| БрМЭЦМі: |
| БОЮФРДздгкPaperWeeklyЃЌЮФжагУabstractiveЕФЗНЪНРДНтОіsentence-levelЕФЮФБОеЊвЊЁЃЭЈЙ§ФЃаЭЯъЯИНщЩмСЫСїГЬЃЌПЩЙЉДѓМвВЮПМЁЃ |
|
в§
ЮФБОеЊвЊЪЧздШЛгябдДІРэжаБШНЯФбЕФвЛИіШЮЮёЃЌБ№ЫЕЪЧгУЛњЦїРДзіЮФеЊСЫЃЌОЭСЌШЫРрзіЮФеЊЕФЪБКђЖМашвЊОпБИКмЧПЕФгябддФЖСРэНтФмСІКЭЙщФЩзмНсФмСІЁЃаТЮХЕФеЊвЊвЊЧѓБрМФмЙЛДгаТЮХЪТМўжаЬсШЁГізюЙиМќЕФаХЯЂЕуЃЌжиаТзщжЏгябдРДаДеЊвЊЃЛpaperЕФеЊвЊашвЊзїепДгШЋЮФжаЬсШЁГізюКЫаФЕФЙЄзїЃЌШЛКѓгУИќМгОЋСЖЕФгябдаДГЩеЊвЊЃЛзлЪіадЕФpaperашвЊзїепЭЈЖСNЦЊЯрЙиtopicЕФpaperжЎКѓЃЌгУзюИХРЈЕФгябдНЋУПЦЊЮФеТЕФЙБЯзЁЂДДаТЕуаДГіРДЃЌВЂЧвЖдБШУПЦЊЮФеТЕФЗНЗЈИїгаЪВУДгХШБЕуЁЃздЖЏЮФеЊБОжЪЩЯзіЕФвЛМўЪТЧщЪЧаХЯЂЙ§ТЫЃЌДгФГжжвтвхЩЯРДЫЕЃЌКЭЭЦМіЯЕЭГЕФЙІФмгавЛЕуЯёЃЌЖМЪЧЮЊСЫШУДѓМвИќПьЕиевЕНИааЫШЄЕФЖЋЮїЃЌжЛЪЧгУСЫВЛЭЌЕФЪжЖЮЖјвбЁЃ
ЮЪЬтУшЪі
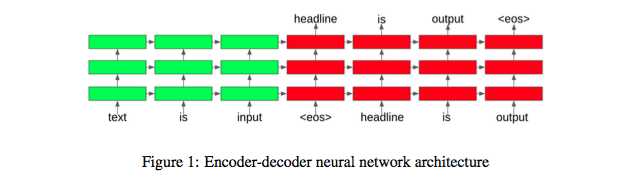
ЮФБОеЊвЊЮЪЬтАДееЮФЕЕЪ§СППЩвдЗжЮЊЕЅЮФЕЕеЊвЊКЭЖрЮФЕЕеЊвЊЮЪЬтЃЌАДееЪЕЯжЗНЪНПЩвдЗжЮЊЬсШЁЪНЃЈextractiveЃЉКЭеЊвЊЪНЃЈabstractiveЃЉЁЃеЊвЊЮЪЬтЕФЬиЕуЪЧЪфГіЕФЮФБОвЊБШЪфШыЕФЮФБОЩйКмЖрКмЖрЃЌЕЋШДдЬВизХЗЧГЃЖрЕФгааЇаХЯЂдкФкЁЃгавЛЕуЕуИаОѕЯёЪЧжїГЩЗжЗжЮіЃЈPCAЃЉЃЌзїгУвВгыЭЦМіЯЕЭГгавЛЕуЯёЃЌЖМЪЧЮЊСЫНтОіаХЯЂЙ§диЕФЮЪЬтЁЃЯждкОјДѓЖрЪ§гІгУЕФЯЕЭГЖМЪЧextractiveЕФЃЌетИіЗНЗЈБШНЯМђЕЅЕЋДцдкКмЖрЕФЮЪЬтЃЌМђЕЅЪЧвђЮЊжЛашвЊДгдЮФжаевГіЯрЖдРДЫЕживЊЕФОфзгРДзщГЩЪфГіМДПЩЃЌЯЕЭГжЛашвЊгУФЃаЭРДбЁдёГіаХЯЂСПДѓЕФОфзгШЛКѓАДеездШЛађзщКЯЦ№РДОЭЪЧеЊвЊСЫЁЃЕЋЪЧеЊвЊЕФСЌЙсадЁЂвЛжТадКмФбБЃжЄЃЌБШШчгіЕНСЫОфзгжаАќКЌСЫДњДЪЃЌМђЕЅЕФСЌЦ№РДИљБОЮоЗЈЛёжЊДњДЪжИЕФЪЧЪВУДЃЌДгЖјЕМжТаЇЙћВЛМбЁЃбаОПжаЫцзХdeep
learningММЪѕдкnlpжаЕФЩюШыЃЌгШЦфЪЧseq2seq+attentionФЃаЭЕФЁАКсааЁБЃЌДѓМвНЋabstractiveЪНЕФеЊвЊбаОПЬсИпСЫвЛИіlevelЃЌВЂЧвЬсГіСЫcopy
mechanismЕШЛњжЦРДНтОіseq2seqФЃаЭжаЕФOOVЮЪЬтЁЃ
БОЮФЬНЬжЕФЪЧгУabstractiveЕФЗНЪНРДНтОіsentence-levelЕФЮФБОеЊвЊЮЪЬтЃЌЮЪЬтЕФЖЈвхБШНЯМђЕЅЃЌЪфШыЪЧвЛИіГЄЖШЮЊMЕФЮФБОађСаЃЌЪфГіЪЧвЛИіГЄЖШЮЊNЕФЮФБОађСаЃЌетРяM>>NЃЌВЂЧвЪфГіЮФБОЕФвтЫМКЭЪфШыЮФБОЕФвтЫМЛљБОвЛжТЃЌЪфШыПЩФмЪЧвЛОфЛАЃЌвВПЩФмЪЧЖрОфЛАЃЌЖјЪфГіЖМЪЧвЛОфЛАЃЌвВПЩФмЪЧЖрОфЛАЁЃ
гяСЯ
етРяЕФгяСЯЗжЮЊСНжжЃЌвЛжжЪЧгУРДбЕСЗЩюЖШбЇЯАФЃаЭЕФДѓаЭгяСЯЃЌвЛжжЪЧгУРДВЮМгЦРВтЕФаЁаЭгяСЯЁЃ
1ЁЂDUC
етИіЭјеОЬсЙЉСЫЮФБОеЊвЊЕФБШШќЃЌ2001-2007ФъдкетИіЭјеОЃЌ2008ФъПЊЪМЛЛЕНетИіЭјеОTACЁЃКмЙйЗНЕФБШШќЃЌИїДѓЮФБОеЊвЊЯЕЭГЖМЛсдкетРяНЯСПвЛЗЌЃЌвЛОіИпЯТЁЃетРяЬсЙЉЕФЪ§ОнМЏЖМЪЧаЁаЭЪ§ОнМЏЃЌгУРДЦРВтФЃаЭЕФЁЃ
2ЁЂGigaword
ИУгяСЯЗЧГЃДѓЃЌДѓИХга950wЦЊаТЮХЮФеТЃЌЪ§ОнМЏгУheadlineРДзіsummaryЃЌМДЪфГіЮФБОЃЌгУfirst
sentenceРДзіinputЃЌМДЪфШыЮФБОЃЌЪєгкЕЅОфеЊвЊЕФЪ§ОнМЏЁЃ
3ЁЂCNN/Daily Mail
ИУгяСЯОЭЪЧЮвУЧдкЛњЦїдФЖСРэНтжагУЕНЕФгяСЯЃЌИУЪ§ОнМЏЪєгкЖрОфеЊвЊЁЃ
