| БрМЭЦМі: |
БОЮФРДздгкpythonГЬађдБЃЌетЦЊЮФеТжївЊЩцМАЫќЕФPythonАцБОЃЌВЂЙизЂПтЕФАВзАЁЂЛљБОЕФЕЭМЖзщМўЃЌвдМАДгЭЗЙЙНЈвЛИіЧАРЁЩёОЭјТчЃЌвдБудкеце§ЕФЪ§ОнМЏЩЯбЇЯАЁЃ
|
|
TensorFlowЪЧЛњЦїбЇЯАгІгУЕФвЛИіПЊдДПтЁЃетЪЧЙШИшДѓФдЕФЕкЖўДњЯЕЭГЃЌШЁДњБедДЯюФПDistBeliefЃЌВЂБЛЙШИшЭЌЪБгУгкбаОПКЭВњЦЗЁЃTensorFlowгІгУПЩвдгУМИжжгябдЪщаДЃКPythonЃЌGoЃЌJavaКЭCЁЃетЦЊЮФеТжївЊЩцМАЫќЕФPythonАцБОЃЌВЂЙизЂПтЕФАВзАЁЂЛљБОЕФЕЭМЖзщМўЃЌвдМАДгЭЗЙЙНЈвЛИіЧАРЁЩёОЭјТчЃЌвдБудкеце§ЕФЪ§ОнМЏЩЯбЇЯАЁЃ
ЩюВубЇЯАЩёОЭјТчЕФбЕСЗЪБМфЭљЭљЪЧЦфдкИДдгГЁОАгІгУЪБгіЕНЕФвЛИіЦПОБЁЃгЩгкЩёОЭјТчЃЌвдМАЦфЫћЕФбЇЯАЫуЗЈЃЌЭЈГЃЖМдкгУОиеѓГЫЗЈЃЌгУЭМаЮДІРэЦїЃЈGPUЃЉЖјВЛЪЧжабыДІРэЦїЃЈCPUЃЉНјааМЦЫуЯдШЛЛсИќПьЁЃ
TensorFlowЭЌЪБжЇГжCPUКЭGPUЃЌВЂЧвЙШИшЩѕжСЮЊДЫзЈУХЭЦГіСЫадФмЩЯгХгкЦфЫћДІРэЦїЕФдЦМЦЫугВМўЁЊЁЊTensorДІРэЦїЃЈTPUЃЉЁЃ
АВзА
TPUдкдЦЖЫВХПЩгУЃЌЖјTensorFlowЕФБОЕиАВзАПЩвдеыЖдCPUЛђGPUЙЙМмЁЃЯывЊгУGPUАцБОЃЌФуЕФЕчФдБиаывЊгавЛИіNVIDIAЯдПЈКЭЦфЫћвЛаЉвЊЧѓЁЃ
ЛљБОЩЯЃЌжСЩйга5жжВЛЭЌЕФАВзАбЁдёЃКvirtualenv, pip, Docker, Anaconda,
КЭДгдДАВзАЁЃ
