аДдкЧАУцЕФЛА
дкЧАУцвЛеТжаЫЕЕНСЫTensorFlowЕФЛљДЁгУЗЈЃЌетвЛеТзїЮЊвЛИіНјНзРДСФСФЩёОЭјТчЕФОпЬхЕФНсЙЙКЭВЮЪ§ЮЪЬтЃЌАќРЈЃК
ЧАРЁЩёОЭјТч
бЛЗЩёОЭјТч
ЩёОЭјТчВЮЪ§
ДѓИХОЭетШ§ИіжааФФкШнЁЃЕБШЛУПИіВПЗжеЙПЊгжЪЧКмЖрЖЋЮїЃЌЕЋЪЧКУдкетРяжЛЪЧСФСФЙЄОпЕФЪЙгУЁЃЫљвдДѓИХЛЙЪЧвЛИіеТНкЕФФкШнЁЃ
ЧАРЁЩёОЭјТч
ЧАРЁЩёОЭјТчАќРЈШЋСДНгЭјТчгыОэЛ§ЩёОЭјТчЃЌетСНепЦфЪЕВЂУЛгаДѓЕФЧјБ№ЃЌвЛАуЧщПіЯТПЩвдНЋОэЛ§ЩёОЭјТчПДзіЪЧвЛИіЬиР§ЁЃ
ШЋСДНгЭјТчгыОэЛ§ЭјТч
ЛєН№ЫЕЙ§ПЦЦеЪщРяМгвЛИіЙЋЪНОЭЛсЩйвЛАыЖСепЃЌЫљвдетРягУЙЋЪНРДжБЙлЕФЫЕУїЖўепЕФЙВЭЌЕуЃК
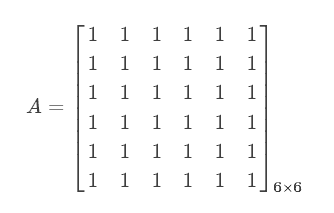
ЧАУцЫЕЕНШЋСДНгЭјТчЪЧвЛИіОиеѓЯрГЫЕФЙ§ГЬЃК
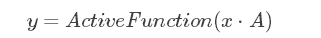
етЪЧвЛИіШЋСДНгЭјТчЃЌxЪЧвЛИівЛЮЌЯђСПЃЌШЋСДНгЭјТчЕФвЛИіЮЪЬтОЭЪЧВЮЪ§СПгаЕуДѓЃЌЩшЯывЛЯТЃЌШчЙћx,yЕФЮЌЖШОљЮЊ1000ЕФЛАФЧУДЯдШЛЫљашОиеѓAЕФВЮЪ§Ъ§СПЧсЖјвзОйЕФОЭЕНДяСЫ106ИіЃЌЖдгкађСаЪ§Он(БШШчвЛЮЌЕФЩљвєЪ§ОнЁЂЖўЮЌЕФЭМаЮЪ§Он)ЖјбдЯдШЛЦфЬиеїКмДѓГЬЖШЩЯПЩФмжЛгыЦфСйНќЕФЪ§ОнгаЙиЃЌетОЭЪЙЕУШЈжЕЯђСПдкМЦЫуЕФЪБКђПЩвдНЋгУВЛЕНЕФВПЗжЪЁТдЃК
ЩЯУцЕФОиеѓДњБэдквўВиВуМЦЫуЙ§ГЬжажЛМЦЫугыЦфСйНќЕФШ§ИіЕуЃЌЦфЫћВПЗжВЛНјааМЦЫуЃЌетбљЪЙЕУОиеѓAЕФВЮЪ§Ъ§СПЕУЕНСЫгааЇЕФМѕЩйЃЌСэЭтгЩгкађСаЪ§ОнЛђЭМЯёЪ§ОндкМЦЫуЙ§ГЬжаЬиеїЕФЯрЫЦадЃЌЪЙЕУИїИіВПЗжЕФЬиеїОпгажиИДадЃЌетбљдкМЦЫужаОЭПЩвдРћгУЭЌвЛЬзШЈжЕЃК
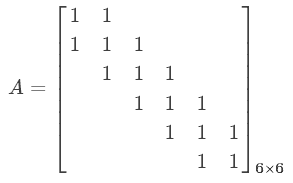
етОЭЪЧЫљЮНЕФШЈжЕЙВЯэЃЌЭЈЙ§етИіЙ§ГЬЃЌОЭПЩвдЪЙЕУШЋСЌНгВужаЕФВЮЪ§СПМЋДѓЕФМѕЩйЁЃетИіОЭЪЧШЋСЌНгЭјТчКЭОэЛ§ЭјТчЕФЙВЭЌЕуЁЃЬсвЛЯТЃЌЩЯУцФЧИіОэЛ§КЫаФПЩвдМЦЫуЕФЬиеїЪЧЁАЛЌЖЏЦНОљЁБЁЃ
НгЯТРДПДЯТКЏЪ§ЕФИЕРявЖеЙПЊЃК
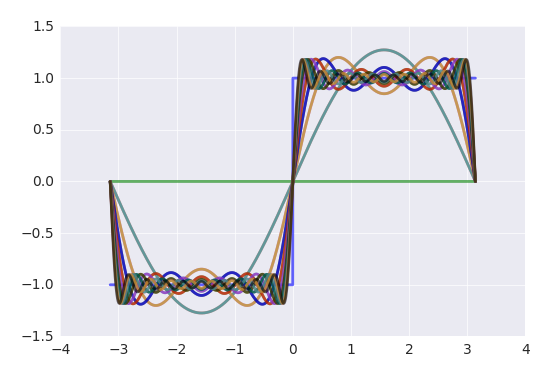
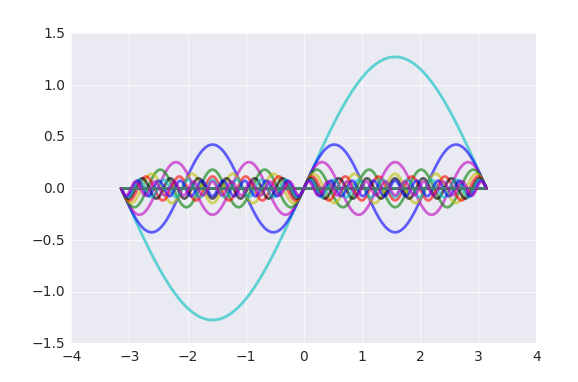