4ЁЂLarge Scale Chinese Short Text Summarization DatasetЃЈLCSTSЃЉ[6]
етЪЧвЛИіжаЮФЖЬЮФБОеЊвЊЪ§ОнМЏЃЌЪ§ОнВЩМЏздаТРЫЮЂВЉЃЌИјбаОПжаЮФеЊвЊЕФЭЏаЌУЧДјРДСЫИЃРћЁЃ
ФЃаЭ
БОЮФЫљЫЕЕФФЃаЭЖМЪЧabstractiveЪНЕФseq2seqФЃаЭЁЃnlpжазюдчЪЙгУseq2seq+attentionФЃаЭРДНтОіЮЪЬтЕФЪЧmachine
translationСьгђЃЌЯжШчНёИУЗНЗЈвбОКсЩЈСЫжюЖрСьгђЕФХХааАёЁЃ
seq2seqЕФФЃаЭвЛАуЖМЪЧШчЯТЕФНсЙЙ[1]ЃК
encoderВПЗжгУЕЅВуЛђепЖрВуrnn/lstm/gruНЋЪфШыНјааБрТыЃЌdecoderВПЗжЪЧвЛИігябдФЃаЭЃЌгУРДЩњГЩеЊвЊЁЃетжжЩњГЩЪНЕФЮЪЬтЖМПЩвдЙщНсЮЊЧѓНтвЛИіЬѕМўИХТЪЮЪЬтp(word|context)ЃЌдкcontextЬѕМўЯТЃЌНЋДЪБэжаУПвЛИіДЪЕФИХТЪжЕЖМЫуГіРДЃЌгУИХТЪзюДѓЕФФЧИіДЪзїЮЊЩњГЩЕФДЪЃЌвРДЮЩњГЩеЊвЊжаЕФЫљгаДЪЁЃетРяЕФЙиМќдкгкШчКЮБэЪОcontextЃЌУПжжФЃаЭзюДѓЕФВЛЭЌЕуЖМдкгкcontextЕФВЛЭЌЃЌетРяЕФcontextПЩФмжЛЪЧencoderЕФБэЪОЃЌвВПЩФмЪЧattentionКЭencoderЕФБэЪОЁЃdecoderВПЗжЭЈГЃВЩгУbeam
searchЫуЗЈРДзіЩњГЩЁЃ
1ЁЂComplex Attention Model[1]
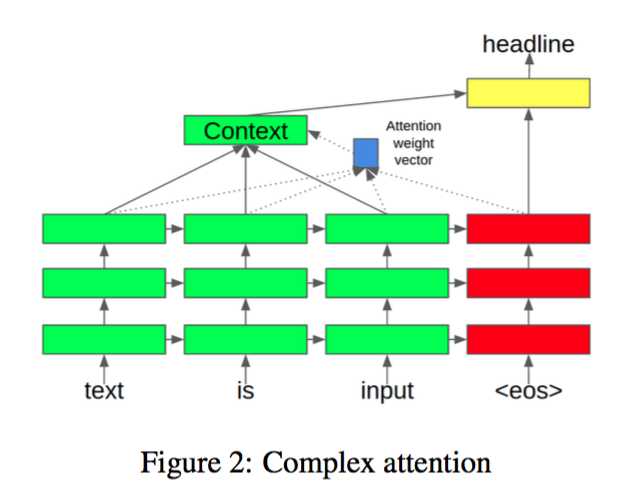
ФЃаЭжаЕФattention weightsЪЧгУencoderжаУПИіДЪзюКѓвЛВуhidden layerЕФБэЪОгыЕБЧАdecoderзюаТвЛИіДЪзюКѓвЛВуhidden
layerЕФБэЪОзіЕуГЫЃЌШЛКѓЙщвЛЛЏРДБэЪОЕФЁЃ
2ЁЂSimple Attention Model[1]
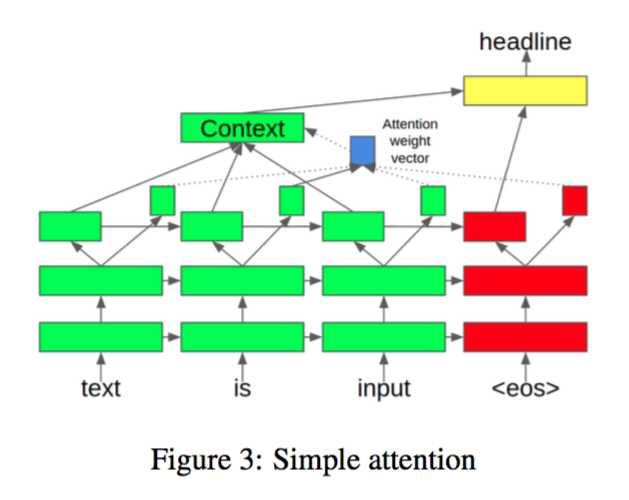
ФЃаЭНЋencoderВПЗждкУПИіДЪзюКѓвЛВуhidden layerЕФБэЪОЗжЮЊСНПщЃЌвЛаЁПщгУРДМЦЫуattention