1.гУvirtualenvКЭDockerАВзАПЩвдАбTensorFlowАВзАдквЛИіЯрЖдЖРСЂЕФЛЗОГЁЃ
2.AnacondaЪЧвЛИіФкЧЖСЫДѓСППЦбЇМЦЫуПтЕФPythonЗЂаЭАцЃЌетаЉПтжавВАќРЈTensorFlowЁЃ
3.pipдђЪЧАВзАpythonАќзюздШЛЕФЙЄОпЃЌВЛашвЊвРРЕЕкШ§ЗНЛЗОГЁЃ
4.зюКѓЃЌЭЈЙ§GitРДДгдДАВзАЃЌЪЧАВзАвЛИіЬиЖЈАцБОЕФTensorFlowЕФзюКУЗНЗЈЃЌетаЉАцБОжавВАќРЈЕБЧАзюЮШЖЈЕФr1.4ЃЈзЋаДБОЮФЪБЃЉЁЃ
зюГЃМћКЭзюМђЕЅЕФЗНЪНЛЙЪЧЭЈЙ§virtualenvКЭpipЃЌвђДЫетСНжжЗНЗЈЛсдкЮФжазХжиНщЩмЁЃ
ШчЙћФувбОЪЙгУPythonвЛЖЮЪБМфСЫЃЌФуПЩФмжЊЕРpipЁЃЯТУцЪЧШчКЮдкUbuntuЩЯЕУЕНЫќЃК

вдЯТМИааЪЧдкUbuntuКЭMac OSXЩЯАВзАTensorFlowЕФЗНЗЈЃК

ЩЯЪіетаЉУќСюдкWindowsЯТЕФPython 3.5.xКЭ3.6.xЯТвВПЩвдгУЁЃ
дквЛИіЕЅЖРЛЗОГжаАВзАTensorFlowдђПЩвдЭЈЙ§virtualenvЛђепcondaЃЈAnacondaЕФвЛВПЗжЃЉЁЃЙ§ГЬДѓжТПЩвдзёбЯрЭЌЕФДњТыЃЌЮЈвЛВЛЭЌЕФЪЧЃЌФуашвЊгУvirtualenvЯШДДНЈВЂМЄЛювЛИіаТЕФЛЗОГЃК

етжжЗНЗЈПЩвдЪЙЕУЫљгаашвЊЕФАќКЭФужЎЧАдкФуВйзїЯЕЭГЩЯХфжУЕФШЋОжАќИєРыПЊЁЃ
КЫаФгІгУНгПкзщМў
гаЖржжгІгУНгПкПЩвдгУгкБраДTensorFlowЁЃзюЕзВуЕФвЛИіБЛГЦЮЊКЫаФЃЌВЂвдеХСПЁЂЭМаЮЁЂЛсЛАетШ§ИіЛљБОзщМўЙЄзїЁЃ
