| БрМЭЦМі: |
БОЮФРДздгкppvke.com
ЃЌБОЮФНщЩмСЫЙњФкЭтДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФЛљБОИХФюЁЂЛљБОбаОПЮЪЬтЁЂММЪѕЬиеїЁЂЯЕЭГЗжРрвдМАЕфаЭЯЕЭГЁЃ
|
|

вЊЪЕЯжИпаЇЕФДѓЪ§ОнЛњЦїбЇЯАЃЌашвЊЙЙНЈвЛИіФмЭЌЪБжЇГжЛњЦїбЇЯАЫуЗЈЩшМЦКЭДѓЙцФЃЪ§ОнДІРэЕФвЛЬхЛЏДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃбаОПЩшМЦИпаЇЁЂПЩРЉеЙЧввзгкЪЙгУЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГУцСйжюЖрММЪѕЬєеНЁЃНќФъРДЃЌДѓЪ§ОнРЫГБЕФаЫЦ№ЃЌЭЦЖЏСЫДѓЪ§ОнЛњЦїбЇЯАЕФбИУЭЗЂеЙЃЌЪЙДѓЪ§ОнЛњЦїбЇЯАЯЕЭГГЩЮЊДѓЪ§ОнСьгђЕФвЛИіШШЕубаОПЮЪЬтЁЃНщЩмСЫЙњФкЭтДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФЛљБОИХФюЁЂЛљБОбаОПЮЪЬтЁЂММЪѕЬиеїЁЂЯЕЭГЗжРрвдМАЕфаЭЯЕЭГЃЛдкДЫЛљДЁЩЯЃЌНјвЛВННщЩмСЫБОЪЕбщЪвбаОПЩшМЦЕФвЛИіПчЦНЬЈЭГвЛДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЊЁЊOctopusЃЈДѓеТгуЃЉЁЃ
1 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГбаОПБГОА
НќФъРДЃЌДѓЪ§ОнММЪѕдкШЋЧђЗЂеЙбИУЭЃЌЯЦЦ№СЫОоДѓЕФбаОПШШГБЃЌв§Ц№ШЋЧђвЕНчЁЂбЇЪѕНчКЭИїЙњеўИЎЕФИпЖШЙизЂЁЃЫцзХМЦЫуЛњКЭаХЯЂММЪѕЕФбИУЭЗЂеЙКЭЦеМАгІгУЃЌаавЕгІгУЪ§ОнГЪБЌеЈаддіГЄЁЃЖЏщќДяЕНЪ§АйTBЩѕжСЪ§PBЙцФЃЕФаавЕ/ЦѓвЕДѓЪ§ОнвбОдЖдЖГЌГіСЫДЋЭГМЦЫуММЪѕКЭаХЯЂЯЕЭГЕФДІРэФмСІЁЃгыДЫЭЌЪБЃЌДѓЪ§ОнЭљЭљвўКЌзХКмЖрдкаЁЪ§ОнСПЪБВЛОпБИЕФЩюЖШжЊЪЖКЭМлжЕЃЌДѓЪ§ОнжЧФмЛЏЗжЮіЭкОђНЋЮЊаавЕ/ЦѓвЕДјРДОоДѓЕФЩЬвЕМлжЕЃЌЪЕЯжЖржжИпИНМгжЕЕФдіжЕЗўЮёЃЌДгЖјЬсЩ§аавЕ/ЦѓвЕЩњВњЙмРэОіВпЫЎЦНКЭОМУаЇвцЁЃ
ДѓЪ§ОнЗжЮіЭкОђДІРэжївЊЗжЮЊМђЕЅЗжЮіКЭжЧФмЛЏИДдгЗжЮіСНДѓРрЁЃМђЕЅЗжЮіжївЊВЩгУРрЫЦгкДЋЭГЪ§ОнПтOLAPЕФДІРэММЪѕКЭЗНЗЈЃЌгУSQLЭъГЩИїжжГЃЙцЕФВщбЏЭГМЦЗжЮіЃЛЖјДѓЪ§ОнЕФЩюЖШМлжЕНіЭЈЙ§МђЕЅЗжЮіЪЧФбвдЗЂЯжЕФЃЌЭЈГЃашвЊЪЙгУЛљгкЛњЦїбЇЯАКЭЪ§ОнЭкОђЕФжЧФмЛЏИДдгЗжЮіВХФмЪЕЯжЁЃ
ЛњЦїбЇЯАКЭЪ§ОнЗжЮіЪЧНЋДѓЪ§ОнзЊЛЛГЩгагУжЊЪЖЕФЙиМќММЪѕЃЌВЂЧвгабаОПБэУїЃЌдкКмЖрЧщПіЯТЃЌДІРэЕФЪ§ОнЙцФЃдНДѓЃЌЛњЦїбЇЯАФЃаЭЕФаЇЙћЛсдНКУ[1~3]ЁЃФПЧАЃЌЙњФкЭтвЕНчКЭбЇЪѕНчзЈМвЦеБщШЯЭЌЕФЙлЕуЪЧЃЌдНРДдНЖрЕФКЃСПЪ§ОнзЪдДМгЩЯдНРДдНЧПДѓЕФМЦЫуФмСІЃЌвбОГЩЮЊЭЦЖЏДѓЪ§ОнЪБДњШЫЙЄжЧФмММЪѕКЭгІгУЗЂеЙЕФЖЏСІЃЌНЋЛљгкДѓЪ§ОнЕФЛњЦїбЇЯАКЭШЫЙЄжЧФмЭЦЩЯСЫаТвЛТжЗЂеЙРЫГБЃЌШУДѓЪ§ОнЛњЦїбЇЯАЃЈbigdata
machine learningЃЉГЩЮЊШЋЧђвЕНчКЭбЇЪѕНчИпЖШЙизЂЕФШШЕубаОПСьгђЁЃЫцзХДѓЪ§ОнЪБДњЕФРДСйЃЌGoogleЁЂFacebookЁЂЮЂШэЁЂАйЖШЁЂЬкбЖЕШЙњФкЭтжјУћЦѓвЕОљЗзЗзГЩСЂзЈУХЕФЛљгкДѓЪ§ОнЕФЛњЦїбЇЯАгыШЫЙЄжЧФмбаЗЂЛњЙЙЃЌЩюШыЯЕЭГЕибаОПЛљгкДѓЪ§ОнЕФЛњЦїбЇЯАКЭжЧФмЛЏМЦЫуММЪѕЁЃ
гЩгкДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЭкОђЕШжЧФмМЦЫуММЪѕдкДѓЪ§ОнжЧФмЛЏЗжЮіДІРэгІгУжаОпгаМЋЦфживЊЕФзїгУЃЌдк2014Фъ12дТжаЙњМЦЫуЛњбЇЛсЃЈCCFЃЉДѓЪ§ОнзЈМвЮЏдБЛсЩЯАйЮЛДѓЪ§ОнЯрЙиСьгђбЇепКЭММЪѕзЈМвЭЖЦБЭЦбЁГіЕФЁА2015ФъДѓЪ§ОнЪЎДѓШШЕуММЪѕгыЗЂеЙЧїЪЦЁБжаЃЌНсКЯЛњЦїбЇЯАЕШжЧФмМЦЫуММЪѕЕФДѓЪ§ОнЗжЮіММЪѕБЛЭЦбЁЮЊДѓЪ§ОнСьгђЕквЛДѓбаОПШШЕуКЭЗЂеЙЧїЪЦ[4]ЁЃ
гЩгкДѓЪ§ОнЛњЦїбЇЯАдкОпЬхЪЕЯжЪБЭЈГЃашвЊЪЙгУЗжВМЪНКЭВЂааЛЏДѓЪ§ОнДІРэММЪѕЗНЗЈЃЌвВгаШЫНЋДѓЪ§ОнЛњЦїбЇЯАГЦЮЊЁАЗжВМЪНЛњЦїбЇЯАЁБЃЈdistributedmachine
learningЃЉЛђЁАДѓЙцФЃЛњЦїбЇЯАЁБЃЈlarge-scale machine learningЃЉЁЃ
ДѓЪ§ОнЛњЦїбЇЯАЃЌВЛНіЪЧЛњЦїбЇЯАКЭЫуЗЈЩшМЦЮЪЬтЃЌЛЙЪЧвЛИіДѓЙцФЃЯЕЭГЮЪЬтЁЃЫќМШВЛЪЧЕЅДПЕФЛњЦїбЇЯАЃЌвВВЛЪЧЕЅДПЕФДѓЪ§ОнДІРэММЪѕЫљФмНтОіЕФЮЪЬтЃЌЖјЪЧвЛИіЭЌЪБЩцМАЛњЦїбЇЯАКЭДѓЪ§ОнДІРэСНИіжївЊЗНУцЕФНЛВцадбаОППЮЬтЁЃвЛЗНУцЃЌЫќШдШЛашвЊМЬајЙизЂЛњЦїбЇЯАЕФЗНЗЈКЭЫуЗЈБОЩэЃЌМДашвЊМЬајбаОПаТЕФЛђИФНјЕФбЇЯАФЃаЭКЭбЇЯАЗНЗЈЃЌвдВЛЖЯЬсЩ§ЗжЮідЄВтНсЙћЕФзМШЗадЃЛгыДЫЭЌЪБЃЌгЩгкЪ§ОнЙцФЃОоДѓЃЌДѓЪ§ОнЛњЦїбЇЯАЛсЪЙМИКѕЫљгаЕФДЋЭГДЎааЛЏЛњЦїбЇЯАЫуЗЈФбвддкПЩНгЪмЕФЪБМфФкЭъГЩМЦЫуЃЌДгЖјЪЙЕУЫуЗЈдкЪЕМЪгІгУГЁОАжаЪЇаЇЁЃвђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАдкЙизЂЛњЦїбЇЯАЗНЗЈКЭЫуЗЈбаОПЕФЭЌЪБЃЌЛЙвЊЙизЂШчКЮНсКЯЗжВМЪНКЭВЂааЛЏЕФДѓЪ§ОнДІРэММЪѕЃЌвдБудкПЩНгЪмЕФЪБМфФкЭъГЩМЦЫуЁЃЮЊСЫФмгааЇЭъГЩДѓЪ§ОнЛњЦїбЇЯАЙ§ГЬЃЌашвЊбаОПВЂЙЙНЈМцОпЛњЦїбЇЯАКЭДѓЙцФЃЗжВМВЂааМЦЫуДІРэФмСІЕФвЛЬхЛЏЯЕЭГЁЃ
вђДЫЃЌСьгђФкГіЯжСЫЁАДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁБЛђепЁАЗжВМЪНбЇЯАЯЕЭГЁБЕФИХФюЃЌВЂНјааСЫжюЖрДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФбаОПгыПЊЗЂЙЄзїЁЃ
2 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФММЪѕЬиеї
ВЮПМЮФЯз[5,6]зЈУХНщЩмСЫДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФММЪѕЬиеїЁЃ
ШчЭМ1ЫљЪОЃЌвЛИіДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЛсЭЌЪБЩцМАЛњЦїбЇЯАКЭДѓЪ§ОнДІРэСНЗНУцЕФжюЖрИДдгММЪѕЮЪЬтЃЌАќРЈЛњЦїбЇЯАЗНУцЕФФЃаЭЁЂбЕСЗЁЂОЋЖШЮЪЬтвдМАДѓЪ§ОнДІРэЗНУцЕФЗжВМЪНДцДЂЁЂВЂааЛЏМЦЫуЁЂЭјТчЭЈаХЁЂОжВПадМЦЫуЁЂШЮЮёЕїЖШЁЂШнДэЕШжюЖрвђЫиЁЃетаЉвђЫиЛЅЯргАЯьЃЌНЛжЏдквЛЦ№ЃЌДѓДѓдіМгСЫЯЕЭГЩшМЦЕФИДдгадЁЃвђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАвбОВЛНіНіЪЧвЛИіЫуЗЈбаОПЮЪЬтЃЌЖјЪЧашвЊеыЖдДѓЪ§ОнМЏЃЌПМТЧДгЕзВуЕФДѓЪ§ОнЗжВМДцДЂЕНжаВуЕФДѓЪ§ОнВЂааЛЏМЦЫуЃЌдйЕНЩЯВуЕФЛњЦїбЇЯАЫуЗЈЃЌЩшМЦвЛжжвЛЬхЛЏЕФжЇГХЯЕЭГЃЌаЮГЩвзгкЮЊЪ§ОнЗжЮіГЬађдБКЭЛњЦїбЇЯАбаОПепЪЙгУЕФЁЂЭъећЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃ
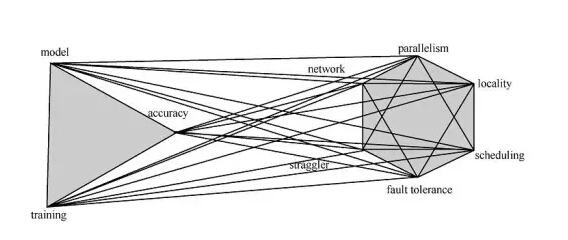
ЭМ1 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЫљЩцМАЕФИДдгвђЫи[5]
вЛИіРэЯыЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЭЈГЃашвЊОпБИвдЯТМИИіЗНУцЕФММЪѕвЊЫиКЭЬиеї[5~7]ЁЃ