етЪЧКЏЪ§ЕФИЕРявЖеЙПЊЃЌетРявўВиСЫОэЛ§ЩёОЭјТчЕФвЛИіЫМЯыЃЌШчЙћНЋађСаxПДГЩвЛИіКЏЪ§ЕФЛАФЧУДЦфЬиеїПЩвдгУвЛЯЕСаЕФМђЕЅКЏЪ§ШЅБэЪОЃЌЖјЯргІЕФШЈжЕОЭЪЧШ§НЧКЏЪ§гыдКЏЪ§ЕФЛ§ЗжЃЌетИіЛ§ЗжЕФЙ§ГЬОЭПЩвдПДзіЪЧОэЛ§ЩёОЭјТчЕФОэЛ§ЕФЙ§ГЬЃЌЧАУцОиеѓЕФР§згжаОэЛ§КЫаФжЛгавЛИіЃЌФмЪАШЁЕФЬиеїЮЊЁАОљжЕЁБЃЌЖјОэЛ§КЫаФПЩвдгаЖрИіЃЌУПИіОэЛ§КЫаФгыдгаађСаxОљзівЛДЮОэЛ§ЕФЛАЫљЕУЕНЕФОЭЪЧЖдгІУПИіЬиеїЕФШЈжЕађСаЁЃИЕРявЖеЙПЊЕФвЛИіЬиЕуОЭЪЧnдНДѓдННгНќгкдКЏЪ§ЃЌФЧУДЕНОэЛ§ЩёОЭјТчетРяОЭПЩвдНЋЦкУшЪіЮЊОэЛ§ЕФЬиеїдНЖрдНПЩвдИќКУЕФУшЪіЪ§ОнЕФЬиеїЁЃ
гУtensorflowРДжБЙлЕФРэНтвЛЯТОэЛ§ЕФЙ§ГЬЃК
import tensorflow
as tf
import numpy as np
kn=np.ones([3,1,2],dtype=np.float32)
kn[:,:,0]=1/3
kernel = tf.Variable(kn)
x = tf.Variable(np.ones([1,1000,1],dtype=np.float32))
y = tf.nn.conv1d(x,kernel,stride=1,padding="SAME")
sess=tf.Session()
sess.run(tf.global_variables_initializer())
print("Out:",sess.run(y))
print("Shape:",np.shape(sess.run(y))) |
етЪЧвЛИіГЄЮЊ1000ЕФвЛЮЌЯђСПЃЌЦфЬиеїжЛгавЛИізюЧАУцЕФ1ДњБэЪфШыЪ§ОнИіЪ§ЮЊ1ЃЌОэЛ§КЫаФЮЌЖШЮЊ[3,1,2]ЃЌ3ДњБэОэЛ§КЫаФДѓаЁЃЌвВОЭЪЧЧАУцЫљЫЕЕФФмИВИЧЖрЩйЪ§ОнЕуЃЌ1ДњБэЪфШыЪ§ОнЬиеїЪ§СПЃЌ2ЪЧЪфГіЪ§ОнЬиеїЪ§СПЃЌПЩвдПДЕНЃЌЖдгкЕк0ИіЬиеїЦфОэЛ§КЫаФЕФШЈжЕЮЊ13вВОЭЪЧЧѓШЁОљжЕЃЌЕкЖўИіОэЛ§КЫаФШЈжЕЮЊ1ЃЌвВОЭЪЧЖдШ§ИіЪ§ОнНјааЯрМгЃЌПЩвдПДЯТзюжеНсЙћЃК
Out: [[[ 0.66666669
2. ]
[ 1. 3. ]
[ 1. 3. ]
...,
[ 1. 3. ]
[ 1. 3. ]
[ 0.66666669 2. ]]]
Shape: (1, 1000, 2) |
ПЩвдПДЕНЃЌЪфГіЪ§ОнЬиеїВЂУЛгаЪВУДЮЅЗДжБОѕЕФЕиЗНЃЌЪфГіЮЊСНИіЬиеїЃЌЕквЛИіЬиеїЮЊОљжЕЃЌЕкЖўИіЮЊЯрМгЃЌгЩгкpaddingБпНчЩшжУЮЊЁАSAMEЁБЃЌвВОЭЪЧДгЕквЛИіЕуПЊЪМзїЮЊЪфГіЕуЃЌетОЭЪЙЕУГЌГіВПЗжЕФШЈжЕЁЂЪ§ОнИГЮЊ0ЁЃ