ДЫЭтЛЙгаИќИпВуЕФгІгУНгПкЃЈШчtf.estimatorЃЉЃЌгУгкМђЛЏЙЄзїСїГЬКЭздЖЏЛЏЪ§ОнМЏЙмРэЁЂбЇЯАЁЂЦРЙРЕШЙ§ГЬЁЃЮоТлШчКЮЃЌСЫНтПтЕФКЫаФЕФЬиадЖдгкЙЙНЈзюаТЕФЛњЦїбЇЯАгІгУГЬађжСЙиживЊЁЃ
КЫаФгІгУНгПкЕФжиЕудкгкЙЙНЈвЛИіМЦЫуЭМЃЌЫќАќКЌвЛЯЕСаХХСаГЩНкЕуЭМаЮЕФВйзїЁЃУПИіНкЕуПЩвдгаЖрИіеХСПЃЈЛљБОЪ§ОнНсЙЙЃЉзїЮЊЪфШыЃЌВЂЖдЫќУЧжДааВйзївдБуМЦЫуЪфГіЃЌдквЛИіЖрВуЭјТчжаетИіЪфГігжПЩвдзїЮЊЦфЫћНкЕуЕФЪфШыЁЃетжжРраЭЕФМмЙЙЪЪгУгкЛњЦїбЇЯАгІгУЃЌШчЩёОЭјТчЁЃ
еХСП
еХСПЪЧTensorFlowжаЕФЛљБОЪ§ОнНсЙЙЃЌЫќДцДЂШЮвтЮЌЪ§ЕФЪ§ОнЃЌРрЫЦгкNumPyжаЕФЖрЮЌЪ§зщЁЃ еХСПгаШ§жжЛљБОРраЭЃКГЃСПЃЌБфСПКЭеМЮЛЗћЁЃ
1.ГЃСПЪЧеХСПВЛБфЕФРраЭЁЃ ЫћУЧПЩвдБЛПДзїУЛгаЪфШыЕФНкЕуЃЌЪфГіЫћУЧДцДЂдкФкВПЕФЕЅИіжЕЁЃ
2.БфСПЪЧПЩБфРраЭЕФеХСПЃЌЦфжЕПЩвддкЭМаЮдЫааЦкМфИФБфЁЃдкЛњЦїбЇЯАгІгУжаЃЌБфСПЭЈГЃДцДЂашвЊгХЛЏЕФВЮЪ§ЃЈР§ШчЃЌЩёОЭјТчжаНкЕужЎМфЕФШЈжиЃЉЁЃБфСПашвЊдкдЫааЭМаЮжЎЧАЭЈЙ§ЕїгУвЛИіЬиЪтЕФВйзїРДГѕЪМЛЏЁЃ
3.еМЮЛЗћЪЧДцДЂРДздЭтВПЪ§ОнЕФеХСПЕФеХСПЁЃЫќУЧДњБэСЫвЛИіЁАГаХЕЁБЃЌМДдкЭМаЮдЫааЪБНЋЬсЙЉвЛИіжЕЁЃ
дкMLгІгУГЬађжаЃЌеМЮЛЗћЭЈГЃгУгкЯђбЇЯАФЃаЭЪфШыЪ§ОнЁЃ
вдЯТМИааИјГіСЫШ§жжеХСПРраЭЕФР§згЃК