weightsЕФЃЌСэвЛДѓПщгУРДзїЮЊencoderЕФБэЪОЁЃетИіФЃаЭНЋзюКѓвЛВуhidden layerЯИЗжСЫВЛЭЌЕФзїгУЁЃ
3ЁЂAttention-Based Summarization(ABS)[2]
етИіФЃаЭгУСЫШ§жжВЛЭЌЕФencoderЃЌАќРЈЃКBag-of-Words EncoderЁЂConvolutional
EncoderКЭAttention-Based EncoderЁЃRushЪЧHarvardNLPзщЕФЃЌетИізщЕФЬиЕуЪЧЗЧГЃЯВЛЖгУCNNРДзіnlpЕФШЮЮёЁЃетИіФЃаЭжаЃЌШУЮвУЧПДЕНСЫВЛЭЌЕФencoderЃЌДгЗЧГЃМђЕЅЕФДЪДќФЃаЭЕНCNNЃЌдйЕНattention-basedФЃаЭЃЌЖјВЛЪЧЧЇЦЊвЛТЩЕФrnnЁЂlstmКЭgruЁЃЖјdecoderВПЗжгУСЫвЛИіЗЧГЃМђЕЅЕФNNLMЃЌОЭЪЧBengio[10]гк2003ФъЬсГіРДЕФЧАРЁЩёОЭјТчгябдФЃаЭЃЌетвЛФЃаЭЪЧКѓајЩёОЭјТчгябдФЃаЭбаОПЕФЛљЪЏЃЌвВЪЧКѓајЖдгкword
embeddingЕФбаОПЕьЖЈСЫЛљДЁЁЃПЩвдЫЕЃЌетИіФЃаЭгУСЫзюМђЕЅЕФencoderКЭdecoderРДзіseq2seqЃЌЪЧвЛДЮЗЧГЃВЛДэЕФГЂЪдЁЃ
4ЁЂABS+[2]
RushЬсГіСЫвЛИіДПЪ§ОнЧ§ЖЏЕФФЃаЭABSжЎКѓЃЌгжЬсГіСЫвЛИіabstractiveгыextractiveШкКЯЕФФЃаЭЃЌдкABSФЃаЭЕФЛљДЁЩЯдіМгСЫfeature
functionЃЌаоИФСЫscore functionЃЌЕУЕНСЫетИіаЇЙћИќМбЕФABS+ФЃаЭЁЃ
5ЁЂRecurrent Attentive Summarizer(RAS)[3]
етИіФЃаЭЪЧRushЕФбЇЩњЬсГіРДЕФЃЌЪфШыжаУПИіДЪзюжеЕФembeddingЪЧИїДЪЕФembeddingгыИїДЪЮЛжУЕФembeddingжЎКЭЃЌОЙ§вЛВуОэЛ§ДІРэЕУЕНaggregate
vectorЃК
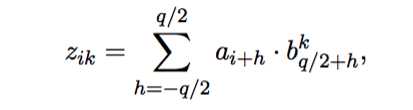
ИљОнaggregate vectorМЦЫуcontextЃЈencoderЕФЪфГіЃЉЃК
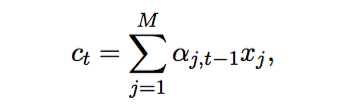