ЕБШЛдкЩёОЭјТчжЎжаЧАУцVariableЪЧашвЊздЪЪгІЕФБфЛЏЕїећвдЬсШЁЬиЖЈЪ§ОнЕФЬиеїЁЃ
tensorflowЙЙНЈЧАРЁЩёОЭјТч
гУtensorflowЙЙНЈЧАРЁЩёОЭјТчзмЙВЗжЮЊШ§жжЗНЪНЃК
ЕквЛжжЃКжБНгЙЙНЈ
import tensorflow
as tf
#ОэЛ§Ву
def conv1d_layer (input_tensor, kernel_size, feature=2,
active_function="relu", name='conv1d'):
activ= {"relu":tf.nn.relu," sigmoid" :tf.nn.sigmoid," tanh" :tf.nn.tanh}
with tf.variable_scope(name):
shape = input_tensor.get_shape().as_list()
kernel = tf.get_variable('kernel',
(kernel_size, shape[-1], feature),
dtype=tf.float32,
initializer= tf.constant_initializer(0))
b = tf.get_variable('b',
[feature],
dtype=tf.float32,
initializer= tf.constant_initializer(0))
out = tf.nn.conv1d(input_tensor,
kernel,
stride=1,
padding='SAME') + b
return activ[active_function](out)
#ШЋСДНгВу
def full_layer (input_tensor, out_dim=2, active_function=" relu",
name='full'):
activ= {"relu":tf.nn.relu, "sigmoid" :tf.nn.sigmoid," tanh":tf.nn.tanh}
with tf.variable_scope(name):
shape = input_tensor.get_shape().as_list()
W = tf.get_variable('W',
(shape[1], out_dim),
dtype=tf.float32,
initializer= tf.constant_initializer(0))
b = tf.get_variable('b',
[out_dim],
dtype=tf.float32,
initializer= tf.constant_initializer(0))
out = tf.matmul(input_tensor,W) + b
return activ [active_function](out) |
ЩЯУцЪЧгУtensorflowКЏЪ§ЙЙНЈЕФШЋСДНгЭјТчгыОэЛ§ЩёОЭјТчЁЃКЏЪ§ЕїгУЙ§ГЬПЩвдЪЙгУЃК
net=full_layer(xx,