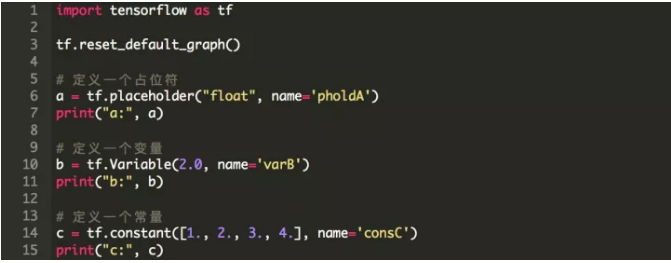

ЧызЂвтЃЌеХСПдкДЫДІВЛАќКЌжЕЃЌВЂЧвжЛгаЕБЭМаЮдкЛсЛАжадЫааЕФЪБКђЫќУЧЕФжЕВХПЩгУЁЃ
ЭМаЮ
ФПЧАЮЊжЙЃЌЭМаЮжЛБЃДцУЛгаСЌНгЕФ3ИіеХСПЁЃЯждкЃЌШУЮвУЧЖдеХСПНјаавЛаЉВйзїЃК


НсЙћЪфГігжЪЧвЛИіУћЮЊ"add"ЕФеХСПЃЌЯждкЮвУЧЕФФЃаЭПДЦ№РДШчЯТЭМЫљЪОЁЃФуПЩвдЪЙгУTensorFlowЕФФкжУЙІФмTensorBoardЬНЫїФуЕФЭМаЮвдМАЦфЫћВЮЪ§ЁЃ

ЭМ1ЃКгЩвЛДЮГЫЗЈКЭМгЗЈзщГЩЕФTensorFlowЭМЁЃ
СэвЛИіЬНЫїЭМаЮЕФгагУЙЄОпШчЯТДњТыЫљЪОЃЌЫќПЩвдНЋЫљгаЕФВйзїЪфГіЕНЦСФЛЁЃ


ЛсЛА
зюКѓЃЌЮвУЧЕФЭМгІИУдкЛсЛАжадЫааЁЃЧызЂвтЃЌБфСПБЛдЄЯШГѕЪМЛЏЃЌЖјеМЮЛЗћеХСПдђЭЈЙ§feed_dictНгЪеОпЬхжЕЁЃ
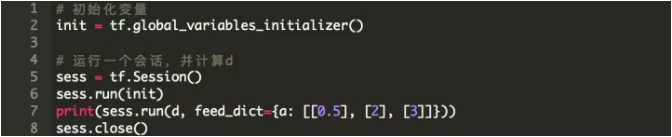

ЩЯУцЕФР§згЪЧвЛИібЇЯАФЃаЭЕФМђЛЏЁЃзмжЎЃЌЫќЯдЪОСЫШчКЮНЋЛљБОЕФtfзщМўзщКЯдквЛИіЭМБэжаВЂдкЛсЛАжадЫааЁЃДЫЭтЃЌЫќЛЙЫЕУїСЫВйзїШчКЮдкВЛЭЌФЃаЭЕФеХСПЩЯдЫааЁЃ
дкЯТУцЕФеТНкжаЃЌЮвУЧНЋЪЙгУКЫаФгІгУНгПкРДдквЛИіецЪЕЪ§ОнМЏЩЯЙЙНЈвЛИігУгкЛњЦїбЇЯАЕФЩёОЭјТчЁЃ
ЩёОЭјТчФЃаЭ
дкетвЛВПЗжЮвУЧЪЙгУTensorFlowЕФКЫаФзщМўДгЭЗПЊЪМНЈСЂвЛИіЧАРЁЩёОЭјТчЁЃ ЮвУЧБШНЯвЛИіЩёОЭјТчЕФШ§жжНсЙЙЃЌетНЋдквЛИівўВиВужаЕФНкЕуЪ§СПЩЯгаЫљВЛЭЌЁЃ
IrisЪ§ОнМЏ