ЦфжаШЈжигЩЯТЪНМЦЫуЃК
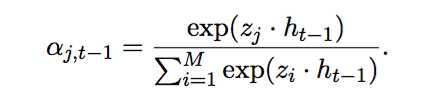
decoderВПЗжгУRNNLMРДзіЩњГЩЃЌRNNLMЪЧдкBengioЬсГіЕФNNLMЛљДЁЩЯЬсГіЕФИФНјФЃаЭЃЌвВЪЧвЛИіжїСїЕФгябдФЃаЭЁЃ
6ЁЂbig-words-lvt2k-1sentФЃаЭ[4]
етИіФЃаЭв§ШыСЫlarge vocabulary trick(LVT)ММЪѕЕНЮФБОеЊвЊЮЪЬтЩЯЁЃБОЗНЗЈжаЃЌУПИіmini
batchжаdecoderЕФДЪЛуБэЪмжЦгкencoderЕФДЪЛуБэЃЌdecoderДЪЛуБэжаЕФДЪгЩвЛЖЈЪ§СПЕФИпЦЕДЪЙЙГЩЁЃетИіФЃаЭЕФЫМТЗжиЕуНтОіЕФЪЧгЩгкdecoderДЪЛуБэЙ§ДѓЖјдьГЩsoftmaxВуЕФМЦЫуЦПОБЁЃБОФЃаЭЗЧГЃЪЪКЯНтОіЮФБОеЊвЊЮЪЬтЃЌвђЮЊеЊвЊжаЕФКмЖрДЪЖМЪЧРДздгкдЮФжЎжаЁЃ
7ЁЂwords-lvt2k-2sent-hierattФЃаЭ[4]
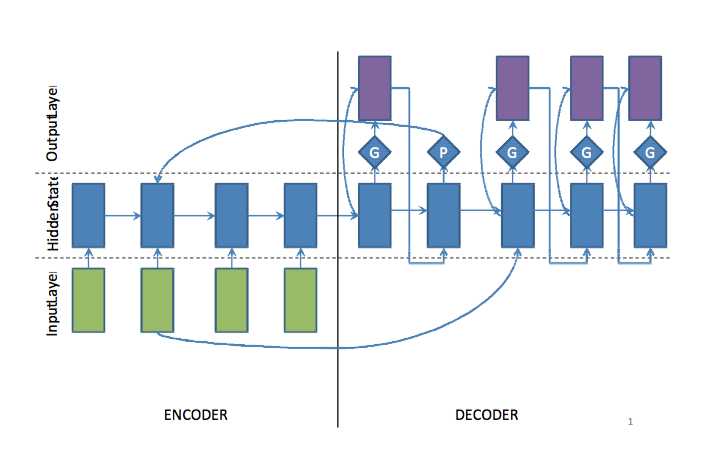
ЮФБОеЊвЊжаОГЃгіЕНетбљЕФЮЪЬтЃЌвЛаЉЙиМќДЪГіЯжКмЩйЕЋШДКмживЊЃЌгЩгкФЃаЭЛљгкword embeddingЃЌЖдЕЭЦЕДЪЕФДІРэВЂВЛгбКУЃЌЫљвдБОЮФЬсГіСЫвЛжжdecoder/pointerЛњжЦРДНтОіетИіЮЪЬтЁЃФЃаЭжаdecoderДјгавЛИіПЊЙиЃЌШчЙћПЊЙизДЬЌЪЧДђПЊgeneratorЃЌдђЩњГЩвЛИіЕЅДЪЃЛШчЙћЪЧЙиБеЃЌdecoderдђЩњГЩвЛИідЮФЕЅДЪЮЛжУЕФжИеыЃЌШЛКѓПНБДЕНеЊвЊжаЁЃpointerЛњжЦдкНтОіЕЭЦЕДЪЪБТГАєадБШНЯЧПЃЌвђЮЊЪЙгУСЫencoderжаЕЭЦЕДЪЕФвўВиВуБэЪОзїЮЊЪфШыЃЌЪЧвЛИіЩЯЯТЮФЯрЙиЕФБэЪОЃЌЖјНіНіЪЧвЛИіДЪЯђСПЁЃетИіpointerЛњжЦКЭКѓУцгавЛЦЊжаЕФcopyЛњжЦЫМТЗЗЧГЃРрЫЦЁЃ
8ЁЂfeats-lvt2k-2sent-ptrФЃаЭ[4]
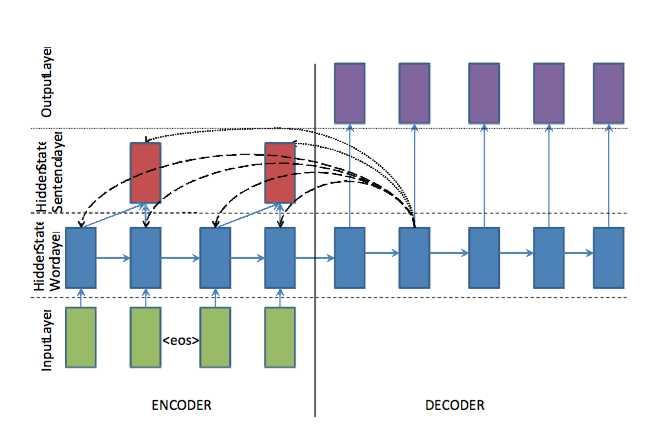