featrue=2, active_function="relu", name="full_connect_1")
net=conv1d_layer(net,3, feature=2, active_function="relu",
name="conv1d_1") |
етбљОЭЙЙГЩСЫЕЅвЛВуЩёОЭјТчЕФЙЙНЈЁЃ
ЖдгкЖрВуЩёОЭјТчЖјбдПЩвдНЋЪфГіЪ§ОнНјааНјааОэЛ§КЭШЋСДНгВйзїЃК
net = conv1d_layer(net,
3, feature=2, active_function="relu",
name="conv1d_1")
net = conv1d_layer(net, 3, feature=2, active_function="relu",
name="conv1d_2")
net=conv1d_layer(net, 3, feature=2, active_function="relu",
name="conv1d_3") |
ЕБШЛУПВуЕФnameвЊВЛЭЌЃЌЗёдђЛсБЈДэЁЃ
ЕкЖўжжЃКЭЈЙ§contribИпВуДЮAPI
ЧАУцгУвЛаЉЛљБОЕФAPIЙЙНЈЙ§ГЬашвЊздааЕФШЅаДвЛаЉКЏЪ§ЃЌЕЋЪЧетИіКЏЪ§ЪЧПЩвдЭЈЙ§contribРяУцЕФКЏЪ§ШЅНјааМђЕЅЕФЙЙНЈЕФЃК
import tensorflow.contrib.slim
as slim
net = slim.conv2d(net, 3, 1, scope='conv1d_1')
net = slim.flatten(net)
net = slim.flatten(net)
net = slim.fully_connected(net, 2,
activation_fn=tf.nn.relu,
scope='outes',
reuse=False) |
ПЩвдПДЕНЭЈЙ§slimИпВуДЮapiЪЕМЪЩЯПЩвдМђЛЏећИіЭјТчЕФЙЙНЈЙ§ГЬЁЃетРягаИіreuseВЮЪ§ЃЌЪЧИДгУВЮЪ§ЁЃ
ЭЈЙ§kerasЙЙНЈЩёОЭјТч
kerasЦфЪЕЪЧвЛИіЙЙНЈЩёОЭјТчБШНЯЗНБуЕФКЏЪ§ПтЃЌЦфЕзВуМЦЫуПЩвдЗХЕНtensorflowжЎжаЃК
from keras.layers
import Input, Dense, Conv1D
net = Input(shape=(1000,1))
net = Conv1D(kernel_size=3,filters=1,padding="same")(net)
net=Activation("relu")(net) |
ЕБШЛБОеТвдЬьtensorflowЮЊжїЃЌЫљвдетРяkerasНіЙЉСЫНтЁЃЦфЪЕЯжЦ№РДБШtensorflowЯрЖдМђЕЅЁЃ
бЛЗЩёОЭјТч
бЛЗЩёОЭјТчЙЙНЈЦ№РДЯрЖдгкЧАРЁЩёОЭјТчРДЫЕБШНЯТщЗГЃЌЕБШЛзюТщЗГЕФЪЧЦфбЕСЗЙ§ГЬЁЃ
ЧАУцЫЕЕНШЋСДНгЭјТчЕФЙ§ГЬЮЊЃК
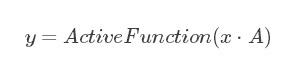