гІЕБДгећИібЇЯАЕФЩњУќжмЦк/СїЫЎЯпРДПМТЧЃЌАќРЈбЕСЗЪ§ОнКЭЬиеїЕФЬсШЁЁЂВЂаабЇЯАЫуЗЈЕФЩшМЦЁЂбЕСЗФЃаЭКЭВЮЪ§ЕФВщбЏЙмРэЁЂЗжВМЪНбЕСЗМЦЫуЙ§ГЬЃЌЖМгІдквЛИівЛЬхЛЏЕФбЇЯАЯЕЭГЦНЬЈЩЯЭъГЩЁЃ
гІЬсЙЉЖржжВЂаабЕСЗФЃЪНЃЌжЇГжВЛЭЌЕФЛњЦїбЇЯАФЃаЭКЭЫуЗЈЁЃ
ашвЊЬсЙЉЖдЕзВуЯЕЭГЕФГщЯѓЃЌвдЪЕЯжЖдЕзВуЭЈгУДѓЪ§ОнДІРэв§ЧцЕФжЇГжЃЌВЂЬсЙЉЪ§ОнПЦбЇжаГЃгУЕФБрГЬгябдНгПкЃЈAPIЃЉЁЃ
гІИУгЕгаПЊЗХКЭЗсИЛЕФЩњЬЌЁЂЙуЗКЕФгІгУКЭПьЫйЕФНјЛЏФмСІЁЃ
дкЩЯЪіММЪѕЬиеїжаЃЌвЛИіЗЧГЃживЊЕФЫМТЗЪЧЃЌвЊЭЈЙ§ЯЕЭГГщЯѓРДНЕЕЭЯЕЭГЩшМЦЕФИДдгадЁЃШчЭМ2ЫљЪОЃЌвЛИіЩшМЦСМКУЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЃЌгІЕБЭЈЙ§ЖЈвхЬиЖЈЕФЛњЦїбЇЯАБрГЬМЦЫуКЭЯЕЭГГщЯѓНгПкЃЌНЋЩЯВуЛњЦїбЇЯАКЭЕзВуЗжВМЪНЯЕЭГНтёюПЊРДЃЌНЋЛњЦїбЇЯАЪЕЯждкЯжгаЕФДѓЪ§ОнМЦЫуЦНЬЈжЎЩЯЃЌЖјВЛашвЊПМТЧЕзВуЯЕЭГВуУцЕФвђЫиЃЌвдДЫЪЕЯжЕзВуДѓЪ§ОнДІРэЦНЬЈЖдЩЯВугУЛЇЕФЭИУїЛЏЃЌШУЩЯВугУЛЇДгжюЖрЕзВуЕФЗжВМКЭВЂааЛЏДѓЪ§ОнБрГЬМЦЫуЯИНкжаНтЗХГіРДЃЌвдБуЫћУЧжТСІгкЩЯВуЕФЛњЦїбЇЯАФЃаЭКЭЫуЗЈЕФЩшМЦЪЕЯжЁЃЭЈЙ§БрГЬМЦЫуКЭЯЕЭГГщЯѓВуAPIЃЌЯђЩЯЬсЙЉИїжжЛњЦїбЇЯАБрГЬМЦЫуНгПквдМАбЇЯАФЃаЭКЭбЕСЗЪ§ОнЕФБэЪОЃЌЯђЯТгЩЕзВуЗжВМЪНЯЕЭГИКд№ДІРэВЂЬсЙЉИпаЇЕФЗжВМКЭВЂааЛЏМЦЫуЪЕЯжЁЃ
ЭМ2 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГГщЯѓ
3 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФжївЊбаОПЮЪЬт
жЊУћЕФApache FlinkДѓЪ§ОнЗжЮіЯЕЭГбаОПепдк2014ФъVLDBЛсвщжїЬтБЈИцКЭТлЮФжа[8]ЃЌДгЪ§ОнЗжЮіЕФИДдгГЬЖШКЭЪ§ОнЙцФЃЕФЮЌЖШЃЌПМВьСЫЯжгаЕФЯрЙибаОПЙЄзїКЭЯЕЭГЃЌШчЭМ3ЫљЪОЁЃЯжгаЕФЯЕЭГвЊУДжївЊгУгкаЁЙцФЃИДдгЗжЮіЃЌвЊУДжївЊгУгкДѓЙцФЃЕФМђЕЅЭГМЦЗжЮіЃЌШБЩйМШОпгаИДдгЪ§ОнЗжЮіФмСІгжОпгаЧПДѓЕФДѓЪ§ОнДІРэФмСІЕФДѓЪ§ОнЗжЮіЯЕЭГЃЛЮФеТзїепЩѕжСШЯЮЊЃЌЖдгкаавЕДѓЪ§ОнЗжЮіШЫдБЖјбдЃЌЯжгаЕФЙЄОпЛЙДІгкЁАЪЏЦїЪБДњЁБ[8]ЁЃ

ЭМ3 баОПепApache FlinkЬсГіЕФЗжЮіЮЌЖШКЭбаОПЯжзД[8]
гыДЫЭЌЪБЃЌжјУћЕФUC Berkeley AMPLabдкбаОПЛљгкSparkЕФЛњЦїбЇЯАПтMLBase[9]ЪБЃЌДгМЦЫуадФмКЭЯЕЭГвзгУадСНИіживЊЮЌЖШЃЌПМВьСЫЯжгаЕФДѓЪ§ОнЛњЦїбЇЯАбаОПЙЄзїКЭЯЕЭГЃЌШчЭМ4ЫљЪОЁЃУцЯђЛњЦїбЇЯАКЭЪ§ОнЗжЮіЪБЃЌФПЧАвбгаЕФЙЄзїКЭЯЕЭГЃЌОјДѓЖрЪ§ЖМЮДФмЭЌЪБОпБИДѓЙцФЃЗжЮіДІРэФмСІКЭСМКУЕФЯЕЭГвзгУадЁЃ
ЭМ4 SparkЯЕЭГбаОПепЬсГіЕФЗжЮіЮЌЖШКЭбаОПЯжзД[9]
вђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАГ§СЫашвЊМЬајЙизЂКЭбаОПДЋЭГвтвхЩЯЕФбЇЯАЗНЗЈКЭЫуЗЈЮЪЬтЃЌвдВЛЖЯЬсИпбЇЯАОЋЖШЭтЃЌЛЙашвЊжиЕуЙизЂКЭбаОПНтОіДѓЪ§ОнГЁОАЯТЫљЬигаЕФСНДѓММЪѕЮЪЬтЃК
вЛЪЧДѓЪ§ОнИДдгЗжЮіЪБЕФМЦЫуадФмЮЪЬтЃЛ
ЖўЪЧДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФПЩБрГЬадКЭвзгУадЮЪЬтЁЃ
ЃЈ1ЃЉДѓЪ§ОнИДдгЗжЮіЪБЕФМЦЫуадФмЮЪЬт
дкМЦЫуадФмЗНУцЃЌДѓЙцФЃЪ§ОнМЏИјКмЖрДЋЭГДЎааЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЭкОђЫуЗЈДјРДКмДѓЕФЬєеНЃЌашвЊбаОПНтОіУцЯђДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЕФИпаЇМЦЫуЗНЗЈКЭЯЕЭГЁЃдкЪ§ОнМЏНЯаЁЪБЃЌКмЖрИДдгЖШдкO(n
log n)ЁЂO(n2)ЩѕжСO(n3)ЕФДЋЭГДЎааЛЏЛњЦїбЇЯАЫуЗЈЖМПЩвдгааЇЙЄзїЃЛЕЋЕБЪ§ОнЙцФЃдіГЄЕНМЋДѓГпЖШЪБЃЌЯжгаЕФДЎааЛЏЫуЗЈНЋЛЈЗбФбвдНгЪмЕФЪБМфПЊЯњЃЌЪЙЕУЫуЗЈдкЪЕМЪгІгУГЁОАжаЪЇаЇЃЌетИјвЕНчДѓСПЪЕМЪЕФДѓЪ§ОнИДдгЗжЮігІгУДјРДКмЖраТЕФЬєеНКЭЮЪЬт[10]ЁЃе§ШчЮЂШэШЋЧђИБзмВУТНЦцВЉЪПдк2012ФъжИГіЕФЃЌЁАДѓЪ§ОнЪЙЕУЯжгаЕФДѓЖрЪ§ЛњЦїбЇЯАЫуЗЈЪЇаЇЃЌУцЯђДѓЪ§ОнДІРэЪБетаЉЫуЗЈЖМашвЊжиаДЁБЁЃ
дкДѓаЭЛЅСЊЭјЦѓвЕЃЌДѓЙцФЃЛњЦїбЇЯАЫуЗЈОГЃгУгкДІРэЪЎвкжСЧЇвкМЖБ№ЕФбљБОвдМАвЛвкжСЪ§ЪЎвкЪ§ОнЬиеїЕФДѓЙцФЃЪ§ОнМЏЁЃР§ШчЃЌGoogleжјУћЕФSetiЬЋПеЫбЫїЯюФПашвЊНјааИпДяЧЇвкбљБОЁЂЪЎвкЬиеїЪ§ОнЕФДѓЙцФЃЛњЦїбЇЯАЃЌЬкбЖPeacockжїЬтФЃаЭЗжЮіЯЕЭГашвЊНјааИпДяЪЎвкЮФЕЕЁЂАйЭђДЪЛуЁЂАйЭђжїЬтЕФжїЬтФЃаЭбЕСЗЃЌЖјНівЛИіАйЭђДЪЛуГЫвдАйЭђжїЬтЕФОиеѓЃЌЦфЪ§ОнДцДЂСПМДИпДя3TBЃЌШчЙћдйПМТЧЪЎвкЮФЕЕГЫвдАйЭђжїЬтЕФОиеѓЃЌЦфЪ§ОнСПИќЪЧИпДя3
PB[3]ЁЃШчДЫДѓСПЕФбЕСЗбљБОЃЌМгЩЯЛњЦїбЇЯАЫуЗЈБОЩэЕФИДдгадЃЌЕМжТФбвддкДЋЭГЕФДЎааЛЏМЦЫуЦНЬЈЩЯЁЂдкПЩНгЪмЕФЪБМфФкЭъГЩШчДЫОоДѓЕФИДдгЗжЮіМЦЫуШЮЮёЃЌвђЖјДјРДСЫЪЎЗжЭЛГіЕФМЦЫуадФмЮЪЬтЁЃвђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАЫуЗЈКЭЯЕЭГашвЊбаОПНтОіДѓЙцФЃГЁОАЯТИпаЇЕФЗжВМЪНКЭВЂааЛЏЫуЗЈЩшМЦвдМАМЦЫуЮЪЬтЃЌвдБЃжЄЫуЗЈКЭЯЕЭГПЩвддкПЩНгЪмЕФЪБМфФкЭъГЩДѓЙцФЃЪ§ОнЕФбЇЯАКЭбЕСЗЁЃ
ЃЈ2ЃЉДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФПЩБрГЬадКЭвзгУадЮЪЬт
ЮЊСЫТњзуМБОчдіГЄЕФДѓЪ§ОнДІРэашЧѓЃЌЙ§ШЅМИФъРДЃЌШЋЧђЭЦГіСЫHadoop[11]КЭSpark[12]ЕШЖржжжїСїДѓЪ§ОнДІРэММЪѕКЭЯЕЭГЦНЬЈЁЃетаЉжїСїММЪѕКЭЦНЬЈЕФГіЯжЮЊДѓЪ§ОнЕФДІРэЬсЙЉСЫСМКУЕФММЪѕЪжЖЮКЭЗНЗЈЁЃHadoopЕФГіЯжЪЙЕУДѓЪ§ОнДІРэММЪѕКЭЦНЬЈДгЮоЕНгаЃЌЖјЛљгкФкДцМЦЫуЕФSparkЯЕЭГЕФГіЯжЪЙЕУДѓЪ§ОнЗжЮіМЦЫуДгТ§ЕНПьЁЃШЛЖјЃЌЯжгаЕФДѓЪ§ОнДІРэММЪѕКЭЯЕЭГЦНЬЈЖМДцдкКмДѓЕФвзгУадЮЪЬтЃЌФбвдЮЊЦеЭЈЕФГЬађдБеЦЮеКЭЪЙгУЃЌгШЦфЪЧУцЯђИДдгЕФДѓЙцФЃЛњЦїбЇЯАКЭЪ§ОнЗжЮіЪБЃЌетИіЮЪЬтИќЮЊЭЛГіЁЃ
ДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЕФВЂааЛЏГЬађЩшМЦЃЌБШДЋЭГЕФДЎааЛЏЫуЗЈЩшМЦИДдгКмЖрЁЂЖдГЬађдБЕФММЪѕвЊЧѓИќИпЁЃЖдгкЦеЭЈЕФЪ§ОнЗжЮіГЬађдБЛђЛњЦїбЇЯАбаОПепРДЫЕЃЌдкЬиЖЈЕФДѓЪ§ОнБрГЬФЃаЭКЭЦНЬЈЯТНјааВЂааЛЏЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЩшМЦЃЌашвЊеЦЮеКмЖрЗжВМЪНЯЕЭГБГОАжЊЪЖКЭВЂааГЬађЩшМЦММЧЩЃЌетЖдЫћУЧРДЫЕФбЖШНЯДѓЃЌОГЃвЊАбЪЕМЪЙЄзїЕФДѓВПЗжЪБМфЛЈЗбдкЕзВуИДдгЕФВЂааЛЏКЭЗжВМЪНБрГЬКЭЕїЪдЩЯЃЌИјЩЯВуЪ§ОнЗжЮіКЭЫуЗЈЩшМЦЙЄзїДјРДКмДѓЕФВЛБуКЭРЇФбЃЌЕМжТЦеЭЈГЬађдБгыЯжгаЕФИїжжДѓЪ§ОнДІРэЦНЬЈжЎМфДцдквЛИіФбвдгтдНЕФКшЙЕ[8ЃЌ9ЃЌ13~15]ЁЃ