Ъ§ОнМЏжаЕФдЮФвЛАуЖМЛсКмГЄЃЌдЮФжаЕФЙиМќДЪКЭЙиМќОфзгЖдгкаЮГЩеЊвЊЖМКмживЊЃЌетИіФЃаЭЪЙгУСНИіЫЋЯђRNNРДВЖзНетСНИіВуДЮЕФживЊадЃЌвЛИіЪЧword-levelЃЌвЛИіЪЧsentence-levelЃЌВЂЧвИУФЃаЭдкСНИіВуДЮЩЯЖМЪЙгУattentionЃЌШЈжиШчЯТЃК
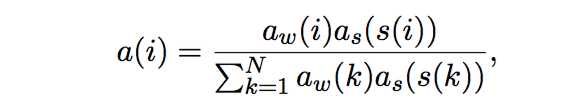
9ЁЂCOPYNET[8]
encoderВЩгУСЫвЛИіЫЋЯђRNNФЃаЭЃЌЪфГівЛИівўВиВуБэЪОЕФОиеѓMзїЮЊdecoderЕФЪфШыЁЃdecoderВПЗжгыДЋЭГЕФSeq2SeqВЛЭЌжЎДІдкгквдЯТШ§ВПЗжЃК
дЄВтЃКдкЩњГЩДЪЪБДцдкСНжжФЃЪНЃЌвЛжжЪЧЩњГЩФЃЪНЃЌвЛжжЪЧПНБДФЃЪНЃЌЩњГЩФЃаЭЪЧвЛИіНсКЯСНжжФЃЪНЕФИХТЪФЃаЭЁЃ
зДЬЌИќаТЃКгУt-1ЪБПЬЕФдЄВтГіЕФДЪРДИќаТtЪБПЬЕФзДЬЌЃЌCOPYNETВЛНіНіДЪЯђСПЃЌЖјЧвЪЙгУMОиеѓжаЬиЖЈЮЛжУЕФhidden
stateЁЃ
ЖСШЁMЃКCOPYNETвВЛсбЁдёадЕиЖСШЁMОиеѓЃЌРДЛёШЁЛьКЯСЫФкШнКЭЮЛжУЕФаХЯЂЁЃ
етИіФЃаЭгыЕк7ИіФЃаЭЫМЯыЗЧГЃЕФРрЫЦЃЌвђЮЊКмКУЕиДІРэСЫOOVЕФЮЪЬтЃЌЫљвдНсЙћЖМЗЧГЃКУЁЃ
10ЁЂMRT+NHG[7]
етИіФЃаЭЕФЬиБ№жЎДІдкгкгУСЫMinimum Risk TrainingбЕСЗЪ§ОнЃЌЖјВЛЪЧДЋЭГЕФMLEЃЈзюДѓЫЦШЛЙРМЦЃЉЃЌНЋЦРМлжИБъАќКЌдкгХЛЏФПБъФкЃЌИќМгжБНгЕиЖдЦРМлжИБъзігХЛЏЃЌЕУЕНСЫВЛДэЕФНсЙћЁЃ
НсЙћ
ЦРМлжИБъЪЧЗёПЦбЇПЩааЖдгквЛИібаОПСьгђЕФбаОПЫЎЦНгазХжБНгЕФгАЯьЃЌФПЧАдкЮФБОеЊвЊШЮЮёжазюГЃгУЕФЦРМлЗНЗЈЪЧROUGE(Recall-Oriented
Understudy for Gisting Evaluation)ЁЃROUGEЪмЕНСЫЛњЦїЗвыздЖЏЦРМлЗНЗЈBLEUЕФЦєЗЂЃЌВЛЭЌжЎДІдкгкЃЌВЩгУейЛиТЪРДзїЮЊжИБъЁЃЛљБОЫМЯыЪЧНЋФЃаЭЩњГЩЕФеЊвЊгыВЮПМеЊвЊЕФnдЊзщЙБЯзЭГМЦСПзїЮЊЦРХавРОнЁЃ