ЖјбЛЗЩёОЭјТчгыЩЯвЛВНЕФЪфШыЯрЙиЃЌЦфЪЕжЛЪЧГЫвдСЫвЛИіЩЯвЛВНЕФОиеѓЃК
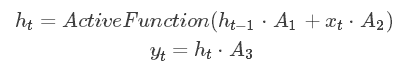
етОЭЪЧвЛИізюМђЕЅЕФбЛЗЩёОЭјТчЃЌдкДЫжЎЩЯПЩвдЙЙНЈЖрВуЕФЩёОЭјТчЃЌЖЈвхytгыxtжЎМфЕФЙиЯЕЮЊЃК
етЪЧЙЙНЈЕФЖрВуЕФбЛЗЩёОЭјТчЁЃЦфЫћЕФбЛЗЩёОЭјТчНсЙЙЪЧдкЦфЩЯНјааЕФаоИФЁЃжЛЪЧВЮЪ§ИќЖрЃЌБШШчLSTMЁЃLSTMЪфШыжаМгШыСЫвЛИіCОиеѓгУгкБЃДцМЧвфЁЃ
tensorflowЙЙНЈбЛЗЩёОЭјТч
ЩЯУцЫЕЕНвЛИібЛЗЩёОЭјТчЕФВуПЩвдЭЈЙ§ШчЯТЕФКЏЪ§ЙЙНЈЃК
cell = tf.contrib.rnn.BasicLSTMCell(
hidden_size, forget_bias=0.0, state_is_tuple=True,
reuse=not is_training) |
ЖрВуОэЛ§ЩёОЭјТчЙЙНЈЃК
cell = tf.contrib.rnn.MultiRNNCell(
[cell for _ in range(num_layers)], state_is_tuple=True) |
ЧАУцЫЕЕНбЛЗЩёОЭјТчЕФЪ§ОнЪфШыЪЧвЛВНвЛВНЪфШыЕФЃЌвђДЫетРядкНјааЪ§ОнЪфШыЕФЙ§ГЬжавВашвЊвЛВНвЛВНЕФНјааЪ§ОнЕФЪфШыЃК
for time_step
in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step,
:], state) |
етРягаСНИіЕиЗНашвЊНтЪЭЃЌЕквЛИіЪЧreuseЕФЮЪЬтЃЌвђЮЊдкЕк0ВНжЎКѓЕФБфСПгыЧАУцЕФБфСПЖМЪЧИДгУЕФЃЌвђДЫетРяашвЊНЋЦфИФБфЮЊИДгУФЃЪНЁЃЕкЖўИіЪЧstateЃЌетИіstateЪЧLSTMЩёОЭјТчНсЙЙЫљЬигаЕФЃЌЦфФПЕФдкгкБЃДцЁАМЧвфЁБЃЌЖјМЧвфСПЕФЖрЩйдђЫцзХЩёОЭјТчШЮЮёБфЛЏЖјздЪЪгІЕФБфЛЏЃЌвђДЫГЦжЎЮЊЁАГЄЖЬМЧвфЁБЃЌетЪБcell_outputзїЮЊЪфГіОЭПЩвдгУгкКѓајДІРэСЫЁЃПЩвдПДЕНRNNЕФЙЙНЈЙ§ГЬЯрБШгкЧАРЁЩёОЭјТчЖјбдЪЧБШНЯИДдгЕФЃЌетЦфжазюЙиМќЕФЪЧвђЮЊЦфЪфШыЪЧЁАвЛВНвЛВНЁБЕФНјааЪфШыЕФЁЃ
ЩёОЭјТчВЮЪ§бЁШЁ
етвЛНкФкШнЕФЛАОЭБШНЯЖрСЫЃЌЖјЧвгаКмЖрЁАаўбЇЁБЕФИаОѕЃЌвђЮЊВЮЪ§ЕФбЁШЁЖМДјгавЛЖЈЕФжїЙлЕФвђЫиЁЃ
здгЩВЮЪ§Ъ§СПгыЙ§ФтКЯЮЪЬт
ЕквЛИіЮЪЬтОЭЪЧВЮЪ§Ъ§СПЃЌВЮЪ§Ъ§СПЕФдіЖрЛсв§Ц№вЛИіНЯДѓЕФЮЪЬтОЭЪЧЙ§ФтКЯЮЪЬтЃЌгУЧњЯпФтКЯЕФЗНЪНРДСЫНтЃК