ЮвУЧЪЙгУМђЕЅЕФIrisЪ§ОнМЏЃЌИУЪ§ОнМЏгЩ150ИіжВЮяЪЕР§зщГЩЃЌУПИіЪЕР§ЖМгаЦф4ИіЮГЖШЃЈгУзїЪфШывЊЫиЃЉМАЦфРраЭЃЈашвЊдЄВтЕФЪфГіжЕЃЉЁЃ
вЛжжжВЮяПЩвдЪєгкШ§жжПЩФмЕФЪфГіРраЭжЎвЛЃКsetosaЃЌvirginicaКЭversicolorЁЃ ЮвУЧЪзЯШДгTensorFlowЕФЭјеОЯТдиЪ§Он
- ЫќЗжЮЊ120ИібљБОЕФбЕСЗМЏКЭ30ИібљБОЕФВтЪдМЏЁЃ
ФЃаЭКЭбЇЯА
ЮвУЧЕФЩёОЭјТчЕФЪфШыКЭЪфГіВуЕФаЮзДНЋЖдгІгкЪ§ОнЕФаЮзДЃЌМДЪфШыВуНЋАќКЌДњБэЫФИіЪфШыЬиеїЕФЫФИіЩёОдЊЃЌЖјЪфГіВуНЋАќКЌШ§ИіЩёОдЊЃЌУПвЛИіЩёОдЊДцДЂ1БШЬиЃЌ3БШЬивдЖРШШЕФЗНЪНПЩвдДцДЂжВЮяЕФШ§жжРраЭЁЃР§ШчЁАsetosaЁБЮяжжПЩвдгУЪИСП[1,0,0]БрТыЃЌЁАvirginicaЁБгУ[0,1,0]БрТыЁЃ
ЮвУЧЮЊвўВиВужаЕФЩёОдЊЪ§ФПбЁдёШ§ИіжЕЃК5,10КЭ20ЃЌЕУЕНЃЈ4-5-3ЃЉЃЌЃЈ4-10-3ЃЉКЭЃЈ4-20-3ЃЉЕФЭјТчДѓаЁЁЃ
етвтЮЖзХЃЌР§ШчЃЈ4-5-3ЃЉНЋга4ИіЪфШыЩёОдЊЃЌ5ИіЁАвўВиЁБЩёОдЊКЭ3ИіЪфГіЩёОдЊЁЃ
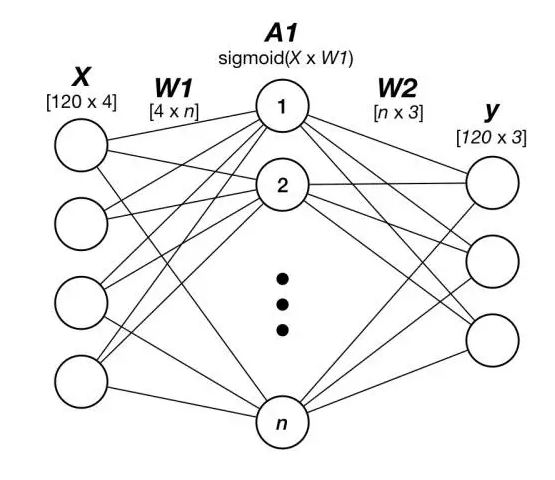
ЭМ2ЃКЮвУЧЕФШ§ВуЧАРЁЩёОЭјТч
ЯТУцЕФДњТыЖЈвхСЫвЛИіКЏЪ§ЃЌЮвУЧдкетИіКЏЪ§жаДДНЈФЃаЭЃЌЖЈвхвЛИіашвЊзюаЁЛЏЕФЫ№ЪЇКЏЪ§ЃЌВЂЧвдЫаа2000ДЮЕќДњЃЌРДбЕСЗЯАЕУзюгХШЈжиW_1КЭW_2ЁЃ