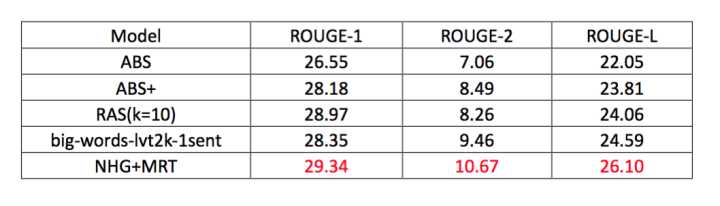
дкгЂЮФЪ§ОнМЏDUC-2004ЩЯНјааЦРВтЃЌНсЙћШчЯТЃК
дкжаЮФЪ§ОнМЏLCSTSЩЯНјааЦРВтЃЌНсЙћШчЯТЃК
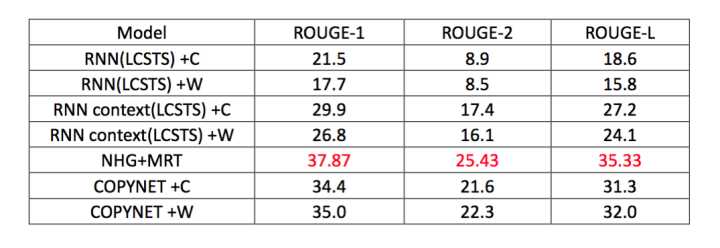
ВЛЙмЪЧжаЮФЪ§ОнМЏЛЙЪЧгЂЮФЪ§ОнМЏЩЯЃЌзюКУЕФНсЙћЖМЪЧРДздгкФЃаЭ10[7],ВЂЧвИУФЃаЭжЛЪЧВЩгУзюЦеЭЈЕФseq2seq+attentionФЃаЭЃЌЖМУЛгагУЕНаЇЙћИќКУЕФcopyЛњжЦЛђепpointerЛњжЦЁЃ
ЫМПМ
здЖЏЮФеЊЪЧЮвЙизЂЕФЕквЛИіnlpСьгђЃЌдчЦкСЫКмЖрЯрЙиЕФpaperЃЌДгЗНЗНУцУцЖМгаЫљСЫНтЃЌвВгавЛаЉБШНЯЧГБЁЕФЯыЗЈЃЌЯждкзмНсвЛЯТЁЃ
1ЁЂЮЊЪВУДMRTФЧЦЊЮФеТЕФНсЙћЛсБШЦфЫћИїжжИїбљЕФФЃаЭЖМвЊКУФиЃПвђЮЊЫћжБНгНЋROUGEжИБъАќКЌдкСЫД§гХЛЏЕФФПБъжаЃЌЖјВЛЪЧгыЦфЫћФЃаЭвЛбљЃЌВЩгУДЋЭГЕФMLEРДзіЃЌДЋЭГЕФФПБъЦРМлЕФЪЧФуЕФЩњГЩжЪСПШчКЮЃЌЕЋгыЮвУЧзюжеЦРМлЕФжИБъROUGEВЂЮожБНгЙиЯЕЁЃЫљвдЫЕЃЌЛЛСЫвЛжжгХЛЏФПБъЃЌжБНгЖЈЮЛгкЦРМлжИБъЩЯзігХЛЏЃЌаЇЙћвЛЖЈЛсКмКУЁЃетЕуВЛНіНідкздЖЏЮФеЊжаГіЯжЙ§ЃЌЮвМЧЕУдкbotЯрЙиЕФpaperжаЛЙгаЛњЦїдФЖСРэНтЯрЙиЕФpaperжаЖМгаГіЯжЃЌжЛЪЧОпЬхЕФЦРМлжИБъВЛЭЌЖјвбЁЃетвЛЕуКмгаЦєЗЂадЃЌШчЙћдкЮФеТ[7]жаВЩгУcopyЛњжЦРДНтОіOOVЮЪЬтЃЌЛсВЛЛсгаИќМгОЊШЫЕФаЇЙћФиЃПЮвУЧЪУФПвдД§ЁЃ
2ЁЂOOV(out of vocabulary)ЕФЮЪЬтЁЃвђЮЊЮФБОеЊвЊЫЕЕНЕзЃЌЖМЪЧвЛИігябдЩњГЩЕФЮЪЬтЃЌжЛвЊЪЧЩцМАЕНЩњГЩЕФЮЪЬтЃЌБиШЛЛсгіЕНOOVЮЪЬтЃЌвђЮЊВЛПЩФмНЋЫљгаДЪЖМЗХЕНДЪБэжаРДМЦЫуИХТЪЃЌПЩааЕФЗНЗЈЪЧгУбЁдёtopnИіИпЦЕДЪРДзщГЩДЪБэЁЃЮФеТ[4]КЭ[