import tensorflow
as tf
import numpy as
#ЖЈвхКЏЪ§еЙПЊНзЪ§
N = 6
x = tf.placeholder (dtype=tf.float32, shape=[1,None])
y = tf.placeholder (dtype=tf.float32, shape=[1,None])
comp = []
#КЏЪ§еЙПЊЯю
for itr in range(N):
comp.append(tf.pow(x, itr))
x_v = tf.concat(comp,axis=0)
#ЖЈвхеЙПЊЯЕЪ§
A = tf.Variable(tf.zeros([1, N]))
y_new = tf.matmul(A, x_v)
#ЖЈвхlossКЏЪ§
loss = tf.reduce_sum(tf.square(y-y_new))
#гУЬнЖШЕќДњЗЈЧѓНт
train_step = tf.train.GradientDescentOptimizer (0.0005).minimize(loss)
sess = tf.Session()
sess.run (tf.global_variables_initializer())
#ЕќДњ9000ДЮ
for itr in range(90000):
sess.run(train_step,
feed_dict= {x:np.array ([[-1, 0, 0.5773502691896258,
1, 1.5, 2]]),
y:np.array ([[0, 0, -0.3849, 0, 1.875, 4]])})
print(sess.run(A.value()))
#ЭМаЮЛцжЦ
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.style.use ('seaborn-darkgrid')
lin = np.array ([np.linspace(-1, 2, 100)])
ly =sess.run (y_new, feed_dict={x: lin})
plt.plot(lin[0], ly[0])
plt.scatter ([-1, 0, 0.5773502691896258, 1, 1.5,
2],
[0, 0, -0.3849, 0, 1.875, 4])
plt.show() |
РДПДЯТЪфГіЭМаЮЃК
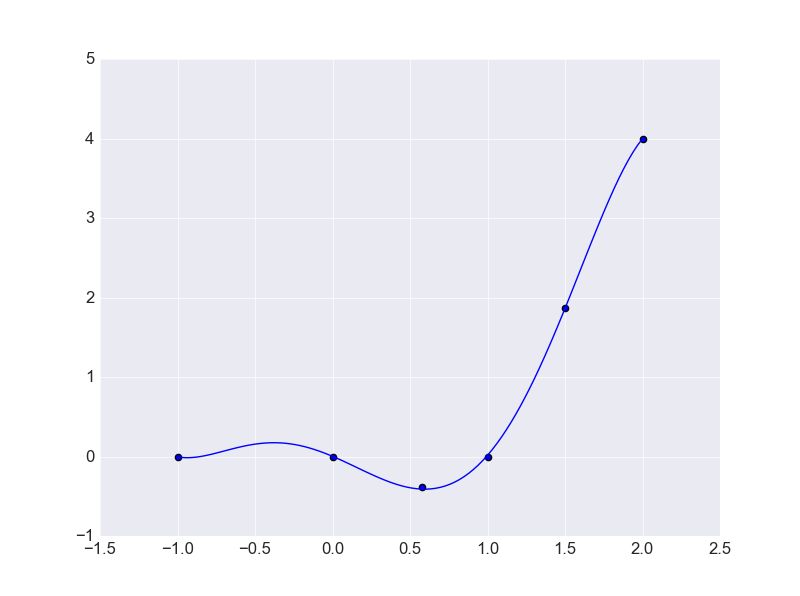
ПЩвдПДЕНЧњЯпЭъУРЕФЭЈЙ§СЫУПвЛИіЕуЃЌЕЋЪЧетжжЧщПіПЩФмВЂЗЧЪЧвЛИіЁАКУЁБЕФНсЙћЃЌвђЮЊЦфЖдгкбЕСЗЪ§ОнФтКЯЙ§гкКУСЫЃЌЖдгкбЕСЗМЏвдЭтЕФЪ§ОнПЩФмдЄВтаЇЙћВЂВЛРэЯыЁЃНЋКЏЪ§ШЁжЕЗЖЮЇДг-5ЕН5дйРДЛцжЦЭМаЮЃК
import matplotlib.pyplot
as plt
import matplotlib as mpl
mpl.style.use('seaborn-darkgrid')
lin = np.array([np.linspace(-5, 5, 100)])
ly =sess.run(y_new, feed_dict={x: lin})