СэвЛЗНУцЃЌМДЪЙЖдгкжюШчGoogleЁЂАйЖШЕШОпгаЧПДѓММЪѕСІСПЕФЛЅСЊЭјЦѓвЕГЬађдБРДЫЕЃЌЫцзХЖржжДѓЪ§ОнДІРэгыБрГЬЦНЬЈЕФГіЯжвдМАИїжжЗжЮігІгУЮЪЬташЧѓЕФВЛЭЌЃЌЫћУЧвВГЃГЃашвЊеыЖдВЛЭЌЦНЬЈЃЌжиИДБраДКЭВтЪдИїжжВЂааЛЏЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЃЌетжждкЖрИіДѓЪ§ОнЦНЬЈЩЯжиИДБраДКЭГЂЪдЪ§вдАйМЦЕФЛњЦїбЇЯАЫуЗЈЕФЙЄзїИКЕЃвВКмжиЁЃе§ШчАЂРяАЭАЭМЏЭХИБзмВУЁЂИпМЖбаОПдБеТЮФсдВЉЪПдкжаЙњМЦЫуЛњбЇЛсЕквЛНьДѓЪ§ОнбЇЪѕЛсвщЩЯЫљжИГіЕФЃЌЁАЬдБІФкВПашвЊЪЙгУЕФВЂааЛЏЛњЦїбЇЯАЫуЗЈКмЖрЃЌЫцзХаТаЭЕФВЂааЛЏМЦЫуПђМмЕФж№ВНГіЯжЃЌашвЊНЋЦфж№ИіЪЕЯжЕНMPIЁЂMapReduceЁЂSparkЕШВЂааМЦЫуПђМмЩЯЃЛШчЙћКѓУцГіЯжИќЯШНјЕФПђМмЃЌгжУцСйзХНЋетаЉЫуЗЈжиаТЪЕЯжвЛБщЕФИКЕЃЁБЁЃ
еыЖдДѓЪ§ОнЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЃЌЯжгаЕФДѓЪ§ОнДІРэММЪѕКЭЦНЬЈДцдкКмДѓЕФПЩБрГЬадКЭвзгУадЮЪЬтЃЌЕМжТЦеЭЈГЬађдБКЭГЃЙцЕФГЬађЩшМЦЗНЗЈгыЯжгаЕФДѓЪ§ОнЗжЮіДІРэБрГЬММЪѕжЎМфДцдкзХвЛИіКмДѓЕФКшЙЕЁЃе§ШчCCFДѓЪ§ОнзЈМвЮЏдБЛсЁЖ2015ФъДѓЪ§ОнЗЂеЙЧїЪЦдЄВтБЈИцЁЗжИГіЕФФЧбљЃЌЁАгЩгкЯжгаЕФДѓЪ§ОнЦНЬЈвзгУадВюЃЌЖјДЙжБгІгУаавЕЕФЪ§ОнЗжЮігжЩцМАСьгђзЈМвжЊЪЖКЭСьгђНЈФЃЃЌФПЧАдкДѓЪ§ОнаавЕЗжЮігІгУгыЭЈгУЕФДѓЪ§ОнММЪѕжЎМфДцдкКмДѓЕФКшЙЕЃЌШБЩйЯрЛЅЕФНЛВцШкКЯЁБ[4]ЁЃ
вђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАЯЕЭГвЊНтОіЕФвЛИіживЊЮЪЬтЪЧЃЌШУВЛвзЪЙгУЕФДѓЪ§ОнДІРэММЪѕКЭЦНЬЈБфЕУвзгкЪЙгУЃЌвЊЬюЦНЦеЭЈГЬађдБКЭГЃЙцГЬађЩшМЦЗНЗЈгыЯжгаЕФДѓЪ§ОнДІРэММЪѕжЎМфЕФКшЙЕЃЌОЁПЩФмШУЦеЭЈГЬађдБгУГЃЙцГЬађЩшМЦЗНЗЈБуФмгааЇЭъГЩДѓЪ§ОнЕФИДдгЗжЮіДІРэЁЃ
ИљОнGoogle SetiЯюФПбаОПШЫдБдкПЊЗЂЪЕМЪЕФДѓаЭЛњЦїбЇЯАЯЕЭГЩЯЕФОбщЃЌдкУцЯђДѓЪ§ОнЪБЃЌПМТЧЕНгУЛЇПЊЗЂаЇТЪЮЪЬтЃЌЯЕЭГвзгУадгыЬсИпЛњЦїбЇЯАОЋЖШМИКѕЭЌЕШживЊЃЌгаЪБЩѕжСБШОЋЖШЮЪЬтИќЮЊживЊЃЌЁАвВаэЙ§ШЅбЇЪѕНчКмЩйЙиаФЩшМЦвЛИіОЋЖШЩдВюЁЂЕЋгаИќКУвзгУадКЭЯЕЭГПЩППадЕФбЇЯАЫуЗЈЃЌЕЋдкЪЕМЪгІгУжаЃЌетЛсЬхЯжГіЗЧГЃживЊЕФМлжЕЁБЁЃ
4 ДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФЗжРр
НќМИФъРДЃЌЫцзХДѓЪ§ОнЕФРДСйЃЌЛљгкДѓЪ§ОнЕФЛњЦїбЇЯАЗНЗЈКЭЯЕЭГГЩЮЊвЕНчКЭбЇЪѕНчЦеБщЙизЂЕФбаОПШШЕуЁЃЮЊСЫЬсЙЉгааЇЕФДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЪжЖЮЃЌвЕНчКЭбЇЪѕНчдкГЂЪдЖржжЭООЖКЭЗНЗЈЃЌдкВЛЭЌЕФВЂааМЦЫуФЃаЭКЭЦНЬЈЯТЃЌдкЪЕМЪЕФЪ§ОнЗжЮіЭкОђжаЕУЕНгІгУЁЃ
НЯдчГіЯжвдМАЯжгаЕФвЛаЉДѓЪ§ОнЛњЦїбЇЯАЫуЗЈКЭЯЕЭГДѓЖрВЩгУНЯЮЊЕЭВуЕФНєёюКЯЁЂЖЈжЦЛЏЗНЗЈЙЙНЈЁЃетаЉЫуЗЈКЭЯЕЭГДѓЖМеыЖдЬиЖЈЕФгІгУЃЌбЁдёЬиЖЈЕФЦНЬЈКЭФЃаЭЃЌеыЖдЬиЖЈЕФЛњЦїбЇЯАФЃаЭКЭЬиЖЈЕФМЦЫуФЃЪНЃЌДгДЎааЫуЗЈКЭдаЭЕНЗжВМВЂааЛЏЫуЗЈКЭдаЭЃЌздЕзВуЯђЩЯНјааНєёюКЯКЭЖЈжЦЛЏЕФПЊЗЂКЭгХЛЏЁЃОЁЙметПЩвдзюДѓЛЏРћгУЯЕЭГзЪдДвдДяЕНзюМбЕФадФмЃЌЕЋетжжЕЭВуЕФНєёюКЯЖЈжЦЛЏЪЕЯжЗНЗЈЃЌНЋбЇЯАКЭЯЕЭГЛьдгдквЛЦ№ЃЌЪЕЯжФбЖШДѓЃЌЫуЗЈКЭЯЕЭГвВФбвдЕїЪдКЭЮЌЛЄ[5,6]ЁЃ
ДгЧАЪіЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЬиеїРДПДЃЌвЛИіЩшМЦСМКУЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГгІЕБПМТЧИпВуЕФЯЕЭГВуГщЯѓЃЌЯђЩЯЮЊГЬађдБЬсЙЉвзгкЪЙгУЕФИпВуЛњЦїбЇЯАЫуЗЈБрГЬНгПкЃЌЯђЯТЛљгкЯжгаЕФЭЈгУЛЏДѓЪ§ОнДІРэЦНЬЈЬсЙЉДѓЙцФЃЪ§ОнЕФЗжВМКЭВЂааЛЏМЦЫуФмСІЁЃЮЊДЫЃЌНќФъРДвбОПЊЪМГіЯжЛљгкИїжжИпВуБрГЬМЦЫуКЭЯЕЭГГщЯѓЩшМЦДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФбаОПЙЄзїЁЃ
дкИпВуБрГЬМЦЫуКЭЯЕЭГГщЯѓЩЯЃЌФПЧАЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГДѓжТПЩЗжЮЊ3жжжївЊЕФБрГЬМЦЫуКЭЯЕЭГГщЯѓЗНЗЈЃЌЗжБ№ЪЧЛљгкОиеѓФЃаЭЕФГщЯѓЁЂЛљгкЭМФЃаЭЕФГщЯѓвдМАЛљгкВЮЪ§ФЃаЭЕФГщЯѓЁЃ
ЃЈ1ЃЉЛљгкОиеѓФЃаЭЕФГщЯѓ
ЛљгкОиеѓФЃаЭЕФГщЯѓЛљгкетбљвЛИіЪТЪЕЃКДѓЖрЪ§ЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЖМПЩвдБэЪОЮЊОиеѓЛђЯђСПДњЪ§МЦЫуЃЌвђДЫПЩвдЙЙНЈвЛИіЛљгкОиеѓМЦЫуФЃаЭЕФЛњЦїбЇЯАЯЕЭГЃЌдЪаэГЬађдБжБНгЛљгкОиеѓМЦЫуПьЫйЙЙНЈЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЁЃзюЕфаЭЕФЛљгкОиеѓФЃаЭЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЩаВЛЖрМћЃЌUCBerkeley
AMP LabЭЦГіЕФSpark MLlibЪЧвЛИіЪдЭМЛљгкОиеѓМЦЫуФЃаЭЙЙНЈЩЯВуИїжжЛњЦїбЇЯАЫуЗЈЕФЯЕЭГЃЛзюНќSparkЯЕЭГЬсГіСЫвЛИіDataFrameЕФЪ§ОнГщЯѓЛњжЦЃЌдЪаэЛљгкОиеѓКЭБэЕШЪ§ОнНсЙЙЃЌЩшМЦИїжжЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЁЃДЫЭтЃЌЙњФкгЩФЯОЉДѓбЇPASAДѓЪ§ОнЪЕбщЪвбаОППЊЗЂЕФЁАOctopusЃЈДѓеТгуЃЉЁБЯЕЭГЪЧвЛИівдДѓЙцФЃОиеѓФЃаЭЮЊжааФЕФПчЦНЬЈДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃ
ЃЈ2ЃЉЛљгкЭМФЃаЭЕФГщЯѓ
ЫфШЛОиеѓПЩвдБэЪОДѓЖрЪ§ЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЃЌЕЋЖдгквЛаЉЛљгкЭМФЃаЭЕФЩчЛсЭјТчЗжЮіЮЪЬтЃЌЛљгкОиеѓФЃаЭНјааМЦЫуВЂЗЧзюгааЇЕФЗНЗЈЃЈЫфШЛЭМКЭОиеѓБэЪООпгаРэТлЩЯЕФЕШМладЃЉЁЃОиеѓФЃаЭЖдгкЭМЪ§ОнЕФБэДяВЛШчЭМФЃаЭЃЌЧвЭЈГЃЛсУцСйЯЁЪшадЕФЮЪЬтЁЃвђДЫЃЌвЛаЉЩчЛсЭјТчЗжЮіРрЕФЪЕМЪгІгУашвЊЛљгкИќЮЊИпаЇЕФЭМФЃаЭЕФбЇЯАКЭЗжЮіЗНЗЈЃЌЮЊДЫГіЯжСЫЯргІЕФЛљгкЭМФЃаЭЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃзюЕфаЭЕФЛљгкЭМФЃаЭЕФЯЕЭГЪЧУРЙњПЈФЭЛљУЗТЁДѓбЇЃЈCMUЃЉЭЦГіЕФGraphLabЯЕЭГ[16]вдМАЛљгкSparkЙЙНЈЕФGraphXЯЕЭГЁЃ
ЃЈ3ЃЉЛљгкВЮЪ§ФЃаЭЕФГщЯѓ
ЛљгкОиеѓФЃаЭКЭЭМФЃаЭЕФЯЕЭГжївЊЪЧДгЪ§ОнБэЪОФЃаЭЕФНЧЖШРДЙЙНЈЯЕЭГЃЌетСНжжЗНЗЈЕФЬиЕуЪЧИќНгНќгкЪЕМЪбЇЯАЮЪЬтжаздШЛЛЏЕФЪ§ОнБэЪОКЭМЦЫуФЃаЭЃЌвђДЫЖдгкЪ§ОнЗжЮіШЫдБЗНБуПьЫйЕиЙЙНЈЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈБШНЯздШЛКЭжБЙлЁЃЕЋЪЧЃЌДѓЪ§ОнЛњЦїбЇЯАГЃГЃЛЙашвЊЩцМАДѓЙцФЃФЃаЭЃЌР§ШчЃЌНќМИФъЗЂеЙбИУЭЕФЩюЖШЩёОЭјТчЫуЗЈЃЌГЃГЃашвЊЭЈЙ§ЖдДѓСПФЃаЭВЮЪ§ЕФЕїгХРДЬсИпбЇЯАОЋЖШЃЌдкетжжЧщПіЯТЃЌЩЯЪіСНжжЗНЗЈЛсШБЩйСщЛюадЃЌФбвдШУЫуЗЈЩшМЦепЭЈЙ§ПижЦФЃаЭВЮЪ§НјааЫуЗЈгХЛЏЁЃЮЊДЫЃЌгабаОПепЬсГіСЫвЛжжЛљгкФЃаЭВЮЪ§ЕФГщЯѓЗНЗЈЃЌМДАбЫљгаЛњЦїбЇЯАЫуЗЈГщЯѓЮЊЖдбЇЯАЙ§ГЬжавЛзщФЃаЭВЮЪ§ЕФЙмРэКЭПижЦЃЌВЂЬсЙЉЖдДѓЙцФЃГЁОАЯТДѓСПФЃаЭВЮЪ§ЕФгааЇЙмРэКЭЗУЮЪЁЃФПЧАВЮЪ§ФЃаЭзюЕфаЭЕФЗНЗЈЪЧзюГѕгЩУРЙњПЈФЭЛљУЗТЁДѓбЇЕФLiMuЕШШЫЬсГіЕФЁЂКѓдкКмЖрЯЕЭГжаЕУЕННјвЛВНгІгУЕФParameter