ШчЧАЫљЪіЃЌЪфШыКЭЪфГіОиеѓБЛРЁЫЭЕНtf.placeholderеХСПЃЌВЂЧвШЈжиБЛБэЪОЮЊБфСПЃЌвђЮЊЫќУЧЕФжЕдкУПДЮЕќДњжаБфЛЏЁЃЫ№ЪЇКЏЪ§БЛЖЈвхЮЊЮвУЧдЄВтy_estКЭЪЕМЪЮяжжРраЭyжЎМфЕФЦНОљЗНВюЃЌЮвУЧЪЙгУЕФМЄЛюКЏЪ§ЪЧsigmoidЁЃзюКѓЃЌгЩcreate_train_modelКЏЪ§ЗЕЛибЇЯАШЈжиВЂЪфГіЫ№ЪЇКЏЪ§ЕФзюжежЕЁЃ
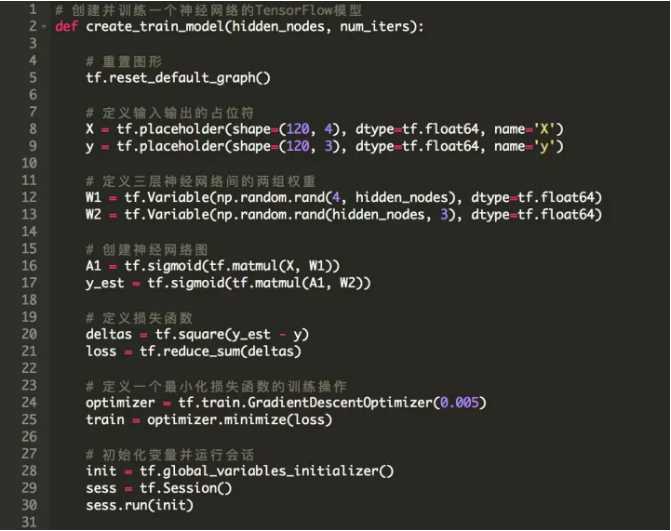
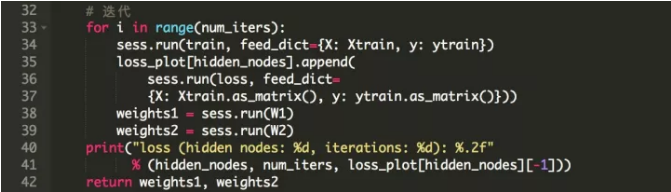
КУЃЌШУЮвУЧДДНЈЃЈжЎЧАЬсЕНЕФЃЉШ§ИіЩёОЭјТчМмЙЙЃЌВЂдкЕќДњжаЛцжЦЫ№ЪЇКЏЪ§ЁЃ
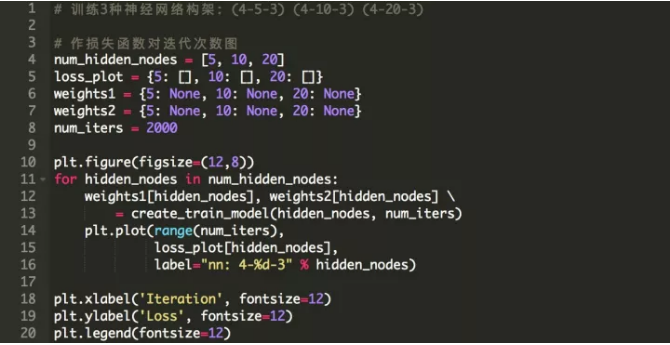

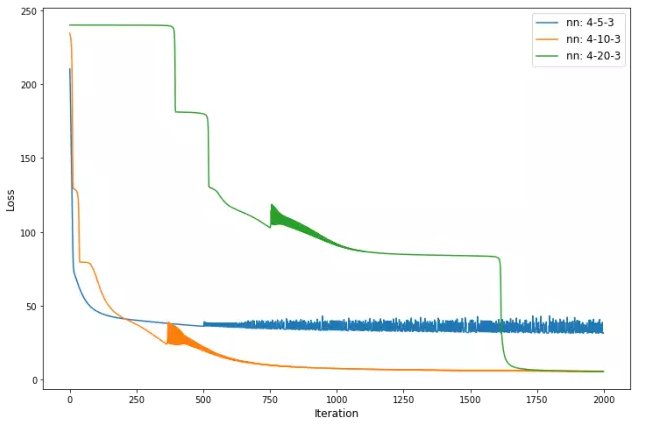
ЭМ3ЃК2000ДЮЕќДњКѓЃЌВЛЭЌЩёОЭјТчЙЙМмЕФЫ№ЪЇКЏЪ§ЁЃ
ЮвУЧПЩвдПДЕНЃЌОпга20ИівўВиЩёОдЊЕФЭјТчашвЊИќЖрЕФЪБМфРДДяЕНзюаЁжЕЃЌетЪЧгЩгкЦфИќИпЕФИДдгадЁЃЖјОпга5ИівўВиЩёОдЊЕФЭјТчЯнШыОжВПзюаЁжЕЃЌВЂЧвВЛЛсИјГіКУЕФНсЙћЁЃ
ЮоТлШчКЮЃЌЖдгкIrisетбљМђЕЅЕФЪ§ОнМЏЃЌМДЪЙЪЧОпга5ИівўВиЩёОдЊЕФаЁЭјТчвВгІИУФмЙЛбЇЯАЕНвЛИіКУЕФФЃаЭЁЃдкЮвУЧЕФР§згжаЃЌетжЛЪЧвЛИіЫцЛњЪТМўЃЌФЃаЭБЛЯожЦдквЛИіОжВПзюаЁжЕЃЌЖјЧвШчЙћЮвУЧвЛДЮгжвЛДЮЕидЫааДњТыЃЌЫќВЂВЛЛсОГЃЗЂЩњЁЃ
ФЃаЭЦРЙР
зюКѓЃЌШУЮвУЧРДЦРЙРЮвУЧЕФФЃаЭЁЃЮвУЧЪЙгУбЇЯАШЈжиW_1КЭW_2ЃЌНЋФЃаЭгІгУгкВтЪдМЏЕФРраЭЕФдЄВтЁЃзМШЗадЖЈвхЮЊе§ШЗдЄВтбљБОЕФАйЗжБШЁЃ