plt.plot(lin[0], ly[0])
plt.scatter([-1, 0, 0.5773502691896258, 1, 1.5,
2],
[0, 0, -0.3849, 0, 1.875, 4])
plt.show() |
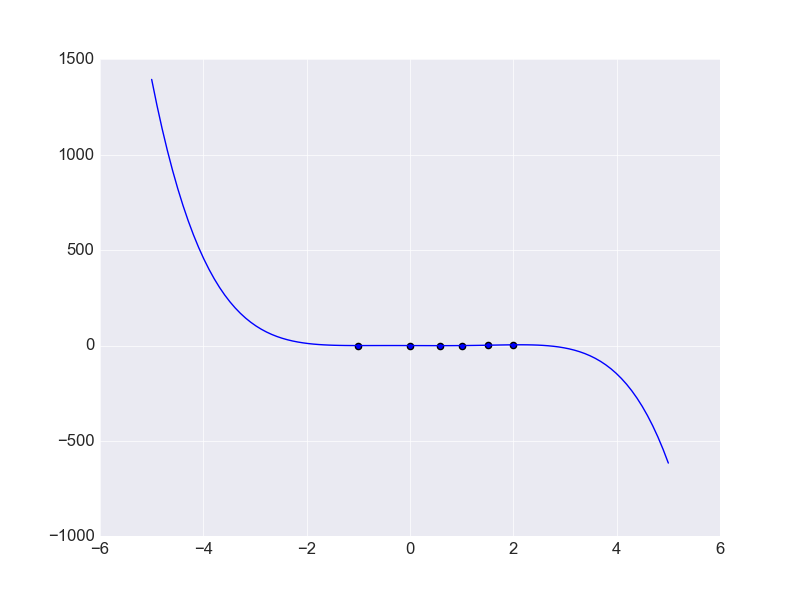
дкбЕСЗЪ§ОнжЎЭтЧњЯпБфаЮБШНЯДѓЃЌетЛсгАЯьЖдгкЧњЯпЕФФтКЯаЇЙћЁЃСэвЛЗНУцРДЫЕвВОЭЪЧЖдгкЪ§ОнЕФдЄВтаЇЙћВЛРэЯыЁЃдкетРяШчЙћМѕЩйВЮЪ§Ъ§СПЃК
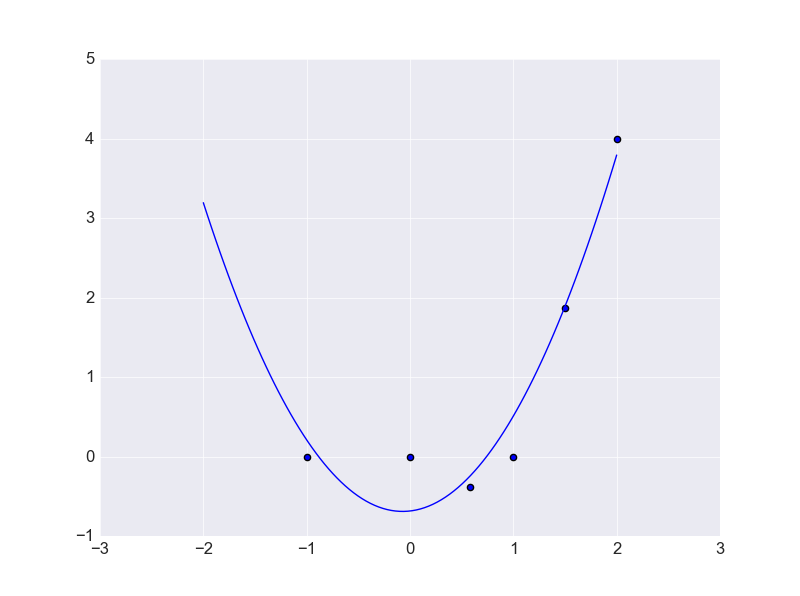
ДЫЪБПЩФмВЂЮДЭЈЙ§УПвЛИіЕуЃЌЕЋЪЧЫљгУЕФздгЩВЮЪ§ИіЪ§жЛгаШ§ИіЃЌЕЋЪЧЖдгкПЩФмЕФЪ§ОнЗжВМаЮЪНЃК
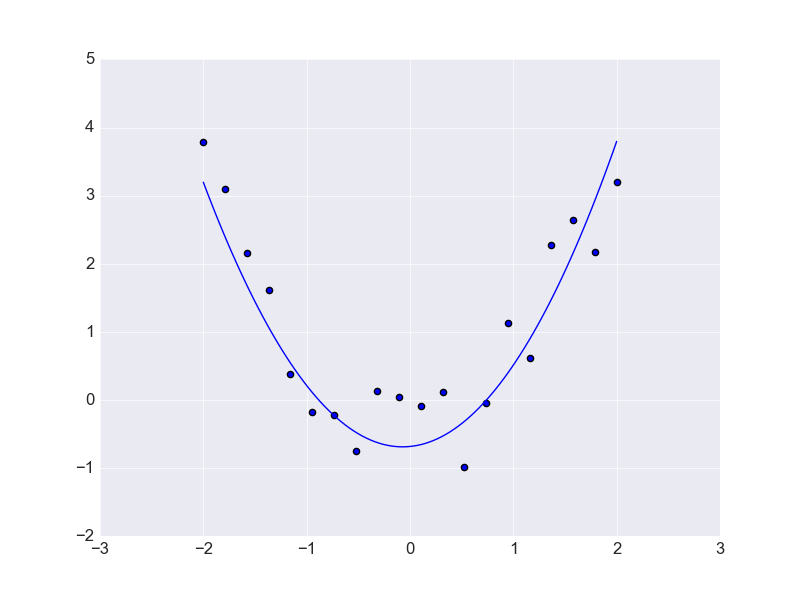
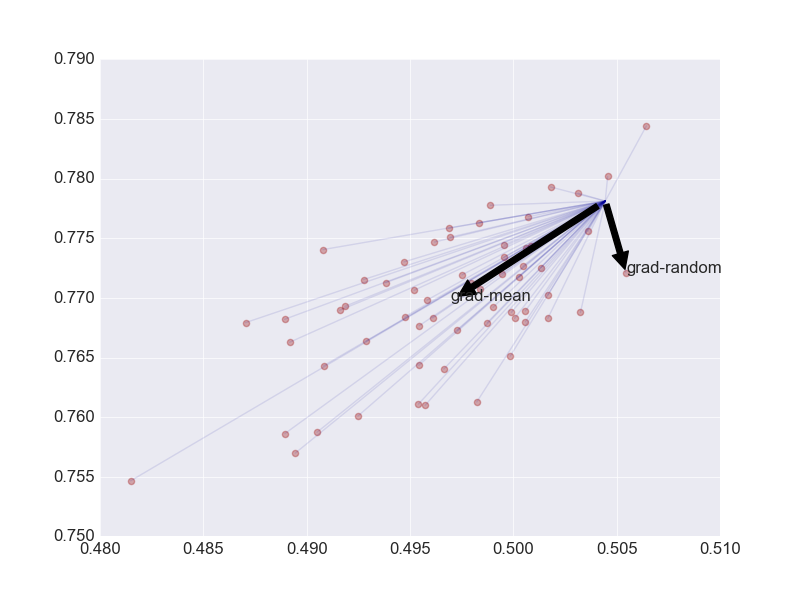
ЯждкгУЁЎЖўДЮЧњЯпЁЏПЩвдЖдЪ§ОнНјааИќКУЕФдЄВтЃЌвђДЫНтОіЙ§ФтКЯЮЪЬтзюИљБОЕФЮЪЬтОЭЪЧдіМгбЕСЗМЏЪ§СПЁЃ
BATCHSIZE
етИіЪЧвЛДЮЪфШыЖрЩйЪ§ОнгУгкбЕСЗЕФЮЪЬтЃЌЯТУцЕФЬнЖШЗНЯђЪЧЛљгкЖўЮЌЧњУцФтКЯЕФLMSЗНЗЈЫљбдЕФЃЌПЩвдПДЕНЃК
ЫцЛњЬнЖШДјгавЛЖЈЕФЫцЛњадЃЌЫфШЛАДееИХТЪНЧЖШРДЫЕЪЧПЩвдЪеСВЕФЃЌЕЋЪЧЯдШЛЭЈЙ§60ИіЪ§ОнНјааЬнЖШЕФЙРМЦЫљДјРДЕФЗНЯђдЄВтИќМгзМШЗЃЌвђДЫBATCHSIZEДцдкЕФвЛИівтвхОЭЪЧНјааИќКУЕФЬнЖШЗНЯђЕФдЄВтЃЌЕБШЛШчЙћгУећИібЕСЗМЏРДЙРМЦЬнЖШЗНЯђЕФЛАЪЧИќКУЕФЁЃЕЋЪЧетРяУцСйвЛИіаЇТЪКЭФкДцЕФЮЪЬтЁЃетРягУ17ВуInceptionЭјТчРДзіИіБэИёЃЌЪЕбщЛњЦїОЭЪЧE3ЗЧGPUАцБОЃК

ЮвЯыетИіБэИёвбОФмЫЕУїЮЪЬтСЫЃЌЫфШЛПЩвдИќКУЕФЙРМЦЬнЖШЗНЯђЃЌЕЋЪЧМЦЫуЪБМфКЭФкДцЕФЯћКФЪЧГЪЯпаддіГЄЕФЁЃ
ЬнЖШВЮЪ§
ЬнЖШВЮЪ§ЕФбЁШЁзмЕФРДЫЕЖдгкЕќДњЕФгАЯьЪЧБШДѓЕФЃЌЙ§ДѓЕФЬнЖШВЮЪ§ЛсЪЙЕУЕќДњЗЂЩЂЃК
ФЧИіРЖЯпЃЌдкМЦЫуЙ§ГЬжаВЛНіУЛгаж№НЅМѕЩйЗДЖјдНРДдНДѓЃЌЯыРэНтЗЂЩЂЙ§ГЬБШНЯМђЕЅЃК
| train_step = tf.train.GradientDescentOptimizer(500).minimize(loss) |
АбЧњЯпФтКЯЕФЬнЖШВЮЪ§бЁЮЊ500ЃЌЮветРябЁдёЕФЪЧ0.5РДЙлВьlossКЏЪ§ЃК

етИіЗЂЩЂЪЧГЪжИЪ§діМгЕФЃЌКмПьОЭГЌГіЛњЦїЕФЪ§жЕБпНчЁЃ