Server[17ЃЌ18]ЁЃ
ЪЕМЪЕФЯЕЭГвВПЩФмЛсЪЧвЛжжМцгаЩЯЪіЖржжРраЭЕФЛьКЯЯЕЭГЁЃДЫЭтЃЌвВгаВЛЩйЯЕЭГДгВЂааФЃЪННЧЖШРДЧјЗжЃЌЗжЮЊЪ§ОнВЂааКЭФЃаЭВЂааСНжжЗНЪНЃЌЧввЛаЉЯЕЭГжЛЬсЙЉЪ§ОнВЂааЗНЪНЃЌСэвЛаЉЯЕЭГЛсЭЌЪБЬсЙЉЪ§ОнВЂааКЭФЃаЭВЂааСНжжЗНЪНЁЃ
5 ЕфаЭДѓЪ§ОнбЇЯАЗНЗЈКЭЯЕЭГНщЩм
5.1 ЛљгкЬиЖЈЦНЬЈЕФЖЈжЦЪНВЂааЛЏЛњЦїбЇЯАЫуЗЈгыЫуЗЈПт
ЫцзХHadoop MapReduce[11]КЭSpark[12]ДѓЪ§ОнВЂааМЦЫугыБрГЬЦНЬЈЕФГіЯжКЭГЩЪьгІгУЃЌHadoopКЭSparkвбОГЩЮЊФПЧАДѓЪ§ОнЗжЮіДІРэЕФжїСїЦНЬЈЁЃЮЊСЫНтОіДѓЙцФЃЛњЦїбЇЯАЮЪЬтЃЌгаДѓСПЕФбаОПЙЄзїжТСІгкЛљгкHadoopMapReduceКЭSparkвдМАДЋЭГЕФMPIВЂааМЦЫуПђМмЃЌЭъГЩИїжжВЂааЛЏЛњЦїбЇЯАКЭЪ§ОнЭкОђЫуЗЈЕФЩшМЦЁЃдкжюШчTPDSЁЂJPDCЁЂIPDPSЁЂICPPЁЂICPADSЁЂIEEEBigDataЕШДѓЪ§ОнКЭЗжВМВЂааМЦЫуСьгђЕФжЊУћЦкПЏКЭЙњМЪЛсвщЩЯЃЌетаЉВЂааЛЏЫуЗЈбаОПЙЄзїВЛЪЄУЖОйЁЃгЩгкашвЊЭЌЪБЙЫМАЩЯВуЛњЦїбЇЯАЫуЗЈЩшМЦКЭЕзВуЗжВМВЂааЛЏДѓЪ§ОнДІРэЯЕЭГВуЯИНкЃЌзмЬхЖјбдЃЌЛљгкЩЯЪіВЛЭЌЕФВЂааЛЏБрГЬЗНЗЈКЭЦНЬЈНјааВЂааЛЏЛњЦїбЇЯАЫуЗЈЩшМЦЃЌШдЪєгквЛжжзЈвЕадНЯЧПЁЂММЪѕвЊЧѓНЯИпЁЂЙ§ГЬНЯЮЊЗБЫіЕФЙЄзїЃЌФбвдЮЊШБЩйЗжВМЪНКЭВЂааМЦЫужЊЪЖБГОАЕФЦеЭЈГЬађдБЪЙгУЁЃ
ЮЊСЫШУЦеЭЈЪ§ОнЗжЮіГЬађдБФмЙЛжБНгЪЙгУВЂааЛЏЛњЦїбЇЯАЫуЗЈЃЌФПЧАЦеБщЕФвЛжжзіЗЈЪЧЃЌдкВЛЭЌЕФВЂааЛЏМЦЫуЦНЬЈЩЯЃЌгЩзЈвЕЕФЛњЦїбЇЯАЫуЗЈЩшМЦепЪЕЯжВЂааЛЏЛњЦїбЇЯАЫуЗЈЃЌЬсЙЉвЛИіЛњЦїбЇЯАКЭЪ§ОнЭкОђЙЄОпАќвдЙЉвЛАуЕФЪ§ОнЗжЮіКЭгІгУПЊЗЂГЬађдБжБНгЪЙгУЃЌШчHadoopЯТЕФMahoutвдМАSparkЛЗОГЯТЕФMLlibЁЃ
MahoutЕФжївЊШЮЮёЪЧЩшМЦВЂЬсЙЉвЛаЉЛљгкMapReduceЕФПЩРЉеЙЕФЛњЦїбЇЯАСьгђОЕфЫуЗЈПтЃЌАќРЈОлРрЁЂЗжРрЁЂЭЦМіЙ§ТЫЁЂЦЕЗБЯюМЏЭкОђЕШЁЃетаЉВЂааЛЏЫуЗЈЖМЪЧЛљгкHadoopMapReduceЦНЬЈЭъГЩЕФЃЌгУЛЇПЩжБНгЕїгУMahoutЫуЗЈПтЪЕЯжКУЕФЫуЗЈЁЃШЛЖјЃЌMahoutЬсЙЉЕФВЂааЛЏЛњЦїбЇЯАЫуЗЈЪ§СПгаЯоЃЌЖјЧвзїЮЊБъзМЕФШэМўАќЃЌЦфЫљЬсЙЉЕФЫуЗЈМИКѕЖМЪЧБъзМЕФЃЌдкЫуЗЈОЋЖШКЭадФмЩЯВЛвЛЖЈФмТњзугУЛЇЕФашвЊЁЃНјвЛВНЃЌMapReduceЕФЩшМЦФПБъЪЧНтОіЪ§ОнУмМЏЕЋМЦЫуТпМЯрЖдМђЕЅЕФХњДІРэЮЪЬтЁЃШЛЖјЃЌДѓЖрЪ§ЛњЦїбЇЯАЫуЗЈЕФМЦЫуСїГЬЖМБШНЯИДдгЃЌФЃаЭЕФбЕСЗЙ§ГЬЭљЭљашвЊЖрДЮЕќДњМЦЫуЃЈШчЬнЖШЯТНЕЫуЗЈЃЉЁЂгажаМфЪ§ОнМЏашвЊЙВЯэЕШЁЃMapReduceФЃаЭДІРэетРрЮЪЬтЪБЃЌЖюЭтЕФЕїЖШКЭГѕЪМЛЏПЊЯњЕМжТЦфДІРэадФмЦЋЕЭЁЃ
ЮЊСЫПЫЗўMapReduceдкМЦЫуадФмЩЯЕФШБЯнЃЌВЛЖЯЕигааТЕФВЂааЛЏМЦЫуФЃаЭКЭПђМмГіЯжЃЌUCBerkeley
AMPЪЕбщЪвЭЦГіЕФЁЂФПЧАвбГЩЮЊApacheПЊдДЯюФПЕФSpark[12]ЯЕЭГЪЧФПЧАзюгагАЯьСІЕФДѓЪ§ОнДІРэЦНЬЈжЎвЛЁЃSparkЪЙгУЛљгкФкДцМЦЫуЕФВЂааЛЏМЦЫуФЃаЭRDDЃЈresilientdistributed
datasetЃЉ[12]ЃЌЬсЙЉСЫвЛИіЧПДѓЕФЗжВМЪНФкДцВЂааМЦЫув§ЧцЃЌЪЕЯжСЫгХвьЕФМЦЫуадФмЃЌЭЌЪБЛЙБЃГжгыHadoopЦНЬЈдкЕзВуЗжВМЪНЪ§ОнДцДЂЩЯЕФМцШнадЁЃдкSparkжДаав§ЧцЩЯЃЌAMPЪЕбщЪвЪЕЯжСЫКмЖрЛњЦїбЇЯАЫуЗЈЃЌВЂж№ВНећРэГЩSparkЯТЕФвЛИіЛњЦїбЇЯАЫуЗЈПтЯюФПMLlibЁЃMLlibФПЧАвВАќКЌвЛаЉОиеѓВйзїЃЌВЂЯЃЭћЛљгкОиеѓЕФБэЪОЩшМЦПЊЗЂвЛаЉЭГМЦАќКЭЛњЦїбЇЯАЫуЗЈПтЁЃЮЊСЫМгЫйЩЯВуМЦЫуЃЌMLlibЕзВуЭЈЙ§BreezeЪЙгУСЫBLASЃЈbasiclinear
algebra subprogramЃЉЕЅЛњЕФОиеѓКЏЪ§ПтЁЃBLASЪЧКмЖрИќИпВуЕФЪ§бЇКЏЪ§ПтКЭЪ§бЇБрГЬгябдЃЈШчLAPACKКЭMATLABЕШЃЉЕФЛљБОЙЙГЩЕЅдЊЁЃBLASКЭLAPACKЪЧЕБЯТЦеБщЪЙгУЕФЯпадДњЪ§КЏЪ§ПтЃЌжївЊЖЈвхСЫвЛаЉЯпадДњЪ§жаГЃгУЕФдЫЫуВйзїКЭЗНГЬЧѓНтЁЂОиеѓЗжНтЕФКЏЪ§ЁЃДЫЭтЃЌЛљгкMLlibЕФЙЄзїЛљДЁЃЌUCBerkeleyЛЙМЦЛЎбаЗЂMLBase[9]ЯюФПЃЌИУЯюФПдіМгСЫЛњЦїбЇЯАФЃаЭздЖЏбЁдёКЭВЮЪ§здЖЏгХЛЏЕШЙІФмЃЌЬсЙЉСЫвдФПБъЮЊЕМЯђЕФИпВуЛњЦїбЇЯАЗНЗЈНгПкЁЃ
ЬсЙЉЛњЦїбЇЯАЫуЗЈПтдквЛЖЈГЬЖШЩЯМѕЧсСЫГЬађдБНјааЛњЦїбЇЯАЫуЗЈЩшМЦЕФИКЕЃЁЃЕЋМДЪЙШчДЫЃЌГЬађдББраДГЬађЪБШдШЛашвЊЪьЯЄОпЬхЕФВЂааБрГЬМЦЫуФЃаЭКЭЦНЬЈЃЌЖјЧвгЩгкЪЕМЪЪ§ОнЗжЮігІгУЕФашЧѓВЛЭЌЃЌКмЖрЪБКђЙЄОпАќЫљЬсЙЉЕФЭЈгУЫуЗЈдкбЇЯАОЋЖШКЭМЦЫуадФмЩЯПЩФмВЛФмТњзуашЧѓЃЌашвЊГЬађдБЖЈжЦКЭИФНјФГИіВЂааЛЏЛњЦїбЇЯАЫуЗЈЛђепПЊЗЂаТЕФЫуЗЈЃЌетЖдЦеЭЈЪ§ОнЗжЮіГЬађдБШдШЛЪЧКмДѓЕФЬєеНЁЃ
5.2 НсКЯДЋЭГЪ§ОнЗжЮіЦНЬЈЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГ
ЫфШЛгаСЫЛљгкДѓЪ§ОнДІРэЦНЬЈЕФЛњЦїбЇЯАЫуЗЈЩшМЦЗНЗЈЃЌФмЙЛНЯКУЕиНтОівЛЬхЛЏЕФДѓЪ§ОнДцДЂЁЂМЦЫувдМАВЂааЛЏЫуЗЈЩшМЦЮЪЬтЃЌЕЋНігаЛњЦїбЇЯАЯЕЭГШдШЛВЛФмКмКУЕиНтОіИїИіЦНЬЈЖджеЖЫгУЛЇДцдкЕФПЩБрГЬадКЭвзгУадВЛЙЛЕФЮЪЬтЁЃЮЊДЫЃЌЛЙашвЊНјвЛВНбаОПНтОіетаЉЮЪЬтЁЃ
ДгПЩБрГЬадКЭвзгУадНЧЖШРДЫЕЃЌЖдгкаавЕЪ§ОнЗжЮіЪІЃЌзюЪьЯЄЪЙгУЕФЗжЮігябдКЭЛЗОГЭЈГЃЪЧRЁЂPythonЁЂMATLABЕШЯЕЭГЁЃRЪЧФПЧАдкЪ§ОнЗжЮігІгУСьгђзюЙуЮЊЪЙгУЕФЪ§ОнЗжЮіЁЂЭГМЦМЦЫуМАжЦЭМЕФПЊдДШэМўЯЕЭГЃЌЬсЙЉСЫДѓСПЕФзЈвЕФЃПщКЭЪЕгУЙЄОпЁЃЮЊСЫОЁПЩФмЫѕаЁRгябдЛЗОГгыЯжгаДѓЪ§ОнЦНЬЈМфЕФКшЙЕЃЌЙЄвЕНчКЭбаОПНчвбОГЂЪддкRжаРћгУЗжВМЪНВЂааМЦЫув§ЧцРДДІРэДѓЪ§ОнЁЃзюдчЕФЙЄзїКЭЯЕЭГRHadoopЃЌЪЧгЩRevolutionAnalyticsЗЂЦ№ЕФвЛИіПЊдДЯюФПЃЌЦфФПБъЪЧНЋЭГМЦгябдRгыHadoopНсКЯЦ№РДЃЌФПЧАИУЯюФПАќРЈ3ИіR
packageЃЈАќЃЉЃЌЗжБ№ЮЊжЇГжгУRгябдБраДMapReduceгІгУЕФrmrЁЂгУгкRгябдЗУЮЪHDFSЕФrhdfsвдМАгУгкRгябдЗУЮЪHBaseЕФrhbaseЁЃЦфжаЃЌHadoopжївЊгУРДДцДЂКЭДІРэЕзВуЕФКЃСПЪ§ОнЃЌгУRгябдЬцДњJavaгябдЭъГЩMapReduceЫуЗЈЕФЩшМЦЪЕЯжЁЃ
РрЫЦЕиЃЌUC Berkeley AMPЪЕбщЪвдк2014Фъ1дТвВЭЦГіСЫвЛИіГЦЮЊSparkRЕФЯюФПЁЃSparkRвВЪЧзїЮЊвЛИіRЕФРЉеЙАќЃЌЮЊRгУЛЇЬсЙЉвЛИіЧсСПМЖЕФЁЂдкRЛЗОГРяЪЙгУSparkRDD
APIБраДГЬађЕФНгПкЁЃЫќдЪаэгУЛЇдкRЕФshellЛЗОГРяНЛЛЅЪНЕиЯђSparkМЏШКЬсНЛдЫаазївЕЁЃ
ШЛЖјЃЌФПЧАЕФRHadoopКЭSparkRЖМЛЙДцдквЛИіЭЌбљЕФЮЪЬтЃКШдвЊЧѓгУЛЇЪьЯЄMapReduceЛђSparkRDDЕФБрГЬПђМмКЭГЬађНсЙЙЃЌШЛКѓНЋздМКЕФMapReduceЛђSparkГЬађЪЕЯжЕНЛљгкRЕФБрГЬНгПкЩЯЃЌетКЭдкHadoopЛђSparkЩЯаДгІгУГЬађУЛгаЬЋДѓЕФЧјБ№ЃЌжЛЪЧБрГЬНгПкгУRгябдЗтзАСЫвЛЯТЁЃДЫЭтЃЌетаЉЙЄзїЖМЪЧЛљгкЕЅвЛЦНЬЈЃЌЮоЗЈНтОіПчЦНЬЈЭГвЛДѓЪ§ОнЛњЦїбЇЯАЫуЗЈЩшМЦЕФЮЪЬтЁЃ