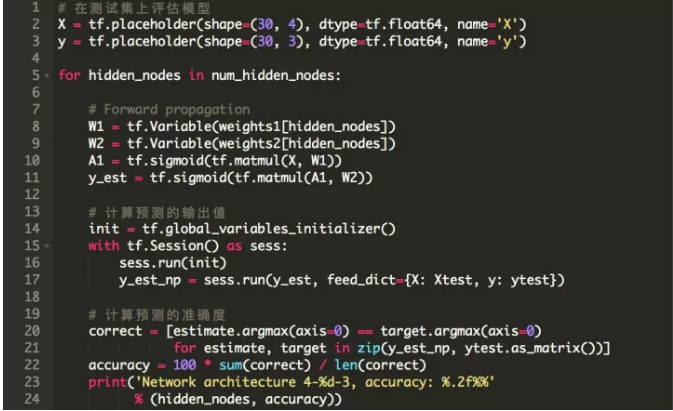

змЕФРДЫЕЃЌЮвУЧЩшЗЈгУвЛИіМђЕЅЕФЧАРЁЩёОЭјТчРДДяЕНЗЧГЃИпЕФОЋШЗЖШЃЌЬиБ№ЪЧЪЙгУвЛИіЗЧГЃаЁЕФЪ§ОнМЏЕФШДДяЕНШчДЫИпОЋЖШЕФдЄВтЃЌетЗЧГЃСюШЫОЊбШЁЃ
ФуПЩвддкетРяЪЙгУTensorFlowЕФИпМЖгІгУНгПкРДПДвЛИіИќМђЕЅЕФР§згЁЃ
зЪдД
БОНЬГЬжЛНщЩмСЫTensorFlowПЩвдзіЕФвЛаЁВПЗжЁЃ вдЯТЪЧвЛаЉгаЙиTensorFlowКЭЩюШыбЇЯАЕФИќЖрзЪдДЃК
1.TensorFlow.org
2.гУPythonНјааЩюЖШбЇЯАЕФTensorFlowЭъећжИФЯ
3.гУTensorFlowЩюШыбЇЯА
4.Ъ§ОнПЦбЇЃКPythonЩюЖШбЇЯА
НсТл
дкетЦЊЮФеТжаЃЌЮвУЧНщЩмСЫгУгкЛњЦїбЇЯАЕФTensorFlowПтЃЌЮЊАВзАЬсЙЉСЫМђвЊЕФжИЕМЃЌНщЩмСЫTensorFlowЕзВуКЫаФгІгУНгПкЕФЛљБОзщМўЃКеХСПЃЌЭМаЮКЭЛсЛАЃЌзюКѓЙЙНЈСЫвЛИіЩёОЭјТчФЃаЭРДЖдецЪЕЪ§ОнМЏЁЊЁЊIrisЪ§ОнМЏНјааЗжРрЁЃ
змЕФРДЫЕЃЌРэНтTensorFlowЕФБраДдРэПЩФмашвЊвЛаЉЪБМфЃЌвђЮЊЫќЪЧвЛИіЗћКХПтЃЌЕЋЪЧвЛЕЉЪьЯЄСЫКЫаФзщМўЃЌетЖдЙЙНЈЛњЦїбЇЯАгІгУГЬађРДЫЕЪЧЯрЕБЗНБуЕФЁЃдкетЦЊЮФеТжаЃЌЮвУЧЪЙгУЕзВуЕФКЫаФгІгУНгПкРДеЙЯжЛљБОЕФзщМўЃЌВЂЧвЖдФЃаЭгаЭъШЋЕФПижЦЃЌЕЋЪЧЭЈГЃШЫУЧЛсЪЙгУИќИпМЖЕФгІгУНгПкЃЌБШШчtf.estimatorЃЌЩѕжСЪЧЭтВПЕФПтЃЌБШШчKerasЁЃ
|