8]ЖМВЩгУСЫЯрЫЦЕФЫМТЗЃЌДгinputжаПНБДдЮФЕНoutputжаЃЌЖјВЛНіНіЪЧЩњГЩЃЌетРяашвЊЩшжУвЛИіgateРДОіЖЈетИіДЪЪЧcopyРДЛЙЪЧgenerateГіРДЁЃЯдШЛЃЌдіМгСЫcopyЛњжЦЕФФЃаЭЛсдкКмДѓГЬЖШЩЯНтОіСЫOOVЕФЮЪЬтЃЌОЭЛсЯджјЕиЬсЩ§ЦРМлНсЙћЁЃетжжЫМТЗВЛНіНідкЮФеЊЮЪЬтЩЯЪЪгУЃЌдквЛЧаЩњГЩЮЪЬтЩЯЖМЪЪгУЃЌБШШчbotЁЃ
3ЁЂЙигкЦРМлжИБъЕФЮЪЬтЁЃвЛИіЦРМлжИБъЪЧЗёПЦбЇжБНггАЯьСЫетИіСьгђЕФЗЂеЙЫЎЦНЃЌШЫЙЄЦРМлЮвУЧОЭВЛЬсСЫЃЌжЛЫЕздЖЏЦРМлЁЃROUGEжИБъдк2003ФъОЭБЛLinЬсГіСЫ[9]ЃЌ13ФъЙ§ШЅСЫЃЌШдШЛУЛгавЛИіИќМгКЯЪЪЕФЦРМлЬхЯЕРДДњЬцЫќЁЃROUGEЦРМлЬЋЙ§ЫРАхЃЌжЛФмЦРМлГіoutputКЭtargetжЎМфЕФвЛаЉБэУцаХЯЂЃЌВЂВЛЩцМАЕНгявхВуУцЩЯЕФЖЋЮїЃЌЪЧЗёПЩвдЬсГівЛжжИќМгИпВуДЮЕФЦРМлЬхЯЕЃЌДггявхетИіВуУцРДЦРМлеЊвЊЕФаЇЙћЁЃЦфЪЕММЪѕЩЯЮЪЬтВЛДѓЃЌвђЮЊМЦЫуСНИіЮФБОађСажЎМфЕФЯрЫЦЖШгаЮоЪ§жжНтОіЗНАИЃЌгаМрЖНЁЂЮоМрЖНЁЂАыМрЖНЕШЕШЕШЕШЁЃКмЦкД§гавЛжжаТЕФЬхЯЕРДЦРМлеЊвЊаЇЙћЃЌЯраХаТЕФЦРМлЬхЯЕвЛЖЈЛсЭЦЖЏздЖЏЮФеЊСьгђЕФЗЂеЙЁЃ
4ЁЂЙигкЪ§ОнМЏЕФЮЪЬтЁЃLCSTSЪ§ОнМЏЕФЙЙНЈИјжаЮФЮФБОеЊвЊЕФбаОПЕьЖЈСЫЛљДЁЃЌНЋЛсКмДѓГЬЖШЕиЭЦЖЏздЖЏЮФеЊдкжаЮФСьгђЕФЗЂеЙЁЃЯждкЕФЛЅСЊЭјзюВЛШБЩйЕФОЭЪЧЪ§ОнЃЌДѓСПЕФЗЧНсЙЙЛЏЪ§ОнЁЃЕЋШчКЮЙЙНЈвЛИіИпжЪСПЕФгяСЯЪЧвЛИіФбЬтЃЌШчКЮОЁСПБмУтгУЙ§ЖрЕФШЫЙЄЪжЖЮРДБЃжЄжЪСПЃЌШчКЮгУздЖЏЕФЗНЗЈРДЬсЩ§гяСЯЕФжЪСПЖМЪЧФбЬтЁЃЫљвдЃЌШчЙћФмЙЛЬсГівЛжжШЋаТЕФЫМТЗРДЙЙНЈздЖЏЮФеЊгяСЯЕФЛАЃЌНЋЛсЗЧГЃгавтвхЁЃ
|