5.3 ЛљгкЬиЖЈЦНЬЈЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГ
ЮЊСЫПЫЗўЧАЪізіЗЈЕФШБЯнЃЌНќФъРДЃЌбЇЪѕНчКЭвЕНчПЊЪМГЂЪдзмНсЛњЦїбЇЯАЫуЗЈЩшМЦЕФЙВЭЌЬиадЃЌНсКЯДѓЙцФЃбЇЯАЪБЫљашвЊПМТЧЕФЕзВуЗжВМЪНЪ§ОнДцДЂКЭВЂааЛЏМЦЫуЕШЯЕЭГЮЪЬтЃЌзЈУХбаОПФмЭЌЪБМцЙЫВЂжЇГжДѓЪ§ОнЛњЦїбЇЯАКЭДѓЪ§ОнЗжВМВЂааДІРэЕФвЛЬхЛЏДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃ
дкЙњФкЭтЕФЛњЦїбЇЯАКЭДѓЪ§ОнММЪѕЗНУцЕФЛсвщжаЃЌвбОЦЕЗБГіЯжДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЯрЙиЕФбаОПЙЄзїЃЌШчSparkMLlibЁЂIBMЕФSystemMLЁЂApache
FlinkЁЂGraphLabЁЂParameter ServerЁЂPetuumЕШЃЛДЫЭтЃЌЬкбЖЁЂАйЖШЕШЙњФкжјУћЛЅСЊЭјЦѓвЕвВЭЦГіСЫВЛЭЌЕФУцЯђДѓЪ§ОнЕФЗжВМЪНЛњЦїбЇЯАЯЕЭГЃЌШчЬкбЖЕФPeacockКЭMarianaДѓЙцФЃЛњЦїбЇЯАЯЕЭГЁЂАйЖШЕФELFКЭАйЖШЛњЦїбЇЯАдЦЦНЬЈBMLЁЃ
ЃЈ1ЃЉSpark MLlib
MLLibгыSparkЛЗОГећКЯКѓПЩЭъећНтОіДѓЪ§ОнЕФЗжВМЪНДцДЂЁЂВЂааЛЏМЦЫувдМАЩЯВуЕФЛњЦїбЇЯАЫуЗЈЩшМЦКЭЪЙгУЮЪЬтЃЌвђДЫЃЌПЩНЋЦфЪгЮЊвЛИіЛљБОЕФЛњЦїбЇЯАЯЕЭГЁЃФПЧАЦфвбОЯђЩЯВуЬсЙЉЖржжгХЛЏЗНЗЈЁЂЗжРрЫуЗЈЁЂЛиЙщЫуЗЈЁЂЭЦМіЫуЗЈЁЂОлРрЫуЗЈЁЃЕЋЦфЫуЗЈЪ§ФПКЭНгПкгаЯоЃЌФбвдЭъШЋТњзугУЛЇИїжжИїбљЕФашЧѓЃЌЧвзїЮЊвЛИіЫуЗЈПтЃЌгУЛЇФбвдЖдФкВПЫуЗЈНјааЩюВуЖЈжЦгХЛЏЁЃвђДЫЃЌЦфдкСщЛюадЗНУцШдШЛДцдкВЛзуЁЃ
ЃЈ2ЃЉSystemML
SystemML[14,15]ЪЧгЩIBMWaston Research Center КЭIBM Almaden
Research CenterСЊКЯбаЗЂЕФвЛПюДѓЪ§ОнбЇЯАЯЕЭГЁЃЖдгУЛЇЬсЙЉСЫвЛИіРрЫЦгкRгябдЕФИпВуЩљУїЪНгябдЃЌЛљгкетжжгябдБраДЕФГЬађПЩвдБЛздЖЏБрвызЊЛЏЮЊMapReduceзївЕдкHadoopМЏШКЩЯдЫааЁЃетжжИпВугябдЬсЙЉСЫДѓСПЕФМрЖНКЭЗЧМрЖНЕФЛњЦїбЇЯАЫуЗЈЫљашвЊЕФЯпадДњЪ§ВйзїЫузгЃЌАќРЈИпВуЫузгHOPЃЈhigh-leveloperatorЃЉКЭЕзВуЫузгLOPЃЈlow-level
operatorЃЉЁЃSystemMLзюДѓЕФгХЪЦЪЧЦфОпгаНЯКУЕФПЩБрГЬадКЭвзгУадЃЌгУЛЇВЛашвЊОпБИШЮКЮЗжВМЪНЯЕЭГЕФИХФюЛђБрГЬОбщЃЌМДПЩРћгУЦфаДГіПЩРЉеЙЕФЛњЦїбЇЯАЫуЗЈЃЛЦфзюДѓЕФШБЕудкгкЕзВуМЦЫуЦНЬЈЕЅвЛЃЌжЛВЩгУСЫMapReduceзїЮЊЕзВуЗжВМЪНжДааЦНЬЈЃЌЖјЕзВуЕФMapReduceзївЕБОЩэжДааадФмВЂВЛИпЃЌНќФъРДгПЯжГіЕФИпаЇЗжВМЪНМЦЫуПђМмШчSparkЁЂFlinkЕШЃЌдкжкЖрадФмжИБъЩЯдЖдЖИпгкMapReduceЁЃ
ЃЈ3ЃЉApache Flink
Apache Flink[19]ЪЧгЩХЗжоЕФЖрУћбаОПепКЭЖрМвзЪжњЕЅЮЛЃЈШчEIT1ICT LabsЁЂDFG2ЁЂIBMЁЂOracleЁЂHPЕШЃЉСЊКЯбаЗЂЕФвЛПюПЊдДЕФВЂааЛЏЪ§ОнЗжЮіШэМўеЛЃЌЯюФПдчЦкЕФУћГЦЪЧStratosphereЁЃОЙ§вЛЖЮЪБМфЕФЗЂеЙЃЌФПЧАвбОГЩЮЊApacheПЊдДЯюФПЁЃFlinkЭЌбљвтЪЖЕНЃЌЪ§ОнЗжЮіШЫдБдкЗжВМЪНЯЕЭГЩЯБраДДѓЪ§ОнЗжЮіЫуЗЈЪБЃЌашвЊгаДѓСПЕФОЋСІКФЗбдкЗжВМЪНГЬађЕїЪдвдМАЕзВуЕїгХЩЯЁЃЮЊСЫЪЙЪ§ОнЗжЮіШЫдБФмЙЛдкЮоашЙЫМАИїжжВЂааЛЏгХЛЏЮЪЬтЕФЧщПіЯТОЭПЩвдНјааЩюЖШЪ§ОнЗжЮіЃЌFlinkЬсЙЉСЫвЛПюЪ§ОнЗжЮіеЛЪНШэМўЁЃЫќЯђгУЛЇЬсЙЉСЫвЛжжзЈгУЕФНХБОЪНгябдMeteorScriptЃЌВЂЧвЛсздЖЏНЋЛљгкИУгябдПЊЗЂЕФГЬађзЊЛЛЕНЕзВуЕФЗжВМЪНМЦЫуЦНЬЈNepheleЩЯ[20]ЁЃгЩгкЦфзЈгУадгябдВЛЙЛЦеМАЃЌФПЧАЯЕЭГЖдгябдНгПкгжзіСЫИќЖрЕФРЉГфЃЌжЇГжJavaЁЂScalaЕШгябдЁЃFlinkЯюФПЕФгХЪЦдкгкЦфДгЩЯЕНЯТЬсЙЉСЫвЛећЬзЭъећЕФеЛЪННтОіЗНАИЃЌЪдЭМЮЊгУЛЇЬсЙЉвзгкЪЙгУЕФЪ§ОнЗжЮіЯЕЭГЃЌЭЌЪБЭЈЙ§вЛаЉБрвыгХЛЏЪжЖЮОЁПЩФмЕиЬсЩ§ГЬађжДааЕФадФмЃЛЦфШБЕудкгкЦфЕзВуЪЧзЈгУЕФЕЅвЛЛЏМЦЫуЦНЬЈЃЌгыФПЧАЦеБщЪЙгУЕФжїСїДѓЪ§ОнЦНЬЈHadoopКЭSparkЩаЮДФмМЏГЩЪЙгУЃЌЧвЩЯВуЕФгябдНгПкВувВУЛгаАќКЌЯждкЪ§ОнЗжЮіЪІЙуЮЊЪЙгУЕФRЁЂPythonЕШгябдНгПкЁЃ
ЃЈ4ЃЉGraphLab
GraphLab[16]ЪЧCMUПЊЗЂЕФвЛИівдЖЅЕуЮЊМЦЫуЕЅдЊЕФДѓЙцФЃЭМДІРэЯЕЭГЃЌЪЧвЛИіЛљгкЭМФЃаЭГщЯѓЕФЛњЦїбЇЯАЯЕЭГЁЃЩшМЦГѕжджївЊЪЧНтОіОпгавдЯТЬиЕуЕФЛњЦїбЇЯАЮЪЬтЃКгаОжВПвРРЕЕФЯЁЪшЪ§ОнМЏЁЂЕќДњПЩЪеСВЁЂвьВНжДааЁЃЮЊСЫЪЕЯжетИіФПБъЃЌGraphLabАбЪ§ОнжЎМфЕФвРРЕЙиЯЕГщЯѓГЩGraphНсЙЙЃЌвдЖЅЕуЮЊМЦЫуЕЅдЊЃЌНЋЫуЗЈЕФжДааЙ§ГЬГщЯѓГЩУПИіЖЅЕуЩЯЕФGASЃЈgatherЁЂapplyЁЂscatterЃЉЙ§ГЬЃЌЦфВЂааЕФКЫаФЫМЯыЪЧЖрИіЖЅЕуЭЌЪБжДааЁЃGraphLabЕФгХЕуЪЧФмЙЛИпаЇЕиДІРэДѓЙцФЃЭМЫуЗЈЮЪЬтЛђепПЩЙщНсЮЊЭМЮЪЬтЕФЛњЦїбЇЯАКЭЪ§ОнЭкОђЫуЗЈЮЪЬтЃЛЦфШБЕудкгкЬсЙЉЕФНгПкЯИНкБШНЯИДдгЃЌЖдгкЦеЭЈЕФЪ§ОнЗжЮіГЬађдБЖјбдЃЌгаНЯДѓЕФЪЙгУФбЖШЁЃ
ЃЈ5ЃЉParameterServerгыPetuum
КмЖрЛњЦїбЇЯАЫуЗЈГЃГЃвЊНтОібЇЯАбЕСЗЙ§ГЬжаФЃаЭВЮЪ§ЕФИпаЇДцДЂгыИќаТЮЪЬтЁЃЮЊСЫгааЇгІЖдКЭТњзуДѓЪ§ОнГЁОАЯТетРрЛњЦїбЇЯАЫуЗЈЕФашвЊЃЌбаОПепЬсГіСЫвЛжжГЦЮЊParameterServerЕФПђМм[17]ЃЌЬсЙЉСЫвЛИіЗжВМЪНШЋОжФЃаЭВЮЪ§ДцДЂКЭЗУЮЪНгПкЃЌФЃаЭВЮЪ§ДцДЂдкЖрЬЈЗўЮёЦїЃЈserverЃЉжаЃЌЙЄзїНкЕуЃЈworkerЃЉПЩвдЭЈЙ§ЭјТчЗУЮЪAPIЗНБуЕиЖСШЁШЋОжВЮЪ§ЁЃ
Li MuЕШШЫПЊЗЂСЫвЛЬзЛљгкParameterServerПђМмЕФЗжВМЪНЛњЦїбЇЯАЯЕЭГ[17]ЃЌИУЯЕЭГгЩвЛИіЗўЮёЦїзщЃЈserver
groupЃЉКЭЖрИіЙЄзїзщЃЈworker groupЃЉЙЙГЩЁЃЦфжаЃЌЗўЮёЦїзщжаАќРЈвЛИіЗўЮёЦїЙмРэЃЈservermanagerЃЉНкЕуКЭЖрИіЗўЮёЦїНкЕуЁЃУПИіЗўЮёЦїНкЕуДцДЂВПЗжШЋОжЙВЯэВЮЪ§ЃЛЗўЮёЦїЙмРэНкЕугУРДДцДЂЗўЮёЦїНкЕуЕФдЊаХЯЂЃЌВЂЭЈЙ§аФЬјЛњжЦЙмРэЫљгаЗўЮёЦїЁЃдкИУЯЕЭГжаЃЌУПИіЙЄзїзщАќКЌвЛИіШЮЮёЕїЖШЦїЃЈtaskschedulerЃЉКЭЖрИіЙЄзїНкЕуЃЌЙЄзїНкЕужЛгыЗўЮёЦїНкЕуЭЈаХЛёШЁШЋОжВЮЪ§вдМАЭЦЫЭОжВПИќаТЃЌВЛЭЌЕФЙЄзїзщПЩвдЭЌЪБдЫааВЛЭЌЕФгІгУЁЃParameterServerЕФгХЕуЪЧЮЊДѓЙцФЃЛњЦїбЇЯАЬсЙЉСЫЗЧГЃСщЛюЕФФЃаЭВЮЪ§ЕїгХКЭПижЦЛњжЦЃЛШБЕуЪЧШБЩйЖдДѓЙцФЃЛњЦїбЇЯАЪБЕФЪ§ОнМАБрГЬМЦЫуФЃаЭЕФИпВуГщЯѓЃЌЪЙгУНЯЮЊЗБЫіЃЌЭЈГЃБШНЯЪЪКЯгкЛњЦїбЇЯАЫуЗЈбаОПепЛђепашвЊЭЈЙ§ЕїећВЮЪ§ЩюЖШгХЛЏЛњЦїбЇЯАЫуЗЈЕФЪ§ОнЗжЮіГЬађдБЪЙгУЁЃ
