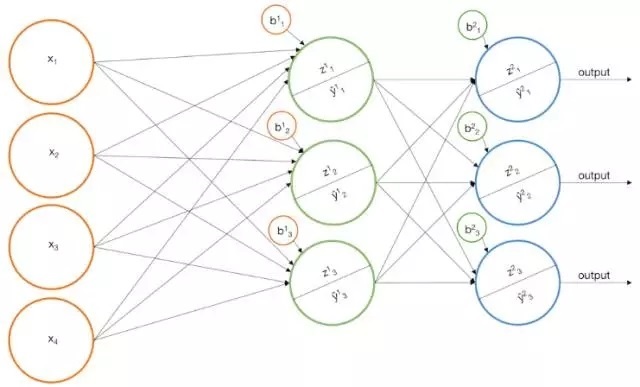
使用不止两层的神经网络,即深度学习
你可能想知道,我们是否可以扩展我们的香草式神经网络,使得其输出层被输入到第四层(进而第五层,第六层等等)?
是这样的,这就是通常所说的“深度学习”。实践中,它非常高效。但是值得注意的是,任何一个隐藏层都可以通过一个单隐藏层的网络来模拟。实际上,根据通用逼近定理,可以使用具有单个隐藏层的神经网络来逼近任何连续的函数。
深层神经网络架构经常选择偏向于单个隐层结构的原因就在于,他们更倾向于在拟合过程中更快速地收敛并得到最终的结果。

用模型去拟合带标签的训练样本 (反向传播法)
在拟合阶段,到目前为止,我们已经讨论了神经网络如何能够有效地工作,但是我们还没有讨论如何用神经网络去拟合带标签的训练样本。
一个等价的问题就是:给定一些带标签的训练样本,我们该如何选择网络的最佳权重值?
对此,梯度下降法是常见的答案(尽管用最大似然估量法也可以做到)。
下面继续我们的示例问题,梯度下降的过程会像这样:
以一些带标签的训练数据开始
选择一个可微的损失函数并最小化,
选择一个网络结构。具体地说就是确定网络的层数以及每层的节点数
随机地初始化网络权重
用网络运行训练数据来生成每个样本的预测值。根据损失函数来度量总体的误差值(这就是所谓的前向传播过程)。
当每个权重发生小的变化,确定当前的损失值将改变多少。换句话说,计算L对于网络中每个权重的梯度值(这就是所谓的后向传播过程)。
沿负梯度的方向走一小步。例如,,,那么小幅度的减少会导致当前损失小幅度的降低。因此我们更新(这里0.001就是我们所预定义的步长)。
以固定的次数重复进行这个过程(从步骤5开始),直至损失函数收敛为止。
这些是最基本的想法。实际中,这面临了一系列的困难:
挑战一: 计算复杂度
在拟合的过程中,我们需要计算的一个东西是L对于每个权重的梯度值。这是个棘手的问题,因为L依赖于输出层中的每个节点,并且每个节点依赖于之前的层中的每个节点,以此类推。这就意味着计算是一个链式规则的噩梦(请记住,实际上许多神经网络都有数十层数千个节点)。
我归纳了解决这个噩梦的四个技巧。
处理这个问题的关键是要认识到,在应用链式规则的时候,将重用相同中间层的导数值。
如果你仔细追踪这个的话,你就可以避免重新计算相同的东西几千次。
另一个技巧就是使用特殊的激活函数,其衍生物可以写成他们值的函数。例如,=的导数。这是很方便的,因为在正向传播过程中,当我们计算每个训练样本时,我们必须为某个向量x逐元素地计算。
在反向传播过程中,我们可以在计算L相对于权重的梯度时重用这些值,从而节省时间和内存的占用。
第三个技巧就是将训练数据分成“小批量”,并逐一更新每个批次的权重。例如,如果将训练数据划分为{batch1,batch2,batch3},则训练数据首先将
使用batch1更新权重值
使用batch2更新权重值
使用batch3更新权重值
这里,L的梯度将在每次更新后重复地计算。
最后的一个值得注意的技巧就是使用GPU而不是CPU,因为GPU更适合并行地执行大量的计算。
挑战二:梯度下降法可能会无法找到绝对最小值点
这不仅仅是一个神经网络的问题,因为它也是一个梯度下降问题。在梯度下降的过程中,权重可能会陷入局部最小值。权重也可能超过最小值。
处理这个问题的一个技巧就是调整不同的步长。
另一个技巧就是增加网络中的节点数或网络层数(注意过拟合现象)。
此外,一些像使用动量的启发式技巧也可能有效。
挑战三: 如何泛化?
我们如何编写一个通用的程序来拟合任何数量的节点和网络层的神经网络呢?
答案是, 你不用这样做,你是用Tensorflow。但是,如果你真的想这么做的话,最困难的部分就是计算损失函数的梯度。
这么做的技巧就是意识到你可以把梯度表示为一个递归函数。5层的神经网络只是一个4层带一些感知器的神经网络,而4层的神经网络只是一个3层带一些感知器的神经网络。诸如此类。更正式的说,这称为自动分化。 |