БШНЯДѓЕФЬнЖШВЮЪ§ПЩвдВЮПМЩЯУцФЧИіЭМЕФКьЯпЃЌдкСНИіЕужЎМфВЛЭЃе№ЕДЁЃЖјЙ§аЁЕФЬнЖШВЮЪ§ЛсЪЙЕУЪеСВЛКТ§ЁЃБШШчКнаФвЛаЉНЋЬнЖШВЮЪ§бЁЮЊ5ЁС10?15
| tf.train.GradientDescentOptimizer(5e-15) |
етЪБЃК
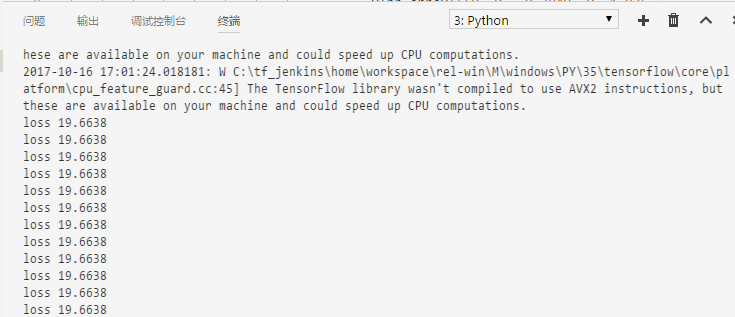
enter image description here
ЪеСВЙ§ГЬБфЕУМЋЮЊЛКТ§ЃЌЛђепЫЕЛљБОУЛгаБфЛЏЁЃ
РэжЧЕФзіЗЈЬнЖШВНГЄЫцзХЕќДњВЛЖЯЕФМѕЩйЁЃ
BATCHNORMВу
ЧАУцЫЕЙ§BPЫуЗЈжавЛИіЙ§ГЬОЭЪЧГЫвдОиеѓЃКгааЫШЄВЮПМЮФеТ
ЕЋЫцзХВуЪ§діЖрЫљГЫЕФОиеѓвВдкВЛЖЯЕФдіЖрЃЌФЧУДОЭЛсгіЕНЬнЖШЯћЪЇЕФЮЪЬтЃЌОЭЯёМІЬРЫЕЕФУПЬьЭќМЧАйЗжжЎвЛЃЌвЛАйЬьКѓОЭЪЃЯТ37%СЫЃЌетЪЧвЛИіжИЪ§ЕФЮЪЬтЃЌBPЫуЗЈвВЪЧШчДЫЃЌвђДЫв§ШыСЫBATCHNORMВуЃЌвдНтОіЩЯЪіЮЪЬтЁЃtensorflowжагаЯргІЕФДњТыЃК
| tf.contrib.layers.batch_norm |
аЮЯѓЛЏ
вЛАудкЬжТлДПРэТлЮЪЬтЕФЪБКђКмЖрШЫЖМгаИіКмВЛКУЕФЯАЙпОЭЪЧеввЛИіЮяРэгГЩфЃЌетжжЮяРэгГЩфПЩвдАяжњРэНтЮЪЬтЃЌЕЋЪЧПЩФмЛсдкжЎКѓЕФбЇЯАжаВЂВЛШчжБНгЕФЪ§бЇРэНтИќгаАяжњЁЃ
ФЧУДдйРДПДЯТећИіЕФбЛЗЩёОЭјТчЕФНсЙЙЃК
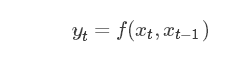
ЛђепЫЕЃК 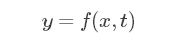
етжжаЮЪНЕФЮЪЬтдкАќКЌГЫЗЈВйзїЕФЧщПіЯТГЦжЎЮЊЗЧЯпадЮЪЬтЁЃПЩФмгУвЛИіБШНЯЙуЮЊШЫжЊЕФДЪОЭЪЧЛьучЃЌRNNКЭCNNЭјТчОљПЩвдЖдЛьучЮќв§згНјаажиНЈЁЃ
ЯТУцетИіЪЧвЛИіЕфаЭЕФЛьучЮќв§згЃК 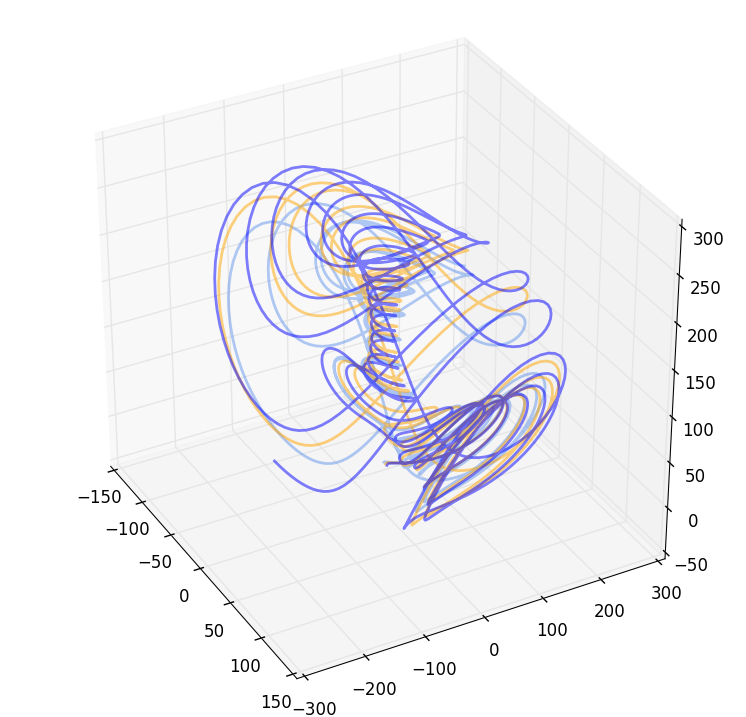
ЗНГЬУшЪіЃК
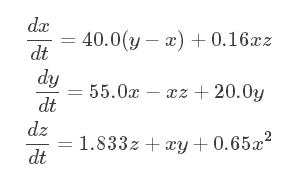
ФЧУДЪ§жЕЧѓНтЩЯЪіЗНГЬЕФЙ§ГЬЪЕМЪЩЯОЭЪЧРрЫЦгкRNNЕФЙ§ГЬЁЃ
ФЧУДШ§ЬхдЫЖЏЗНГЬЪЕМЪЩЯвВЪЧвЛИіЗЧЯпадЗНГЬЕФЮЪЬтЃЌВЂЧвШ§ЬхдЫЖЏВЂЗЧЪЧЭъШЋВЛПЩдЄВтЕФЁЃ

КмЖрЪБКђЦфБэЯжГіИХТЪЕФЬиеїЃЌетЪЧПЩвдЭЈЙ§ЭГМЦЗжЮіЕУЕНЕФЁЃ
гааЫШЄЕФЃЌПЩвдВЮПМЪ§жЕФЃФтЙ§ГЬгУЩёОЭјТчжиНЈЮќв§згЁЃ
|