ЙњМЪжјУћЕФЛњЦїбЇЯАзЈМвЁЂУРЙњПЈФЭЛљУЗТЁДѓбЇЛњЦїбЇЯАЯЕEricXingНЬЪкЪЧДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФГЋЕМепЁЃЫћШЯЮЊЃЌДЋЭГЕФЛњЦїбЇЯАбаОПЙ§гкМђЛЏЛњЦїбЇЯАЫуЗЈБОЩэЕФЮЪЬтвдМАДѓЙцФЃЪ§ОнЛњЦїбЇЯАДцдкЕФЯЕЭГЮЪЬт[21]ЁЃгЩгкДѓЙцФЃЛњЦїбЇЯАДцдкКмЖраТЕФЬєеНЃЌНќМИФъРДжївЊжТСІгкДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФбаОПЃЌВЂСьЕМЦфSAILINGЪЕбщЪвбаОПЪЕЯжСЫДѓЪ§ОнбЇЯАЯЕЭГPetuum[18ЃЌ21]ЁЃPetuumвВЪЧвЛИіЛљгкParameter
ServerПђМмЕФЯЕЭГЃЌЙиМќзщМўАќРЈParameterServerКЭЕїЖШЦїЁЃPetuumЕФParameter
ServerжаЪЙгУSSPЃЈstale synchronous parallelЃЉвЛжТадФЃаЭЃЌдЪаэМЦЫуЫйЖШТ§ЕФНкЕуДгБОЛњЛКДцжаЖСШЁГТОЩЕФВЮЪ§жЕЃЌвдДЫДѓДѓНкЪЁЭјТчПЊЯњКЭЭјТчЕШД§ЪБМфЃЌЪЙЕУТ§ЛњЦїЕФДѓВПЗжЪБМфгУдкМЦЫуЖјВЛЪЧЕШД§ЩЯЁЃPetuumдкЪЙгУЩЯашвЊЫуЗЈЩшМЦепЖдЗжВМЪНЯЕЭГИХФюКЭЯЕЭГгавЛЖЈСЫНтЃЌЦфвзгУадШдгавЛЖЈЕФЯожЦЃЌЧвЦфЕзВуЪ§ОнДцДЂКЭВЂааМЦЫуПђМмгыЩЯВуЕФбЇЯАЫуЗЈВувдНєёюКЯЕФЗНЪНШЋВПздМКЪЕЯжЃЌЯЕЭГЪЕЯжИДдгадКЭДњМлНЯДѓЁЃ
ЃЈ6ЃЉЬкбЖPeacockгыMarianaЩюЖШбЇЯАЦНЬЈ
Peacock[3]ЪЧЬкбЖЙЋЫОбаЗЂЕФвЛИіДѓЙцФЃLDAжїЬтФЃаЭбЕСЗЯЕЭГЁЃИУЯЕЭГЭЈЙ§ВЂааМЦЫуПЩЖд10вкЁС1вкМЖБ№ЕФДѓЙцФЃОиеѓНјааЗжНтЃЌДгЖјДгКЃСПЮФЕЕбљБОЪ§ОнжабЇЯА10Эђ~100ЭђСПМЖЕФвўКЌгявхЁЃЮЊСЫЭъГЩДѓЙцФЃДІРэЃЌPeacockЛљгкМЊВМЫЙВЩбљЕФLDAбЕСЗЫуЗЈНјааСЫВЂааЛЏЩшМЦЃЌВЂЩшМЦЪЕЯжСЫвЛИіЭъећЕФОпгаДѓЙцФЃбљБОЪ§ОнДІРэФмСІЕФбЕСЗЯЕЭГЁЃPeacockвбЙуЗКгІгУдкЬкбЖЕФЮФБОгявхРэНтЁЂQQШКЭЦМіЁЂгУЛЇЩЬвЕаЫШЄЭкОђЁЂЯрЫЦгУЛЇРЉеЙЁЂЙуИцЕуЛїТЪзЊЛЏТЪдЄЙРЕШЖрИівЕЮёЪ§ОнжаЃЌЪЧвЛИізЈЮЊLDAВЂааЛЏМЦЫуЖјЖЈжЦЕФДѓЙцФЃбЕСЗЯЕЭГЃЌВЛЪЧвЛИіЭЈгУЛЏЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃ
ЮЊСЫЬсЙЉИќЮЊЙуЗКЕФДѓЙцФЃВЂааЛЏЛњЦїбЇЯАДІРэФмСІЃЌЬкбЖбаОПЙЙНЈСЫвЛИіГЦЮЊMarianaЕФЩюЖШбЇЯАЦНЬЈ[22]ЃЌИУЦНЬЈгЩ3ЬзДѓЙцФЃЩюЖШбЇЯАЯЕЭГЙЙГЩЃЌАќРЈЛљгкЖрGPUЕФЩюЖШЩёОЭјТчВЂааМЦЫуЯЕЭГMarianaDNNЁЂЛљгкЖрGPUЕФЩюЖШОэЛ§ЩёОЭјТчВЂааМЦЫуЯЕЭГMariana
CNNвдМАЛљгкCPUМЏШКЕФЩюЖШЩёОЭјТчВЂааМЦЫуЯЕЭГMariana ClusterЁЃMarianaПЩЬсЙЉЪ§ОнВЂааКЭФЃаЭВЂааМЦЫуЃЌЛљгкGPUКЭCPUМЏШКЬсЩ§ФЃаЭЙцФЃЃЌМгЫйбЕСЗадФмЁЃЦфжаЃЌMarianaDNNдкЬкбЖФкВПгУгкЮЂаХгявєЪЖБ№ЩљбЇФЃаЭбЕСЗЃЌПЩбЕСЗГЌЙ§1ЭђаЁЪБЕФгявєЪ§ОнЁЂГЌЙ§40вкЕФЪ§ОнбљБОвдМАГЌЙ§5
000ЭђЕФВЮЪ§ЃЌЯрЖдгкЕЅGPUЖјбдЃЌ6GPUПЩЪЕЯж4.6БЖЕФМгЫйБШЃЛЖјMarianaCNNгУгкЮЂаХЭМЯёЪЖБ№ЃЌПЩбЕСЗ2
000ИівдЩЯЕФЗжРрЁЂ300ЭђвдЩЯЕФЪ§ОнбљБОвдМАГЌЙ§6 000ЭђЕФВЮЪ§ЃЌЯрЖдгкЕЅGPUЖјбдЃЌ4GPUПЩЪЕЯж2.5БЖЕФМгЫйБШЃЌдкЭМЮФРраЇЙћЙуИцЕуЛїТЪЬсЩ§ЗНУцвВШЁЕУГѕВНгІгУЃЛMarianaClusterЪЕЯжСЫвЛИіЛљгкParameter
ServerФЃаЭЕФДѓЙцФЃЭЈгУЛЏЛњЦїбЇЯАКЭбЕСЗЯЕЭГЃЌжївЊгУгкНјааДѓЙцФЃЙуИцВЂааЛЏбЕСЗЃЌЭъГЩЙуИцЕуЛїТЪдЄЙРФЃаЭбЕСЗКЭЙуИцЕуЛїадФмгХЛЏЁЃ
ЃЈ7ЃЉАйЖШELFгыАйЖШЛњЦїбЇЯАдЦЦНЬЈBML
АйЖШЙЋЫОбаЗЂСЫвЛИіДѓЙцФЃЗжВМЪНЛњЦїбЇЯАПђМмКЭЯЕЭГELFЃЈessential learningframeworkЃЉ[23]ЁЃELFЪЧвЛИіЛљгкParameter
ServerФЃаЭЕФЭЈгУЛЏДѓЙцФЃЛњЦїбЇЯАЯЕЭГЃЌПЩдЪаэгУЛЇЗНБуПьЫйЕиЩшМЦЪЕЯжДѓЪ§ОнЛњЦїбЇЯАЫуЗЈЃЌдкЯЕЭГЩшМЦЩЯЮќЪеСЫHadoopЁЂSparkКЭMPIЕШДѓЪ§ОнЦНЬЈЕФгХЕуЃЌгУРрЫЦгкSparkЕФШЋФкДцDAGМЦЫув§ЧцЃЌПЩЛљгкЪ§ОнСїЕФБрГЬФЃЪНЃЌЭЈЙ§ИпЖШГщЯѓЕФБрГЬНгПкЃЌШУгУЛЇЗНБуЕиЭъГЩИїжжЛњЦїбЇЯАЫуЗЈЕФВЂааЛЏЩшМЦКЭПьЫйМЦЫуЁЃ
дкELFЕФЛљДЁЩЯЃЌАйЖШНјвЛВНПЊЗЂСЫвЛИіЛњЦїбЇЯАдЦЦНЬЈBMLЃЈBaidumachine learningЃЉЃЌИУЦНЬЈжЇГжЗсИЛЕФЛњЦїбЇЯАЫуЗЈЃЌПЩжЇГж20ЖржжДѓЙцФЃВЂааЛњЦїбЇЯАЫуЗЈЃЌЬсЙЉАќРЈЪ§ОндЄДІРэЫуЗЈЁЂЗжРрЫуЗЈЁЂОлРрЫуЗЈЁЂжїЬтФЃаЭЁЂЭЦМіЫуЗЈЁЂЩюЖШбЇЯАЁЂађСаФЃаЭЁЂдкЯпбЇЯАдкФкЕФИїжжЛњЦїбЇЯАЫуЗЈжЇГжЃЌВЂЭЈЙ§ЗжВМКЭВЂааЛЏМЦЫуЪЕЯжгХвьЕФМЦЫуадФмЁЃBMLдкАйЖШФкВПЕФвЕЮёЯЕЭГжаОРњСЫЯпЩЯДѓЙцФЃЪЙгУВПЪ№ПМбщЃЌГадиЙЋЫОФкИїжжживЊЕФдкЯпвЕЮёЯпгІгУЃЌАќРЈЗяГВЙуИцCTRдЄЙРЁЂЫбЫїLTRХХУћЕШЁЃ
6 ПчЦНЬЈЭГвЛДѓЪ§ОнЛњЦїбЇЯАЯЕЭГOctopusЕФбаОПЩшМЦ
6.1 OctopusЕФЛљБОЩшМЦЫМЯы
ЩЯЪіОјДѓЖрЪ§ДѓЪ§ОнЛњЦїбЇЯАЗНЗЈКЭЯЕЭГЖМЪЧЛљгкЬиЖЈЦНЬЈЙЙНЈЕФЃЌФбвдМЏГЩКЭМцШнЯжгаКЭЮДРДГіЯжЕФЖржжДѓЪ§ОнДІРэв§ЧцКЭЦНЬЈЁЃЯжЪЕЪРНчжаЕФИїжжДѓЪ§ОнЗжЮіДІРэгІгУЭЈГЃЛсгаВЛЭЌЕФЗжЮіДІРэашЧѓКЭЬиеїЃЌР§ШчЃЌгааЉПЩФмЪЧМЋДѓЙцФЃЪ§ОнЕФРыЯпЗжЮіДІРэЃЌгааЉПЩФмЪЧвЊЧѓИпЪЕЪБадЯьгІЕФСЊЛњЗжЮіДІРэЃЌетаЉВЛЭЌЕФЗжЮіашЧѓвЊЧѓЕзВугаВЛЭЌЬиадЕФДѓЪ§ОнДІРэЦНЬЈжЇГжЃЛДЫЭтЃЌЫцзХДѓЪ§ОнДІРэММЪѕКЭЦНЬЈЕФВЛЖЯЗЂеЙЃЌФПЧАКЭЮДРДВЛЖЯгааТЕФДѓЪ§ОнБрГЬЗНЗЈКЭДІРэЦНЬЈГіЯжЁЃвђДЫЃЌЦѓвЕФкашвЊНЋЦфдгаЦНЬЈЩЯвбОПЊЗЂКУЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЃЌИФаДКЭвЦжВЕНаТЕФЦНЬЈЩЯЃЌетНЋИјЦѓвЕДјРДКмДѓЕФжиИДадРЭЖЏКЭПЊЗЂИКЕЃЁЃ
ЮЊДЫЃЌвЛИіРэЯыЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЛЙашвЊгЕгаФмЙЛжЇГжЯжгаКЭЮДРДГіЯжЕФВЛЭЌДѓЪ§ОнДІРэЦНЬЈЕФФмСІЃЌЪЕЯжПчЦНЬЈДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЕФЩшМЦФмСІЃЌДяЕНЁАWriteOnceЃЌRun
AnywhereЁБЕФПчЦНЬЈЫуЗЈЩшМЦКЭдЫааФПБъЁЃ
еыЖдДѓЪ§ОнЛњЦїбЇЯАЯЕЭГашвЊжиЕубаОПНтОіЕФМЦЫуадФмвдМАПЩБрГЬадгывзгУадЮЪЬтЃЌВЂПМТЧЩЯЪіЕФПчЦНЬЈашЧѓЬиадЃЌФЯОЉДѓбЇPASAДѓЪ§ОнЪЕбщЪве§дкбаОПЩшМЦвЛИіПчЦНЬЈДѓЪ§ОнЛњЦїбЇЯАЕФЭГвЛБрГЬФЃаЭКЭЯЕЭГЦНЬЈЁЃИУЯЕЭГЛљгкОиеѓБрГЬМЦЫуФЃаЭЃЌНсКЯRБрГЬгябдКЭБрГЬЗНЗЈЃЌЩшМЦЬсЙЉвЛИіПчЦНЬЈЕФЭГвЛБрГЬМЦЫуПђМмЃЌзюжебаОПЪЕЯжвЛИіПчЦНЬЈДѓЪ§ОнЛњЦїбЇЯАЯЕЭГOctopusЃЈДѓеТгуЃЉЁЃ
ЗжЮіЗЂЯжЃЌЛњЦїбЇЯАКЭЪ§ОнЭкОђЫуЗЈжаЕФжїЬхМЦЫуДѓЖрПЩБэЪОЮЊОиеѓЛђЯђСПдЫЫуЃЌетЭЈГЃвВЪЧЫуЗЈжазюКФЪБЕФВПЗжЁЃОиеѓВйзївВЪЧЛњЦїбЇЯАбаОПепгУРДУшЪіЮЪЬтКЭЫуЗЈзюЮЊздШЛКЭГЃгУЕФЗНЪНЃЌЛљгкОиеѓПЩвдБэЪОКЭПЬЛДѓЖрЪ§ЪЕМЪгІгУжаЩцМАЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЮЪЬтЁЃЛљгкетбљЕФЪТЪЕЃЌЮЊСЫИјДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЬсЙЉвЛжжздШЛКЭЭГвЛЕФБрГЬМЦЫуФЃаЭКЭБрГЬЗНЗЈЃЌРрЫЦгкMapReduceжаЛљгкЪ§ОнМЧТМСаБэЕФГщЯѓБрГЬМЦЫуФЃаЭЃЌНЋбаОПНЈСЂвЛжжЛљгкОиеѓФЃаЭЕФГщЯѓБрГЬМЦЫуФЃаЭЃЌвдДЫзїЮЊДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЩшМЦЕФЭГвЛБрГЬМЦЫуФЃаЭКЭНгПкЁЃ
OctopusЪЧвЛИіИпВуЕФДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЭГвЛБрГЬФЃаЭКЭЯЕЭГЦНЬЈЃЌдЪаэЪ§ОнЗжЮіКЭДѓЪ§ОнгІгУПЊЗЂГЬађдБЧсЫЩЕиЩшМЦКЭПЊЗЂИїжжДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈгыгІгУГЬађЁЃЭЈЙ§ЬсЙЉЛљгкОиеѓЕФЭГвЛБрГЬМЦЫуФЃаЭЃЌЪЙгУЛљгкRгябдЕФЪ§ОнЗжЮіГЬађЩшМЦгябдКЭГЬађЩшМЦЗНЗЈЃЌдЪаэгУЛЇЗНБуЕиБраДКЭдЫааГЃЙцЕФRгябдГЬађЃЌЖјЮоашСЫНтЕзВуДѓЪ§ОнЦНЬЈЕФЗжВМКЭВЂааЛЏБрГЬМЦЫужЊЪЖЃЌЪЙЕзВуЕФЗжВМВЂааМЦЫуПђМмКЭДѓЪ§ОнЦНЬЈЖдгУЛЇЭъШЋЭИУїЃЛЕзВуЦНЬЈЩЯЃЌЭЈЙ§СМКУЕФЯЕЭГВуГщЯѓЃЌПЩвдПьЫйМЏГЩHadoopКЭSparkЕШЭЈгУДѓЪ§ОнВЂааМЦЫуПђМмКЭЯЕЭГЦНЬЈЃЌЖјЧвГЬађНіашБраДвЛДЮЃЌВЛашвЊгаШЮКЮаоИФМДПЩИљОнашвЊбЁдёВЂЦНЛЌдЫаагкШЮКЮвЛИіЦНЬЈЃЌДгЖјЪЕЯжЁАWriteOnceЃЌRun
AnywhereЁБЕФПчЦНЬЈЬиадЁЃ
6.2 ЛљгкОиеѓФЃаЭЕФЭГвЛБрГЬКЭМЦЫуФЃаЭ
ЗжЮіЗЂЯжЃЌвЛЗНУцЃЌДѓЪ§ОнЛњЦїбЇЯАЫуЗЈжаЕФжїЬхМЦЫуКмЖрПЩБэЪОЮЊОиеѓЛђЯђСПдЫЫуЃЈЯђСППЩЪгЮЊЭЫЛЏЮЊ1ЮЌЕФЬиЪтОиеѓЃЉЃЌЭЈГЃетвВЪЧЫуЗЈжазюКФЪБЕФВПЗжЃЛСэвЛЗНУцЃЌОиеѓВйзїЭЈГЃвВЪЧЛњЦїбЇЯАбаОПепгУРДУшЪіЮЪЬтКЭЫуЗЈзюЮЊздШЛКЭГЃгУЕФЗНЪНЁЃР§ШчЃЌбЕСЗбљБОЬиеїжЕЕФЙщвЛЛЏЭљЭљЪЧЭЈЙ§ЖдОиеѓааЛђСаЧѓКЭКѓдйГ§вдИУЧѓКЭЕФжЕЃЛKNNЫуЗЈЃЈзюНќСкЫуЗЈЃЉЕФКЫаФВйзїЪЧОиеѓЯрМѕКЭОиеѓдЊЫиЧѓЦНЗНВйзїЃЛPCAЃЈжїГЩЗжЗжЮіЃЉЫуЗЈПЩвдЭЈЙ§ОиеѓЯрГЫЛђОиеѓЕФSVDЗжНтНјааЧѓНтЃЛзюаЁЖўГЫЗЈЕФНтЮіЗЈЩцМАОиеѓЕФЯрГЫКЭЧѓФцВйзїЃЛЛЅСЊЭјЦѓвЕЭЦМіЯЕЭГжаЃЌЯрЫЦадЗжЮіЕФКЫаФЪЧИпДяЪ§вкгУЛЇГЫвдЪ§вкЮяЦЗЕФОиеѓЗжНтМЦЫуЮЪЬтЃЛЖјЬкбЖPeacockжїЬтФЃаЭбЕСЗЯЕЭГдђЩцМАЪ§ЪЎвкЮФЕЕГЫвдЪ§АйЭђДЪЛуЕФОоДѓОиеѓМЦЫуЮЪЬтЃЛдкаХЯЂМьЫїСьгђЃЌжјУћЕФPageRankЫуЗЈвВПЩвдБэЪОГЩОиеѓЕФЕќДњЯрГЫЃЛЩчЛсЭјТчжаПЩвдЭЈЙ§МЦЫуХѓгбЙиЯЕОиеѓЕФУнЃЌДгЖјНјааЛљгкЙВЭЌКУгбЕФЭЦМіЃЛЕчзгЩЬЮёжаПЩвдЭЈЙ§ЖдгУЛЇЖдЩЬЦЗЕФЙКТђМЧТМНјааОиеѓЗжНтЃЌЕУЕНЩЬЦЗКЭгУЛЇЕФОлРрВЂЗжЮіЦфЧБдкгявхжїЬтФЃаЭЁЃКмЖрЦфЫћЕФЪ§ОнЗжЮіКЭДѓЪ§ОнПЦбЇМЦЫуЮЪЬтвВГЃГЃвЊЛљгкОиеѓФЃаЭЭъГЩЮЪЬтЕФУшЪіКЭЗжЮіМЦЫуЙ§ГЬЁЃвђДЫЃЌЛљгкОиеѓПЩвдБэЪОКЭПЬЛДѓЖрЪ§ЪЕМЪгІгУжаЩцМАЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЮЪЬтЁЃ
ЛљгкетбљЕФЪТЪЕЃЌЮЊСЫИјДѓЪ§ОнЛњЦїбЇЯАЬсЙЉвЛжжЭГвЛЕФБрГЬМЦЫуФЃаЭвдМАБрГЬЗНЗЈЃЌРрЫЦгкMapReduceВЩгУСЫЛљгкЪ§ОнМЧТМСаБэЕФГщЯѓБрГЬМЦЫуФЃаЭЃЌбаОПНЈСЂСЫвЛжжЛљгкОиеѓФЃаЭЕФГщЯѓБрГЬМЦЫуФЃаЭЃЌвдДЫзїЮЊДѓЪ§ОнЛњЦїбЇЯАЫуЗЈЩшМЦЕФЭГвЛБрГЬМЦЫуФЃаЭКЭНгПкЁЃ
етжжГщЯѓОиеѓБрГЬМЦЫуФЃаЭНЋГЩЮЊЭГвЛЛњЦїбЇЯАЫуЗЈЩшМЦКЭБрГЬМЦЫуЕФКЫаФЃЌЫќОпгаШчЯТ3ИіживЊзїгУЁЃ
ЛљгкЛњЦїбЇЯАКЭЪ§ОнЭкОђЫуЗЈжажїЬхМЦЫуДѓЖрПЩБэЪОЮЊОиеѓЛђЯђСПдЫЫуЕФЪТЪЕЃЌЮЊЪ§ОнЗжЮігУЛЇЬсЙЉвЛжжздШЛКЭЭГвЛЛЏЕФДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈНЈФЃКЭБэЪОЗНЗЈЁЃ
зїЮЊвЛИіИєРыКЭНтёюЩЯВуЪ§ОнЗжЮіЫуЗЈгыЯТВуИїжжДѓЪ§ОнЦНЬЈЕФжаМфНгПкЃЌЪЕЯжЕзВуЦНЬЈЖдЩЯВуГЬађдБМАЦфГЬађЕФЭИУїадЃЌвдДЫЬсИпЭГвЛЦНЬЈЖдЩЯВуГЬађдБЕФвзгУадЁЃ
ЮЊЪЕЯжЭГвЛДѓЪ§ОнЛњЦїбЇЯАЯЕЭГПЊЗХЪНМЏГЩПђМмЬсЙЉвЛжжНгПкБъзМЁЃеыЖдШЮвтвЛИіФтМЏГЩЪЙгУЕФЕзВуДѓЪ§ОнЦНЬЈЃЌжЛвЊзёееЫљНЈСЂЕФЭГвЛОиеѓБрГЬНгПкЃЌЪЕЯжвЛИіЭъГЩИУНгПкГЬађМЦЫуШЮЮёЕФЪЪХфЦїЛђВхМўЃЌМДПЩвдВЉВЩжкГЄКЭМцШнВЂаюЕФПЊЗХЪНПђМмЃЌСЌНгКЭМЏГЩЪЙгУИїжжжїСїЕФДѓЪ§ОнЦНЬЈЃЌЪЙЕУЩЯВуЕФЛњЦїбЇЯАЫуЗЈОпгаДІРэДѓЙцФЃЪ§ОнЕФФмСІЁЃ
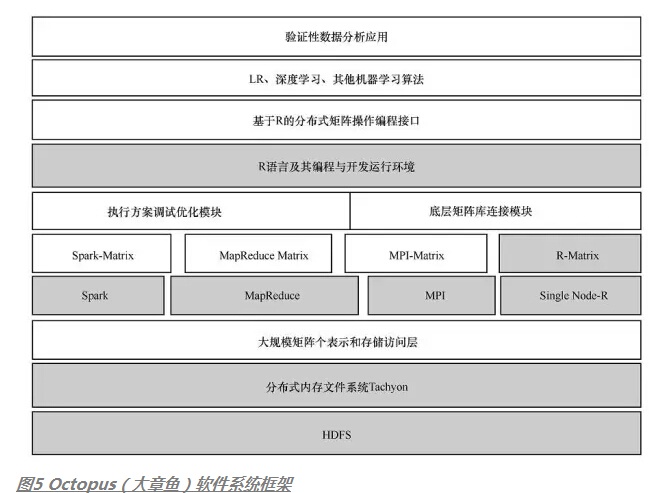
6.3 OctopusШэМўПђМмКЭЯЕЭГЩшМЦ
ШчЭМ5ЫљЪОЃЌOctopusЪЧвЛжжЛљгкСМКУЕФЯЕЭГГщЯѓЕФВуДЮЛЏЯЕЭГЁЃЦфзюЕзВуЪЧЗжВМЪНЮФМўЯЕЭГЃЌШчHDFSКЭЗжВМЪНФкДцЮФМўЯЕЭГTachyonЃЌЫќУЧБЛгУРДДцДЂКЭЫїв§ДѓЙцФЃЕФОиеѓЪ§ОнЁЃдкДцДЂВужЎЩЯЃЌOctopusПЩвдгУЖржжДѓЪ§ОнМЦЫув§ЧцКЭЕЅЛњRв§ЧцРДжДааВЛЭЌЙцФЃЕФОиеѓВйзїЁЃOctopusЬсЙЉИјгУЛЇЕФБрГЬAPIЪЧЛљгкRгябдЕФИпВуОиеѓМЦЫуНгПкЃЌЛљгкИУНгПкЃЌгУЛЇВЛашвЊСЫНтЗжВМКЭВЂааМЦЫуЯЕЭГжЊЪЖЃЌОЭПЩвдКмШнвзЕиЩшМЦЪЕЯжДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЛђгІгУЁЃ
6.4 OctopusЯЕЭГЕФММЪѕЬиеї
OctopusОпгавдЯТММЪѕЬиеїЁЃ
ЃЈ1ЃЉвзгкЪЙгУЕФИпВуБрГЬAPI
OctopusЬсЙЉИјгУЛЇвЛзщЛљгкRгябдЕФДѓЙцФЃОиеѓдЫЫуAPIЃЌГЦЮЊOctMatrixЁЃетаЉAPIЬсЙЉИїжжДѓЙцФЃЗжВМЪНОиеѓМЦЫуВйзїЃЌЦфаЮЪНЩЯгыБъзМRгябджаЕФЕЅЛњОиеѓ/ЯђСПВйзїAPIКмЯрЫЦЁЃГЬађдБПЩЛљгкетаЉОиеѓдЫЫуНгПкЃЌгУRгябдПьЫйБраДИїжжЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЁЃГ§СЫзюГЃгУЕФДѓЙцФЃОиеѓГЫЗЈЃЌOctopusвВЬсЙЉСЫЦфЫћИїжжОиеѓВйзїЃЌШчОиеѓгыОиеѓЕФМгЗЈКЭМѕЗЈЁЂОиеѓдЊЫиМЖБ№ЕФГЫЗЈКЭГ§ЗЈЁЂзгОиеѓдЫЫуЕШЁЃетаЉAPIЖЈвхСЫИпВуОиеѓВйзїЗћЃЈoperatorЃЉКЭВйзїЃЈoperationЃЉЃЌвђДЫЪьЯЄRБрГЬгябдКЭБрГЬЗНЗЈЕФгУЛЇПЩвдКмШнвзЕигУЦфБрГЬЪЕЯжДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЃЌЧвВЛашвЊСЫНтЕзВуДѓЪ§ОнДІРэЦНЬЈМАЦфВЂааЛЏБрГЬЗНЗЈЁЃ
ЃЈ2ЃЉвЛДЮБраДЃЌЫцДІдЫаа
гУOctopusБраДЭъГЩЕФЫуЗЈКЭГЬађЃЌПЩвддЫаадкВЛЭЌЕФЕзВуДѓЪ§ОнМЦЫув§ЧцКЭЦНЬЈЩЯЁЃгУOctMatrixAPIЪЕЯжЕФЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЃЌгУЛЇПЩвддкЕЅЛњRЩЯгУаЁЪ§ОнНјааВтЪдЃЌВЛашвЊаоИФДњТыОЭПЩвдгУДѓЪ§ОндкЕзВуЕФДѓЪ§ОнМЦЫув§ЧцКЭЦНЬЈЩЯжДааЃЌжЛашвЊМђЕЅЧаЛЛЕзВуЕФДѓЪ§ОнМЦЫув§ЧцШчSparkЁЂHadoopMapReduceЛђMPIМДПЩЁЃДЫЭтЃЌOctopusЭЈЙ§ЬсЙЉЭЈгУНгПкПЩЪЕЯжЖдЕзВуВЛЭЌЮФМўЯЕЭГЕФМЏГЩЃЌВЂЪЕЯжЛљгкВЛЭЌЮФМўЯЕЭГЕФДѓЙцФЃОиеѓЪ§ОнДцДЂЗУЮЪНгПкЃЌАќРЈHDFSЁЂTachyonвдМАЛљгкЕЅЛњБОЕиЕФЮФМўЯЕЭГЁЃ
ЃЈ3ЃЉЮоЗьШкКЯRЩњЬЌЯЕЭГ
OctopusПЩдЫаагкБъзМЕФRЛЗОГЯТЃЌЪЕЯжгыRЛЗОГЕФЮоЗьШкКЯЃЌвђДЫПЩвдРћгУRЩњЬЌЯЕЭГжаЕФЗсИЛзЪдДЃЌБШШчЕкШ§ЗНRАќЁЃГ§СЫДЋЭГЕФОиеѓ/ЯђСПКЏЪ§ЃЌOctopusвВдкOctMatrixжаЬсЙЉapplyКЏЪ§ЃЌДЋШыapplyКЏЪ§ЕФВЮЪ§ПЩвдЪЧШЮвтЕФRКЏЪ§ЃЌАќРЈUDFЃЈuserdefined
functionЃЉЁЃЕБOctMatrixдЫаадкЗжВМЪНЛЗОГжаЪБЃЌКЏЪ§ВЮЪ§ПЩвддкМЏШКжаБЛгІгУгкOctMatrixЕФУПИідЊЫиЁЂУПааЛђУПСаЃЌКЏЪ§ВЮЪ§дкМЏШКЕФУПИіНкЕуВЂаажДааЁЃ
6.5 OctopusжаЗжВМЪНОиеѓМЦЫугХЛЏ
ДѓЙцФЃЪ§ОнЭЈГЃЛсЕМжТећИіЪ§ОнЗжЮіМЦЫуЪБМфЙ§ГЄЃЌФбвддкПЩНгЪмЕФЪБМфФкЭъГЩЗжЮіШЮЮёЃЌЮЊДЫашвЊНшжњгкЗжВМЪНКЭВЂааЛЏМЦЫуММЪѕЪЕЯжДѓЙцФЃЪ§ОнЗжЮіМЦЫуЪБЕФМгЫйКЭадФмЬсЩ§ЃЌвдЬсИпЪ§ОнЗжЮіЕФЯьгІЪБМфЁЃгЩгкВЩгУДѓЙцФЃОиеѓзїЮЊДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіЕФБрГЬМЦЫуНгПкЃЌдкЕзВуДѓЪ§ОнЦНЬЈЩЯЕФДѓЙцФЃОиеѓдЫЫуЕФадФмНЋжБНгЙиЯЕЕНЩЯВуЫуЗЈжДааЕФадФмЁЃЮЊДЫЃЌДѓЙцФЃОиеѓМЦЫуадФмгХЛЏЪЧашвЊжиЕубаОПНтОіЕФЙиМќММЪѕЮЪЬтжЎвЛЁЃ
дкЫљгаОиеѓМЦЫужаЃЌОиеѓГЫЗЈЪЧЪЙгУзюЖрЧвзюЮЊКФЪБЕФМЦЫуЃЌаэЖрОиеѓЕФвђзгЗжНтВйзївВЖМПЩвдгЩОиеѓГЫЗЈНќЫЦЪЕЯжЁЃвђДЫЃЌОиеѓГЫЗЈЕФгХЛЏЪЧећИіОиеѓМЦЫугХЛЏжазюЮЊживЊЕФЮЪЬтЁЃСНИіДѓЙцФЃОиеѓНјааЗжВМКЭВЂааЛЏЯрГЫдЫЫуЪБЃЌвЛИіживЊЮЪЬтЪЧШчКЮКЯРэЛЎЗжОиеѓЪ§ОнЃЌвдБуРћгУЖрИіМЦЫуНкЕуЗжВМКЭВЂааЛЏЕиЭъГЩМЦЫуЁЃВЛЭЌДѓаЁКЭаЮзДЕФОиеѓЃЌЦфЛЎЗжЗНЗЈПЩФмЛсдьГЩМЦЫуадФмЩЯЕФВювьЃЌР§ШчЃЌЗНаЮОиеѓгыГЄЬѕаЮОиеѓашвЊПМТЧВЛЭЌЕФЛЎЗжЗНЗЈЃЌЖјвЛИіДѓОиеѓгывЛИіаЁОиеѓЯрГЫЪБЃЌЕБаЁОиеѓПЩДцЗХдкЕЅНкЕуЕФФкДцжаЪБЃЌЖдаЁОиеѓПЩВЛНјааЛЎЗжЃЌЖјИФгУЙуВЅЗНЪННЋаЁОиеѓЗЂЫЭЕНУПИіМЦЫуНкЕуЩЯЃЌвдДЫЭъГЩСНИіОиеѓЕФдЫЫуЃЌетбљПЩвдБмУтДѓСПЕФЭјТчЪ§ОнДЋЪфЁЃвђДЫЃЌашвЊИљОнОиеѓЕФДѓаЁКЭаЮзДЃЌКЯРэЛЎЗжОиеѓЃЌвдБувдзюаЁЕФМЦЫуДњМлЭъГЩГЫЗЈдЫЫуЁЃ
Г§СЫВЛЭЌаЮзДКЭДѓаЁЕФОиеѓЛЎЗжВпТдгХЛЏЭтЃЌБЛЛЎЗжКѓТфЕНУПИіМЦЫуНкЕуЩЯЗжВМДІРэЕФзгОиеѓМЦЫувВашвЊНјаагХЛЏЁЃОиеѓГЫЗЈЪЧЕфаЭЕФМЦЫуУмМЏаЭШЮЮёВЂЧвДцдкаэЖрЕЅЛњЕФИпадФмЕФЯпадДњЪ§ПтЃЌШчBLASЁЂLapackКЭMKLЁЃгЩгкдкJVMжажДааЯпадДњЪ§МЦЫуадФмНЯЕЭЃЌOctopusНЋМЦЫуУмМЏЕФОиеѓМЦЫуДгJVMжаЭЈЙ§JNILoaderзАдиЕНБОЕиЯпадДњЪ§ПтЃЈШчBLASЁЂLapackЃЉжажДааЃЌетбљПЩЯджјМгЫйзгОиеѓЕФМЦЫуадФмЁЃ
6.6 OctopusЯЕЭГЕФБрГЬЪЙгУ
ЭМ6ЯдЪОСЫOctopusЯЕЭГЕФЪЙгУЗНЪНЁЃOctopusЪЙгУБъзМЕФRБрГЬКЭПЊЗЂЛЗОГЃЌдЪаэгУЛЇЪЙгУRгябдЃЌВЂЛљгкДѓЙцФЃОиеѓМЦЫуФЃаЭБраДИїжжЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЁЃЯЕЭГПЩЪЕЯжгыSparkЁЂHadoopMapReduceКЭMPIЕФМЏГЩЃЌЕзВуПЩЮоЗьЧаЛЛдЫаагкВЛЭЌЕФДѓЪ§ОнЦНЬЈЩЯЁЃЛљгкOctopusЫљЩшМЦЪЕЯжЕФЫуЗЈЛђГЬађДњТыЃЌЮоашаоИФМДПЩЦНЛЌЧаЛЛВЂдЫаагкЩЯЪіШЮвтвЛИіЕзВуДѓЪ§ОнМЦЫув§ЧцКЭЦНЬЈЩЯЃЌжЛвЊМђЕЅЕиаоИФГЬађДњТыжаЕФМЦЫув§ЧцРраЭбЁдёВЮЪ§МДПЩЁЃ
ЛљгкRгябдКЭГѕВНбаОПЩшМЦЕФOctopusЃЌЩшМЦЪЕЯжСЫЖрИіЕфаЭЕФЛњЦїбЇЯАЫуЗЈЃЌАќРЈLRЁЂSVMЁЂОлРрЁЂЩюЖШбЇЯАЕШЃЌвдбщжЄбаОПЩшМЦЕФдаЭЯЕЭГЕФгааЇадЁЃ
ЭМ7ЪЧЛљгкГЃЙцRгябдЫљЪЕЯжЕФLinearRegressionЫуЗЈгыЛљгкOctopusЫљЪЕЯжЕФLinear
RegressionЫуЗЈЕФЪОР§ДњТыЁЃгЩДњТыБШНЯПЩМћЃЌСНепдкаЮЪНЩЯЗЧГЃНгНќЃЌНідкгаЙиОиеѓдЫЫуЕїгУЕФAPIЩЯгаЮЂаЁВювьЁЃ

гЩЭМ7ПЩМћЃЌдкRгябджаЛљгкОиеѓНјааЛњЦїбЇЯАЕФЫуЗЈЩшМЦНЯЮЊМђНрКЭЗНБуЃЌLinearRegressionДњТыНіНіашвЊ20аазѓгвМДПЩЪЕЯжЭъећЕФЫуЗЈЁЃ
7 НсЪјгя
НќМИФъРДЃЌДѓЪ§ОнММЪѕЕФЗЂеЙЭЦЖЏСЫДѓЪ§ОнЛњЦїбЇЯАКЭжЧФмМЦЫуММЪѕЕФЗЂеЙШШГБЁЃДѓЪ§ОнЛњЦїбЇЯАВЛНіЪЧвЛИіЕЅДПЕФЛњЦїбЇЯАЮЪЬтЃЌИќЪЧвЛИіДѓЙцФЃЕФИДдгЯЕЭГЮЪЬтЃЛЪЧвЛИіЭЌЪБЩцМАЛњЦїбЇЯАКЭДѓЪ§ОнДІРэСНИіСьгђЕФНЛВцбаОППЮЬтЁЃвЊЪЕЯжгааЇЕФДѓЪ§ОнЛњЦїбЇЯАДІРэЃЌашвЊЙЙНЈвЛИіФмЭЌЪБжЇГжЛњЦїбЇЯАЫуЗЈЩшМЦКЭДѓЙцФЃЪ§ОнДІРэЕФвЛЬхЛЏДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЁЃ
БОЮФНщЩмСЫЙњФкЭтДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЕФЛљБОИХФюЁЂЛљБОбаОПЮЪЬтЁЂММЪѕЬиеїЁЂЯЕЭГЗжРрвдМАЕфаЭЯЕЭГЁЃдкДЫЛљДЁЩЯЃЌНјвЛВННщЩмСЫбаОПЩшМЦЕФПчЦНЬЈЭГвЛДѓЪ§ОнЛњЦїбЇЯАдаЭЯЕЭГOctopusЁЃЛљгкДѓЖрЪ§ЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈПЩБэЪОЮЊОиеѓдЫЫуЕФЪТЪЕЃЌOctopusВЩгУОиеѓФЃаЭзїЮЊДѓЪ§ОнЛњЦїбЇЯАКЭЪ§ОнЗжЮіГщЯѓБрГЬМЦЫуФЃаЭЃЌЬсЙЉСЫвЛИіЛљгкОиеѓЕФИпВуБрГЬФЃаЭКЭНгПкЃЌВЂЛљгкRгябдКЭПЊЗЂЛЗОГЯђгУЛЇЬсЙЉСЫвЛИіОиеѓдЫЫуRРЉеЙАќЃЌЮЊгУЛЇЬсЙЉПЩРЉеЙадКУЧввзгкЪЙгУЕФОиеѓдЫЫуВйзїЃЌдЪаэгУЛЇЛљгкЫљЬсЙЉЕФДѓЙцФЃОиеѓдЫЫуВйзїЃЌПьЫйЩшМЦЪЕЯжИїжжЛњЦїбЇЯАКЭЪ§ОнЗжЮіЫуЗЈЁЃOctopusФмдкЕзВуЮоЗьЕиМЏГЩКЭЪЙгУВЛЭЌЕФДѓЪ§ОнМЦЫув§ЧцКЭЦНЬЈЃЌЭъГЩДѓЪ§ОнЛњЦїбЇЯАЫуЗЈЕФЗжВМКЭВЂааЛЏжДааЃЌВЂжЇГжЕЅНкЕуRЛЗОГвдМАSparkЁЂHadoopMapReduceКЭMPIЕШЖржжДѓЪ§ОнМЦЫув§ЧцКЭЦНЬЈЃЌВЂФмЪЕЯжетаЉЦНЬЈМфЕФЮоЗьЧаЛЛЃЌЪЕЯжЁАWrite
OnceЃЌRun AnywhereЁБЕФПчЦНЬЈЬиеїЁЃОЭЮвУЧЫљжЊЃЌOctopusЪЧФПЧАЪРНчЩЯЕквЛИіОпгаПчЦНЬЈЬиадЃЌЭЌЪБЛЙФмЪЕЯжЕзВуДѓЪ§ОнЦНЬЈЖдЩЯВуГЬађдБЭИУїЛЏЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГбаОПЙЄзїЁЃ
е§ШчCCFДѓЪ§ОнзЈМвЮЏдБЛсЗЂВМЕФ2014ФъЁЖжаЙњДѓЪ§ОнММЪѕгыВњвЕЗЂеЙАзЦЄЪщЁЗжаЫљЫЕЃЌФПЧАДѓЪ§ОнЛњЦїбЇЯАЯЕЭГЩаДІдквЛИіГѕЦкЕФЬНЫїКЭбаОПНзЖЮЃЌОЁЙмЙњФкЭтвбОгаВЛЩйбаОППЊЗЂЙЄзїЃЌЕЋбаОПЩшМЦИпаЇЁЂПЩРЉеЙЧввзгкЪЙгУЕФДѓЪ§ОнЛњЦїбЇЯАЯЕЭГШдУцСйжюЖрЕФММЪѕЬєеНЁЃвђДЫЃЌДѓЪ§ОнЛњЦїбЇЯАЯЕЭГНЋЪЧФПЧАКЭЮДРДМИФъЕФШШЕубаОПСьгђЃЌЙЄвЕНчКЭбЇЪѕНчЖМНЋГжајЕиЭЖШыЯрЕБЖрЕФзЪдДНјааЩюШыЕФбаОППЊЗЂЙЄзїЁЃ
ЭЌбљЃЌЫфШЛГѕВНбаОПЩшМЦСЫПчЦНЬЈДѓЪ§ОнЛњЦїбЇЯАЯЕЭГOctopusЃЌЕЋЦфжаШдШЛгаДѓСПашвЊНјвЛВНЩюШыбаОПНтОіКЭЭъЩЦЕФММЪѕЮЪЬтЃЌР§ШчДѓЙцФЃОиеѓдЫЫуЕФЩюЖШгХЛЏЁЂЯЁЪшОиеѓЕФДцДЂЙмРэКЭМЦЫугХЛЏЁЂвьЙЙДѓЪ§ОнДІРэЦНЬЈЛЗОГЯТВЛЭЌОиеѓМЦЫуЪБЕФЦНЬЈздЖЏбЁдёЁЂЛљгкОиеѓМЦЫуБэДяЪНКЭМЦЫуСїЭМЕФМЦЫугХЛЏЕШЁЃДЫЭтЃЌНігаОиеѓМЦЫуФЃаЭЛЙВЛФмТњзуЫљгаЕФДѓЪ§ОнЛњЦїбЇЯАМЦЫуашЧѓЃЌЛЙашвЊПМТЧЦфЫћМЦЫуФЃаЭЃЌШчЭМФЃаЭКЭВЮЪ§ФЃаЭЃЈparameterserverЃЉЕФЛьКЯЪЙгУЃЌаЮГЩвЛИіФмТњзуИїжжДѓЪ§ОнЛњЦїбЇЯАЫуЗЈЩшМЦашЧѓЕФзлКЯЯЕЭГЁЃ |









